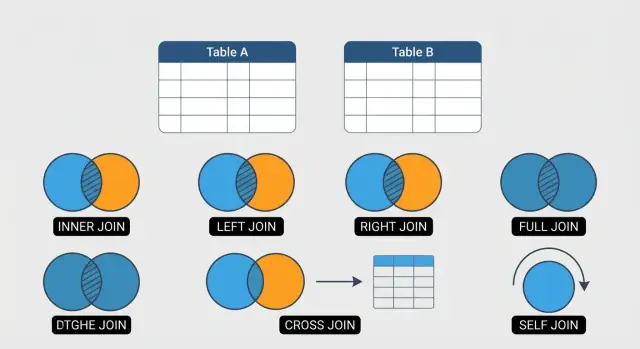
Wat SQL JOINs zijn en waarom je ze gebruikt
Een SQL JOIN laat je rijen uit twee (of meer) tabellen combineren tot één resultaat door ze te matchen op een gerelateerde kolom — meestal een ID.
Waarom JOINs ertoe doen
De meeste echte databases zijn bewust opgesplitst in aparte tabellen zodat je dezelfde informatie niet steeds hoeft te herhalen. Bijvoorbeeld: de naam van een klant staat in een customers-tabel, terwijl hun aankopen in een orders-tabel staan. JOINs zijn hoe je die stukken weer aan elkaar knoopt wanneer je antwoorden nodig hebt.
Daarom zie je JOINs overal in rapportage en analyse:
- Een salesrapport bouwen met klantnamen, ordertotalen en betaalstatus
- Klanten vinden die nog niet hebben besteld
- Ongelijkheden auditen, zoals orders zonder betalingen
- "Eén rij per klant" samenvattingen maken uit veel gerelateerde rijen
Zonder JOINs zou je aparte queries moeten draaien en resultaten handmatig combineren—traag, foutgevoelig en moeilijk reproduceerbaar.
Als je producten bouwt bovenop een relationele database (dashboards, adminpanelen, interne tools, klantportals), zijn JOINs ook wat "ruwe tabellen" verandert in gebruikersgerichte weergaven. Platforms zoals Koder.ai (die React + Go + PostgreSQL-apps genereert vanuit chat) blijven vertrouwen op goede JOIN-principes wanneer je accurate lijsten, rapporten en reconciliatieschermen nodig hebt — want de databaselogica verdwijnt niet, ook al gaat ontwikkeling sneller.
De 6 JOIN-types die je het meest gebruikt
Deze gids richt zich op zes JOINs die het grootste deel van het dagelijkse SQL-werk dekken:
- INNER JOIN: retourneert alleen rijen die in beide tabellen matchen (handig voor "toon me bevestigde relaties").
- LEFT JOIN: behoudt elke rij uit de linkertabel en voegt toe wat er van de rechterkant te matchen valt (handig voor "inclusief ontbrekende gerelateerde data").
- RIGHT JOIN: de spiegel van LEFT JOIN (minder gebruikelijk, maar nuttig afhankelijk van stijl of leesbaarheid).
- FULL OUTER JOIN: behoudt alle rijen uit beide tabellen, matcht waar mogelijk (geweldig voor reconciliatie en het vinden van gaten).
- CROSS JOIN: produceert alle combinaties van rijen (handig voor kalenders, scenario's of testdata — maar gemakkelijk te misbruiken).
- SELF JOIN: een tabel aan zichzelf joinen (handig voor hiërarchieën zoals medewerkers/managers).
Een korte opmerking over syntax
JOIN-syntax is grotendeels gelijk in de meeste SQL-databases (PostgreSQL, MySQL, SQL Server, SQLite). Er zijn enkele verschillen — vooral rond FULL OUTER JOIN-ondersteuning en sommige edge-case gedragingen — maar de concepten en kernpatronen zijn goed overdraagbaar.
De voorbeeldtabellen die we gebruiken (customers, orders, payments)
Om de JOIN-voorbeelden eenvoudig te houden gebruiken we drie kleine tabellen die een veelvoorkomende echte opzet weerspiegelen: klanten plaatsen orders, en orders kunnen (of niet) betalingen hebben.
Een kleine opmerking voordat we beginnen: de voorbeeldtabellen hieronder tonen maar een paar kolommen, maar sommige queries later verwijzen naar extra velden (zoals order_date, created_at, status of paid_at) om veelvoorkomende patronen te demonstreren. Zie die kolommen als "typische" velden die je vaak in productieschema's zult hebben.
1) customers
Primary key: customer_id
| customer_id | name |
|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
2) orders
Primary key: order_id
Foreign key: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
Let op: order_id = 104 verwijst naar customer_id = 5, wat niet bestaat in customers. Die "ontbrekende match" is handig om te zien hoe LEFT JOIN, RIGHT JOIN en FULL OUTER JOIN zich gedragen.
3) payments
Primary key: payment_id
Foreign key: order_id → orders.order_id
| payment_id | order_id | amount |
|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
Twee belangrijke "leerpunten" hier:
order_id = 102 heeft twee payment-rijen (een gesplitste betaling). Als je orders aan payments joinet, verschijnt die order twee keer — dit is waar duplicaten mensen vaak verrassen.payment_id = 9004 verwijst naar order_id = 999, wat niet bestaat in orders. Dat creëert nog een "onvergelijkbare" case.
Wat je kunt verwachten als we deze tabellen joinen
- Matchende rijen: bijv. klant 1 ↔ orders 101/102; order 101 ↔ payment 9001.
- Niet-matchende rijen: bijv. klant 3 en 4 hebben geen orders; order 104 heeft geen klant; payment 9004 heeft geen order.
- Duplicaten: het joinen van
orders naar payments zal order 102 herhalen omdat die twee gerelateerde betalingen heeft.
INNER JOIN: Alleen overeenkomende rijen behouden
Een INNER JOIN geeft alleen de rijen terug waar er een match is in beide tabellen. Als een klant geen orders heeft, verschijnt die niet in het resultaat. Als een order naar een niet-bestaande klant verwijst (slechte data), verschijnt die order ook niet.
Het basismodel
Je kiest een "linker" tabel, joind een "rechter" tabel en verbindt ze met een conditie in de ON-clausule.
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
Het belangrijkste is de regel ON o.customer_id = c.customer_id: die vertelt SQL hoe rijen horen te relateren.
Praktijkgeval: klanten die een bestelling plaatsten
Als je een lijst wilt van alleen klanten die daadwerkelijk minimaal één order hebben geplaatst (en de ordergegevens), is INNER JOIN de natuurlijke keuze:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
Dit is handig voor dingen als "stuurt een follow-up e-mail bij een bestelling" of "bereken omzet per klant" (wanneer je alleen geeft om klanten met aankopen).
Veelgemaakte fout: ontbrekende of onduidelijke join-condities
Als je een join schrijft maar de ON-conditie vergeet (of op de verkeerde kolommen joind), kun je per ongeluk een Cartesian product maken (elke klant gecombineerd met elke order) of subtiel verkeerde matches produceren.
Fout (niet doen):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
Zorg altijd dat je een duidelijke join-voorwaarde in ON hebt (of USING in specifieke gevallen waar dat van toepassing is — verderop behandeld).
LEFT JOIN: Alles uit de linker tabel behouden
Een LEFT JOIN geeft alle rijen uit de linkertabel terug en voegt bijpassende data uit de rechtertabel toe indien die bestaat. Als er geen match is, verschijnen de rechterkolommen als NULL.
Wanneer je het gebruikt
Gebruik een LEFT JOIN wanneer je een volledige lijst van je primaire tabel wilt, plus optionele gerelateerde data.
Voorbeeld: "Toon alle klanten, en includeer hun orders als ze die hebben."
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
- Klanten met orders verschijnen met hun ordergegevens.
- Klanten zonder orders verschijnen nog steeds, maar
o.order_id (en andere orders-kolommen) zullen NULL zijn.
De "geen match" rijen vinden (klassiek patroon)
Een zeer gebruikelijke reden om LEFT JOIN te gebruiken is om items te vinden die geen gerelateerde records hebben.
Voorbeeld: "Welke klanten hebben nooit een order geplaatst?"
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
Die WHERE ... IS NULL-voorwaarde houdt alleen de linkertabelrijen waar de join geen match kon vinden.
Let op: meerdere matches vermenigvuldigen rijen
LEFT JOIN kan linker-rijen "dupliceren" wanneer er meerdere overeenkomende rijen aan de rechterkant zijn.
Als één klant 3 orders heeft, verschijnt die klant 3 keer — één keer per order. Dat is verwacht, maar kan je verrassen als je klanten probeert te tellen.
Bijvoorbeeld, dit telt orders (niet klanten):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
Als je klanten wilt tellen, tel je meestal de klantkey (vaak met COUNT(DISTINCT c.customer_id)), afhankelijk van wat je meet.
RIGHT JOIN: Alles uit de rechter tabel behouden
Een RIGHT JOIN behoudt alle rijen uit de rechtertabel en alleen de overeenkomende rijen uit de linkertabel. Als er geen match is, verschijnen de linker-kolommen als NULL. Het is in wezen een spiegelbeeld van een LEFT JOIN.
Een eenvoudig voorbeeld
Met onze voorbeeldtabellen wil je misschien elke betaling weergeven, ook als die niet aan een order te koppelen is (misschien is de order verwijderd of zijn de betaalgegevens rommelig).
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
Wat je krijgt:
- Alle payments zijn opgenomen (omdat
payments rechts staat).
- Als een betaling geen overeenkomende order heeft, dan zijn
o.order_id en o.customer_id NULL.
Dezelfde query als LEFT JOIN (vaak te verkiezen)
Meestal kun je een RIGHT JOIN herschrijven als een LEFT JOIN door de tabelvolgorde om te draaien:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
Dit geeft hetzelfde resultaat, maar veel mensen vinden het makkelijker leesbaar: je begint met de "hoofd"-tabel waar je om geeft (hier payments) en haalt optioneel gerelateerde data op.
Leesbaarheid: waarom veel teams RIGHT JOIN vermijden
Veel SQL-styleguides ontmoedigen RIGHT JOIN omdat het lezers dwingt mentaal het patroon om te keren:
- "Begin met de hoofdtafel"
- "LEFT JOIN extra tabellen"
Als optionele relaties consequent als LEFT JOINs worden geschreven, worden queries makkelijker te scannen.
Wanneer RIGHT JOIN nog steeds handig kan zijn
Een RIGHT JOIN kan handig zijn als je een bestaande query bewerkt en je merkt dat de "moet-behouden" tabel momenteel rechts staat. In plaats van de hele query te herschrijven (vooral een lange met meerdere joins), kan het schakelen naar RIGHT JOIN een snelle, laag-risico wijziging zijn.
FULL OUTER JOIN: Alle rijen uit beide tabellen behouden
Beheer je gegenereerde code
Neem de broncode mee wanneer je JOIN-zware logica aangepaste wijzigingen nodig heeft.
Een FULL OUTER JOIN retourneert elke rij uit beide tabellen.
- Als een rij matcht op de join-key, krijg je één gecombineerde rij (zoals bij
INNER JOIN).
- Als een rij alleen in de linkertabel bestaat, verschijnt die alsnog — met
NULLs voor de rechterkolommen.
- Als een rij alleen in de rechtertabel bestaat, verschijnt die alsnog — met
NULLs voor de linker-kolommen.
Wanneer het nuttig is
Een klassiek bedrijfsgeval is reconciliatie van orders versus payments:
- Je wilt betaalde orders zien (matches)
- onbetaalde orders (order bestaat, betaling ontbreekt)
- vreemde betalingen (betaling bestaat, maar geen order — datavout, terugbetaling, verkeerde referentie, etc.)
Voorbeeld:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
Database-ondersteuning (wie kan het direct draaien)
FULL OUTER JOIN wordt ondersteund in PostgreSQL, SQL Server en Oracle.
Het is niet beschikbaar in MySQL en SQLite (daar heb je een workaround voor nodig).
Portable alternatief: UNION van LEFT JOIN en RIGHT JOIN
Als je database FULL OUTER JOIN niet ondersteunt, kun je het simuleren door te combineren:
- alle rijen van
orders (met matching payments waar beschikbaar), en
- alle rijen van
payments die niet aan een order matchen.
Een veelgebruikt patroon:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
Tip: wanneer je NULLs aan één kant ziet, is dat je signaal dat de rij aan de andere kant ontbrak — precies wat je wilt voor audits en reconciliatie.
CROSS JOIN: Maak alle combinaties (gebruik met zorg)
Een CROSS JOIN retourneert alle mogelijke paren van rijen uit twee tabellen. Als tabel A 3 rijen heeft en tabel B 4 rijen, heeft het resultaat 3 × 4 = 12 rijen. Dit wordt ook wel een cartezisch product genoemd.
Dat klinkt eng — en dat kan het ook zijn — maar het is echt nuttig wanneer je juist combinaties wilt genereren.
Een klein, veilig voorbeeld: maten × kleuren (SKU's genereren)
Stel dat je productopties in aparte tabellen onderhoudt:
sizes: S, M, Lcolors: Red, Blue
Een CROSS JOIN kan alle mogelijke varianten genereren (handig voor het aanmaken van SKU's, het vooraf bouwen van een catalogus of testen):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
Resultaat (3 × 2 = 6 rijen):
- S / Red
- S / Blue
- M / Red
- M / Blue
- L / Red
- L / Blue
De grote waarschuwing: resultaten groeien snel
Omdat het aantal rijen vermenigvuldigt, kan CROSS JOIN snel exploderen:
- 10.000 klanten × 50 producten = 500.000 rijen
- 100.000 × 100.000 = 10.000.000.000 rijen
Dat kan queries vertragen, geheugen overweldigen en output opleveren die niemand kan gebruiken. Als je combinaties nodig hebt, houd de inputtabellen klein en overweeg limieten of filters op een gecontroleerde manier.
SELF JOIN: Een tabel aan zichzelf koppelen
Bouw snel een adminpanel
Maak snel React-, Go- en PostgreSQL-CRUD-schermen en verfijn daarna de queries.
Een SELF JOIN is precies wat het zegt: je joinet een tabel aan zichzelf. Dit is nuttig wanneer één rij in een tabel relateert aan een andere rij in dezelfde tabel — meestal bij "ouder/kind"-relaties zoals medewerkers en hun managers.
Waarom aliassen nodig zijn (en hoe ze helpen)
Omdat je dezelfde tabel twee keer gebruikt, moet je elke "kopie" een andere alias geven. Aliassen maken de query leesbaar en vertellen SQL aan welke kant je refereert.
Een veelgebruikt patroon is:
e voor de employeem voor de manager
Praktisch voorbeeld: medewerkers en hun managers
Stel een employees-tabel voor met:
idnamemanager_id (verwijst naar het id van een andere medewerker)
Om elke medewerker met de naam van zijn manager te tonen:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Top-level medewerkers afhandelen (NULL manager_id)
Let op dat de query een LEFT JOIN gebruikt, niet een INNER JOIN. Dat is belangrijk omdat sommige medewerkers geen manager hebben (bijvoorbeeld de CEO). In die gevallen is manager_id vaak NULL, en een LEFT JOIN behoudt de medewerkerrij terwijl manager_name NULL toont.
Als je een INNER JOIN zou gebruiken, zouden die top-level medewerkers uit de resultaten verdwijnen omdat er geen bijpassende managerrij is om mee te joinen.
Join-condities: ON versus USING (en waarom het ertoe doet)
Een JOIN weet niet "magisch" hoe twee tabellen zich verhouden — je moet het opgeven. Die relatie wordt gedefinieerd in de join-conditie, en die hoort direct naast de JOIN omdat het uitlegt hoe de tabellen matchen, niet hoe je het uiteindelijke resultaat wilt filteren.
ON: het meest flexibel (en het meest gebruikt)
Gebruik ON wanneer je volledige controle wilt over de match-logica — verschillende kolomnamen, meerdere voorwaarden of extra regels.
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON is ook waar je complexere matches kunt definiëren (bijvoorbeeld matchen op twee kolommen) zonder dat je query een gokspel wordt.
USING: korter, maar alleen voor kolommen met dezelfde naam
Sommige databases (zoals PostgreSQL en MySQL) ondersteunen USING. Het is een handige shorthand wanneer beide tabellen een kolom met exact dezelfde naam hebben en je daarop wilt joinen.
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
Een voordeel: USING geeft meestal slechts één customer_id-kolom in de output (in plaats van twee kopieën).
Vermijd ambiguïteit: kwalificeer kolomnamen in joins
Zodra je tabellen joinet, overlappen kolomnamen vaak (id, created_at, status). Als je SELECT id schrijft, kan de database een "ambiguous column"-fout geven — of erger, je leest per ongeluk de verkeerde id.
Gebruik bij voorkeur tabelprefixes (of aliassen) voor duidelijkheid:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
Vermijd SELECT * in joined queries
SELECT * wordt snel rommelig bij joins: je haalt onnodige kolommen binnen, loopt kans op dubbele namen en maakt het lastiger te zien wat de query moet opleveren.
Selecteer in plaats daarvan precies de kolommen die je nodig hebt. Je resultaat is schoner, makkelijker te onderhouden en vaak efficiënter — vooral wanneer tabellen breed zijn.
Gegevens filteren bij joins: WHERE versus ON
Wanneer je tabellen joinet, filteren zowel WHERE als ON, maar ze doen dat op verschillende momenten.
- ON bepaalt welke rijen matchen tijdens de join.
- WHERE filtert het finale resultaat nadat de join al gevormd is.
Dat tijdsverschil is de reden dat mensen per ongeluk een LEFT JOIN in een INNER JOIN veranderen.
Hoe WHERE per ongeluk een LEFT JOIN kan breken
Stel dat je alle klanten wilt, zelfs degenen zonder recente betaalde orders.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Probleem: voor klanten zonder bijpassende order zijn o.status en o.order_date NULL. De WHERE-clausule verwerpt die rijen, dus de unmatched klanten verdwijnen — je LEFT JOIN gedraagt zich als een INNER JOIN.
Verplaats join-gerelateerde voorwaarden naar ON om unmatched rijen te behouden
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Nu verschijnen klanten zonder kwalificerende orders nog steeds (met NULL-orderkolommen), wat meestal het doel is van een LEFT JOIN.
Korte checklist: wat hoort in ON versus WHERE?
- Zet voorwaarden in ON wanneer ze beschrijven welke rechter-tablerijen mogen matchen (status/datums/typen op de joined tabel).
- Zet voorwaarden in WHERE wanneer ze beschrijven welke uiteindelijke rijen je wilt behouden (filters op de linkertabel, of wanneer je expliciet een match vereist).
- Als je "behoud alle linker-rijen, maar beperk rechter-rijen" nodig hebt, geef de voorkeur aan LEFT JOIN + voorwaarden in ON.
- Als je echt alleen rijen met een match bedoelt, gebruik dan INNER JOIN (of
WHERE o.order_id IS NOT NULL expliciet).
Duplicaten en many-to-many verrassingen vermijden
Bouw en verdien credits
Verdien credits door te delen wat je bouwde met Koder.ai of anderen uit te nodigen.
Joins voegen niet alleen kolommen toe — ze kunnen ook rijen vermenigvuldigen. Dat is meestal correct gedrag, maar het verrast vaak wanneer totalen ineens verdubbelen (of erger).
Waarom rijen vermenigvuldigen
Een join geeft één outputrij voor elk paar matchende rijen.
- One-to-many: één klant kan veel orders hebben. Als je
customers aan orders joind, verschijnt elke klant mogelijk meerdere keren — één keer per order.
- Many-to-many (de echte valkuil): als je
orders aan payments joinet en elke order meerdere betalingen kan hebben, kun je meerdere rijen per order krijgen. Als je ook joined met een andere "many" tabel (zoals order_items), kun je een vermenigvuldigingseffect krijgen: payments × items per order.
Eerst aggregereer, dan join
Als je doel "één rij per klant" of "één rij per order" is, vat dan eerst de "many"-kant samen en join daarna.
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
Dit houdt de join-vorm voorspelbaar: één orderrij blijft één orderrij.
DISTINCT is een laatste redmiddel
SELECT DISTINCT kan duplicaten lijken op te lossen, maar het verbergt mogelijk het echte probleem:
- Het kan legitieme rijen stilletjes weghalen.
- Het kan een slechte join-voorwaarde verbergen (zoals het missen van onderdeel van een samengestelde sleutel).
- Het kan totalen verkeerd maken (vooral bij sommen en tellingen).
Gebruik het alleen wanneer je zeker weet dat duplicaten puur per ongeluk zijn en je begrijpt waarom ze ontstonden.
Korte veiligheidscontrole: valideer aantallen
Voordat je resultaten vertrouwt, vergelijk rijaantallen:
- Tel rijen in je hoofdtafel (bijv. orders).
- Tel rijen na de join.
- Als het aantal onverwacht stijgt, inspecteer welke sleutel(s) meerdere matches veroorzaken en beslis of je moet aggregeren of een andere join-route moet nemen.
Prestatiebasis en een korte JOIN-spiekbrief
JOINs krijgen vaak de schuld van "trage queries", maar de echte oorzaak is meestal hoeveel data je de database vraagt te combineren en hoe gemakkelijk het is om matching rijen te vinden.
Indexering (conceptueel) en waarom het JOINs helpt
Zie een index als de inhoudsopgave van een boek. Zonder index moet de database mogelijk veel rijen scannen om matches voor je JOIN-voorwaarde te vinden. Met een index op de join-key (bijv. customers.customer_id en orders.customer_id) kan de database veel sneller naar de relevante rijen springen.
Je hoeft de interne werking niet te kennen om dit goed te gebruiken: als een kolom vaak gebruikt wordt om rijen te matchen (ON a.id = b.a_id), is het een goede kandidaat om geïndexeerd te worden.
Join op stabiele keys (niet op namen of e-mails)
Waar mogelijk, join op stabiele, unieke identifiers:
- Goed:
customers.customer_id = orders.customer_id
- Riskant:
customers.email = orders.email of customers.name = orders.name
Namen veranderen en kunnen herhaald voorkomen. E-mails kunnen wijzigen, ontbreken of verschillen in case/format. ID's zijn specifiek ontworpen voor consistente matches en zijn vaak geïndexeerd.
Verminder het werk vroeg
Twee gewoonten maken JOINs merkbaar sneller:
- Selecteer minder kolommen. Vermijd
SELECT * bij het joinen van meerdere tabellen — extra kolommen verhogen geheugen- en netwerkverbruik.
- Beperk rijen vóór of tijdens de JOIN. Filter zo vroeg mogelijk.
Voorbeeld: beperk orders eerst en join dan:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
Als je deze queries iteratief ontwikkelt in een app-build (bijvoorbeeld een rapportagepagina gebaseerd op PostgreSQL), kunnen tools zoals Koder.ai het scaf-folding versnellen — schema, endpoints, UI — terwijl jij de controle behoudt over de JOIN-logica die correctheid bepaalt.
Korte JOIN-spiekbrief
- INNER JOIN → alleen rijen die in beide tabellen matchen
- LEFT JOIN → alle rijen uit de linkertabel, plus matches uit de rechter (niet-matches worden
NULL)
- RIGHT JOIN → alle rijen uit de rechtertabel, plus matches uit de linker (
NULL wanneer ontbrekend)
- FULL OUTER JOIN → alle rijen uit beide tabellen; matches samengevoegd, niet-matches tonen
NULLs
- CROSS JOIN → elke combinatie van rijen (aantallen vermenigvuldigen; gebruik met zorg)
- SELF JOIN → een tabel aan zichzelf koppelen (handig voor hiërarchieën en vergelijkingen)