26 dic 2025·8 min
Strumenti interni per sviluppatori con Claude Code: cruscotti CLI sicuri
Costruisci strumenti interni con Claude Code per risolvere ricerca log, feature toggle e controlli sui dati, mantenendo il privilegio minimo e chiari guardrail.
Quale problema dovrebbe risolvere davvero il tuo strumento interno
Gli strumenti interni spesso nascono come scorciatoia: un comando o una pagina che fa risparmiare al team 20 minuti durante un incidente. Il rischio è che la stessa scorciatoia possa trasformarsi silenziosamente in una porta sul retro privilegiata se non definisci il problema e i confini fin da subito.
I team solitamente ricorrono a uno strumento quando lo stesso problema si ripete ogni giorno, per esempio:
- Ricerca nei log lenta, incoerente o dispersa tra sistemi
- Feature toggle che richiedono una modifica manuale rischiosa o una scrittura diretta sul database
- Controlli sui dati che dipendono da una sola persona che esegue uno script dal proprio laptop
- Attività on-call semplici, ma facili da sbagliare alle 2 di notte
Questi problemi sembrano piccoli finché lo strumento non può leggere log di produzione, interrogare dati dei clienti o cambiare flag. A quel punto si tratta di controllo degli accessi, tracce di audit e scritture accidentali. Uno strumento “solo per ingegneri” può comunque causare un outage se esegue una query ampia, colpisce l'ambiente sbagliato o cambia stato senza un chiaro passo di conferma.
Definisci il successo in termini stretti e misurabili: operazioni più veloci senza allargare i permessi. Un buon strumento interno elimina passaggi, non le salvaguardie. Invece di dare a tutti accesso ampio al database per verificare un possibile problema di fatturazione, costruisci uno strumento che risponda a una sola domanda: “Mostrami gli eventi di fatturazione falliti di oggi per l'account X”, usando credenziali di sola lettura e con ambito ristretto.
Prima di scegliere un'interfaccia, decidi cosa serve alle persone nel momento. Una CLI è ottima per compiti ripetibili durante l'on-call. Una dashboard web è migliore quando i risultati richiedono contesto e visibilità condivisa. A volte rilasci entrambe, ma solo se sono viste leggere delle stesse operazioni protette. L'obiettivo è una sola capacità ben definita, non una nuova superficie di amministrazione.
Scegli un solo dolore e mantieni lo scope piccolo
Il modo più rapido per rendere uno strumento interno utile (e sicuro) è scegliere un solo lavoro chiaro e farlo bene. Se prova a gestire log, feature flag, fix di dati e gestione utenti dal giorno uno, crescerà comportamenti nascosti e sorprenderà le persone.
Inizia con una singola domanda che un utente pone durante il lavoro reale. Per esempio: “Dato un request ID, mostrami l'errore e le righe circostanti attraverso i servizi.” È stretto, testabile e facile da spiegare.
Sii esplicito su chi è destinatario dello strumento. Uno sviluppatore che esegue il debug in locale ha bisogno di opzioni diverse rispetto a chi è on-call, e entrambi differiscono da support o analista. Mescolare i pubblici porta ad aggiungere comandi “potenti” che la maggioranza degli utenti non dovrebbe mai toccare.
Scrivi input e output come un piccolo contratto.
Gli input devono essere espliciti: request ID, intervallo di tempo, ambiente. Gli output devono essere prevedibili: righe corrispondenti, nome del servizio, timestamp, conteggio. Evita effetti collaterali nascosti come “inoltre svuota la cache” o “inoltre ritenta il job”. Sono quelle funzionalità che causano incidenti.
Default a sola lettura. Puoi comunque rendere lo strumento prezioso con ricerca, diff, validazione e report. Aggiungi azioni di scrittura solo quando puoi nominare uno scenario reale che le richiede e puoi vincolarle strettamente.
Una semplice dichiarazione di scope che mantiene il team onesto:
- Un compito principale, una schermata o un comando principale
- Una fonte di dati (o una vista logica), non “tutto”
- Flag espliciti per ambiente e intervallo di tempo
- Prima sola lettura, niente azioni in background
- Se esistono scritture, richiedi conferma e registra ogni modifica
Mappa le fonti dati e le operazioni sensibili presto
Prima che Claude Code scriva qualsiasi cosa, annota cosa toccherà lo strumento. La maggior parte dei problemi di sicurezza e affidabilità emergono qui, non nell'interfaccia. Tratta questa mappatura come un contratto: dice ai revisori cosa è in scope e cosa è fuori limite.
Inizia con un inventario concreto delle fonti dati e dei proprietari. Per esempio: log (app, gateway, auth) e dove risiedono; le tabelle o viste del database esatte che lo strumento può interrogare; il tuo store di feature flag e le regole di naming; metriche e trace e quali label è sicuro filtrare; e se prevedi di scrivere note nei sistemi di ticketing o incident.
Poi nomina le operazioni consentite allo strumento. Evita il permesso “admin”. Definisci invece verbi auditabili. Esempi comuni: ricerca ed export in sola lettura (con limiti), annotare (aggiungere una nota senza modificare la history), toggling di flag specifici con TTL, backfill limitati (range di date e numero di record), e modalità dry-run che mostrano l'impatto senza cambiare i dati.
I campi sensibili richiedono gestione esplicita. Decidi cosa deve essere mascherato (email, token, session ID, chiavi API, identificatori cliente) e cosa può essere mostrato solo troncato. Per esempio: mostrare gli ultimi 4 caratteri di un ID, o hasharlo in modo consistente così le persone possono correlare eventi senza vedere il valore grezzo.
Infine, concorda le regole di retention e audit. Se un utente esegue una query o cambia un flag, registra chi l'ha fatto, quando, quali filtri sono stati usati e il conteggio dei risultati. Conserva i log di audit più a lungo dei log applicativi. Anche una regola semplice come “query conservate 30 giorni, record di audit 1 anno” evita dibattiti dolorosi durante un incidente.
Modello di accesso a privilegio minimo che resta semplice
Il principio del privilegio minimo è più facile quando il modello è noioso. Inizia elencando cosa può fare lo strumento, poi etichetta ogni azione come sola lettura o scrittura. La maggior parte degli strumenti interni richiede solo accessi di lettura per la maggior parte delle persone.
Per una dashboard web, usa il sistema di identità esistente (SSO con OAuth). Evita password locali. Per una CLI, preferisci token a breve durata che scadono in fretta e limita il loro ambito alle azioni necessarie. I token condivisi a lunga durata tendono a essere incollati in ticket, salvati nella cronologia della shell o copiati su macchine personali.
Mantieni RBAC ridotto. Se servono più di pochi ruoli, probabilmente lo strumento fa troppo. Molti team vanno bene con tre ruoli:
- Viewer: sola lettura, impostazioni sicure predefinite
- Operator: lettura più un piccolo insieme di azioni a basso rischio
- Admin: azioni ad alto rischio, usato raramente
Separa gli ambienti presto, anche se l'interfaccia sembra la stessa. Rendi difficile il “fare per sbaglio in prod.” Usa credenziali diverse per ambiente, file di config diversi e endpoint API diversi. Se un utente supporta solo staging, non dovrebbe nemmeno riuscire ad autenticarsi contro la produzione.
Le azioni ad alto rischio meritano uno step di approvazione. Pensa a cancellare dati, cambiare feature flag, riavviare servizi o eseguire query pesanti. Aggiungi un controllo di seconda persona quando il raggio d'azione è ampio. Pattern pratici includono conferme digitate che includono il target (nome servizio e ambiente), registrare chi ha richiesto e chi ha approvato, e aggiungere un breve delay o una finestra schedulata per le operazioni più pericolose.
Se generi lo strumento con Claude Code, rendi regola che ogni endpoint e comando dichiari il ruolo richiesto in anticipo. Questa abitudine mantiene le revisioni dei permessi semplici man mano che lo strumento cresce.
Guardrail che prevengono incidenti e query errate
Pianificalo prima di costruire
Mappa input, output e permessi prima che il codice venga generato.
La modalità di fallimento più comune per gli strumenti interni non è un attaccante. È un collega stanco che esegue il comando “giusto” con input sbagliati. Tratta i guardrail come feature di prodotto, non come rifinitura.
Default di sicurezza
Inizia con una postura sicura: sola lettura per default. Anche se l'utente è admin, lo strumento dovrebbe aprirsi in una modalità che può solo recuperare dati. Rendi le azioni di scrittura opt-in e ovvie.
Per qualsiasi operazione che cambi stato (toggle di flag, backfill, cancellazione), richiedi una digitazione di conferma esplicita. “Sei sicuro? y/N” è troppo facile da eseguire per abitudine. Chiedi all'utente di ridigitare qualcosa di specifico, come il nome dell'ambiente più l'ID target.
Una validazione stretta degli input previene la maggior parte dei disastri. Accetta solo le forme che supporti davvero (ID, date, ambienti) e rifiuta tutto il resto in ingresso. Per le ricerche, vincola la potenza: limita i risultati, impone intervalli di tempo sensati e usa una lista consentita invece di permettere pattern arbitrari che colpiscono il tuo store di log.
Per evitare query runaway, aggiungi timeout e limiti di rate. Uno strumento sicuro fallisce rapidamente e spiega il motivo, invece di bloccarsi e martellare il database.
Un set di guardrail che funziona bene in pratica:
- Default a sola lettura, con un chiaro interruttore “modalità scrittura”
- Digitazione di conferma per le scritture (includi env + target)
- Validazione stretta per ID, date, limiti e pattern consentiti
- Timeout di query più limiti per utente
- Mascheramento dei segreti nell'output e nei log dello strumento
Igiene dell'output
Assumi che l'output dello strumento verrà copiato in ticket e chat. Maschera i segreti per default (token, cookie, chiavi API ed email se necessario). Inoltre pulisci ciò che memorizzi: i log di audit devono registrare cosa è stato tentato, non i dati grezzi restituiti.
Per una dashboard di ricerca nei log, restituisci un'anteprima breve e un conteggio, non payload completi. Se qualcuno ha davvero bisogno dell'evento completo, rendilo un'azione separata chiaramente controllata e con la propria conferma.
Come lavorare con Claude Code senza perdere il controllo
Tratta Claude Code come un junior veloce: utile, ma non un lettore della mente. Il tuo compito è mantenere il lavoro vincolato, revisionabile e facile da annullare. Questa è la differenza tra strumenti che sembrano sicuri e strumenti che ti sorprendono alle 2 di notte.
Inizia con una specifica che il modello possa seguire
Prima di chiedere codice, scrivi una piccola specifica che nomini l'azione utente e l'esito atteso. Mantienila sul comportamento, non sui dettagli del framework. Una buona spec di solito sta su mezza pagina e copre:
- Comandi o schermate (nomi esatti)
- Input (flag, campi, formati, limiti)
- Output (cosa viene mostrato, cosa viene salvato)
- Casi di errore (input non valido, timeout, risultati vuoti)
- Controlli di permesso (cosa succede quando l'accesso è negato)
Per esempio, se stai costruendo una CLI di ricerca log, definisci un comando end-to-end: logs search --service api --since 30m --text "timeout", con un hard cap sui risultati e un chiaro messaggio di “accesso negato”.
Richiedi piccoli incrementi che puoi verificare
Richiedi prima uno scheletro: wiring della CLI, caricamento della config e una chiamata dati stub. Poi chiedi esattamente una funzionalità completata fino in fondo (inclusa validazione ed errori). Piccoli diff rendono le review reali.
Dopo ogni cambiamento, chiedi una spiegazione in linguaggio semplice di cosa è cambiato e perché. Se la spiegazione non corrisponde al diff, fermati e riscrivi il comportamento e i vincoli di sicurezza.
Genera test presto, prima di aggiungere altre funzionalità. Copri almeno il percorso felice, input non validi (date errate, flag mancanti), permesso negato, risultati vuoti e limiti di rate o timeout del backend.
CLI vs dashboard web: scegliere l'interfaccia giusta
Una CLI e una dashboard interna possono risolvere lo stesso problema, ma falliscono in modi diversi. Scegli l'interfaccia che rende la strada sicura la più facile.
Una CLI è di solito la scelta migliore quando la velocità conta e l'utente sa già cosa vuole. Si adatta bene ai workflow in sola lettura, perché puoi mantenere permessi stretti e evitare pulsanti che attivano azioni di scrittura per errore.
Una CLI è una scelta forte per query veloci on-call, script e automazione, tracce di audit esplicite (ogni comando è scritto), e rollout a basso overhead (un binario, una config).
Una dashboard web è migliore quando serve visibilità condivisa o passaggi guidati. Può ridurre gli errori spingendo verso default sicuri come range di tempo, ambienti e azioni pre-approvate. Le dashboard funzionano anche per viste di stato team-wide, azioni guardate che richiedono conferma e spiegazioni integrate di cosa fa un pulsante.
Quando possibile, usa lo stesso backend API per entrambi. Metti auth, rate limit, limiti di query e audit logging in quell'API, non nell'interfaccia. Così CLI e dashboard diventano client diversi con ergonomie diverse.
Decidi anche dove viene eseguito, perché cambia il rischio. Una CLI su un laptop può far trapelare token. Eseguirla su un bastion host o in un cluster interno può ridurre l'esposizione e rendere più facile logging e applicazione di policy.
Esempio: per la ricerca nei log, una CLI è ottima per un ingegnere on-call che tira gli ultimi 10 minuti per un servizio. Una dashboard è migliore per una war room condivisa dove tutti hanno la stessa vista filtrata, più un'azione guidata “export per postmortem” controllata dai permessi.
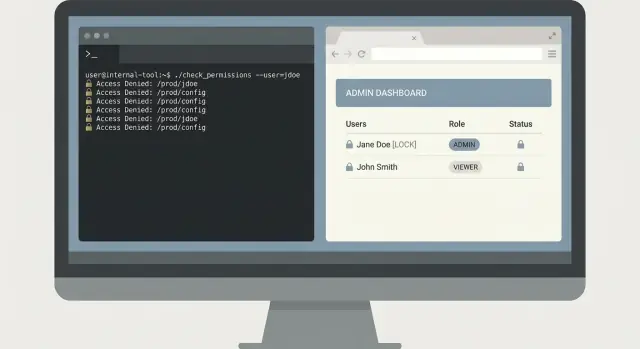
Un esempio realistico: tool di ricerca log per on-call
Crea il primo strumento sicuro
Trasforma la tua specifica CLI o dashboard in codice funzionante tramite una chat semplice.
Sono le 02:10 e on-call riceve la segnalazione: “Cliccando Paga a volte fallisce per un cliente.” Support ha uno screenshot con un request ID, ma nessuno vuole incollare query casuali in un sistema di log con permessi admin.
Una piccola CLI può risolvere questo problema in modo sicuro. La chiave è mantenerla ristretta: trovare l'errore velocemente, mostrare solo il necessario e lasciare i dati di produzione intatti.
Un flow CLI minimale
Inizia con un comando che impone limiti di tempo e un identificatore specifico. Richiedi un request ID e una finestra temporale, con default su una finestra corta.
oncall-logs search --request-id req_123 --since 30m --until now
Restituisci prima un sommario: nome del servizio, classe di errore, conteggio e i primi 3 messaggi corrispondenti. Poi permetti un passo esplicito di expand che stampi le righe di log complete solo quando l'utente lo richiede.
oncall-logs show --request-id req_123 --limit 20
Questo design in due passi previene dump di dati accidentali. Rende anche le review più semplici perché lo strumento ha un percorso chiaro e sicuro di default.
Azione opzionale di follow-up (senza scritture)
On-call spesso deve lasciare una traccia per chi segue. Invece di scrivere nel database, aggiungi un'azione opzionale che crea il payload di una nota ticket o applica un tag nel sistema di incident, ma che non tocchi mai i record cliente.
Per mantenere il privilegio minimo, la CLI dovrebbe usare un token di sola lettura per i log, e un token separato e con ambito ristretto per l'azione ticket/tag.
Registra un record di audit per ogni esecuzione: chi l'ha eseguita, quale request ID, quali limiti di tempo sono stati usati e se hanno espanso i dettagli. Quel log di audit è la tua rete di sicurezza quando qualcosa va storto o quando l'accesso deve essere revisionato.
Errori comuni che creano problemi di sicurezza e affidabilità
I piccoli strumenti interni spesso partono come “piccolo aiuto veloce.” Proprio per questo finiscono con default rischiosi. Il modo più rapido per perdere fiducia è un incidente grave, come uno strumento che cancella dati quando avrebbe dovuto essere in sola lettura.
Gli errori che emergono più spesso:
- Dare al tool accesso di scrittura al DB di produzione quando servivano solo letture, confidando in un “stare attenti”
- Saltare una traccia di audit, così poi non puoi rispondere a chi ha eseguito un comando, con quali input e cosa è cambiato
- Permettere SQL libero, regex o filtri ad hoc che scansiscono tabelle o log enormi e mandano giù i sistemi
- Mescolare ambienti in modo che azioni su staging possano raggiungere prod perché config, token o base URL sono condivisi
- Stampare segreti su terminale, console del browser o log, poi dimenticare che quegli output finiscono incollati in ticket e chat
Un fallimento realistico: un ingegnere on-call usa una CLI di ricerca log durante un incidente. Lo strumento accetta qualsiasi regex e la invia al backend di log. Un pattern costoso scorre ore di log ad alto volume, fa impennare i costi e rallenta le ricerche per tutti. Nella stessa sessione, la CLI stampa un token API in output di debug, che finisce incollato in un documento dell'incidente.
Default più sicuri che prevengono la maggior parte degli incidenti
Tratta la sola lettura come un vero confine di sicurezza, non come un'abitudine. Usa credenziali separate per ambiente e account di servizio separati per strumento.
Alcuni guardrail fanno la maggior parte del lavoro:
- Usa query allow-listate (o template) invece di SQL raw, e imposta limiti su range temporali e righe
- Logga ogni azione con request ID, identità utente, ambiente target e parametri esatti
- Richiedi selezione esplicita dell'ambiente, con conferma rumorosa per la produzione
- Redigi i segreti per default e disabilita l'output di debug a meno che non sia richiesta una flag privilegiata
Se lo strumento non può fare qualcosa di pericoloso per design, il tuo team non dovrà contare sulla perfetta attenzione alle 3 del mattino.
Checklist rapida prima del rilascio
Mantieni lo strumento verificabile
Ottieni il codice sorgente completo così il tuo team può revisionare e possedere ogni modifica.
Prima che il tuo strumento interno raggiunga utenti reali (soprattutto on-call), trattalo come un sistema di produzione. Conferma che accessi, permessi e limiti di sicurezza siano reali, non impliciti.
Inizia da accesso e permessi. Molti incidenti avvengono perché un accesso “temporaneo” diventa permanente o perché uno strumento guadagna silenziosamente poteri di scrittura nel tempo.
- Auth e offboarding: conferma chi può accedere, come si concede l'accesso e come viene revocato lo stesso giorno in cui qualcuno cambia team
- Ruoli piccoli: mantieni 2-3 ruoli al massimo (viewer, operator, admin) e scrivi cosa può fare ciascun ruolo
- Sola lettura per default: rendi la visualizzazione il percorso predefinito e richiedi un ruolo esplicito per tutto ciò che cambia dati
- Gestione segreti: conserva token e chiavi fuori dal repo e verifica che lo strumento non li stampi nei log o nei messaggi di errore
- Break-glass flow: se serve accesso di emergenza, rendilo limitato nel tempo e registrato
Poi valida i guardrail che prevengono gli errori comuni:
- Conferme per azioni rischiose: richiedi digitazioni di conferma per delete, backfill o cambi di config
- Limiti e timeout: imposta cap su dimensione dei risultati, finestre temporali e timeout delle query
- Validazione degli input: valida ID, date e nomi ambienti; rifiuta tutto ciò che sembra “run everywhere”
- Log di audit: registra chi ha fatto cosa, quando e da dove; rendi i log facili da cercare durante gli incidenti
- Metriche e errori di base: traccia tasso di successo, latenza e tipologie di errore principali per notare rotture precocemente
Applica change control come faresti per qualsiasi servizio: peer review, pochi test focalizzati sui percorsi pericolosi e un piano di rollback (incluso un modo per disabilitare lo strumento velocemente se si comporta male).
Prossimi passi: rollout sicuro e miglioramento continuo
Tratta il primo rilascio come un esperimento controllato. Inizia con un team, un workflow e un piccolo set di task reali. Un tool di ricerca log per on-call è un buon pilota perché puoi misurare il tempo risparmiato e individuare query rischiose velocemente.
Mantieni il rollout prevedibile: pilota con 3–10 utenti, parti in staging, limita l'accesso con ruoli a privilegio minimo (non token condivisi), imposta limiti di utilizzo e registra log di audit per ogni comando o click. Assicurati di poter ripristinare rapidamente config e permessi.
Scrivi il contratto dello strumento in linguaggio chiaro. Elenca ogni comando (o azione della dashboard), i parametri consentiti, cosa significa successo e cosa indicano gli errori. Le persone smettono di fidarsi degli strumenti interni quando gli output sembrano ambigui, anche se il codice è corretto.
Aggiungi un loop di feedback che venga realmente controllato. Monitora quali query sono lente, quali filtri sono comuni e quali opzioni confondono le persone. Quando vedi workaround ripetuti, di solito è un segnale che l'interfaccia manca di un default sicuro.
La manutenzione ha bisogno di un owner e di un calendario. Decidi chi aggiorna le dipendenze, chi ruota le credenziali e chi viene paged se lo strumento si rompe durante un incidente. Revisiona le modifiche generate dall'AI come faresti per un servizio di produzione: diff dei permessi, sicurezza delle query e logging.
Se il tuo team preferisce iterazione guidata dalla chat, Koder.ai può essere un modo pratico per generare una piccola CLI o dashboard da una conversazione, mantenere snapshot di stati noti e ripristinare rapidamente quando una modifica introduce rischio.