08 ott 2025·8 min
Database SQL distribuiti: quando usare Spanner, Cockroach, Yugabyte
Scopri cos'è il SQL distribuito, come differiscono Spanner, CockroachDB e YugabyteDB e in quali casi reali giustifica un SQL fortemente consistente multi-regione.
Scopri cos'è il SQL distribuito, come differiscono Spanner, CockroachDB e YugabyteDB e in quali casi reali giustifica un SQL fortemente consistente multi-regione.
“Distributed SQL” è un database che si presenta e si usa come un tradizionale database relazionale—tabelle, righe, join, transazioni e SQL—ma è progettato per girare come cluster su molte macchine (e spesso su più regioni) mantenendo il comportamento di un unico database logico.
Questa combinazione conta perché prova a offrire tre cose insieme:
Un RDBMS classico (come PostgreSQL o MySQL) è generalmente più semplice da gestire quando tutto vive su un singolo nodo primario. Puoi scalare le letture con repliche, ma scalare le scritture e sopravvivere a outage regionali di solito richiede architetture aggiuntive (sharding, failover manuale e logiche applicative attente).
Molti sistemi NoSQL hanno seguito la strada opposta: prima scalabilità e disponibilità, talvolta relaxando le garanzie di consistenza o offrendo modelli di query più semplici.
Distributed SQL cerca una via di mezzo: mantenere il modello relazionale e le transazioni ACID, ma distribuire i dati automaticamente per gestire crescita e guasti.
I database Distributed SQL sono costruiti per problemi come:
Per questo prodotti come Google Spanner, CockroachDB e YugabyteDB sono spesso valutati per deploy multi-regione e servizi always-on.
Distributed SQL non è automaticamente “meglio”. Accetti più componenti mobili e diverse realtà di performance (salti di rete, consenso, latenza cross-region) in cambio di resilienza e scala.
Se il tuo carico entra in un singolo database ben gestito con una replica semplice, un RDBMS convenzionale può essere più semplice ed economico. Distributed SQL ripaga quando l'alternativa è sharding custom, failover complessi o requisiti di business che chiedono consistenza e uptime multi-regione.
Distributed SQL vuole sembrare un database SQL familiare mentre memorizza i dati su più macchine (e spesso più regioni). La parte difficile è coordinare molti computer perché si comportino come un sistema affidabile e unico.
Ogni pezzo di dato è normalmente copiato su diversi nodi (replica). Se un nodo muore, un'altra copia può ancora servire letture e accettare scritture.
Per evitare che le repliche divergano, i sistemi Distributed SQL usano protocolli di consenso—più comunemente Raft (CockroachDB, YugabyteDB) o Paxos (Spanner). A grandi linee, consenso significa:
Questa “votazione di maggioranza” è ciò che dà la forte consistenza: una volta che una transazione è commessa, gli altri client non vedranno una versione precedente del dato.
Nessuna singola macchina può contenere tutto, quindi le tabelle vengono suddivise in pezzi più piccoli chiamati shard/partizioni (Spanner li chiama splits; CockroachDB li chiama ranges; YugabyteDB li chiama tablets).
Ogni partizione è replicata (usando consenso) e posizionata su nodi specifici. Il posizionamento non è casuale: puoi influenzarlo tramite policy (ad esempio, mantenere i record dei clienti EU nelle regioni EU, o tenere le partizioni “calde” su nodi più veloci). Un buon posizionamento riduce i viaggi cross-network e rende le performance più prevedibili.
Con un database single-node, una transazione può spesso commettere con operazioni locali su disco. Nel Distributed SQL, una transazione può toccare più partizioni—potenzialmente su nodi diversi.
Commettere in modo sicuro di solito richiede coordinazione extra:
Questi passi introducono round trip di rete, ed è per questo che le transazioni distribuite tipicamente aumentano la latenza—soprattutto quando i dati attraversano regioni.
Quando il deployment si estende su regioni, i sistemi cercano di mantenere le operazioni “vicine” agli utenti:
Questo è il bilanciamento core multi-regione: puoi ottimizzare per la reattività locale, ma la forte consistenza su lunghe distanze pagherà sempre un costo di rete.
Prima di scegliere Distributed SQL, verifica le esigenze di base. Se hai una singola regione primaria, carichi prevedibili e poca operation, un database relazionale convenzionale (o un Postgres/MySQL gestito) è generalmente il modo più semplice per spedire funzionalità velocemente. Spesso puoi allungare molto un setup single-region con repliche di lettura, caching e un buon lavoro su schema/indici.
Distributed SQL vale la pena quando una (o più) delle seguenti è vera:
I sistemi distribuiti aggiungono complessità e costi. Sii cauto se:
Se puoi rispondere “sì” a due o più di queste, Distributed SQL vale probabilmente la pena valutare:
Distributed SQL suona come “prendi tutto insieme”, ma i sistemi reali ti costringono a scegliere—soprattutto quando le regioni non riescono a comunicare affidabilmente.
Pensa a una partizione di rete come “il collegamento tra regioni è instabile o giù”. In quel momento, un database può prioritizzare:
I sistemi Distributed SQL sono tipicamente costruiti per favorire la consistenza per le transazioni. Questo è spesso quello che i team vogliono—fino a quando una partizione non richiede che certe operazioni aspettino o falliscano.
La forte consistenza significa che una volta che una transazione è commessa, qualsiasi lettura successiva restituisce quel valore commesso—niente “ha funzionato in una regione ma non in un'altra”. Questo è critico per:
Se la promessa del tuo prodotto è “quando lo confermiamo, è reale”, la forte consistenza è una feature, non un lusso.
Due comportamenti pratici contano:
La forte consistenza tra regioni richiede di solito consenso (più repliche devono essere d'accordo prima del commit). Se le repliche sono sparse tra continenti, la velocità della luce diventa un vincolo: ogni scrittura cross-region può aggiungere decine o centinaia di millisecondi.
Il tradeoff è semplice: più sicurezza geografica e correttezza spesso significa maggiore latenza di scrittura a meno che non si scelga con cura dove i dati vivono e dove è permesso commettere transazioni.
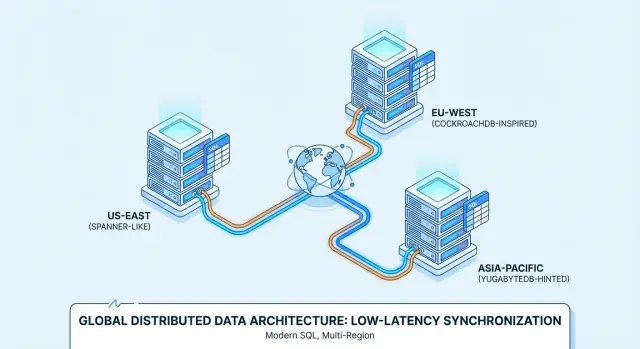
Google Spanner è un database Distributed SQL offerto principalmente come servizio gestito su Google Cloud. È progettato per deploy multi-regione dove vuoi un unico database logico con dati replicati tra nodi e regioni. Spanner supporta due opzioni di dialetto SQL—GoogleSQL (il suo dialetto nativo) e un dialetto compatibile PostgreSQL—quindi la portabilità varia a seconda di quale scegli e dalle funzionalità su cui fa affidamento la tua applicazione.
CockroachDB è un database Distributed SQL che mira a essere familiare alle squadre abituate a PostgreSQL. Usa il protocollo wire di PostgreSQL e supporta una larga parte del SQL in stile Postgres, ma non è un sostituto byte-per-byte di Postgres (alcune estensioni e comportamenti di edge-case differiscono). Puoi eseguirlo come servizio gestito (CockroachDB Cloud) o self-host.
YugabyteDB è un database distribuito con un'API SQL compatibile con PostgreSQL (YSQL) e un'ulteriore API compatibile Cassandra (YCQL). Come CockroachDB, è spesso valutato da team che vogliono ergonomia di sviluppo simile a Postgres pur scalando su nodi e regioni. È disponibile sia self-hosted sia come offerta gestita (YugabyteDB Managed), con deploy che vanno da single-region HA a configurazioni multi-regione.
I servizi gestiti tipicamente riducono il lavoro operativo (upgrade, backup, integrazioni di monitoring), mentre il self-hosting dà più controllo su networking, tipi di istanze e dove i dati fisicamente girano. Spanner è più comune come servizio gestito su GCP; CockroachDB e YugabyteDB sono spesso visti sia in modelli gestiti sia self-hosted, incluse opzioni multi-cloud e on-prem.
Tutti e tre parlano “SQL”, ma la compatibilità quotidiana dipende dalla scelta del dialetto (Spanner), dalla copertura delle feature Postgres (CockroachDB/YugabyteDB) e dal fatto se la tua app dipende da estensioni, funzioni o semantiche di transazione specifiche di Postgres.
Pianificare e testare qui ripaga: verifica presto query, migrazioni e comportamento dell'ORM invece di assumere equivalenza drop-in.
Un classico fit per Distributed SQL è un prodotto B2B SaaS con clienti in Nord America, Europa e APAC—pensate strumenti di supporto, piattaforme HR, dashboard di analytics o marketplace.
Il requisito di business è semplice: gli utenti vogliono reattività “locale”, mentre l'azienda vuole un unico database logico sempre disponibile.
Molti team SaaS finiscono con un mix di requisiti:
Distributed SQL può modellare questo pulitamente con località per tenant: posiziona i dati primari di ogni tenant in una regione specifica (o in un set di regioni) mantenendo schema e modello di query coerenti su tutto il sistema. Così eviti la proliferazione di “un database per regione” pur rispettando esigenze di residenza.
Per mantenere l'app veloce, di solito punti a:
Questo conta perché i round trip cross-region dominano la latenza percepita dall'utente. Anche con forte consistenza, un buon design di località assicura che la maggior parte delle richieste non paghi costi intercontinentali.
I guadagni tecnici contano solo se l'operatività rimane gestibile. Per un SaaS globale pianifica:
Se fatto bene, Distributed SQL ti dà un'esperienza prodotto unica che sembra comunque locale—senza dividere il team ingegneristico in “stack EU” e “stack APAC”.
I sistemi finanziari sono il luogo dove l'“eventual consistency” può tradursi in perdita reale di denaro. Se un cliente effettua un ordine, viene autorizzato un pagamento e un saldo viene aggiornato, quei passaggi devono concordare su una singola verità—subito.
La forte consistenza è importante perché evita che due regioni (o due servizi) prendano entrambe una decisione “ragionevole” che porta a un ledger errato.
In un workflow tipico—crea ordine → riserva fondi → cattura pagamento → aggiorna saldo/ledger—vuoi garanzie come:
Distributed SQL è adatto perché fornisce transazioni ACID e vincoli attraverso nodi (e spesso regioni), così le invarianti del ledger reggono anche durante i guasti.
La maggior parte delle integrazioni di pagamento prevedono molti retry: timeout, webhook retry e rielaborazione dei job sono normali. Il database dovrebbe aiutare a rendere i retry sicuri.
Un approccio pratico è affiancare chiavi di idempotenza a livello applicativo con unicità imposta dal database:
idempotency_key per cliente/tentativo di pagamento.(account_id, idempotency_key).In questo modo il secondo tentativo diventa un no-op innocuo invece che un doppio addebito.
Eventi di vendita e run payroll possono generare forti picchi di scritture (autorizzazioni, capture, transfer). Con Distributed SQL puoi scalare aggiungendo nodi per aumentare il throughput di scrittura mantenendo lo stesso modello di consistenza.
La chiave è pianificare i hot key (es. un singolo account merchant che riceve tutto il traffico) e usare pattern di schema che distribuiscano il carico.
I workflow finanziari richiedono spesso trail di audit immutabili, tracciabilità (chi/cosa/quando) e politiche di retention prevedibili. Anche senza nominare regolamenti specifici, assumi che serviranno: voci di ledger append-only, record con timestamp, accessi controllati e regole di retention/archiviazione che non compromettano l'auditabilità.
Inventario e prenotazioni sembrano semplici finché non hai più regioni che servono la stessa risorsa scarsa: l'ultimo posto del concerto, un prodotto in “limited drop” o una camera per una notte specifica.
La difficoltà non è leggere la disponibilità—è impedire a due persone di rivendicare con successo lo stesso elemento quasi contemporaneamente.
In un setup multi-regione senza forte consistenza, ogni regione può temporaneamente credere di avere ancora disponibilità basandosi su dati leggermente obsoleti. Se due utenti completano il checkout in regioni diverse in quella finestra, entrambe le transazioni possono essere accettate localmente e confliggere durante la riconciliazione.
Così nasce l'oversell cross-region: non perché il sistema sia “sbagliato”, ma perché ha permesso verità divergenti per un breve periodo.
Distributed SQL viene spesso scelto qui perché può imporre un unico risultato autorevole per le scritture—così “l'ultimo posto” viene davvero allocato una sola volta, anche se le richieste arrivano da continenti diversi.
Hold + confirm: metti una hold temporanea (un record di prenotazione) in una transazione, poi conferma il pagamento in un secondo step.
Scadenze: le hold dovrebbero scadere automaticamente (es. dopo 10 minuti) per evitare che l'inventario rimanga bloccato se l'utente abbandona il checkout.
Transactional outbox: quando una prenotazione è confermata, scrivi una riga “evento da inviare” nella stessa transazione, poi consegnala in maniera asincrona a email, fulfillment, analytics o a un message bus—senza rischiare il gap “prenotato ma nessuna conferma inviata”.
Il takeaway: se il tuo business non tollera doppie allocazioni across regioni, le garanzie transazionali forti diventano una feature di prodotto, non un dettaglio tecnico.
L'alta disponibilità (HA) è un buon fit per Distributed SQL quando il downtime è costoso, gli outage imprevedibili sono inaccettabili e vuoi che la manutenzione non sia un evento traumatico.
L'obiettivo non è “mai cadere”—è rispettare SLO chiari (ad esempio 99.9% o 99.99% uptime) anche quando nodi muoiono, zone vanno giù o stai applicando upgrade.
Trasforma “always-on” in aspettative misurabili: downtime massimo mensile, RTO e RPO.
I sistemi Distributed SQL possono continuare a servire letture/scritture durante molti guasti comuni, ma solo se la topologia corrisponde al tuo SLO e la tua app gestisce errori transitori (retry, idempotenza) in modo pulito.
La manutenzione pianificata conta anche. Rolling upgrade e sostituzione di istanze sono più semplici quando il database può spostare leadership/repliche lontano dai nodi impattati senza prendere offline l'intero cluster.
Multi-zone protegge da outage di una singola AZ/zone e da molti guasti hardware, spesso con latenza e costi inferiori. Spesso è sufficiente se compliance e base utenti sono principalmente in una regione.
Multi-region protegge da un'intera regione e supporta failover regionale. Il tradeoff è latenza di scrittura più alta per transazioni fortemente consistenti che spaziano regioni, più pianificazione di capacità complessa.
Non dare per scontato che il failover sia istantaneo o invisibile. Definisci cosa significa “failover” per il tuo servizio: spike di errori brevi? periodi in sola lettura? alcuni secondi di latenza aumentata?
Esegui “game days” per verificarlo:
Anche con replica sincrona, conserva backup e prova il restore. I backup proteggono da errori operativi (migrazioni sbagliate, delete accidentali), bug applicativi e corruzione che può replicarsi.
Valida il point-in-time recovery (se disponibile), la velocità di restore e la capacità di recuperare in un ambiente pulito senza toccare la produzione.
I requisiti di residenza compaiono quando regolamenti, contratti o policy interne dicono che certi record devono essere memorizzati (e talvolta processati) in un paese o regione specifica.
Questo può riguardare dati personali, informazioni sanitarie, dati di pagamento, workload governativi o dataset “di proprietà del cliente” dove il contratto impone dove i dati devono risiedere.
Distributed SQL è spesso considerato perché può mantenere un unico database logico posizionando fisicamente i dati in regioni diverse—senza costringerti a gestire un'intera stack applicativa separata per ogni geografia.
Se un regolatore o cliente richiede “i dati restano nella regione”, non basta avere repliche a bassa latenza vicine. Potresti dover garantire che:
Questo spinge i team verso architetture dove la posizione è una preoccupazione di prima classe, non un ripensamento.
Un pattern comune in SaaS è il posizionamento per tenant. Ad esempio: i clienti EU hanno le righe/partizioni bloccate nelle regioni EU, gli US nei data center US.
A livello alto combini tipicamente:
L'obiettivo è rendere difficile violare accidentalmente la residenza via accessi operativi, restore di backup o replicazione cross-region.
Residenza e obblighi di compliance variano molto per paese, industria e contratto. Cambiano anche nel tempo.
Tratta la topologia del database come parte del programma di compliance e convalida le ipotesi con consulenti legali qualificati (e, quando rilevante, con gli auditor).
Le topologie compatibili con la residenza possono complicare le visioni globali del business. Se i dati dei clienti sono intenzionalmente mantenuti in regioni separate, analytics e reporting potrebbero:
In pratica molte squadre separano i workload operativi (forte consistenza, sensibili alla residenza) dall'analytics (warehouse regionali o dataset aggregati governati) per mantenere la compliance senza rallentare il reporting di prodotto quotidiano.
Distributed SQL può salvarti da outage dolorosi e limiti regionali, ma raramente fa risparmiare denaro di default. Pianificare aiuta a evitare di pagare per “assicurazioni” che non serve davvero.
I budget si dividono spesso in quattro voci:
I sistemi Distributed SQL aggiungono coordinazione—specialmente per scritture fortemente consistenti che devono essere confermate da un quorum.
Un modo pratico per stimare l'impatto:
Questo non significa “non farlo”, ma che dovresti progettare i percorsi per ridurre scritture sequenziali (batching, retry idempotenti, transazioni meno chatty).
Se i tuoi utenti sono per lo più in una regione, un Postgres single-region con repliche di lettura, ottimi backup e un piano di failover testato può essere più economico e semplice—e veloce.
Distributed SQL ripaga quando serve davvero scritture multi-regione, RPO/RTO stretti o posizionamento residenza-dati.
Tratta la spesa come un trade-off:
Se la perdita evitata (downtime + churn + rischio compliance) è maggiore del premium ongoing, il design multi-regione è giustificato. Altrimenti, parti più semplice—e tieni una strada per evolvere dopo.
Adottare Distributed SQL è meno sollevare e spostare un database e più dimostrare che il tuo workload si comporta bene quando dati e consenso sono sparsi su nodi (e forse regioni). Un piano leggero aiuta a evitare sorprese.
Scegli un workload che rappresenta un vero dolore: es. checkout/prenotazione, provisioning account, o posting su ledger.
Definisci metriche di successo prima:
Se vuoi accelerare nel PoC, aiuta costruire una piccola app “realistica” (API + UI) invece di soli benchmark sintetici. Per esempio, team a volte usano Koder.ai per far partire velocemente un baseline React + Go + PostgreSQL via chat, poi sostituiscono il layer database con CockroachDB/YugabyteDB (o si connettono a Spanner) per testare pattern di transazione, retry e comportamento end-to-end. L'obiettivo non è lo starter stack ma accorciare il ciclo da “idea” a “workload misurabile”.
Monitoring e runbook contano quanto il SQL:
Parti con uno sprint PoC, poi metti in budget tempo per una review di readiness production e un cutover graduale (dual writes o shadow reads quando possibile).
Se vuoi stimare costi o tier, vedi /pricing. Per walkthrough pratici e pattern di migrazione, sfoglia /blog.
Se poi documenti i risultati del PoC, i tradeoff architetturali o le lezioni di migrazione, considera di condividerli col team (e pubblicamente quando possibile): piattaforme come Koder.ai offrono anche modi per guadagnare crediti creando contenuti educativi o riferendo altri builder, il che può compensare i costi di sperimentazione mentre valuti le opzioni.
Un database Distributed SQL offre un'interfaccia relazionale e SQL (tabelle, join, vincoli, transazioni) ma gira come un cluster su più macchine—spesso anche su più regioni—comportandosi come un unico database logico.
Nella pratica cerca di combinare:
Un RDBMS single-node o con primary/replica è spesso più semplice, economico e veloce per OLTP in una singola regione.
Distributed SQL diventa interessante quando l'alternativa è:
La maggior parte dei sistemi si basa su due idee fondamentali:
Questo abilita la forte consistenza anche in presenza di guasti, ma aggiunge overhead di coordinazione di rete.
I database dividono le tabelle in pezzi più piccoli (spesso chiamati partizioni/shard, o con nomi specifici del fornitore come ranges/tablets/splits). Ogni partizione:
Di solito si influenza il posizionamento con politiche in modo che i dati “hot” e i writer primari restino vicini, riducendo viaggi cross-network.
Le transazioni distribuite spesso toccano più partizioni, potenzialmente su nodi o regioni diverse. Un commit sicuro può richiedere:
Questi passaggi introducono round trip di rete ed è il motivo principale per cui la latenza di scrittura può aumentare—soprattutto quando il consenso attraversa regioni.
Considera Distributed SQL quando due o più delle seguenti sono vere:
Se il carico sta bene in una regione con repliche e caching, un RDBMS convenzionale è spesso la scelta migliore.
La forte consistenza significa che una volta che una transazione è confermata, le letture successive non vedranno dati più vecchi.
In termini di prodotto aiuta a prevenire:
Il costo è che durante partizioni di rete un sistema fortemente consistente può bloccare o far fallire alcune operazioni invece di accettare verità divergenti.
Fai leva su vincoli del database + transazioni:
idempotency_key (o simile) per richiesta/tentativo(account_id, idempotency_key)Così i retry diventano no-op invece che duplicati—essenziale per pagamenti, provisioning e rielaborazione di job in background.
Una separazione pratica:
Prima di scegliere, testa ORM/migrazioni e qualsiasi estensione Postgres di cui dipendi—non dare per scontata la sostituzione drop-in.
Inizia con un PoC focalizzato su un workflow critico (checkout, prenotazione, posting su ledger). Valida:
Se ti serve aiuto per stimare costi/tiers, vedi /pricing. Per note di implementazione, sfoglia /blog.