02 set 2025·8 min
Protobuf vs JSON per le API: velocità, dimensione e compatibilità
Confronta Protobuf e JSON per le API: dimensione del payload, velocità, leggibilità, tooling, versioning e quando ciascun formato è più adatto nei prodotti reali.
Confronta Protobuf e JSON per le API: dimensione del payload, velocità, leggibilità, tooling, versioning e quando ciascun formato è più adatto nei prodotti reali.
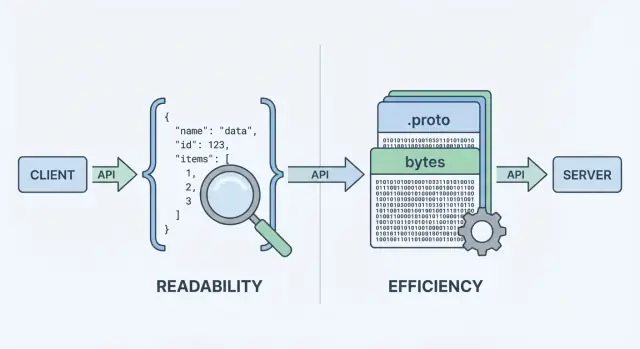
Quando la tua API invia o riceve dati, ha bisogno di un formato di dati—un modo standard per rappresentare le informazioni nel corpo di richieste e risposte. Quel formato viene poi serializzato (convertito in byte) per il trasporto sulla rete e deserializzato di nuovo in oggetti utilizzabili su client e server.
Due delle scelte più comuni sono JSON e Protocol Buffers (Protobuf). Possono rappresentare gli stessi dati di business (utenti, ordini, timestamp, liste di elementi), ma fanno scelte diverse in termini di prestazioni, dimensione del payload e flusso di lavoro per gli sviluppatori.
JSON (JavaScript Object Notation) è un formato basato su testo costruito da strutture semplici come oggetti e array. È popolare per le API REST perché è facile da leggere, facile da registrare e facile da ispezionare con strumenti come curl e DevTools del browser.
Un motivo chiave per cui JSON è ovunque: la maggior parte dei linguaggi lo supporta eccellentemente e puoi guardare una risposta e capirla immediatamente.
Protobuf è un formato di serializzazione binario creato da Google. Invece di inviare testo, invia una rappresentazione binaria compatta definita da uno schema (un file .proto). Lo schema descrive i campi, i loro tipi e i tag numerici.
Essendo binario e guidato da schema, Protobuf solitamente produce payload più piccoli e può essere più veloce da parsare—il che conta quando hai volumi elevati di richieste, reti mobili o servizi sensibili alla latenza (comune negli stack gRPC, ma non limitato a gRPC).
È importante separare cosa stai inviando da come viene codificato. Un “utente” con id, nome ed email può essere modellato sia in JSON che in Protobuf. La differenza è il costo che paghi in:
Non esiste una risposta valida per ogni caso. Per molte API pubbliche, JSON rimane la scelta predefinita perché è accessibile e flessibile. Per comunicazioni interne tra servizi, sistemi sensibili alle prestazioni o contratti rigorosi, Protobuf può essere più adatto. L'obiettivo di questa guida è aiutarti a scegliere in base ai vincoli—non all'ideologia.
Quando un'API restituisce dati, non può inviare “oggetti” direttamente sulla rete. Deve prima trasformarli in uno stream di byte. Quella conversione è la serializzazione—pensala come il confezionare i dati in una forma spedibile. Dall'altra parte, il client fa il contrario (deserializzazione), scartando i byte e ricostruendo le strutture dati.
Un flusso tipico request/response è così:
Quello step di “codifica” è dove la scelta del formato conta. La codifica JSON produce testo leggibile come {\\\"id\\\":123,\\\"name\\\":\\\"Ava\\\"}. La codifica Protobuf produce byte binari compatti che non hanno significato per un umano senza strumenti.
Perché ogni risposta deve essere impacchettata e scartata, il formato influenza:
Lo stile della tua API spesso guida la decisione:
curl e semplice da loggare e ispezionare.Puoi usare JSON con gRPC (via transcoding) o Protobuf su HTTP normale, ma l'ergonomia predefinita del tuo stack—framework, gateway, librerie client e abitudini di debugging—spesso decide cosa è più facile gestire quotidianamente.
Quando si confrontano protobuf vs json, si parte quasi sempre da due metriche: quanto è grande il payload e quanto tempo ci vuole per codificare/decodificare. Il succo è semplice: JSON è testo e tende a essere verboso; Protobuf è binario e tende a essere compatto.
JSON ripete i nomi dei campi e usa rappresentazioni testuali per numeri, booleani e strutture, quindi spesso invia più byte sulla rete. Protobuf sostituisce i nomi dei campi con tag numerici e impacchetta i valori in modo efficiente, il che porta comunemente a payload notevolmente più piccoli—soprattutto per oggetti grandi, campi ripetuti e dati profondamente annidati.
Detto questo, la compressione può ridurre il divario. Con gzip o brotli, le chiavi ripetute di JSON si comprimono molto bene, quindi le differenze tra JSON e Protobuf in termini di dimensione possono ridursi nelle distribuzioni reali. Anche Protobuf può essere compresso, ma il vantaggio relativo spesso è minore.
I parser JSON devono tokenizzare e validare il testo, convertire stringhe in numeri e gestire casi limite (escaping, spazi, unicode). La decodifica Protobuf è più diretta: leggi il tag → leggi il valore tipizzato. In molti servizi, Protobuf riduce il tempo CPU e la creazione di garbage, migliorando la latenza al tail sotto carico.
Su reti mobili o collegamenti ad alta latenza, meno byte normalmente significano trasferimenti più veloci e meno tempo di radio (che può anche aiutare la batteria). Ma se le tue risposte sono già piccole, l'overhead del handshake, TLS e l'elaborazione server possono dominare—rendendo la scelta del formato meno evidente.
Misura con i tuoi payload reali:
Questo trasforma i dibattiti sulla “serializzazione API” in dati affidabili per la tua API.
Qui JSON spesso vince per default. Puoi ispezionare una richiesta o risposta JSON quasi ovunque: in DevTools del browser, output di curl, Postman, reverse proxy e log in chiaro. Quando qualcosa si rompe, “cosa abbiamo effettivamente inviato?” è di solito a portata di copia/incolla.
Protobuf è diverso: è compatto e rigoroso, ma non leggibile dall'uomo. Se registri byte Protobuf grezzi vedrai blob base64 o binario non leggibile. Per capire il payload hai bisogno del giusto schema .proto e di un decoder (per esempio protoc, tooling specifico per linguaggio o i tipi generati dal tuo servizio).
Con JSON, riprodurre un problema è semplice: prendi un payload loggato, redigi i segreti, riproducilo con curl e sei vicino a un test minimale.
Con Protobuf, tipicamente debufferai:
Questo step in più è gestibile—ma solo se il team ha un flusso di lavoro ripetibile.
Il logging strutturato aiuta entrambi i formati. Registra ID di richiesta, nomi dei metodi, identificatori utente/account e campi chiave invece dei corpi interi.
Per Protobuf in particolare:
.proto usato?”.Per JSON, valuta di registrare JSON canonicalizzato (ordinamento stabile delle chiavi) per rendere più semplici le diff e le timeline degli incidenti.
Le API non spostano solo dati—spostano significato. La differenza più grande tra JSON e Protobuf è quanto chiaramente quel significato è definito e applicato.
JSON è di default “senza schema”: puoi inviare qualsiasi oggetto con qualsiasi campo, e molti client lo accetteranno purché sembri ragionevole.
Questa flessibilità è comoda all'inizio, ma può anche nascondere errori. Problemi comuni includono:
userId in una risposta, user_id in un'altra, o campi mancanti a seconda del percorso di codice.\\\"42\\\", \\\"true\\\" o \\\"2025-12-23\\\"—facili da produrre, facili da interpretare male.null potrebbe significare “sconosciuto”, “non impostato” o “intenzionalmente vuoto”, e client diversi potrebbero trattarlo in modo diverso.Puoi aggiungere JSON Schema o una specifica OpenAPI, ma JSON di per sé non obbliga i consumatori a seguirla.
Protobuf richiede uno schema definito in un file .proto. Uno schema è un contratto condiviso che dichiara:
Quel contratto aiuta a prevenire cambiamenti accidentali—come trasformare un intero in una stringa—perché il codice generato si aspetta tipi specifici.
Con Protobuf, i numeri restano numeri, le enum sono vincolate ai valori noti e i timestamp sono tipicamente modellati usando tipi well-known (invece di formati di stringhe ad-hoc). “Non impostato” è anche più chiaro: in proto3, l'assenza è distinta dai valori di default quando usi campi optional o tipi wrapper.
Se la tua API dipende da tipi precisi e parsing prevedibile tra team e linguaggi, Protobuf fornisce regole che JSON di solito ottiene solo tramite convenzioni.
Le API evolvono: aggiungi campi, modifichi comportamenti e ritiri parti vecchie. L'obiettivo è cambiare il contratto senza sorprendere i consumatori.
Una buona strategia di evoluzione punta a entrambi, ma la compatibilità backward è di solito il requisito minimo.
In Protobuf, ogni campo ha un numero (es. email = 3). Quel numero—non il nome del campo—è ciò che va sul wire. I nomi servono principalmente agli umani e al codice generato.
Per questo motivo:
Modifiche sicure (di solito)
Modifiche rischiose (spesso breaking)
Pratica consigliata: usa reserved per numeri/nomi vecchi e tieni un changelog.
JSON non ha uno schema integrato, quindi la compatibilità dipende dai tuoi pattern:
Documenta le deprecazioni presto: quando un campo è deprecato, per quanto tempo sarà supportato e cosa lo sostituisce. Pubblica una semplice policy di versioning (es. “i cambiamenti additivi sono non-breaking; le rimozioni richiedono una major version”) e rispettala.
Scegliere tra JSON e Protobuf spesso dipende da dove la tua API deve girare—e cosa il tuo team vuole mantenere.
JSON è praticamente universale: ogni browser e runtime backend può parsarlo senza dipendenze aggiuntive. In una web app, fetch() + JSON.parse() è il percorso naturale, e proxy, gateway API e strumenti di osservabilità tendono a “capire” JSON out-of-the-box.
Protobuf può funzionare anche nel browser, ma non è un default a costo zero. Di solito aggiungerai una libreria Protobuf (o codice JS/TS generato), gestirai la dimensione del bundle e deciderai se inviare Protobuf su endpoint HTTP che gli strumenti del browser possono ispezionare.
Su iOS/Android e nei linguaggi backend (Go, Java, Kotlin, C#, Python, ecc.), il supporto Protobuf è maturo. La grande differenza è che Protobuf presuppone che userai librerie per piattaforma e in genere genererai codice dai .proto.
La generazione di codice porta vantaggi reali:
Aggiunge anche costi:
.proto condivisi, pinning delle versioni)Protobuf è strettamente associato a gRPC, che ti dà una storia di tooling completa: definizioni di servizio, stub client, streaming e interceptor. Se stai valutando gRPC, Protobuf è la scelta naturale.
Se stai costruendo una API REST tradizionale in JSON, l'ecosistema tooling di JSON (DevTools del browser, debugging con curl, gateway generici) rimane più semplice—soprattutto per API pubbliche e integrazioni rapide.
Se stai ancora esplorando la superficie dell'API, può aiutare prototipare rapidamente entrambi gli stili prima di standardizzare. Per esempio, team che usano Koder.ai spesso mettono su una API REST JSON per massima compatibilità e un servizio interno gRPC/Protobuf per efficienza, poi benchmarkano i payload reali prima di decidere cosa diventi “di default”. Perché Koder.ai può generare app full-stack (React per il web, Go + PostgreSQL per il backend, Flutter per mobile) e supporta planning mode più snapshot/rollback, è pratico iterare sui contratti senza trasformare la decisione del formato in un refactor a lungo termine.
La scelta tra JSON e Protobuf non riguarda solo dimensione del payload o velocità. Influenza anche quanto bene la tua API si integra con livelli di caching, gateway e gli strumenti che il team usa durante gli incidenti.
La maggior parte dell'infrastruttura di caching HTTP (cache del browser, reverse proxy, CDN) è ottimizzata intorno alle semantiche HTTP, non a un particolare formato del body. Una CDN può cachare qualsiasi byte finché la risposta è cacheable.
Detto questo, molti team si aspettano JSON all'edge perché è facile da ispezionare e debug. Con Protobuf, il caching funziona comunque, ma dovrai essere deliberato su:
Vary)Cache-Control, ETag, Last-Modified)Content-Type e Accept)Se supporti sia JSON che Protobuf, usa la content negotiation:
Accept: application/json o Accept: application/x-protobufContent-Type corrispondenteAssicurati che le cache capiscano questo impostando Vary: Accept. Altrimenti, una cache potrebbe memorizzare una risposta JSON e servirla a un client Protobuf (o viceversa).
Gateway API, WAF, trasformatori request/response e strumenti di osservabilità spesso assumono body JSON per:
Il Protobuf binario può limitare queste feature a meno che il tuo tooling non sia Protobuf-aware (o aggiunga passaggi di decodifica).
Un pattern comune è JSON ai bordi, Protobuf dentro:
Questo mantiene semplici le integrazioni esterne e cattura i benefici di performance di Protobuf dove controlli sia client che server.
La scelta JSON o Protobuf cambia come i dati vengono codificati e parsati—ma non sostituisce requisiti di sicurezza fondamentali come autenticazione, crittografia, autorizzazione e validazione server-side. Un serializer veloce non salverà un'API che accetta input non fidati senza limiti.
Può essere allettante considerare Protobuf “più sicuro” perché binario e meno leggibile. Non è una strategia di sicurezza. Gli attaccanti non hanno bisogno che i payload siano leggibili dall'uomo—hanno bisogno del tuo endpoint. Se l'API espone campi sensibili, accetta stati non validi o ha autenticazione debole, cambiare formato non risolve il problema.
Cripta il trasporto (TLS), applica controlli di autorizzazione, valida gli input e registra in modo sicuro sia che tu usi JSON REST o grpc protobuf.
Entrambi i formati condividono rischi comuni:
Per mantenere le API dipendenti sotto carico e abuso, applica gli stessi guardrail a entrambi i formati:
In sintesi: “binario vs testo” incide su prestazioni ed ergonomia. Sicurezza e affidabilità derivano da limiti coerenti, dipendenze aggiornate e validazione esplicita—indipendentemente dal serializer scelto.
Scegliere tra JSON e Protobuf riguarda meno quale sia “migliore” e più cosa la tua API deve ottimizzare: amichevolezza per l'umano e diffusione, o efficienza e contratti rigidi.
JSON è di solito la scelta più sicura quando hai bisogno di ampia compatibilità e debugging semplice.
Scenari tipici:
Protobuf tende a vincere quando prestazioni e coerenza contano più della leggibilità.
Scenari tipici:
Usa queste domande per restringere rapidamente la scelta:
Se sei indeciso, l'approccio “JSON ai bordi, Protobuf dentro” è spesso un compromesso pragmatico.
Migrare formati riguarda meno riscrivere tutto e più ridurre il rischio per i consumatori. Le mosse più sicure mantengono l'API utilizzabile durante la transizione e rendono facile il rollback.
Scegli una superficie a basso rischio—spesso una chiamata interna servizio→servizio o un singolo endpoint read-only. Questo ti permette di validare lo schema Protobuf, i client generati e i cambiamenti di osservabilità senza trasformare l'intera API in un progetto “big bang”.
Un primo passo pratico è aggiungere una rappresentazione Protobuf per una risorsa esistente mantenendo invariata la shape JSON. Scoprirai rapidamente dove il tuo modello dati è ambiguo (null vs missing, numeri vs stringhe, formati di data) e potrai risolverlo nello schema.
Per le API esterne, il supporto dual è di solito il percorso più fluido:
Content-Type e Accept./v2/...) solo se la negoziazione è difficile col tuo tooling.Durante questo periodo, assicurati che entrambi i formati siano prodotti dalla stessa fonte di verità per evitare drift sottile.
Pianifica per:
Pubblica i file .proto, commenti sui campi ed esempi concreti di request/response (JSON e Protobuf) così i consumatori possono verificare di interpretare correttamente i dati. Una breve “guida di migrazione” e un changelog riducono il carico di supporto e accorciano i tempi di adozione.
Scegliere tra JSON e Protobuf spesso riguarda la realtà del tuo traffico, dei client e dei vincoli operativi. La strada più affidabile è misurare, documentare le decisioni e mantenere le tue modifiche API noiose.
Esegui un piccolo esperimento su endpoint rappresentativi.
Monitora:
Fallo in staging con dati simili alla produzione, poi valida in produzione su una fetta di traffico.
Sia che tu usi JSON Schema/OpenAPI o file .proto:
Anche se scegli Protobuf per le prestazioni, mantieni la documentazione amichevole:
Se mantieni documentazione o SDK, rendili facili da trovare (ad esempio: /docs e /blog). Se prezzi o limiti d'uso influenzano le scelte di formato, rendilo visibile (/pricing).
JSON è un formato basato su testo, facile da leggere, registrare e testare con strumenti comuni. Protobuf è un formato binario compatto definito da uno schema .proto, che spesso produce payload più piccoli e parsing più veloce.
Scegli in base ai vincoli: portata e facilità di debug (JSON) vs efficienza e contratti rigidi (Protobuf).
Le API inviano byte, non oggetti in memoria. La serializzazione codifica gli oggetti del server in un payload (testo JSON o binario Protobuf) per il trasporto; la deserializzazione decodifica quei byte nuovamente in oggetti client/server.
La scelta del formato influisce su larghezza di banda, latenza e CPU necessaria per codificare/decodificare.
Spesso sì, specialmente con oggetti grandi o annidati e campi ripetuti, perché Protobuf usa tag numerici e codifica binaria efficiente.
Tuttavia, se abiliti gzip/brotli, le chiavi ripetute di JSON si comprimono molto bene, quindi la differenza di dimensione nel mondo reale può ridursi. Misura sia le dimensioni raw che quelle compresse.
Può esserlo. Il parsing JSON richiede di tokenizzare il testo, gestire escaping/unicode e convertire stringhe in numeri. La decodifica Protobuf è più diretta (tag → valore tipizzato), il che spesso riduce tempo CPU e allocazioni.
Detto questo, se i payload sono piccolissimi, la latenza complessiva può essere dominata da TLS, RTT di rete e lavoro applicativo, non dalla serializzazione.
Di default è più complicato. JSON è leggibile dall'uomo e facile da ispezionare in DevTools, log, curl e Postman. I payload Protobuf sono binari, quindi normalmente hai bisogno dello schema .proto corrispondente e degli strumenti di decodifica.
Un miglioramento pratico è registrare una view di debug decodificata e redatta (di solito in JSON) insieme agli ID di richiesta e ai campi chiave.
JSON è flessibile e spesso “senza schema” a meno che non applichi JSON Schema/OpenAPI. Questa flessibilità può portare a campi incoerenti, valori “stringly-typed” e semantiche null ambigue.
Protobuf impone tipi tramite un contratto .proto, genera codice fortemente tipizzato e rende l'evoluzione del contratto più chiara—soprattutto quando coinvolge più team e linguaggi.
La compatibilità in Protobuf è guidata dai numeri dei campi (tag). Le modifiche sicure sono di solito additive (nuovi campi opzionali con numeri nuovi). I cambiamenti che rompono includono il riuso di numeri di campo o la modifica incompatibile dei tipi.
Per Protobuf, riserva i numeri/nomi rimossi (reserved) e tieni un changelog. Per JSON, preferisci campi additivi, mantieni i tipi stabili e considera i campi sconosciuti ignorabili.
Sì. Usa la content negotiation HTTP:
Accept: application/json o Accept: application/x-protobufContent-Type corrispondenteVary: Accept così le cache non mescolano i formatiSe la negoziazione è difficile con il tuo tooling, un endpoint/versione separata può essere una tattica di migrazione temporanea.
Dipende dall'ambiente:
Considera il costo di manutenzione della codegen e del versioning degli schemi quando scegli Protobuf.
Tratta entrambi come input non attendibili. La scelta del formato non è una misura di sicurezza.
Guardrail pratici per entrambi:
Mantieni parser/librerie aggiornati per ridurre l'esposizione a vulnerabilità dei parser.