26 aug 2025·8 min
Hoe je AI-first producten bouwt met modellen in de applicatielogica
Een praktische gids voor het bouwen van AI-first producten waarbij het model beslissingen stuurt: architectuur, prompts, tools, data, evaluatie, veiligheid en monitoring.
Wat het betekent om een AI-first product te bouwen
Een AI-first product bouwen betekent niet simpelweg "een chatbot toevoegen." Het betekent dat het model een echt, werkend onderdeel is van je applicatielogica—op dezelfde manier als een regelsysteem, zoekindex of aanbevelingsalgoritme.
Je app gebruikt AI niet alleen; hij is ontworpen rond het feit dat het model input zal interpreteren, acties zal kiezen en gestructureerde outputs zal produceren waarop de rest van het systeem vertrouwt.
In praktische zin: in plaats van elke beslisroute hard te coderen ("als X dan Y"), laat je het model de vage onderdelen afhandelen—taal, intentie, ambiguïteit, prioritering—terwijl jouw code regelt wat precies moet zijn: permissies, betalingen, databasewrites en handhaving van beleid.
Wanneer AI-first geschikt is (en wanneer niet)
AI-first werkt het beste wanneer het probleem:
- Veel geldige inputs heeft (vrije tekst, rommelige documenten, uiteenlopende gebruikersdoelen)
- Te veel randgevallen heeft om handmatig regels te onderhouden
- Meer waarde heeft in oordelen, samenvattingen of synthese dan in perfecte determinisme
Regelgebaseerde automatisering is meestal beter wanneer vereisten stabiel en exact zijn—belastingberekeningen, voorraadlogica, geschiktheidschecks of compliance-workflows waarbij de output elke keer hetzelfde moet zijn.
Veelvoorkomende productdoelen die AI-first ondersteunt
Teams kiezen vaak voor modelgedreven logica om:
- Snelheid te verhogen: conceptantwoorden maken, velden extraheren, verzoeken sneller routeren
- Ervaringen te personaliseren: uitleg, plannen of aanbevelingen afstemmen
- Beslissingen te ondersteunen: afwegingen benadrukken, opties genereren, bewijs samenvatten
De afwegingen die je moet accepteren (en ontwerpen voor)
Modellen kunnen onvoorspelbaar zijn, soms vol vertrouwen fout, en hun gedrag kan veranderen als prompts, providers of opgehaalde context veranderen. Ze voegen ook kosten per verzoek toe, kunnen latentie introduceren en brengen veiligheids- en vertrouwenszorgen met zich mee (privacy, schadelijke output, beleidsinbreuken).
De juiste mentaliteit: behandel het model als een component, niet als een magische antwoordsdoos. Behandel het als een afhankelijkheid met specificaties, faalmodi, tests en monitoring—zodat je flexibiliteit krijgt zonder het product op wensdenken te baseren.
Kies de juiste use case en definieer succes
Niet elke feature profiteert ervan om een model aan het stuur te zetten. De beste AI-first use cases beginnen met een duidelijke "job-to-be-done" en eindigen met een meetbaar resultaat dat je week na week kunt volgen.
Begin met de taak, niet met het model
Schrijf een eendelige job story: "Wanneer ___, wil ik ___, zodat ik ___." Maak het resultaat meetbaar.
Voorbeeld: "Wanneer ik een lange klantmail ontvang, wil ik een voorgesteld antwoord dat bij ons beleid hoort, zodat ik binnen 2 minuten kan reageren." Dat is veel actievere dan "voeg een LLM toe aan e-mail."
Breng de beslismomenten in kaart
Identificeer de momenten waarop het model acties kiest. Deze beslismomenten moeten expliciet zijn zodat je ze kunt testen.
Veelvoorkomende beslispunten zijn:
- Intentie classificeren en routeren naar de juiste workflow
- Besluiten of er een verduidelijkingsvraag gesteld moet worden of doorgegaan kan worden
- Tools selecteren (search, CRM-lookup, opstellen, ticket aanmaken)
- Besluiten wanneer er naar een mens geëscaleerd moet worden
Als je de beslissingen niet kunt benoemen, ben je nog niet klaar om modelgedreven logica te lanceren.
Schrijf acceptatiecriteria voor gedrag
Behandel modelgedrag als elke andere productvereiste. Definieer in gewone taal wat "goed" en "slecht" is.
Bijvoorbeeld:
- Goed: gebruikt het nieuwste beleid, citeert het correcte order-ID, stelt één duidelijke vraag als informatie ontbreekt
- Slecht: verzint kortingen, verwijst naar niet-ondersteunde locaties, of antwoordt zonder vereiste data te controleren
Deze criteria vormen later de basis voor je evaluatieset.
Identificeer beperkingen vroeg
Maak een lijst met beperkingen die je ontwerpskeuzes vormen:
- Tijd (reactietijddoelen)
- Budget (kosten per taak)
- Compliance (PII-hantering, auditvereisten)
- Ondersteunde locales (talen, toon, culturele verwachtingen)
Definieer succesmetingen die je kunt monitoren
Kies een kleine set metrics gekoppeld aan de taak:
- Taakvoltooiingspercentage
- Nauwkeurigheid (of beleidsnaleving) op representatieve gevallen
- CSAT of kwalitatieve gebruikersbeoordeling
- Tijdswinst per taak (of time-to-resolution)
Als je succes niet kunt meten, blijf je over vibes discussiëren in plaats van het product te verbeteren.
Ontwerp de AI-gedreven gebruikersstroom en systeemgrenzen
Een AI-first flow is geen "scherm dat een LLM aanroept." Het is een end-to-end reis waarin het model bepaalde beslissingen neemt, het product ze veilig uitvoert en de gebruiker georiënteerd blijft.
Kaart de end-to-end lus
Begin met de pijplijn als een eenvoudige keten: inputs → model → acties → outputs.
- Inputs: wat de gebruiker aanlevert (tekst, bestanden, selecties) plus app-context (accounttier, workspace, recente activiteit).
- Modelstap: waar het model verantwoordelijk voor is (classificeren, opstellen, samenvatten, volgende actie kiezen).
- Acties: wat je systeem kan doen (zoeken, taak aanmaken, record bijwerken, e-mail versturen).
- Outputs: wat de gebruiker ziet (een concept, een uitleg, een bevestigingsscherm, een fout met vervolgstappen).
Deze kaart dwingt duidelijkheid over waar onzekerheid acceptabel is (opstellen) versus waar dat niet is (factureringswijzigingen).
Trek systeemgrenzen: model versus deterministische code
Scheid deterministische paden (permissiecontroles, businessregels, berekeningen, databasewrites) van modelgedreven beslissingen (interpretatie, prioritering, natural-language generatie).
Een nuttige vuistregel: het model mag aanbevelen, maar code moet verifiëren voordat iets onomkeerbaars gebeurt.
Beslis waar het model draait
Kies een runtime op basis van beperkingen:
- Server: het beste voor private data, consistente tooling, auditlogs.
- Client: handig voor lichte assistentie en privacy door lokale verwerking, maar moeilijker te controleren.
- Edge: snellere globale latentie, maar beperkte afhankelijkheden.
- Hybride: snelle intentdetectie aan de edge en zwaarder werk op de server splitsen.
Budgetteer latentie, kosten en datapermissies
Stel een per-verzoek latentie- en kostenbudget vast (inclusief retries en toolcalls) en ontwerp de UX eromheen (streaming, progressieve resultaten, "ga door op de achtergrond").
Documenteer databronnen en permissies die bij elke stap nodig zijn: wat het model mag lezen, wat het mag schrijven en wat expliciete gebruikersbevestiging vereist. Dit wordt een contract voor zowel engineering als vertrouwen.
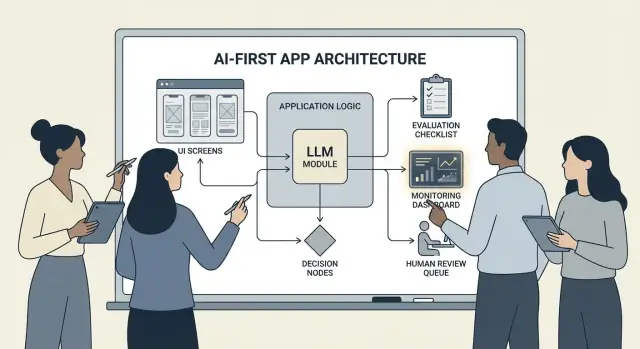
Architectuurpatronen: Orchestratie, State en Traces
Wanneer een model deel uitmaakt van je applicatielogica, is "architectuur" niet alleen servers en API's—het gaat om hoe je betrouwbaar een keten van modelbeslissingen uitvoert zonder controle te verliezen.
Orchestratie: de dirigent van modelwerk
Orchestratie is de laag die beheert hoe een AI-taak end-to-end uitgevoerd wordt: prompts en templates, toolcalls, geheugen/context, retries, timeouts en fallbacks.
Goede orchestrators behandelen het model als één component in een pipeline. Ze beslissen welke prompt te gebruiken, wanneer een tool aangeroepen wordt (search, database, e-mail, betaling), hoe context samen te persen of op te halen, en wat te doen als het model iets ongeldigs teruggeeft.
Als je sneller van idee naar werkende orchestratie wilt, kan een vibe-coding workflow helpen prototypen zonder de app-scaffolding opnieuw te bouwen. Bijvoorbeeld, Koder.ai laat teams webapps (React), backends (Go + PostgreSQL) en zelfs mobiele apps (Flutter) creëren via chat—en vervolgens itereren op flows zoals "inputs → model → tool calls → validaties → UI" met features als planning mode, snapshots en rollback, plus source-code export wanneer je klaar bent om de repo te beheren.
Toestandsmachines voor multi-step taken
Multi-step ervaringen (triage → informatie verzamelen → bevestigen → uitvoeren → samenvatten) werken het beste wanneer je ze modelleert als een workflow of toestandsmachine.
Een eenvoudig patroon: elke stap heeft (1) toegestane inputs, (2) verwachte outputs, en (3) transities. Dit voorkomt doelloze gesprekken en maakt randgevallen expliciet—zoals wat er gebeurt als de gebruiker van gedachten verandert of gedeeltelijke info geeft.
Single-shot versus multi-turn redeneren
Single-shot werkt goed voor afgebakende taken: classificeer een bericht, stel een kort antwoord op, extraheer velden uit een document. Het is goedkoper, sneller en makkelijker te valideren.
Multi-turn redeneren is beter wanneer het model verduidelijkende vragen moet stellen of wanneer tools iteratief nodig zijn (bijv. plan → zoek → verfijn → bevestig). Gebruik het doelbewust en beperk loops met tijd-/staplimieten.
Idempotentie: vermijd herhaalde bijwerkingen
Modellen voeren retries uit. Netwerken falen. Gebruikers dubbelklikken. Als een AI-stap bijwerkingen kan veroorzaken—e-mail verzenden, boeken, afschrijven—maak die dan idempotent.
Veelvoorkomende tactieken: voeg een idempotentiesleutel toe aan elke "execute"-actie, sla het actieresultaat op en zorg dat retries hetzelfde resultaat teruggeven in plaats van het te herhalen.
Traces: maak elke stap debugbaar
Voeg traceerbaarheid toe zodat je kunt beantwoorden: Wat zag het model? Wat besloot het? Welke tools draaiden?
Log een gestructureerde trace per run: promptversie, inputs, opgehaalde context-IDs, toolrequests/-responses, validatiefouten, retries en de uiteindelijke output. Dit verandert "AI deed iets vreemds" in een regelbare, repareerbare tijdlijn.
Prompting als productlogica: duidelijke contracten en formaten
Wanneer het model deel uitmaakt van je applicatielogica, stoppen prompts met louter "copy" te zijn en worden uitvoerbare specificaties. Behandel ze als productvereisten: expliciete scope, voorspelbare outputs en wijzigingsbeheer.
Begin met een system prompt die het contract definieert
Je system prompt moet de rol van het model vaststellen, wat het wel en niet mag doen, en de veiligheidsregels die voor jouw product relevant zijn. Houd het stabiel en herbruikbaar.
Neem op:
- Rol en doel: wie het is (bijv. "support triage assistant") en wat succes betekent.
- Scope grenzen: welke verzoeken het moet weigeren of escaleren.
- Veiligheidsregels: PII-hantering, medische/juridische disclaimers, geen giswerk.
- Toolbeleid: wanneer tools aan te roepen vs. direct antwoorden.
Structureer prompts met duidelijke inputs/outputs
Schrijf prompts als API-definities: lijst de exacte inputs die je levert (gebruikertekst, accounttier, locale, beleidsfragmenten) en de exacte outputs die je verwacht. Voeg 1–3 voorbeelden toe die lijken op echt verkeer, inclusief lastige randgevallen.
Een nuttig patroon is: Context → Taak → Beperkingen → Outputformaat → Voorbeelden.
Gebruik begrensde formaten voor machineleesbare resultaten
Als code op de output moet handelen, vertrouw dan niet op proza. Vraag om JSON dat bij een schema past en wijs alles anders af.
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
Versieer prompts en rol veilig uit
Sla prompts op in versiebeheer, tag releases en rol ze uit zoals features: gefaseerde deployment, A/B waar passend, en snelle rollback. Log de promptversie met elke response voor debugging.
Bouw een prompt-test suite
Maak een kleine, representatieve set cases (happy path, ambigue verzoeken, beleidsinbreuken, lange inputs, verschillende locales). Voer ze automatisch uit bij elke promptwijziging en laat de build falen als outputs het contract breken.
Tool Calling: laat het model beslissen, laat code uitvoeren
Design with Planning Mode
Map decisions, tools, and boundaries before you generate any code.
Tool calling is de schoonste manier om verantwoordelijkheden te splitsen: het model beslist wat er moet gebeuren en welke capaciteit te gebruiken, terwijl je applicatiecode de actie uitvoert en geverifieerde resultaten teruggeeft.
Dit houdt feiten, berekeningen en bijwerkingen (tickets aanmaken, records updaten, e-mails sturen) in deterministische, controleerbare code—in plaats van op vrije tekst te vertrouwen.
Ontwerp een kleine, bewuste toolset
Begin met een handvol tools die 80% van de verzoeken dekken en makkelijk te beveiligen zijn:
- Search (je docs/helpcenter) om productvragen te beantwoorden
- DB lookup (eerst read-only) voor gebruikers-/account-/orderstatus
- Calculator voor prijzen, totalen, conversies en regelgebaseerde rekensommen
- Ticketing om supportverzoeken te openen wanneer de gebruiker follow-up door een mens nodig heeft
Houd het doel van elke tool smal. Een tool die "alles" doet wordt moeilijk te testen en makkelijk verkeerd te gebruiken.
Valideer inputs, sanitize outputs
Behandel het model als een onbetrouwbare aanroeper.
- Valideer toolinputs met strikte schema's (typen, bereiken, enums). Wees streng bij ontbrekende IDs of te brede queries.
- Sanitize tooloutputs voordat je ze teruggeeft aan het model: verwijder geheimen, normaliseer formaten en geef alleen de velden terug die het model nodig heeft.
Dit verkleint prompt-injectie risico via opgehaalde tekst en beperkt onbedoelde datalekken.
Voeg permissies en rate limits per tool toe
Elke tool zou moeten handhaven:
- Permissies: wie welke records of acties mag benaderen
- Rate limits: per gebruiker/sessie/tool om misbruik en runaway loops te beperken
Als een tool toestand kan wijzigen (ticketing, refunds), vraag dan om sterkere autorisatie en schrijf een auditlog.
Ondersteun altijd een "geen-tool" pad
Soms is geen actie het beste: antwoord vanuit bestaande context, stel een verduidelijkingsvraag of leg beperkingen uit.
Maak "geen tool" tot een volwaardige uitkomst zodat het model niet tools aanroept om alleen maar bezig te lijken.
Data en RAG: maak het model geworteld in jouw realiteit
Als de antwoorden van je product moeten overeenkomen met je beleid, voorraad, contracten of interne kennis, heb je een manier nodig om het model te funderen in jouw data—niet alleen in zijn algemene training.
RAG versus fine-tuning versus simpele context
- Simpele context (een paar paragrafen in de prompt plakken) werkt wanneer kennis klein, stabiel is en je het elke keer kunt meesturen (bijv. een korte prijzentabel).
- RAG (Retrieval-Augmented Generation) is het beste als informatie groot, vaak veranderend of citation-gevoelig is (bijv. helpcenter-artikelen, productdocs, account-specifieke data).
- Fine-tuning is goed wanneer je consistente stijl/format of domeinspecifieke patronen wilt—niet als primaire manier om feiten op te slaan. Gebruik het om schrijfstijl en regels te verbeteren; combineer het met RAG voor actuele waarheid.
Ingestie basics: chunking, metadata, freshness
RAG-kwaliteit is grotendeels een ingestieprobleem.
Chunk documenten in stukken passend bij je model (vaak een paar honderd tokens), bij voorkeur aligned met natuurlijke grenzen (koppen, FAQ-items). Sla metadata op zoals: documenttitel, sectiekop, product/version, doelgroep, locale en permissies.
Plan voor versheid: schema voor re-indexering, 'last updated' bijhouden en oude chunks laten verlopen. Een verouderde chunk die hoog rankt degradeert de hele feature.
Citaten en gekalibreerde antwoorden
Laat het model bronnen citeren door te retourneren: (1) antwoord, (2) een lijst met snippet-IDs/tekstbronnen, en (3) een confidentieverklaring.
Als retrieval zwak is, instrueer het model te melden wat het niet kan bevestigen en bied vervolgstappen aan ("Ik kon dat beleid niet vinden; hier is wie je kunt contacteren"). Voorkom dat het gaten invult.
Private data: toegangscontrole en redactie
Handhaaf toegang voordat je ophaalt (filter op gebruiker/org-permissies) en opnieuw voor generatie (redigeer gevoelige velden).
Beschouw embeddings en indexen als gevoelige dataopslag met auditlogs.
Wanneer retrieval faalt: elegante fallbacks
Als topresultaten irrelevant of leeg zijn, val terug op: een verduidelijkingsvraag, routeren naar menselijke support, of overschakelen naar een niet-RAG-modus die beperkingen uitlegt in plaats van te gokken.
Betrouwbaarheid: vangrail, validatie en caching
Wanneer een model deel uitmaakt van je app-logica, is "meestal goed" niet genoeg. Betrouwbaarheid betekent dat gebruikers consistent gedrag zien, je systeem veilig outputs kan consumeren en storingen gracieus degraderen.
Definieer betrouwbaarheidsdoelen (voordat je fixes toevoegt)
Schrijf op wat "betrouwbaar" betekent voor de feature:
- Consistente outputs: vergelijkbare inputs moeten vergelijkbare antwoorden produceren (toon, detailniveau, beperkingen).
- Stabiele formaten: de response moet elke keer parseerbaar zijn (JSON, lijst, specifieke velden).
- Beperkt gedrag: duidelijke grenzen aan wat het model mag doen (geen giswerk, bronnen citeren, vragen bij onzekerheid).
Deze doelen worden acceptatiecriteria voor prompts en code.
Guardrails: valideer, filter en handhaaf beleid
Behandel modeloutput als onbetrouwbare input.
- Schema-validatie: verplicht een strikt format (bijv. JSON met vereiste keys) en wijs alles af dat niet parseert.
- Contentfilters: voer scheldwoordenchecks, PII-detectie of beleidsvalidators uit op zowel gebruikersinput als modeloutput.
- Businessregels: handhaaf beperkingen in code (prijslimieten, geschiktheidsregels, toegestane acties), zelfs als de prompt ze noemt.
Als validatie faalt, geef een veilige fallback (stel een vraag, schakel naar een eenvoudiger template of routeer naar een mens).
Retries die echt helpen
Vermijd blinde herhalingen. Retry met een gewijzigde prompt die het faalmechanisme adresseert:
- "Return valid JSON only. No markdown."
- "If unsure, set
confidenceto low and ask one question."
Beperk retries en log de reden van elke mislukking.
Deterministische naverwerking
Gebruik code om te normaliseren wat het model produceert:
- canonicaliseer eenheden, datums en namen
- verwijder duplicaten
- pas rangschikkingsregels of drempels toe
Dit vermindert variantie en maakt outputs makkelijker te testen.
Caching zonder privacyproblemen te creëren
Cache herhaalbare resultaten (identieke queries, gedeelde embeddings, toolresponses) om kosten en latentie te verlagen.
Geef voorkeur aan:
- korte TTLs voor user-specifieke data
- cachekeys die ruwe PII uitsluiten (of zorgvuldig hashen)
- "do not cache"-vlaggen voor gevoelige flows
Goed toegepast verbetert caching consistentie en behoudt gebruikersvertrouwen.
Veiligheid en vertrouwen: risico's beperken zonder UX te breken
Iterate without fear
Experiment with prompts and tools, then roll back quickly when something breaks.
Veiligheid is geen aparte compliance-laag die je achteraf toevoegt. In AI-first producten kan het model acties, bewoordingen en beslissingen beïnvloeden—dus veiligheid moet deel uitmaken van je productcontract: wat de assistent mag doen, wat hij moet weigeren en wanneer hij hulp moet vragen.
Belangrijke veiligheidszorgen om voor te ontwerpen
Noem de risico's waar je app echt aan blootstaat en koppel voor elk risico een controle:
- Gevoelige data: persoonsidentificatie, credentials, private documenten en alles wat gereguleerd is.
- Schadelijke instructies: instructies die zelfbeschadiging, geweld, illegale activiteiten of onveilige medische/financiële handelingen mogelijk maken.
- Bias en oneerlijke uitkomsten: inconsistente kwaliteit van service, aanbevelingen of beslissingen tussen groepen.
Toegestane/geblokkeerde onderwerpen + escalatiepaden
Schrijf een expliciet beleid dat je product kan afdwingen. Wees concreet: categorieën, voorbeelden en verwachte reacties.
Gebruik drie niveaus:
- Toegestaan: normaal beantwoorden.
- Beperkt: beantwoorden met randvoorwaarden (bijv. alleen algemene info, geen stapsgewijze instructies).
- Geblokkeerd: weigeren en routeren naar een escalatiepad (support, hulpbronnen of een menselijke agent).
Escalatie moet een productflow zijn, geen enkele weigeringstekst. Bied een "Praat met een persoon"-optie en zorg dat de overdracht context bevat die de gebruiker al heeft gedeeld (met toestemming).
Menselijke beoordeling voor acties met grote impact
Als het model echte gevolgen kan veroorzaken—betalingen, refunds, accountwijzigingen, annuleringen, dataverwijdering—voeg dan een checkpoint toe.
Goede patronen: bevestigingsschermen, "concept dan goedkeuren", limieten (bedragen), en een menselijke review-queue voor randgevallen.
Openbaarmakingen, toestemming en testbaar beleid
Vertel gebruikers dat ze met AI praten, welke data wordt gebruikt en wat wordt opgeslagen. Vraag toestemming waar nodig, vooral voor het opslaan van gesprekken of het gebruiken van data om het systeem te verbeteren.
Behandel interne veiligheidsbeleid als code: versieer ze, documenteer de rationale en voeg tests toe (voorbeeldprompts + verwachte uitkomsten) zodat veiligheid niet terugvalt bij elke prompt- of modelupdate.
Evaluatie: test het model als elk ander kritiek component
Als een LLM kan veranderen wat je product doet, heb je een herhaalbare manier nodig om te bewijzen dat het nog steeds werkt—voordat gebruikers regressies ontdekken.
Behandel prompts, modelversies, toolschema's en retrieval-instellingen als release-waardige artefacten die testen vereisen.
Bouw een evaluatieset uit de praktijk
Verzamel echte gebruikersintenties uit supporttickets, zoekopdrachten, chatlogs (met toestemming) en salesgesprekken. Zet ze om in testcases die bevatten:
- Veelvoorkomende happy-path verzoeken
- Ambigue prompts die verduidelijking vereisen
- Randgevallen (ontbrekende data, conflicterende beperkingen, ongebruikelijke formaten)
- Beleidsgevoelige scenario's (persoonlijke data, niet-toegestane content)
Elke case moet verwacht gedrag bevatten: het antwoord, de genomen beslissing (bijv. "roep tool A aan") en elke vereiste structuur (JSON-velden aanwezig, citaten opgenomen, etc.).
Kies metrics die bij productrisico passen
Eén score vangt niet de kwaliteit. Gebruik een kleine set metrics die aan gebruikersuitkomsten zijn gekoppeld:
- Nauwkeurigheid / taak-succes: lost het de gebruiker zijn doel op?
- Gebaseerdheid: worden beweringen ondersteund door context of bronnen?
- Formaatvaliditeit: voldoet output aan het contract (JSON, tabel, bullets)?
- Weigeringspercentage: weigert het wanneer het zou moeten—en vermijdt het onterechte weigeringen?
Houd kosten en latentie naast kwaliteit bij; een "beter" model dat reactietijd verdubbelt kan conversie schaden.
Voer offline evaluaties bij elke wijziging uit
Draai offline evaluaties vóór release en na elke prompt-, model-, tool- of retrievalwijziging. Versieer resultaten zodat je runs kunt vergelijken en snel kunt achterhalen wat stuk ging.
Voeg online tests toe met vangrails
Gebruik A/B-tests om echte uitkomsten te meten (voltooiingspercentage, bewerkingen, gebruikerswaarderingen), maar voeg veiligheidsrails toe: definieer stopcondities (bijv. pieken in invalide outputs, weigeringen of toolfouten) en rol automatisch terug wanneer drempels overschreden worden.
Monitoring in productie: drift, fouten en feedback
Ship the full app stack
Create a React web app plus a Go and PostgreSQL backend from a single conversation.
Een AI-first feature live zetten is nog geen finish. Zodra echte gebruikers komen, komt het model onbekende formuleringen, randgevallen en veranderende data tegen. Monitoring verandert "het werkte in staging" in "het blijft werken volgende maand."
Log wat belangrijk is (zonder geheimen te verzamelen)
Leg genoeg context vast om fouten te reproduceren: gebruikersintentie, promptversie, toolcalls en de uiteindelijke output.
Log inputs/outputs met privacy-veilige redactie. Behandel logs als gevoelige data: strip e-mails, telefoonnummers, tokens en vrije tekst die persoonlijke details kan bevatten. Houd een "debug mode" die je tijdelijk voor specifieke sessies kunt inschakelen in plaats van standaard maximale logging.
Houd de juiste signalen in de gaten
Monitor foutpercentages, toolfouten, schema-violaties en drift. Concreet, volg:
- Tool-call succesratio en timeouts (keek het model de juiste tool en slaagde de uitvoering?)
- Outputformat/schema-compliance (wezen validators het af?)
- Fallback-gebruik (hoe vaak moest je naar een veiligere of eenvoudigere route?)
- Contentveiligheidsblokken (hoe vaak weigerde of redigeerde je?)
Voor drift vergelijk je huidig verkeer met je baseline: veranderingen in onderwerpmix, taal, gemiddelde promptlengte en "onbekende" intenties. Drift is niet altijd slecht—maar het is een signaal om te her-evalueren.
Alerts, runbooks en incidentrespons
Stel alertdrempels en on-call runbooks in. Alerts moeten gekoppeld zijn aan acties: rol een promptversie terug, disable een onbetrouwbare tool, verscherp validatie of schakel naar fallback.
Plan incidentrespons voor onveilig of incorrect gedrag. Definieer wie veiligheidschakelaars kan omzetten, hoe gebruikers geïnformeerd worden en hoe je het incident documenteert en eruit leert.
Sluit de lus met gebruikersfeedback
Gebruik feedbackloops: duimpjes omhoog/omlaag, redencodes, bug reports. Vraag naar een korte "waarom?" (verkeerde feiten, volgde niet de instructies, onveilig, te langzaam) zodat je issues naar de juiste oplossing kunt leiden—prompt, tools, data of beleid.
UX voor modelgedreven logica: transparantie en controle
Modelgedreven features voelen magisch als ze werken—en breekbaar als ze dat niet doen. UX moet onzekerheid aannemen en gebruikers toch helpen het doel te bereiken.
Toon het "waarom" zonder te overbelasten
Gebruikers vertrouwen AI-uitkomsten meer wanneer ze kunnen zien waar het vandaan komt—niet omdat ze een les willen, maar omdat het helpt beslissen of ze moeten handelen.
Gebruik progressieve onthulling:
- Begin met de uitkomst (antwoord, concept, aanbeveling).
- Bied een "Waarom?" of "Toon werk"-toggle die belangrijke inputs onthult: het gebruikersverzoek, gebruikte tools en geraadpleegde bronnen of records.
- Als je retrieval gebruikt, toon citaten die naar het exacte fragment verwijzen (bijv. "Gebaseerd op: Policy §3.2"). Houd het scanbaar.
Als je diepere uitleg hebt, link intern (bijv. /blog/rag-grounding) in plaats van de UI vol te proppen.
Ontwerp voor onzekerheid (zonder enge waarschuwingen)
Een model is geen rekenmachine. De interface moet vertrouwen en verificatie communiceren.
Praktische patronen:
- Vertrouwensindicatoren in gewone taal ("Waarschijnlijk correct", "Moet worden nagekeken") in plaats van valse precisie.
- Opties, geen enkele antwoorden: "Hier zijn 3 manieren om te reageren." Dit verlaagt de kosten van een verkeerde eerste gok.
- Bevestigingen voor acties met grote impact (e-mails versturen, data verwijderen, betalingen). Vraag één duidelijke vraag: "Deze boodschap naar 12 ontvangers sturen?"
Maak corrigeren en herstellen moeiteloos
Gebruikers moeten de output kunnen bijsturen zonder opnieuw te beginnen:
- Inline bewerken met "Wijzigingen toepassen" zodat het model verder werkt vanaf de correcties.
- "Regenerate" met bedieningsopties (toon, lengte, beperkingen) in plaats van een blinde herkansing.
- "Undo" en een zichtbare geschiedenis zodat fouten herstelbaar zijn.
Bied een escape hatch
Als het model faalt—of de gebruiker twijfelt—bied een deterministische flow of menselijke hulp.
Voorbeelden: "Overschakelen naar handmatig formulier", "Gebruik template" of "Contact support" (bijv. /support). Dit is geen fallback van schaamte; het beschermt taakvoltooiing en vertrouwen.
Van prototype naar productie (zonder alles opnieuw te bouwen)
De meeste teams falen niet omdat LLMs incapabel zijn; ze falen omdat het pad van prototype naar een betrouwbaar, testbaar en monitorbaar feature langer is dan verwacht.
Een praktische manier om dat pad te verkorten is door vroeg de "product skeleton" te standaardiseren: toestandsmachines, toolschema's, validatie, traces en een deploy/rollback verhaal. Platforms zoals Koder.ai kunnen nuttig zijn wanneer je snel een AI-first workflow wilt opzetten—UI, backend en database samen bouwen—en vervolgens veilig itereren met snapshots/rollback, custom domains en hosting. Zodra je klaar bent om te operationaliseren, kun je de broncode exporteren en verdergaan met je gekozen CI/CD en observability-stack.