Cosa copre questo post (e perché conta)
Snowflake ha reso popolare un'idea semplice ma di grande impatto nel data warehousing cloud: tenere separate l'archiviazione dei dati e il compute delle query. Questa separazione cambia due problemi quotidiani per i team dati: come i warehouse scalano e come li paghi.
Invece di trattare il warehouse come una singola “scatola” fissa (dove più utenti, più dati o query più complesse competono per le stesse risorse), il modello di Snowflake ti permette di memorizzare i dati una sola volta e avviare la quantità di compute adeguata quando serve. Il risultato è spesso un tempo di risposta più rapido, meno colli di bottiglia nei picchi di utilizzo e un controllo più chiaro su cosa costa (e quando).
Tema #1: prestazioni e scaling senza i compromessi abituali
Questo post spiega, in linguaggio semplice, cosa significa davvero separare storage e compute—e come questo influisce su:
- Concorrenza (molte persone che eseguono query contemporaneamente)
- Scaling elastico (aumentare o ridurre il compute)
- Comportamento dei costi (pagare il compute solo mentre è in esecuzione, più lo storage continuativo)
Indicheremo anche dove il modello non risolve tutto per magia—perché alcune sorprese nei costi e nelle prestazioni derivano da come sono progettati i carichi di lavoro, non dalla piattaforma in sé.
Tema #2: perché l'ecosistema può contare quanto la velocità
Una piattaforma veloce non è tutta la storia. Per molte squadre, il tempo per creare valore dipende dal fatto se puoi collegare facilmente il warehouse agli strumenti che già usi—pipeline ETL/ELT, dashboard BI, strumenti di catalog/governance, controlli di sicurezza e fonti dati dei partner.
L'ecosistema di Snowflake (inclusi pattern di condivisione dati e modalità di distribuzione in stile marketplace) può abbreviare i tempi di implementazione e ridurre l'ingegneria personalizzata. Questo post copre cosa significa avere un “ecosistema profondo” in pratica e come valutarlo per la tua organizzazione.
A chi è rivolto
Questa guida è scritta per responsabili dei dati, analisti e decisori non specialisti—chiunque abbia bisogno di capire i compromessi dietro l'architettura di Snowflake, lo scaling, i costi e le scelte di integrazione senza perdersi nel gergo dei vendor.
Prima della separazione: perché i warehouse tradizionali raggiungono dei limiti
I data warehouse tradizionali erano costruiti attorno a un'ipotesi semplice: compri (o affitti) una quantità fissa di hardware e poi fai girare tutto sulla stessa macchina o cluster. Funzionava bene quando i carichi erano prevedibili e la crescita graduale—ma ha creato limiti strutturali quando i volumi di dati e il numero di utenti sono aumentati velocemente.
Il modello classico: cluster fissi e pianificazione capace
I sistemi on‑prem e le prime migrazioni “lift-and-shift” in cloud tipicamente apparivano così:
- Un singolo cluster MPP (massively parallel processing) gestiva storage, CPU e memoria insieme.
- Si dimensionava il cluster per la domanda di picco, perché ridimensionare era lento, rischioso o richiedeva downtime.
- La pianificazione della capacità diventava un progetto ricorrente: prevedere la crescita, giustificare il budget, ordinare hardware, installare, migrare.
Anche quando i vendor offrivano “nodi”, il modello di base rimaneva lo stesso: scalare significava spesso aggiungere nodi più grandi o più numerosi a un unico ambiente condiviso.
I punti dolenti: scaling lento, spese sprecate e code
Questo design crea alcuni problemi comuni:
- Scaling lento: se un periodo di report trimestrale richiede più potenza, non sempre puoi aggiungerla rapidamente. Devi aspettare o sovradimensionare “per sicurezza”.
- Capacità inattiva: i cluster dimensionati per i picchi restano sotto-utilizzo la maggior parte del tempo—eppure li paghi lo stesso (costi hardware, licenze, tempo operativo).
- Code sotto carico: quando più team eseguono query contemporaneamente, competono per le stesse risorse. Job pesanti possono bloccare dashboard interattive, causando timeout, stakeholder frustrati e regole del tipo “non eseguire quella query durante l'orario lavorativo”.
Poiché questi warehouse erano strettamente accoppiati all'ambiente, le integrazioni crescevano spesso in modo organico: script ETL personalizzati, connettori fatti a mano e pipeline una tantum. Funzionavano—fino a quando uno schema cambiava, un sistema a monte si spostava o si introduceva un nuovo strumento. Mantenere tutto in funzione poteva somigliare più a manutenzione continua che a progresso stabile.
L'idea centrale: separare storage e compute
I data warehouse tradizionali spesso legano due lavori molto diversi: storage (dove risiedono i dati) e compute (la capacità che legge, unisce, aggrega e scrive quei dati).
Storage vs compute (in parole semplici)
Storage è come una dispensa a lungo termine: tabelle, file e metadata sono conservati in modo economico e duraturo, pensati per essere sempre disponibili.
Compute è come lo staff in cucina: è l'insieme di CPU e memoria che effettivamente “prepara” le tue query—eseguendo SQL, ordinando, scansionando, costruendo risultati e gestendo utenti multipli.
Lo spostamento chiave: scalarli in modo indipendente
Snowflake separa questi due elementi così puoi regolare ciascuno senza costringere l'altro a cambiare.
- Se il volume dei dati cresce, aggiungi più storage (di solito incrementale e relativamente prevedibile).
- Se il traffico di report aumenta, aggiungi più compute (ridimensionando o aggiungendo virtual warehouse) senza spostare o duplicare i dati sottostanti.
Praticamente, questo cambia le operazioni quotidiane: non devi “comprare troppo” compute solo perché lo storage cresce, e puoi isolare i carichi (per esempio, analisti vs job ETL) così non si rallentino a vicenda.
Cosa non è
Questa separazione è potente, ma non è magia.
- Non è scaling gratuito. Più o più grandi warehouse generalmente significano spesa compute più alta.
- Non è risparmio automatico ogni volta. Query scritte male, schedulazioni di refresh non necessarie o warehouse sempre attivi possono ancora generare costi.
- Non è una scusa per ignorare la pianificazione. Serve scegliere le taglie dei warehouse, impostare auto-suspend e allineare il compute ai pattern di utilizzo del business.
Il valore è nel controllo: pagare storage e compute separatamente e abbinarli a ciò di cui i tuoi team hanno realmente bisogno.
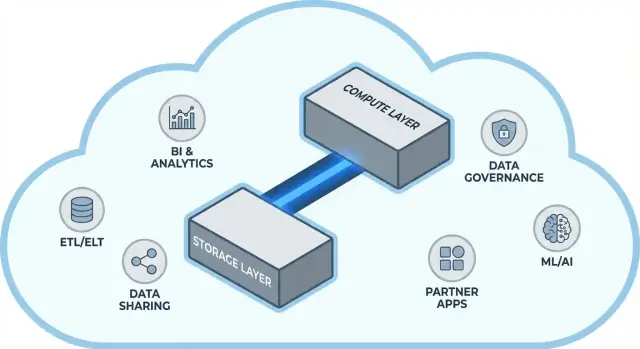
L'architettura di Snowflake in termini semplici
Snowflake è più facile da capire come tre livelli che lavorano insieme, ma possono scalare indipendentemente.
1) Storage: object storage del cloud
Le tue tabelle alla fine risiedono come file di dati nello object storage del provider cloud (S3, Azure Blob, o GCS). Snowflake gestisce i formati dei file, la compressione e l'organizzazione per te. Non “attacchi dischi” né dimensioni volumi: lo storage cresce al crescere dei dati.
2) Compute: virtual warehouses
Il compute è confezionato come virtual warehouses: cluster indipendenti di CPU/memoria che eseguono le query. Puoi far girare più warehouse contemporaneamente sugli stessi dati. Questa è la differenza chiave rispetto ai sistemi più vecchi dove i carichi pesanti tendevano a competere sulle stesse risorse.
Un layer di servizi separato gestisce il “cervello” del sistema: autenticazione, parsing e ottimizzazione delle query, gestione delle transazioni/metadata e coordinamento. Questo layer decide come eseguire efficientemente una query prima che il compute tocchi i dati.
Come scorre una query
Quando invii SQL, il layer dei servizi di Snowflake lo analizza, costruisce un piano di esecuzione e poi passa quel piano a un virtual warehouse scelto. Il warehouse legge solo i file di dati necessari dallo storage a oggetti (e beneficia della cache quando possibile), li elabora e restituisce i risultati—senza spostare permanentemente i dati di base nel warehouse.
Concorrenza e isolamento (senza gergo)
Se molte persone eseguono query contemporaneamente, puoi:
- usare warehouse separati per team/carichi diversi (isolamento dei workload), oppure
- abilitare warehouse multi-cluster così Snowflake può aggiungere più cluster di compute quando la domanda sale e poi ridimensionare.
Questa è la base architetturale dietro le prestazioni di Snowflake e il controllo dei “vicini rumorosi”.
Scaling e concorrenza: cosa cambia davvero
Il grande cambiamento pratico di Snowflake è che scalare il compute è indipendente dai dati. Invece di “il warehouse diventa più grande”, puoi regolare le risorse per workload senza copiare tabelle, riorganizzare dischi o pianificare downtime.
Elasticità: ridimensionare il compute senza muovere i dati
In Snowflake, un virtual warehouse è il motore compute che esegue le query. Puoi ridimensionarlo (es. da Small a Large) in pochi secondi, e i dati restano nello storage condiviso. Questo significa che l'ottimizzazione delle prestazioni spesso diventa una semplice domanda: “Questo workload ha bisogno di più potenza proprio ora?”
Questo abilita anche burst temporanei: scala su per la chiusura di fine mese, poi riduci quando il picco è passato.
Concorrenza: meno code
I sistemi tradizionali spesso costringono team diversi a condividere lo stesso compute, trasformando le ore di punta in una coda alla cassa.
Snowflake ti permette di eseguire warehouse separati per team o workload—per esempio, uno per gli analisti, uno per le dashboard e uno per l'ELT. Poiché questi warehouse leggono gli stessi dati sottostanti, riduci il problema “la mia dashboard ha rallentato il tuo report” e rendi le prestazioni più prevedibili.
Tradeoff che noterai
Il compute elastico non è garanzia di successo. Trappole comuni includono:
- Cold start: i warehouse sospesi possono impiegare un momento a riprendere, aggiungendo latenza per job sporadici.
- Scelte di right-sizing: sovradimensionare spreca soldi; sottodimensionare causa query lente e frustrazione.
- Serve governance: usa auto-suspend/auto-resume, resource monitor e ownership chiara così i warehouse non restino accesi o proliferino senza controllo.
Il cambiamento netto: scaling e concorrenza diventano decisioni operative giornaliere anziché progetti infrastrutturali.
Modello di costo: dove avvengono i risparmi (e dove no)
Right-size con guardrail
Avvia rapidamente uno strumento amministrativo per decisioni sul dimensionamento dei warehouse e regole di isolamento dei carichi.
Come funziona realmente la fatturazione in Snowflake
La strategia “pay for what you use” in Snowflake è, di fatto, due contatori che corrono in parallelo:
- Compute: addebitato per il tempo in cui il tuo virtual warehouse è in esecuzione (in crediti).
- Storage: addebitato per la quantità di dati memorizzata (più eventuale storage extra per funzionalità come Time Travel/Fail-safe).
È da questa separazione che possono nascere i risparmi: puoi mantenere molti dati a basso costo mentre accendi il compute solo quando serve.
Dove i costi possono aumentare
La maggior parte delle spese “inaspettate” nasce dai comportamenti di compute piuttosto che dallo storage. Fattori comuni:
- Warehouse sovradimensionati (scegliere una taglia più grande del necessario)
- Workload always-on (warehouse lasciati in esecuzione notte o weekend)
- Query inefficienti (scansioni non filtrate, join non necessari, trasformazioni pesanti eseguite ripetutamente)
- Pattern ad alta concorrenza (molte dashboard piccole che si aggiornano continuamente)
Separare storage e compute non rende automaticamente le query efficienti—SQL sbagliato può comunque consumare crediti rapidamente.
Controlli pratici che funzionano nel mondo reale
Non serve il dipartimento finance per gestire questo—bastano alcuni paletti:
- Auto-suspend / auto-resume per non pagare il tempo inattivo
- Resource monitor per avvisare o limitare il consumo di crediti per warehouse/team
- Scheduling (eseguire i batch in finestre definite; sospendere dev/test fuori orario)
- Right-sizing e testare taglie più piccole prima di scalare su
Usato bene, il modello premia la disciplina: compute brevi e dimensionati correttamente abbinati a una crescita di storage prevedibile.
Condivisione dati e collaborazione come funzionalità di primo livello
Snowflake tratta la condivisione come una caratteristica progettata nella piattaforma—non come un ripiego basato su export, file drop o ETL one-off.
Condividere senza copiare (in molti casi)
Invece di mandare estratti in giro, Snowflake può permettere a un altro account di interrogare gli stessi dati tramite uno “share” sicuro. In molti scenari, i dati non devono essere duplicati in un secondo warehouse né esportati nello storage a oggetti per il download. Il consumer vede il database/tabella condivisa come se fosse locale, mentre il provider mantiene il controllo su cosa viene esposto.
Questo approccio disaccoppiato è prezioso perché riduce la proliferazione dei dati, accelera l'accesso e diminuisce il numero di pipeline da costruire e mantenere.
Pattern comuni di collaborazione
Condivisione con partner e clienti: un vendor può pubblicare dataset curati ai clienti (es. analytics di utilizzo o dati di riferimento) con confini chiari—solo schemi, tabelle o view permessi.
Condivisione interna per domini: team centrali possono esporre dataset certificati a product, finance e operations senza far creare a ogni team le proprie copie. Questo supporta una cultura del “uno set di numeri” pur permettendo ai team di eseguire il proprio compute.
Collaborazione governata: progetti congiunti (es. con agenzie, fornitori o controllate) possono lavorare su un dataset condiviso mantenendo colonne sensibili mascherate e accessi tracciati.
Limitazioni da considerare
La condivisione non è “imposta e dimenticata”. Serve ancora:
- Governance: ownership chiara, revisioni degli accessi e policy per PII/dati regolamentati.
- Contratti e aspettative: chi paga il compute, SLA, retention e cosa succede se cambiano le definizioni.
- Discoverability: senza un catalog e una naming chiara, le persone non troveranno (o non si fideranno di) i dati giusti. Allinea le share con documentazione e catalog se già li usi.
Perché l'ecosistema può contare quanto le prestazioni
Un warehouse veloce è utile, ma la sola velocità raramente determina se un progetto viene consegnato in tempo. Ciò che spesso fa la differenza è l'ecosistema intorno alla piattaforma: connessioni pronte all'uso, tool e know-how che riducono il lavoro custom.
In pratica, un ecosistema include:
- Connettori a sorgenti e destinazioni (app SaaS, database, strumenti di streaming)
- Tool partner per ingest, trasformazione, BI, qualità dati e osservabilità
- App e integrazioni native che girano vicino ai dati
- Template e reference architecture (modelli comuni, pattern, guide di deploy)
- Conoscenza della community: esempi, forum, meetup e disponibilità di hiring
Perché l'ecosistema può battere i benchmark per la velocità di delivery
I benchmark misurano una fetta ristretta delle prestazioni in condizioni controllate. I progetti reali passano la maggior parte del tempo su:
- Far entrare i dati in modo affidabile e incrementale
- Modellare, testare e documentare i dataset
- Task operativi (monitoraggio, alerting, controllo dei costi)
- Revisioni di sicurezza, controlli accessi e audit
Se la tua piattaforma ha integrazioni mature per questi passaggi, eviti di costruire e mantenere codice di collegamento. Questo in genere accorcia i tempi di implementazione, migliora l'affidabilità e facilita il cambio di team o vendor senza riscrivere tutto.
Un semplice lens di valutazione: copertura, qualità, manutenibilità
Quando valuti un ecosistema, cerca:
- Copertura: supporta le tue sorgenti chiave, strumenti BI, orchestrazione e bisogni di governance?
- Qualità: i connettori sono mantenuti attivamente, ben documentati e provati alla tua scala?
- Manutenibilità: quanto sforzo continuo richiede—upgrade, breaking change, debug e supporto?
Le prestazioni ti danno capacità; l'ecosistema spesso determina quanto velocemente trasformi quella capacità in risultati di business.
Ecosistema di integrazione: far entrare, uscire e usare i dati
Metti KPI su mobile
Crea un'app Flutter per verifiche KPI e alert che usa il tuo modello dati esistente.
Snowflake può eseguire query velocemente, ma il valore si vede quando i dati si muovono affidabilmente attraverso il tuo stack: dalle sorgenti, dentro Snowflake, e di nuovo negli strumenti che le persone usano ogni giorno. L'“ultimo miglio” è spesso ciò che determina se una piattaforma sembra senza sforzo o costantemente fragile.
Le principali categorie di integrazione da pianificare
La maggior parte dei team ha bisogno di un mix di:
- ELT/ETL per ingest da database, app SaaS, file e object storage.
- BI e analytics per dashboard, esplorazione self-serve e semantic layer.
- Reverse ETL per riportare dati curati in CRM, marketing e sistemi di supporto.
- Orchestrazione per scheduling, dipendenze, backfill e promozione degli ambienti.
- Streaming per eventi near-real-time e change data capture.
- Tool ML per pipeline di feature, workflow di training e monitoring dei modelli.
Domande da porre prima di scegliere i connettori
Non tutti gli strumenti “compatibili Snowflake” si comportano allo stesso modo. Durante la valutazione concentrati su dettagli pratici:
- Il connettore è certificato/supportato (e da chi)? Qual è il percorso di escalation?
- Può gestire load incrementali in modo pulito (CDC, timestamp, high-water marks)?
- Come gestisce il drift di schema—nuove colonne, cambi di tipo, campi eliminati?
- Quali garanzie offre su retry, deduplica e exactly-once vs at-least-once?
Non trascurare l'operatività
Le integrazioni hanno bisogno anche di prontezza day‑2: monitoraggio e alert, hook per lineage/catalog e workflow di incident response (ticketing, on-call, runbook). Un ecosistema forte non è solo più loghi—sono meno sorprese quando le pipeline falliscono alle 2 di notte.
Governance, sicurezza e fiducia su scala
Con la crescita dei team, la parte più difficile dell'analytics spesso non è la velocità, ma assicurarsi che le persone giuste possano accedere ai dati giusti per lo scopo giusto, con prove che i controlli funzionino. Le feature di governance di Snowflake sono pensate per questa realtà: tanti utenti, tanti prodotti dati e condivisioni frequenti.
Principi di governance che funzionano davvero
Inizia con ruoli chiari e una mentalità di least-privilege. Invece di dare accesso direttamente alle persone, definisci ruoli come ANALYST_FINANCE o ETL_MARKETING, poi concedi a quei ruoli l'accesso a database, schemi, tabelle e—quando serve—view specifiche.
Per campi sensibili (PII, identificatori finanziari) usa masking policies così le persone possono interrogare i dataset senza vedere i valori raw, a meno che il loro ruolo non lo permetta. Abbina tutto a auditing: traccia chi ha interrogato cosa e quando, così sicurezza e compliance possono rispondere senza congetture.
Perché la governance cambia condivisione e self-service
Una buona governance rende la condivisione più sicura e scalabile. Quando il tuo modello di condivisione è costruito su ruoli, policy e accessi auditati, puoi abilitare con sicurezza il self-service (più utenti che esplorano dati) senza aprire la porta a esposizioni accidentali.
Riduce anche l'attrito per la compliance: le policy diventano controlli ripetibili piuttosto che eccezioni una tantum. Questo conta quando i dataset vengono riutilizzati tra progetti, reparti o partner esterni.
Consigli pratici che prevengono dolori futuri
- Convenzioni di naming: standardizza nomi per database/schemi che segnalino scopo e sensibilità (es.
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). La coerenza accelera le revisioni e riduce gli errori.
- Separazione degli ambienti: mantieni DEV/TEST/PROD separati logicamente, con controlli più stretti in PROD. Tratta i dati di produzione come eccezione, non come default.
- Revisioni degli accessi: imposta una cadenza (mensile per dati ad alto rischio, trimestrale altrimenti). Rivedi membership dei ruoli, utenti inattivi e privilegi elevati.
La fiducia su scala è meno una singola “controllo perfetto” e più un sistema di abitudini piccole e affidabili che mantengono l'accesso intenzionale e spiegabile.
Carichi di lavoro e pattern di best practice
Traccia la spesa dei warehouse
Costruisci un hub leggero per costi e utilizzo che aiuti i team a vedere le cause del consumo di compute.
Snowflake tende a brillare quando molte persone e strumenti devono interrogare gli stessi dati per ragioni diverse. Poiché il compute è confezionato in warehouse indipendenti, puoi mappare ogni workload a una forma e un orario che funzionino.
Mappature comuni dei workload
Analytics & dashboard: Metti gli strumenti BI su un warehouse dedicato dimensionato per un volume di query stabile e prevedibile. Questo evita che i refresh delle dashboard vengano rallentati dall'esplorazione ad hoc.
Analisi ad hoc: Dai agli analisti un warehouse separato (spesso più piccolo) con auto-suspend abilitato. Ottieni iterazione rapida senza pagare per il tempo inattivo.
Data science & sperimentazione: Usa un warehouse dimensionato per scansioni più pesanti e burst occasionali. Se gli esperimenti impennano, scala temporaneamente questo warehouse senza impattare gli utenti BI.
App dati & embedded analytics: Tratta il traffico dell'app come un servizio di produzione—warehouse separato, timeout conservativi e resource monitor per prevenire spese a sorpresa.
Se stai costruendo app interne leggere (es. un portale ops che interroga Snowflake e mostra KPI), un percorso rapido è generare uno scaffold React + API e iterare con gli stakeholder. Piattaforme come Koder.ai (una piattaforma vibe-coding che costruisce app web/server/mobile da chat) possono aiutare i team a prototipare rapidamente queste app basate su Snowflake, poi esportare il codice sorgente quando sei pronto a operationalizzare.
Pattern best-practice che reggono
Una regola semplice: separa i warehouse per pubblico e scopo (BI, ELT, ad hoc, ML, app). Abbinalo a buone abitudini di query—evita SELECT * ampi, filtra presto e fai attenzione ai join inefficienti. Sul fronte del modeling, dai priorità a strutture che rispecchiano come le persone interrogano i dati (spesso un semantic layer pulito o mart ben definiti), piuttosto che iper-ottimizzare layout fisici.
Quando considerare alternative o complementi
Snowflake non è la sostituzione per tutto. Per carichi transazionali ad alta velocità e bassa latenza (tipici OLTP), un database specializzato è di solito più adatto, mentre Snowflake resta la scelta per analytics, reporting, condivisione e prodotti dati downstream. Setup ibridi sono comuni—e spesso i più pratici.
Considerazioni per la migrazione: cosa pianificare prima di muovere tutto
Una migrazione a Snowflake raramente è un “lift and shift”. La separazione storage/compute cambia come dimensioni, tuning e costi dei workload—quindi pianificare in anticipo previene sorprese dopo il cutover.
Una sequenza pratica di migrazione
Inizia con un inventario: quali sorgenti alimentano il warehouse, quali pipeline lo trasformano, quali dashboard dipendono da esso e chi possiede ogni componente. Poi prioritizza per impatto di business e complessità (es. reporting finanziario critico prima, sandbox sperimentali dopo).
Successivamente, converti SQL e logica ETL. Gran parte dello SQL standard si trasferisce, ma dettagli come funzioni, gestione delle date, codice procedurale e pattern con temp table spesso richiedono riscritture. Valida i risultati presto: esegui output in parallelo, confronta conteggi di righe e aggregati e conferma i casi limite (null, fusi orari, logiche di dedup).
Infine, pianifica il cutover: una finestra di freeze, una strategia di rollback e una chiara “definition of done” per ogni dataset e report.
Rischi tipici da monitorare
Le dipendenze nascoste sono le più comuni: un estratto su spreadsheet, una stringa di connessione hard-coded, un job a valle che nessuno ricorda. Sorprese sulle prestazioni possono emergere quando vecchie assunzioni di tuning non si applicano (es. abuso di tiny warehouse, o molte query piccole eseguite senza considerare la concorrenza). I picchi di costo di solito derivano da warehouse lasciati accesi, retry incontrollati o workload dev/test duplicati. Gap di permessi emergono quando si passa da ruoli grossolani a una governance più granulare—i test dovrebbero includere esecuzioni con utenti in least-privilege.
Change management (non saltarlo)
Stabilisci un modello di ownership (chi possiede dati, pipeline e costi), eroga formazione basata sui ruoli per analisti e ingegneri e definisci un piano di supporto per le prime settimane dopo il cutover (rotazione on-call, runbook di incident e un luogo dove segnalare problemi).
Scegliere una piattaforma moderna non riguarda solo la massima velocità da benchmark. Conta se la piattaforma si adatta ai tuoi workload reali, al modo di lavorare del team e agli strumenti su cui fai affidamento.
Checklist pratica di valutazione
Usa queste domande per guidare la short list e le conversazioni con i vendor:
- Workload: stai principalmente eseguendo dashboard schedulati, analisi ad-hoc, data science, ELT/ETL o app rivolte ai clienti? Hai bisogno di finestre batch prevedibili o di capacità elastica a burst?
- Bisogni di concorrenza: quante persone (o applicazioni) interrogheranno contemporaneamente e quanto è “spiky” l'uso durante le ore lavorative?
- Requisiti di condivisione dati: devi condividere dati live con partner, unità di business o clienti senza spedire file? Prevedi di consumare dataset di terze parti?
- Adattamento degli strumenti: i tuoi strumenti BI, orchestrazione, catalog e CI/CD si integrano senza problemi? Cosa si rompe se ti muovi?
- Governance e sicurezza: hai bisogno di controllo accessi fine-grained, trail di audit, masking, policy di retention e separazione dei compiti?
- Vincoli di costo: quali costi contano di più—spesa steady-state, spesa nelle ore di picco o la possibilità di spegnere il compute? Come eviterai sprechi “always-on”?
Piano pilota breve (2–4 settimane)
Scegli due o tre dataset rappresentativi (non campioni toy): una large fact, una sorgente semi-strutturata complessa e un dominio critico per il business.
Poi esegui query reali degli utenti: dashboard al picco mattutino, esplorazione analitica, load schedulati e alcuni join peggiori. Traccia: tempo di query, comportamento in concorrenza, tempo di ingest, sforzo operativo e costo per workload.
Se nella valutazione rientra “quanto velocemente possiamo consegnare qualcosa che la gente usa davvero”, considera di aggiungere al pilot un deliverable piccolo—come un'app di metriche interna o un workflow governato di richiesta dati che interroga Snowflake. Costruire quel sottile strato spesso rivela più rapidamente le realtà di integrazione e sicurezza rispetto ai soli benchmark, e strumenti come Koder.ai possono accelerare il ciclo prototipo‑produzione generando la struttura dell'app via chat e permettendo di esportare il codice per la manutenzione a lungo termine.
Passi successivi suggeriti
Se vuoi aiuto a stimare la spesa e confrontare opzioni, comincia dalla pagina dei prezzi.
Per guida su migrazione e governance, consulta gli articoli correlati nel blog.