23 set 2025·6 min
ZSTD vs Brotli vs GZIP: scegliere la compressione per le API
Confronta ZSTD, Brotli e GZIP per le API: velocità, rapporto di compressione, costo CPU e impostazioni pratiche per payload JSON e binari in produzione.
Confronta ZSTD, Brotli e GZIP per le API: velocità, rapporto di compressione, costo CPU e impostazioni pratiche per payload JSON e binari in produzione.
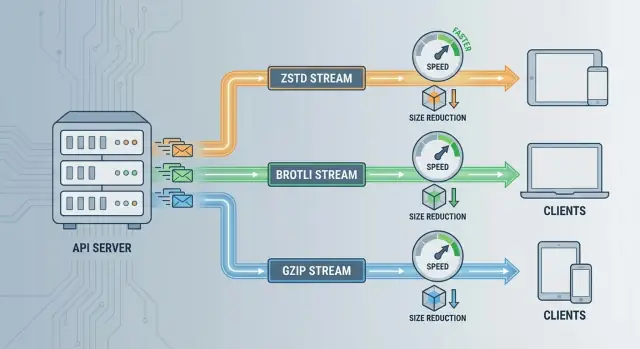
Accept-Encoding (cosa supporta il client) e Content-Encoding (cosa ha scelto il server).\n\n### Cosa porta alle API\n\nLa compressione ti dà principalmente tre vantaggi:\n\n- Meno banda: le risposte più piccole consumano meno byte end‑to‑end.\n- Meno latenza su link limitati: meno byte spesso significa download più veloci su mobile, Wi‑Fi congestionato e chiamate cross‑region.\n- Meno costi di egress: se paghi per i dati in uscita, ridurre la dimensione trasferita può abbassare direttamente la bolletta.\n\nLo scambio è semplice: la compressione risparmia banda ma costa CPU (compress/decompress) e talvolta memoria (buffer). Se vale la pena dipende dal collo di bottiglia del tuo sistema.\n\n### Quando la compressione aiuta di più\n\nLa compressione brilla quando le risposte sono:\n\n- Ricche di testo e ripetitive, come JSON, risposte GraphQL, HTML o log.\n- Medie o grandi, dove risparmiare decine o centinaia di kilobyte conta.\n- Servite su reti lente o costose, ad esempio client mobile, traffico internazionale o chiamate cross‑region.\n\nSe ritorni grandi liste JSON (cataloghi, risultati di ricerca, analytics), la compressione è spesso una delle vittorie più semplici.\n\n### Quando aiuta meno\n\nLa compressione è spesso uno spreco di CPU quando le risposte sono:\n\n- Piccole (per esempio poche centinaia di byte). L'overhead di header + CPU può superare il risparmio.\n- Già compresse (JPEG/PNG, MP4, ZIP, molti PDF). Ricomprimere di solito dà pochi benefici e a volte aumenta la dimensione.\n- Servizi CPU‑bound (endpoint affollati che già lottano con il calcolo). Aggiungere compressione può aumentare la latenza di tail.\n\n### Gli assi decisionali che userai in questa guida\n\nQuando scegli tra ZSTD vs Brotli vs GZIP per la compressione API, la decisione pratica spesso si riduce a:\n\n1. Riduzione della dimensione (rapporto di compressione)\n2. Latenza (tempo server fino al primo byte più tempo di decodifica client)\n3. Supporto client (cosa i tuoi chiamanti e gli intermediari gestiscono in modo affidabile)\n\nTutto il resto di questo articolo riguarda bilanciare questi tre fattori per la tua API e i tuoi pattern di traffico.\n\n## ZSTD vs Brotli vs GZIP: confronto rapido\n\nTutti e tre riducono la dimensione del payload, ma ottimizzano per vincoli diversi—velocità, rapporto di compressione e compatibilità.\n\n### Sintesi a colpo d'occhio\n\n- ZSTD (Zstandard): spesso il miglior bilanciamento per le API quando ti interessa bassa latenza e CPU prevedibile. Buon rapporto senza essere lento.\n- Brotli: spesso vince per minori byte sulla rete, specialmente per risposte molto testuali (JSON, contenuti simili a HTML). I livelli alti possono costare più CPU.\n- GZIP: l'opzione “funziona ovunque”. Ampiamente supportato e facile da operare, ma tipicamente più lento e/o più grande rispetto alle alternative moderne a pari budget di CPU.\n\n### Punti di forza tipici (e cosa significano per le API)\n\nVelocità di ZSTD: ottima quando la tua API è sensibile alla latenza di tail o i server sono CPU‑bound. Può comprimere abbastanza velocemente che l'overhead spesso è trascurabile rispetto al tempo di rete—specialmente per risposte JSON di dimensioni medio‑grandi.\n\nRapporto di Brotli: migliore quando la banda è la priorità (client mobile, egress costoso, distribuzione via CDN) e le risposte sono per lo più testuali. Ridurre anche pochi KB può valere la pena se puoi permetterti CPU extra.\n\nCompatibilità di GZIP: utile quando hai bisogno del massimo supporto client con minimo rischio di negoziazione (SDK vecchi, client embedded, proxy legacy). È una baseline sicura anche se non è la migliore.\n\n### Cosa cambia davvero il “livello di compressione”\n\nI “livelli” di compressione sono preset che scambiano tempo CPU per output più piccolo:\n\n- Livelli bassi: compressione più veloce, payload più grandi. Buoni per API in tempo reale.\n- Livelli alti: payload più piccoli, compressione più lenta (e a volte più memoria). Meglio per risposte grandi e cacheabili.\n\nLa decompressione è di solito molto più economica della compressione per tutti e tre, ma livelli molto alti possono comunque aumentare il costo client—importante per mobile.\n\n### Regola pratica semplice\n\n- Scelta predefinita: usa ZSTD per la maggior parte delle API JSON/REST/GraphQL dove la latenza conta.\n- Passa a Brotli: quando stai ottimizzando per byte minimi (risposte testuali, distribuzione CDN, reti lente) e puoi permetterti più CPU.\n- Rimani su GZIP: quando ti serve ampia compatibilità o la tua infrastruttura non supporta codifiche più recenti.\n\n## Rapporto di compressione vs latenza: il trade‑off fondamentale\n\nLa compressione è spesso venduta come “risposte più piccole = API più veloci”. Questo è spesso vero su reti lente o costose—ma non automaticamente. Se la compressione aggiunge abbastanza tempo CPU al server, la richiesta può diventare più lenta nonostante meno byte in rete.\n\n### Dove va il tempo\n\nÈ utile separare due costi:\n\n- Tempo di compressione (lato server): lavoro fatto prima che il server possa iniziare a inviare byte. Questo può aggiungere direttamente al tempo di risposta (TTFB).\n- Tempo di decompressione (lato client): lavoro fatto dopo aver ricevuto i byte. Di solito più economico della compressione, ma può pesare su dispositivi poco potenti o client ad alto throughput.\n\nUn alto rapporto di compressione può ridurre il tempo di trasferimento, ma se la compressione aggiunge (per esempio) 15–30 ms di CPU per risposta, potresti perdere più tempo di quello che risparmi—soprattutto su connessioni veloci.\n\n### La trappola della latenza di tail sotto carico\n\nSotto carico, la compressione può peggiorare la p95/p99 più che la p50. Quando l'uso CPU sale, le richieste attendono in coda. La coda amplifica piccoli costi per richiesta in grandi ritardi—la latenza media può sembrare ok, ma gli utenti più lenti ne soffrono.\n\n### Misuralo come una feature di performance\n\nNon indovinare. Fai un test A/B o un rollout graduale e confronta:\n\n- p50 e p95 (idealmente p99)\n- Utilizzo CPU e saturazione delle istanze API\n- Dimensioni delle risposte e TTFB\n\nTesta con pattern di traffico e payload realistiche. Il livello di compressione “migliore” è quello che riduce il tempo totale, non solo i byte.\n\n## Costi CPU e memoria su server e client\n\nLa compressione non è “gratis”—sposta lavoro dalla rete alla CPU e alla memoria su entrambe le estremità. Nelle API, questo si traduce in tempo di gestione richieste più alto, footprint di memoria maggiore e talvolta rallentamenti client.\n\n### Dove si spende la CPU\n\nLa maggior parte della CPU viene spesa compressendo le risposte. La compressione trova pattern, costruisce stati/dizionari e scrive l'output codificato.\n\nLa decompressione è tipicamente più economica, ma comunque rilevante:\n\n- I server possono decomprimere le richieste (raro per JSON API, più comune per upload o batch di eventi).\n- I client decomprimono le risposte sul percorso critico prima di parsare il JSON.\n\nSe la tua API è già CPU‑bound (server applicativi occupati, auth pesante, query costose), attivare un livello alto di compressione può aumentare la latenza di tail anche se i payload si riducono.\n\n### Considerazioni sulla memoria\n\nLa compressione può aumentare l'uso di memoria in vari modi:\n\n- Buffer: le implementazioni possono richiedere buffer input/output; payload più grandi implicano buffer più grandi.\n- Buffering completo vs streaming: la compressione in streaming può iniziare a inviare prima e mantenere la memoria più bassa, mentre il buffering completo può gonfiare il picco di memoria per richiesta.\n\nIn ambienti containerizzati, picchi di memoria più alti possono tradursi in OOM kills o limiti più stretti che riducono la densità.\n\n### Impatto su autoscaling e limiti container\n\nLa compressione aggiunge cicli CPU per risposta, riducendo il throughput per istanza. Questo può far scattare l'autoscaling prima, aumentando i costi. Un pattern comune: la banda cala, ma il consumo CPU sale—quindi la scelta giusta dipende da quale risorsa è scarsa per te.\n\n### Perché la velocità di decompressione conta per i client\n\nSu mobile o dispositivi a bassa potenza, la decompressione compete con rendering, esecuzione JavaScript e batteria. Un formato che fa risparmiare pochi KB ma impiega più tempo a decomprimere può risultare più lento, in particolare quando conta il “tempo per dati utilizzabili”.\n\n## ZSTD per API: punti di forza, limiti e valori predefiniti sensati\n\nZstandard (ZSTD) è un formato moderno progettato per offrire un buon rapporto di compressione senza rallentare l'API. Per molte API ricche di JSON è una solida “default”: risposte visibilmente più piccole di GZIP a latenza simile o inferiore, più decompressione molto veloce sui client.\n\n### Dove ZSTD eccelle\n\nZSTD è più utile quando ti interessa il tempo end‑to‑end, non solo i byte minimi. Tende a comprimere rapidamente e decomprimere estremamente velocemente—utile per API dove ogni millisecondo di CPU compete con la gestione della richiesta.\n\nFunziona bene su un ampio range di dimensioni payload: JSON piccoli‑medi vedono guadagni significativi, mentre risposte grandi possono beneficiare ancora di più.\n\n### Livelli di compressione sensati per API\n\nPer la maggior parte delle API, inizia con livelli bassi (comuni 1–3). Spesso offrono il miglior compromesso latenza/size.\n\nUsa livelli più alti solo quando:\n\n- I payload sono grandi (centinaia di KB o MB)\n- La banda è costosa o limitata\n- Hai misurato che la CPU non è il collo di bottiglia\n\nUn approccio pragmatico è un default globale basso, poi aumentare selettivamente il livello per alcuni endpoint con risposte grandi.\n\n### Streaming e modalità dizionario\n\nZSTD supporta lo streaming, che può ridurre la memoria di picco e iniziare a inviare dati prima per risposte grandi.\n\nLa modalità dizionario può dare grandi vantaggi per API che tornano molti oggetti simili (chiavi ripetute, schemi stabili). È più efficace quando:\n\n- I payload sono relativamente piccoli ma frequenti\n- Puoi gestire dizionari versionati in modo sicuro\n\n### Limiti di compatibilità da tenere d'occhio\n\nIl supporto server è semplice in molti stack, ma la compatibilità client può essere il fattore decisivo. Alcuni client HTTP, proxy e gateway non annunciano o non accettano Content-Encoding: zstd di default.\n\nSe servi consumatori terzi, mantieni un fallback (di solito GZIP) ed abilita ZSTD solo quando Accept-Encoding lo include chiaramente.\n\n## Brotli per API: quando vince e quando no\n\nBrotli è progettato per comprimere molto bene il testo. Su JSON, HTML e altri payload “verbosi”, spesso supera GZIP sul rapporto di compressione—specialmente a livelli alti.\n\n### Dove Brotli vince\n\nLe risposte molto testuali sono il punto forte di Brotli. Se l'API invia grandi documenti JSON (cataloghi, risultati di ricerca, blob di configurazione), Brotli può ridurre i byte in modo significativo, utile su reti lente e per ridurre costi di egress.\n\nBrotli è anche forte quando puoi comprimere una volta e servire molte volte (risposte cacheabili, risorse versionate). In questi casi, Brotli ad alto livello può valere la pena perché il costo CPU si ammortizza.\n\n### Dove Brotli delude\n\nPer risposte API dinamiche (generate ad ogni richiesta), i migliori rapporti di Brotli spesso richiedono livelli alti che possono essere costosi in CPU e aggiungere latenza. Una volta considerato il tempo di compressione, il vantaggio reale su ZSTD (o anche su GZIP ben configurato) può essere più piccolo del previsto.\n\nÈ anche meno convincente per payload che non si comprimono bene (dati già compressi, molti formati binari). In quei casi consumi CPU inutilmente.\n\n### Indicazioni pratiche sui livelli\n\n- Compressione a runtime: usa livelli bassi (comuni 1–4) per evitare spike di CPU.\n- Precompressed/statico: livelli più alti (spesso 8–11) possono valere la pena quando ammortizzati su molte richieste.\n\n### Note sul supporto client\n\nI browser generalmente supportano bene Brotli su HTTPS, ecco perché è popolare per il traffico web. Per client API non browser (SDK mobile, dispositivi IoT, stack HTTP più vecchi), il supporto può essere inconsistenti—quindi negozia correttamente con Accept-Encoding e mantieni un fallback (tipicamente GZIP).\n\n## GZIP per API: compatibilità e performance pratiche\n\nGZIP resta la risposta predefinita perché è l'opzione più universalmente supportata. Quasi tutti i client HTTP, browser, proxy e gateway capiscono Content-Encoding: gzip, e quella prevedibilità conta quando non controlli completamente cosa c'è tra il server e gli utenti.\n\n### Perché rimane comune\n\nIl vantaggio non è che GZIP sia “migliore”—è che raramente è la scelta sbagliata. Molte organizzazioni hanno anni di esperienza operativa con esso, default sensati nei web server e meno sorprese con intermediari che potrebbero gestire male codifiche più nuove.\n\n### Livelli pratici per API\n\nPer payload API (spesso JSON), livelli medio‑bassi sono il sweet spot. Livelli come 1–6 spesso danno la maggior parte della riduzione della dimensione mantenendo CPU ragionevole.\n\nLivelli molto alti (8–9) possono spremere qualcosina in più, ma il tempo CPU aggiuntivo di solito non vale per traffico dinamico dove la latenza conta.\n\n### Come si confronta sulle CPU moderne\n\nSu hardware moderno, GZIP è generalmente più lento di ZSTD a rapporti di compressione simili, e spesso non raggiunge i migliori rapporti di Brotli su testo. Nei workload reali di API questo spesso significa:\n\n- ZSTD vince spesso su rapporto velocità/byte_risparmiati.\n- Brotli può vincere sulle dimensioni per testo altamente comprimibile, ma può costare più CPU a seconda delle impostazioni.\n- GZIP resta competitivo perché è "abbastanza veloce" ed è altamente ottimizzato negli stack.\n\n### Edge case di compatibilità (client e intermediari vecchi)\n\nSe devi supportare client vecchi, dispositivi embedded, proxy aziendali rigidi o gateway legacy, GZIP è la scelta più sicura. Alcuni intermediari possono rimuovere codifiche sconosciute, non passarle o interrompere la negoziazione—problemi meno comuni con GZIP.\n\nSe il tuo ambiente è misto o incerto, partire da GZIP (e aggiungere ZSTD/Brotli solo dove controlli l'intero percorso) è spesso la strategia di rollout più affidabile.\n\n## Tipi di payload: cosa si comprime bene (e cosa no)\n\nI guadagni dalla compressione non dipendono solo dall'algoritmo. Il fattore più importante è il tipo di dati che invii. Alcuni payload si riducono molto con ZSTD, Brotli o GZIP; altri quasi per nulla e consumano solo CPU.\n\n### Candidati ideali (alto ritorno)\n\nLe risposte testuali tendono a comprimersi estremamente bene perché contengono chiavi ripetute, spazi e pattern prevedibili.\n\n- JSON (incluse risposte REST tipiche)\n- GraphQL (spesso verboso con nomi di campo ripetuti)\n- XML e HTML\n- Grandi log di testo e stack traces restituiti dalle API\n\nIn generale, più ripetizione e struttura, migliore il rapporto di compressione.\n\n### Payload binari: “forse” (misura prima)\n\nFormati binari come Protocol Buffers e MessagePack sono più compatti del JSON, ma non sono “casuali”. Possono comunque contenere tag ripetuti, schemi simili e sequenze prevedibili.\n\nQuesto significa che spesso sono ancora comprimibili, soprattutto per risposte grandi o endpoint con liste. La risposta affidabile è testare con traffico reale: stesso endpoint, stessi dati, compressione on/off e confronta dimensione e latenza.\n\n### Di solito non vale la pena (già compressi)\n\nMolti formati sono già compressi internamente. Applicare compressione HTTP sopra di essi in genere dà risparmi trascurabili e può aumentare il tempo di risposta.\n\n- Immagini: JPEG, PNG, WebP\n- Video/audio: MP4 (e simili)\n- Archivi: ZIP, file gzip\n- PDF: spesso usa già compressione\n\nPer questi è comune disabilitare la compressione per tipo di contenuto.\n\n### Euristiche pratiche (semplice da mantenere)\n\nUn approccio semplice è comprimere solo quando le risposte superano una dimensione minima.\n\n- Imposta una soglia minima (per esempio, qualche KB) prima di abilitare Content-Encoding.\n- Comprimi sempre risposte testuali grandi; valuta di saltare la compressione per JSON piccoli dove gli header dominano.\n\nQuesto mantiene la CPU concentrata sui payload dove la compressione davvero riduce banda e migliora le performance end‑to‑end.\n\n## Intestazioni HTTP e negoziazione: farlo correttamente\n\nLa compressione funziona bene solo quando client e server concordano un encoding. Questo avviene tramite Accept-Encoding (inviato dal client) e Content-Encoding (inviato dal server).\n\n### Accept-Encoding e Content-Encoding (semplici esempi)\n\nUn client pubblicizza cosa può decodificare:\n\nhttp\nGET /v1/orders HTTP/1.1\nHost: api.example\nAccept-Encoding: zstd, br, gzip\n\n\nIl server sceglie uno e dichiara cosa ha usato:\n\nhttp\nHTTP/1.1 200 OK\nContent-Type: application/json\nContent-Encoding: zstd\n\n\nSe il client invia Accept-Encoding: gzip e rispondi con Content-Encoding: br, quel client potrebbe non riuscire a parsare il corpo. Se il client non invia Accept-Encoding, il comportamento più sicuro è non comprimere.\n\n### Ordine di priorità lato server\n\nUn ordine pratico per le API è spesso:\n\n- zstd prima (ottimo equilibrio velocità/rapporto)\n- poi br (spesso più piccolo, a volte più lento)\n- poi gzip (massima compatibilità)\n\nIn altre parole: zstd > br > gzip.Non considerarlo universale: se il tuo traffico è per lo più browser, br potrebbe avere priorità più alta; se hai client mobile vecchi, gzip potrebbe essere la scelta più sicura.
Usa la compressione delle risposte quando le risposte sono ricche di testo (JSON/GraphQL/XML/HTML), di dimensioni medio‑grandi e i tuoi utenti sono su reti lente/costose o sostieni costi significativi di egress. Evitala (o usa una soglia alta) per risposte piccole, media già compressa (JPEG/MP4/ZIP/PDF) e servizi CPU‑bound dove lavoro aggiuntivo per richiesta peggiorerebbe p95/p99.
Perché scambia larghezza di banda con CPU (e a volte memoria). Il tempo di compressione può ritardare l'inizio dell'invio dei byte (TTFB) e, sotto carico, amplificare la coda delle richieste—spesso peggiorando la latenza di tail anche se la latenza media migliora. La configurazione “migliore” è quella che riduce il tempo end‑to‑end, non solo le dimensioni dei payload.
Una priorità pratica per molte API è:
zstd prima (veloce, buon rapporto)br (spesso la più piccola per testo, può costare più CPU)gzip (compatibilità più ampia)Basati sempre su ciò che il client annuncia in e mantieni un fallback sicuro (di solito o ).
Parti dal basso e misura.
Usa una soglia minima di dimensione per non consumare CPU su payload minuscoli.
Regola per endpoint confrontando bytes risparmiati vs tempo server aggiunto e l'impatto su p50/p95/p99.
Concentrati su tipi di contenuto strutturati e ripetitivi:
La compressione deve seguire la negoziazione HTTP:
Accept-Encoding (per es., zstd, br, gzip)Content-Encoding supportatoSe il client non invia , la risposta più sicura è tipicamente . Non restituire mai un che il client non ha annunciato, altrimenti rischi errori nel parsing del corpo.
Aggiungi:
Vary: Accept-EncodingQuesto evita che CDN/proxy memorizzino una variante compressa (es. gzip) e la servano a un client che non l'ha richiesta o non la può decodificare (o per zstd/br). Se supporti più codifiche, questa intestazione è essenziale per la correttezza della cache.
I guasti comuni includono:
Tratta il rollout come una feature di performance:
Accept-EncodinggzipidentityI livelli più alti danno solitamente guadagni di dimensione decrescenti ma possono far salire la CPU e peggiorare p95/p99.
Una pratica comune è abilitare la compressione solo per Content-Type testuali e disabilitarla per formati già compressi.
Accept-EncodingContent-EncodingContent-Encoding dichiara gzip ma il corpo non è compresso)Accept-Encoding)Content-Length errato quando si streamma/comprimePer il debug, cattura intestazioni raw e verifica la decompressione con un client/strumento noto funzionante.
Se la latenza di tail cresce sotto carico, abbassa il livello, aumenta la soglia o passa a un codec più veloce (spesso ZSTD).