06 mag 2025·8 min
Store chiave-valore per cache, sessioni e ricerche veloci
Scopri come gli store chiave-valore abilitano caching, sessioni utente e ricerche istantanee—più TTL, eviction, opzioni di scaling e i compromessi pratici da considerare.
Scopri come gli store chiave-valore abilitano caching, sessioni utente e ricerche istantanee—più TTL, eviction, opzioni di scaling e i compromessi pratici da considerare.
L'obiettivo principale di uno store chiave-valore è semplice: ridurre la latenza per gli utenti finali e il carico sul database primario. Invece di eseguire la stessa query costosa o ricalcolare lo stesso risultato, la tua app può recuperare un valore precomputato in un singolo, prevedibile passaggio.
Uno store chiave-valore è ottimizzato attorno a un'operazione: “dato questo key, restituisci il value.” Questo focus ristretto abilita un percorso critico molto corto.
In molti sistemi, una lookup può spesso essere gestita con:
Il risultato sono tempi di risposta bassi e coerenti—esattamente ciò che serve per caching, archiviazione sessioni e altre ricerche ad alta velocità.
Anche se il tuo database è ben ottimizzato, deve comunque parsare le query, pianificarle, leggere indici e coordinare la concorrenza. Se migliaia di richieste chiedono la stessa lista “top products”, quel lavoro ripetuto si somma.
Una cache key-value sposta quel traffico di letture ripetute via dal database. Il database può concentrarsi su richieste che lo richiedono davvero: scritture, join complessi, reporting e letture critiche per la consistenza.
La velocità non è gratis. Gli store chiave-valore in genere sacrificano query ricche (filtri, join) e possono avere garanzie diverse su persistenza e consistenza a seconda della configurazione.
Brillano quando puoi nominare il dato con una chiave chiara (per esempio, user:123, cart:abc) e vuoi un recupero rapido. Se devi spesso fare “trova tutti gli elementi dove X”, un database relazionale o documentale è di solito una scelta migliore come store primario.
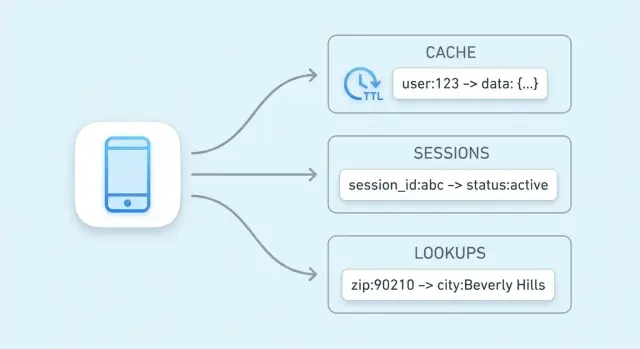
Uno store chiave-valore è il tipo più semplice di database: memorizzi un valore (alcuni dati) sotto una chiave unica (un'etichetta) e poi recuperi il valore fornendo la chiave.
Pensa a una chiave come a un identificatore che è facile ripetere esattamente, e a un valore come a ciò che vuoi ottenere.
Le chiavi sono solitamente stringhe corte (come user:1234 o session:9f2a...). I valori possono essere piccoli (un contatore) o più grandi (un blob JSON).
Gli store chiave-valore sono costruiti per query “dammi il valore per questa chiave”. Internamente, molti usano una struttura simile a una hash table: la chiave viene trasformata in una posizione dove il valore si trova velocemente.
Per questo si parla spesso di lookup a tempo costante (spesso scritto O(1)): le prestazioni dipendono molto più da quante richieste fai che da quanti record totali esistono. Non è magia—collisioni e limiti di memoria contano ancora—ma per uso tipico di cache/sessioni è molto veloce.
Dati hot è la piccola porzione di informazioni richieste ripetutamente (pagine prodotto popolari, sessioni attive, contatori di rate-limit). Tenere i dati hot in uno store chiave-valore—soprattutto in memoria—evita query più lente al database e mantiene i tempi di risposta prevedibili sotto carico.
Caching significa conservare una copia di dati usati frequentemente in un posto più veloce della fonte originale. Uno store chiave-valore è un luogo comune per farlo perché restituisce un valore con una singola lookup per chiave, spesso in pochi millisecondi.
Il caching è utile quando le stesse domande vengono fatte ripetutamente: pagine popolari, ricerche ripetute, chiamate API comuni o calcoli costosi. È anche utile quando la fonte “reale” è più lenta o soggetta a limiti—come un database primario sotto carico o un'API di terze parti a pagamento.
Candidati ideali sono risultati letti spesso e che non devono essere perfettamente aggiornati all'istante:
Una regola semplice: memorizza output che puoi rigenerare se necessario. Evita di mettere in cache dati che cambiano costantemente o che devono essere consistenti su tutte le letture (per esempio, un saldo bancario).
Senza cache, ogni vista pagina potrebbe scatenare molte query al database o chiamate API. Con una cache, l'applicazione può servire molte richieste dallo store key-value e “fallback” al database o all'API solo su cache miss. Questo riduce il volume di query, la contesa sulle connessioni e può migliorare l'affidabilità durante picchi di traffico.
Il caching scambia freschezza per velocità. Se i valori in cache non vengono aggiornati rapidamente, gli utenti possono vedere informazioni stale. Nei sistemi distribuiti, due richieste possono temporaneamente leggere versioni diverse dello stesso dato.
Gestisci questi rischi scegliendo TTL appropriati, decidendo quali dati possono essere “leggermente vecchi” e progettando l'applicazione per tollerare cache miss occasionali o ritardi di refresh.
Un “pattern” di cache è un flusso ripetibile su come la tua app legge e scrive dati quando è coinvolta una cache. Scegliere quello giusto dipende meno dal tool (Redis, Memcached, ecc.) e più da quanto spesso i dati sottostanti cambiano e da quanta stale data puoi tollerare.
Con cache-aside, l'applicazione controlla la cache esplicitamente:
Adatto a: dati letti spesso ma che cambiano raramente (pagine prodotto, configurazioni, profili pubblici). È anche un buon default perché i guasti degradano in modo elegante: se la cache è vuota, puoi comunque leggere dal database.
Read-through significa che il livello cache recupera dal database in caso di miss (la tua app legge “dalla cache” e la cache sa come caricare). Operativamente semplifica il codice applicativo, ma aggiunge complessità al livello cache (serve un loader integrato).
Write-through significa che ogni scrittura va sincronamente sia nella cache che nel database. Le letture sono generalmente veloci e coerenti, ma le scritture sono più lente perché devono completare due operazioni.
Adatto a: dati per cui vuoi meno miss e letture più coerenti (impostazioni utente, feature flag), quando la latenza di scrittura è accettabile.
Con write-back, l'app scrive prima nella cache e la cache flusha i cambi al database in seguito (spesso in batch).
Vantaggi: scritture molto veloci e minore carico sul database.
Rischio aggiunto: se il nodo cache fallisce prima del flush, puoi perdere dati. Usalo solo quando puoi tollerare perdite o hai meccanismi di durabilità forti.
Se i dati cambiano raramente, cache-aside con un TTL sensato di solito basta. Se i dati cambiano frequentemente e le letture stale sono problematiche, considera write-through (o TTL molto brevi più invalidazione esplicita). Se il volume di scritture è estremamente elevato e la perdita occasionale è accettabile, write-behind può valere il compromesso.
Mantenere i dati in cache “abbastanza freschi” riguarda soprattutto la scelta della giusta strategia di scadenza per ogni chiave. L'obiettivo non è accuratezza perfetta, ma evitare che risultati obsoleti sorprendano gli utenti mantenendo i benefici di velocità.
Un TTL imposta una scadenza automatica su una chiave così che scompaia (o diventi indisponibile) dopo una durata. TTL corti riducono la stalezza ma aumentano i miss e il carico backend. TTL lunghi migliorano l'hit rate ma rischiano di servire valori datati.
Un modo pratico per scegliere TTL:
Il TTL è passivo. Quando sai che un dato è cambiato, spesso è preferibile invalidare attivamente: cancellare la chiave vecchia o scrivere immediatamente il nuovo valore.
Esempio: dopo che un utente aggiorna la sua email, cancella user:123:profile o aggiornala subito nella cache. L'invalidazione attiva riduce le finestre di stalezza ma richiede che l'app esegua in modo affidabile questi aggiornamenti alla cache.
Invece di cancellare chiavi vecchie, includi una versione nel nome della chiave, come product:987:v42. Quando il prodotto cambia, aumenta la versione e inizia a leggere/scrivere v43. Le versioni vecchie scadranno naturalmente dopo un po'. Questo evita race in cui un server cancella una chiave mentre un altro la sta scrivendo.
Uno stampede avviene quando una chiave popolare scade e molte richieste la ricreano simultaneamente.
Soluzioni comuni includono:
I dati di sessione sono il piccolo pacchetto di informazioni che la tua app necessita per riconoscere un browser o un client mobile di ritorno. Al minimo, è un session ID (o token) che mappa a uno stato lato server. A seconda del prodotto, può includere anche stato utente (flag di login, ruoli, nonce CSRF), preferenze temporanee e dati sensibili al tempo come il contenuto del carrello.
Gli store chiave-valore sono una corrispondenza naturale perché le letture e scritture di sessione sono semplici: cerca un token, prendi un valore, aggiornalo e imposta una scadenza. Rendono anche facile applicare TTL così le sessioni inattive spariscono automaticamente, mantenendo lo storage pulito e riducendo il rischio in caso di furto di token.
Un flusso comune:
Usa chiavi chiare e scope e mantieni i valori piccoli:
sess:<token> o sess:v2:<token> (la versioning aiuta i cambi futuri).user_sess:<userId> -> <token> per far rispettare “una sola sessione attiva per utente” o per revocare le sessioni per utente.Il logout dovrebbe cancellare la chiave di sessione e gli indici correlati (come user_sess:<userId>). Per la rotazione (raccomandata dopo login, cambi di privilegi o periodicamente), crea un nuovo token, scrivi la nuova sessione e poi elimina la vecchia chiave. Questo restringe la finestra in cui un token rubato resta utile.
Il caching è l'uso più comune di uno store chiave-valore, ma non è l'unico modo in cui può velocizzare il sistema. Molte applicazioni si affidano a letture rapide per piccoli pezzi di stato frequentemente referenziati—cose “adiacenti alla sorgente di verità” che devono essere verificate rapidamente quasi ad ogni richiesta.
I controlli di autorizzazione spesso stanno sul percorso critico: ogni chiamata API può dover rispondere a “questo utente può farlo?”. Tirare i permessi da un database relazionale ad ogni richiesta può aggiungere latenza e carico.
Uno store chiave-valore può contenere dati di autorizzazione compatti per lookup rapidi, per esempio:
perm:user:123 → una lista/set di codici permessoentitlement:org:45 → feature del piano abilitateQuesto è particolarmente utile quando il modello di permessi è molto in lettura e cambia relativamente poco. Quando i permessi cambiano (aggiornamenti di ruolo, upgrade di piano), puoi aggiornare o invalidare un piccolo set di chiavi così la richiesta successiva rispecchia le nuove regole di accesso.
I feature flag sono valori piccoli, letti frequentemente, che devono essere disponibili rapidamente e coerentemente tra molti servizi.
Un pattern comune è memorizzare:
flag:new-checkout → true/falseconfig:tax:region:EU → blob JSON o configurazione versionataGli store chiave-valore funzionano bene perché le letture sono semplici, prevedibili e molto veloci. Puoi anche versionare i valori (ad esempio config:v27:...) per rendere i rollout più sicuri e permettere rollback rapidi.
Il rate limiting spesso si riduce a contatori per utente, chiave API o IP. Gli store supportano operazioni atomiche, che permettono di incrementare un contatore in modo sicuro anche quando molte richieste arrivano contemporaneamente.
Potresti tracciare:
rl:user:123:minute → incrementa ogni richiesta, scade dopo 60 secondirl:ip:203.0.113.10:second → controllo burst su finestre molto breviCon un TTL su ogni contatore, i limiti si resettano automaticamente senza job di background. È una base pratica per limitare i tentativi di login, proteggere endpoint costosi o far rispettare quote basate sul piano.
Pagamenti e altre operazioni “esegui esattamente una volta” necessitano protezione da retry—causati da timeout, retry client o ri-consegna di messaggi.
Uno store chiave-valore può registrare chiavi di idempotenza:
idem:pay:order_789:clientKey_abc → risultato o stato memorizzatoAlla prima richiesta, processi e memorizzi l'esito con un TTL. Ai retry successivi restituisci l'esito memorizzato invece di rieseguire l'operazione. Il TTL evita crescita illimitata mantenendo la finestra realistica di retry.
Questi usi non sono “caching” nel senso classico; servono a mantenere bassa latenza per letture ad alta frequenza e primitivi di coordinamento che richiedono velocità e atomicità.
“Store chiave-valore” non sempre significa “stringa dentro, stringa fuori”. Molti sistemi offrono strutture dati più ricche che ti permettono di modellare bisogni comuni direttamente nello store—spesso più velocemente e con meno complessità rispetto a gestire tutto nel codice applicativo.
Gli hash (o mappe) sono ideali quando hai un singolo “oggetto” con diversi attributi correlati. Invece di creare molte chiavi come user:123:name, user:123:plan, user:123:last_seen, puoi tenerli insieme sotto una sola chiave, per esempio user:123 con campi.
Questo riduce la proliferazione di chiavi e ti permette di recuperare o cambiare solo il campo necessario—utile per profili, feature flag o piccoli blob di configurazione.
I set sono ottimi per domande “X è nel gruppo?”:
I sorted set aggiungono ordinamento tramite uno score, utile per leaderboard, “top N” e ranking per tempo o popolarità. Puoi memorizzare punteggi come contatori di visualizzazioni o timestamp e leggere rapidamente gli elementi migliori.
I problemi di concorrenza emergono spesso in funzionalità piccole: contatori, quote, azioni una-tantum e rate limit. Se due richieste arrivano insieme e l'app fa “leggi → +1 → scrivi”, puoi perdere aggiornamenti.
Le operazioni atomiche risolvono questo eseguendo la modifica come passo singolo e indivisibile nello store:
Con incrementi atomici non servono lock o coordinazione fra server. Questo significa meno race condition, codice più semplice e comportamento più prevedibile sotto carico—specialmente per rate limiting e quote dove “quasi corretto” diventa un problema visibile ai clienti.
Quando uno store chiave-valore inizia a gestire traffico serio, “renderlo più veloce” spesso significa “renderlo più largo”: distribuire letture e scritture su più nodi mantenendo il sistema prevedibile in caso di guasti.
Replica mantiene copie multiple degli stessi dati.
Sharding divide lo spazio delle chiavi fra nodi.
Molte distribuzioni combinano entrambi: shard per throughput e repliche per disponibilità.
“Alta disponibilità” significa che il livello cache/sessioni continua a servire richieste anche se un nodo fallisce.
Con client-side routing, la tua applicazione (o la libreria) calcola quale nodo possiede una chiave (comune con consistent hashing). È molto veloce, ma i client devono conoscere i cambi di topologia.
Con server-side routing, invii le richieste a un proxy o endpoint di cluster che le inoltra al nodo giusto. Questo semplifica i client e i rollout, ma aggiunge un hop.
Pianifica la memoria dall'alto:
Gli store chiave-valore sembrano “istantanei” perché tengono i dati hot in memoria e sono ottimizzati per letture/scritture veloci. Questa velocità ha un costo: spesso si sceglie tra prestazioni, durabilità e consistenza. Capire i compromessi in anticipo evita sorprese dolorose.
Molti store supportano diverse modalità di persistenza:
Scegli la modalità che corrisponde allo scopo dei dati: la cache tollera la perdita; lo storage delle sessioni spesso richiede più attenzione.
In setup distribuiti potresti vedere consistenza eventuale—le letture possono temporaneamente restituire un valore più vecchio dopo una scrittura, specialmente durante failover o lag di replica. Una consistenza più forte (per esempio richiedere ack da più nodi) riduce anomalie ma aumenta la latenza e può ridurre la disponibilità durante problemi di rete.
Le cache si riempiono. Una politica di eviction decide cosa rimuovere: least-recently-used, least-frequently-used, random o “non espellere” (che trasforma la memoria piena in errori di scrittura). Decidi se preferisci entry mancanti in cache o errori sotto pressione.
Assumi che gli outage accadano. Fallback tipici includono:
Progettare questi comportamenti intenzionalmente è ciò che rende il sistema percepito come affidabile dagli utenti.
Gli store chiave-valore spesso stanno sul “percorso caldo” della tua app. Questo li rende sia sensibili (possono contenere token di sessione o identificatori utente) sia costosi (sono spesso a consumo di memoria). Fare bene le basi presto evita incidenti dolorosi.
Inizia con confini di rete chiari: posiziona lo store in una subnet/VPC privata e permetti traffico solo dai servizi applicativi che ne hanno veramente bisogno.
Usa autenticazione se il prodotto la supporta e applica il principio del privilegio minimo: credenziali separate per app, admin e automazione; ruota i segreti; evita token “root” condivisi.
Cripta i dati in transito (TLS) quando possibile—specialmente se il traffico attraversa host o zone. La cifratura at-rest dipende dal prodotto e deployment; se disponibile, abilitala per servizi gestiti e verifica anche la cifratura dei backup.
Un piccolo set di metriche ti dice se la cache aiuta o danneggia:
Aggiungi alert per cambi improvvisi, non solo soglie assolute, e registra le operazioni sulle chiavi con attenzione (evita di loggare valori sensibili).
I maggiori driver sono:
Le leve pratiche per i costi sono ridurre la dimensione dei valori e impostare TTL realistici, così lo store contiene solo ciò che è realmente utile.
Inizia standardizzando il naming delle chiavi in modo che le chiavi di cache e sessione siano prevedibili, ricercabili e sicure da operare in bulk. Una convenzione semplice come app:env:feature:id (per esempio shop:prod:cart:USER123) aiuta a evitare collisioni e rende il debug più veloce.
Definisci una strategia TTL prima del rilascio. Decidi quali dati possono scadere rapidamente (secondi/minuti), cosa necessita di durate più lunghe (ore) e cosa non dovrebbe mai essere memorizzato. Se stai cacheando righe di DB, allinea i TTL a quanto spesso cambiano i dati sottostanti.
Scrivi un piano di invalidazione per ogni tipo di elemento in cache:
product:v3:123) quando vuoi un comportamento “invalidate all” sempliceScegli poche metriche e monitorale fin da subito:
Monitora anche il conteggio di evictions e l'uso di memoria per confermare che la cache sia dimensionata correttamente.
Valori troppo grandi aumentano tempo di rete e pressione sulla memoria—preferisci frammenti più piccoli precomputati. Evita TTL mancanti (dati stale e memory leak) e crescita illimitata delle chiavi (ad es. memorizzare ogni query di ricerca per sempre). Fai attenzione a non mettere dati user-specific sotto chiavi condivise.
Se stai valutando opzioni, confronta una cache locale in-process con una cache distribuita e decidi dove la consistenza è più importante. Per dettagli implementativi e guida operativa, rivedi /docs. Se stai pianificando capacità o hai bisogno di ipotesi di prezzo, consulta /pricing.
Se stai costruendo un prodotto nuovo (o modernizzando uno esistente), aiuta pensare a caching e archiviazione sessioni come preoccupazioni di prim'ordine fin dall'inizio. On Koder.ai, i team spesso prototipano un'app end-to-end (React sul web, servizi in Go con PostgreSQL, e opzionalmente Flutter per mobile) e poi iterano sulle prestazioni con pattern come cache-aside, TTL e contatori per rate-limiting. Funzionalità come planning mode, snapshots e rollback rendono più semplice sperimentare design di chiavi e strategie di invalidazione in sicurezza, e puoi esportare il sorgente quando sei pronto per eseguirlo nella tua pipeline.
I key-value store sono ottimizzati per una singola operazione: dato un key, restituisci un value. Questo focus ristretto permette percorsi molto veloci come indici in memoria e hashing, con meno overhead di pianificazione rispetto a database generalisti.
Offrono anche vantaggi indiretti: scaricano dal database principale letture ripetute (pagine popolari, risposte comuni alle API), lasciando al database il lavoro su scritture e query complesse.
Una chiave è un identificatore unico che puoi ripetere esattamente (spesso una stringa come user:123 o sess:<token>). Il valore è qualunque cosa tu voglia recuperare: da un contatore piccolo a un blob JSON.
Buone chiavi sono stabili, contestualizzate e prevedibili, il che rende caching, sessioni e ricerche più semplici da gestire e debuggare.
Memorizza risultati che sono letti frequentemente e che puoi rigenerare se necessario.
Esempi comuni:
Evita di memorizzare dati che devono essere perfettamente aggiornati (ad es. saldi bancari) a meno di una solida strategia di invalidazione.
Cache-aside (lazy loading) è spesso la scelta predefinita:
key dalla cache.Funziona bene perché degrada in modo elegante: se la cache è vuota o giù, puoi comunque servire dal database (con opportune precauzioni).
Usa read-through quando vuoi che il livello cache carichi automaticamente i dati in caso di miss (semplifica il codice di lettura dell'app, ma richiede integrazione nel livello cache).
Usa write-through quando vuoi che ogni scrittura aggiorni sincronicamente cache e database: le letture restano più coerenti ma le scritture sono più lente.
Scegli in base alla tolleranza alla complessità operativa (read-through) o alla latenza di scrittura accettabile (write-through).
Un TTL (time to live) imposta la scadenza automatica di una chiave. TTL brevi riducono il rischio di valori obsoleti ma aumentano i miss e il carico sul backend; TTL lunghi migliorano il hit rate ma aumentano il rischio di dati non aggiornati.
Consigli pratici:
Un cache stampede accade quando una chiave molto richiesta scade e molte richieste la ricostruiscono contemporaneamente.
Mitigazioni comuni:
Queste tecniche riducono i picchi improvvisi verso il database o le API esterne.
Le sessioni si prestano bene: accessi semplici (leggi/scrivi per token) e scadenze TTL per eliminare automaticamente sessioni inattive.
Buone pratiche:
sess:<token> (versionare con aiuta le migrazioni).Molti store supportano l'incremento atomico, che rende i contatori sicuri sotto concorrenza.
Un pattern tipico:
rl:user:123:minute → incrementa per ogni richiestaSe il contatore supera la soglia, rallenta o rifiuta la richiesta. Il TTL azzera i limiti automaticamente senza job in background.
Punti chiave da considerare:
Progetta modalità degradate: bypass della cache, servire dati leggermente stale quando sicuro, o fail-closed per operazioni sensibili.
sess:v2:<token>