Perché la gestione della memoria influenza prestazioni e sicurezza
La gestione della memoria è l’insieme di regole e meccanismi che un programma usa per richiedere memoria, usarla e restituirla. Ogni programma in esecuzione ha bisogno di memoria per cose come variabili, dati utente, buffer di rete, immagini e risultati intermedi. Poiché la memoria è limitata e condivisa con il sistema operativo e altre applicazioni, i linguaggi devono decidere chi è responsabile di liberarla e quando questo avviene.
Quelle decisioni modellano due risultati che interessano la maggior parte delle persone: quanto veloce sembra un programma e quanto si comporta in modo affidabile sotto pressione.
Cosa intendiamo per “prestazioni” qui
Le prestazioni non sono un singolo numero. La gestione della memoria può influire su:
- Throughput: quanto lavoro puoi completare al secondo (richieste gestite, frame renderizzati, file processati).
- Latenza: quanto impiega una singola operazione, in particolare i picchi di latenza dovuti a pause o a allocazioni lente.
- Impronta di memoria: quanta RAM il programma occupa durante l’esecuzione, che influisce su costi, durata della batteria e frequenza dello swapping del SO.
Un linguaggio che alloca rapidamente ma a volte si mette in pausa per fare pulizia può risultare bene nei benchmark ma dare una sensazione di scattosità nelle app interattive. Un altro modello che evita le pause può richiedere un design più attento per prevenire leak e errori di lifetime.
Cosa intendiamo per “sicurezza” qui
La sicurezza riguarda la prevenzione di errori legati alla memoria, come:
- Crash (accesso a memoria non valida)
- Corruzione dei dati (scrivere dove non si dovrebbe)
- Vulnerabilità di sicurezza (bug che un attaccante può trasformare in exploit)
Molti problemi di sicurezza di alto profilo risalgono a errori di memoria come use-after-free o buffer overflow.
Questa guida è un tour non tecnico dei principali modelli di memoria usati dai linguaggi popolari, cosa ottimizzano e i compromessi che accetti quando ne scegli uno.
Concetti fondamentali: Stack, Heap e tempi di vita degli oggetti
La memoria è il posto dove il programma conserva i dati mentre gira. La maggior parte dei linguaggi organizza questo attorno a due aree principali: lo stack e l’heap.
Stack: deposito rapido e temporaneo
Pensa allo stack come a un mazzo ordinato di post-it usati per il task corrente. Quando una funzione inizia, ottiene un piccolo “frame” sullo stack per le sue variabili locali. Quando la funzione termina, quel frame viene rimosso tutto insieme.
Questo è veloce e prevedibile — ma funziona solo per valori la cui dimensione è nota e il cui lifetime termina con la chiamata di funzione.
Heap: spazio flessibile per oggetti di durata maggiore
L’heap è più come un magazzino dove puoi conservare oggetti finché ti servono. È ideale per liste di dimensione dinamica, stringhe o oggetti condivisi tra parti diverse del programma.
Poiché gli oggetti nell’heap possono sopravvivere a una singola funzione, la domanda chiave diventa: chi è responsabile di liberarli e quando? Questa responsabilità è il “modello di gestione della memoria” di un linguaggio.
Lifetimes e perché puntatori/riferimenti contano
Un puntatore o riferimento è un modo per accedere a un oggetto in modo indiretto — come avere il numero di scaffale di una scatola nel magazzino. Se la scatola viene buttata ma hai ancora il numero di scaffale, potresti leggere dati spazzatura o causare un crash (un classico bug di use-after-free).
Un semplice scenario di esempio
Immagina un ciclo che crea un record cliente, formatta un messaggio e lo scarta:
- Sullo stack: piccole variabili temporanee usate solo durante la formattazione.
- Nell’heap: il record cliente e il testo del messaggio (dimensioni variabili).
Alcuni linguaggi nascondono questi dettagli (pulizia automatica), mentre altri li espongono (liberi esplicitamente la memoria, o devi seguire regole sull’ownership). Il resto di questo articolo esplora come queste scelte influenzano velocità, pause e sicurezza.
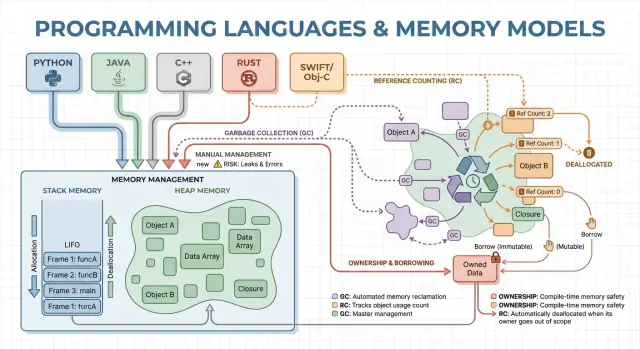
Gestione manuale della memoria: controllo con rischio maggiore
La gestione manuale significa che il programma (e quindi lo sviluppatore) richiede memoria esplicitamente e poi la rilascia. Nella pratica questo appare come malloc/free in C o new/delete in C++. È ancora comune nella programmazione di sistema dove serve controllo preciso su quando la memoria viene acquisita e restituita.
A cosa serve l’allocazione/liberazione esplicita
Tipicamente allochi memoria quando un oggetto deve sopravvivere alla chiamata corrente, cresce dinamicamente (es. un buffer ridimensionabile) o richiede un layout specifico per interoperabilità con hardware, SO o protocolli di rete.
Vantaggio di prestazioni: costi prevedibili (se fatto bene)
Senza garbage collector in background, ci sono meno pause impreviste. Allocazione e deallocazione possono essere rese molto prevedibili, specialmente se abbinate a allocator personalizzati, pool o buffer a dimensione fissa.
Il controllo manuale può anche ridurre l’overhead: non c’è fase di tracing, nessuna write barrier e spesso meno metadata per oggetto. Con codice ben progettato puoi raggiungere obiettivi di latenza stringenti e mantenere l’uso di memoria entro limiti rigorosi.
Rischi di sicurezza: i classici modi di fallire
Il compromesso è che il programma può commettere errori che il runtime non previene automaticamente:
- Memory leak (dimenticare di liberare)
- Double-free (liberare due volte)
- Use-after-free (accedere dopo la liberazione)
Questi bug possono causare crash, corruzione dei dati e vulnerabilità di sicurezza.
Mitigazioni comuni
I team riducono il rischio limitando dove è permessa l’allocazione raw e adottando pattern come:
- RAII in C++ (risorse liberate automaticamente quando gli oggetti escono dallo scope)
- Smart pointer (es.
std::unique_ptr) per codificare l’ownership
- Standard di codifica, checklist per code review, sanitizer e analisi statica
Quando è una buona scelta
La gestione manuale è spesso adatta per software embedded, sistemi in tempo reale, componenti di OS e librerie critiche per le prestazioni — scenari dove il controllo stretto e la latenza prevedibile contano più della comodità per lo sviluppatore.
Garbage Collection: produttività e sicurezza prevedibile
La garbage collection (GC) è la pulizia automatica della memoria: invece di dover fare free manualmente, il runtime traccia gli oggetti e recupera quelli non più raggiungibili dal programma. In pratica, questo ti permette di concentrarti sul comportamento e sul flusso dei dati mentre il sistema gestisce la maggior parte delle decisioni di allocazione e deallocazione.
Come la GC individua gli oggetti inutilizzati
La maggior parte dei collector identifica prima gli oggetti vivi, poi recupera il resto.
La tracing GC parte dalle radici (come variabili sullo stack, riferimenti globali e registri), segue i riferimenti per marcare tutto ciò che è raggiungibile e poi libera l’heap dagli oggetti non marcati. Se nessuno punta a un oggetto, diventa eleggibile per la raccolta.
Stili comuni di GC (a livello alto)
Generational GC si basa sull’osservazione che molti oggetti muoiono giovani. Separa l’heap in generazioni e raccoglie frequentemente l’area giovane, che di solito è meno costosa e migliora l’efficienza complessiva.
Concurrent GC svolge parte del lavoro di raccolta in parallelo con i thread dell’applicazione, mirando a ridurre pause lunghe. Può richiedere più bookkeeping per mantenere una vista coerente della memoria mentre il programma continua a girare.
Compromessi di prestazioni
La GC tipicamente scambia controllo manuale con lavoro a runtime. Alcuni sistemi privilegiano throughput elevato (molto lavoro completato al secondo) ma possono introdurre pause stop-the-world. Altri minimizzano le pause per applicazioni sensibili alla latenza, ma possono aggiungere overhead durante l’esecuzione normale.
Perché piace agli sviluppatori
La GC rimuove un’intera classe di bug di lifetime (soprattutto use-after-free) perché gli oggetti non vengono reclamati mentre sono ancora raggiungibili. Riduce anche leak dovuti a deallocazioni mancate (anche se puoi comunque “perdere” memoria mantenendo riferimenti più a lungo del necessario). In grandi codebase dove l’ownership è difficile da tracciare manualmente, questo spesso accelera l’iterazione.
Dove la troverai
Runtime con garbage collection sono comuni sulla JVM (Java, Kotlin), .NET (C#, F#), Go e nei motori JavaScript di browser e Node.js.
Itera senza paura
Sperimenta con allocator e strutture dati, poi torna indietro se i risultati non convincono.
Il reference counting è una strategia in cui ogni oggetto traccia quanti “proprietari” (riferimenti) puntano a esso. Quando il conteggio scende a zero, l’oggetto viene liberato immediatamente. Questa immediatezza è intuitiva: non appena nulla può raggiungere un oggetto, la sua memoria viene ripresa.
Come funziona (e perché piace)
Ogni volta che copi o memorizzi un riferimento a un oggetto, il runtime incrementa il suo contatore; quando un riferimento scompare, lo decrementa. Raggiungere zero innesca la pulizia in quel momento.
Questo rende la gestione delle risorse semplice: gli oggetti spesso rilasciano memoria vicino al momento in cui smetti di usarli, il che può ridurre l’uso di picco della memoria ed evitare reclamazioni ritardate.
Caratteristiche di prestazione
Il reference counting tende ad avere un overhead costante e stabile: operazioni di incremento/decremento avvengono su molte assegnazioni e chiamate. L’overhead è solitamente piccolo, ma è onnipresente.
Il vantaggio è che di solito non si hanno grandi pause stop-the-world come in alcuni GC di tracing. La latenza è spesso più uniforme, anche se possono comunque verificarsi ondate di deallocazioni quando grandi grafi di oggetti perdono il loro ultimo proprietario.
Il grande problema: i cicli
Il reference counting non può reclamare oggetti coinvolti in un ciclo. Se A riferisce B e B riferisce A, entrambi i conteggi restano sopra zero anche se nulla altro può raggiungerli — creando un leak.
Gli ecosistemi affrontano questo in vari modi:
- Weak references (puntatori non proprietari) per interrompere i cicli in pattern comuni (delegate, link genitore/figlio).
- Rilevamento dei cicli sovrapposto al reference counting (una passata di tracing che trova cicli non raggiungibili).
Dove lo vedrai
- Swift / Objective-C usano ARC (Automatic Reference Counting), con riferimenti “strong/weak/unowned” per gestire i cicli.
- Python usa il reference counting per la pulizia immediata, più un rilevatore di cicli per raccogliere garbage ciclico.
Ownership e borrowing: sicurezza della memoria a compile-time
Ownership e borrowing è un modello di memoria associato a Rust. L’idea è semplice: il compilatore applica regole che rendono difficile creare puntatori pendenti, double-free e molte data race — senza fare affidamento su un garbage collector a runtime.
Ownership: un proprietario chiaro, cleanup deterministico
Ogni valore ha esattamente un “proprietario” alla volta. Quando il proprietario esce dallo scope, il valore viene pulito immediatamente e in modo prevedibile. Questo dà una gestione deterministica delle risorse (memoria, handle di file, socket) simile alla pulizia manuale, ma con molte meno possibilità di errore.
L’ownership può anche spostarsi: assegnare un valore a una nuova variabile o passarlo a una funzione può trasferire la responsabilità. Dopo una move, il binding precedente non può più essere usato, il che previene i use-after-free per costruzione.
Borrowing: accesso temporaneo senza prendere ownership
Il borrowing ti permette di usare un valore senza diventarne il proprietario.
Un borrow in sola lettura permette accessi ripetuti e può essere copiato liberamente.
Un borrow mutabile consente aggiornamenti, ma deve essere esclusivo: mentre esiste, nessun altro può leggere o scrivere lo stesso valore. Questa regola “uno scrittore o molti lettori” è verificata al compile-time.
Benefici per la sicurezza — e i costi
Poiché i lifetimes sono tracciati, il compilatore può rifiutare codice che vivrebbe oltre i dati a cui fa riferimento, eliminando molti bug da dangling-reference. Le stesse regole impediscono anche molte condizioni di race nel codice concorrente.
Il compromesso è una curva di apprendimento e alcuni vincoli di design. Potrebbe essere necessario ristrutturare i flussi di dati, introdurre confini di ownership più chiari o usare tipi specializzati per stato mutabile condiviso.
Dove eccelle
Questo modello è indicato per codice di sistema — servizi, embedded, networking e componenti sensibili alle prestazioni — dove si vuole cleanup prevedibile e bassa latenza senza pause GC.
Arene, regioni e pool: pattern di allocazione veloci
Pianifica i lifetimes in anticipo
Mappa i tempi di vita degli oggetti e i confini di ownership prima di generare codice.
Quando crei molti oggetti di breve durata — nodi AST in un parser, entità in un frame di gioco, dati temporanei durante una richiesta web — l’overhead di allocare e liberare ogni oggetto singolarmente può dominare il tempo di esecuzione. Arene (detti anche regioni) e pool sono pattern che scambiano deallocazioni fini per una gestione rapida e cumulativa.
Cosa sono arena/region
Un’arena è una “zona” di memoria dove allochi molti oggetti nel tempo e poi rilasci tutti insieme resettando l’arena.
Invece di tracciare il lifetime di ogni singolo oggetto, leghi i lifetime a un confine chiaro: “tutto ciò che è allocato per questa richiesta” o “tutto ciò che è allocato durante la compilazione di questa funzione”.
Perché può essere veloce
Le arene sono spesso rapide perché:
- riducono le chiamate all’allocator (spesso basta avanzare un puntatore)
- evitano i costi di free per ogni oggetto
- migliorano la località della cache tenendo oggetti correlati vicini
Questo può aumentare il throughput e ridurre i picchi di latenza causati da frequenti free o contesa sull’allocator.
Casi d’uso tipici
Arene e pool compaiono in:
- parser e compilatori (alberi sintattici, tabelle dei simboli)
- dati con scope per richiesta (alloca durante la richiesta, libera alla fine)
- giochi (allocazioni per frame resettate ogni frame)
- simulazioni e job batch
Considerazioni di sicurezza
La regola principale è semplice: non lasciare che riferimenti escano dalla regione che possiede la memoria. Se qualcosa allocata in un’arena viene memorizzata globalmente o restituita oltre la vita dell’arena, rischi use-after-free.
Linguaggi e librerie gestiscono questo in modi diversi: alcuni si basano sulla disciplina e sulle API, altri possono codificare il confine della regione nei tipi.
Come si integra con altri approcci
Arene e pool non sono un’alternativa alla garbage collection o all’ownership — spesso sono un complemento. I linguaggi con GC usano comunemente pool per i cammini caldi; i linguaggi basati su ownership possono usare arene per raggruppare allocazioni e rendere espliciti i lifetimes. Usati con cura, offrono allocazioni “veloci per default” senza perdere chiarezza su quando la memoria viene rilasciata.
Ottimizzazioni del compilatore e del runtime che cambiano il quadro
Il modello di memoria di un linguaggio è solo una parte della storia delle prestazioni e della sicurezza. Compilatori e runtime moderni riscrivono il tuo programma per allocare meno, liberare prima ed evitare lavoro extra. Per questo regole come “GC è lento” o “la gestione manuale è la più veloce” spesso non reggono nelle applicazioni reali.
Escape analysis: quando l’heap non è necessario
Molte allocazioni esistono solo per passare dati tra funzioni. Con l’escape analysis, un compilatore può dimostrare che un oggetto non vive oltre lo scope corrente e lasciarlo sul lo stack invece che nell’heap.
Questo può eliminare un’allocazione heap, insieme ai costi associati (tracciamento GC, aggiornamenti del reference count, lock dell’allocator). Nei linguaggi gestiti, questa è una delle ragioni principali per cui piccoli oggetti possono costare meno di quanto ti aspetteresti.
Inlining e rimozione delle allocazioni
Quando un compilatore inlines una funzione (sostituisce la chiamata con il corpo della funzione), può “vedere attraverso” livelli di astrazione. Questa visibilità abilita ottimizzazioni come:
- eliminazione di oggetti temporanei
- replacement scalare (trasformare un oggetto in poche variabili locali)
- rimozione del traffico di reference-count quando i lifetimes diventano ovvi
API ben progettate possono diventare “a costo zero” dopo le ottimizzazioni, anche se sorgono come molto allocanti.
JIT vs compilazione ahead-of-time
Un JIT (just-in-time) può ottimizzare usando dati di produzione reali: quali percorsi di codice sono caldi, dimensioni tipiche degli oggetti e pattern di allocazione. Questo spesso migliora il throughput, ma può aggiungere tempo di warm-up e pause occasionali per ricompilazione o GC.
I compilatori ahead-of-time devono indovinare più in anticipo, ma offrono startup prevedibile e latenza più stabile.
Le leve di tuning del runtime (e quando toccarle)
I runtime basati su GC espongono impostazioni come dimensione dell’heap, obiettivi di pause e soglie di generazione. Modificale quando hai evidenze misurate (es. picchi di latenza o pressione di memoria), non come primo passo.
Perché lo stesso algoritmo si comporta diversamente
Due implementazioni dello “stesso” algoritmo possono differire in conteggi nascosti di allocazioni, oggetti temporanei e accessi indiretti. Quelle differenze interagiscono con ottimizzatori, allocator e comportamento della cache — quindi confronti di prestazioni richiedono profiling, non supposizioni.
Compromessi di prestazione: Throughput, Latenza e Uso di Memoria
Prototipa una versione mobile
Prova lo stesso workflow in Flutter per confrontare la pressione di memoria su dispositivi mobili.
Le scelte di gestione della memoria non cambiano solo come scrivi codice — cambiano quando viene fatto il lavoro, quanta memoria devi riservare e quanto coerente risulta l’esperienza per gli utenti.
Throughput vs latenza (un esempio concreto)
Throughput è “quanto lavoro per unità di tempo”. Pensa a un job notturno che processa 10 milioni di record: se GC o reference counting aggiungono un piccolo overhead ma aumentano la produttività degli sviluppatori, potresti comunque finire più velocemente.
Latenza è “quanto impiega una singola operazione end-to-end”. Per una richiesta web, una singola risposta lenta danneggia l’esperienza, anche se il throughput medio è alto. Un runtime che occasionalmente si mette in pausa per reclamare memoria può andare bene per batch, ma essere percepito negativamente in app interattive.
Impronta di memoria: costo e velocità
Una impronta di memoria maggiore aumenta i costi cloud e può rallentare i programmi. Quando il working set non entra bene nelle cache CPU, la CPU aspetta più spesso i dati dalla RAM. Alcune strategie scambiano memoria extra per velocità (es. mantenere oggetti liberati in pool), altre riducono la memoria ma aggiungono bookkeeping.
Frammentazione e località della cache (in parole semplici)
La frammentazione accade quando la memoria libera è divisa in molte piccole lacune — come cercare di parcheggiare un furgone in un parcheggio con spazi minuscoli sparsi. Gli allocator possono impiegare più tempo a trovare spazio e la memoria può crescere anche quando “sufficientemente” libera.
La località della cache significa che i dati correlati stanno vicini. L’allocazione tramite pool/arena spesso migliora la località (oggetti allocati insieme finiscono vicini), mentre heap con oggetti di vita molto diversa può degenerare in layout meno cache-friendly.
Requisiti di timing prevedibile
Se hai bisogno di tempi di risposta consistenti — giochi, app audio, sistemi di trading, controller embedded o real-time — “per lo più veloci ma occasionalmente lenti” può essere peggiore di “leggermente più lento ma coerente”. Qui contano pattern di deallocazione prevedibili e controllo stretto sulle allocazioni.
Checklist di misurazione
- Esegui benchmark sia del throughput (jobs/sec) che della tail latency (p95/p99)
- Profila le allocazioni: rate di allocazione, tempo di pausa, tempo speso in alloc/free
- Usa carichi rappresentativi (forme di traffico reali, dimensioni dei dati, concorrenza)
- Monitora la memoria: peak RSS, dimensione heap nel tempo, metriche di frammentazione se disponibili
- Ripeti le esecuzioni per catturare variabilità (effetti di warm-up, cicli GC in background)
Sicurezza e robustezza: come i modelli di memoria prevengono bug comuni
Gli errori di memoria non sono solo “scivoloni di programmatore”. In molti sistemi reali si trasformano in problemi di sicurezza: crash improvvisi (denial of service), esposizione accidentale di dati (lettura di memoria liberata o non inizializzata) o condizioni sfruttabili dove gli attaccanti portano il programma a eseguire codice non voluto.
Come i bug si mappano ai modelli di memoria
Diversi modelli tendono a fallire in modi diversi:
- Gestione manuale (es. C/C++) rischia spesso use-after-free, double free e buffer overflow — problemi che possono corrompere la memoria ed essere sfruttabili.
- Garbage collection rimuove la maggior parte degli errori stile UAF perché gli oggetti non vengono liberati finché raggiungibili, ma puoi comunque avere memory leak (riferimenti tenuti involontariamente) e rischi nell’interoperabilità nativa.
- Reference counting fornisce cleanup immediato, aiutando il rilascio prevedibile delle risorse, ma può soffrire di cicli (leak) e problemi sottili nei lifetime con stato mutabile condiviso.
- Ownership/borrowing (es. modello di Rust) previene molte classi di UAF e data race a compile-time rendendo difficile avere riferimenti pendenti o mutazioni non sincronizzate.
Sicurezza thread e concorrenza
La concorrenza cambia il modello di minaccia: memoria che va bene in un thread può diventare pericolosa quando un altro thread la libera o la muta. I modelli che impongono regole sulla condivisione (o richiedono sincronizzazione esplicita) riducono la possibilità di condizioni di race che portano a stato corrotto, fughe di dati e crash intermittenti.
Difesa in profondità resta importante
Nessun modello di memoria elimina tutti i rischi — bug di logica (errori di autenticazione, default insicuri, validazione errata) capitano comunque. I team forti stratificano protezioni: sanitizer nei test, librerie standard sicure, code review rigorose, fuzzing e confini stretti attorno al codice unsafe/FFI. La sicurezza della memoria riduce significativamente la superficie di attacco, non la garantisce.