10 ott 2025·8 min
Redis per le tue applicazioni: pattern, insidie e consigli
Scopri come usare Redis nelle tue app: caching, sessioni, code, pub/sub e rate limiting—più scalabilità, persistenza, monitoraggio e le insidie da evitare.
Scopri come usare Redis nelle tue app: caching, sessioni, code, pub/sub e rate limiting—più scalabilità, persistenza, monitoraggio e le insidie da evitare.
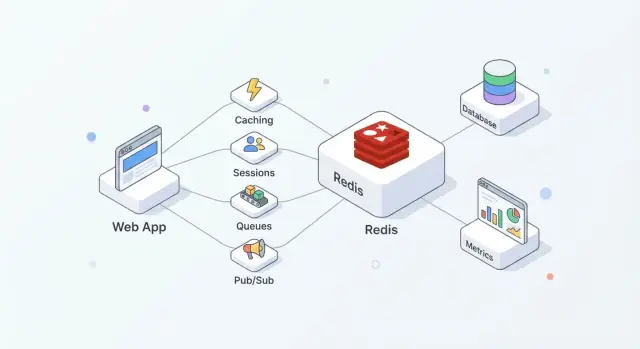
Redis è un archivio in-memory spesso usato come "layer veloce" condiviso per le applicazioni. I team lo apprezzano perché è semplice da adottare, estremamente rapido per le operazioni comuni e abbastanza flessibile da svolgere più compiti (cache, sessioni, contatori, code, pub/sub) senza introdurre un sistema nuovo per ciascuno.
In pratica, Redis funziona meglio se lo consideri come velocità + coordinamento, mentre il tuo database principale rimane la fonte di verità.
Una configurazione comune appare così:
Questa separazione mantiene il database concentrato su correttezza e durabilità, mentre Redis assorbe letture/scritture ad alta frequenza che altrimenti aumenterebbero latenza o carico.
Ben usato, Redis tende a produrre alcuni risultati pratici:
Redis non sostituisce un database primario. Se servono query complesse, conservazione a lungo termine, o reporting analitico, il database rimane il posto giusto.
Inoltre, non dare per scontato che Redis sia “durevole per impostazione predefinita.” Se perdere anche pochi secondi di dati è inaccettabile, dovrai configurare la persistenza con cura—o usare un sistema diverso—in base ai tuoi requisiti di recovery.
Spesso Redis viene descritto come un “key-value store”, ma è più utile pensarlo come un server molto veloce che può tenere e manipolare piccoli pezzi di dati identificati da nome (la chiave). Questo modello favorisce pattern di accesso prevedibili: di solito sai esattamente cosa vuoi (una sessione, una pagina cache, un contatore) e Redis può recuperarlo o aggiornarlo in un solo round trip.
Redis mantiene i dati in RAM, per questo può rispondere in microsecondi o millisecondi bassi. Il compromesso è che la RAM è limitata e più costosa del disco.
Decidi presto se Redis è:
Redis può persistere su disco (snapshot RDB e/o AOF append-only), ma la persistenza aggiunge overhead di scrittura e obliga a decisioni di durabilità (per esempio, “veloce ma può perdere un secondo” vs “più lento ma più sicuro”). Tratta la persistenza come una manopola da regolare in base all’impatto sul business, non come una casella da spuntare automaticamente.
Redis esegue comandi principalmente su un singolo thread, il che può sembrare limitante finché non consideri due cose: le operazioni sono tipicamente piccole e non c’è overhead di locking tra più thread worker. Finché eviti comandi costosi e payload sovradimensionati, questo modello può essere estremamente efficiente sotto alta concorrenza.
La tua app parla con Redis via TCP usando librerie client. Usa connection pooling, mantieni le richieste piccole e preferisci batching/pipelining quando servono più operazioni.
Pianifica timeout e retry: Redis è veloce, ma le reti no, e la tua applicazione dovrebbe degradare in modo elegante quando Redis è occupato o temporaneamente non disponibile.
Se stai costruendo un nuovo servizio e vuoi standardizzare queste basi rapidamente, una piattaforma come Koder.ai può aiutarti a scaffoldare un’app React + Go + PostgreSQL e poi aggiungere funzionalità basate su Redis (caching, sessioni, rate limiting) tramite un workflow guidato—permettendoti comunque di esportare il codice sorgente ed eseguirlo dove ti serve.
La cache aiuta solo quando ha una ownership chiara: chi la popola, chi la invalida e cosa significa "fresh enough".
Cache-aside significa che l’applicazione—not Redis—controlla letture e scritture.
Flusso tipico:
Redis è un key-value store veloce; la tua app decide come serializzare, versionare e scadere le voci.
Il TTL è tanto una decisione di prodotto quanto tecnica. TTL brevi riducono la stalezza ma aumentano il carico sul database; TTL lunghi risparmiano lavoro ma rischiano risultati obsoleti.
Consigli pratici:
user:v3:123) così le forme cache vecchie non rompono il nuovo codice.Quando una chiave calda scade, molte richieste possono mancare contemporaneamente.
Difese comuni:
Buoni candidati includono risposte API, risultati di query costose e oggetti calcolati (raccomandazioni, aggregazioni). Caching di pagine HTML complete può funzionare, ma attenzione alla personalizzazione e ai permessi—usa caching di frammenti quando la logica è specifica per utente.
Redis è un posto pratico per tenere stati di login a breve durata: ID di sessione, metadati dei refresh token e flag "ricorda questo dispositivo". L’obiettivo è rendere l’autenticazione veloce mantenendo sotto controllo la durata delle sessioni e la revoca.
Un pattern comune: la tua app emette un session ID random, memorizza un record compatto in Redis e restituisce l’ID al browser come cookie HTTP-only. Ad ogni richiesta cerchi la chiave di sessione e aggiungi identità e permessi al contesto della richiesta.
Redis funziona bene perché le letture di sessione sono frequenti e la scadenza della sessione è integrata.
Progetta chiavi facili da scandire e revocare:
sess:{sessionId} → payload della sessione (userId, issuedAt, deviceId)user:sessions:{userId} → Set di sessionId attivi (opzionale, per “logout ovunque”)Usa un TTL su sess:{sessionId} che corrisponda alla durata della sessione. Se ruoti le sessioni (raccomandato), crea un nuovo session ID e cancella immediatamente quello vecchio.
Fai attenzione alla “sliding expiration” (estendere il TTL ad ogni richiesta): può mantenere sessioni in vita indefinitamente per utenti molto attivi. Un compromesso più sicuro è estendere il TTL solo quando è vicino alla scadenza.
Per disconnettere un singolo dispositivo, elimina sess:{sessionId}.
Per disconnettere su tutti i dispositivi, o:
user:sessions:{userId}, oppureuser:revoked_after:{userId} e considera invalide le sessioni emesse prima di quel tempoIl metodo del timestamp evita grandi operazioni di fan-out.
Conserva il minimo indispensabile in Redis—preferisci ID invece di dati personali. Non memorizzare mai password in chiaro o segreti a lunga durata. Se devi memorizzare dati legati a token, conserva hash e usa TTL stretti.
Limita chi può connettersi a Redis, richiedi autenticazione e mantieni gli session ID ad alta entropia per prevenire attacchi di indovinamento.
Il rate limiting è uno degli usi in cui Redis eccelle: è veloce, condiviso tra istanze app e offre operazioni atomiche che mantengono i contatori consistenti sotto traffico intenso. Serve a proteggere endpoint di login, ricerche costose, flow di reset password e qualsiasi API che può essere scansionata o attaccata con brute force.
Fixed window è il più semplice: “100 richieste al minuto.” Conti le richieste nel bucket del minuto corrente. È facile, ma può permettere raffiche al confine (es., 100 a 12:00:59 e 100 a 12:01:00).
Sliding window smussa i confini guardando gli ultimi N secondi/minuti invece del bucket corrente. È più equo, ma tipicamente costa di più (potresti aver bisogno di sorted set o più bookkeeping).
Token bucket è ottimo per gestire burst. Gli utenti “guadagnano” token col tempo fino a un cap; ogni richiesta spende un token. Permette brevi picchi mantenendo un tasso medio imposto.
Un pattern fixed-window comune è:
INCR key per incrementare un contatoreEXPIRE key window_seconds per impostare/resetare il TTLLa sfida è farlo in sicurezza. Se esegui INCR e EXPIRE come chiamate separate, un crash tra le due può creare chiavi che non scadono mai.
Approcci più sicuri includono:
INCR e impostare EXPIRE solo quando il contatore viene creato.SET key 1 EX <ttl> NX per l’inizializzazione, poi INCR dopo (spesso comunque racchiuso in uno script per evitare race).Le operazioni atomiche contano soprattutto quando il traffico schizza: senza di esse, due richieste possono “vedere” la stessa quota residua e passare entrambe.
La maggior parte delle app ha bisogno di più livelli:
rl:user:{userId}:{route})Per endpoint con burst, il token bucket (o un fixed window generoso con una breve finestra di “burst”) evita di punire spike legittimi come caricamenti di pagina o riconnessioni mobili.
Decidi in anticipo cosa significa "sicuro":
Un compromesso comune è fail-open per route a basso rischio e fail-closed per quelle sensibili (login, reset password, OTP), con monitoraggio per rilevare quando il rate limiting smette di funzionare.
Redis può alimentare job in background quando serve una coda leggera per invio email, ridimensionamento immagini, sincronizzazione dati o task periodici. La chiave è scegliere la struttura dati giusta e definire regole chiare per retry e gestione degli errori.
Liste sono la coda più semplice: i producer fanno LPUSH, i worker BRPOP. Sono facili, ma serve logica aggiuntiva per job “in-flight”, retry e visibility timeout.
Sorted set brillano quando la schedulazione conta. Usa lo score come timestamp (o priorità) e i worker prendono il prossimo job dovuto. Adatto a job ritardati e code con priorità.
Streams sono spesso la scelta predefinita per una distribuzione di lavoro durevole. Supportano consumer group, mantengono una storia e permettono a più worker di coordinarsi senza inventarsi una propria lista di processing.
Con Streams consumer groups un worker legge un messaggio e poi lo ACKa. Se un worker va giù, il messaggio resta pending e può essere reclamato da un altro worker.
Per i retry, tieni conto dei tentativi (nel payload del messaggio o in una chiave laterale) e applica backoff esponenziale (spesso via un sorted set come “retry schedule”). Dopo un numero massimo di tentativi, sposta il job in una dead-letter queue (un altro stream o una lista) per revisione manuale.
Dai per scontato che i job possano eseguirsi due volte. Rendi gli handler idempotenti:
job:{id}:done) con SET ... NX prima degli effetti collateraliMantieni i payload piccoli (conserva i dati grandi altrove e passa riferimenti). Applica backpressure limitando la lunghezza della coda, rallentando i producer quando il lag cresce e scalando i worker in base alla profondità in sospeso e al tempo di elaborazione.
Redis Pub/Sub è il modo più semplice per broadcastare eventi: i publisher inviano un messaggio su un canale e ogni subscriber connesso lo riceve immediatamente. Non c’è polling—solo un push leggero che funziona bene per aggiornamenti in tempo reale.
Pub/Sub è ottimo quando ti interessa la velocità e il fan-out più che la consegna garantita:
Un modello mentale utile: Pub/Sub è come una stazione radio. Chi è sintonizzato sente la trasmissione, ma nessuno ottiene automaticamente una registrazione.
Pub/Sub ha trade-off importanti:
Per questi motivi, Pub/Sub è una scelta inadeguata per workflow in cui ogni evento deve essere elaborato (esattamente una volta—o anche almeno una volta).
Se ti servono durabilità, retry, consumer group o gestione del backpressure, Redis Streams sono quasi sempre la scelta migliore. Le Streams permettono di memorizzare eventi, processarli con ack e recuperare dopo riavvii—molto più vicino a una coda leggera durevole.
In deployment reali avrai più istanze app subscribe. Alcuni consigli pratici:
app:{env}:{domain}:{event} (es., shop:prod:orders:created).notifications:global, e target utenti con notifications:user:{id}.Usato così, Pub/Sub è un segnale evento veloce, mentre Streams (o un’altra coda) gestisce gli eventi che non puoi permetterti di perdere.
La scelta della struttura dati non riguarda solo “cosa funziona”—influenza l’uso di memoria, la velocità di query e la semplicità del codice nel tempo. Una buona regola è scegliere la struttura che risponde alle domande che farai in seguito (pattern di lettura), non solo come archivi oggi i dati.
INCR/DECR.SISMEMBER è veloce e le operazioni di set sono semplici.Le operazioni Redis sono atomiche a livello di comando, quindi puoi incrementare contatori senza condizioni di race. Page view e contatori di rate-limit tipicamente usano stringhe con INCR più expiry.
Le leaderboard sono il caso d’uso perfetto per sorted sets: puoi aggiornare punteggi (ZINCRBY) e ottenere i migliori (ZREVRANGE) efficientemente senza scansionare tutte le voci.
Se crei molte chiavi come user:123:name, user:123:email, user:123:plan, moltiplichi l’overhead per chiave e complichi la gestione.
Un hash come user:123 con campi (name, email, plan) mantiene i dati correlati insieme e di solito riduce il numero di chiavi. Rende anche gli aggiornamenti parziali più semplici (aggiorna un campo invece di riscrivere un JSON intero).
Quando hai dubbi, modella un piccolo campione e misura l’uso di memoria prima di impegnarti in una struttura per dati ad alto volume.
Redis è spesso descritto come “in-memory”, ma hai comunque scelte su cosa succede quando un nodo riavvia, il disco si riempie o un server sparisce. La configurazione giusta dipende da quanto puoi permetterti di perdere e da quanto rapidamente devi recuperare.
RDB snapshots salvano un dump puntuale del dataset. Sono compatti e veloci da caricare allo startup, rendendo i riavvii più rapidi. Il compromesso è che puoi perdere le scritture più recenti dall’ultimo snapshot.
AOF (append-only file) registra le operazioni di scrittura mano a mano che avvengono. Questo tipicamente riduce la perdita potenziale di dati perché i cambiamenti sono registrati più continuamente. Gli AOF possono crescere di dimensione e i replay all’avvio possono richiedere più tempo—anche se Redis può riscrivere/compattare l’AOF per mantenerlo gestibile.
Molti team eseguono entrambi: snapshot per riavvii più rapidi e AOF per migliore durabilità delle scritture.
La persistenza non è gratuita. Scritture su disco, politiche di fsync AOF e operazioni di rewrite in background possono aggiungere spike di latenza se lo storage è lento o satura. D’altra parte, la persistenza rende i riavvii meno spaventosi: senza persistenza, un riavvio involontario significa un Redis vuoto.
La replica mantiene una copia (o copie) dei dati sui replica in modo da poter fare failover quando il primario cade. L’obiettivo è di solito disponibilità prima di tutto, non coerenza perfetta. In caso di failure, i replica possono essere leggermente indietro, e un failover può perdere le ultime scritture in alcuni scenari.
Prima di sintonizzare nulla, scrivi due numeri:
Usa questi obiettivi per scegliere la frequenza RDB, le impostazioni AOF e se ti servono replica (e failover automatizzato) per il ruolo di Redis—cache, store di sessioni, coda o datastore primario.
Una singola istanza Redis può portarti sorprendentemente lontano: è semplice da gestire, facile da ragionare e spesso abbastanza veloce per molti workload di caching, sessioni o code.
Lo scaling diventa necessario quando raggiungi limiti duri—di solito il tetto di memoria, saturazione CPU o il fatto che una singola istanza diventi un single point of failure inaccettabile.
Considera più nodi quando una (o più) di queste condizioni è vera:
Un primo passo pratico è spesso separare i workload (due istanze Redis) prima di passare a un cluster.
Lo sharding significa dividere le chiavi su più nodi Redis in modo che ogni nodo memorizzi solo una porzione dei dati. Redis Cluster è il modo integrato di Redis per farlo automaticamente: lo spazio delle chiavi è diviso in slot e ogni nodo ne possiede alcuni.
Il vantaggio è maggiore memoria totale e throughput aggregato. Il compromesso è complessità: le operazioni multi-key diventano vincolate (le chiavi devono essere sullo stesso shard) e il troubleshooting coinvolge più componenti.
Anche con uno sharding “equo”, il traffico reale può essere sbilanciato. Una singola chiave popolare ("hot key") può sovraccaricare un nodo mentre gli altri restano inattivi.
Mitigazioni includono TTL brevi con jitter, spezzare il valore su più chiavi (key hashing) o ridisegnare i pattern di accesso in modo che le letture si distribuiscano.
Un Redis Cluster richiede un client consapevole del cluster che possa scoprire la topologia, instradare le richieste al nodo giusto e seguire redirezioni quando gli slot si spostano.
Prima della migrazione, conferma:
Lo scaling funziona meglio se è un’evoluzione pianificata: valida con test di carico, strumenta la latenza delle chiavi e migra il traffico gradualmente invece di abilitare tutto in una volta.
Redis è ideale come “layer veloce” condiviso in memoria per:
Usa il tuo database primario per dati autoritativi e duraturi e per query complesse. Tratta Redis come un acceleratore e un coordinatore, non come fonte di verità.
No. Redis può persistere i dati, ma non è “durevole per impostazione predefinita”. Se ti servono query complesse, garanzie forti di durabilità o funzionalità di analytics/reporting, conserva quei dati nel database primario.
Se anche perdere pochi secondi di dati è inaccettabile, non dare per scontato che le impostazioni di persistenza di Redis siano sufficienti senza una configurazione attenta (o valuta un sistema diverso per quel carico).
Decidi in base alla perdita di dati accettabile e al comportamento al riavvio:
Definisci prima RPO/RTO, poi regola la persistenza per soddisfarli.
Nel pattern cache-aside l’applicazione gestisce la logica:
Funziona bene quando l’app può tollerare miss occasionali e hai un piano chiaro per scadenza/invalidazione.
Scegli i TTL in base all’impatto sull’utente e al carico sul backend:
user:v3:123) quando la forma cache potrebbe cambiare.Se non sei sicuro, inizia con TTL più corti, misura il carico sul DB e aggiusta.
Usa una (o più) delle seguenti tecniche:
Questi pattern prevengono cadute sincronizzate della cache che sovraccaricherebbero il database.
Un approccio comune è:
sess:{sessionId} con un TTL che corrisponda alla durata della sessione.user:sessions:{userId} come set di sessioni attive per il logout globale.Evita di estendere il TTL ad ogni richiesta ("sliding expiration") a meno che non sia controllato (per esempio estendi solo quando la sessione è vicina alla scadenza).
Usa aggiornamenti atomici così i contatori non si bloccano o non vanno in race:
INCR e EXPIRE come due chiamate separate non protette.Scopa le chiavi con attenzione (per-utente, per-IP, per-route) e decidi in anticipo se essere fail-open o fail-closed quando Redis non è disponibile—soprattutto per endpoint sensibili come il login.
Scegli in base a durabilità e requisiti operativi:
LPUSH/BRPOP): semplici, ma richiedono logiche per retry, job in-flight e timeout.Usa Pub/Sub per broadcast real-time e veloci dove perdere messaggi è accettabile (presence, dashboard live). Ha:
Se ogni evento deve essere processato, preferisci Redis Streams per durabilità, consumer group, retry e gestione del backpressure. Per l’igiene operativa, proteggi Redis con ACL/network isolation e monitora latenza/evictions; tieni un runbook come .
Mantieni i payload dei job piccoli; conserva i grossi blob altrove e passa riferimenti.
/blog/monitoring-troubleshooting-redis