Database SQL vs NoSQL: differenze chiave e casi d'uso
Scopri le vere differenze tra database SQL e NoSQL: modelli di dati, scalabilità, consistenza e quando conviene usare ciascuno per le tue applicazioni.
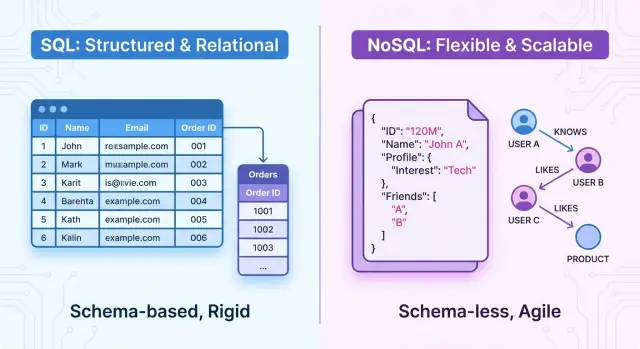
Panoramica: SQL e NoSQL in sintesi
Scegliere tra database SQL e NoSQL condiziona il modo in cui progetti, costruisci e scalabilizzi la tua applicazione. Il modello di dati influenza tutto, dalle strutture e pattern di query alle prestazioni, alla affidabilità e alla rapidità con cui il team può evolvere il prodotto.
A grandi linee, i database SQL sono sistemi relazionali. I dati sono organizzati in tabelle con schemi fissi, righe e colonne. Le relazioni tra entità sono esplicite (tramite chiavi esterne) e interroghi i dati usando SQL, un linguaggio dichiarativo potente. Questi sistemi enfatizzano transazioni ACID, forte consistenza e una struttura ben definita.
I database NoSQL sono sistemi non relazionali. Invece di un singolo modello tabellare rigido, offrono vari modelli di dati progettati per esigenze diverse, come:
- key‑value
- documenti
- wide‑column
- grafi
Questo significa che “NoSQL” non è una sola tecnologia, ma un termine ombrello per approcci diversi, ciascuno con compromessi in flessibilità, prestazioni e modellazione dei dati. Molti sistemi NoSQL rilassano garanzie strette di consistenza in favore di alta scalabilità, disponibilità o bassa latenza.
L'articolo si concentra sulla differenza tra SQL e NoSQL—modelli di dati, linguaggi di query, prestazioni, scalabilità e consistenza (ACID vs consistenza eventuale). L'obiettivo è aiutarti a decidere tra SQL e NoSQL per progetti specifici e capire quando ciascun tipo è più adatto.
Non è detto che tu debba sceglierne solo uno. Molte architetture moderne adottano la polyglot persistence, dove SQL e NoSQL coesistono nello stesso sistema, ognuno occupandosi dei carichi per cui è più adatto.
Che cos'è un database SQL (relazionale)?
Un database SQL (relazionale) memorizza i dati in forma tabellare strutturata e usa il Structured Query Language (SQL) per definire, interrogare e manipolare quei dati. Si basa sul concetto matematico di relazioni, che si possono pensare come tabelle ben organizzate.
Struttura principale: tabelle, righe, colonne e schemi
I dati sono organizzati in tabelle. Ogni tabella rappresenta un tipo di entità, come customers, orders o products.
- Una riga (record) è un'istanza di quell'entità, come un singolo cliente.
- Una colonna (campo) è un attributo specifico, per esempio
emailoorder_date.
Ogni tabella segue uno schema fisso: una struttura predefinita che specifica
- quali colonne esistono
- i loro tipi di dato (es.
INTEGER,VARCHAR,DATE) - i vincoli (es.
NOT NULL,UNIQUE)
Lo schema è applicato dal database, il che aiuta a mantenere i dati coerenti e prevedibili.
Chiavi e relazioni
I database relazionali sono eccellenti nel modellare come le entità si relazionano tra loro.
- Una primary key identifica in modo univoco ogni riga in una tabella (es.
customer_id). - Una foreign key è una colonna che fa riferimento a una primary key in un'altra tabella, collegando righe correlate.
Queste chiavi permettono di definire relazioni come:
- one‑to‑many (un cliente, molti ordini)
- many‑to‑many (prodotti in molti ordini, ordini con molti prodotti)
Transazioni e proprietà ACID
I database relazionali supportano transazioni—gruppi di operazioni che si comportano come un'unica unità. Le transazioni sono definite dalle proprietà ACID:
- Atomicità: tutte le operazioni hanno successo, o nessuna viene applicata.
- Consistenza: le transazioni portano il database da uno stato valido a un altro.
- Isolamento: transazioni concorrenti non si interferiscono a vicenda.
- Durabilità: una volta confermati, i dati sono memorizzati in modo sicuro.
Queste garanzie sono cruciali per sistemi finanziari, gestione inventario e qualsiasi applicazione dove la correttezza conta.
Database SQL comuni
Tra i sistemi relazionali più diffusi troviamo:
- MySQL e MariaDB
- PostgreSQL
- Microsoft SQL Server
- Oracle Database
Tutti implementano SQL, aggiungendo ciascuno estensioni e strumenti per amministrazione, tuning e sicurezza.
Che cos'è un database NoSQL (non relazionale)?
I database NoSQL sono store non relazionali che non usano il tradizionale modello tabella–riga–colonna dei sistemi SQL. Si concentrano su modelli di dati flessibili, scalabilità orizzontale e alta disponibilità, spesso a scapito di garanzie transazionali rigorose.
Modelli di dati flessibili
Molti database NoSQL sono descritti come schema‑less o schema‑flessibili. Invece di definire uno schema rigido in anticipo, puoi memorizzare record con campi o strutture diverse nella stessa collection o bucket.
Questo è particolarmente utile per:
- requisiti applicativi in evoluzione
- gestire dati semi‑strutturati (log, eventi, profili utenti)
- memorizzare dati nidificati come documenti JSON
Poiché i campi possono essere aggiunti o omessi per record, gli sviluppatori possono iterare rapidamente senza migrazioni per ogni cambiamento strutturale.
Principali tipi di NoSQL
NoSQL è un termine ombrello che copre diversi modelli:
- Document databases: memorizzano dati come documenti simili a JSON con campi nidificati. Esempi: MongoDB, Couchbase.
- Key–value stores: semplici mappe associative dove ogni chiave mappa un valore. Ottimi per caching e sessioni. Esempi: Redis, Amazon DynamoDB (modalità key–value).
- Column‑family stores: organizzano i dati per famiglie di colonne per alto throughput in scrittura e tabelle larghe. Esempi: Apache Cassandra, HBase.
- Graph databases: si concentrano su nodi e relazioni, ideali per dati altamente connessi. Esempi: Neo4j, Amazon Neptune.
Modelli di consistenza
Molti sistemi NoSQL privilegiano disponibilità e tolleranza alle partizioni, offrendo consistenza eventuale invece di transazioni ACID su tutto il dataset. Alcuni offrono livelli di consistenza configurabili o funzionalità transazionali limitate (per documento, partizione o range di chiavi), così puoi scegliere tra garanzie più forti e prestazioni maggiori per operazioni specifiche.
Modelli di dati: struttura, schemi e relazioni
La modellazione dei dati è dove SQL e NoSQL sembrano più diversi. Influisce su come progetti funzionalità, interroghi i dati e fai evolvere l'applicazione.
Struttura e schemi
I database SQL usano schemi strutturati e predefiniti. Progetti tabelle e colonne in anticipo, con tipi rigidi e vincoli:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Ogni riga deve rispettare lo schema. Cambiarlo in seguito richiede solitamente migrazioni (ALTER TABLE, backfill, ecc.).
I database NoSQL tipicamente supportano schemi flessibili. Un document store può permettere che ogni documento abbia campi diversi:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
I campi possono essere aggiunti per documento senza una migrazione centrale. Alcuni sistemi NoSQL offrono schemi opzionali o vincoli, ma in generale sono più larghi.
Normalizzazione vs denormalizzazione
I modelli relazionali incoraggiano la normalizzazione: dividere i dati in tabelle collegate per evitare duplicazioni e mantenere l'integrità. Ciò favorisce scritture coerenti e compatte, ma letture complesse possono richiedere join multipli.
I modelli NoSQL spesso favoriscono la denormalizzazione: incorporare i dati correlati insieme per le letture più frequenti. Questo migliora prestazioni di lettura e semplifica le query, ma le scritture possono diventare più lente o complesse perché la stessa informazione può trovarsi in più posti.
Modellare le relazioni
In SQL, le relazioni sono esplicite e imposte:
- One‑to‑many: foreign key (users → orders)
- Many‑to‑many: tabelle di join (users_roles)
In NoSQL, le relazioni si modellano con:
- Embedding (il documento utente contiene un array di ordini) per dati strettamente accoppiati
- Referencing (user_id dentro il documento ordine) per collezioni grandi o accessi indipendenti
La scelta dipende dai pattern di accesso:
- Se recuperi sempre un utente e i suoi 10 ordini più recenti insieme, l’embedding può essere ideale.
- Se gli ordini sono grandi, aggiornati frequentemente o acceduti separatamente, i riferimenti e query separate sono migliori.
Impatto sull’evoluzione dei requisiti
Con SQL, i cambi di schema richiedono più pianificazione ma garantiscono coerenza su tutto il dataset. Le rifattorizzazioni sono esplicite: migrazioni, backfill, aggiornamenti di vincoli.
Con NoSQL, i requisiti che evolvono sono spesso più facili da supportare nel breve termine. Puoi iniziare a memorizzare nuovi campi subito e aggiornare gradualmente i documenti vecchi. Il compromesso è che il codice applicativo deve gestire più forme di documento e casi limite.
Scegliere tra modelli normalizzati (SQL) e denormalizzati (NoSQL) non è una questione di “meglio” ma di allineare la struttura dei dati ai pattern di query, al volume di scrittura e alla frequenza di cambiamento del modello del dominio.
Linguaggi di query e pattern di accesso
SQL: dichiarativo e standardizzato
I database SQL si interrogano con un linguaggio dichiarativo: descrivi cosa vuoi, non come recuperarlo. Costrutti come SELECT, WHERE, JOIN, GROUP BY e ORDER BY permettono di esprimere query complesse su più tabelle in una singola istruzione.
Perché SQL è standard (ANSI/ISO), molti sistemi relazionali condividono una sintassi di base comune. I vendor aggiungono estensioni, ma competenze e query spesso si trasferiscono bene tra PostgreSQL, MySQL, SQL Server e altri.
Questa standardizzazione porta un ricco ecosistema: ORM, query builder, tool di reporting, BI, framework di migrazione e ottimizzatori di query. Puoi integrare molti di questi strumenti con pochi cambi, riducendo il lock‑in e accelerando lo sviluppo.
NoSQL: API di query e pattern
I sistemi NoSQL espongono query in modi più vari:
- Document stores (MongoDB, Couchbase) usano oggetti di query simili a JSON e talvolta linguaggi di query proprietari.
- Key‑value stores (Redis, API in stile DynamoDB) puntano a lookup per chiave primaria e pochi accessi tramite indici secondari.
- Wide‑column stores (Cassandra, HBase) ottimizzano per query che seguono chiavi primarie e chiavi di clustering predefinite.
- Motori di ricerca (Elasticsearch, Solr) offrono DSL per full‑text e query per rilevanza.
Alcuni NoSQL forniscono pipeline di aggregazione o meccanismi tipo MapReduce per analytics, ma join cross‑collection o cross‑partition sono limitati o assenti. Invece, i dati correlati vengono spesso incorporati nello stesso documento o denormalizzati.
Pattern di accesso e produttività
Le query relazionali spesso si basano su pattern con molti JOIN: normalizzi i dati e poi ricostruisci entità al momento della lettura. Questo è potente per reporting ad‑hoc, ma i join complessi possono essere più difficili da ottimizzare.
Gli accessi NoSQL tendono ad essere document‑ o key‑centric: progetti i dati attorno alle query più frequenti dell'applicazione. Le letture sono veloci e semplici—spesso un singolo lookup per chiave—ma cambiare i pattern di accesso richiederà di rimodellare i dati.
Per apprendimento e produttività:
- Il modello dichiarativo di SQL e l'abbondanza di risorse lo rendono accessibile e durevole come competenza.
- Le query NoSQL possono essere più semplici per pattern prevedibili, ma ogni sistema ha sintassi e limiti propri, quindi le competenze sono meno portabili.
I team che necessitano di query ad‑hoc ricche e traversamenti di relazioni tendono a preferire SQL. I team con pattern stabili e altissima scala trovano spesso i modelli NoSQL più adatti.
Consistenza, transazioni e i trade‑off del CAP
ACID: garanzie forti nei sistemi SQL
La maggior parte dei database SQL è progettata attorno alle transazioni ACID:
- Atomicità: una transazione riesce completamente o fallisce.
- Consistenza: ogni transazione porta il dato da uno stato valido a un altro, applicando i vincoli.
- Isolamento: le transazioni concorrenti non interferiscono (con livelli come READ COMMITTED, REPEATABLE READ, SERIALIZABLE).
- Durabilità: una volta confermata, la scrittura sopravvive a crash.
Questo rende i database relazionali ideali quando la correttezza è più importante del puro throughput di scrittura.
BASE e consistenza eventuale in molti sistemi NoSQL
Molti database NoSQL tendono verso le proprietà BASE:
- Basically Available: il sistema cerca di rimanere operativo e rispondere.
- Soft state: lo stato può essere temporaneamente incoerente tra repliche.
- Eventual consistency: se non arrivano nuovi aggiornamenti, tutte le repliche convergono.
Le scritture possono essere molto veloci e distribuite, ma una lettura potrebbe vedere dati obsoleti per un breve periodo.
Teorema CAP nella pratica
Il CAP afferma che in un sistema distribuito soggetto a partizioni di rete bisogna scegliere tra:
- Consistency (C): tutti i client vedono gli stessi dati allo stesso tempo.
- Availability (A): ogni richiesta riceve una risposta.
Non puoi garantire entrambi C e A durante una partizione.
Pattern tipici:
- Molte installazioni SQL privilegiano forte consistenza: utile per pagamenti, inventario, saldi contabili, prenotazioni e ogni workflow dove una lettura stale può causare perdite o violazioni.
- Molti setup NoSQL privilegiano disponibilità e consistenza eventuale: adatti per analytics, feed social, cataloghi prodotti, log, caching, dove inconsistenze temporanee sono tollerabili e velocità/disponibilità sono prioritarie.
Sistemi moderni spesso mescolano modalità (es. consistenza configurabile per operazione) così che parti diverse dell’app possano scegliere le garanzie necessarie.
Differenze di scalabilità e prestazioni
Come scalano normalmente i database SQL
I database SQL tradizionali sono pensati per un singolo nodo potente.
Si scala solitamente verticalmente: più CPU, RAM e dischi veloci su un server. Molti motori supportano anche repliche di lettura: nodi aggiuntivi che rispondono solo a richieste in sola lettura mentre tutte le scritture vanno al primario. Questo va bene per:
- volume di scrittura moderato
- query analitiche/reporting pesanti
- carichi dove la forte consistenza è cruciale
Tuttavia, lo scaling verticale ha limiti hardware e di costo, e le repliche possono introdurre lag di replica per le letture.
NoSQL e scaling orizzontale
I sistemi NoSQL sono di solito costruiti per lo scaling orizzontale: distribuire i dati su molti nodi usando sharding o partizionamento. Ogni shard contiene un sottoinsieme dei dati, così letture e scritture possono essere distribuite, aumentando il throughput.
Questo è adatto a:
- carichi massivi scrittura‑intensivi
- dataset molto grandi che eccedono lo storage di una singola macchina
- applicazioni globali che vogliono dati vicini agli utenti
Il compromesso è una maggiore complessità operativa: scegliere chiavi di shard, gestire rebalancing e query cross‑shard.
Pattern di prestazioni e indicizzazione
Per carichi read‑heavy con join e aggregazioni complesse, un database SQL con indici ben progettati può essere estremamente veloce, perché l'ottimizzatore usa statistiche e piani di esecuzione.
Molti sistemi NoSQL privilegiano pattern di accesso semplici basati su chiave. Eccellono in lookup a bassa latenza e alto throughput quando le query sono prevedibili e i dati modellati attorno a questi pattern.
La latenza in cluster NoSQL può essere molto bassa, ma query cross‑partition, indici secondari e operazioni multi‑documento possono essere più lente o limitate. Operativamente, scalare NoSQL significa più gestione del cluster, mentre scalare SQL spesso implica più hardware e attenta indicizzazione su pochi nodi.
Quando scegliere un database SQL
Carichi transazionali e business‑critical
I database relazionali brillano quando servono transazioni OLTP affidabili e numerose:
- sistemi finanziari (pagamenti, contabilità, trading)
- gestione ordini e inventario
- ERP, CRM e piattaforme di billing
Questi sistemi si appoggiano a transazioni ACID, forte consistenza e rollback chiaro. Se un trasferimento non deve mai doppiare addebiti o perdere fondi, un database SQL è generalmente più sicuro di molte opzioni NoSQL.
Dati strutturati e relazioni complesse
Quando il modello dei dati è stabile e le entità sono fortemente correlate, un database relazionale è spesso la scelta naturale. Esempi:
- clienti, ordini, fatture, prodotti, spedizioni
- cartelle cliniche con pazienti, visite, prescrizioni, esami
Gli schemi normalizzati, le foreign key e i join di SQL rendono più semplice applicare integrità e interrogare relazioni complesse senza duplicare i dati.
Analisi su schemi ben definiti
Per reporting e BI su dati strutturati (star/snowflake schema, data mart), i database SQL e i data warehouse compatibili con SQL sono generalmente preferiti. I team di analisi conoscono SQL e gli strumenti esistenti si integrano direttamente con i sistemi relazionali.
Maturità, competenze e compliance
Il dibattito spesso ignora la maturità operativa. I database SQL offrono:
- affidabilità e tool consolidati
- un ampio bacino di ingegneri, DBA e analisti esperti in SQL
- funzionalità per auditing, controllo accessi, cifratura e backup che soddisfano normative rigorose
Quando audit, certificazioni o esposizione legale sono rilevanti, un database SQL è spesso la scelta più semplice e difendibile nel confronto SQL vs NoSQL.
Quando scegliere un database NoSQL
I database NoSQL sono spesso la scelta giusta quando scalabilità, flessibilità e disponibilità sono più importanti di join complessi e garanzie transazionali rigorose.
Sistemi ad alto traffico e su larga scala
Se prevedi volumi massicci di scritture, picchi imprevedibili o dataset che crescono in terabyte, i sistemi NoSQL (key‑value o wide‑column) sono spesso più semplici da scalare orizzontalmente. Sharding e replica sono frequentemente integrati, permettendo di aumentare la capacità aggiungendo nodi.
Tipici casi d'uso:
- applicazioni web e mobile ad alto traffico
- backend per gaming e leaderboard real‑time
- ad tech, motori di raccomandazione e servizi di personalizzazione
Flessibilità durante iterazioni rapide
Quando il modello dei dati cambia spesso, un design flessibile è prezioso. I document database permettono di evolvere campi e strutture senza migrazioni per ogni cambiamento.
Adatto per:
- CMS e cataloghi prodotti
- profili utente e preferenze
- activity feed e log d'evento, dove emergono nuovi tipi di evento
IoT, caching e serie temporali
I store NoSQL sono forti anche per carichi append‑heavy e ordinati nel tempo:
- telemetry IoT e sensori
- metriche, logging e monitoring
- layer di caching per dati letti frequentemente (sessioni, token, feature flags)
Key‑value e time‑series database sono ottimizzati per scritture molto veloci e letture semplici.
Distribuzione globale e disponibilità continua
Molte piattaforme NoSQL privilegiano geo‑replica e scritture multi‑regione, permettendo agli utenti globali di leggere e scrivere con bassa latenza. Questo è utile quando:
- l'app deve rimanere disponibile durante outage regionali
- utenti in diversi continenti richiedono tempi di risposta locali
Il compromesso è spesso accettare consistenza eventuale invece di ACID forte tra regioni.
Limiti e compromessi
Scegliere NoSQL spesso significa rinunciare ad alcune funzionalità di SQL:
- consistenza più debole o configurabile; non tutte le letture vedono l'ultima scrittura
- query ad‑hoc e join limitati; devi progettare le query in anticipo
- maggiore responsabilità nell'applicazione per far rispettare alcune regole di integrità
Quando questi compromessi sono accettabili, NoSQL offre migliore scalabilità, flessibilità e portata globale rispetto a un database relazionale tradizionale.
Pattern ibridi e polyglot persistence
La polyglot persistence significa usare intenzionalmente più tecnologie di database nello stesso sistema, scegliendo lo strumento migliore per ogni compito invece di forzare tutto in un unico store.
Setup ibrido tipico
Un pattern comune è:
- SQL per i dati core: ordini, pagamenti, profili utente, configurazione. Qui serve forte consistenza, transazioni e query ricche.
- NoSQL per sessioni e caching: un key‑value store per sessioni utente, rate limit, flag di feature o aggregati caldi; a volte un document store per preferenze o feed.
Questo mantiene il “sistema di record” in un database relazionale, scaricando carichi volatili o di sola lettura su NoSQL.
Combinare diversi tipi di NoSQL
Puoi anche combinare sistemi NoSQL:
- Key‑value per cache e sessioni.
- Document per contenuti o dati generati dagli utenti con schemi flessibili.
- Wide‑column o time‑series per metriche e log di eventi.
- Motore di ricerca per full‑text e query analitiche.
L'obiettivo è allineare ogni datastore a un pattern di accesso specifico: lookup semplici, aggregati, ricerca o letture temporali.
Costi di integrazione e operatività
Le architetture ibride richiedono integrazione:
- ETL o streaming per sincronizzare store o costruire read models.
- Event streaming per propagare cambiamenti (es. da SQL a cache o analytics).
- API che nascondono i database sottostanti così i servizi non devono sapere dove risiedono i dati.
Il compromesso è sovraccarico operativo: più tecnologie da imparare, monitorare, mettere in sicurezza, backuppare e debuggare. La polyglot persistence funziona meglio quando ogni datastore risolve un problema reale e misurabile, non solo perché è alla moda.
Come scegliere tra SQL e NoSQL per un progetto
Scegliere è questione di far combaciare i tuoi dati e i pattern di accesso con lo strumento giusto, non seguire la moda.
1. Parti dai tuoi dati e dalle relazioni
Chiedi:
- I miei dati sono tabellari con entità chiare (utenti, ordini, fatture)?
- Ho molti join e relazioni ricche (1‑to‑many, many‑to‑many)?
Se sì, un database relazionale è solitamente la scelta predefinita. Se i dati sono simili a documenti, nidificati o variano molto da record a record, un modello documentale o altro NoSQL potrebbe essere più adatto.
2. Chiarisci esigenze di consistenza e transazioni
- Ho bisogno di transazioni ACID multi‑riga o multi‑tabella per correttezza (es. pagamenti, inventario)?
- È accettabile che alcune letture siano leggermente stale?
La forte consistenza e transazioni complesse favoriscono SQL. Elevato throughput di scrittura con consistenza rilassata può favorire NoSQL.
3. Capisci scala e prestazioni
- Quali volumi di lettura/scrittura oggi? Tra 2–3 anni?
- Ho bisogno di bassa latenza in più regioni?
Molti progetti scalano bene con SQL usando indicizzazione e hardware adeguato. Se prevedi scala enorme con pattern semplici (lookup per chiave, serie temporali), certi sistemi NoSQL possono essere più economici.
4. Pattern di query e reporting
- Avrò bisogno di analytics ad‑hoc, join e reporting flessibile?
- Chi interrogherà i dati (solo ingegneri o anche analisti/business)?
SQL è ideale per query complesse, strumenti BI e esplorazione ad‑hoc. Molti NoSQL sono ottimizzati per percorsi di accesso predefiniti e rendono più difficile l'emergere di nuovi tipi di query.
5. Competenze del team, tool e hosting
- Cosa sa già fare il team: SQL, design di schemi o specifici sistemi NoSQL?
- Cosa offre il tuo hosting (PostgreSQL/MySQL gestiti, MongoDB gestito, DynamoDB, ecc.)?
- Quale ecosistema ha migliori librerie, driver e monitoraggio per il tuo stack?
Favorisci tecnologie che il tuo team può gestire con sicurezza, specialmente per troubleshooting in produzione e migrazioni.
6. Costi e complessità operativa
- Possiamo permetterci di gestire cluster NoSQL distribuiti, o un'istanza SQL gestita copre i bisogni?
- Come si confrontano costi di storage e read/write per il carico previsto?
Un singolo database SQL gestito spesso è più economico e semplice finché non lo superi chiaramente.
7. Testa con carichi realistici
Prima di prendere una decisione:
- Modella un sottoinsieme rappresentativo dei dati in uno schema SQL e in un candidato modello NoSQL.
- Implementa alcune query e scritture critiche.
- Esegui test di carico con volumi e pattern realistici.
- Misura latenza, throughput, tassi di errore e sforzo operativo.
Usa quei dati—non le supposizioni—per scegliere. Per molti progetti, partire con SQL è la strada più sicura, con la possibilità di introdurre componenti NoSQL in seguito per casi molto specifici o ad alta scala.
Miti comuni su SQL e NoSQL
Mito 1: NoSQL sostituirà SQL
NoSQL non è arrivato per sostituire i database relazionali, ma per completarli.
I database relazionali dominano ancora i sistemi di record: finanza, HR, ERP, inventario e qualsiasi workflow dove consistenza e transazioni ricche contano. NoSQL eccelle dove schemi flessibili, alto throughput di scrittura o letture globali sono più importanti dei join complessi e delle garanzie ACID.
La maggior parte delle organizzazioni usa entrambi, scegliendo lo strumento giusto per ogni carico.
Mito 2: SQL non scala orizzontalmente
I database relazionali storicamente scalano verticalmente, ma i motori moderni supportano:
- repliche di lettura
- sharding/partitioning
- SQL distribuito (sistemi NewSQL)
Scalare un sistema relazionale può essere più coinvolto rispetto ad aggiungere nodi a un cluster NoSQL, ma la scalabilità orizzontale è possibile con il giusto design e tooling.
Mito 3: NoSQL non ha schemi o regole
“Schema‑less” significa spesso “lo schema è applicato dall'applicazione, non dal database.”
I document, key–value e wide‑column store hanno comunque struttura. Permettono però che questa struttura evolva per record o collection. Senza contratti di dati chiari e validazione, però, si arriva rapidamente a dati inconsistenti.
Mito 4: Un tipo è sempre più veloce
Le prestazioni dipendono molto più dalla modellazione dei dati, dall'indicizzazione e dai pattern di accesso che dalla categoria “SQL vs NoSQL.”
Una collezione NoSQL senza indici adeguati sarà più lenta di una tabella relazionale ben ottimizzata per molte query. Allo stesso modo, uno schema relazionale che ignora i pattern di query sarà sottoperformante rispetto a un modello NoSQL progettato per quelle query.
Mito 5: SQL è sempre più sicuro o affidabile di NoSQL
Molti database NoSQL offrono durabilità, cifratura, auditing e controllo accessi. Un database relazionale mal configurato può essere insicuro e fragile.
Sicurezza e affidabilità sono proprietà del prodotto specifico, del deployment, della configurazione e della maturità operativa—non della categoria “SQL” o “NoSQL.”
Migrazione e strategie di coesistenza
I team cambiano tra SQL e NoSQL per due ragioni principali: scalabilità e flessibilità. Un prodotto ad alto traffico spesso mantiene il database relazionale come sistema di record, poi introduce NoSQL per gestire letture a scala o per nuove funzionalità con schemi più flessibili.
Pattern di migrazione
Una migrazione big‑bang è rischiosa. Opzioni più sicure:
- Migrazione incrementale: estrai un bounded context (es. catalogo prodotti) e sposta solo quei dati e traffico a NoSQL, mantenendo il resto su SQL.
- Dual writes: per un periodo, i servizi scrivono sia su SQL che su NoSQL. Quando il nuovo store è provato, ritiri gradualmente il vecchio percorso.
- Sync pipelines: mantieni un database primario e streamma i dati all'altro usando CDC, code di messaggi o job ETL.
Insidie di schema e modello
Passare da SQL a NoSQL spinge spesso a replicare tabelle come documenti o key‑value. Questo porta a:
- dati NoSQL troppo normalizzati con troppi join a livello applicativo
- documenti che crescono senza controllo
Progetta prima i nuovi pattern di accesso, poi crea lo schema NoSQL attorno alle query reali.
Coesistenza e reti di sicurezza
Un pattern comune è SQL per i dati autoritativi (billing, account) e NoSQL per viste read‑heavy (feed, ricerca, caching). Indipendentemente dalla scelta, investi in:
- backfill ripetibili e rollback
- validazione dei dati tra store
- test di carico che riflettano pattern reali di query
Questo mantiene le migrazioni controllate invece che dolorose e irreversibili.
Riepilogo e raccomandazioni pratiche
SQL e NoSQL differiscono principalmente in quattro aree:
- Modello di dati – SQL usa tabelle, righe e schemi ben definiti; NoSQL favorisce documenti, chiave‑valore, wide‑column o grafi con struttura più flessibile.
- Query – SQL offre un linguaggio unico ed espressivo; NoSQL usa API o sintassi specifiche per ciascun database.
- Consistenza & transazioni – SQL ruota attorno ad ACID e forte consistenza; molti NoSQL scambiano garanzie per disponibilità, scala o latenza.
- Scalabilità – SQL tradizionalmente scala verticalmente (e sempre più orizzontalmente con clustering); NoSQL è spesso pensato per shard e replica su molti nodi.
Nessuna categoria è universalmente migliore. La scelta «giusta» dipende dai tuoi requisiti reali, non dalle mode.
Come scegliere nella pratica
-
Scrivi i tuoi bisogni:
- Struttura e relazioni dei dati
- Pattern di query e reporting
- Aspettative su consistenza vs disponibilità
- Picchi di traffico, volumi dati e obiettivi di latenza
- Competenze operative e tooling del team
-
Default sensato:
- Preferisci SQL per sistemi transazionali, analisi e dati aziendali strutturati.
- Considera NoSQL per carichi ad alta scrittura, scala molto ampia o dati semi‑strutturati.
-
Inizia in piccolo e misura:
- Costruisci un proof‑of‑concept verticale.
- Raccogli metriche: latenza delle query, throughput, errori, sforzo operativo.
- Itera su schema, indici e partizionamento in base all'uso reale.
-
Rimani aperto agli ibridi:
- Usa più database se parti diverse del sistema hanno bisogni diversi.
- Documenta decisioni, compromessi e pattern nel tuo knowledge base (ad esempio sotto
/docs/architecture/datastores).
Per approfondire, estendi questa panoramica con standard interni, checklist di migrazione e letture aggiuntive nel tuo handbook ingegneristico o nel tuo /blog.
Domande frequenti
Qual è la differenza principale tra database SQL e NoSQL?
SQL (relazionale) databases:
- Usano tabelle con righe e colonne.
- Impongono uno schema fisso (colonne, tipi, vincoli).
- Si interrogano con SQL, un linguaggio standardizzato.
- Puntano su transazioni ACID e forte consistenza.
NoSQL (non‑relazionale) databases:
- Usano modelli flessibili (documenti, chiave‑valore, wide‑column, grafi).
- Spesso permettono dati schema‑flessibili o schema‑adattabili.
- Usano API di query o DSL specifici del database.
- Spesso scambiano alcune garanzie di consistenza per scalabilità e disponibilità.
Quando è preferibile un database SQL?
Usa un database SQL quando:
- I tuoi dati sono ben strutturati e relazionali (utenti, ordini, fatture).
- Hai bisogno di transazioni ACID su più righe o tabelle.
- Correttezza e consistenza sono più importanti della pura velocità.
- Prevedi molte query ad‑hoc, join e necessità di reportistica.
- Compliance, auditing e manutenzione a lungo termine sono critici.
Per la maggior parte dei nuovi sistemi di record aziendali, SQL è un buon default.
Quando è preferibile un database NoSQL?
NoSQL è adatto quando:
- Devi scalare scritture e storage orizzontalmente su molti nodi.
- I tuoi dati sono semi‑strutturati, nidificati o cambiano spesso forma.
- I pattern di accesso sono noti e possono essere modellati su lookup per chiave o documento.
- Piccole inconsistenze temporanee sono accettabili (feed, log, viste analitiche).
- Gestisci telemetry IoT, serie temporali, caching o contenuti generati dagli utenti su larga scala.
In che modo differiscono schemi e modellazione dei dati tra SQL e NoSQL?
Database SQL:
- Usano schemi predefiniti; ogni riga deve rispettare la definizione della tabella.
- Incoraggiano la normalizzazione per ridurre duplicazioni e far rispettare i vincoli.
- Impiegano chiavi esterne e vincoli per gestire le relazioni.
NoSQL:
- Permettono che documenti/record abbiano campi diversi nella stessa raccolta.
- Spesso favoriscono la denormalizzazione e l'embedding dei dati correlati.
- Delegano all'applicazione gran parte del controllo delle regole sui dati.
In pratica il controllo dello schema passa dal database (SQL) all'applicazione (NoSQL).
Come differiscono SQL e NoSQL in termini di consistenza e transazioni?
Database SQL:
- Ruotano attorno a transazioni ACID con forte consistenza.
- Sono ideali quando ogni lettura deve vedere uno stato valido e aggiornato.
Molti sistemi NoSQL:
- Privilegiano disponibilità e tolleranza alle partizioni.
- Seguono le proprietà BASE e consistenza eventuale: le repliche convergono nel tempo.
- Possono offrire livelli di consistenza configurabili per operazione o partizione.
Scegli SQL quando le letture stale sono pericolose; scegli NoSQL quando una breve staleness è accettabile in cambio di scalabilità e uptime.
Come scalano tipicamente SQL e NoSQL?
I database SQL tipicamente:
- Partono da scaling verticale (server più potenti).
- Aggiungono repliche di lettura per scalare le letture.
- Possono usare sharding o prodotti SQL distribuiti per lo scale‑out.
I database NoSQL tipicamente:
- Sono progettati fin dall'inizio per lo scaling orizzontale.
- Shardano o partizionano i dati su molti nodi.
- Rendono più semplice aumentare la capacità aggiungendo server commodity.
Il compromesso è che i cluster NoSQL sono operativamente più complessi, mentre SQL può raggiungere prima i limiti di un singolo nodo.
Posso usare SQL e NoSQL insieme nello stesso sistema?
Sì. La polyglot persistence è comune:
- Usa SQL come sistema di record autoritativo (pagamenti, account, entità core).
- Aggiungi NoSQL per sessioni, cache, feed, log o ricerca.
Pattern di integrazione includono:
- Change data capture o stream dagli SQL verso NoSQL.
- Job ETL periodici per costruire viste ottimizzate in lettura.
- Servizi che nascondono i datastore sottostanti dietro API stabili.
La regola è aggiungere ogni datastore solo quando risolve un problema chiaro.
Come devo approcciare una migrazione tra SQL e NoSQL?
Per muoversi gradualmente e in sicurezza:
- Identifica un bounded context (es. catalogo prodotti) da migrare.
- Modella i dati attorno ai nuovi pattern di accesso, non tabella per tabella.
- Usa dual writes o CDC per mantenere sincronizzati vecchio e nuovo store temporaneamente.
- Valida i dati tra gli store e pianifica backfill ripetibili.
- Sposta il traffico incrementando la produzione con rollback pronti.
Evita migrazioni big‑bang; preferisci passi incrementali e ben monitorati.
Quali fattori dovrei valutare quando scelgo tra SQL e NoSQL?
Valuta:
- Struttura dei dati: tabellare con relazioni chiare vs documenti/eventi flessibili.
- Bisogni di consistenza: ACID rigoroso vs staleness accettabile.
- Scala e latenza: volume di scritture previsto, dimensione dei dati, utenti globali.
- Pattern di query: join e analytics ad‑hoc vs lookup prevedibili per chiave/documento.
- Competenze del team: cosa sapete gestire con sicurezza.
- Costi e operazioni: soluzioni gestite vs cluster distribuiti.
Prototipa entrambe le opzioni per i flussi critici e misura latenza, throughput e complessità prima di decidere.
Quali sono i miti comuni su SQL vs NoSQL?
Falsi miti comuni:
- “NoSQL sostituirà SQL” – nella pratica si completano a vicenda.
- “SQL non può scalare orizzontalmente” – i sistemi moderni supportano repliche, sharding e SQL distribuito.
- “NoSQL non ha schemi” – lo schema esiste, ma spesso è applicato a livello applicazione o tramite validatori.
- “Un tipo è sempre più veloce” – le prestazioni dipendono soprattutto da modellazione, indicizzazione e carico di lavoro.
Valuta prodotti e architetture specifiche anziché basarti sui miti di categoria.