Perché il REST di Roy Fielding conta ancora
Roy Fielding non è solo un nome legato a una parola di moda sulle API. È stato uno degli autori chiave delle specifiche HTTP e URI e, nella sua tesi di dottorato, ha descritto uno stile architetturale chiamato REST (Representational State Transfer) per spiegare perché il Web funziona così bene.
Questa origine è importante perché REST non è stato inventato per creare “endpoint dall'aspetto carino”. Era un modo per descrivere i vincoli che permettono a una rete globale e caotica di scalare: molti client, molti server, intermediari, caching, guasti parziali e cambiamenti continui.
Cosa ti darà questo post
Se ti sei mai chiesto perché due “API REST” sembrano completamente diverse — o perché una piccola scelta di design si trasforma poi in problemi di paginazione, confusione sul caching o breaking change — questa guida è pensata per ridurre quelle sorprese.
Ne uscirai con:
- decisioni più chiare quando progetti o valuti un'API
- un vocabolario migliore per discutere i compromessi con il tuo team
- un senso pratico di quali idee REST contano davvero nei progetti reali
REST in una pagina: stile, non standard
REST non è una checklist, un protocollo o una certificazione. Fielding lo descrisse come uno stile architetturale: un insieme di vincoli che, applicati insieme, producono sistemi che scalano come il Web—semplici da usare, capaci di evolvere nel tempo e amichevoli con gli intermediari (proxy, cache, gateway) senza coordinazione costante.
Il problema che REST risolveva
Il Web iniziale doveva funzionare attraverso molte organizzazioni, server, reti e tipi di client. Doveva crescere senza un controllo centrale, sopravvivere a guasti parziali e permettere che nuove funzionalità apparissero senza rompere le precedenti. REST affronta questo favorendo un piccolo numero di concetti largamente condivisi (come identificatori, rappresentazioni e operazioni standard) rispetto a contratti personalizzati e fortemente accoppiati.
“Vincoli architetturali” in parole semplici
Un vincolo è una regola che limita la libertà di design in cambio di benefici. Per esempio, puoi rinunciare allo stato di sessione lato server in modo che le richieste possano essere gestite da qualsiasi nodo server, migliorando affidabilità e scalabilità. Ogni vincolo REST compie un compromesso simile: meno flessibilità ad-hoc, più prevedibilità ed evolvibilità.
REST vs API “simili a REST"
Molte API HTTP prendono in prestito idee REST (JSON su HTTP, endpoint URL, magari codici di stato) ma non applicano l'insieme completo di vincoli. Non è “sbagliato”—spesso riflette scadenze di prodotto o necessità interne. È però utile nominare la differenza: un'API può essere orientata alle risorse senza essere pienamente REST.
Un modello mentale in un paragrafo
Pensa a un sistema REST come a risorse (cose che puoi nominare con URL) con cui i client interagiscono tramite rappresentazioni (la vista corrente di una risorsa, come JSON o HTML), guidati da link (azioni successive e risorse correlate). Il client non ha bisogno di regole segrete fuori banda; segue la semantica standard e naviga usando i link, proprio come fa un browser nel Web.
Risorse e rappresentazioni: il vocabolario centrale
Prima di perderci nei vincoli e nei dettagli HTTP, REST parte da uno spostamento concettuale semplice: pensa in termini di risorse, non di azioni.
Risorsa = un sostantivo che puoi identificare
Una risorsa è una “cosa” indirizzabile nel tuo sistema: un utente, una fattura, una categoria di prodotto, un carrello. La cosa importante è che sia un sostantivo con un'identità.
Per questo /users/123 si legge naturalmente: identifica l'utente con ID 123. Confrontalo con URL a forma di azione come /getUser o /updateUserPassword. Quelli descrivono verbi—operazioni—non la cosa su cui si opera.
REST non dice che non puoi eseguire azioni. Dice che le azioni dovrebbero essere espresse attraverso l'interfaccia uniforme (per le API HTTP, di solito metodi come GET/POST/PUT/PATCH/DELETE) che agiscono sugli identificatori di risorsa.
Rappresentazione = una vista della risorsa
Una rappresentazione è ciò che invii sulla rete come istantanea o vista di quella risorsa in un dato momento. La stessa risorsa può avere più rappresentazioni.
Per esempio, la risorsa /users/123 potrebbe essere rappresentata come JSON per un'app, o HTML per un browser.
GET /users/123
Accept: application/json
Potrebbe restituire:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
Mentre:
GET /users/123
Accept: text/html
Potrebbe restituire una pagina HTML che rende gli stessi dettagli dell'utente.
L'idea chiave: la risorsa non è il JSON e non è l'HTML. Sono solo formati usati per rappresentarla.
Perché questo modo di vedere cambia il design delle API
Una volta che modelli l'API attorno a risorse e rappresentazioni, diverse decisioni pratiche diventano più facili:
- I nomi restano stabili.
/users/123 rimane valido anche se la tua UI, i workflow o il modello dati evolvono.
- Gli endpoint diventano più semplici. Invece di inventare un nuovo URL per ogni operazione, riutilizzi gli URL delle risorse e vari il metodo o la rappresentazione.
- Il codice client diventa meno accoppiato. I client si concentrano su “recupera l'utente” o “aggiorna i campi dell'utente” invece di memorizzare un catalogo di endpoint-azione.
Questa mentalità orientata alle risorse è la base su cui i vincoli REST si costruiscono. Senza di essa, “REST” spesso si riduce a “JSON su HTTP con qualche URL carino”.
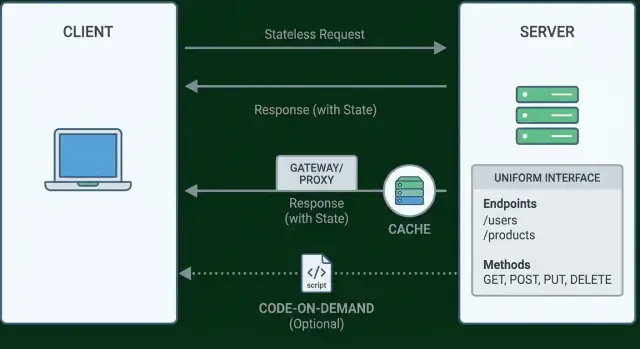
Vincolo 1: Separazione Client–Server
La separazione client–server è il modo in cui REST impone una divisione pulita delle responsabilità. Il client si concentra sull'esperienza utente (cosa le persone vedono e fanno), mentre il server si occupa di dati, regole e persistenza (ciò che è vero e ciò che è permesso). Quando mantieni separate queste preoccupazioni, ogni lato può cambiare senza costringere una riscrittura dell'altro.
Cosa vive sul client vs. sul server?
In termini semplici, il client è lo “strato di presentazione”: schermate, navigazione, validazione dei form per feedback rapido e comportamenti UI ottimistici (per esempio mostrare subito un nuovo commento). Il server è la “fonte della verità”: autenticazione, autorizzazione, regole di business, archiviazione dati, auditing e tutto ciò che deve rimanere consistente tra dispositivi.
Una regola pratica: se una decisione influenza sicurezza, denaro, permessi o consistenza dei dati condivisi, appartiene al server. Se riguarda solo come si percepisce l'esperienza (layout, suggerimenti locali di input, stati di caricamento), appartiene al client.
Perché si adatta ai pattern delle app moderne
Questo vincolo si mappa direttamente a setup comuni:
- SPA + API: un'app web (React/Vue/etc.) itera sulla UI mentre l'API continua a servire risorse.
- App mobile: client iOS e Android possono condividere le stesse regole e gli stessi endpoint server.
- Integrazioni di terze parti: i partner consumano le stesse capacità del server senza aver bisogno della tua UI.
La separazione client–server è ciò che rende realistico “un backend, molte interfacce”.
Trappola comune: far trapelare stato UI nelle sessioni server
Un errore frequente è memorizzare lo stato del workflow UI sul server (per esempio: “in quale step del checkout è l'utente”) in una sessione lato server. Questo accoppia il backend a uno specifico flusso di schermate e rende la scalabilità più difficile.
Meglio inviare il contesto necessario in ogni richiesta (o ricavarlo dalle risorse memorizzate), così il server resta focalizzato su risorse e regole—non sul ricordare come procede una specifica UI.
Vincolo 2: Interazioni senza stato
La mancanza di stato significa che il server non deve ricordare nulla di un client tra una richiesta e l'altra. Ogni richiesta porta tutte le informazioni necessarie per capirla e rispondere correttamente—chi chiama, cosa vuole e qualsiasi contesto richiesto per elaborarla.
Perché questo conta
Quando le richieste sono indipendenti, puoi aggiungere o rimuovere server dietro un bilanciatore di carico senza preoccuparti di “quale server conosce la mia sessione”. Questo migliora la scalabilità e la resilienza: qualsiasi istanza può gestire qualsiasi richiesta.
Semplifica anche le operazioni. Il debug è spesso più semplice perché il contesto completo è visibile nella richiesta (e nei log), invece che nascosto nella memoria della sessione server.
I compromessi che percepisci nelle API reali
Le API senza stato tipicamente inviano qualche dato in più per chiamata. Invece di fare affidamento su una sessione server memorizzata, i client includono credenziali e contesto ogni volta.
Devi anche essere esplicito sui flussi utente “stateful” (come paginazione o checkout multi-step). REST non proibisce esperienze multi-step—sposta però lo stato sul client o su risorse server identificate e recuperabili.
Pattern pratici (e cosa risolvono)
- Token di autenticazione (es. Bearer JWT): ogni richiesta include un header
Authorization: Bearer … così qualsiasi server può autenticare.
- Idempotency keys: per operazioni come “crea pagamento”, i client inviano un
Idempotency-Key così i retry non duplicano il lavoro.
- Correlation IDs: un header come
X-Correlation-Id ti permette di tracciare una singola azione utente attraverso servizi e log, anche in un sistema distribuito.
Per la paginazione, evita che “il server ricordi la pagina 3.” Preferisci parametri espliciti come ?cursor=abc o un link next che il client può seguire, mantenendo lo stato di navigazione nelle risposte invece che nella memoria del server.
Vincolo 3: Risposte cacheabili
Il caching riguarda il riutilizzo sicuro di una risposta precedente in modo che il client (o qualcosa nel mezzo) non debba chiedere al tuo server di fare lo stesso lavoro di nuovo. Fatto bene, riduce la latenza per gli utenti e il carico per te—senza cambiare il significato dell'API.
Cosa significa “cacheabile” nella pratica
Una risposta è cacheabile quando è sicuro che un'altra richiesta riceva lo stesso payload per un periodo di tempo. In HTTP comunichi questa intenzione con header di caching:
Cache-Control: il quadro principale (per quanto tempo tenerla, se può essere memorizzata da cache condivise, ecc.)ETag e Last-Modified: validator che permettono ai client di chiedere “è cambiato?” e ottenere una risposta economica “not modified”Expires: un modo più vecchio per esprimere freschezza, ancora visto in giro
Questo è più grande del “solo caching del browser.” Proxy, CDN, gateway API e persino app mobili possono riutilizzare risposte quando le regole sono chiare.
Cosa è solitamente sicuro cacheggiare (e cosa no)
Buoni candidati:
- Dati pubblici identici per tutti (cataloghi prodotti, documentazione, feature flag non user-specific)
- Risorse in sola lettura che cambiano raramente (configurazione statica, dati di riferimento)
- Risposte GET che non dipendono da cookie o autorizzazione
Solitamente pessimi candidati:
- Dati personali legati a un account (profili, ordini, messaggi)
- Risposte legate all'autenticazione (scambi di token, stato di sessione)
- Qualsiasi cosa che varia per utente a meno che non la gestisci esplicitamente (es.: con regole
private)
Risultati pratici che noterai
- Pagine più veloci e app più reattive (meno attesa in rete)
- Costi minori su server e database (meno computazioni ripetute)
- Meno incidenti di “rate limit” (le letture cacheggiate riducono il volume di richieste)
L'idea chiave: il caching non è un ripensamento. È un vincolo REST che premia le API che comunicano chiaramente freschezza e validazione.
L'interfaccia uniforme è spesso fraintesa come “usa GET per leggere e POST per creare.” Quella è solo una piccola parte. L'idea di Fielding è più ampia: le API dovrebbero essere abbastanza coerenti da non costringere i client a conoscenze speciali endpoint-per-endpoint.
-
Identificazione delle risorse: nomini le cose (risorse) con identificatori stabili (tipicamente URL), non azioni. Pensa /orders/123, non /createOrder.
-
Manipolazione tramite rappresentazioni: i client modificano una risorsa inviando una rappresentazione (JSON, HTML, ecc.). Il server controlla la risorsa; il client scambia rappresentazioni.
-
Messaggi auto-descrittivi: ogni richiesta/risposta dovrebbe portare abbastanza informazioni per capire come elaborarla—metodo, codice di stato, header, tipo di media e un body chiaro. Se il significato è nascosto in documenti fuori banda, i client diventano fortemente accoppiati.
-
Hypermedia (HATEOAS): le risposte dovrebbero includere link e azioni consentite così i client possono seguire il workflow senza hard-codare ogni pattern di URL.
Perché riduce l'accoppiamento
Un'interfaccia coerente rende i client meno dipendenti dai dettagli interni del server. Col tempo, ciò significa meno breaking change, meno “casi speciali” e meno lavoro quando i team evolvono gli endpoint.
Euristiche pratiche che puoi applicare
- Usa i codici di stato in modo coerente: es.
200 per letture riuscite, 201 per risorse create (con Location), 400 per problemi di validazione, 401/403 per auth, 404 quando una risorsa non esiste.
- Standardizza il formato degli errori in tutta l'API. Esempio di campi:
code, message, details, requestId.
- Mantieni significativi media type e header (
Content-Type, header di caching), così i messaggi si spiegano da soli.
L'interfaccia uniforme riguarda la predicibilità e l'evolvibilità, non solo i “verbi corretti”.
Messaggi auto-descrittivi: progettare per la comprensione
Un messaggio “auto-descrittivo” è tale se dice al ricevente come interpretarlo—senza richiedere conoscenza tribale fuori banda. Se un client (o un intermediario) non può capire cosa significa una risposta guardando solo gli header HTTP e il body, hai creato un protocollo privato che viaggia sopra HTTP.
La vittoria più semplice è essere espliciti con Content-Type (cosa stai inviando) e spesso con Accept (cosa vuoi indietro). Una risposta con Content-Type: application/json dice al client le regole di parsing di base, ma puoi andare oltre con media type vendor o profile quando il significato conta.
Esempi di approcci:
- Media type generico + campi stabili:
application/json con uno schema attentamente mantenuto. Il più semplice per la maggior parte dei team.
- Media type vendor:
application/vnd.acme.invoice+json per segnalare una rappresentazione specifica.
- Profile: mantieni
application/json, aggiungi un parametro profile o un link a un profilo che definisce la semantica.
Versioning e compatibilità (senza rompere i client)
Il versioning dovrebbe proteggere i client esistenti. Opzioni popolari includono:
- Versioning via URL (
/v1/orders): ovvio, ma può incoraggiare il “fork” delle rappresentazioni invece di evolverle.
- Versioning via header o media type (tramite
Accept): mantiene gli URL stabili e rende parte del messaggio “cosa significa”.
- Evoluzione additiva: preferisci aggiungere nuovi campi mantenendo quelli vecchi; depreca gradualmente.
Qualunque sia la scelta, punta alla retrocompatibilità per default: non rinominare campi a cuor leggero, non cambiare significato in modo silenzioso e tratta le rimozioni come breaking change.
Errori coerenti e nomi chiari
I client imparano più in fretta quando gli errori hanno lo stesso aspetto ovunque. Scegli una forma di errore (es.: code, message, details, traceId) e usala in tutti gli endpoint. Usa nomi di campo chiari e prevedibili (createdAt vs created_at) e mantieni una sola convenzione.
La documentazione aiuta—ma la chiarezza deve vivere nel messaggio
Buona documentazione accelera l'adozione, ma non può essere l'unico posto dove esiste il significato. Se un client deve leggere una wiki per capire se status: 2 significa “pagato” o “in attesa”, il messaggio non è auto-descrittivo. Header ben progettati, media type e payload leggibili riducono quella dipendenza e rendono i sistemi più facili da evolvere.
Hypermedia (spesso riassunto come HATEOAS: Hypermedia As The Engine Of Application State) significa che un client non deve “conoscere” in anticipo i prossimi URL dell'API. Invece, ogni risposta include passi successivi scopribili come link: dove andare dopo, quali azioni sono possibili e talvolta quale metodo HTTP usare.
Come si presenta nella pratica
Invece di hard-codare percorsi come /orders/{id}/cancel, il client segue i link forniti dal server. Il server sta effettivamente dicendo: “Dato lo stato corrente di questa risorsa, ecco le mosse valide.”
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
Se l'ordine poi diventa paid, il server potrebbe smettere di includere cancel e aggiungere refund—senza rompere un client ben comportato.
L'hypermedia brilla quando i flussi evolvono: onboarding, checkout, approvazioni, abbonamenti o qualsiasi processo dove “ciò che è permesso dopo” cambia in base allo stato, ai permessi o alle regole di business.
Riduce anche i URL hard-coded e le assunzioni fragili del client. Puoi riorganizzare le rotte, introdurre nuove azioni o deprecare quelle vecchie mantenendo i client funzionanti finché mantieni il significato delle relazioni dei link.
Perché i team lo saltano (e cosa perdono)
I team spesso evitano HATEOAS perché sembra lavoro extra: definire formati di link, accordarsi sui nomi delle relazioni e insegnare agli sviluppatori client a seguire i link invece di costruire URL.
Quello che perdi è un vantaggio chiave di REST: accoppiamento lasco. Senza hypermedia, molte API diventano “RPC su HTTP”—possono usare HTTP, ma i client dipendono ancora molto dalla documentazione out-of-band e da template di URL fissi.
Vincolo 5: Sistema a livelli
Un sistema a livelli significa che un client non deve sapere (e spesso non può sapere) se sta parlando con il server d'origine “reale” o con degli intermediari lungo il percorso. Questi livelli possono includere API gateway, reverse proxy, CDN, servizi di autenticazione, WAF, service mesh e persino il routing interno tra microservizi.
Perché i livelli sono utili
I livelli creano confini puliti. I team di sicurezza possono applicare TLS, rate limit, autenticazione e validazione delle richieste al bordo senza cambiare ogni servizio backend. I team operativi possono scalare orizzontalmente dietro un gateway, aggiungere caching in una CDN o spostare traffico durante incidenti. Per i client, può semplificare le cose: un endpoint API stabile, header coerenti e formati di errore prevedibili.
I compromessi che percepisci nella pratica
Gli intermediari possono introdurre latenza nascosta (passaggi in più, handshake in più) e rendere il debug più difficile: il bug potrebbe trovarsi nelle regole del gateway, nella cache CDN o nel codice dell'origine. Il caching può anche creare confusione quando livelli diversi cacheggiano in modo diverso o quando un gateway riscrive header che influenzano le chiavi di cache.
Consigli pratici per evitare che i livelli ti danneggino
- Usa ID di tracing end-to-end: accetta un request ID (o generane uno) e propagalo attraverso ogni hop; includilo nelle risposte e nei log.
- Rendi esplicita la propagazione degli errori: standardizza i corpi di errore e mappa chiaramente i fallimenti upstream (non trasformare ogni problema in un generico 500).
- Imposta timeout per hop: timeout del gateway, timeout upstream e timeout client dovrebbero essere allineati per evitare disconnessioni “misteriose”.
- Documenta il comportamento di caching: sii chiaro su quali risposte sono cacheabili e quali header gli intermediari devono preservare.
I livelli sono potenti—quando il sistema rimane osservabile e prevedibile.
Vincolo 6 (opzionale): Code-on-Demand
Il code-on-demand è l'unico vincolo REST esplicitamente opzionale. Significa che un server può estendere un client inviando codice eseguibile che gira lato client. Invece di spedire ogni comportamento nel client in anticipo, il client può scaricare nuova logica quando serve.
L'esempio familiare del web: JavaScript
Se hai mai caricato una pagina che poi diventa interattiva—validazione di un form, rendering di un grafico, filtraggio di una tabella—hai già usato code-on-demand. Il server fornisce HTML e dati, più JavaScript che gira nel browser per fornire comportamento.
Questo è uno dei motivi per cui il web può evolvere rapidamente: un browser può rimanere client general-purpose, mentre i siti consegnano nuove funzionalità senza richiedere all'utente di installare una nuova app.
Perché è opzionale (e perché molte API lo evitano)
REST “funziona” anche senza code-on-demand perché gli altri vincoli già abilita-no scalabilità, semplicità e interoperabilità. Un'API può essere puramente orientata alle risorse—servendo rappresentazioni come JSON—mentre i client implementano il proprio comportamento.
Molte API moderne evitano intenzionalmente di inviare codice eseguibile perché complica:
- Sicurezza: il codice eseguibile amplia la superficie di attacco (injection, problemi di supply-chain, script maligni).
- Policy di contenuto: i browser applicano restrizioni come Content Security Policy (CSP) e le organizzazioni possono bloccare script inline o origini non note.
- Audit e compliance: è più difficile dimostrare quale codice è stato eseguito su un client in un dato momento, specialmente se è scaricato dinamicamente.
Quando code-on-demand può ancora avere senso
Può essere utile quando controlli l'ambiente client e hai bisogno di rilasciare rapidamente comportamenti UI, o quando vuoi un client sottile che scarica “plugin” o regole dal server. Ma va trattato come uno strumento in più, non come un requisito.
La lezione chiave: puoi seguire pienamente REST senza code-on-demand—molte API di produzione lo fanno—perché il vincolo è su estendibilità opzionale, non sulla base dell'interazione orientata alle risorse.
Applicare REST oggi: scelte pratiche ed errori comuni
La maggior parte dei team non rifiuta REST—adotta uno stile “REST-ish” che mantiene HTTP come trasporto mentre abbandona silenziosamente vincoli chiave. Questo può andare bene, purché sia un compromesso consapevole e non un incidente che si manifesta poi con client fragili e riscritture costose.
Scorciatoie REST-ish comuni (e perché accadono)
Alcuni pattern ricorrono spesso:
- Endpoint RPC:
/doThing, /runReport, /users/activate—facili da nominare, facili da collegare.
- URL ricchi di verbi:
/createOrder, /updateProfile, /deleteItem—i metodi HTTP diventano un ripensamento.
- Sessioni nascoste: API “stateless” che comunque si appoggiano a sticky session, memoria server o stato di workflow implicito.
Queste scelte spesso sembrano produttive all'inizio perché rispecchiano nomi di funzioni interne e operazioni di business.
Conseguenze che noterai più avanti
- Client fragili: se i client dipendono da forme endpoint specifiche e comportamenti ad-hoc, piccoli refactor server diventano breaking change.
- Versioning difficile: quando gli URL codificano azioni invece di risorse stabili, finisci per versionare comportamenti invece di evolvere rappresentazioni.
- Cache miss (e maggiore latenza): ignorare header di cache o usare POST per tutto impedisce agli intermediari (e ai browser) di aiutarti.
- Problemi di scalabilità: lo stato lato server nascosto complica la scalabilità orizzontale e rende i guasti più difficili da recuperare.
Checklist pragmatica di allineamento
Usala come revisione “quanto siamo veramente REST?”:
- Nominare risorse, non azioni: preferisci
/orders/{id} a /createOrder.
- Usare i metodi HTTP intenzionalmente: GET per recupero, POST per creazione, PUT/PATCH per aggiornamenti, DELETE per rimozioni.
- Rendere le richieste indipendenti: nessuna memoria server necessaria per capire “in quale step è il client”.
- Sfruttare il caching dove è sicuro: definisci
Cache-Control, ETag e Vary per le risposte GET.
- Standardizzare errori e media type: codici di stato coerenti e forme di risposta riducono i casi speciali.
Dove si vede mentre costruisci davvero
I vincoli REST non sono solo teoria—sono guide che senti mentre rilasci. Quando generi rapidamente un'API (per esempio scaffoldando un frontend React con backend Go + PostgreSQL), l'errore più facile è lasciare che “ciò che è più veloce da collegare” determini l'interfaccia.
Se usi una piattaforma di vibe-coding come Koder.ai per costruire un'app web a partire da una chat, conviene portare questi vincoli REST nella conversazione fin da subito—nominare prima le risorse, restare senza stato, definire forme di errore coerenti e decidere dove il caching è sicuro. Così anche l'iterazione rapida produce API prevedibili per i client e più facili da evolvere. (E perché Koder.ai supporta l'esportazione del codice sorgente, puoi continuare a rifinire contratto e implementazione man mano che i requisiti maturano.)
Takeaway per team API e web app
Definite prima le risorse chiave, poi scegliete i vincoli deliberatamente: se saltate caching o hypermedia, documentate perché e cosa usate al loro posto. L'obiettivo non è la purezza—è la chiarezza: identificatori di risorse stabili, semantica prevedibile e compromessi espliciti che mantengono i client resilienti mentre il sistema evolve.