Perché RabbitMQ è importante per i team applicativi
RabbitMQ è un message broker: si inserisce tra le parti del tuo sistema e muove in modo affidabile il “lavoro” (messaggi) dai producer ai consumer. I team applicativi lo adottano quando chiamate sincrone dirette (HTTP tra servizi, database condivisi, cron) iniziano a creare dipendenze fragili, carichi irregolari e catene di errore difficili da debug.
Problemi che RabbitMQ risolve
Picchi di traffico e carichi sbilanciati. Se la tua app riceve 10× più iscrizioni o ordini in una finestra breve, processare tutto immediatamente può sovraccaricare i servizi a valle. Con RabbitMQ, i producer accodano rapidamente i task e i consumer li elaborano a un ritmo controllato.
Accoppiamento stretto tra servizi. Quando il Servizio A deve chiamare il Servizio B e attendere, guasti e latenza si propagano. Il messaging li disaccoppia: A pubblica un messaggio e continua; B lo elabora quando disponibile.
Gestione degli errori più sicura. Non tutti i fallimenti devono diventare errori visibili all'utente. RabbitMQ ti aiuta a ritentare l'elaborazione in background, isolare i messaggi “velenosi” e evitare di perdere lavoro durante outage temporanei.
Risultati tipici osservati dai team
I team ottengono carichi più regolari (assorbendo i picchi), servizi disaccoppiati (meno dipendenze in runtime) e retry controllati (meno rielaborazioni manuali). Ugualmente importante, diventa più semplice capire dove il lavoro è bloccato—nel producer, in una coda o in un consumer.
Cosa copre questa guida (e cosa no)
Questa guida si concentra su RabbitMQ pratico per i team applicativi: concetti base, pattern comuni (pub/sub, work queue, retry e dead-letter queue) e aspetti operativi (sicurezza, scalabilità, osservabilità, troubleshooting).
Non è una specifica completa di AMQP né un deep dive su ogni plugin di RabbitMQ. L'obiettivo è aiutarti a progettare flussi di messaggi che restino manutenibili nei sistemi reali.
Glossario rapido
- Producer: componente dell'app che invia messaggi.
- Consumer: componente dell'app che riceve ed elabora messaggi.
- Queue: buffer che trattiene i messaggi finché un consumer non li elabora.
- Exchange: punto di ingresso che instrada i messaggi verso una o più code.
- Routing key: etichetta usata dagli exchange per decidere dove inviare un messaggio.
Nozioni di base su RabbitMQ: cos'è e quando usarlo
RabbitMQ è un message broker che instrada messaggi tra le parti del sistema, così i producer possono passare lavoro e i consumer possono elaborarlo quando sono pronti.
Messaging AMQP vs chiamate HTTP dirette
Con una chiamata HTTP diretta, il Servizio A manda una richiesta al Servizio B e normalmente attende una risposta. Se B è lento o down, A fallisce o resta bloccato, e devi gestire timeout, retry e backpressure in ogni chiamante.
Con RabbitMQ (comunemente tramite AMQP), A pubblica un messaggio al broker. RabbitMQ lo memorizza e instrada alle code giuste, e B lo consuma in modo asincrono. La differenza chiave è che comunichi attraverso uno strato intermedio durevole che fa da buffer sui picchi e smussa i carichi irregolari.
Quando il messaging è adatto (e quando non lo è)
Il messaging è adatto quando:
- Vuoi disaccoppiare team/servizi in modo che possano deployare e scalare indipendentemente.
- Ti serve lavoro asincrono (inviare email, generare PDF, controlli antifrode) senza bloccare la richiesta utente.
- Ti aspetti traffico a raffiche e vuoi assorbire i picchi con le code.
- Hai bisogno di consegna affidabile con ack, retry e dead-letter queue.
Il messaging non è adatto quando:
- Hai veramente bisogno di una risposta immediata per servire la richiesta (es. “questa password è valida?”).
- Stai facendo semplici letture sincrone dove una chiamata diretta è più chiara e più facile da debuggare.
- Non hai un piano per versioning dei messaggi, retry e monitoraggio (sposti semplicemente la complessità invece di ridurla).
Request/response vs workflow asincrono (esempio semplice)
Sincrono (HTTP):
Un servizio di checkout chiama un servizio di fatturazione via HTTP: “Crea fattura.” L'utente aspetta mentre la fatturazione viene eseguita. Se la fatturazione è lenta, la latenza del checkout aumenta; se è down, il checkout fallisce.
Asincrono (RabbitMQ):
Il checkout pubblica invoice.requested con l'id dell'ordine. L'utente riceve una conferma immediata che l'ordine è stato ricevuto. La fatturazione consuma il messaggio, genera la fattura e poi pubblica invoice.created per email/notifiche. Ogni passo può ritentare indipendentemente e gli outage temporanei non rompono automaticamente l'intero flusso.
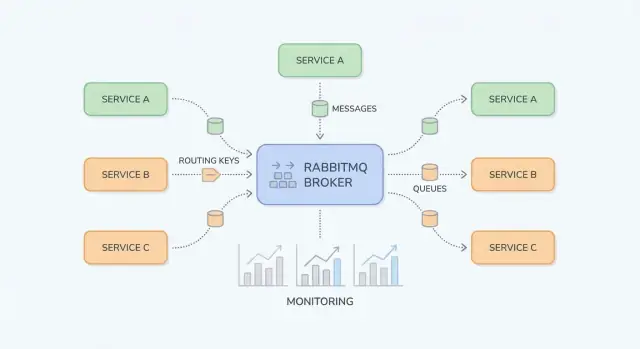
Elementi fondamentali: Exchange, Queue e Routing
RabbitMQ si capisce più facilmente separando “dove si pubblicano i messaggi” da “dove si memorizzano”. I producer pubblicano su exchange; gli exchange instradano verso code; i consumer leggono dalle code.
Exchange: come RabbitMQ decide dove inviare un messaggio
Un exchange non memorizza messaggi. Valuta delle regole e inoltra i messaggi a una o più code.
- Direct exchange: instrada per corrispondenza esatta sulla routing key. Usalo quando vuoi destinazioni chiare e esplicite (es.
billing o email).
- Topic exchange: instrada usando pattern nelle routing key. Utile per pub/sub flessibile e comportamento “iscriviti a una categoria”.
- Fanout exchange: broadcasta a ogni coda bound, ignorando le routing key. Usalo quando ogni consumatore dovrebbe ricevere ogni evento (es. invalidazione cache).
- Headers exchange: instrada basandosi sugli header del messaggio invece che su routing key. Utile quando il routing dipende da più attributi (es.
region=eu E tier=premium), ma mantienilo per casi speciali perché è più difficile da ragionare.
Code e binding: come i messaggi finiscono nel posto giusto
Una queue è dove i messaggi restano fino a quando un consumer li elabora. Una coda può avere un consumer o molti (competing consumers), e i messaggi sono tipicamente consegnati a un consumer alla volta.
Un binding collega un exchange a una coda e definisce la regola di routing. Pensalo come: “Quando un messaggio arriva all'exchange X con routing key Y, consegnalo alla coda Q.” Puoi bindare più code allo stesso exchange (pub/sub) o bindare una singola coda più volte per diverse routing key.
Routing key e pattern (topic exchange)
Per i direct exchange il routing è esatto. Per i topic exchange le routing key sono parole separate da punti, come:
orders.createdorders.eu.refunded
I binding possono includere wildcard:
* corrisponde esattamente a una parola (es. orders.* corrisponde a orders.created)# corrisponde a zero o più parole (es. orders.# corrisponde a orders.created e orders.eu.refunded)
Questo ti permette di aggiungere nuovi consumer senza cambiare i producer: crea una nuova coda e bindala con il pattern necessario.
Acknowledgement dei messaggi: ack, nack, requeue
Dopo che RabbitMQ consegna un messaggio, il consumer segnala l'esito:
- ack: “Elaborato correttamente.” RabbitMQ rimuove il messaggio dalla coda.
- nack (o reject): “Fallito.” Puoi scegliere di dropparlo o requeue.
- requeue: rimette il messaggio in coda per essere riprovato (spesso immediatamente).
Fai attenzione al requeue: un messaggio che fallisce sempre può loopare all'infinito e bloccare la coda. Molti team collegano i nack a una strategia di retry e a una dead-letter queue (coperta più avanti) così i fallimenti sono gestiti in modo prevedibile.
Casi d'uso comuni nelle applicazioni reali
RabbitMQ è ideale quando devi spostare lavoro o notifiche tra parti del sistema senza imporre che tutto aspetti un singolo passo lento. Ecco pattern pratici che si vedono spesso nei prodotti.
Publish/subscribe per notifiche (fanout/topic)
Quando più consumer devono reagire allo stesso evento—senza che il publisher sappia chi siano—pub/sub è una scelta naturale.
Esempio: quando un utente aggiorna il profilo, potresti notificare indicizzazione search, analytics e sync verso CRM in parallelo. Con un fanout exchange broadcasti a tutte le code bound; con un topic exchange instradi selettivamente (es. user.updated, user.deleted). Questo evita accoppiamenti stretti e permette ai team di aggiungere nuovi subscriber senza cambiare il producer.
Work queue per job in background
Se un task richiede tempo, mettilo in coda e lascia che i worker lo processino asincronamente:
- elaborazione immagini/video
- invio di email transazionali
- generazione di PDF o report
- import/export di dati
Questo mantiene le richieste web veloci e ti permette di scalare i worker indipendentemente. È anche un modo naturale per controllare la concorrenza: la coda diventa la tua “to-do list” e il numero di worker la “manopola del throughput”.
Integrazione event-driven tra servizi
Molti workflow attraversano confini di servizio: order → billing → shipping è l'esempio classico. Invece che un servizio chiami il successivo e resti bloccato, ogni servizio può pubblicare un evento quando finisce il proprio passo. I servizi a valle consumano eventi e proseguono il workflow.
Questo migliora la resilienza (un outage temporaneo di shipping non rompe il checkout) e rende l'ownership più chiara: ogni servizio reagisce agli eventi che gli interessano.
Collegare dipendenze lente o inaffidabili
RabbitMQ è anche un buffer tra la tua app e dipendenze lente o inaffidabili (API di terze parti, sistemi legacy, database a batch). Metti in coda le richieste rapidamente, poi processale con retry controllati. Se la dipendenza è giù, il lavoro si accumula in sicurezza e defluisce dopo—anziché causare timeout su tutta l'applicazione.
Se stai introdurre code gradualmente, un piccolo “async outbox” o una singola coda di background è spesso un buon primo passo (vedi /blog/next-steps-rollout-plan).
Progettare flussi di messaggi manutenibili
Un setup RabbitMQ resta piacevole da usare quando le rotte sono prevedibili, i nomi coerenti e i payload evolvono senza rompere i consumer più vecchi. Prima di aggiungere un'altra coda, assicurati che la “storia” di un messaggio sia ovvia: dove nasce, come viene instradato e come un collega può debuggarlo end-to-end.
Scegli il tipo di exchange che corrisponde alle tue esigenze di routing
Scegliere l'exchange giusto riduce binding one-off e fan-out inattesi:
- Direct exchange: migliore quando una routing key mappa a una coda specifica (es.
billing.invoice.created).
- Topic exchange: migliore per pub/sub flessibile con pattern (es.
billing.*.created, *.invoice.*). È la scelta più comune per routing di eventi manutenibile.
- Fanout exchange: migliore quando ogni consumatore deve ricevere ogni messaggio (raro per eventi business; più comune per segnali broadcast).
Una buona regola: se inventi logica di routing complessa nel codice, potrebbe appartenere a un topic exchange invece.
Basi dello schema del messaggio: versioning e compatibilità
Tratta i body dei messaggi come API pubbliche. Usa versioning esplicito (per esempio un campo top-level come schema_version: 2) e punta alla retrocompatibilità:
- Aggiungi campi; non rinominare/rimuovere.
- Preferisci campi opzionali con valori di default sicuri.
- Se un cambiamento incompatibile è inevitabile, pubblica un nuovo tipo di messaggio/routing key invece di cambiare silenziosamente il vecchio.
Questo mantiene i consumer vecchi funzionanti mentre quelli nuovi adottano la nuova schema quando sono pronti.
Correlation ID e trace ID per il debug cross-service
Rendi il troubleshooting economico standardizzando i metadata:
correlation_id: collega comandi/eventi appartenenti alla stessa azione di business.trace_id (o W3C traceparent): collega i messaggi al tracing distribuito attraverso flussi HTTP e async.
Quando ogni publisher imposta questi campi in modo consistente, puoi seguire una singola transazione attraverso più servizi senza indovinare.
Convenzioni di naming che scalano col sistema
Usa nomi prevedibili e ricercabili. Un pattern comune:
- Exchanges:
<domain>.<type> (es. billing.events)
- Routing key:
<domain>.<entity>.<verb> (es. billing.invoice.created)
- Code:
<service>.<purpose> (es. reporting.invoice_created.worker)
La coerenza batte l'ingegnosità: il tuo futuro sé (e la rotazione on-call) ti ringrazieranno.
Pattern di affidabilità: Retry, DLQ e Idempotenza
Standardizza retry e DLQ
Crea una configurazione pronta da modificare per retry e dead-letter con convenzioni di naming coerenti.
La messaggistica affidabile è soprattutto pianificare i fallimenti: i consumer crashano, le API a valle fanno timeout e alcuni eventi sono malformati. RabbitMQ fornisce gli strumenti, ma il tuo codice applicativo deve collaborare.
Consegna almeno una volta (e cosa significa per il tuo codice)
Una configurazione comune è la at-least-once delivery: un messaggio può essere consegnato più volte, ma non dovrebbe perdersi silenziosamente. Succede tipicamente quando un consumer riceve un messaggio, inizia il lavoro e poi fallisce prima di ackare—RabbitMQ lo rimetterà in coda e lo ridistribuirà.
Conclusione pratica: i duplicati sono normali, quindi il tuo handler deve poter essere eseguito più volte senza effetti indesiderati.
Strategie di idempotenza per i consumer
Idempotenza significa “elaborare lo stesso messaggio due volte ha lo stesso effetto di una sola volta”. Approcci utili:
- Chiavi di deduplica: includi un
message_id stabile (o una chiave di business come order_id + event_type + version) e salvalo in una tabella/cache dei processati con TTL.
- Aggiornamenti sicuri: usa scritture condizionali (es. aggiorna solo se lo stato è ancora
PENDING) o vincoli di unicità nel DB per evitare double-create.
- Pattern outbox/inbox: persisti prima la ricezione dell'evento e poi elabora, così i retry non ripetono effetti collaterali.
Retry con TTL + DLX/DLQ
I retry sono meglio trattati come un flusso separato, non un loop stretto nel consumer.
Un pattern comune:
- Su failure transitoria, reject e instrada verso una retry queue con una TTL per coda (o per messaggio).
- Quando la TTL scade, il messaggio viene dead-lettered indietro nella coda originale tramite un dead-letter exchange (DLX).
- Tieni traccia del numero di tentativi via header (o codificandolo nella routing key) e fermati dopo N tentativi.
Questo crea backoff senza tenere i messaggi “stuck” come non acked.
Messaggi velenosi: quarantena e replay
Alcuni messaggi non riusciranno mai (schema errato, dati referenziati assenti, bug). Rilevali con:
- raggiungimento del massimo di retry
- fallimenti ripetuti con la stessa firma di errore
Instrada questi messaggi in una DLQ per quarantena. Tratta la DLQ come una inbox operativa: ispeziona i payload, risolvi il problema sottostante e poi replaya manualmente i messaggi selezionati (meglio tramite uno strumento/script controllato) invece di rimettere tutto indiscriminatamente nella coda principale.
La performance di RabbitMQ è solitamente limitata da pochi fattori pratici: come gestisci le connessioni, quanto velocemente i consumer possono processare il lavoro e se le code sono usate come “storage”. L'obiettivo è throughput costante senza backlog crescente.
Connessioni vs canali (riuso e limiti)
Un errore comune è aprire una nuova connessione TCP per ogni publisher o consumer. Le connessioni sono più pesanti di quanto sembri (handshake, heartbeat, TLS), quindi mantienile a lungo e riusale.
Usa canali per multiplexare lavoro su un numero minore di connessioni. Regola empirica: poche connessioni, molti canali. Tuttavia non creare migliaia di canali alla leggera—ogni canale ha overhead e la libreria client può avere limiti. Preferisci un piccolo pool di canali per servizio e riusa i canali per il publish.
Prefetch e concorrenza (throughput senza sovraccarico)
Se i consumer prendono troppi messaggi contemporaneamente, vedrai picchi di memoria, tempi di elaborazione lunghi e latenza irregolare. Imposta un prefetch (QoS) così ogni consumer mantiene un numero controllato di messaggi non ackati.
Linee guida pratiche:
- Per job lenti (chiamate API, elaborazione file), inizia con prefetch 1–10 per consumer.
- Per handler veloci e leggeri in CPU, aumenta il prefetch gradualmente monitorando ack rate e risorse host.
- Scala aggiungendo più istanze consumer (o thread) prima di alzare drasticamente il prefetch.
Dimensione del messaggio: mantieni i payload leggeri
I messaggi grandi riducono il throughput e aumentano la pressione sulla memoria (publisher, broker e consumer). Se il payload è grosso (documenti, immagini, JSON voluminosi), valuta di metterlo altrove (object storage o DB) e inviare solo un ID + metadata tramite RabbitMQ.
Una buona euristica: mantieni i messaggi nell'ordine dei KB, non dei MB.
Backpressure: prevenire la crescita infinita delle code
La crescita delle code è un sintomo, non una strategia. Aggiungi backpressure così i producer rallentano quando i consumer non tengono il passo:
- Limita il lavoro dei consumer: cap della concorrenza e prefetch per mantenere prevedibile il lavoro in-flight.
- Rileva e reagisci alla crescita: alert su profondità delle code e rapporto publish vs ack.
- Shedding del carico: per eventi non critici, droppa o campiona i messaggi prima della pubblicazione durante i picchi.
In caso di dubbi, cambia una sola impostazione alla volta e misura: publish rate, ack rate, lunghezza della coda e latenza end-to-end.
Checklist di sicurezza per distribuzioni RabbitMQ
Trasforma i pattern in codice velocemente
Prototipa exchange, code e routing key in chat, poi esporta il codice sorgente.
La sicurezza per RabbitMQ riguarda soprattutto l'indurimento dei “confini”: come i client si connettono, chi può fare cosa e come tieni le credenziali lontane da posti sbagliati. Usa questa checklist come baseline e adattala ai tuoi requisiti di compliance.
Crittografa le connessioni con TLS
- Abilita TLS per tutte le connessioni client (AMQP over TLS su 5671, o la porta che scegli) e preferisci versioni e cipher moderni.
- Usa certificati che corrispondano al nome host del broker a cui i client si collegano.
- Pianifica la rotazione dei certificati: monitora le scadenze, automatizza i rinnovi quando possibile e prova le procedure di reload così la rotazione non diventi un outage.
- Se puoi, valida i client con mTLS per servizi interni che gestiscono dati sensibili.
Autenticazione e autorizzazione
I permessi di RabbitMQ diventano potenti se li usi in modo coerente.
- Crea utenti separati per ogni applicazione (evita account condivisi “app”).
- Usa vhost per partizionare tenant o sistemi (es. un vhost per prodotto/team).
- Applica permessi a minor privilegio per vhost:
- Configure (creare/modificare risorse)
- Write (publish)
- Read (consume)
Separare dev/staging/prod in modo sicuro
- Esegui cluster separati per ambiente quando possibile. Se devi condividere infrastruttura, isola con vhost e credenziali separate.
- Non permettere a un'app dev di puntare a un broker prod “solo per test”. Rendi questo impossibile via policy di rete e naming DNS.
Gestire i segreti correttamente nelle applicazioni
- Non hardcodare credenziali nel codice, config committati o immagini container.
- Inietta segreti a runtime tramite la tua piattaforma (Kubernetes secrets, un secrets manager, o variabili CI criptate).
- Ruota regolarmente le credenziali e rimuovi utenti inutilizzati.
Per l'hardening operativo (porte, firewall e auditing), mantieni un runbook interno breve e collegalo dalla documentazione centrale così i team seguono uno standard.
Monitoraggio e osservabilità: cosa misurare
Quando RabbitMQ si comporta male, i sintomi appaiono prima nelle applicazioni: endpoint lenti, timeout, aggiornamenti mancanti o job che “non finiscono mai”. Una buona osservabilità ti permette di confermare se il broker è la causa, individuare il collo di bottiglia (publisher, broker o consumer) e agire prima che gli utenti notino.
Metriche chiave del broker da tracciare
Inizia con un set piccolo di segnali che ti dicono se i messaggi fluiscono.
- Profondità della coda (messages ready + unacked): profondità in crescita indica che i consumer non tengono il passo o sono bloccati.
- Publish rate e ack rate: publish in crescita mentre gli ack restano fermi = backlog. Ack in calo improvviso = failure o timeout dei consumer.
- Utilizzo dei consumer: i consumer sono inattivi, saturi o si riavviano frequentemente? Abbina questo a prefetch e concorrenza.
- Redeliveries / requeues: forte indicatore di errori di processamento, politica di retry errata o messaggi velenosi.
Segnali di alert che catturano incidenti presto
Allerta sulle tendenze, non solo su soglie fisse.
- Backlog in crescita per N minuti: profondità in aumento costante è più azionabile di “depth > X”.
- Requeues/redeliveries ripetuti: indica un loop di fallimento che consuma CPU e blocca la coda.
- Churn di connessioni e canali: disconnect frequenti possono indicare crash dell'app, problemi di rete o heartbeat mal configurati.
- Unacked alti e bloccati per lunghi periodi: suggerisce consumer appesi o elaborazioni troppo lunghe.
Log e tracciamento dei messaggi durante gli incidenti
I log del broker ti aiutano a separare “RabbitMQ è giù” da “i client lo stanno usando male.” Cerca fallimenti di autenticazione, connessioni bloccate (resource alarms) e errori frequenti di canale. Lato applicazione, assicurati che ogni tentativo di processamento logghi un correlation ID, il nome della coda e l'esito (acked, rejected, retried).
Se usi tracing distribuito, propaga gli header di trace attraverso le proprietà del messaggio così puoi collegare “richiesta API → messaggio pubblicato → lavoro del consumer”.
Cruscotti e runbook interni
Costruisci un dashboard per ogni flusso critico: publish rate, ack rate, depth, unacked, requeues e numero di consumer. Aggiungi link diretti nel cruscotto al runbook interno e una checklist “cosa controllare prima” per chi è on-call.
Risolvere problemi comuni di RabbitMQ
Quando qualcosa “si blocca” in RabbitMQ, resisti alla tentazione di riavviare subito. La maggior parte dei problemi diventa ovvia una volta che controlli (1) binding e routing, (2) stato dei consumer e (3) resource alarm.
Messaggi non consumati
Se i publisher dicono “inviato con successo” ma le code restano vuote (o si riempie la coda sbagliata), controlla il routing prima del codice.
Inizia dall'interfaccia di Management:
- Verifica il tipo di exchange e che la coda abbia il binding previsto.
- Conferma che la routing key usata dal producer corrisponda al pattern di binding (specialmente con exchange
topic).
- Assicurati di pubblicare nel vhost corretto.
Se la coda ha messaggi ma nessuno li consuma, controlla:
- Un consumer è connesso e iscritto alla coda giusta?
- Il consumer non è bloccato a causa di prefetch troppo basso/alto o bloccato su lavoro lento a valle?
- Gli ack stanno arrivando (unacked in crescita di solito significa che il consumer non sta ackando o è sovraccarico)?
Duplicati e messaggi fuori ordine
I duplicati vengono di solito da retry (crash del consumer dopo il lavoro ma prima dell'ack), interruzioni di rete o requeue manuali. Mitiga rendendo gli handler idempotenti (es. dedup per message ID in DB).
La consegna fuori ordine è prevista con più consumer o requeue. Se l'ordine è importante, usa un solo consumer per quella coda o partiziona per chiave in più code.
Allarmi di memoria/disco
Gli allarmi indicano che RabbitMQ si sta proteggendo.
- Disk alarm: libera spazio su disco, sposta log o espandi il volume; poi conferma che l'allarme si è risolto.
- Memory alarm: riduci i messaggi in-flight (lower prefetch, limitare publisher), e controlla messaggi sovradimensionati.
Replay sicuro da una DLQ
Prima di riprodurre, risolvi la causa sottostante per evitare loop di messaggi velenosi. Requeuea in piccoli batch, aggiungi un limite di retry e marca i fallimenti con metadata (conteggio tentativi, ultimo errore). Considera di inviare i messaggi riprodotti a una coda separata prima, così puoi fermarti rapidamente se lo stesso errore si ripresenta.
RabbitMQ vs alternative: scegliere lo strumento giusto
Crea il tuo primo servizio a coda
Genera uno scheletro producer/consumer RabbitMQ da un prompt, poi iteralo prima di scrivere codice.
Scegliere uno strumento di messaging riguarda più il pattern di traffico, la tolleranza ai guasti e il comfort operativo che il “migliore assoluto”.
Quando RabbitMQ è la scelta giusta
RabbitMQ eccelle quando ti serve consegna affidabile dei messaggi e routing flessibile tra componenti applicativi. È una buona scelta per workflow asincroni classici—comandi, job in background, notifiche fan-out e pattern request/response—specialmente quando vuoi:
- Acknowledgement per messaggio e backpressure (consumer lenti non perdono lavoro)
- Routing ricco (topic, headers, direct) senza doverlo implementare tu
- Scalata operativa semplice per molti team (aggiungi consumer, regola prefetch, gestisci code)
Se il tuo obiettivo è spostare lavoro più che mantenere un lungo log di eventi, RabbitMQ è spesso il default confortevole.
RabbitMQ vs sistemi di streaming tipo Kafka
Kafka e sistemi simili sono progettati per streaming ad alto throughput e log di eventi di lunga durata. Scegli un sistema tipo Kafka quando ti servono:
- Replayabilità (i consumer possono rielaborare la storia)
- Throughput molto alto con scaling per partizioni
- Un singolo “source of truth” event stream per analytics + servizi
Contro: i sistemi tipo Kafka possono avere overhead operativo maggiore e spingerti verso design orientati al throughput (batching, strategia di partizionamento). RabbitMQ tende a essere più semplice per throughput da basso a medio con bassa latenza end-to-end e routing complesso.
Quando può bastare una coda semplice
Se hai una sola app che produce job e una worker pool che consuma—e ti bastano semantiche più semplici—una coda basata su Redis (o un servizio task gestito) può essere sufficiente. I team solitamente lo superano quando servono garanzie di consegna più forti, dead-lettering, pattern di routing multipli o separazione più chiara tra producer e consumer.
Considerazioni per una possibile migrazione
Progetta i contratti dei messaggi come se potessi cambiare in futuro:
- Mantieni schema dei messaggi versionato e retrocompatibile.
- Evita feature specifiche del broker nel payload (metti routing in header/metadata, non nel body).
- Costruisci producer/consumer così possono funzionare in parallelo durante una migrazione.
Se poi ti servirà la replayabilità, puoi spesso bridgeare eventi da RabbitMQ verso un sistema log-based mantenendo RabbitMQ per i workflow operativi.
Prossimi passi: piano di rollout e checklist per il team
Introdurre RabbitMQ funziona meglio trattandolo come un prodotto: parti piccoli, definisci responsabilità e prova l'affidabilità prima di estenderlo ad altri servizi.
Checklist di partenza (adozione da un singolo servizio)
Scegli un workflow che beneficia dell'elaborazione asincrona (es. invio email, generazione report, sync con API terza parte).
- Definisci il contratto del messaggio: campi richiesti, versione e cosa significa “successo”.
- Crea un exchange + una queue con convenzioni di naming chiare.
- Imposta limiti di concorrenza del consumer e prefetch per non sovraccaricare i sistemi a valle.
- Aggiungi comportamento di retry (con backoff) e una dead-letter queue (DLQ) fin dal primo giorno.
- Rendi gli handler idempotenti (sicuri da elaborare più volte).
- Documenta i passi operativi “ferma l'emorragia” (pausa consumer, svuota la coda, replay DLQ).
Se ti serve un template di riferimento per naming, tier di retry e policy di base, centralizzalo nella documentazione (/docs).
Mentre applichi questi pattern, valuta di standardizzare lo scaffold tra i team. Ad esempio, team che usano Koder.ai spesso generano un piccolo producer/consumer skeleton da un prompt in chat (includendo naming convention, wiring retry/DLQ e header di trace/correlation), poi esportano il codice sorgente per revisione e iterano in “planning mode” prima del rollout.
Ownership operativa (rendila esplicita)
RabbitMQ funziona quando “qualcuno possiede la coda”. Decidi questo prima della produzione:
- Chi monitora: di solito il team platform/SRE monitora la salute del broker; i team di servizio si occupano delle loro code e del comportamento dei consumer.
- Chi gestisce la DLQ: il team del servizio on-call (con chiari percorsi di escalation).
- Runbook: un runbook a livello broker e uno per servizio per ogni coda critica.
Se formalizzi il supporto o l'hosting gestito, allinea le aspettative presto (vedi /pricing) e stabilisci una via di contatto per incidenti o onboarding (vedi /contact).
Esperimenti successivi (convalidare prima di scalare)
Esegui piccoli esercizi a tempo per costruire fiducia:
- Load test: valida throughput, concorrenza dei consumer e latenza sotto condizioni di picco.
- Failure drill: kill dei consumer, riavvio del broker, simulazione di latenza di rete, verifica retry e comportamento DLQ.
- Versioning schema: introduci un messaggio v2 mentre i consumer v1 sono ancora attivi; conferma compatibilità e i passaggi di rollout.
Quando un servizio è stabile per qualche settimana, replica gli stessi pattern—non reinventarli per ogni team.