14 mag 2025·8 min
Perché i carichi OLTP e OLAP raramente dovrebbero condividere lo stesso database
Scopri perché mescolare transazioni (OLTP) e analisi (OLAP) in un unico database può rallentare le app, aumentare i costi e complicare le operazioni — e cosa fare invece.
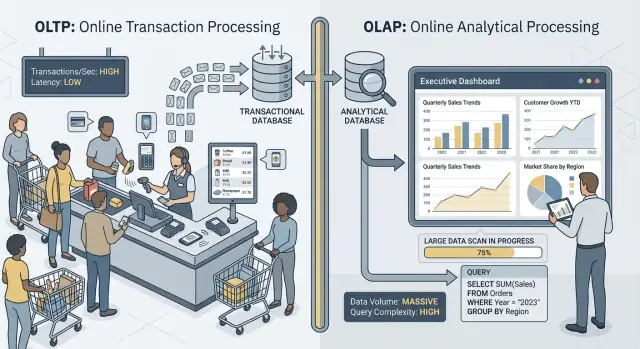
OLTP vs OLAP: cosa sono (senza gergo)
Quando si parla di “OLTP” e “OLAP” si intendono due modi molto diversi di usare un database.
OLTP: il database che fa girare il business
OLTP (Online Transaction Processing) è il carico dietro le azioni quotidiane che devono essere veloci e corrette ogni volta. Pensa: “salva questa modifica adesso.”
Tipiche attività OLTP includono creare un ordine, aggiornare l'inventario, registrare un pagamento o cambiare un indirizzo cliente. Queste operazioni sono di solito piccole (poche righe), frequenti e devono rispondere in millisecondi perché una persona o un altro sistema stanno aspettando.
OLAP: il database che spiega il business
OLAP (Online Analytical Processing) è il carico usato per capire cosa è successo e perché. Pensa: “scansiona molti dati e riassumili.”
Tipiche attività OLAP includono dashboard, report di trend, analisi per coorti, previsioni e domande “slice-and-dice” come: “Come è cambiato il fatturato per regione e categoria di prodotto negli ultimi 18 mesi?” Queste query spesso leggono molte righe, eseguono aggregazioni pesanti e possono durare secondi (o minuti) senza essere "sbagliate".
Stessi dati, obiettivi diversi—e necessità diverse
L'idea principale è semplice: OLTP ottimizza per scritture veloci e consistenti e letture piccole, mentre OLAP ottimizza per letture ampie e calcoli complessi. Poiché gli obiettivi divergono, anche le migliori impostazioni del database, gli indici, il layout dello storage e l'approccio di scaling spesso differiscono.
Nota anche il termine: raramente, non mai. Alcune squadre piccole possono condividere un database per un periodo, specialmente con volumi modesti e disciplina nelle query. Le sezioni successive spiegano cosa si rompe prima, i pattern comuni di separazione e come spostare il reporting fuori dalla produzione in modo sicuro.
Esempi rapidi
- Checkout (OLTP): un cliente clicca “Pay” e la tua app scrive un ordine, lo stato del pagamento e aggiorna l'inventario.
- Dashboard di reporting (OLAP): un manager apre una dashboard che aggrega migliaia (o milioni) di ordini per mostrare conversion rate, valore medio d'ordine e trend settimanali.
Obiettivi diversi, metriche di successo diverse
OLTP e OLAP possono entrambi “usare SQL”, ma sono ottimizzati per lavori differenti—e questo si vede in cosa considerano successo.
OLTP: velocità, concorrenza e correttezza
I sistemi OLTP (transazionali) alimentano le operazioni giornaliere: flussi di checkout, aggiornamenti account, prenotazioni, strumenti di supporto. Le priorità sono chiare:
- Tempi di risposta rapidi per letture/scritture piccole (millisecondi)
- Molti utenti concorrenti senza rallentamenti
- Correttezza e consistenza, perché un saldo sbagliato o un ordine duplicato sono problemi reali
Il successo viene spesso misurato con metriche di latenza come p95/p99, tasso di errori e comportamento sotto picchi di concorrenza.
OLAP: scansione, aggregazione e flessibilità
I sistemi OLAP rispondono a domande come “Cosa è cambiato questo trimestre?” o “Quale segmento ha abbandonato dopo il nuovo prezzo?” Queste query spesso:
- Scansionano grandi quantità di dati su molte righe
- Eseguono aggregazioni (SUM, COUNT, percentili) e join
- Cambiano frequentemente mentre gli analisti esplorano e raffinano le domande
Il successo qui è più simile a throughput di query, time-to-insight e la capacità di eseguire query complesse senza dover ottimizzare manualmente ogni report.
Perché “un sistema per tutto” crea compromessi
Quando forzi entrambi i carichi su un unico database, chiedi al sistema di essere eccellente sia nelle transazioni piccole e ad alto volume sia nelle grandi scansioni esplorative. Il risultato è quasi sempre un compromesso: l'OLTP ottiene latenze imprevedibili, l'OLAP viene limitato per proteggere la produzione e i team litigano su quali query sono “permesse”. Obiettivi diversi meritano metriche di successo diverse—e di solito sistemi separati.
Contesa di risorse: quando l'analisi ruba alle transazioni
Quando OLTP (le transazioni quotidiane della tua app) e OLAP (reporting e analisi) girano sullo stesso database, competono per le stesse risorse finite. Il risultato non è solo “report più lenti.” Spesso si traduce in checkout più lentI, login bloccati e comportamenti imprevedibili dell'app.
CPU e memoria: query lunghe vs query brevi
Le query analitiche tendono a essere lunghe e pesanti: join su tabelle grandi, aggregazioni, ordinamenti e raggruppamenti. Possono monopolizzare i core CPU e, altrettanto importante, la memoria per hash join e buffer di ordinamento.
Nel frattempo, le query transazionali sono solitamente piccole ma sensibili alla latenza. Se la CPU è satura o la pressione sulla memoria forza frequenti eviction, quelle piccole query iniziano ad aspettare dietro le grandi—anche se ogni transazione richiede solo pochi millisecondi di lavoro effettivo.
I/O disco: grandi scansioni vs molte piccole letture/scritture
L'analisi spesso provoca scansioni di tabelle e letture di molte pagine in sequenza. L'OLTP fa il contrario: molte piccole letture casuali oltre a scritture continue su indici e log.
Mettendoli insieme, il sottosistema di storage deve gestire pattern di accesso incompatibili. Le cache che aiutavano l'OLTP possono essere “lavate via” dalle scansioni analitiche e la latenza di scrittura può aumentare quando il disco è occupato a trasmettere dati per i report.
Pressione sul pool di connessioni e code
Pochi analisti che eseguono query ampie possono occupare connessioni per minuti. Se l'app usa un pool di dimensione fissa, le richieste si accodano in attesa di una connessione libera. Questo effetto di code può far sembrare il sistema rotto: la latenza media può risultare accettabile, ma le latenze di coda (p95/p99) diventano dolorose.
Cosa notano gli utenti
Dall'esterno, questo si manifesta come timeout, flussi di checkout lenti, risultati di ricerca ritardati e comportamento instabile—spesso “solo durante i report” o “solo a fine mese.” Il team app vede errori; gli analisti vedono query lente; il problema reale è la contesa condivisa sotto.
Layout dei dati e necessità di indicizzazione vanno in direzioni opposte
OLTP e OLAP non si limitano a “usare il database in modo diverso”—premiano design fisici opposti. Quando cerchi di soddisfare entrambi in un unico posto, finisci per fare un compromesso costoso e comunque sotto-performante.
OLTP: ottimizzato per lookup rapidi e selettivi
Il carico transazionale è dominato da query brevi che toccano una piccola porzione di dati: recuperare un ordine, aggiornare una riga di inventario, elencare gli ultimi 20 eventi per un singolo utente.
Questo spinge gli schemi OLTP verso storage orientato per righe e indici che supportano lookup puntuali e piccole scansioni di range (spesso su chiavi primarie, chiavi esterne e pochi indici secondari di valore). L'obiettivo è latenza prevedibile e bassa—soprattutto per le scritture.
OLAP: ottimizzato per scansioni, raggruppamenti e sintesi
Il carico analitico spesso deve leggere molte righe e poche colonne: “fatturato per settimana per regione”, “tasso di conversione per campagna”, “prodotti migliori per margine”.
I sistemi OLAP beneficiano di storage columnare (per leggere solo le colonne necessarie), partizionamento (per escludere velocemente dati vecchi o irrilevanti) e pre-aggregazioni (materialized views, rollup, tabelle di riepilogo) così i report non ricalcolano sempre gli stessi totali.
Perché "indicizzare tutto" fallisce
Una reazione comune è aggiungere indici finché ogni dashboard non è veloce. Ma ogni indice in più aumenta il costo delle scritture, lo spazio di archiviazione e può rallentare compiti di manutenzione come vacuum, reindex e backup.
Planner di query e deriva delle statistiche (in parole semplici)
I database scelgono i piani di query basandosi su statistiche—stime di quante righe corrispondono a un filtro, quanto è selettivo un indice e come sono distribuiti i dati. L'OLTP cambia i dati costantemente. Man mano che le distribuzioni cambiano, le statistiche possono deragliare e il planner può scegliere un piano che era ottimo ieri ma è lento oggi.
Aggiungi query OLAP pesanti che scandiscono e fanno join su tabelle grandi, e ottieni più variabilità: il “miglior piano” diventa più difficile da prevedere, e ottimizzare per un carico spesso peggiora l'altro.
Locking, MVCC e effetti collaterali di manutenzione
Anche se il tuo database “supporta la concorrenza”, mescolare reporting pesante con transazioni live crea rallentamenti sottili difficili da prevedere—e ancora più difficili da spiegare a un cliente che vede il checkout che gira a vuoto.
Le query lunghe creano comunque problemi di lock
Le query in stile OLAP spesso scandiscono molte righe, uniscono più tabelle e durano secondi o minuti. Durante quel tempo possono tenere lock (per esempio su oggetti di schema, o quando devono ordinare/aggregare in strutture temporanee) e frequentemente aumentano la contesa indirettamente mantenendo molte righe “in gioco”.
Anche con MVCC (multi-version concurrency control), il database deve tracciare versioni multiple della stessa riga così lettori e scrittori non si bloccano a vicenda. Questo aiuta, ma non elimina la contesa—soprattutto quando le query toccano tabelle "calde" che le transazioni aggiornano costantemente.
MVCC ha un costo nascosto: la pulizia diventa più difficile
MVCC significa che le vecchie versioni delle righe rimangono finché il database non può rimuoverle in sicurezza. Un report di lunga durata può mantenere aperto uno snapshot vecchio, impedendo alla pulizia di recuperare spazio.
Questo impatta:
- Vacuum / garbage collection: la pulizia non può rimuovere i tuple/versioni morte rapidamente.
- Bloat/fragmentazione: lo storage cresce, gli indici diventano meno efficienti e le cache meno utili.
- Pressione sulla compattazione: alcuni motori rispondono eseguendo lavori in background più pesanti, che rubano I/O e CPU alle transazioni.
Il risultato è un doppio colpo: il reporting fa lavorare di più il database e rallenta il sistema nel tempo.
I livelli di isolamento amplificano la variabilità della latenza
Gli strumenti di reporting spesso richiedono isolamento più forte (o accidentalmente eseguono una transazione lunga). Un isolamento più alto può aumentare l'attesa sui lock e la quantità di versioning che il motore deve gestire. Dal lato OLTP, si vede come spike imprevedibili: la maggior parte degli ordini scrive velocemente, poi alcuni rallentano all'improvviso.
Esempio pratico: il reporting di fine mese rallenta gli ordini
A fine mese, finance esegue una query “fatturato per prodotto” che scansiona ordini e righe per l'intero mese. Mentre gira, le nuove scritture di ordini vengono accettate, ma il vacuum non può recuperare le vecchie versioni e gli indici lavorano molto. L'API degli ordini inizia a vedere timeout occasionali—non perché sia “down”, ma perché contesa e overhead di pulizia spingono la latenza oltre i limiti.
Picchi di carico e latenza imprevedibile
Prototype an OLTP OLAP split
Map services, tables, and reporting flows in Koder.ai planning mode before you build.
I sistemi OLTP vivono e muoiono dalla prevedibilità. Un checkout, un ticket di supporto o un aggiornamento di saldo non sono “abbastanza ok” se sono veloci al 95% del tempo—gli utenti notano i momenti lenti. L'OLAP, invece, è spesso bursty: poche query pesanti possono rimanere silenti per ore e poi consumare molto CPU, memoria e I/O.
I picchi accadono per ragioni normali
Il traffico analitico tende ad accumularsi intorno a routine:
- Dashboard per lo “standup” mattutino dove molti aggiornano gli stessi grafici
- Report schedulati che partono all'inizio dell'ora
- Chiusure di fine mese e revisioni trimestrali che attivano lunghe scansioni e join
Nel frattempo, il traffico OLTP è di solito più costante. Quando i due carichi condividono un database, questi picchi di analisi si traducono in latenza imprevedibile per le transazioni—timeout, pagine lente e retry che generano ulteriore carico.
Perché limiti e scheduling aiutano—ma non risolvono il disallineamento
Puoi ridurre i danni con tattiche come eseguire i report di notte, limitare la concorrenza, imporre statement timeouts o impostare cap sui costi delle query. Sono guardrail utili, specialmente per il “reporting su produzione”.
Ma non rimuovono la tensione fondamentale: le query OLAP sono progettate per usare molte risorse per rispondere a grandi domande, mentre l'OLTP ha bisogno di fette di risorse piccole e rapide tutto il giorno. Al primo refresh imprevisto di una dashboard, query ad-hoc o backfill che passa, il database condiviso è esposto di nuovo.
Il problema del vicino rumoroso
Su infrastruttura condivisa, un utente o job analitico “rumoroso” può monopolizzare la cache, saturare il disco o mettere sotto pressione lo scheduling CPU—senza fare nulla di sbagliato. L'OLTP diventa danno collaterale, e la parte più difficile è che i fallimenti sembrano casuali: spike di latenza invece di errori chiari e ripetibili.
Complessità operativa: backup, sicurezza e capacity planning
Mescolare OLTP e OLAP non crea solo problemi di performance—rende anche le operazioni quotidiane più difficili. Il database diventa una scatola “tuttofare” e ogni attività operativa eredita i rischi combinati dei due carichi.
Backup, restore e disaster recovery rallentano
Le tabelle analitiche tendono a crescere in larghezza e velocità (più storici, più colonne, più aggregati). Questo volume extra cambia la storia del ripristino.
Un backup completo richiede più tempo, consuma più storage e aumenta la probabilità di superare la finestra di backup. I restore sono peggiori: quando devi recuperare rapidamente, ripristini non solo i dati transazionali necessari all'app, ma anche grandi dataset analitici che non servono per riavviare il business. I test di disaster recovery richiedono più tempo e quindi vengono eseguiti meno spesso—esattamente il contrario di ciò che vorresti.
Il capacity planning diventa un tiro al bersaglio
La crescita transazionale è di solito prevedibile: più clienti, più ordini, più righe. La crescita analitica è spesso a scatti: una nuova dashboard, una nuova policy di retention o un team che decide di conservare “solo un anno in più” di eventi raw.
Quando convivono, è difficile rispondere a domande come:
- Stiamo crescendo per il successo del prodotto o perché i report stanno conservando più storico?
- Serve storage veloce per le transazioni o storage economico per l'analisi?
Quell'incertezza porta a sovra-provisionare (pagare per risorse inutilizzate) o sotto-provisionare (outage a sorpresa).
I guardrail sono più difficili da applicare in modo equo
In un database condiviso, una query “innocua” può diventare un incidente. Finirai per aggiungere guardrail come timeouts delle query, quote di carico, finestre di report schedulate o regole di workload management. Aiutano, ma sono fragili: l'app e gli analisti competono per gli stessi limiti e cambiare le policy per un gruppo può rompere l'altro.
Sicurezza e controllo di accesso diventano complessi
Le applicazioni tipicamente richiedono permessi stretti e mirati. Gli analisti spesso necessitano di ampio accesso in sola lettura, a volte su molte tabelle, per esplorare e validare. Mettere entrambi nello stesso database aumenta la pressione per concedere privilegi più larghi “solo per far funzionare il report”, ampliando il raggio d'azione degli errori e il numero di persone che possono vedere dati operativi sensibili.
Scaling e costi: finisci per pagare due volte (o peggio)
Start a transactional app fast
Create a React plus Go backend app from chat, ready for transactional workloads.
Cercare di far convivere OLTP e OLAP in uno stesso database sembra spesso più economico—finché non inizi a scalare. Il problema non è solo la performance. È che il modo “giusto” di scalare ciascun carico ti spinge verso infrastrutture diverse, e combinarle ti obbliga a compromessi costosi.
Lo scaling OLTP è guidato dalle scritture (e spesso doloroso)
I sistemi transazionali sono limitati dalle scritture: molti aggiornamenti piccoli, latenza stretta e picchi da assorbire immediatamente. Scalare l'OLTP spesso significa scaling verticale (CPU più potente, dischi più veloci, più memoria) perché i carichi write-heavy non si fan out facilmente.
Quando i limiti verticali sono raggiunti, si valuta lo sharding o altri pattern di scaling delle scritture. Questo aggiunge overhead ingegneristico e spesso richiede cambi nell'app.
Lo scaling OLAP è guidato dal compute (e spesso elastico)
I carichi analitici scalano in modo diverso: grandi scansioni, aggregazioni pesanti e tanto throughput di lettura. I sistemi OLAP tipicamente scalano aggiungendo compute distribuito, e molte architetture moderne separano compute e storage così puoi aumentare la potenza di query senza spostare o duplicare i dati.
Se l'OLAP condivide il database OLTP, non puoi scalare l'analisi indipendentemente: devi scalare tutto il database—anche se le transazioni vanno bene.
Il conto nascosto: pagare risorse da OLTP per l'analisi
Per mantenere le transazioni veloci mentre girano i report, i team sovra-provisionano il database di produzione: CPU extra, storage di fascia alta e istanze grandi “per ogni evenienza.” Questo significa pagare prezzi OLTP per supportare comportamenti OLAP.
La separazione riduce il sovra-provisionamento perché ogni sistema può essere dimensionato per il suo compito: OLTP per scritture a bassa latenza, OLAP per letture bursty. Il risultato è spesso più economico nel complesso—anche se si tratta di “due sistemi”—perché smetti di comprare capacità transazionale premium per eseguire reporting in produzione.
Architetture comuni che mantengono OLTP e OLAP separati
La maggior parte dei team separa il carico transazionale (OLTP) dal carico analitico (OLAP) aggiungendo un secondo sistema orientato alla lettura invece di costringere un database a servire entrambi.
Pattern 1: replica di sola lettura per reporting
Un primo passo comune è una read replica (o follower) del database OLTP, su cui eseguono query gli strumenti BI.
Pro: cambi minimi all'app, SQL familiare, facile da impostare.
Contro: è ancora lo stesso motore e schema, quindi i report pesanti possono saturare CPU/I/O della replica; alcune analisi richiedono funzionalità non disponibili sulle repliche; e il lag di replica significa che i numeri possono avere minuti (o più) di ritardo. Il lag crea conversazioni confuse del tipo “perché non corrisponde alla produzione?” durante gli incidenti.
Migliore per: team piccoli, volumi modesti, “near-real-time” utile ma non critico e query di reporting controllate.
Pattern 2: data warehouse dedicato / database analitico
Qui l'OLTP resta ottimizzato per scritture e letture puntuali, mentre l'analisi va in un data warehouse (o DB analitico columnare) progettato per scansioni, compressione e grandi aggregazioni.
Pro: performance OLTP prevedibili, dashboard più veloci, migliore concorrenza per gli analisti e tuning dei costi/più chiaro.
Contro: ora gestisci un altro sistema e serve un modello dati (spesso star schema) favorevole all'analisi.
Migliore per: dati in crescita, molti stakeholder, reporting complesso o requisiti di latenza OLTP stringenti.
Pattern 3: pipeline basata su CDC verso l'analytics
Invece di ETL periodico, trasmetti le modifiche usando CDC (change data capture) dal log OLTP nel warehouse (spesso con ELT).
Pro: dati più freschi con meno carico su OLTP, processamento incrementale più semplice e migliore auditabilità.
Contro: più componenti in movimento e gestione attenta dei cambi di schema.
Migliore per: volumi più grandi, necessità di freschezza elevata e team pronti a costruire pipeline dati.
Come portare i dati da OLTP a OLAP in sicurezza
Spostare i dati dal database transazionale (OLTP) in un sistema analitico (OLAP) non è solo “copiare tabelle” ma costruire una pipeline affidabile e a basso impatto. L'obiettivo è semplice: l'analytics ottiene ciò che serve senza mettere a rischio il traffico di produzione.
ETL vs ELT (versione in parole semplici)
ETL (Extract, Transform, Load) significa pulire e rimodellare i dati prima che arrivino nel warehouse. Utile quando il warehouse è costoso da calcolare o vuoi controllo stretto su cosa archiviare.
ELT (Extract, Load, Transform) carica dati più grezzi e poi li trasforma dentro il warehouse. Spesso è più veloce da impostare e più facile da evolvere: puoi mantenere la storia "source of truth" e aggiustare le trasformazioni quando cambiano i requisiti.
Regola pratica: se la logica di business cambia spesso, ELT riduce il rework; se la governance richiede solo dati curati, ETL può essere preferibile.
Basi del CDC: catturare il cambiamento senza query pesanti
Change Data Capture (CDC) trasmette insert/update/delete dall'OLTP (spesso dal log del database) nel tuo sistema di analytics. Invece di scansionare ripetutamente tabelle grandi, CDC ti permette di spostare solo ciò che è cambiato.
Cosa abilita:
- Reporting quasi in tempo reale senza leggere pesantemente la produzione
- Replay e backfill quando serve ricostruire tabelle analitiche
- Tracciamento della storia (chi ha cambiato cosa e quando), se conservi gli eventi di cambiamento
Freschezza dei dati: realtime vs near-real-time vs daily
La freschezza è una decisione di business con un costo tecnico.
- Realtime (secondi): ottimo per dashboard operative, ma difficile da mantenere stabile; piccoli problemi nella pipeline si vedono subito.
- Near-real-time (minuti): punto dolce comune—buona per decisioni rapide senza complessità estrema.
- Batch giornalieri: il più semplice ed economico, ideale per report finanziari dove “ieri” è sufficiente.
Definisci uno SLA chiaro (per esempio: “i dati sono al massimo 15 minuti indietro”) così gli stakeholder sanno cosa significa “fresco”.
Controlli di qualità dati che preven-gono errori silenziosi
Le pipeline si rompono spesso in modo silenzioso—finché qualcuno non nota numeri diversi. Aggiungi controlli leggeri per:
- Cambi di schema: colonne nuove, rinominate o cambi di tipo che possono annullare dati.
- Eventi in arrivo in ritardo: ordini o pagamenti che arrivano ore dopo; gestiscili con una “finestra di lookback”.
- Deduplicazione: retry e replay possono duplicare conteggi; usa ID stabili e caricamenti idempotenti.
Queste salvaguardie mantengono l'OLAP affidabile mentre proteggono l'OLTP.
Quando condividere un database può andare bene
Earn credits for your writeup
Publish about your build and earn Koder.ai credits to keep shipping.
Mantenere OLTP e OLAP insieme non è automaticamente "sbagliato". Può avere senso temporaneamente quando l'app è piccola, i bisogni di reporting sono limitati e puoi imporre confini rigidi così l'analytics non sorprende i clienti con checkout lenti, pagamenti falliti o timeout.
Situazioni in cui può funzionare
App piccole con analytics leggere e limiti di query severi spesso vanno bene su un singolo database—soprattutto all'inizio. La chiave è essere onesti su cosa significa “leggero”: poche dashboard, conteggi di righe modesti e un tetto chiaro su runtime e concorrenza delle query.
Per un insieme ristretto di report ricorrenti, materialized views o tabelle di riepilogo possono ridurre il costo dell'analisi. Invece di scandire le transazioni raw, pre-calcoli totali giornalieri, top categorie o rollup per cliente. Questo mantiene molte query brevi e prevedibili.
Se gli utenti di business accettano numeri ritardati, finestre di report off-peak aiutano. Programma i job più pesanti di notte o in orari a basso traffico e considera un ruolo di reporting dedicato con permessi e limiti di risorse più stretti.
Guardrail da aggiungere
- Imposta statement timeouts e cancella query runaway.
- Limita la concorrenza per gli utenti di reporting.
- Monitora p95/p99 per le transazioni core separatamente dai tempi di reporting.
Segnali chiari che è ora di separare
Se vedi latenza delle transazioni in aumento, incidenti ricorrenti durante i report, esaurimento del pool di connessioni o storie tipo “una query ha messo giù la produzione”, sei oltre la zona sicura. A quel punto separare i database (o almeno usare repliche) smette di essere un'ottimizzazione e diventa igiene operativa di base.
Checklist pratica per la migrazione: da condiviso a separato
Spostare l'analytics fuori dal database di produzione è più questione di rendere visibile il lavoro, fissare obiettivi e migrare a passi controllati che di una "riscrittura totale".
1) Inventario di cosa succede davvero oggi
Parti dalle evidenze, non dalle supposizioni. Estrai:
- Endpoint/query OLTP principali per frequenza e p95/p99 (checkout, login, crea ordine, ecc.)
- Report/dashboard OLAP principali per runtime, volume di scansione e importanza di business
Includi l'analytics "nascosta": SQL ad-hoc dagli strumenti BI, export schedulati e download CSV.
2) Definisci obiettivi: SLO OLTP e freschezza analytics
Scrivi gli obiettivi che ottimizzerai:
- SLO OLTP: p95/p99 di latenza, tasso di errori e throughput massimo da sostenere
- Freschezza analytics: quanto possono essere stale i dati (5 minuti, 1 ora, giorno dopo), più il tempo per ricostruire se la pipeline si rompe
Questo evita discussioni tipo “è lento” vs “va bene” e aiuta a scegliere l'architettura giusta.
3) Scegli un percorso di separazione
Scegli l'opzione più semplice che rispetti gli obiettivi:
- Replica di sola lettura: più veloce da adottare per reporting read-heavy, ma può ancora stressare la replica e avere lag
- Warehouse: migliore per scansioni grandi, molti join e storia lunga; solitamente la casa giusta per la BI
- Pipeline CDC (ETL/ELT): ideale per analytics near-real-time senza toccare la produzione
4) Rollout sicuro (prima in parallelo)
- Valida le definizioni (fusi orari, rimborsi, “utente attivo”, ecc.) così i numeri combaciano.
- Esegui vecchie e nuove dashboard in parallelo per un ciclo di business completo.
- Fai cut-over report per report, iniziando dalle query più dolorose.
- Blocca l'accesso diretto al "reporting su produzione" una volta che gli stakeholder si fidano della nuova fonte.
5) Aggiungi guardrail per non regredire
Monitora lag delle repliche/del pipeline, ritardi delle dashboard e spesa del warehouse. Imposta budget per le query (timeouts, limiti di concorrenza) e mantieni un playbook di incidenti: cosa fare quando la freschezza cala, i carichi esplodono o le metriche chiave divergono.
Nota pratica se stai costruendo l'app
Se sei nelle fasi iniziali e corri, il rischio maggiore è costruire involontariamente l'analytics nella stessa via di produzione (per esempio query di dashboard che diventano "cruciali per la produzione"). Un modo per evitarlo è progettare la separazione fin dall'inizio—even se parti con una replica modesta—e inserirla nella checklist architetturale.
Piattaforme come Koder.ai possono aiutare qui perché puoi prototipare il lato OLTP (React app + Go services + PostgreSQL) e progettare il confine reporting/warehouse in modalità planning prima di rilasciare. Man mano che il prodotto cresce, puoi esportare codice, evolvere lo schema e aggiungere componenti CDC/ELT senza trasformare il “reporting su produzione” in un'abitudine permanente.
Domande frequenti
What’s the simplest way to explain OLTP vs OLAP?
OLTP (Online Transaction Processing) gestisce le operazioni quotidiane come la creazione di ordini, l'aggiornamento dell'inventario e la registrazione dei pagamenti. Prioritizza bassa latenza, alta concorrenza e correttezza.
OLAP (Online Analytical Processing) risponde a domande di business tramite grandi scansioni e aggregazioni (dashboard, trend, analisi per coorti). Prioritizza throughput, query flessibili e sintesi rapida più che tempi di risposta in millisecondi.
Why does running analytics on the same database hurt transactional performance?
Perché i carichi competono per le stesse risorse:
- CPU e memoria: aggregazioni e join lunghi possono soffocare le query transazionali brevi.
- I/O su disco: le scansioni analitiche disturbano le piccole letture/scritture casuali e le scritture su log/index tipiche dell'OLTP.
- Cache churn: grandi scansioni possono espellere le pagine calde dell'OLTP, rallentando l'app.
- Pressione sul pool di connessioni: poche query BI lunghe possono occupare connessioni e causare code nell'app.
Il risultato sono spesso p95/p99 imprevedibili per le azioni core degli utenti.
Can’t we just add more indexes to make both OLTP and OLAP fast?
Di solito no. Aggiungere indici per velocizzare le dashboard spesso ricade male perché:
- Ogni indice extra aumenta il costo di scrittura (insert/update/delete deve aggiornare più strutture).
- Gli indici aumentano lo spazio di archiviazione e rallentano la manutenzione (vacuum/reindicizzazione/backup).
- Si finisce per ottimizzare per una singola reportistica e peggiorare altre query o le scritture OLTP.
Per l'analisi, si ottengono risultati migliori con in un sistema OLAP-oriented.
How do MVCC and long-running queries make shared databases slower over time?
MVCC aiuta a evitare blocchi tra lettori e scrittori, ma non rende i carichi misti "gratuiti". Problemi pratici includono:
- I report lunghi mantengono snapshot vecchi aperti, ritardando la pulizia delle vecchie versioni di riga.
- I ritardi nella pulizia causano bloat/fragmentazione, che rallenta le query e peggiora l'efficacia delle cache.
- Le operazioni di pulizia/compattazione in background possono rubare CPU e I/O all'OLTP.
Quindi, anche senza blocchi evidenti, l'analisi pesante degrada le prestazioni nel tempo.
What are the warning signs that it’s time to separate OLTP and OLAP?
Spesso si notano segnali come:
- Picchi nella latenza p95/p99 per endpoint di checkout/login/update
- Timeout o aumento dei retry durante i periodi di reportistica
- Esaurimento del pool di connessioni (richieste dell'app in attesa di connessioni libere)
- Incidenti che si correlano con report di fine mese/trimestre
Se il sistema sembra "lento a caso" durante l'aggiornamento delle dashboard, è un classico segno di carico misto.
When does a read replica make sense for reporting?
Un read replica è spesso il primo passo:
- Pro: cambi minimi nell'app, schema/SQL familiari, isola le scritture di produzione.
- Contro: i report pesanti possono comunque saturare CPU/I/O della replica; il lag di replica può confondere il confronto dei numeri; resta una tecnologia row-store tipica dell'OLTP.
È un buon ponte quando il volume è modesto e "minuti di ritardo" sono accettabili.
When should we use a dedicated data warehouse instead of a replica?
Un data warehouse è più adatto quando serve:
- Buone prestazioni su grandi scansioni, join e aggregazioni
- Molti analisti che eseguono query in parallelo
- Conservare una storia lunga senza penalizzare l'OLTP
- Separazione chiara di tuning e costi (OLTP per latenza, OLAP per throughput)
Di solito richiede un modello adatto all'analisi (spesso star/snowflake) e una pipeline per caricare i dati.
What is CDC, and why is it often better than running big ETL queries on production?
CDC (Change Data Capture) cattura insert/update/delete dal database OLTP (spesso dal log) e li manda nell'analytics.
Aiuta perché:
- Muovi solo le modifiche, invece di rieseguire scansioni complete.
- Ottieni freschezza quasi realtime con meno impatto su OLTP.
- Replay e backfill sono più semplici con uno stream di cambiamenti.
Il compromesso è avere più componenti e gestire con cura cambi di schema e ordering.
How do I choose between ETL and ELT for moving OLTP data into OLAP?
Scegli in base a quanto cambia la logica di business e a cosa vuoi archiviare:
- ELT: carichi dati quasi grezzi e trasformi nel warehouse. Più facile evolvere quando le definizioni cambiano.
- ETL: trasformi prima di caricare. Utile quando devi memorizzare solo dati curati o vuoi controllo rigoroso a monte.
Un approccio pratico è partire con ELT per velocità, poi aggiungere governance (test, modelli curati) quando le metriche critiche si stabilizzano.
Is it ever acceptable to keep OLTP and OLAP on the same database?
Sì—temporaneamente—se l'analytics resta davvero leggero e applichi guardrail:
- Timeout per le statement e cancellazione di query runaway
- Limiti di concorrenza per gli utenti di reporting (ruolo/pool separato)
- Pre-aggregazioni (materialized views/summary tables)
- Monitoraggio separato di p95/p99 per l'OLTP rispetto ai tempi delle reportistiche
Diventa inaccettabile quando la reportistica provoca regolarmente picchi di latenza, esaurimento dei pool o incidenti in produzione.