15 jun 2025·8 min
AI die backend‑schemas, API's en datamodellen ontwerpt
Ontdek hoe door AI gegenereerde schema's en API's de levering versnellen, waar ze tekortschieten en een praktische workflow om backendontwerp te beoordelen, testen en beheren.
Ontdek hoe door AI gegenereerde schema's en API's de levering versnellen, waar ze tekortschieten en een praktische workflow om backendontwerp te beoordelen, testen en beheren.
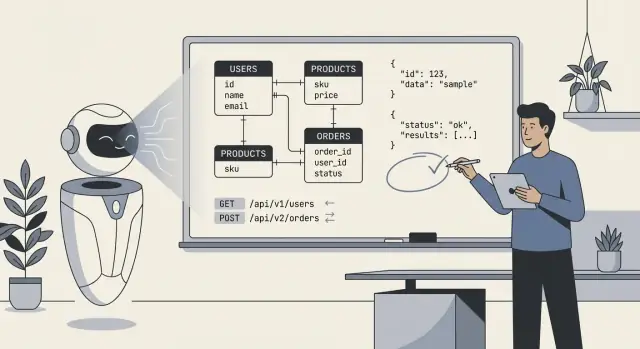
Als mensen zeggen “AI ontwierp onze backend”, bedoelen ze meestal dat het model een eerste schets produceerde van het technische fundament: databasetabellen (of collecties), hoe die onderdelen met elkaar verbonden zijn en de API's die data lezen en schrijven. In de praktijk is het minder “AI heeft alles gebouwd” en meer “AI stelde een structuur voor die we kunnen implementeren en verfijnen.”
Minimaal kan AI genereren:
users, orders, subscriptions, plus velden en basistypen.AI kan “typische” patronen afleiden, maar kan niet betrouwbaar het juiste model kiezen als vereisten vaag of domeinspecifiek zijn. Het weet niet jouw werkelijke beleidsregels voor:
cancelled vs refunded vs voided).Behandel AI‑output als een snel, gestructureerd startpunt—nuttig om opties te verkennen en weglatingen te vinden—maar niet als een specificatie die je ongewijzigd kunt uitrollen. Jouw taak is om heldere regels en randgevallen aan te leveren en daarna te reviewen wat de AI produceerde, precies zoals je het eerste ontwerp van een junior‑engineer zou beoordelen: behulpzaam, soms indrukwekkend, soms subtiel fout.
AI kan snel een schema of API schetsen, maar kan de ontbrekende feiten niet verzinnen die een backend passend maken voor je product. De beste resultaten ontstaan wanneer je AI behandelt als een snelle junior‑ontwerper: jij levert duidelijke randvoorwaarden, zij stelt opties voor.
Voordat je om tabellen, endpoints of modellen vraagt, noteer het volgende:
Als vereisten onduidelijk zijn, neigt AI te gokken: overal optionele velden, generieke statuskolommen, onduidelijke eigendom en inconsistente naamgeving. Dat leidt vaak tot schema's die logisch lijken maar falen onder echt gebruik—vooral rond permissies, rapportage en randgevallen (refunds, annuleringen, gedeeltelijke verzendingen, meerstapsgoedkeuringen). Je betaalt daar later voor met migraties, workarounds en verwarrende API's.
Gebruik dit als startpunt en plak het in je prompt:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
AI is het meest effectief wanneer je het gebruikt als een snelle draft‑machine: het kan in enkele minuten een eerste datamodel en bijpassende endpoints schetsen. Die snelheid verandert hoe je werkt — niet omdat de output magisch “correct” is, maar omdat je meteen iets concreets hebt om op te itereren.
De grootste winst is het wegnemen van de koude start. Geef AI een korte omschrijving van entiteiten, kernuserflows en constraints, en het kan tabellen/collecties, relaties en een basis API‑oppervlak voorstellen. Dit is vooral waardevol voor demo's of wanneer vereisten nog onstabiel zijn.
Snelheid betaalt zich het meest uit bij:
Mensen zijn vermoeid en verliezen consistentie. AI niet — dus het is handig om conventies uniform toe te passen in de hele backend:
createdAt, updatedAt, customerId)/resources, /resources/:id) en payloadsDie consistentie maakt je backend makkelijker te documenteren, testen en overdragen.
AI is ook goed in volledigheid. Vraag om een volledige CRUD‑set plus veelvoorkomende operaties (search, list, bulk updates) en het genereert vaak een meer uitgebreide startoppervlakte dan een gehaaste menselijke schets.
Een simpele winst is gestandaardiseerde errors: één uniforme foutvelop (code, message, details) over alle endpoints. Zelfs als je het later verfijnt, voorkomt één vorm vanaf het begin een wirwar van ad‑hoc responses.
De mindset: laat AI de eerste 80% snel produceren, besteed je tijd aan de laatste 20% die oordeel vereist — bedrijfsregels, randgevallen en het “waarom” achter het model.
AI‑gegenereerde schema's zien er vaak “schoon” uit: nette tabellen, redelijke namen en relaties die het happy path volgen. Problemen ontstaan meestal wanneer echte data, echte gebruikers en echte workflows het systeem belasten.
AI kan alle kanten op:
Een snelle test: als je meestgebruikte pagina’s 6+ joins nodig hebben, ben je mogelijk over‑genormaliseerd; als updates veel rijen tegelijk moeten aanpassen, ben je mogelijk onder‑genormaliseerd.
AI laat vaak “saaie” vereisten weg die het backendontwerp sturen:
tenant_id op tabellen of tenant‑scoping niet afdwingen in unieke constraints.deleted_at toevoegen maar unieke regels of querypatronen niet aanpassen.created_by/updated_by, wijzigingshistorie of ongewijzigde eventlogs.AI kan gokken dat:
invoice_number),Dergelijke fouten leiden vaak tot onhandige migraties en application‑side workarounds.
De meeste gegenereerde schema's reflecteren niet hóe je gaat queryen:
Als het model de top 5 queries van je app niet kan beschrijven, kan het het schema daar niet betrouwbaar op afstemmen.
AI maakt vaak verrassend standaard‑uitziende API's. Het kopieert patronen uit populaire frameworks en publieke API's, wat tijd kan besparen. Het risico is dat het optimaliseert voor wat plausibel lijkt in plaats van wat correct is voor jouw product, datamodel en toekomstige veranderingen.
Resourcemodellering basics. Met een helder domein kiest AI meestal logische zelfstandige naamwoorden en URL‑structuren (bijv. /customers, /orders/{id}, /orders/{id}/items). Het is ook goed in het consequent toepassen van naamgevingsregels over endpoints.
Common endpoint scaffolding. AI voegt vaak de essentials toe: list vs detail endpoints, create/update/delete, en voorspelbare request/response‑vormen.
Baseline conventies. Als je er expliciet om vraagt, standaardiseert het paginering, filtering en sortering (bijv. ?limit=50&cursor=... voor cursorpaginering of ?page=2&pageSize=25 voor page‑based), plus ?sort=-createdAt en filters als ?status=active.
Leaky abstractions. Een klassiek probleem is het direct exposen van interne tabellen als “resources”, vooral bij join‑tabellen, gededupliceerde velden of auditkolommen. Je krijgt dan endpoints als /user_role_assignments die implementatiedetails tonen in plaats van een gebruiksvriendelijke interface (“rollen voor een gebruiker”). Dat maakt de API lastiger onderhoudbaar.
Inconsistente foutafhandeling. AI kan stijlen mixen: soms 200 met een foutbody, soms juiste 4xx/5xx. Je wilt een helder contract:
400, 401, 403, 404, 409, 422){ "error": { "code": "...", "message": "...", "details": [...] } })Versionering als bijzaak. Veel designs van AI vergeten een versioneringsstrategie totdat het pijnlijk wordt. Bepaal vanaf dag één of je pad‑versioning (/v1/...) of header‑gebaseerde versie gebruikt en wat een breaking change veroorzaakt.
Gebruik AI voor snelheid en consistentie, maar behandel API‑ontwerp als een productinterface. Als een endpoint je database weerspiegelt in plaats van het mentale model van je gebruiker, heeft de AI geoptimaliseerd voor makkelijke generatie in plaats van lange‑term bruikbaarheid.
Behandel AI als een snelle junior‑ontwerper: goed in drafts, niet aansprakelijk voor het eindresultaat. Het doel is snelheid te benutten terwijl je architectuur intentioneel, reviewbaar en testgedreven blijft.
Als je een vibe‑coding tool gebruikt zoals Koder.ai, wordt deze taakverdeling extra belangrijk: het platform kan snel een backend schetsen en implementeren (bijv. Go‑services met PostgreSQL), maar je moet nog steeds invarianten, autorisatiegrenzen en migratieregels definiëren waar je mee kunt leven.
Begin met een strakke prompt die het domein, constraints en “wat succes is” beschrijft. Vraag eerst om een conceptueel model (entiteiten, relaties, invarianten), geen tabellen.
Itereer dan in vaste stappen:
Deze lus werkt omdat je AI‑voorstellen omzet in bewijsbare artefacten die je kunt accepteren of verwerpen.
Houd drie lagen apart:
Vraag AI deze als aparte secties op te leveren. Als iets verandert (bijv. een nieuwe status), werk je eerst de conceptuele laag bij en reconcile je daarna schema en API. Dat vermindert onbedoelde koppeling en maakt refactors minder pijnlijk.
Elke iteratie moet een spoor achterlaten. Gebruik korte ADR‑achtige samenvattingen (één pagina of minder) met:
deleted_at”).Plak relevante beslissingsnotities letterlijk terug in de AI‑prompt zodat het model eerdere keuzes niet “vergeet” en je team later begrijpt waarom iets zo ontworpen is.
AI is het makkelijkst te sturen als je prompting als specificatie‑schrijven behandelt: definieer het domein, geef constraints en eis concrete outputs (DDL, endpointtabellen, voorbeelden). Het doel is niet “creatief zijn” maar “precies zijn.”
Vraag om een datamodel en regels die het consistent houden.
Als je al conventies hebt, vermeld ze: naamgevingsstijl, ID‑type (UUID vs bigint), nullable‑beleid en indexeerverwachtingen.
Vraag om een API‑tabel met expliciete contracten, niet alleen een lijst routes.
Voeg bedrijfsgedrag toe: pagineringstijl, sorteerbare velden en hoe filtering werkt.
Laat het model in releases denken.
billing_address to Customer. Provide a safe migration plan: forward migration SQL, backfill steps, feature-flag rollout, and a rollback strategy. API must remain compatible for 30 days; old clients may omit the field.”Vage prompts geven vage systemen:
Als je betere output wilt, verscherp de prompt: specificeer regels, randgevallen en het format van het deliverable.
AI kan een redelijke backend schetsen, maar daadwerkelijk uitrollen vereist nog altijd een menselijke controle. Gebruik deze checklist als release‑gate: als je een item niet zeker kunt beantwoorden, pauzeer en herstel het voordat het productiedata raakt.
(tenant_id, slug))._id suffixen, timestamps) en pas ze uniform toe.Leg systeemregels schriftelijk vast:
Voer voordat je merge een korte “happy path + worst path” review uit: één normale request, één ongeldige request, één ongeautoriseerde request en één scenario met hoge load. Als de API‑gedragingen je verrassen, zal het je gebruikers ook verrassen.
AI kan snel een plausibel schema en API‑oppervlak genereren, maar het kan niet bewijzen dat de backend correct werkt onder echte traffic, echte data en toekomstige veranderingen. Behandel AI‑output als draft en veranker het met tests die gedrag vastleggen.
Begin met contracttests die requests, responses en foutsemantiek valideren — niet alleen happy paths. Bouw een kleine suite die draait tegen een echte instantie (of container) van de service.
Focus op:
Als je een OpenAPI‑spec publiceert, genereer tests ervan — maar voeg ook handgeschreven gevallen toe voor lastige delen die specs niet goed kunnen uitdrukken (autorisatieregels, bedrijfsconstraints).
AI‑schema's missen vaak operationele details: veilige defaults, backfills en omkeerbaarheid. Voeg migratietests toe die:
Houd een gescripte rollback‑handleiding voor productie: wat te doen als een migratie langzaam is, tabellen lockt of compatibiliteit breekt.
Benchmark geen generieke endpoints. Capture representatieve querypatronen (top list views, search, joins, aggregaties) en load test die.
Meet:
Hier falen AI‑designs vaak: “redelijke” tabellen die onder load dure joins produceren.
Voeg geautomatiseerde checks toe voor:
Zelfs basisbeveiligingstests voorkomen de meest kostbare AI‑fouten: werkende endpoints die te veel blootstellen.
AI kan een goed “versie 0” schema schetsen, maar je backend leeft door versie 50. Het verschil tussen een backend die goed veroudert en één die instort is hoe je het evolueert: migraties, gecontroleerde refactors en heldere documentatie van intentie.
Behandel elke schema‑wijziging als een migratie, zelfs als AI “gewoon de tabel aanpast” voorstelt. Gebruik expliciete, omkeerbare stappen: voeg nieuwe kolommen toe, backfill, en verscherp daarna constraints. Geef de voorkeur aan additionele wijzigingen boven destructieve totdat je bewezen hebt dat niets van het oude afhangt.
Als je AI om schema‑updates vraagt, geef het huidige schema en de migratieregels die je volgt (bijv. “geen kolommen droppen; gebruik expand/contract”). Dat verkleint de kans op theoretisch correcte maar productierisicovolle voorstellen.
Brekende veranderingen zijn zelden één moment; het is een transitie.
AI kan stap‑voor‑stap plannen maken (inclusief SQL‑snippets en rollout‑volgorde), maar je moet runtime‑impact valideren: locks, langdurige transacties en of backfills hervat kunnen worden.
Refactors moeten gericht zijn op isolatie. Bij normalisatie, tabelopsplitsing of introductie van een eventlog: behoud compatibiliteitslagen: views, translatielaag of “shadow” tabellen. Vraag AI om een refactor voor te stellen die bestaande API‑contracten behoudt en vermeld wat moet veranderen in queries, indexen en constraints.
Drift ontstaat omdat volgende prompts de oorspronkelijke intentie vergeten. Houd een korte “data model contract” bij: naamgevingsregels, ID‑strategie, timestamp‑semantiek, soft‑delete beleid en invarianten (“een order total is afgeleid, niet opgeslagen”). Hergebruik dit in toekomstige AI‑prompts zodat ontwerpen binnen dezelfde grenzen blijven.
AI kan snel tabellen en endpoints schetsen, maar het “eigent” je risico niet. Behandel security en privacy als primaire vereisten in je prompt en verifieer ze in review — vooral rond gevoelige data.
Label velden op gevoeligheid (public, internal, confidential, regulated). Die classificatie stuurt wat encrypted, gemaskeerd of geminimaliseerd wordt.
Bijv.: passwords nooit opslaan (alleen salted hashes), tokens kortlevend en encrypted at rest, PII als email/telefoon maskeren in admin views en exports. Als een veld niet nodig is voor productwaarde, sla het dan niet op — AI voegt vaak “nice to have” attributen toe die risico verhogen.
AI‑gegenereerde APIs kiezen vaak voor simpele “rolchecks”. RBAC is makkelijk te redeneren maar faalt bij eigendomregels (“users mogen alleen hun eigen invoices zien”) of contextregels (“support ziet data alleen bij een actief ticket”). ABAC kan dit beter, maar vereist expliciete policies.
Wees duidelijk over het patroon en zorg dat elk endpoint het consequent afdwingt — vooral list/search endpoints, die vaak lekken.
Gegenereerde code kan hele request bodies, headers of database‑rijen loggen bij fouten. Dat kan wachtwoorden, auth‑tokens en PII lekken naar logs en APM. Stel defaults in zoals: gestructureerde logs, allowlist van velden die gelogd mogen worden, redacteer secrets (Authorization, cookies, reset tokens) en vermijd raw payload logs op validatiefouten.
Ontwerp vanaf dag één voor verwijdering: gebruikersverzoeken, accountsluiting en “recht om vergeten te worden”. Definieer retentiewindows per dataklasse (bv. audit events vs marketing events) en zorg dat je kunt aantonen wat wanneer verwijderd is.
Als je auditlogs bewaart, sla minimale identificatoren op, bescherm ze strenger en documenteer export‑/verwijderprocedures voor compliance‑verzoeken.
AI is het best wanneer je het als snelle junior‑architect inzet: uitstekend in een eerste draft, zwakker in domeinkritische afwegingen. De juiste vraag is niet “Kan AI mijn backend ontwerpen?” maar “Welke onderdelen kan AI veilig schetsen en welke moeten onder menselijke verantwoordelijkheid vallen?”
AI bespaart tijd bij:
Hier is AI waardevol voor snelheid, consistentie en dekking — vooral als je al weet hoe het product moet werken en fouten makkelijk herkend worden.
Wees voorzichtig (of gebruik AI alleen als inspiratie) bij:
Daar wegen domeinexpertise en nauwkeurigheid zwaarder dan AI‑snelheid. Subtiele vereisten (juridisch, klinisch, boekhoudkundig) missen vaak in de prompt en AI vult gaten zelfverzekerd in.
Een praktische regel: laat AI opties voorstellen, maar vereis een finale review voor datamodelinvarianten, autorisatiegrenzen en migratiestrategie. Als je niet kunt zeggen wie verantwoordelijk is voor schema en API‑contracten, rol dan geen door AI ontworpen backend uit.
Als je werkstromen en guardrails beoordeelt, bekijk gerelateerde gidsen in /blog. Voor hulp bij het toepassen van deze praktijken op je teamproces, zie /pricing.
Als je de voorkeur geeft aan een end‑to‑end workflow waarin je via chat kunt itereren, een werkende app genereert en toch controle behoudt via broncode‑export en rollback‑vriendelijke snapshots, is Koder.ai ontworpen voor precies die build‑and‑review loop.
Het betekent meestal dat het model een eerste versie genereerde van:
Een menselijk team moet nog steeds bedrijfsregels, beveiligingsgrenzen, queryprestaties en migratieveiligheid valideren voordat je het uitrolt.
Geef concrete inputs die AI niet veilig kan raden:
Hoe duidelijker de randvoorwaarden, hoe minder de AI gaten vult met kwetsbare aannames.
Begin met een conceptueel model (businessconcepten + invarianten) en leid daaruit af:
Deze lagen gescheiden houden maakt het makkelijker om opslag te veranderen zonder de API te breken — of de API te herzien zonder per ongeluk businessregels te beschadigen.
Veelvoorkomende problemen zijn:
tenant_id en samengestelde unieke constraints)deleted_at)Vraag AI om te ontwerpen rond je topqueries en verifieer daarna:
tenant_id + created_at)Als je de top 5 queries/endpoints niet kunt noemen, beschouw elk indexplan als onvolledig.
AI is goed in standaard scaffolding, maar let op:
200 met een foutbody, inconsistente 4xx/5xx)Behandel de API als een productinterface: maak endpoints rondom gebruikersconcepten, niet de databaselaag.
Gebruik een herhaalbare lus:
Gebruik consistente HTTP‑codes en een enkel fout‑envelop, bijvoorbeeld:
Prioriteer tests die gedrag vastleggen:
Tests zijn hoe je het ontwerp in eigendom neemt in plaats van de aannames van de AI te erven.
AI is prima voor drafts als patronen duidelijk zijn (CRUD‑MVPs, interne tools). Wees voorzichtig wanneer:
Een goed beleid: AI mag opties voorstellen, maar mensen moeten tekenen voor schema‑invarianten, autorisatie en rollout/migratiestrategie.
Een schema kan er “netjes” uitzien en toch falen onder echte workflows en load.
Zo verander je AI‑output in artefacten die je kunt bewijzen of verwerpen in plaats van te vertrouwen op tekst.
400, 401, 403, 404, 409, 422, 429{"error":{"code":"...","message":"...","details":[...]}}
Zorg er ook voor dat foutmeldingen geen interne details lekken (SQL, stacktraces, geheimen) en dat de vorm overal hetzelfde is.