27 set 2025·8 min
Rilasci Blue/Green e Canary: una strategia chiara per le release
Scopri quando usare Blue/Green o Canary, come funziona lo spostamento del traffico, cosa monitorare e passaggi pratici di rollout e rollback per rilasci più sicuri.
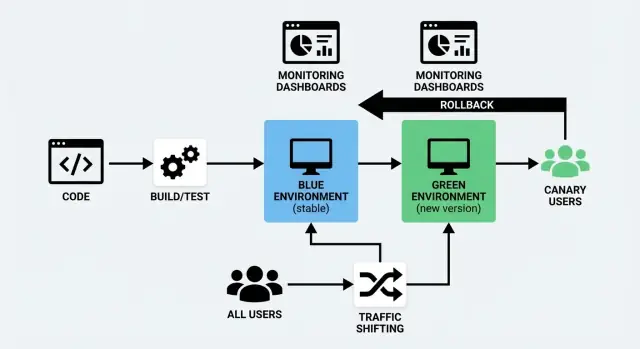
Cosa significano i rilasci Blue/Green e Canary
Rilasciare nuovo codice è rischioso per una ragione semplice: non sai davvero come si comporterà finché gli utenti reali non lo usano. Blue/Green e Canary sono due modi comuni per ridurre quel rischio mantenendo il downtime vicino allo zero.
Blue/Green in parole semplici
Un deployment blue/green usa due ambienti separati ma simili:
- Blue: la versione che attualmente serve gli utenti (l'ambiente “live”).
- Green: un secondo ambiente pronto dove distribuire la nuova versione.
Prepari l'ambiente Green in background—distribuisci la nuova build, esegui controlli, lo preriscaldi—e poi sposti il traffico da Blue a Green quando sei sicuro. Se qualcosa va storto, puoi tornare rapidamente indietro.
L'idea chiave non è “due colori”, ma un passaggio netto e reversibile.
Canary in parole semplici
Un rilascio canary è un rollout graduale. Invece di cambiare tutto in una volta, invii la nuova versione a una piccola porzione di utenti prima (per esempio, 1–5%). Se tutto sembra sano, estendi il rollout passo dopo passo fino al 100% del traffico.
L'idea chiave è imparare dal traffico reale prima di impegnarti completamente.
L'obiettivo comune: rilasci più sicuri con meno downtime
Entrambi gli approcci sono strategie di deployment che mirano a:
- ridurre l'impatto sugli utenti quando qualcosa si rompe
- supportare un rilascio senza downtime (o il più vicino possibile)
- rendere i rollback meno stressanti e più prevedibili
Lo fanno in modi diversi: Blue/Green punta a uno switch rapido tra ambienti, mentre Canary si basa sull'esposizione controllata tramite spostamento del traffico.
Non esiste un’opzione “migliore” in assoluto
Nessun approccio è automaticamente superiore. La scelta giusta dipende da come viene usato il prodotto, da quanto sei sicuro nei test, da quanto velocemente vuoi feedback e da che tipo di failure vuoi evitare.
Molte squadre li combinano—usando Blue/Green per semplicità infrastrutturale e tecniche Canary per l'esposizione graduale agli utenti.
Nelle sezioni successive li confronteremo direttamente e mostreremo quando ciascuno funziona meglio.
Blue/Green vs Canary: confronto rapido
Blue/Green e Canary sono entrambi modi per rilasciare cambiamenti senza interrompere gli utenti—ma differiscono nel modo in cui il traffico si sposta verso la nuova versione.
Come cambia il traffico
Blue/Green esegue due ambienti completi: “Blue” (corrente) e “Green” (nuovo). Verifichi Green, poi sposti tutto il traffico in una volta—come premere un interruttore controllato.
Canary invia la nuova versione prima a una piccola fetta di utenti (per esempio 1–5%), poi sposta gradualmente il traffico mentre osservi le prestazioni nel mondo reale.
Pro e contro che contano davvero
| Fattore | Blue/Green | Canary |
|---|---|---|
| Velocità | Cutover molto rapido dopo la validazione | Più lento per design (rollout a gradini) |
| Rischio | Medio: una release difettosa colpisce tutti dopo lo switch | Minore: i problemi spesso emergono prima del rollout completo |
| Complessità | Moderata (due ambienti, switch pulito) | Più alta (split del traffico, analisi, step graduali) |
| Costo | Più alto (praticamente raddoppi capacità durante il rollout) | Spesso più basso (puoi scalare con la capacità esistente) |
| Migliore per | Cambiamenti grandi e coordinati | Miglioramenti frequenti e piccoli |
Una guida semplice per decidere
Scegli Blue/Green quando vuoi un momento di taglio pulito e prevedibile—soprattutto per cambiamenti grandi, migrazioni o release che richiedono una netta separazione “vecchio vs nuovo”.
Scegli Canary quando distribuisci spesso, vuoi imparare dal traffico reale in sicurezza e preferisci ridurre il blast radius lasciando che le metriche guidino ogni passo.
Se sei indeciso, parti con Blue/Green per semplicità operativa, poi aggiungi Canary per i servizi ad alto rischio quando il monitoraggio e le pratiche di rollback sono consolidate.
Quando Blue/Green è la scelta giusta
Blue/Green è una buona scelta quando vuoi che i rilasci si sentano come un “colpo di interruttore”. Esegui due ambienti di produzione: Blue (corrente) e Green (nuovo). Quando Green è verificato, instradi gli utenti lì.
Hai bisogno di downtime quasi zero
Se il tuo prodotto non può tollerare finestre di manutenzione visibili—flussi di checkout, sistemi di prenotazione, dashboard autenticati—Blue/Green aiuta perché la nuova versione è avviata, preriscaldata e controllata prima che gli utenti reali vi siano indirizzati. Gran parte del “tempo di deploy” avviene fuori dalla vista dei clienti.
Vuoi il rollback più semplice possibile
Il rollback spesso è solo rimettere il traffico su Blue. Questo è prezioso quando:
- una release deve essere reversibile in pochi minuti
- vuoi evitare hotfix d'emergenza sotto pressione
- ti serve una risposta al fallimento chiara e ripetibile
Il vantaggio chiave è che il rollback non richiede ricostruire o ridistribuire—è uno switch di traffico.
Le modifiche al DB devono essere compatibili
Blue/Green è più semplice quando le migrazioni del database sono backward compatible, perché per un periodo Blue e Green possono coesistere (e leggere/scrivere entrambi, a seconda del routing e della configurazione dei job).
Esempi adatti:
- modifiche additive allo schema (nuove colonne nullable, nuove tabelle)
- ampliamento dei formati dati in modo che il codice vecchio li ignori
Esempi rischiosi: rimuovere colonne, rinominare campi o cambiare significati in place—questi possono rompere la promessa di “tornare indietro” a meno di migrazioni in più fasi.
Puoi permetterti ambienti duplicati e controllo del routing
Blue/Green richiede capacità extra (due stack) e un modo per dirigere il traffico (load balancer, ingress o routing della piattaforma). Se hai già automazione per provisioning e una leva di routing pulita, Blue/Green diventa la scelta pratica per release ad alta confidenza e basso stress.
Quando i Canary hanno più senso
Un rilascio canary è una strategia dove distribuisci un cambiamento a una piccola fetta di utenti reali, impari da ciò che succede e poi espandi. È la scelta giusta quando vuoi ridurre il rischio senza fermare tutto per un grande rilascio “tutto in una volta”.
Hai tanto traffico e segnali chiari
Canary funziona meglio per app ad alto traffico perché anche l'1–5% del traffico può fornire dati significativi rapidamente. Se già monitori metriche chiare (tasso di errori, latenza, conversione, completamento checkout, timeout API), puoi validare la release su pattern di uso reale invece di affidarti solo agli ambienti di test.
Sei preoccupato per prestazioni e casi limite
Alcuni problemi emergono solo sotto carico reale: query DB lente, cache miss, latenza regionale, dispositivi insoliti o flussi utente rari. Con un canary puoi confermare che il cambiamento non aumenta gli errori né degrada le prestazioni prima che raggiunga tutti.
Hai bisogno di rollout a tappe, non di un singolo cutover
Se il tuo prodotto viene rilasciato frequentemente, ha più team che contribuiscono o include cambiamenti che possono essere introdotti gradualmente (tweak UI, esperimenti di prezzo, logiche di raccomandazione), i canary sono naturali. Puoi espandere da 1% → 10% → 50% → 100% in base a quanto osservi.
Le feature flag fanno parte della tua cassetta degli attrezzi
Il canary si sposa bene con le feature flag: puoi distribuire il codice in sicurezza e poi abilitare la funzionalità per un sottoinsieme di utenti, regioni o account. I rollback diventano meno drammatici—spesso basta spegnere una flag anziché ridistribuire.
Se miri alla delivery progressiva, i canary sono spesso il punto di partenza più flessibile.
Vedi anche: /blog/feature-flags-and-progressive-delivery
Fondamenti dello spostamento del traffico (senza gergo)
Lo spostamento del traffico significa semplicemente controllare chi riceve la nuova versione della tua app e quando. Invece di spostare tutti in una volta, trasferisci le richieste gradualmente (o selettivamente) dalla versione vecchia a quella nuova. È il cuore pratico sia di un deployment blue/green sia di un rilascio canary—ed è ciò che rende un rilascio senza downtime realistico.
Il “volante”: dove viene instradato il traffico
Puoi spostare il traffico in diversi punti dello stack. La scelta giusta dipende da cosa già usi e da quanto controllo fine ti serve.
- Load balancer: divide le richieste in entrata tra due ambienti o due gruppi di server.
- Ingress controller (Kubernetes): instrada il traffico a Services diversi basandosi su regole.
- Service mesh: controlla il traffico tra servizi con regole precise e maggiore visibilità.
- CDN / routing edge: utile quando vuoi decisioni di routing vicino agli utenti, spesso per traffico web.
Non hai bisogno di tutti i livelli. Scegli una sola “fonte di verità” per le decisioni di routing così che la tua gestione delle release non diventi approssimazione.
Modi comuni per dividere il traffico
La maggior parte dei team usa uno (o un mix) di questi approcci per lo spostamento del traffico:
- Basato su percentuale: 1% → 5% → 25% → 50% → 100%. Pattern classico del canary.
- Basato su header: instrada richieste con un header specifico (per esempio dagli strumenti QA o tester interni) alla nuova versione.
- Cohort di utenti: prima gruppi specifici—dipendenti, beta user, una regione o un livello di cliente.
La percentuale è più facile da spiegare, ma le cohort sono spesso più sicure perché puoi controllare quali utenti vedono il cambiamento (e evitare di sorprendere i clienti più importanti nelle prime ore).
Sessioni e cache: i due “tranelli”
Due elementi rompono comunemente piani di deployment solidi:
Sticky sessions (affinità di sessione). Se il tuo sistema vincola un utente a un server/versione, uno split al 10% potrebbe non comportarsi come il 10%. Può anche causare bug confusi quando gli utenti rimbalzano tra versioni durante la sessione. Se puoi, usa storage sessione condiviso o assicurati che il routing mantenga un utente coerentemente su una versione.
Cache warming. Le nuove versioni spesso incontrano cache fredde (CDN, cache applicativa, cache di query DB). Questo può sembrare un peggioramento delle prestazioni anche quando il codice è a posto. Pianifica tempo per preriscaldare le cache prima di aumentare il traffico, specialmente per pagine ad alto traffico e endpoint costosi.
Tratta le modifiche al traffico come operazioni controllate
Considera i cambiamenti di routing come modifiche di produzione, non come un click occasionale.
Documenta:
- chi può cambiare gli split del traffico
- come viene approvato (on‑call? release manager? ticket di change?)
- dove si fa (config load balancer, regole ingress, policy mesh)
- come si definisce “stop” (il trigger per mettere in pausa il rollout e seguire il piano di rollback)
Quella piccola governance evita che persone volenterose “spostino al 50%” mentre ancora verificavi se il canary è sano.
Cosa monitorare durante un rollout
Porta le idee Canary su mobile
Crea un'app Flutter e iterala in sicurezza mentre rilasci le modifiche.
Un rollout non è solo “il deploy è riuscito?” È “gli utenti reali stanno avendo una esperienza peggiore?” Il modo più semplice per restare calmi durante Blue/Green o Canary è osservare un piccolo insieme di segnali che ti dicono: il sistema è sano e la modifica sta danneggiando i clienti?
I quattro segnali principali: errori, latenza, saturazione, impatto utente
Tasso di errori: monitora 5xx HTTP, fallimenti di richiesta, timeout e errori di dipendenze (DB, pagamenti, API terze parti). Un canary che aumenta “piccoli” errori può comunque generare molto lavoro al supporto.
Latenza: osserva p50 e p95 (e p99 se disponibile). Una modifica che mantiene stabile la latenza media può comunque creare code lunghe che gli utenti percepiscono.
Saturazione: guarda quanto è “pieno” il sistema—CPU, memoria, IO disco, connessioni DB, depth delle code, pool di thread. Problemi di saturazione spesso emergono prima dei blackout.
Segnali d'impatto utente: misura ciò che gli utenti esperiscono davvero—fallimenti nel checkout, successo del login, risultati di ricerca restituiti, crash dell'app, tempi di caricamento delle pagine chiave. Questi sono spesso più significativi dei soli numeri infrastrutturali.
Costruisci una “dashboard di rilascio” leggibile da tutti
Crea una dashboard compatta che stia su uno schermo e sia condivisa nel canale di rilascio. Mantienila coerente ad ogni rollout così le persone non perdono tempo a cercare grafici.
Includi:
- tasso di errori (totale + endpoint chiave)
- latenza (p50/p95 per percorsi critici)
- saturazione (i 3 vincoli principali per lo stack, es.: CPU app, connessioni DB, depth delle code)
- KPI d'impatto utente (1–3 flussi business‑critical)
Se fai un canary release, segmenta le metriche per versione/gruppo di istanze così puoi confrontare canary vs baseline. Per blue/green, confronta il nuovo ambiente vs il vecchio durante la finestra di cutover.
Imposta soglie chiare per mettere in pausa o rollback
Decidi le regole prima di spostare traffico. Esempi di soglie:
- il tasso di errori aumenta del X% rispetto al baseline per Y minuti
- p95 supera un limite fisso (o cresce del X% rispetto al baseline)
- un KPI d'impatto utente scende sotto il minimo accettabile
I numeri esatti dipendono dal tuo servizio, ma la cosa importante è l'accordo. Se tutti conoscono il piano di rollback e i trigger, eviti discussioni mentre i clienti sono impattati.
Alert focalizzati sulla finestra di rollout
Aggiungi (o stringi temporaneamente) gli alert specifici per le finestre di rollout:
- picchi imprevisti di 5xx/timeout
- regressione improvvisa della latenza su rotte chiave
- crescita rapida di segnali di saturazione (pool di connessioni, code)
Mantieni gli alert azionabili: “cosa è cambiato, dove e cosa fare dopo”. Se gli alert sono rumorosi, la gente ignorerà il segnale importante quando lo spostamento del traffico è in corso.
Controlli pre‑rilascio che catturano i problemi presto
La maggior parte dei fallimenti nei rollout non è causata da “bug grandi”. Sono mismatch piccoli: una config mancante, una migrazione DB sbagliata, un certificato scaduto o un’integrazione che si comporta diversamente nel nuovo ambiente. I controlli pre‑rilascio sono l'occasione per trovare questi problemi quando il blast radius è ancora ridotto.
Inizia con health check e smoke test
Prima di spostare qualsiasi traffico (sia per blue/green che per canary), conferma che la nuova versione sia viva e in grado di servire richieste.
- Assicurati che gli endpoint di health riportino OK (non solo “il processo è in esecuzione”)
- Valida le dipendenze: database, cache, code, object storage, provider email/SMS
- Conferma che segreti e variabili d'ambiente siano presenti e correttamente scoperte
Esegui test end‑to‑end rapidi contro il nuovo ambiente
I test unitari sono utili, ma non provano che il sistema distribuito funzioni. Esegui una breve suite end‑to‑end automatizzata contro il nuovo ambiente che finisca in minuti, non ore.
Concentrati su flussi che attraversano confini di servizio (web → API → DB → terze parti) e includi almeno una richiesta “reale” per ogni integrazione chiave.
Verifica i percorsi utente critici (quelli che pagano le bollette)
I test automatici a volte tralasciano l'ovvio. Fai una verifica mirata e orientata all'uomo dei workflow principali:
- login e reset password
- checkout o flusso di pagamento (inclusi i percorsi di errore)
- azioni core “crea / aggiorna / elimina” che gli utenti fanno ogni giorno
Se supporti ruoli multipli (admin vs cliente), campiona almeno un percorso per ruolo.
Mantieni una checklist di readiness pre‑rilascio
Una checklist trasforma la conoscenza tribale in una strategia ripetibile. Tienila breve e actionabile:
- migrazioni DB applicate e reversibili (o chiaramente sicure)
- osservabilità pronta: logs, dashboard, alert per metriche chiave
- piano di rollback rivisto (chi, come e cosa significa “stop”)
Quando questi controlli sono di routine, lo spostamento del traffico diventa un passo controllato—non un salto nel vuoto.
Rollout Blue/Green: playbook pratico
Possiedi il percorso di rilascio
Mantieni il controllo esportando il codice sorgente quando ne hai bisogno.
Un rollout blue/green è più semplice da eseguire quando lo tratti come una checklist: prepara, distribuisci, valida, switcha, osserva, poi pulisci.
1) Distribuisci su Green (senza toccare gli utenti)
Spedisci la nuova versione nell'ambiente Green mentre Blue continua a servire traffico reale. Mantieni config e segreti allineati così Green sia un vero mirror.
2) Verifica Green prima di qualsiasi switch di traffico
Esegui controlli veloci e ad alto segnale: l'app parte correttamente, le pagine chiave si caricano, pagamenti/login funzionano e i log sembrano normali. Se hai smoke test automatici, eseguili ora. È anche il momento per verificare che dashboard e alert per Green siano attivi.
3) Pianifica le migrazioni DB in modo sicuro (espandi/contrai)
Blue/Green si complica con il database. Usa un approccio espandi/contrai:
- Espandi: aggiungi nuove colonne/tabelle in modo backward compatible.
- Distribuisci Green in modo che possa funzionare con schema vecchio e nuovo.
- Contrai: rimuovi i vecchi campi solo dopo che Blue è ritirato e sei sicuro che il nuovo codice sia stabile.
Questo evita scenari in cui “Green funziona, Blue si rompe” durante lo switch.
4) Preriscalda le cache e gestisci i job in background
Prima di switchare il traffico, preriscalda le cache critiche (home page, query comuni) così gli utenti non pagano il costo del “cold start”.
Per job in background/cron, decidi chi li esegue:
- esegui i job in un solo ambiente durante il cutover per evitare doppie elaborazioni
5) Switch del traffico, poi osserva
Inverti il routing da Blue a Green (load balancer/DNS/ingress). Osserva tasso di errori, latenza e metriche di business per una breve finestra.
6) Verifica post‑switch e pulizia
Esegui un controllo in stile utente reale, poi mantieni Blue disponibile brevemente come fallback. Una volta stabile, disabilita i job di Blue, archivia i log e deprovisiona Blue per ridurre costi e confusione.
Canary Rollout: playbook pratico
Un canary rollout riguarda l'apprendimento sicuro. Invece di mandare subito tutti gli utenti alla nuova versione, esponi una piccola fetta del traffico reale, osserva da vicino e poi espandi. L'obiettivo non è “andare piano”, è “dimostrare che è sicuro” con prove a ogni passo.
Un piano di ramp semplice (1–5% → 25% → 50% → 100%)
- Prepara il canary
Distribuisci la nuova versione insieme alla versione stabile corrente. Assicurati di poter instradare una percentuale definita di traffico a ciascuna e che entrambe le versioni siano visibili nel monitoraggio (dashboard separate o tag aiutano).
- Stage 1: 1–5%
Parti piccolissimo. Qui i problemi evidenti emergono in fretta: endpoint rotti, config mancanti, sorprese nelle migrazioni DB o picchi di latenza imprevisti.
Annota per questa fase:
- cosa è cambiato in questa release (incluse config “piccole”)
- cosa ti aspettavi che succedesse
- cosa hai osservato (errori, latenza, impatti utente)
- Stage 2: 25%
Se il primo stage è pulito, aumenta fino a circa un quarto del traffico. Vedrai più varietà reale: comportamenti utente diversi, dispositivi della long tail, casi limite e concorrenza più alta.
- Stage 3: 50%
A metà traffico diventano più evidenti i problemi di capacità e performance. Se raggiungerai un limite di scalabilità, spesso i segnali precoci emergono qui.
- Stage 4: 100% (promozione)
Quando le metriche sono stabili e l'impatto utente è accettabile, sposta tutto il traffico sulla nuova versione e dichiara la promozione.
Scegliere gli intervalli di ramp (quanto aspettare a ogni step)
I tempi dipendono da rischio e volume di traffico:
- Cambiamento ad alto rischio o basso traffico: aspetta più a lungo per ogni stage per ottenere segnale sufficiente (es.: 30–60 minuti o più). I servizi a basso traffico possono aver bisogno di ore per mostrare pattern significativi.
- Cambiamento a basso rischio con alto traffico: stage più corti possono funzionare (es.: 5–15 minuti), perché raccogli dati rapidamente.
Considera anche i cicli di business. Se il tuo prodotto ha picchi (es.: pause pranzo, weekend, run di fatturazione), esegui il canary abbastanza a lungo da coprire le condizioni che tipicamente causano problemi.
Automatizza promozione e rollback
I rollout manuali creano esitazione e inconsistenza. Quando possibile, automatizza:
- promozione quando le metriche rimangono entro le soglie per una finestra definita
- rollback quando le soglie sono violate (es.: tasso di errori o latenza oltre il limite)
L'automazione non rimuove il giudizio umano—rimuove il ritardo.
Tratta ogni stage come un esperimento
Per ogni step annota:
- sintesi del cambiamento (cosa esattamente è diverso)
- criteri di successo (quali metriche devono rimanere stabili)
- risultati osservati (cosa hai visto, incluso “niente di anomalo”)
- decisione (promuovere, tenere o rollback) e perché
Questi appunti trasformano la storia dei rollout in un playbook per la prossima release—e rendono gli incidenti futuri molto più semplici da diagnosticare.
Piani di rollback e gestione degli errori
I rollback sono più semplici quando decidi prima cosa significa “male” e chi può premere il pulsante. Un piano di rollback non è pessimismo—è come impedisci che piccoli problemi diventino interruzioni prolungate.
Definisci trigger di rollback chiari
Scegli una lista corta di segnali e imposta soglie esplicite per evitare dibattiti durante un incidente. Trigger comuni includono:
- tasso di errori: picchi di 5xx, checkout falliti, login falliti o timeout API
- latenza: p95/p99 sopra un limite concordato per una finestra sostenuta (es.: 5–10 minuti)
- KPI di business: cali improvvisi di conversione, successo pagamento, iscrizioni o aumento cancellazioni
Rendi il trigger misurabile (“p95 > 800ms per 10 minuti”) e assegnalo a un owner (on‑call, release manager) con permesso di agire subito.
Mantieni il rollback veloce (e noioso)
La velocità conta più dell'eleganza. Il tuo rollback dovrebbe essere una di queste azioni:
- invertire lo spostamento del traffico (tipico per blue/green e canary): rimetti il traffico sulla versione precedente nota come buona
- ridistribuire la versione precedente: se l'infrastruttura è cambiata, rilancia l'ultima build stabile e riesegui i controlli di health
Evita “fix manuale e continua il rollout” come prima mossa. Stabilizza prima, indaga dopo.
Pianifica rollout parziali
Con un canary, alcuni utenti potrebbero aver creato dati con la nuova versione. Decidi in anticipo:
- gli utenti “canary” vengono instradati immediatamente indietro, o mantenuti sul canary mentre valuti?
- se i formati dei dati sono cambiati, il DB è backward compatible? Se no, il rollback potrebbe richiedere una mitigazione separata.
Review post‑azione che migliori il prossimo rilascio
Una volta stabile, scrivi una breve nota post‑azione: cosa ha causato il rollback, quali segnali mancavano e cosa cambierai nella checklist. Trattalo come un ciclo di miglioramento prodotto per il processo di rilascio, non come un esercizio di colpa.
Feature flag e consegna progressiva
Pianifica il rollout prima
Mappa passaggi, controlli e trigger di rollback prima di inviare traffico a una nuova versione.
Le feature flag separano “deploy” (spedire codice in produzione) da “release” (attivarlo per le persone). Questo è importante perché puoi usare la stessa pipeline—blue/green o canary—controllando l'esposizione con un semplice interruttore.
Distribuisci senza pressione, rilascia con intento
Con le flag puoi fare merge e deploy in sicurezza anche se una feature non è pronta per tutti. Il codice è presente ma dormiente. Quando sei sicuro, abiliti gradualmente la flag—spesso più velocemente che spingere una nuova build—e se qualcosa va storto puoi disabilitarla altrettanto in fretta.
Abilitazione mirata (non tutto o niente)
La consegna progressiva riguarda l'aumento di accesso in passi deliberati. Una flag può essere abilitata per:
- un gruppo di utenti specifico (staff interno, beta user, tier a pagamento)
- una regione (iniziando da un paese o data center)
- una percentuale di utenti (1% → 10% → 50% → 100%)
Questo è utile quando un canary indica che la versione è sana, ma vuoi comunque gestire il rischio della feature separatamente.
Guardrail per evitare il “debito delle flag”
Le feature flag sono potenti, ma solo se governate. Alcuni accorgimenti le mantengono ordinate e sicure:
- ownership: ogni flag ha un team o una persona responsabile
- scadenza: imposta una data di rimozione (o revisione) così le flag vecchie non si accumulino
- documentazione: descrivi cosa fa la flag, chi impatta e come rollbackarla
Una regola pratica: se qualcuno non sa rispondere “cosa succede quando la spegniamo?” la flag non è pronta.
Per una guida più approfondita sull'uso delle flag come parte di una strategia di rilascio, vedi: /blog/feature-flags-release-strategy.
Come scegliere la strategia e iniziare
Scegliere tra blue/green e canary non è “qual è migliore”. È cosa vuoi controllare e cosa puoi realisticamente gestire con il tuo team e i tool.
Un modo rapido per decidere
Se la tua priorità principale è un cutover pulito e prevedibile e un facile pulsante “torna alla versione precedente”, blue/green è solitamente la scelta più semplice.
Se la priorità è ridurre il blast radius e imparare dal traffico reale prima di estendere la release, canary è più sicuro—soprattutto quando i cambiamenti sono frequenti o difficili da testare completamente in anticipo.
Una regola pratica: scegli l'approccio che il tuo team può eseguire con costanza alle 2 di notte quando qualcosa va storto.
Parti in piccolo: pilota su una cosa
Scegli un servizio (o un workflow user‑facing) e fai un pilota per alcune release. Scegli qualcosa abbastanza importante da contare, ma non così critico che tutti blocchino. L'obiettivo è costruire memoria muscolare su spostamento del traffico, monitoraggio e rollback.
Scrivi un runbook semplice (e assegna responsabilità)
Tienilo corto—una pagina va bene:
- cosa significa “bene” (metriche chiave e soglie)
- chi è responsabile durante un rollout
- come mettere in pausa, rollbackare e comunicare
Assicurati che la responsabilità sia chiara. Una strategia senza owner resta un suggerimento.
Usa prima gli strumenti che hai già
Prima di aggiungere nuove piattaforme, guarda gli strumenti che già usi: impostazioni del load balancer, script di deploy, monitoraggio esistente e processo di incident. Aggiungi nuovo tooling solo quando rimuove frizioni reali che hai provato nel pilota.
Se stai costruendo e distribuendo servizi rapidamente, piattaforme che combinano generazione app con controlli di deployment possono ridurre il carico operativo. Per esempio, Koder.ai è una piattaforma che permette di creare app web, backend e mobile da un'interfaccia chat—e poi distribuirle e ospitarle con funzioni di sicurezza come snapshot e rollback, oltre al supporto per domini personalizzati ed esportazione del codice sorgente. Queste capacità si allineano bene con l'obiettivo principale di questo articolo: rendere i rilasci ripetibili, osservabili e reversibili.
Passi successivi suggeriti
Se vuoi vedere opzioni di implementazione e workflow supportati, rivedi /pricing e /docs/deployments. Poi pianifica il tuo primo rilascio pilota, registra cosa ha funzionato e itera il runbook dopo ogni rollout.