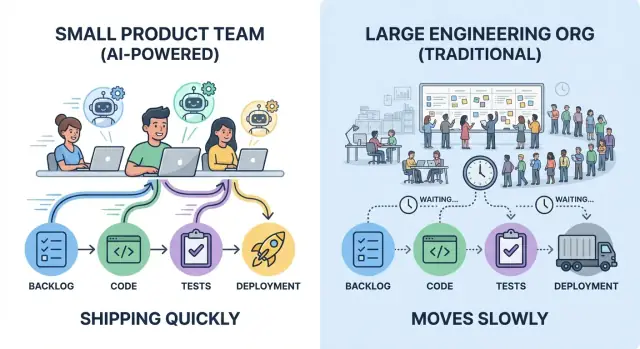
Cosa significa davvero “velocità” nella delivery di prodotto
“Rilasciare più velocemente” non è solo digitare codice in fretta. La vera velocità di delivery è il tempo che intercorre tra un'idea che diventa un miglioramento affidabile percepibile dagli utenti — e il momento in cui il team impara se ha funzionato.
Le metriche che descrivono davvero la velocità
I team discutono di velocità perché misurano cose diverse. Una visione pratica è un piccolo set di metriche di delivery:
- Lead time: quanto tempo ci vuole dal “abbiamo deciso di farlo” fino a “è live per gli utenti”.
- Cycle time: quanto tempo un pezzo di lavoro resta “in corso” una volta che qualcuno lo inizia.
- Deployment frequency: quanto spesso puoi rilasciare in sicurezza (quotidianamente, settimanalmente, on demand).
- Time-to-learning: quanto rapidamente ottieni un segnale affidabile (uso, ticket di supporto, retention, revenue) che ti dice cosa fare dopo.
Un team piccolo che deploya cinque piccole modifiche a settimana spesso impara più in fretta rispetto a un'organizzazione più grande che rilascia un grande update al mese — anche se il rilascio mensile contiene più codice.
Cosa significa “usare l'AI” (e cosa non significa)
Nella pratica, “AI per l'ingegneria” somiglia spesso a una serie di assistenti integrati nel lavoro esistente:
- Copilot per bozzare codice, refactor e documentazione
- Generazione di test e strumenti per mantenere i test
- Supporto alla code review (individuare edge case, suggerire semplificazioni)
- Bot di supporto e ops (sintetizzare incidenti, bozzare runbook, rispondere a “dove è implementato questo?”)
L'AI aiuta soprattutto ad aumentare la throughput per persona e a ridurre il rework—ma non sostituisce un buon giudizio di prodotto, requisiti chiari o ownership.
L'idea centrale: overhead vs. loop di iterazione
La velocità è principalmente limitata da due forze: overhead di coordinamento (passaggi di consegne, approvazioni, attese) e loop di iterazione (build → release → osserva → aggiusta). L'AI amplifica i team che già mantengono il lavoro piccolo, le decisioni chiare e il feedback corto.
Senza abitudini e guardrail—test, code review e disciplina di rilascio—l'AI può anche accelerare il lavoro sbagliato con la stessa efficienza.
La tassa nascosta della scala: l'overhead di coordinamento
Le grandi organizzazioni ingegneristiche non aggiungono solo persone—aggiungono connessioni. Ogni nuovo confine di team introduce lavoro di coordinamento che non rilascia funzionalità: sincronizzare priorità, allineare design, negoziare ownership e instradare modifiche attraverso i canali “giusti”.
Dove va realmente il tempo
L'overhead di coordinamento appare in punti familiari:
- Riunioni per “allineare tutti” (stato, pianificazione, allineamento roadmap)
- Review che richiedono più stakeholder (security, privacy, architettura, brand)
- Handoff tra ruoli o team (product → design → engineering → platform → SRE)
- Documentazione scritta per abilitare quegli handoff e difendere decisioni in seguito
Niente di tutto ciò è intrinsecamente negativo. Il problema è che si sommano—e crescono più velocemente delle nuove teste.
Le dipendenze creano attesa, non lavoro
In una grande organizzazione, una semplice modifica spesso attraversa diverse linee di dipendenza: un team possiede la UI, un altro l'API, un team platform gestisce il deployment, e un gruppo infosec gestisce le approvazioni. Anche se ogni gruppo è efficiente, il tempo in coda domina.
I rallentamenti comuni sembrano:
- Una feature bloccata da un board di revisione architetturale trimestrale
- Una piccola modifica API che aspetta due settimane nel backlog della piattaforma
- Un rilascio tenuto finché non si apre una finestra centrale di QA o compliance
- “Abbiamo bisogno del sign-off del Team X” che si trasforma in una catena di tre meeting
Come l'overhead allunga il lead time
Il lead time non è solo tempo di coding; è tempo trascorso dall'idea alla produzione. Ogni stretta di mano aggiuntiva aumenta la latenza: aspetti il prossimo meeting, il prossimo reviewer, il prossimo sprint, il prossimo slot nella coda di qualcun altro.
I team piccoli spesso vincono perché possono mantenere l'ownership stretta e le decisioni locali. Questo non elimina le review—riduce il numero di salti tra “pronto” e “spedito”, dove le grandi organizzazioni silenziosamente perdono giorni e settimane.
I team piccoli vincono con ownership chiara e meno handoff
La velocità non riguarda solo il digitare più veloce—riguarda far aspettare meno persone. I team piccoli tendono a spedire rapidamente quando il lavoro ha single-threaded ownership: una persona (o una coppia) chiaramente responsabile che guida una feature dall'idea alla produzione, con un decisore nominato che può risolvere i tradeoff.
La single-threaded ownership rende le decisioni economiche
Quando un proprietario è responsabile dei risultati, le decisioni non rimbalzano tra product, design, engineering e “il team platform” in un loop. L'owner raccoglie input, prende la decisione e procede.
Questo non significa lavorare da soli. Significa che tutti sanno chi sta guidando, chi approva e cosa significa “fatto”.
Meno handoff significa meno rework
Ogni handoff aggiunge due tipi di costo:
- Perdita di contesto: i dettagli vengono semplificati, le assunzioni restano non dette e gli edge case scompaiono.
- Rework: la persona successiva scopre vincoli troppo tardi e rimanda il lavoro a monte.
I team piccoli evitano questo mantenendo il problema all'interno di un loop stretto: lo stesso owner partecipa a requisiti, implementazione, rollout e follow-up. Il risultato è meno momenti “aspetta, non intendevo questo”.
Come l'AI aiuta un owner a coprire più ambiti
L'AI non sostituisce l'ownership—la estende. Un singolo owner può rimanere efficace su più attività usando l'AI per:
- Bozzare specifiche iniziali, note di rilascio e aggiornamenti per i clienti
- Riassumere thread lunghi, la storia di un incidente o decisioni precedenti in un brief breve
- Scaffolding dell'implementazione: generare boilerplate, outline di test, script di migrazione o stub client API
L'owner verifica e decide ancora, ma il tempo necessario per passare dalla pagina bianca a una bozza utilizzabile scende drasticamente.
Se usi un workflow vibe-coding (ad esempio, Koder.ai), questo modello “un owner copre l'intera slice” diventa ancora più semplice: puoi bozzare un piano, generare una UI React più un backend Go/PostgreSQL, iterare con piccoli cambi nella stessa chat—poi esportare il codice sorgente quando vuoi un controllo più stretto.
Segnali che avete una forte ownership
Cerca questi segnali operativi:
- Un backlog per iniziativa (non sparso su tool o team diversi)
- Una definizione di done, inclusi test e rollout (non “done in dev”)
- Un singolo decisore per priorità e scope
- Interfacce chiare con altri team: le richieste sono esplicite, limitate nel tempo e documentate
Quando questi segnali sono presenti, un team piccolo può muoversi con fiducia—e l'AI rende più facile sostenere quel momentum.
Loop di feedback più stretti battono i grandi piani
I grandi piani sembrano efficienti perché riducono il numero di “momenti decisionali”. Ma spesso spostano l'apprendimento alla fine—dopo settimane di costruzione—quando le modifiche costano di più. I team piccoli vanno più veloci riducendo la distanza tra un'idea e il feedback nel mondo reale.
I loop corti prevengono lavoro sprecato
Un loop di feedback corto è semplice: costruisci la cosa più piccola che può insegnarti qualcosa, mettila davanti agli utenti e decidi cosa fare dopo.
Quando il feedback arriva in giorni (non trimestri), smetti di rifinire la soluzione sbagliata. Eviti anche l'over-engineering di requisiti “just in case” che raramente si realizzano.
Come appare un apprendimento veloce
I team piccoli possono eseguire cicli leggeri che comunque producono segnali forti:
- Prototipi veloci: mock cliccabili o flussi sottili “happy path” per validare se gli utenti capiscono il valore.
- Interviste utenti precoci: 5–8 conversazioni spesso evidenziano le obiezioni principali e i pezzi mancanti.
- Iterazioni A/B rapide: piccoli cambi UI o onboarding misurati in una finestra breve possono mostrare quale direzione riduce l'attrito.
La chiave è trattare ogni ciclo come un esperimento, non come un mini-progetto.
L'AI può accelerare l'apprendimento, non solo la costruzione
La maggior leva dell'AI qui non è scrivere più codice—è comprimere il tempo da “abbiamo sentito qualcosa” a “sappiamo cosa provare dopo”. Per esempio, puoi usare l'AI per:
- Sintetizzare feedback da interviste, ticket di supporto, recensioni app o note di vendita in takeaway netti.
- Raggruppare temi (es. punti di confusione, funzionalità mancanti, problemi di fiducia) così i pattern emergono in fretta.
- Bozzare esperimenti: proporre ipotesi, metriche di successo e il test più piccolo che le confermi o smentisca.
Questo significa meno tempo in meeting di sintesi e più tempo a eseguire il test successivo.
Velocità di shipping vs. velocità di apprendimento
I team spesso celebrano la shipping velocity—quante feature sono uscite. Ma la vera velocità è la learning velocity: quanto rapidamente riduci l'incertezza e prendi decisioni migliori.
Una grande org può rilasciare molto e restare lenta se impara tardi. Un team piccolo può rilasciare meno “volume” ma muoversi più in fretta imparando prima, correggendo prima e lasciando che le prove—non le opinioni—modellino la roadmap.
L'AI come moltiplicatore di forza, non come sostituto
Accorcia il tempo per apprendere
Distribuisci presto, impara più velocemente e mantieni i rilasci abbastanza piccoli da essere sicuri.
L'AI non rende un team piccolo “più grande.” Allunga il giudizio e l'ownership esistenti del team. Il vantaggio non è che l'AI scrive codice; è che elimina gli attriti nelle parti della delivery che rubano tempo senza migliorare il prodotto.
Usi ad alto leverage che si sommano
I team piccoli ottengono guadagni sproporzionati quando puntano l'AI su lavori necessari ma raramente differenzianti:
- Generazione di boilerplate: scaffolding di nuovi endpoint, file di test, template di migrazione, config CI o componenti UI ripetitivi.
- Refactor con un piano: rinomine, estrazione di helper, conversione di pattern e aggiornamento dei punti di chiamata—soprattutto con vincoli chiari (“non cambiare comportamento”, “mantieni stabile API pubblica”).
- Bozze di documentazione: note di rilascio, outline ADR, documentazione API, guide di onboarding e “come eseguire in locale”.
Il pattern è coerente: l'AI accelera il primo 80% così gli umani possono dedicare più tempo all'ultimo 20%—la parte che richiede senso di prodotto.
Dove l'AI aiuta di più (e dove meno)
L'AI brilla nei compiti routinari, nei “problemi noti” e in tutto ciò che parte da pattern presenti nel codebase. È anche ottima per esplorare opzioni rapidamente: proporre due implementazioni, elencare tradeoff o far emergere edge case che potresti aver perso.
Aiuta meno quando i requisiti sono poco chiari, quando la decisione architetturale ha conseguenze a lungo termine, o quando il problema è molto specifico al dominio con poco contesto scritto. Se il team non sa spiegare cosa significa “done”, l'AI può solo generare output dall'aspetto plausibile più velocemente.
Velocità senza scorciatoie: la validazione è non negoziabile
Tratta l'AI come un collaboratore junior: utile, veloce e talvolta sbagliato. Gli umani devono ancora possedere il risultato.
Questo significa che ogni cambiamento assistito dall'AI dovrebbe comunque avere review, test e controlli di base. La regola pratica: usa l'AI per redigere e trasformare; usa gli umani per decidere e verificare. Così i team piccoli possono rilasciare più velocemente senza trasformare la velocità in debito futuro.
Ridurre il context switching con l'assistenza AI
Il context switching è uno dei killer silenziosi della velocità nei team piccoli. Non è solo “essere interrotti”—è il reboot mentale ogni volta che salti tra codice, ticket, doc, thread Slack e parti del sistema poco familiari. L'AI aiuta più quando trasforma quei reboot in rapide soste.
Come l'AI taglia il costo dello switching
Invece di passare 20 minuti a cercare una risposta, puoi chiedere un riassunto rapido, un riferimento ai file probabili o una spiegazione in inglese semplice di ciò che stai guardando. Usata bene, l'AI diventa un generatore di “prima bozza” per capire: può sintetizzare una PR lunga, trasformare un bug vago in ipotesi o tradurre uno stack trace minaccioso in cause probabili.
Il vantaggio non è che l'AI sia sempre corretta—è che ti orienta più in fretta così puoi prendere decisioni reali.
Tattiche pratiche che funzionano nei team reali
Alcuni pattern di prompt riducono sistematicamente il thrash:
- Chiedi opzioni: “Dammi 3 approcci per risolvere questo, con tradeoff e rischio.”
- Spiega questo codice: “Spiega cosa fa questa funzione, gli edge case e cosa si rompe se cambiamo X.”
- Genera un piano: “Crea un piano passo-passo per spedire questo in due piccole PR, includendo test.”
- Scrivi una checklist: “Checklist per rilasciare in sicurezza (monitoraggio, rollback, validazione).”
Questi prompt ti spostano dal vagare all'esecuzione.
Rendi i prompt riutilizzabili, non eroici
La velocità si somma quando i prompt diventano template usati da tutto il team. Mantieni un piccolo “kit di prompt” interno per lavori comuni: review PR, note incidente, piani di migrazione, checklist QA e runbook di rilascio. La coerenza conta: includi l'obiettivo, i vincoli (tempo, scope, rischio) e il formato di output atteso.
Limiti e guardrail
Non incollare segreti, dati clienti o qualsiasi cosa che non metteresti in un ticket. Considera gli output come suggerimenti: verifica affermazioni critiche, esegui test e ricontrolla il codice generato—specialmente su auth, pagamenti e cancellazione dati. L'AI riduce il context switching; non deve sostituire il giudizio ingegneristico.
Rilascia piccolo, rilascia spesso: pratiche che l'AI amplifica
Rilasciare più velocemente non significa fare sprint eroici; significa ridurre la dimensione di ogni cambiamento finché la delivery diventa routine. I team piccoli hanno già un vantaggio qui: meno dipendenze rendono più facile tenere il lavoro sottile. L'AI amplifica quel vantaggio accorciando il tempo tra “idea” e cambiamento sicuro e rilasciabile.
Una pipeline di delivery leggera (che scala verso il basso)
Una pipeline semplice batte una elaborata:
- Trunk-based development: integra su main frequentemente invece di branch long-lived.
- PR piccoli: cambi che possono essere revisionati in minuti, non ore.
- Deploy frequenti: rilascia ogni volta che un cambiamento è pronto, non quando un batch è “abbastanza grande”.
L'AI aiuta redigendo note di rilascio, suggerendo commit più piccoli e segnalando file probabilmente toccati insieme—spingendoti verso PR più pulite e ristrette.
Test accelerati dall'AI: coverage senza attrito
I test sono spesso il punto in cui “rilascia spesso” si inceppa. L'AI può ridurre quel freno:
- Generando test unitari/integrati iniziali da pattern di codice esistenti.
- Brainstormando edge case che potresti perdere (fusi orari, stati vuoti, retry, rate limit).
- Proponendo dati di test e mock che corrispondono alle forme reali delle API.
Tratta i test generati dall'AI come una prima bozza: revisiona per correttezza, poi conserva quelli che proteggono davvero il comportamento.
Fiducia nel rilascio: monitoraggio, alert, rollback
I deploy frequenti richiedono rilevamento rapido e recupero veloce. Imposta:
- Controlli di salute di base e dashboard per i flussi utente core
- Alert legati ai sintomi (error rate, latenza, job falliti), non a metriche di facciata
- Un rollback con un comando (o rollback automatico) così un cattivo rilascio diventa un piccolo intoppo
Se i fondamenti di delivery necessitano un ripasso, collega questo alla lettura condivisa del team: /blog/continuous-delivery-basics.
Con queste pratiche, l'AI non “ti rende più veloce” per magia—elimina i piccoli ritardi che altrimenti si accumulerebbero in cicli di settimane.
Latenza decisionale: approvazioni vs. guardrail
Riduci la latenza decisionale
Usa la Planning Mode per definire scope, rischi e Definition of Done prima di generare il codice.
Le grandi organizzazioni ingegneristiche si muovono raramente lentamente perché la gente è pigra. Si muovono lentamente perché le decisioni si accodano. I consigli architetturali si riuniscono mensilmente. Le revisioni di security e privacy restano nei backlog dei ticket. Una modifica “semplice” può richiedere review del tech lead, poi del staff engineer, poi il sign-off della platform, poi l'approvazione del release manager. Ogni passaggio aggiunge tempo d'attesa, non solo tempo di lavoro.
I team piccoli non possono permettersi quella latenza decisionale, quindi dovrebbero mirare a un modello diverso: meno approvazioni, guardrail più forti.
Cosa cercano di risolvere le approvazioni (e perché rallentano)
Le catene di approvazione sono uno strumento di gestione del rischio. Riducendo la probabilità di cambiamenti sbagliati, però centralizzano anche la decisione. Quando lo stesso piccolo gruppo deve benedire ogni cambiamento significativo, il throughput collassa e gli ingegneri iniziano a ottimizzare per “ottenere l'approvazione” anziché migliorare il prodotto.
Guardrail: l'alternativa per i team piccoli
I guardrail spostano i controlli di qualità dalle riunioni ai default:
- Standard di coding chiari e definition of done
- Checklist leggere per aree a rischio (auth, pagamenti, cancellazione dati)
- Controlli automatizzati: test, linting, type checking, dependency scanning
Invece di “Chi ha approvato questo?”, la domanda diventa “Questo è passato i gate concordati?”.
Come l'AI riduce il costo dei guardrail
L'AI può standardizzare la qualità senza aggiungere più persone al loop:
- Suggerimenti di lint e refactor per allineare il codice agli standard del team
- Summary PR che spiegano intento, scope e rischio in linguaggio semplice
- Checklist di review generate dal diff (es. “tocca PII: confermare politica di retention”) così i revisori non si affidano alla memoria
Questo migliora la consistenza e accelera le review, perché i revisori partono da un brief strutturato invece che da uno schermo bianco.
Mantenere la compliance leggera (senza saltarla)
La compliance non richiede una commissione. Rendila ripetibile:
- Definisci trigger “richiede review” (PII, movimenti di denaro, permessi)
- Usa template per le evidenze (summary PR + checklist + risultati dei test)
- Conserva le decisioni nel thread della PR così le verifiche sono a portata di ricerca
Le approvazioni diventano l'eccezione per lavori ad alto rischio; i guardrail gestiscono il resto. Così i team piccoli restano veloci senza essere imprudenti.
Il lavoro di design come thin slice per mantenere lo slancio
I grandi team spesso “progettano l'intero sistema” prima che qualcuno rilasci. I team piccoli vanno più veloci progettando thin slice: la più piccola unità verticale di valore che può andare da idea → codice → produzione ed essere usata (anche da una piccola coorte).
Cos'è realmente una thin slice
Una thin slice è ownership verticale, non una fase orizzontale. Include quel che serve tra design, backend, frontend e ops per rendere reale un risultato.
Invece di “ridisegnare l'onboarding”, una thin slice potrebbe essere “raccogliere un campo in più alla registrazione, validarlo, memorizzarlo, mostrarlo nel profilo e tracciare il completamento.” È abbastanza piccola da finire in fretta, ma completa quanto basta per imparare.
Come l'AI ti aiuta a scomporre il lavoro (senza indovinare)
L'AI è utile come partner di pensiero strutturato:
- Propone 2–4 opzioni di milestone (minimo vitale, medio, completo)
- Genera una scomposizione dei task per layer (UI, API, dati, analytics, rollout)
- Evidenzia dipendenze nascoste (migrazioni, permessi, edge case)
- Suggerisce un piano di rollout (feature flag, coorte limitata, fallback)
L'obiettivo non è più task, ma un confine shippabile e chiaro.
Definisci il “done” per ogni slice
Lo slancio muore quando il “quasi fatto” si trascina. Per ogni slice scrivi esplicite voci di Definition of Done:
- Comportamento visibile all'utente (cosa è cambiato, per chi)
- Criteri di accettazione (happy path + edge case chiave)
- Strumentazione (nomi eventi, dashboard, alert se necessario)
- Passi di deployment/rollback (o regole di feature flag)
Esempi di thin slice
- Un endpoint:
POST /checkout/quote che ritorna prezzo + tasse
- Una schermata: una pagina impostazioni per le preferenze di notifica
- Un workflow: reset password da richiesta → email → nuova password → conferma
Le thin slice tengono il design onesto: progetti ciò che puoi spedire ora, impari in fretta e lasci che la slice successiva guadagni complessità.
Rischi della velocità accelerata dall'AI (e come gestirli)
Prototipa senza sovraccarico
Valida un flusso di onboarding o impostazioni in giorni, non settimane, usando la chat per iterare.
L'AI può aiutare un team piccolo a muoversi rapidamente, ma cambia anche i modi in cui si fallisce. L'obiettivo non è “rallentare per essere sicuri”—è aggiungere guardrail leggeri così puoi continuare a spedire senza accumulare debito invisibile.
Rischi comuni quando l'AI è in gioco
Muoversi più velocemente aumenta la probabilità che spigoli grezzi arrivino in produzione. Con l'AI, alcuni rischi ricorrenti sono:
- Codice e stile inconsistenti: patch generate dall'AI possono variare in pattern, naming e architettura, rendendo il codebase più difficile da mantenere.
- Problemi di sicurezza: suggerimenti che introducono default insicuri (controlli auth deboli, validazione mancante, deserializzazione non sicura).
- Logica allucinata: il codice può sembrare plausibile ma essere sottilmente sbagliato (edge case, assunzioni errate sulle API, gestione errori inaccurata).
- Spreco di dipendenze: l'AI può introdurre nuove librerie “per facilità”, aumentando superficie d'attacco e costo di manutenzione.
Guardrail che mantengono la velocità senza il caos
Mantieni regole esplicite e facili da seguire. Alcune pratiche pagano in fretta:
- Linee guida di secure coding: una checklist breve per aree comuni (auth, permessi, validazione, logging, cifratura).
- Secret scanning in CI e hook pre-commit, più regole chiare su dove risiedono i segreti.
- Policy sulle dipendenze: lista librerie approvate, pin delle versioni e uno standard “nuova dipendenza richiede una motivazione”.
Controlli umani che contano davvero
L'AI può redigere codice; gli umani devono possedere i risultati.
- Threat modeling per cambiamenti che toccano dati, auth, pagamenti o flussi admin. Anche una review di 10 minuti cattura rischi ad alto impatto.
- Code review che si concentra sul comportamento, non solo sullo stile: input/output, percorsi d'errore, permessi e gestione dei dati.
- Strategia di testing: richiedi unit test per la logica, test di integrazione per flussi critici e un piccolo set di end-to-end ad alto segnale.
Usare l'AI in sicurezza nel quotidiano
Tratta i prompt come testo pubblico: non incollare segreti, token o dati clienti. Chiedi al modello di spiegare le assunzioni, poi verifica con fonti primarie (documentazione) e test. Quando qualcosa sembra “troppo comodo”, di solito merita un controllo più approfondito.
Se usi un ambiente di build guidato dall'AI come Koder.ai, applica le stesse regole: tieni i dati sensibili fuori dai prompt, insisti su test e review, e usa workflow con snapshot/rollback così “veloce” significa anche “recuperabile”.
Come misurare i guadagni e costruire un sistema ripetibile
La velocità conta solo se la vedi, la spieghi e la ricrei. L'obiettivo non è “usare più AI”—è avere un sistema semplice in cui le pratiche assistite dall'AI riducono in modo affidabile il time-to-value senza aumentare il rischio.
Metriche che mostrano la vera velocità di delivery (non l'attività)
Scegli un piccolo set che puoi tracciare settimanalmente:
- Cycle time: da “lavoro iniziato” a “in produzione”.
- Dimensione PR: righe/file cambiati (più piccoli di solito significano review più facili e rilasci più sicuri).
- Tempo di review: tempo mediano che una PR aspetta per la prima review e per il merge.
- Incidenti/regressioni: problemi di produzione per settimana (e gravità), più mean time to recover.
- Tempo di risposta al cliente: tempo dal feedback utente a un cambiamento rilasciato.
Aggiungi un segnale qualitativo: “Cosa ci ha rallentato di più questa settimana?” Aiuta a individuare colli di bottiglia che le metriche non mostrano.
Un ritmo operativo leggero
Mantienilo consistente e adatto ai team piccoli:
- Obiettivi settimanali (30 minuti): 1–3 risultati, non una lunga lista di task.
- Aggiornamenti asincroni giornalieri: ieri/oggi/blocchi in Slack/Linear/GitHub.
- Cadenza demo (settimanale o bisettimanale): mostra il lavoro rilasciato, non slide. Questo rinforza che “fatto” significa in mano agli utenti.
Piano di rollout di 30 giorni per i workflow AI
Settimana 1: Baseline. Misura le metriche sopra per 5–10 giorni lavorativi. Nessuna modifica ancora.
Settimane 2–3: Scegli 2–3 workflow AI. Esempi: generazione descrizione PR + checklist di rischio, assistenza nella scrittura di test, bozza note di rilascio + changelog.
Settimana 4: Confronta prima/dopo e consolida abitudini. Se la dimensione delle PR cala e il tempo di review migliora senza più incidenti, mantieni le pratiche. Se gli incidenti aumentano, aggiungi guardrail (rollout più piccoli, test migliori, ownership più chiara).
Checklist: inizia questa settimana
- Scegli 3 metriche da postare in un thread settimanale.
- Imposta un target predefinito per la dimensione delle PR (e applicalo con norme sociali, non burocrazia).
- Aggiungi uno step di “pre-review” assistito dall'AI: riassunto delle modifiche, rischi e copertura di test.
- Pianifica una demo nel calendario.
- Fai una retro sul collo di bottiglia: cosa ha causato il ritardo maggiore, e cosa cambieremo la prossima settimana?