04 nov 2025·8 min
Vint Cerf, TCP/IP e le scelte che hanno costruito Internet
Esplora come le scelte TCP/IP di Vint Cerf permisero reti interoperabili e poi piattaforme software globali — dall'email e il web alle app cloud.
Esplora come le scelte TCP/IP di Vint Cerf permisero reti interoperabili e poi piattaforme software globali — dall'email e il web alle app cloud.
La maggior parte delle persone vive l'Internet attraverso prodotti: un sito che si carica all'istante, una videochiamata che (per lo più) funziona, un pagamento che si conferma in pochi secondi. Sotto queste esperienze ci sono i protocolli—regole condivise che permettono a sistemi diversi di scambiarsi messaggi in modo sufficientemente affidabile da essere utili.
Un protocollo è come accordarsi su una lingua comune e su una certa etichetta per comunicare: com'è fatto un messaggio, come inizi e finisci una conversazione, cosa fare quando manca qualcosa e come sapere a chi è destinato un messaggio. Senza regole condivise, ogni connessione diventa una negoziazione ad hoc e le reti non scalano oltre piccoli circoli.
Vint Cerf è spesso citato come uno dei “padri di Internet”, ma è più corretto (e utile) vedere il suo ruolo come parte di un team che fece scelte di progettazione pragmatiche—soprattutto intorno a TCP/IP—che trasformarono le “reti” in un internetwork. Quelle scelte non erano inevitabili. Rappresentavano compromessi: semplicità vs funzionalità, flessibilità vs controllo, velocità di adozione vs garanzie perfette.
Le piattaforme globali di oggi—app web, servizi mobili, infrastrutture cloud e API fra aziende—vivono o muoiono ancora per la stessa idea: se standardizzi i confini giusti, puoi permettere a milioni di attori indipendenti di costruire sopra senza chiedere permesso. Il tuo telefono parla con server dall'altra parte del globo non solo perché l'hardware è più veloce, ma perché le regole della strada sono rimaste abbastanza stabili da far accumulare innovazione.
Questa mentalità conta anche quando stai “solo costruendo software”. Per esempio, le piattaforme per sviluppo rapido come Koder.ai funzionano quando forniscono un piccolo insieme di primitive stabili (progetti, deployment, ambienti, integrazioni) lasciando ai team la possibilità di iterare rapidamente ai margini—che si tratti di generare un frontend React, un backend Go + PostgreSQL o un'app mobile Flutter.
Toccheremo brevemente la storia, ma il focus sono le decisioni di progetto e le loro conseguenze: come il layering ha abilitato la crescita, dove la consegna “sufficientemente buona” ha sbloccato nuove applicazioni e quali assunzioni iniziali si sono rivelate errate su congestione e sicurezza. L'obiettivo è pratico: prendi il pensiero da protocollo—interfacce chiare, interoperabilità e compromessi espliciti—e applicalo al design di piattaforme moderne.
Prima che “Internet” esistesse, c'erano molte reti—ma non una rete unica che tutti potessero condividere. Università, laboratori governativi e aziende costruivano i propri sistemi per risolvere bisogni locali. Ogni rete funzionava, ma raramente funzionavano insieme.
Più reti coesistevano per ragioni pratiche, non per amore della frammentazione. Gli operatori avevano obiettivi diversi (ricerca, requisito militare, servizio commerciale), budget differenti e vincoli tecnici diversi. I vendor hardware vendevano sistemi incompatibili. Alcune reti erano ottimizzate per collegamenti a lunga distanza, altre per ambienti di campus, altre per servizi specializzati.
Il risultato fu un sacco di “isole” di connettività.
Se volevi far parlare due reti, l'opzione a forza bruta era riscrivere un lato per adattarsi all'altro. Nella realtà questo accade raramente: è costoso, lento e politicamente complicato.
Quello che serviva era un collante comune—un modo per rete indipendenti di interconnettersi mantenendo le loro scelte interne. Questo significava:
Questa sfida preparò il terreno per le idee di internetworking che Cerf e altri avrebbero promosso: connettere le reti a uno strato condiviso così l'innovazione può succedere sopra di esso e la diversità può continuare sotto.
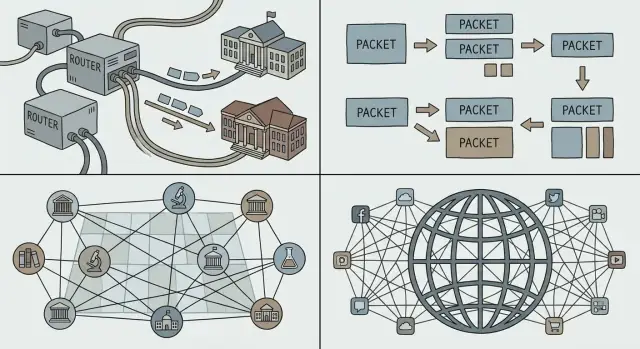
Se hai mai fatto una telefonata, conosci l'intuizione dietro lo circuit switching: una “linea” dedicata è riservata per tutta la durata della chiamata. Funziona bene per voce in tempo reale, ma è uno spreco quando la conversazione è per lo più silenzio.
Lo packet switching ribalta il modello. Un'analogia quotidiana è il servizio postale: invece di riservare un'autostrada privata dalla tua casa a quella di un amico, metti il messaggio in buste. Ogni busta (pacchetto) è etichettata, instradata su strade condivise e riassemblata alla destinazione.
La maggior parte del traffico dei computer è a raffiche. Una email, un download o una pagina web non sono flussi continui—sono un burst di dati, poi nulla, poi un altro burst. Lo packet switching permette a molte persone di condividere gli stessi link di rete in modo efficiente, perché la rete trasporta pacchetti di chiunque abbia qualcosa da inviare in quel momento.
Questa è una ragione chiave per cui Internet ha potuto supportare nuove applicazioni senza rinegoziare il funzionamento della rete sottostante: puoi spedire un messaggio piccolo o un grande video usando lo stesso metodo di base—spezzalo in pacchetti e invia.
I pacchetti scalano anche socialmente, non solo tecnicamente. Diverse reti (gestite da università, aziende o governi) possono interconnettersi purché concordino come inoltrare i pacchetti. Nessun operatore deve “possedere” l'intero percorso; ogni dominio può portare il traffico al successivo.
Poiché i pacchetti condividono i link, si possono verificare ritardi di accodamento, jitter o perfino perdita quando le reti sono occupate. Questi aspetti negativi hanno reso necessari meccanismi di controllo—ritrasmissioni, ordinamento e controllo della congestione—così lo packet switching rimane veloce e equo anche sotto carico.
L'obiettivo che Cerf e i colleghi inseguivano non era “costruire una rete sola”. Era interconnettere molte reti—universitarie, governative, commerciali—permettendo a ciascuna di mantenere la propria tecnologia, i propri operatori e le proprie regole.
TCP/IP è spesso descritto come una “suite”, ma la mossa progettuale cruciale è la separazione delle responsabilità:
Quella separazione permise all’“internet” di comportarsi come un tessuto di consegna comune, mentre l'affidabilità diventava un servizio opzionale stratificato sopra.
Il layering rende i sistemi più facili da evolvere perché puoi aggiornare uno strato senza rinegoziare tutto ciò che sta sopra. Nuovi collegamenti fisici (fibra, Wi‑Fi, cellulare), strategie di routing e meccanismi di sicurezza possono arrivare col tempo—eppure le applicazioni continuano a parlare TCP/IP e a funzionare.
È lo stesso schema su cui fanno affidamento i team di piattaforma: interfacce stabili, interni sostituibili.
IP non promette la perfezione; fornisce primitive semplici e universali: “ecco un pacchetto” e “ecco un indirizzo.” Questa moderazione ha permesso ad applicazioni inaspettate di fiorire—email, il web, lo streaming, la chat in tempo reale—perché gli innovatori potevano costruire ciò di cui avevano bisogno ai margini senza chiedere il permesso alla rete.
Se stai progettando una piattaforma, questo è un test utile: stai offrendo alcuni blocchi costitutivi affidabili o stai overfittando il sistema al caso d'uso del momento?
La consegna “best‑effort” è un'idea semplice: IP proverà a muovere i tuoi pacchetti verso la destinazione, ma non promette che arriveranno, che arriveranno in ordine o che arriveranno in tempo. I pacchetti possono essere scartati quando i link sono occupati, ritardati dalla congestione o seguire percorsi diversi.
Quella semplicità era una caratteristica, non un difetto. Differenti organizzazioni potevano connettere reti molto diverse—linee costose e di alta qualità in alcuni luoghi; collegamenti rumorosi e a bassa banda in altri—senza richiedere a tutti di aggiornare alla stessa infrastruttura premium.
IP best‑effort abbassò il “prezzo d'ingresso” per partecipare. Università, governi, startup e alla fine famiglie potevano unirsi usando la connettività che potevano permettersi. Se il protocollo di base avesse richiesto garanzie rigorose da ogni rete lungo il percorso, l'adozione si sarebbe bloccata: l'anello più debole avrebbe bloccato l'intera catena.
Invece di costruire un core perfettamente affidabile, Internet spinse l'affidabilità agli host (i dispositivi alle estremità). Se un'applicazione ha bisogno di correttezza—come trasferimenti di file, pagamenti o il caricamento di una pagina web—può usare protocolli e logica ai margini per rilevare perdite e recuperare:
TCP è l'esempio classico: trasforma un servizio di pacchetti inaffidabile in uno stream affidabile facendo il lavoro duro agli endpoint.
Per i team di piattaforma, IP best‑effort ha creato una base prevedibile: ovunque nel mondo, puoi presumere di avere lo stesso servizio di base—inviare pacchetti a un indirizzo e che di solito arrivino. Quella coerenza ha reso possibile costruire piattaforme software globali che si comportano in modo simile attraverso paesi, operatori e hardware.
Il principio end‑to‑end è un'idea apparentemente semplice: mantieni il “core” della rete il più minimale possibile e metti l'intelligenza ai margini—nei dispositivi e nelle applicazioni.
Per i costruttori di software, questa separazione è stata una benedizione. Se la rete non deve comprendere la tua applicazione, puoi lanciare nuove idee senza rinegoziare cambiamenti con ogni operatore di rete.
Questa flessibilità è una grande ragione per cui le piattaforme globali hanno potuto iterare rapidamente: email, web, chiamate voce/video e poi le app mobili hanno tutte viaggiato sullo stesso impianto di base.
Un core semplice significa anche che il core non ti “protegge” di default. Se la rete si limita a inoltrare pacchetti, è più facile per attaccanti e abusi sfruttare quella apertura per spam, scanning, attacchi denial‑of‑service e frodi. Il protocollo IP non verifica chi sei. Email (SMTP) non richiedeva la prova della proprietà dell'indirizzo “From”. E i router non sono stati pensati per giudicare l'intento.
La qualità del servizio è un'altra tensione. Gli utenti si aspettano chiamate video fluide e risposte immediate, ma la consegna best‑effort può produrre jitter, congestione e prestazioni incoerenti. L'approccio end‑to‑end sposta molte correzioni verso l'alto: logica di retry, buffering, adattamento del bitrate e prioritarizzazione a livello applicativo.
Molto di ciò che oggi chiamiamo “internet” è struttura aggiunta sopra il core minimale: CDN che avvicinano i contenuti agli utenti, cifratura (TLS) per aggiungere privacy e integrità, e protocolli di streaming che adattano la qualità alle condizioni correnti. Anche capacità “di tipo rete”—come protezione bot, mitigazione DDoS e accelerazione delle prestazioni—sono spesso offerte come servizi di piattaforma al bordo piuttosto che integrate in IP stesso.
Una rete può diventare “globale” solo quando ogni dispositivo può essere raggiunto in modo sufficientemente affidabile, senza che ogni partecipante debba conoscere ogni altro partecipante. Questo è il lavoro di indirizzamento, instradamento e DNS: tre idee che trasformano un insieme di reti collegate in qualcosa che le persone (e il software) possono effettivamente usare.
Un indirizzo è un identificatore che dice alla rete dove sta qualcosa. Con IP, quel “dove” è espresso in una forma numerica strutturata.
Instradamento è il processo di decidere come spostare i pacchetti verso quell'indirizzo. I router non hanno bisogno di una mappa completa di ogni macchina sulla Terra; hanno solo bisogno di informazioni sufficienti per inoltrare il traffico passo dopo passo nella direzione giusta.
La chiave è che le decisioni di forwarding possono essere locali e veloci, mentre il risultato complessivo appare ancora come raggiungibilità globale.
Se ogni singolo indirizzo dispositivo dovesse essere elencato ovunque, Internet collasserebbe sotto il suo stesso carico amministrativo. L'indirizzamento gerarchico permette agli indirizzi di essere raggruppati (per esempio, per rete o provider), così i router possono mantenere rotte aggregate—una voce che rappresenta molte destinazioni.
Questo è il segreto poco glamour dietro la crescita: tabelle di instradamento più piccole, meno aggiornamenti e coordinazione più semplice tra organizzazioni. L'aggregazione è anche il motivo per cui le politiche di assegnazione degli indirizzi IP contano per gli operatori: influenzano direttamente quanto è costoso mantenere il sistema globale coerente.
Gli umani non vogliono digitare numeri, e i servizi non vogliono essere legati permanentemente a una singola macchina. DNS (Domain Name System) è lo strato di naming che mappa nomi leggibili (come api.example.com) agli indirizzi IP.
Per i team di piattaforma, il DNS è più di una comodità:
In altre parole, indirizzamento e instradamento rendono Internet raggiungibile; DNS lo rende utilizzabile e adattabile operativamente su scala piattaforma.
Un protocollo diventa “Internet” quando molte reti e prodotti indipendenti possono usarlo senza chiedere permesso. Una delle scelte più intelligenti intorno a TCP/IP non fu solo tecnica—fu sociale: pubblicare le specifiche, invitare critiche e permettere a chiunque di implementarle.
La serie Request for Comments (RFC) trasformò idee di networking in documenti condivisi e citabili. Invece di uno standard scatola nera controllato da un vendor, gli RFC rendevano le regole visibili: cosa significa ciascun campo, cosa fare nei casi limite e come restare compatibili.
Quell'apertura fece due cose. Prima, ridusse il rischio per chi adottava: università, governi e aziende potevano valutare il design e implementarlo. Seconda, creò un punto di riferimento comune, così i disaccordi potevano risolversi con aggiornamenti del testo piuttosto che con negoziazioni private.
L'interoperabilità è ciò che rende reale il “multi‑vendor”. Quando router, sistemi operativi e applicazioni diversi possono scambiarsi traffico prevedibilmente, gli acquirenti non sono intrappolati. La competizione si sposta da “a quale rete puoi accedere?” a “chi ha il prodotto migliore?”—il che accelera il miglioramento e abbassa i costi.
La compatibilità crea anche effetti di rete: ogni nuova implementazione TCP/IP rende l'intera rete più preziosa, perché può parlare con tutto il resto. Più utenti attraggono più servizi; più servizi attraggono più utenti.
Gli standard aperti non eliminano l'attrito—lo ridistribuiscono. Gli RFC implicano dibattiti, coordinazione e talvolta cambiamenti lenti, specialmente quando miliardi di dispositivi dipendono dal comportamento attuale. Il vantaggio è che il cambiamento, quando avviene, è leggibile e ampiamente implementabile—preservando il beneficio centrale: tutti possono ancora connettersi.
Quando si parla di “piattaforma”, spesso si intende un prodotto su cui altri costruiscono: app di terze parti, integrazioni e servizi che girano su infrastrutture condivise. Su Internet, quelle infrastrutture non sono la rete privata di una singola azienda—sono protocolli comuni che chiunque può implementare.
TCP/IP non ha creato il web, il cloud o gli app store da solo. Ha fornito una base stabile e universale dove quelle cose potevano diffondersi affidabilmente.
Una volta che le reti potevano interconnettersi tramite IP e le applicazioni potevano contare su TCP per la consegna, divenne pratico standardizzare primitive di livello superiore:
Il dono di TCP/IP all'economia delle piattaforme fu prevedibilità: puoi costruire una volta e raggiungere molte reti, paesi e tipi di dispositivi senza negoziare connettività su misura ogni volta.
Una piattaforma cresce più velocemente quando utenti e sviluppatori sentono di poter partire—o almeno non sentirsi intrappolati. I protocolli aperti e ampiamente implementati riducono i costi di switching perché:
Quell'interoperabilità senza permesso è il motivo per cui mercati software globali si sono formati intorno a standard condivisi piuttosto che intorno a un singolo proprietario di rete.
Questi stanno sopra TCP/IP, ma dipendono dalla stessa idea: se le regole sono stabili e pubbliche, le piattaforme possono competere sul prodotto—senza rompere la capacità di connettersi.
La magia di Internet è che funziona attraverso oceani, reti mobili, hotspot Wi‑Fi e router d'ufficio sovraccarichi. La verità meno magica: opera sempre sotto vincoli. La banda è limitata, la latenza varia, i pacchetti si perdono o vengono riordinate, e la congestione può apparire improvvisamente quando molta gente condivide lo stesso percorso.
Anche se il tuo servizio è “in cloud”, gli utenti lo sperimentano attraverso il punto più stretto del percorso verso di loro. Una videochiamata su fibra e la stessa chiamata su un treno affollato sono prodotti diversi, perché latenza, jitter e perdita modellano ciò che gli utenti percepiscono.
Quando troppo traffico colpisce gli stessi link, si formano code e i pacchetti vengono scartati. Se ogni mittente reagisse mandando ancora più dati (o ritentando troppo aggressivamente), la rete potrebbe entrare in collasso per congestione—molto traffico, poca consegna utile.
Il controllo della congestione è l'insieme di comportamenti che mantengono la condivisione equa e stabile: sondare la capacità disponibile, rallentare quando segnali di perdita/latency indicano sovraccarico, poi accelerare cautamente. TCP ha reso popolare questo ritmo “rallenta, poi recupera” così la rete poteva restare semplice mentre gli endpoint si adattavano.
Perché le reti sono imperfette, le applicazioni di successo fanno lavoro extra silenziosamente:
Progetta come se la rete fallisse, brevemente e spesso:
La resilienza non è una caratteristica aggiuntiva—è il prezzo da pagare per operare a scala Internet.
TCP/IP ebbe successo perché rese facile a qualsiasi rete connettersi a qualsiasi altra. Il costo nascosto di quell'apertura è che chiunque può anche inviarti traffico—buono o cattivo.
Il design iniziale di Internet assumeva una comunità relativamente piccola e orientata alla ricerca. Quando la rete divenne pubblica, la stessa filosofia del “inoltra pacchetti” permise spam, frodi, malware, attacchi DDoS e impersonificazione. IP non verifica chi sei. SMTP non richiedeva prova della proprietà dell'indirizzo “From”. E i router non erano pensati per giudicare l'intento.
Man mano che Internet è diventata infrastruttura critica, la sicurezza ha smesso di essere una funzionalità da aggiungere e è diventata un requisito nel modo in cui i sistemi vengono costruiti: identità, riservatezza, integrità e disponibilità richiedono meccanismi espliciti. La rete è rimasta per lo più best‑effort e neutrale, ma applicazioni e piattaforme hanno dovuto presumere che il mezzo non sia affidabile.
Non abbiamo “risolto” IP rendendolo giudice di ogni pacchetto. Invece, la sicurezza moderna è stratificata sopra:
Tratta la rete come ostile per default. Usa il principio del minimo privilegio ovunque: scope stretti, credenziali a breve durata e impostazioni robuste di default. Verifica identità e input a ogni confine, cripta in transito e progetta per i casi di abuso—non solo per i percorsi felici.
Internet non “vinse” perché ogni rete concordò lo stesso hardware, vendor o set perfetto di funzionalità. Durò perché scelte chiave di protocollo resero facile a sistemi indipendenti connettersi, migliorare e continuare a funzionare anche quando parti cadevano.
Layering con cuciture chiare. TCP/IP separò lo “spostare pacchetti” dal “rendere le applicazioni affidabili.” Quella separazione permise alla rete di rimanere general‑purpose mentre le app evolvono velocemente.
Semplicità nel core. La consegna best‑effort significava che la rete non doveva capire ogni necessità applicativa. L'innovazione avvenne ai margini, dove nuovi prodotti potevano essere lanciati senza negoziare con un'autorità centrale.
Interoperabilità al primo posto. Specifiche aperte e comportamento prevedibile hanno reso possibile a organizzazioni diverse di costruire implementazioni compatibili—creando un ciclo di adozione compounding.
Se costruisci una piattaforma, tratta l'interconnessione come una caratteristica, non come un effetto collaterale. Preferisci un piccolo set di primitive che molti team possano comporre rispetto a un grande set di funzionalità “intelligenti” che bloccherebbero gli utenti in un'unica strada.
Progetta per l'evoluzione: presumi che i client saranno vecchi, i server nuovi e alcune dipendenze parzialmente giù. La tua piattaforma dovrebbe degradare con grazia e restare comunque utile.
Se usi un ambiente di costruzione rapida come Koder.ai, gli stessi principi appaiono come capacità di prodotto: un passo di pianificazione chiaro (così le interfacce sono esplicite), iterazione sicura tramite snapshot/rollback e comportamento di deployment/hosting prevedibile che permette a più team di muoversi velocemente senza rompere i consumatori.
Un protocollo è un insieme condiviso di regole su come i sistemi formattano i messaggi, iniziano/terminano gli scambi, gestiscono dati mancanti e identificano le destinazioni. Le piattaforme dipendono dai protocolli perché rendono l'interoperabilità prevedibile, permettendo a team e fornitori indipendenti di integrarsi senza accordi one‑off personalizzati.
L'internetworking ha permesso di connettere multiple reti indipendenti così che i pacchetti potessero attraversarle come un unico percorso end‑to‑end. Il punto chiave è stato farlo senza costringere alcuna rete a riscrivere i propri interni, ed è per questo che uno strato comune (IP) è diventato così importante.
Lo switching a pacchetto divide i dati in pacchetti che condividono i collegamenti di rete con altro traffico, il che è efficiente per le comunicazioni burst tipiche dei computer. Lo circuit switching riserva un percorso dedicato end‑to‑end, che può essere dispendioso quando il traffico è intermittente (come nella maggior parte del traffico web/app).
IP gestisce indirizzamento e instradamento (spostare pacchetti hop‑by‑hop). TCP si trova sopra IP e fornisce affidabilità quando serve (ordinamento, ritrasmissione, controllo di flusso/connessione). Questa separazione permette alla rete di rimanere general‑purpose mentre le applicazioni scelgono le garanzie di consegna necessarie.
“Best‑effort” significa che IP prova a consegnare i pacchetti ma non garantisce arrivo, ordine o tempi. Questa semplicità ha abbassato la barriera d'ingresso per le reti: non servivano garanzie rigorose ovunque, il che ha accelerato l'adozione e reso la connettività globale praticabile anche su collegamenti imperfetti.
È l'idea che il core della rete debba fare il minimo indispensabile, e che intelligenza e complessità vadano messe agli estremi (endpoint/app). Il vantaggio è innovazione più rapida ai margini; il costo è che le applicazioni devono esplicitamente gestire fallimenti, abusi e variabilità.
Gli indirizzi identificano le destinazioni; il routing decide il prossimo hop verso quelle destinazioni. L'indirizzamento gerarchico permette l'aggregazione delle rotte, mantenendo tabelle di routing gestibili su scala globale. Una scarsa aggregazione aumenta la complessità operativa e può stressare il sistema di routing.
DNS mappa nomi leggibili dall'umano (come api.example.com) in indirizzi IP e può cambiare queste mappature senza modificare i client. Le piattaforme usano DNS per steering del traffico, deployment multi‑regione e failover—mantenendo il nome stabile mentre l'infrastruttura sotto cambia.
Gli RFC pubblicano il comportamento dei protocolli in modo aperto così chiunque può implementarli e testare la compatibilità. Questa apertura riduce il lock‑in del venditore, aumenta l'interoperabilità multi‑fornitore e crea effetti di rete: ogni implementazione compatibile aggiunge valore all'ecosistema.
Progetta come se la rete fosse inaffidabile:
Per una guida correlata, vedi i testi su versioning, compatibilità e degradazione graduale.