30 dic 2025·8 min
Triage dei bug con Claude Code: un ciclo pratico per correzioni rapide
Triage dei bug con Claude Code usando un ciclo ripetibile: riprodurre, minimizzare, identificare cause probabili, aggiungere un test di regressione e distribuire una correzione mirata con controlli.
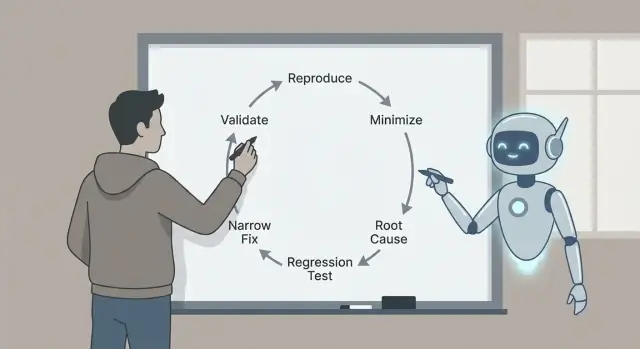
Cosa è il triage dei bug e perché il ciclo conta
I bug sembrano casuali quando ogni segnalazione diventa un mistero isolato. Tocchi il codice, provi qualche idea e speri che il problema scompaia. A volte succede, ma non impari molto, e lo stesso problema ricompare in un'altra forma.
Il triage dei bug è l'opposto. È un modo rapido per ridurre l'incertezza. L'obiettivo non è sistemare tutto subito. L'obiettivo è trasformare un reclamo vago in un'affermazione chiara e testabile, poi fare la modifica più piccola che dimostri che quell'affermazione è falsa.
Per questo il ciclo è importante: riprodurre, minimizzare, identificare le cause probabili con evidenze, aggiungere un test di regressione, implementare una correzione mirata e validare. Ogni passaggio elimina un tipo specifico di supposizione. Saltarne alcuni spesso si paga in seguito con correzioni più grandi, effetti collaterali o bug “risolti” che in realtà non lo erano.
Ecco un esempio realistico. Un utente dice: “Il pulsante Salva a volte non fa nulla.” Senza un ciclo, potresti rovistare nel codice UI e cambiare timing, stato o chiamate di rete. Con il ciclo, prima trasformi “a volte” in “sempre, in queste condizioni esatte”, ad esempio: “Dopo aver modificato un titolo, poi cambiando rapidamente scheda, Salva rimane disabilitato.” Quella singola frase è già progresso.
Claude Code può accelerare la parte di analisi: trasformare segnalazioni in ipotesi precise, suggerire dove guardare e proporre un test minimo che dovrebbe fallire. È particolarmente utile per scansionare codice, log e diff recenti per generare spiegazioni plausibili rapidamente.
Devi però verificare ciò che conta. Conferma che il bug esiste nel tuo ambiente. Preferisci evidenze (log, trace, test che falliscono) a una storia convincente. Mantieni la correzione il più piccola possibile, dimostrala con un test di regressione e convalidala con controlli chiari così non cambi un bug con un altro.
Il risultato è una correzione piccola e sicura che puoi spiegare, difendere e mantenere senza regressioni.
Prepara lo spazio di lavoro per il triage (prima di toccare il codice)
Le buone correzioni partono da uno spazio di lavoro pulito e da un singolo problema chiaro. Prima di chiedere qualsiasi cosa a Claude, scegli una segnalazione e riscrivila come:
“Quando faccio X, mi aspetto Y, ma ottengo Z.”
Se non riesci a scrivere quella frase, non hai ancora un bug. Hai un mistero.
Raccogli le informazioni di base fin da subito così non dovrai continuare a tornare indietro. Questi dettagli rendono i suggerimenti testabili invece che vaghi: versione dell'app o commit (e se è locale, staging o produzione), dettagli dell'ambiente (OS, browser/dispositivo, feature flag, regione), input esatti (campi del form, payload API, azioni utente), chi lo vede (tutti, un ruolo, un singolo account/tenant) e cosa significa “atteso” (testo, stato UI, codice di stato, regola di business).
Poi conserva le evidenze finché sono fresche. Un singolo timestamp può farti risparmiare ore. Cattura i log attorno all'evento (client e server se possibile), uno screenshot o una breve registrazione, ID richiesta o trace, timestamp esatti (con timezone) e lo snippet di dati più piccolo che scatena il problema.
Esempio: un'app React generata da Koder.ai mostra “Pagamento riuscito” ma l'ordine resta “In sospeso”. Nota il ruolo utente, l'ID ordine esatto, il body della risposta API e le righe di log server per quell'ID richiesta. Ora puoi chiedere a Claude di concentrarsi su un solo flusso invece di usare frasi vaghe.
Infine, stabilisci una regola di stop. Decidi cosa conterà come risolto prima di iniziare a codare: un test specifico che passa, uno stato UI che cambia, un errore che non appare più nei log, più una breve checklist di validazione che eseguirai ogni volta. Questo ti evita di “sistemare” il sintomo e consegnare un nuovo bug.
Trasforma la segnalazione in una domanda precisa per Claude
Un report disordinato di solito mescola fatti, supposizioni e frustrazione. Prima di chiedere aiuto, convertilo in una domanda netta che Claude può rispondere con evidenze.
Comincia con un sommario in una frase che nomini la feature e il fallimento. Buono: “Il salvataggio di una bozza a volte cancella il titolo su mobile.” Non buono: “Le bozze sono rotte.” Quella frase diventa l'ancora per l'intero thread di triage.
Poi separa ciò che hai visto da ciò che ti aspettavi. Mantieni il tutto noioso e concreto: il pulsante esatto che hai cliccato, il messaggio sullo schermo, la riga di log, il timestamp, il dispositivo, il browser, il branch, il commit. Se non hai quei dati, dillo.
Una struttura semplice che puoi incollare:
- Sommario (una frase)
- Comportamento osservato (cosa è successo, incluso testo di errore)
- Comportamento atteso (cosa avrebbe dovuto succedere)
- Passaggi di repro (numerati, il set più piccolo che conosci)
- Ambiente (versione app, dispositivo, OS, browser, flag di configurazione)
Se mancano dettagli, chiedili come domande sì/no così le persone possono rispondere velocemente: Succede su un account nuovo? Solo su mobile? Solo dopo un refresh? È iniziato dopo l'ultimo rilascio? Si riproduce in incognito?
Claude è utile anche come “pulitore di report”. Incolla il report originale (inclusi testi copiati da screenshot, log e chat) e poi chiedi:
“Riformula questo come una checklist strutturata. Evidenzia contraddizioni. Elenca le 5 informazioni mancanti più importanti come domande sì/no. Non indagare sulle cause ancora.”
Se un collega dice “Fallisce casualmente,” spingilo verso qualcosa testabile: “Fallisce 2/10 su iPhone 14, iOS 17.2, quando si tocca Salva due volte velocemente.” Ora puoi riprodurlo intenzionalmente.
Step 1 - Riprodurre il bug in modo affidabile
Se non riesci a far succedere il bug a comando, ogni passo successivo è congettura.
Inizia riproducendolo nell'ambiente più piccolo che ancora lo mostra: una build dev locale, un branch minimale, un dataset ridotto e il minor numero possibile di servizi attivi.
Scrivi i passaggi esatti così qualcun altro può seguirli senza chiedere chiarimenti. Rendi tutto copy-paste friendly: comandi, ID e payload di esempio devono essere inclusi esattamente come usati.
Un template semplice per la cattura:
- Setup: branch/commit, flag di configurazione, stato DB (vuoto, seedato, copia prod)
- Passaggi: azioni numerate con input esatti
- Atteso vs reale: cosa pensavi sarebbe successo, cosa è successo invece
- Evidenza: testo di errore, screenshot, timestamp, ID richiesta
- Frequenza: sempre, a volte, solo alla prima esecuzione, solo dopo un refresh
La frequenza cambia la strategia. I bug “sempre” sono ottimi per iterazioni rapide. I bug “a volte” spesso indicano timing, caching, race condition o stato nascosto.
Una volta che hai le note di riproduzione, chiedi a Claude suggerimenti rapidi che riducono l'incertezza senza riscrivere l'app. Buoni sondaggi sono piccoli: una riga di log mirata attorno al punto di rottura (input, output, stato chiave), una flag di debug per un singolo componente, un modo per forzare comportamento deterministico (seed fisso, tempo fisso, worker singolo), un dataset minimo che scatena il problema o una singola richiesta/risposta da riprodurre.
Esempio: un flusso di signup fallisce “a volte”. Claude potrebbe suggerire di loggare l'ID utente generato, il risultato della normalizzazione email e i dettagli dell'errore di vincolo di unicità, poi rieseguire lo stesso payload 10 volte. Se il fallimento avviene solo alla prima esecuzione dopo il deploy, è un forte indizio per controllare migration, warmup cache o dati seed mancanti.
Step 2 - Minimizzare fino a un piccolo test ripetibile
Riproduci problemi mobile
Ricrea bug esclusivi per mobile in Flutter e valida la sequenza di tap esatta.
Una buona riproduzione è utile. Una riproduzione minima è potente. Rende il bug più veloce da capire, più semplice da debug e meno soggetta a “fixare” accidentalmente.
Elimina tutto ciò che non è necessario. Se il bug appare dopo un lungo flow UI, trova il percorso più corto che lo attiva. Rimuovi schermate opzionali, flag e integrazioni non correlate finché il bug o scompare (hai rimosso qualcosa di essenziale) o resta (hai trovato il rumore).
Poi riduci i dati. Se il bug necessita di un payload grande, prova il payload più piccolo che ancora rompe. Se serve una lista di 500 elementi, verifica se 5 falliscono, poi 2, poi 1. Rimuovi campi uno per uno. L'obiettivo è meno parti in movimento possibile che ancora riproducono il bug.
Un metodo pratico è “rimuovi metà e ritesta”:
- Taglia i passaggi a metà e verifica se il bug persiste.
- Se sì, tieni la metà rimanente e taglia ancora.
- Se no, ripristina metà di ciò che hai rimosso e taglia di nuovo.
- Ripeti finché non puoi più rimuovere nulla senza perdere il bug.
Esempio: una pagina di checkout va in crash “a volte” quando si applica un coupon. Scopri che fallisce solo quando il carrello ha almeno un articolo scontato, il coupon è in minuscolo e la spedizione è impostata su “ritiro”. Questo è il caso minimale: un articolo scontato, un coupon minuscolo e opzione ritiro.
Una volta chiaro il caso minimale, chiedi a Claude di trasformarlo in un piccolo scaffold di riproduzione: un test minimo che chiama la funzione che fallisce con gli input più piccoli, uno script corto che colpisce un endpoint con un payload ridotto o un piccolo test UI che visita una route e compie un'azione.
Step 3 - Identificare le probabili cause radice (con evidenze)
Quando puoi riprodurre il problema e hai un caso di test piccolo, smetti di indovinare. L'obiettivo è arrivare a una breve lista di cause plausibili e poi provare o scartare ciascuna.
Una regola utile è tenerla a tre ipotesi. Se ne hai più di tre, il tuo caso di test è probabilmente ancora troppo grande o le osservazioni sono troppo vaghe.
Mappa i sintomi ai componenti
Traduci ciò che vedi in dove potrebbe succedere. Un sintomo UI non significa sempre un bug UI.
Esempio: una pagina React mostra un toast “Salvato”, ma il record manca dopo. Può indicare (1) stato UI, (2) comportamento API, o (3) percorso di scrittura nel DB.
Costruisci evidenze per ogni ipotesi
Chiedi a Claude di spiegare i possibili modi in cui può fallire in linguaggio semplice, poi chiedi quale prova confermerebbe ciascuna ipotesi. L'obiettivo è trasformare “forse” in “controlla questa cosa esatta”.
Tre ipotesi comuni e le evidenze da raccogliere:
- Disallineamento UI/stato: il client aggiorna lo stato locale prima che il server confermi. Prova: cattura uno snapshot di stato prima e dopo l'azione e confrontalo con la risposta API reale.
- Caso limite API: l'handler restituisce 200 ma scarta silenziosamente il lavoro (validazione, parsing ID, feature flag). Prova: aggiungi log richieste/risposte con ID di correlazione e verifica che l'handler arrivi alla chiamata di scrittura con gli input attesi.
- Problema di DB o timing: una transazione fa rollback, si verifica un conflitto, o il “read after write” arriva da una cache/replica. Prova: ispeziona la query DB, le righe interessate e i codici di errore; logga i confini di transazione e il comportamento di retry.
Tieni le note compatte: sintomo, ipotesi, evidenza, verdetto. Quando un'ipotesi combacia con i fatti, sei pronto per fissare un test di regressione e correggere solo ciò che serve.
Step 4 - Aggiungere un test di regressione che fallisca per la ragione giusta
Un buon test di regressione è la tua cintura di sicurezza. Dimostra che il bug esiste e ti dice quando è veramente risolto.
Comincia scegliendo il test più piccolo che corrisponde al fallimento reale. Se il bug appare solo quando più parti collaborano, un unit test potrebbe non coglierlo.
Scegli il livello di test che corrisponde al bug
Usa un unit test quando una singola funzione restituisce il valore sbagliato. Usa un integration test quando il confine tra parti è il problema (handler API più DB, o UI più stato). Usa end-to-end solo se il bug dipende dall'intero flusso utente.
Prima di chiedere a Claude di scrivere qualcosa, riformula il caso minimizzato come comportamento atteso preciso. Esempio: “Quando l'utente salva un titolo vuoto, l'API deve restituire 400 con il messaggio 'title required'.” Ora il test ha un obiettivo chiaro.
Poi fai scrivere a Claude una bozza di test fallente. Mantieni il setup minimo e copia solo i dati che scatenano il bug. Nomina il test con il focus sull'esperienza utente, non sulla funzione interna.
Verifica la bozza (non fidarti ciecamente)
Fai una rapida ricontrollata:
- Conferma che fallisce sul codice corrente per la ragione prevista (non per fixture mancanti o import sbagliati).
- Controlla che le asserzioni siano specifiche (codice di stato esatto, messaggio, testo renderizzato).
- Assicurati che il test copra un solo bug, non un insieme di comportamenti.
- Mantieni il nome focalizzato sull'utente, tipo “rifiuta titolo vuoto al salvataggio” invece di “gestisce validazione”.
Quando il test fallisce per la ragione giusta, sei pronto per implementare una correzione mirata con fiducia.
Step 5 - Implementare una correzione mirata
Revisiona le correzioni su un URL reale
Condividi una build di test stabile con gli stakeholder usando un dominio personalizzato quando serve.
Quando hai un piccolo repro e un test di regressione che fallisce, resisti alla tentazione di “pulire tutto”. L'obiettivo è fermare il bug con la modifica più piccola che renda il test verde per la ragione giusta.
Una buona correzione mirata modifica la superficie minima possibile. Se il fallimento è in una funzione, correggi quella funzione, non tutto il modulo. Se manca un controllo di confine, aggiungi il controllo al confine, non su tutta la catena di chiamate.
Se usi Claude per aiutarti, chiedi due opzioni di fix e poi confrontale per ampiezza e rischio. Esempio: se un form React va in crash quando un campo è vuoto, potresti ottenere:
- Opzione A: Aggiungi una guardia nell'handler di submit che blocca l'input vuoto e mostra un errore.
- Opzione B: Rifattorizza la gestione dello stato in modo che il campo non possa mai essere vuoto.
L'opzione A è spesso la scelta di triage: più piccola, più facile da revisionare e meno probabile che rompa altro.
Per mantenere la correzione stretta, tocca il minor numero di file possibile, preferisci fix locali ai refactor, aggiungi guardie e validazioni dove entra il valore errato e mantieni il cambiamento esplicito con un chiaro prima/dopo. Lascia commenti solo quando la ragione non è ovvia.
Esempio concreto: un endpoint Go panicava quando un parametro query opzionale mancava. La correzione mirata è gestire la stringa vuota al confine dell'handler (parse con valore di default o restituire 400 con messaggio chiaro). Evita di cambiare utilità di parsing condivise a meno che il test di regressione non dimostri che il bug è lì.
Dopo la modifica, riesegui il test fallente e uno o due test vicini. Se la correzione richiede di aggiornare molti test non correlati, è un segnale che il cambiamento è troppo ampio.
Step 6 - Validare la correzione con controlli chiari
La validazione è dove catturi i piccoli problemi facili da perdere: una correzione che passa un test ma rompe un percorso vicino, cambia un messaggio di errore o aggiunge una query lenta.
Prima, riesegui il test di regressione che hai aggiunto. Se passa, esegui i "vicini": test nello stesso file, nello stesso modulo e tutto ciò che copre gli stessi input. I bug spesso si nascondono in helper condivisi, parsing, controlli di confine o caching, quindi i fallimenti più rilevanti solitamente appaiono vicino.
Poi fai un rapido controllo manuale seguendo i passaggi originali del report. Mantienilo breve e specifico: stesso ambiente, stessi dati, stessa sequenza di click o chiamate API. Se il report era vago, testa lo scenario esatto che hai usato per riprodurlo.
Una semplice checklist di validazione
- Il test di regressione passa, più i test correlati nell'area.
- I passaggi manuali di repro non scatenano più il bug.
- La gestione degli errori ha ancora senso (messaggi, codici di stato, retry).
- I casi limite si comportano ancora correttamente (input vuoto, dimensioni massime, caratteri strani).
- Nessuna evidente regressione di performance (loop in più, chiamate extra, query lente).
Se vuoi aiuto per restare concentrato, chiedi a Claude un breve piano di validazione basato sulla tua modifica e sullo scenario fallito. Condividi quale file hai cambiato, quale comportamento intendevi e cosa potrebbe essere plausibilmente influenzato. I migliori piani sono brevi ed eseguibili: 5–8 controlli finibili in pochi minuti, ognuno con pass/fail chiaro.
Infine, registra cosa hai validato nella PR o nelle note: quali test hai eseguito, quali passaggi manuali hai provato e eventuali limiti (per esempio, “non testato su mobile”). Questo rende la correzione più affidabile e più facile da rivedere in seguito.
Errori comuni e trappole (e come evitarli)
Rendi i report azionabili
Trasforma segnalazioni vaghe in enunciati X–Y–Z chiari e passaggi riproducibili.
Il modo più veloce per perdere tempo è accettare una “correzione” prima di poter riprodurre il problema su comando. Se non puoi farlo fallire in modo affidabile, non puoi sapere cosa è davvero migliorato.
Una regola pratica: non chiedere correzioni finché non puoi descrivere un setup ripetibile (passaggi esatti, input, ambiente e cosa significa “sbagliato”). Se il report è vago, dedica i primi minuti a trasformarlo in una checklist che puoi eseguire due volte e ottenere lo stesso risultato.
Trappole che rallentano
Correggere senza un caso riproducibile. Richiedi uno script minimale o una serie di passaggi che falliscano sempre. Se è “a volte”, cattura timing, dimensione dei dati, flag e log finché non smette di essere casuale.
Minimizzare troppo presto. Se riduci il caso prima di aver confermato il fallimento originale, puoi perdere il segnale. Blocca prima la riproduzione di base, poi riducila un cambiamento alla volta.
Lasciare che Claude indovini. Claude può proporre cause probabili, ma serve comunque evidenza. Chiedi 2–3 ipotesi e le esatte osservazioni che confermerebbero o smentirebbero ognuna (una riga di log, un breakpoint, un risultato di query).
Test di regressione che passano per la ragione sbagliata. Un test può “passare” perché non tocca mai il percorso fallente. Assicurati che fallisca prima della correzione e che fallisca con il messaggio o l'asserzione attesi.
Trattare i sintomi invece che il trigger. Se aggiungi un controllo null ma il vero problema è “questo valore non dovrebbe mai essere null”, potresti nascondere un bug più profondo. Preferisci correggere la condizione che crea lo stato errato.
Un rapido controllo di sanità prima di chiudere
Esegui il nuovo test di regressione e i passaggi di repro originali prima e dopo la modifica. Se un bug di checkout avviene solo quando un codice promo è applicato dopo aver cambiato la spedizione, conserva quella sequenza completa come la tua “verità”, anche se il test minimizzato è più piccolo.
Se la tua validazione si basa su “sembra a posto ora”, aggiungi un controllo concreto (un log, una metrica o un output specifico) così la prossima persona può verificarlo rapidamente.
Una checklist rapida, template di prompt e prossimi passi
Quando sei sotto pressione, un piccolo ciclo ripetibile batte il debugging eroico.
Checklist di triage in una pagina
- Riproduci: ottieni un repro affidabile e annota input, ambiente e atteso vs reale.
- Minimizza: riduci ai passaggi o al test più piccolo che ancora fallisce.
- Spiega: elenca 2–3 probabili cause radice e le evidenze per ciascuna.
- Blocca: aggiungi un test di regressione che fallisca per la ragione giusta.
- Correggi + valida: fai la modifica più stretta, poi esegui una breve checklist di validazione.
Scrivi la decisione finale in poche righe così la prossima persona (spesso il te futuro) può fidarsi. Un formato utile è: “Causa radice: X. Trigger: Y. Fix: Z. Perché sicuro: W. Cosa non abbiamo cambiato: Q.”
Template di prompt che puoi incollare
- “Given this bug report and logs, ask me only the missing questions needed to reproduce it reliably.”
- “Help me minimize: propose a smaller test case and tell me what to remove first, one change at a time.”
- “Rank likely root causes and cite the exact files, functions, or conditions that support each claim.”
- “Write a regression test that fails only because of this bug. Explain why it fails for the right reason.”
- “Suggest the narrowest fix, plus a validation checklist (unit, integration, and manual checks) that proves we didn’t break nearby behavior.”
Prossimi passi: automatizza ciò che puoi (uno script di repro salvato, un comando test standard, un template per note di root-cause).
Se costruisci app con Koder.ai (koder.ai), Planning Mode può aiutarti a delineare la modifica prima di toccare il codice, e snapshot/rollback rendono più semplice sperimentare in sicurezza mentre lavori sul repro. Una volta convalidata la correzione, puoi esportare il codice sorgente o distribuire e ospitare l'app aggiornata, incluso con un dominio personalizzato quando necessario.
Domande frequenti
What is bug triage, in plain terms?
Il triage dei bug è l'abitudine di trasformare una segnalazione vaga in un enunciato chiaro e testabile, quindi fare la modifica più piccola che dimostri che l'enunciato non è più vero.
È meno un approccio "risolvi tutto" e più un modo per ridurre l'incertezza passo dopo passo: riprodurre, minimizzare, formulare ipotesi basate su evidenze, aggiungere un test di regressione, correggere in modo mirato e validare.
Why does the reproduce → minimize → test → fix loop matter so much?
Perché ogni fase elimina un diverso tipo di supposizione.
- Riprodurre: dimostra che è reale e ripetibile
- Minimizzare: elimina il rumore così non insegui comportamenti non correlati
- Ipotesi basate su evidenze: evita di correggere la cosa sbagliata
- Test di regressione: dimostra che il bug esisteva e resta corretto
- Correzione mirata + validazione: riduce effetti collaterali e ricadute
How do I turn a messy bug report into something actionable?
Riformulalo così: “Quando faccio X, mi aspetto Y, ma ottengo Z.”
Poi raccogli solo il contesto necessario per renderlo testabile:
- versione/commit + dove succede (local/staging/prod)
- ambiente (dispositivo, OS, browser, flag, regione)
- input/azioni esatti
- chi è colpito (tutti, un ruolo, un tenant)
- evidenza (timestamp, testo di errore, ID richiesta/trace, log)
What should I do first if I can’t reproduce the bug?
Conferma di poterlo riprodurre nell'ambiente più piccolo che ancora lo mostra (spesso dev locale con un dataset minimo).
Se è “a volte”, prova a renderlo deterministico controllando le variabili:
- riesegui lo stesso payload 10 volte
- fissa tempo/casualità se possibile
- riduci la concorrenza (un solo worker/thread)
- aggiungi un log mirato al confine che probabilmente fallisce
Non andare avanti finché non puoi farlo fallire su richiesta, altrimenti stai indovinando.
How do I minimize a bug to a small test case?
Minimizzare significa rimuovere tutto ciò che non è necessario mantenendo il bug.
Un metodo pratico è “rimuovi metà e ritesta”:
- taglia a metà i passaggi/dati
- se fallisce ancora, taglia di nuovo
- se smette di fallire, ripristina metà e taglia diversamente
Riduci sia i passaggi (flusso utente più corto) sia i dati (payload più piccolo, meno campi/elementi) finché non hai il trigger riproducibile più semplice.
How can Claude Code help without turning into guesswork?
Usa Claude Code per accelerare l'analisi, non per sostituire la verifica.
Richieste utili sono del tipo:
- “Ecco i passaggi di repro + log. Elenca 2–3 ipotesi e quale evidenza confermerebbe ognuna.”
- “Dato questo diff e lo stack trace, quali sono i confini di fallimento più probabili?”
- “Bozza un test fallente minimo per questo scenario.”
Poi convalida: riproduci localmente, controlla log/trace e assicurati che il test fallisca per la ragione giusta.
How many root-cause hypotheses should I consider at once?
Mantienile a tre. Più di così di solito significa che il repro è ancora troppo ampio o le osservazioni sono vaghe.
Per ogni ipotesi scrivi:
- sintomo (cosa osservi)
- ipotesi (cosa potrebbe causarlo)
What makes a good regression test for a bug?
Scegli il livello di test più piccolo che corrisponde al fallimento:
- Unit test: una funzione restituisce il valore sbagliato
- Integration test: problemi al confine tra componenti (handler + DB, client + API)
- End-to-end: solo se serve l'intero flusso
Un buon test di regressione:
How do I keep a fix narrow and low-risk?
Fai la modifica più piccola che rende il test di regressione fallente verde.
Regole pratiche:
- tocca il minor numero possibile di file
- correggi al confine dove entra il valore errato
- preferisci una guardia/validazione piuttosto che un refactor in fase di triage
- evita pulizie ampie a meno che il test non dimostri siano necessarie
Se la correzione richiede di aggiornare molti test non correlati, probabilmente è troppo ampia.
How do I validate the fix so the bug doesn’t come back?
Usa una checklist breve che puoi eseguire rapidamente:
- il test di regressione passa
- alcuni test vicini (stesso modulo/inputs) passano
- i passaggi manuali originali non scatenano più il bug
- la gestione degli errori ha ancora senso (messaggi, codici di stato)
- casi limite veloci (input vuoto, dimensione massima, caratteri strani)
- nessun regressione evidente delle prestazioni
Annota cosa hai eseguito e cosa non hai testato in modo che il risultato sia affidabile.