08 lug 2025·8 min
Come creare un'app web per il monitoraggio delle dipendenze tra team
Scopri come pianificare e costruire un'app web per tracciare le dipendenze tra team: modello dati, UX, workflow, avvisi, integrazioni e passaggi di rollout.
Scopri come pianificare e costruire un'app web per tracciare le dipendenze tra team: modello dati, UX, workflow, avvisi, integrazioni e passaggi di rollout.
Prima di progettare schermate o scegliere uno stack tecnico, chiarisci cosa significa “dipendenza” nella tua organizzazione. Se tutti usano il termine per descrivere tutto, la tua app finirà per tracciare nulla in modo efficace.
Scrivi una definizione in una frase che tutti possano ripetere, poi elenca cosa qualifica. Categorie comuni includono:
Definisci anche cosa non è una dipendenza (es. “migliorie carine da avere”, rischi generali o attività interne che non bloccano un altro team). Questo mantiene il sistema pulito.
Il tracciamento delle dipendenze fallisce quando è costruito solo per PM o solo per ingegneri. Nomina i tuoi utenti principali e cosa serve a ciascuno in 30 secondi:
Scegli un piccolo set di risultati, come:
Cattura i problemi che la tua app deve risolvere dal giorno uno: fogli di calcolo obsoleti, owner poco chiari, date mancate, rischi nascosti e aggiornamenti di stato sparsi in thread chat.
Una volta allineato su cosa tracciare e per chi, blocca il vocabolario e il ciclo di vita. Definizioni condivise trasformano “una lista di ticket” in un sistema che riduce i blocchi.
Scegli un piccolo set di tipi che copre la maggior parte delle situazioni reali e rendi ogni tipo facile da riconoscere:
L'obiettivo è la coerenza: due persone dovrebbero classificare la stessa dipendenza nello stesso modo.
Un record di dipendenza dovrebbe essere piccolo ma completo abbastanza per gestirlo:
Se permetti di creare una dipendenza senza team owner o data, stai costruendo un “tracker di preoccupazioni”, non uno strumento di coordinamento.
Usa un modello di stato semplice che corrisponda al modo in cui i team lavorano realmente:
Proposed → Accepted → In progress → Ready → Delivered/Closed, oltre a Rejected.
Scrivi regole per i cambi di stato. Per esempio: “Accepted richiede un team owner e una data target iniziale”, o “Ready richiede evidenza”.
Per la chiusura, richiedi tutto quanto segue:
Queste definizioni diventano la spina dorsale dei filtri, dei promemoria e delle revisioni di stato in seguito.
Un tracker di dipendenze ha successo o fallisce in base a quanto le persone possono descrivere la realtà senza lottare con lo strumento. Parti con un piccolo set di oggetti che corrispondono al linguaggio dei team, poi aggiungi struttura dove previene confusione.
Usa una manciata di record primari:
Evita di creare tipi separati per ogni edge case. È meglio aggiungere qualche campo (es. “type: data/API/approval”) che frammentare troppo presto il modello.
Le dipendenze spesso coinvolgono più gruppi e più task. Modellalo esplicitamente:
Questo previene il pensiero fragile del tipo “una dipendenza = un ticket” e rende possibili i report aggregati.
Ogni oggetto primario dovrebbe includere campi di audit:
Non tutte le dipendenze hanno un team nella tua org chart. Aggiungi un record Owner/Contact (nome, organizzazione, email/Slack, note) e permetti alle dipendenze di puntarvi. Questo mantiene visibili blocchi da vendor o “altri dipartimenti” senza forzarli nella struttura dei team interni.
Se i ruoli non sono espliciti, il tracciamento delle dipendenze diventa un thread di commenti: tutti pensano che qualcun altro sia responsabile e le date vengono “aggiustate” senza contesto. Un modello di ruoli chiaro mantiene l'app affidabile e rende prevedibile l'escalation.
Parti con quattro ruoli quotidiani e uno amministrativo:
Rendi l'Owner richiesto e singolare: una dipendenza, un owner responsabile. Puoi comunque supportare collaboratori (contributori di altri team), ma i collaboratori non devono sostituire la responsabilità.
Aggiungi un percorso di escalation quando un Owner non risponde: prima ping all'Owner, poi al loro manager (o team lead), poi a un owner di programma/release—in base alla struttura della tua org.
Separa “modificare dettagli” da “cambiare impegni”. Un default pratico:
Se supporti iniziative private, definisci chi può vederle (es. solo i team coinvolti + Admin). Evita “dipendenze segrete” che sorprendono i team di delivery.
Non nascondere la responsabilità in un documento di policy. Mostrala in ogni dipendenza:
Etichettare direttamente “Accountable vs Consulted” nel form riduce i rimbalzi e velocizza le revisioni di stato.
Un tracker funziona solo se le persone trovano i loro elementi in pochi secondi e li aggiornano senza pensarci. Progetta attorno alle domande più comuni: “Cosa sto bloccando?”, “Cosa mi blocca?” e “Sta per slittare qualcosa?”.
Inizia con un piccolo set di viste che rispecchiano il modo in cui i team parlano del lavoro:
La maggior parte degli strumenti fallisce nell’“aggiornamento quotidiano”. Ottimizza per la velocità:
Usa colore + etichetta testuale (mai solo colore) e mantieni il vocabolario coerente. Aggiungi un prominente “Last updated” su ogni dipendenza e un avviso di stale quando non è stata toccata per un periodo definito (es. 7–14 giorni). Questo stimola aggiornamenti senza imporre riunioni.
Ogni dipendenza dovrebbe avere un singolo thread che contiene:
Quando la pagina di dettaglio racconta tutta la storia, le revisioni di stato sono più veloci—e molte “sync veloci” spariscono perché la risposta è già scritta.
Un tracker di dipendenze vive o muore sulle azioni quotidiane che supporta. Se i team non possono rapidamente richiedere lavoro, rispondere con un impegno chiaro e chiudere il ciclo con prove, la tua app diventa una “bacheca FYI” anziché uno strumento di esecuzione.
Inizia con un unico flusso “Crea richiesta” che cattura cosa il team fornitore deve consegnare, perché è importante e quando serve. Mantienilo strutturato: data richiesta, criteri di accettazione e link all'epic/spec rilevante.
Da lì, applica uno stato di risposta esplicito:
Questo evita il fallimento più comune: dipendenze silenziose “forse” che sembrano a posto finché non esplodono.
Definisci aspettative leggere nel workflow stesso. Esempi:
Lo scopo non è polizia; è mantenere gli impegni aggiornati per una pianificazione onesta.
Permetti ai team di impostare una dipendenza su At risk con una breve nota e il prossimo step. Quando qualcuno cambia una data o uno stato, richiedi un motivo (dropdown + testo libero). Questa singola regola crea una traccia di audit che rende retrospettive ed escalation fattuali, non emotive.
“Chiudi” dovrebbe significare che la dipendenza è soddisfatta. Richiedi evidenza: link a un PR mergiato, ticket rilasciato, documento o una nota di approvazione. Se la chiusura è sfumata, i team segneranno gli elementi “green” prematuramente per ridurre il rumore.
Supporta aggiornamenti in blocco durante le review di stato: seleziona più dipendenze e imposta lo stesso stato, aggiungi una nota condivisa (es. “replanned dopo reset Q1”) o richiedi aggiornamenti. Questo mantiene l'app abbastanza veloce da usare nelle riunioni reali, non solo dopo.
Le notifiche dovrebbero proteggere la delivery, non distrarre le persone. Il modo più facile per generare rumore è avvisare tutti su tutto. Disegna gli avvisi attorno a punti decisionali (qualcuno deve agire) e segnali di rischio (qualcosa sta deragliando).
Mantieni la prima versione focalizzata su eventi che cambiano il piano o richiedono una risposta esplicita:
Ogni trigger dovrebbe mappare a un passo successivo chiaro: accept/decline, proporre una nuova data, aggiungere contesto o escalare.
Default a notifiche in-app (così gli avvisi sono legati al record della dipendenza) più email per cose che non possono aspettare.
Offri integrazioni chat opzionali—Slack o Microsoft Teams—ma trattale come meccanismi di consegna, non come sistema di verità. I messaggi chat dovrebbero rimandare profondamente all'item (es. /dependencies/123) e includere il minimo contesto: chi deve agire, cosa è cambiato e entro quando.
Fornisci controlli a livello di team e utente:
Qui entrano in gioco anche i “watchers”: notifica il requester, il team owner e gli stakeholder esplicitamente aggiunti—evita broadcast ampi.
L'escalation dovrebbe essere automatica ma conservativa: avvisa quando una dipendenza è in ritardo, quando la data è stata spostata ripetutamente, o quando uno stato blocked non ha aggiornamenti per un periodo definito.
Indirizza le escalation al livello giusto (team lead, program manager) e includi la cronologia in modo che il destinatario possa agire rapidamente senza inseguire il contesto.
Le integrazioni dovrebbero eliminare la reinserimento, non aggiungere overhead di setup. L'approccio più sicuro è partire dai sistemi che i team già usano (issue tracker, calendari e identity), mantenere la prima versione in sola lettura o unidirezionale, poi espandere solo quando le persone fanno affidamento su di essa.
Scegli un tracker primario (Jira, Linear o Azure DevOps) e supporta un flusso link-first semplice:
PROJ-123).Questo evita “due fonti di verità” mentre fornisce visibilità sulle dipendenze. Dopo, aggiungi sync bidirezionale opzionale per un piccolo sottoinsieme di campi (status, due date), con regole di conflitto chiare.
Milestone e scadenze sono spesso mantenute in Google Calendar o Microsoft Outlook. Parti leggendo gli eventi nella tua timeline delle dipendenze (es. “Release Cutoff”, “UAT Window”) senza scrivere nulla indietro.
La sincronizzazione calendar in sola lettura permette ai team di continuare a pianificare dove già lo fanno, mentre la tua app mostra impatti e date imminenti in un unico posto.
Single sign-on riduce l'attrito di onboarding e la deriva dei permessi. Scegli in base alla realtà del cliente:
Se sei agli inizi, spediscine uno primo e documenta come richiedere gli altri.
Anche i team non tecnici beneficiano quando ops interne possono automatizzare handoff. Fornisci pochi endpoint e webhook con esempi copy-paste.
# Create a dependency from a release checklist
curl -X POST /api/dependencies \\
-H "Authorization: Bearer $TOKEN" \\
-d '{"title":"API contract from Payments","trackerUrl":"https://jira/.../PAY-77"}'
I webhooks come dependency.created e dependency.status_changed permettono ai team di integrare strumenti interni senza aspettare la tua roadmap. For more, link to /docs/integrations.
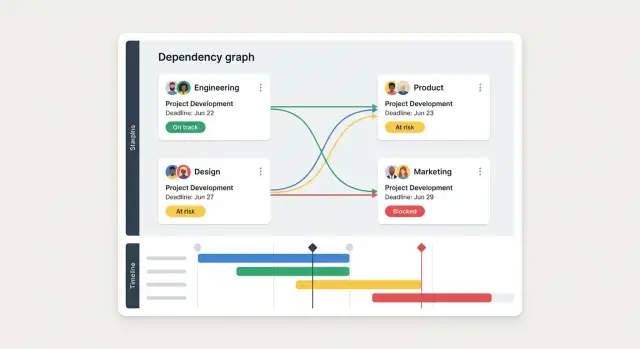
I cruscotti sono dove un'app di dipendenze guadagna il suo peso: trasformano “penso che siamo bloccati” in un quadro condiviso chiaro di cosa richiede attenzione prima del prossimo check-in.
Un solo cruscotto “one size fits all” solitamente fallisce. Progetta invece alcune viste che corrispondono a come le persone conducono le riunioni:
Costruisci un piccolo set di report che le persone useranno davvero nelle review:
Ogni report dovrebbe rispondere: “Chi deve fare cosa dopo?” Includi owner, data prevista e ultimo aggiornamento.
Rendi il filtraggio veloce e ovvio, perché la maggior parte delle riunioni inizia con “mostrami solo…”.
Supporta filtri come team, iniziativa, stato, intervallo date, livello rischio e tag (es. “security review”, “data contract”, “release train”). Salva set di filtri comuni come viste nominate (es. “Release A — prossimi 14 giorni”).
Non tutti vivranno nella tua app tutto il giorno. Fornisci:
Se offri un livello a pagamento, conserva controlli di condivisione admin-friendly e rimanda a /pricing per i dettagli.
Non serve una piattaforma complessa per spedire un'app web di tracciamento dipendenze. Un MVP può essere un sistema semplice in tre parti: UI web per le persone, API per regole e integrazioni, e un database come fonte di verità. Ottimizza per “facile da cambiare” più che per “perfetto”. Imparerai più dall'uso reale che da mesi di architettura upfront.
Un punto di partenza pragmatico potrebbe essere:
Se prevedi integrazioni Slack/Jira a breve, mantieni le integrazioni come moduli/jobs separati che parlano alla stessa API, invece di permettere a tool esterni di scrivere direttamente nel database.
Se vuoi arrivare velocemente a un prodotto funzionante senza costruire tutto da zero, un workflow di sviluppo assistito può aiutare: per esempio, Koder.ai può generare una UI React e un backend Go + PostgreSQL da una specifica chat-based, poi lasciarti iterare usando planning mode, snapshot e rollback. Continui a possedere le decisioni architetturali, ma accorci il percorso da “requirements” a “pilot utilizzabile” e puoi esportare il codice sorgente quando sei pronto a portarlo in-house.
La maggior parte delle schermate sono liste: dipendenze aperte, blocchi per team, cambiamenti della settimana. Progetta per questo:
I dati delle dipendenze possono includere dettagli sensibili di delivery. Usa least-privilege access (visibilità a livello di team dove appropriato) e mantieni audit log per le modifiche—chi ha cambiato cosa e quando. Quella traccia riduce i dibattiti nelle revisioni di stato e rende lo strumento affidabile.
Lanciare un'app per il tracciamento delle dipendenze riguarda più il cambiare abitudini che le funzionalità. Tratta il rollout come un lancio prodotto: inizia in piccolo, dimostra valore, poi scala con un ritmo operativo chiaro.
Scegli 2–4 team che lavorano su una iniziativa condivisa (es. un release train o un programma cliente). Definisci criteri di successo misurabili in poche settimane:
Mantieni la configurazione del pilot minima: solo campi e viste necessari a rispondere a “Cosa è bloccato, da chi e entro quando?”.
La maggior parte dei team già traccia dipendenze in spreadsheet. Importali, ma intenzionalmente:
Esegui una breve passata di QA con gli utenti pilota per confermare definizioni e correggere voci ambigue.
L'adozione rimane quando l'app supporta una cadenza esistente. Fornisci:
Se costruisci rapidamente (es. iterando il pilot con Koder.ai), usa ambienti/snapshot per testare cambi a campi obbligatori, stati e cruscotti con i team pilota—poi avanza (o fai rollback) senza interrompere tutti.
Traccia dove gli utenti si bloccano: campi confusi, stati mancanti o viste che non rispondono alle domande delle review. Rivedi il feedback settimanalmente durante il pilot, poi aggiusta campi e viste predefinite prima di invitare altri team. Un semplice link “Report an issue” a /support aiuta a mantenere il loop chiuso.
Una volta live, i rischi maggiori non sono tecnici—sono comportamentali. La maggior parte dei team non abbandona gli strumenti perché “non funzionano”, ma perché aggiornarli sembra facoltativo, confuso o pieno di rumore.
Troppi campi. Se creare una dipendenza sembra compilare un modulo, le persone la ritarderanno o la salteranno. Parti con un set minimo di campi obbligatori: titolo, team requester, team owner, “next action”, data e stato.
Proprietà non chiara. Se non è ovvio chi deve agire dopo, le dipendenze diventano thread di stato. Rendi esplicito l’owner e il “next action owner” e mostrali in modo prominente.
Nessuna abitudine di aggiornamento. Anche una UI ottima fallisce se gli elementi diventano stale. Aggiungi spinte leggere: evidenzia elementi stale, invia promemoria solo quando la data si avvicina o l'ultimo aggiornamento è vecchio, e rendi gli aggiornamenti facili (cambio stato con un click + breve nota).
Sovraccarico di notifiche. Se ogni commento avvisa tutti, gli utenti silenzieranno il sistema. Di default usa “watchers” opt-in e invia riepiloghi (giornalieri/settimanali) per le urgenze basse.
Tratta “next action” come campo di prima classe: ogni dipendenza aperta dovrebbe avere sempre un prossimo passo chiaro e una singola persona responsabile. Se manca, l'elemento non dovrebbe sembrare “completo” nelle viste chiave.
Definisci anche cosa significa “fatto” (es. risolto, non più necessario o spostato in un altro tracker) e richiedi una breve motivazione di chiusura per evitare elementi zombie.
Decidi chi gestisce tag, lista team e categorie. Tipicamente è un program manager o un ruolo ops con controllo leggero dei cambiamenti. Imposta una policy di ritiro semplice: archivia automaticamente le iniziative vecchie dopo X giorni dalla chiusura e rivedi tag inutilizzati trimestralmente.
Dopo che l'adozione si stabilizza, considera miglioramenti che aggiungono valore senza aumentare l'attrito:
Se ti serve un modo strutturato per prioritizzare, collega ogni idea a un rituale di review (riunione settimanale, pianificazione release, retro incident) così i miglioramenti sono guidati dall'uso reale, non da ipotesi.
Inizia con una definizione in una frase che tutti possano ripetere, poi elenca cosa rientra (work item, deliverable, decisione, ambiente/accesso).
Scrivi anche cosa non conta (nice-to-have, rischi generali, attività interne che non bloccano un altro team). Questo impedisce allo strumento di diventare un vago "tracker di preoccupazioni".
Al minimo progetta per:
Se costruisci per un solo gruppo, gli altri non lo aggiorneranno e il sistema diventerà obsoleto.
Usa un ciclo di vita piccolo e coerente come:
Poi definisci regole per i cambi di stato (es. “Accepted richiede un team owner e una data target”, “Ready richiede evidenza”). La coerenza conta più della complessità.
Richiedi solo ciò che serve per coordinare:
Se permetti owner o data mancanti, raccoglierai elementi su cui non si può agire.
Rendi il "done" verificabile. Richiedi:
Questo evita aggiornamenti "in verde" prematuri solo per ridurre il rumore.
Definisci quattro ruoli di uso quotidiano più l'admin:
Mantieni “una dipendenza, un owner” per evitare ambiguità; usa collaboratori solo come supporto.
Parti con le viste che rispondono alle domande quotidiane:
Ottimizza per aggiornamenti veloci: template, editing inline, controlli keyboard-friendly e un chiaro “Last updated”.
Allerta solo su punti decisionali e segnali di rischio:
Usa watchers invece di broadcast, supporta modalità digest e deduplicazione (un riepilogo per dipendenza per finestra temporale).
Integra per eliminare la doppia immissione, non per creare una seconda fonte di verità:
Tratta chat (Slack/Teams) come canale di consegna che rimanda sempre al record, non come sistema di verità.
Esegui un pilot mirato prima di scalare:
Tratta "nessun owner o data" come incompleto e iterare su dove gli utenti si bloccano.