28 aug 2025·8 min
Autocomplete en typfouttolerantie voor Indiase e‑commerce zoekfunctie
Leer hoe je autocomplete en typfouttolerantie voor Indiase e‑commerce zoekfuncties verbetert met synoniemen, lokale termen, transliteraties en analytics om resultaten te verbeteren.
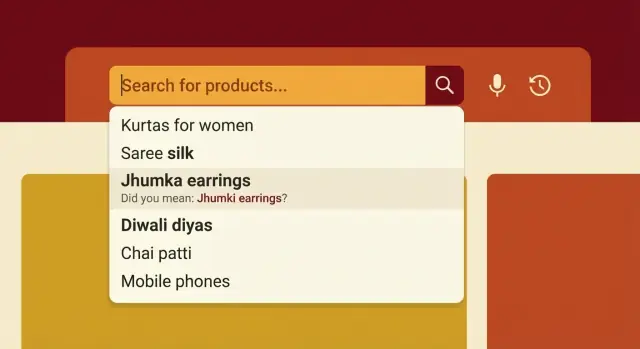
Waarom Indiase productnamen zoekopdrachten breken
Indiase e‑commerce zoekfuncties falen om één simpele reden: mensen noemen hetzelfde product niet op dezelfde manier. Een product kan in het Engels, Hindi, Tamil of een mix ervan worden getypt, en elke regio heeft zijn eigen gangbare woorden.
Een shopper zoekt misschien naar “atta”, “aata”, “gehu ka atta” of alleen de merknaam. Een ander typt “jeera”, “zeera” of simpelweg “cumin”. Als je catalogus maar één van die vormen bevat, kan een heel normale zoekopdracht niets opleveren.
Kleine spelfouten doen meer pijn dan je verwacht, omdat zoekmachines vaak exact op tekst zoeken. Een ontbrekende klinker, een extra spatie of een andere woordvolgorde kan het juiste product uit de topresultaten duwen of zelfs leiden tot zero results.
Veelvoorkomende oorzaken dat Indiase productnamen in veel varianten voorkomen:
- Meerdere schriften en transliteraties (Hindi in Latijnse letters, lokale spellingen)
- Regionale termen voor hetzelfde artikel (voedsel, kleding, huishoudelijke producten)
- Merk-voorop versus generiek-voorop naamgeving (“Surf Excel 1kg” vs “detergent powder”)
- Afkortingen en gesproken vormen (“kurti” vs “kurta top”, “1 ltr” vs “1L”)
- Toetsenbordfouten en autocorrect (“pista” wordt “pita”, “saree” vs “sarri”)
Autocomplete en typfouttolerantie veranderen wat de shopper ervaart. Autocomplete vermindert moeite door mensen te begeleiden naar de bewoording die jouw winkel begrijpt, nog voordat ze zoeken. Typfouttolerantie voorkomt dat “bijna goed” queries falen, zodat shoppers relevante items blijven zien, ook bij onperfecte spelling.
Het praktische doel van autocomplete en typfouttolerantie voor Indiase e‑commerce zoekfunctie is niet “perfecte taalondersteuning”. Het is meetbaar: minder zero-results en snellere productontdekking, zodat meer shoppers bij een productlijst uitkomen in plaats van een dood spoor.
Belangrijke ideeën in gewone taal
Goede zoekfunctie in India gaat minder over ingewikkelde algoritmes en meer over begrijpen hoe mensen daadwerkelijk productnamen typen. Veel shoppers mengen Engels met lokale woorden, spellen hetzelfde ding op drie verschillende manieren en verwachten dat zoekfunctie het toch “begrijpt”.
Autocomplete helpt voordat de zoekterm af is. Als iemand “jeer…” typt, kun je voorstellen tonen als “jeera rice”, “jeera powder” of “jeera whole”. Goed gedaan vermindert autocomplete moeite en stuurt shoppers zachtjes naar termen die in je catalogus bestaan.
Typfouttolerantie betekent dat je nog steeds matcht als de gebruiker een waarschijnlijke fout maakt, zoals “zeera” vs “jeera” of “shampo” vs “shampoo”. Het doel is veelvoorkomende fouten te repareren zonder de betekenis te veranderen. Te veel tolerantie levert rare matches op (bijvoorbeeld een korte zoekterm als “ram” die plots op totaal andere producten matcht).
Synoniemen zijn simpel: verschillende woorden, dezelfde intentie. “Atta” en “wheat flour” moeten op dezelfde set producten uitkomen. In Indiase e‑commerce bevatten synoniemen vaak merkachtige termen, regionale woorden en categorie‑bijnaammaps.
Transliteratie is wanneer mensen Indiase woorden typen met Engelse letters. Iemand typt “namkeen”, “nimeen” of “namkin” afhankelijk van gewoonte en toetsenbord. Transliterationregels helpen deze varianten te matchen, ook als je catalogus maar één spelling gebruikt.
Een praktische manier om over autocomplete en typfouttolerantie voor Indiase e‑commerce zoekfunctie te denken:
- Autocomplete leidt de gebruiker naar een geldige, populaire zoekterm.
- Typfouttolerantie redt de gebruiker wanneer ze een geldig woord verkeerd spellen.
- Synoniemen verbinden verschillende woorden met dezelfde koopintentie.
- Transliteratie verbindt verschillende spellingen met hetzelfde lokale woord.
Als dit helder is, kun je een kleine, gecontroleerde mapping maken en uitbreiden met echte zoekanalytics, in plaats van te gokken.
Bouw je Indiase naamwoordenwoordenboek (gegevens om te verzamelen)
Een goed zoekwoordenboek begint met je eigen data, niet met aannames. Het doel is simpel: vastleggen hoe mensen producten in India noemen, inclusief lokale termen, spellingen en shorthand, zodat autocomplete en typfouttolerantie iets stevigs hebben om op voort te bouwen.
Begin met je catalogus. Producttitels, categorienamen, attributen, variantenlabels, merken, verpakkingsgrootten en eenheden bevatten vaak de “officiële” bewoordingen die shoppers moeten kunnen vinden. Voor kruidenierswaren kan dit zowel generieke als specifieke termen omvatten zoals “toor dal”, “arhar dal” en “split pigeon peas” als je die gebruikt.
Verzamel vervolgens echte klanttaal. Zoeklogs tonen wat mensen typen als ze haast hebben, terwijl klantenservice-chats laten zien hoe ze iets omschrijven als ze het niet kunnen vinden. Zelfs een paar weken logs kunnen herhaalde patronen laten zien zoals “aata/atta”, “dahi/curd” of “chilli/chili”.
Bouw inputs vanuit vijf bronnen en merge en clean ze daarna:
- Catalogustekst (titels, attributen, varianten, merken, maten)
- Zoekopdrachten (inclusief zero-results queries)
- Klantenservice-chats en belnotities
- Regionale en lokale termen die je team al gebruikt
- Eenheids- en bundelshorthand (ml, ltr, pcs, combo, 1+1)
Scheids ten slotte generieke termen van merktermen. “Atta” moet veel producten matchen, terwijl een merknaam niet per ongeluk resultaten voor ongerelateerde items mag trekken. Houd twee gelabelde lijsten (generiek vs merk) zodat latere regels intent niet vervagen en rangorde niet verwarren.
Stappenplan: maak een synoniem- en transliteratieplan
Begin klein. Kies 20 tot 50 categorieën die het meeste zoekverkeer en omzet opleveren, zoals basisartikelen, beauty en populaire elektronica. Dit houdt het werk gefocust en helpt je snel impact te zien in autocomplete en typfouttolerantie.
Bouw dan één gedeelde “naamtafel” die iedereen kan bewerken (merch, content, support). Houd het eerst in een spreadsheet en sync het daarna naar je zoekindex.
1) Maak een canonieke lijst
Kies voor elke categorie de term die je wilt dat het systeem als de “hoofdnaam” beschouwt (canoniek). Gebruik wat klanten herkennen, niet wat de leverancier noemt.
Maak rijen zoals:
| Canonieke term | Synoniemen (zelfde product) | Veelvoorkomende spelfouten | Transliteraties | Notities |
|---|---|---|---|---|
| cumin | jeera | jeera, jeeraa | zeera, zira | Houd “caraway” apart |
| face wash | cleanser | fash wash | fes wash | Niet mappen naar “face cream” |
Voeg eenheden en verpakkingspatronen als aparte, herbruikbare tokens toe: 1kg, 500 g, 2x, combo pack, family pack. Deze veroorzaken vaak zero-results omdat gebruikers het hele patroon typen.
2) Stel strikte “zelfde product” regels in
Een synoniem moet betekenen dat de klant tevreden is met dezelfde resultaten. Schrijf korte regels waar je team zich aan kan houden:
- Toegestaan: regionale naamsvarianten, merkafkortingen, veelvoorkomende spellingsvarianten
- Toegestaan: Hinglish-transliteratie waar de betekenis gelijk blijft
- Niet toegestaan: aangrenzende producten (cleanser vs toner, cumin vs carom)
- Niet toegestaan: verschillende maten als synoniemen (maat is een filter)
- Niet toegestaan: “healthy” of “premium” als synoniem voor het basisartikel
3) Houd het onderhoud eenvoudig
Wijs één eigenaar per categorie aan en voeg een simpele review-cadans toe (wekelijks in het begin). Als support “kon niet vinden” klachten ziet, voegen ze diezelfde dag termen toe aan de tabel.
Als je dit in een custom search stack bouwt, kan een vibe-coding tool zoals Koder.ai helpen om snel het admin scherm en sync‑workflow te leveren, en tegelijk de synoniemenlijst bewerkbaar te houden voor niet-technische teams.
Ontwerp autocomplete die prettig aanvoelt voor India
Autocomplete moet snel, vertrouwd en vergevingsgezind aanvoelen. Voor Indiase e‑commerce levert het grootste voordeel nuttige suggesties bij de eerste paar letters. Mensen typen vaak snel, schakelen tussen Engels en lokale termen en onthouden geen exacte spelling.
Begin met tuning voor prefixes. De eerste 2 tot 4 tekens moeten al sterke, intent‑rijke suggesties tonen. Als iemand “sha” typt, verspil de hoogste plekken niet aan zeldzame items. Toon wat de meeste shoppers bedoelen en waar je veel voorraad van hebt.
Maak suggesties categorie‑bewust, niet alleen woord‑bewust. Als de gebruiker een lokaal woord als “shakkar” typt, moeten suggesties duidelijk naar de productcategorie (suiker) en populaire subtypes wijzen (poeder, organic). Dit vermindert verwarring en verkleint de kans dat ze een ongerelateerd resultaat kiezen.
Houd suggesties kort en leesbaar. Een goed patroon is: merk + product (als het echt veel voorkomt) of product + belangrijkste attribuut. Vermijd het proppen van maten, lange modelnummers en meerdere attributen in één regel.
Hier zijn praktische UI‑regels die meestal goed werken:
- Toon maximaal 5 tot 8 suggesties, waarbij de top 3 geoptimaliseerd is voor hoge conversie.
- Normaliseer spaties en interpunctie, zodat “t-shirt”, “tshirt” en “t shirt” naar dezelfde suggesties leiden.
- Geef de voorkeur aan items en categorieën die je nu kunt leveren (op voorraad en actieve listings).
- Meng typen gecontroleerd: 1–2 categorie‑suggesties, daarna producten, daarna merken.
- Toon geen suggesties die je niet kunt verkopen (geen dode categorieën, geen uit productie genomen merken).
Voorbeeld: een shopper typt “dett”. In India bedoelen veel mensen “Dettol” (merkintentie), maar sommigen willen “handwash” of “sanitizer” (productintentie). Je autocomplete kan “Dettol Handwash”, “Dettol Sanitizer” en een categorie als “Handwash” tonen zodat beide intenties worden afgedekt zonder te raden.
Als je dit consequent doet, wordt autocomplete en typfouttolerantie minder een kwestie van slimme algoritmes en meer van de shopper de volgende voor de hand liggende stap geven.
Stel typfouttolerantie in zonder rommelige matches
Bouw snel zoekregels
Prototypeer autocomplete-, synoniem- en typfoutregels als een echte service in dagen, niet maanden.
Typfouttolerantie helpt mensen producten te vinden, zelfs wanneer ze zich vergissen. Maar als je het te los zet, begint de zoekfunctie “vrijwel genoeg” items te tonen die onjuist voelen. Het doel is simpel: pak duidelijke fouten op en wees voorzichtig wanneer de intentie kan veranderen.
Begin met veilige edit‑afstandregels op basis van woordlengte. Korte woorden breken snel, dus houd die strikt. Langere woorden kunnen iets meer flexibiliteit verdragen.
- 1–4 letters: sta 0–1 bewerking toe (voorbeeld: “atta” → “atta”, “atta” → “attta”)
- 5–8 letters: sta tot 2 bewerkingen toe
- 9+ letters: sta tot 3 bewerkingen toe
- Als een query meerdere woorden heeft, pas bewerkingen per woord toe, maar cap het totaal voor de hele query
Behandel cijfers als een aparte klasse. “1kg” en “10kg” mogen nooit verwisselbaar zijn, en “500ml” mag niet “1500ml” worden. Een praktische regel is: pas geen typfouttolerantie toe binnen numerieke tokens en verander geen eenheden. Sta alleen formatteringsfixes toe zoals spaties of hoofdletters (“1 kg”, “1KG”, “1kg”).
Bescherm merknamen en high‑intent termen tegen “correctie” naar generieke woorden. Houd een kleine beschermde lijst (topmerken, private labels en merkachtige queries). Als een query dicht bij een beschermd woord zit, geef dan de voorkeur aan het tonen van een suggestie in plaats van het stilletjes herschrijven.
Toetsenbord‑buur‑fouten zijn gebruikelijk op mobiel, vooral bij Hinglish. Voeg extra tolerantie toe voor naburige toetsen (a‑s, i‑o, n‑m), maar alleen wanneer de rest van het woord een sterke match is.
Wanneer de correctie ambigu is, toon deze als suggestie, niet als stille vervanging. Bijvoorbeeld: als “dove” “done” of “dovee” kan worden, toon “Bedoelde u dove?” en houd de originele resultaten zichtbaar. Dit behoudt vertrouwen en vermindert boze terugkliks.
Transliteration en lokale termen (praktische regels)
Indiase queries mengen vaak schriften en gewoonten in één regel: “जीरा rice”, “jeera चावल”, “zeera rice” of “poha nashta”. Je zoekfunctie moet deze als dezelfde intentie behandelen, niet als aparte werelden. Voor autocomplete en typfouttolerantie is het doel simpel: vele manieren om een productnaam te schrijven mappen naar één duidelijke productbetekenis.
Begin met een kleine, praktische set regels en breid alleen uit als je ziet dat het werkt.
Praktische normalisatieregels
- Accepteer scriptmixing door alles te normaliseren naar een gedeelde “search‑vorm” (bewaar de originele query voor analytics, maar match tegen de genormaliseerde versie).
- Voeg transliteratieparen alleen toe voor je topitems eerst (bijv. namkeen, bhujia, poha, jeera). Neem de veelvoorkomende spellingen op die gebruikers echt typen.
- Behandel lange klinkervarianten als expliciete paren waar ze ertoe doen (poha vs pauha, jeera vs zeera) in plaats van te proberen elke klinkershift te raden.
- Gebruik klankwissels voorzichtig en nauw: v‑w, b‑v, j‑z. Pas ze alleen toe op bekende producttokens, niet op de hele query, om rare matches te vermijden.
- Houd merknamen en SKU’s grotendeels “zoals getypt” zodat je ze niet per ongeluk herschrijft.
Welke talen eerst ondersteunen
Kies op basis van traffic en zero‑results, niet ambitie. Een gebruikelijke volgorde is Engels plus Hinglish eerst, voeg daarna Hindi‑script toe als een relevant deel van de queries dat gebruikt. Als je later vraag in een regio ziet, breid dan per categorie uit.
Analytics‑loop: verbeter zoeken op basis van echt gedrag
Zet je prototype in productie
Deploy en host je zoektools zodat teams ze direct kunnen gebruiken.
Zoekkwaliteit is geen eenmalige instelling. Behandel het als een wekelijkse gewoonte: kijk wat mensen typen, wat ze klikken en waar ze afhaken. Zo wordt autocomplete en typfouttolerantie voor Indiase e‑commerce steeds beter zonder gokken.
Begin met een kleine set kernmetriek en houd die consistent week na week:
- Zero‑results percentage (totaal en voor topqueries)
- Verfijningspercentage (gebruikers die direct opnieuw typen of filters toevoegen)
- Add‑to‑cart na zoeken (of productklikken na zoeken als carts ruis geven)
- Autocomplete gebruik (klik op suggesties vs volledig handmatig typen)
- Correctie‑impact (typofixed queries die tot klikken leiden vs bounces)
Eens per week, haal je top no‑result queries en classificeer je ze. Houd categorieën simpel zodat teams ze echt gebruiken: ontbrekend synoniem (jeera vs zeera), spellingvariatie, merk of model mismatch, verkeerde taal of schrift, of catalogus‑gap (product niet op voorraad). Het doel is te scheiden tussen “zoekfunctie heeft een synoniem nodig” en “voorraad ontbreekt”.
Autocomplete‑data is vaak de snelste winst. Als gebruikers vaak suggesties negeren en toch afmaken, zijn je suggesties misschien te generiek, in de verkeerde volgorde of missen lokale termen. Als ze suggesties klikken maar toch verfijnen of wegklikken, lijkt de suggestie juist maar leiden de resultaten naar zwakke items.
Typfouten hebben een audit nodig, niet alleen meer tolerantie. Sampel wekelijks 20–50 gecorrigeerde queries en label ze als:
- Helpend (hersteld naar het bedoelde product)
- Onschuldig (dicht genoeg, gebruiker vond nog steeds items)
- Schadelijk (hersteld naar een ander product of categorie)
Zet dit in een eenvoudig dashboard dat product en marketing in 2 minuten kunnen lezen: top zero‑results queries met de toegewezen oorzaak, top autocomplete suggesties en klikratio, en een korte actielijst voor de volgende release. Als je snel interne tools bouwt (bijv. in Koder.ai), zijn dit goede eerste projecten.
Veelvoorkomende fouten en valkuilen om te vermijden
De meeste zoekproblemen in India gaan niet over “meer synoniemen”. Ze komen door een paar voorspelbare fouten die langzaam mensen naar verkeerde resultaten duwen en vertrouwen schaden.
Een van de grootste valkuilen is te brede synoniemen die verschillende producten samenvoegen. Als “cream” en “lotion” uitwisselbaar worden, kan iemand die een dikke face cream wil op een lichte body lotion terechtkomen en vertrekken. Houd synoniemen strak: map varianten van dezelfde intentie, niet aangrenzende categorieën.
Een veelgemaakte fout is het negeren van pakgrootte en eenheidsintentie. “Oil 1L” en “oil 5L” zijn niet dezelfde aankoopmissie, net zomin als “atta 5 kg” en “atta 10 kg”. Als je regels eenheden negeren, kan iemand die in bulk wil inslaan kleine verpakkingen voorgeschoteld krijgen en lijkt je rangorde willekeurig.
Hoge impact fouten om op te letten:
- Verwante producten als synoniemen behandelen (cream vs lotion, shampoo vs conditioner)
- Maten, aantallen en eenheidswoorden negeren (1L, 5L, 500 ml, 10 pcs)
- Typfouttolerantie merknamen laat “corrigeren” naar andere merken
- Autocomplete suggesties tonen die je niet op voorraad hebt of niet naar dat pin‑code kunt leveren
- Regels instellen en vergeten, vooral na promoties en seizoenspiekjes
Merknamen vereisen extra zorg. Als iemand “Himalya face wash” typt en je typinstellingen corrigeren dat naar een ander populair merk, voelt dat als lokken. Een veiliger regel is: wees vergevingsgezind op generieke woorden (“shampu”), maar strikter op merken en modelachtige tokens.
Autocomplete kan ook averechts werken als het niet‑beschikbare items suggereert. Bijvoorbeeld “ghee 2L” suggereren omdat het vaak gezocht wordt, terwijl alleen 1L op voorraad is, leidt tot teleurstelling. Geef voorkeur aan suggesties die je vandaag werkelijk kunt leveren.
Voeg een review‑gewoonte toe: check na een verkoopweek nieuwe topqueries, opkomende misspellings en zero‑results termen. Zelfs kleine seizoensverschuivingen (bruiloftsseizoen, moesson, examenseizoen) veranderen wat mensen typen.
Als je deze regels snel wilt testen, kan Koder.ai helpen bij het prototypen van een search rules service en een adminpagina om synoniemen, eenheden en merkbeschermingen te beheren, en dan de code exporteren als je er klaar voor bent.
Realistisch voorbeeld: “jeera rice” en “zeera rice” fixen
Een shopper typt “zeera rice” en krijgt geen resultaten. Ze zoeken niet iets anders; ze bedoelden “jeera rice” (komijnrijst) maar schreven het zoals ze het uitspreken.
Je lost dit op met twee kleine, veilige wijzigingen: een synoniem voor veelvoorkomende spellingvarianten en een conservatieve typfoutregel. Behandel in dit geval “zeera” als een transliteratievariant van “jeera”, niet als een aparte betekenis.
Een praktische mapping die goed werkt:
- Query synoniem: zeera → jeera
- Query synoniem: zira → jeera
- Laat productnamen in de catalogus ongewijzigd (rename SKUs niet)
Voeg daarna een typfouttolerantieregel toe die strikt is op korte woorden. Sta bijvoorbeeld 1 bewerking toe alleen wanneer tokenlengte 5+ is. Dat helpt “jeera” vs “jeeraa” op te vangen, maar voorkomt rommelige matches op zeer korte tokens.
Na de wijziging moet autocomplete de shopper leiden in plaats van te wild te raden. Als ze “zee…” typen, suggereer:
- “jeera rice”
- “jeera basmati rice”
- “jeera (cumin)”
En als ze “zeera rice” indienen, tonen de resultaten eerst je “jeera rice” producten, plus gerelateerde items zoals cumin en basmati, afhankelijk van je rangorde.
Een week later check je ecommerce zoekanalytics gericht op gedrag, niet alleen klikken:
- Zero‑results percentage voor “zeera”, “zira” en “jeera”
- Verfijningspercentage (typte men opnieuw?)
- Add‑to‑cart ratio na zoeken voor die queries
- Topklikken om te bevestigen dat het synoniem geen ongerelateerde items trekt
Als het slechter wordt (bijv. “zira” begint op een merknaam of andere categorie te matchen), rol je snel terug door alleen dat synoniemgroup uit te schakelen, niet het hele systeem. Houd versiebeheer zodat je in minuten kunt terugdraaien. Deze strakke feedbackloop is de kern van autocomplete en typfouttolerantie voor Indiase e‑commerce zoekfuncties.
Korte checklist voordat je wijzigingen uitrolt
Lever een synoniembeheerder uit
Maak een interne beheerpagina voor synoniemen en transliteraties die je merch-team kan bewerken.
Voer voor je nieuwe synoniemen, autocomplete of typinstellingen een korte testpass uit die echte querydata en hands‑on testen mengt. Dit voorkomt dat “helpende” wijzigingen rommelige resultaten creëren.
Gebruik deze pre‑ship checklist:
- Haal je top 50 zoekopdrachten uit de laatste 7–14 dagen en groepeer ze op intentie (merk, generiek product, variant zoals maat of kleur, en probleem zoals “hair fall oil”). Noteer dubbele betekenissen.
- Haal je top 50 zero‑results queries en bepaal voor elk de fix: map naar bestaande categorie, voeg synoniem toe (lokaal woord of spelling), voeg ontbrekend product toe, of blokkeer als irrelevant.
- Werk je synoniem‑ en transliteratielijst bij met een eigenaar, laatste wijzigingsdatum en korte reden. Dit voorkomt willekeurige duplicaten.
- Test autocomplete in je topcategorieën met echte gebruikersfrases: probeer Engels, Hinglish en veelgebruikte shorthand. Controleer dat suggesties niet te snel naar nicheitems springen en dat populaire varianten (zoals “1kg”, “500g”, “pack of 2”) aanwezig zijn.
- Stress‑test typfouttolerantie met 20 lastige queries: merkfouten (dubbele letters), gemixte nummers (“iPhone 15 pro 256”), en vergelijkbare woorden (“jeera/zeera”, “besan/besan flour”). Bevestig dat topresultaten nog steeds correct zijn, niet alleen “dichtbij”.
Als iets faalt, rol dan een kleinere wijziging uit. Een voorzichtige rollout werkt beter dan een grote update die zoekresultaten willekeurig maakt.
Volgende stappen: een eenvoudige rollout‑planning (en hoe je het sneller bouwt)
Begin met één categorie waar zoekpijn duidelijk is, zoals kruidenierswaren, persoonlijke verzorging of mobiele accessoires. Houd de scope klein voor één week zodat je oorzaak en gevolg kunt zien. Kies 2–3 succesmetriek die je daadwerkelijk kunt beïnvloeden, bijvoorbeeld zero‑results, zoek‑naar‑product‑klikratio en add‑to‑cart na zoeken.
Een simpele rollout die goed werkt ziet er zo uit:
- Dag 1: Baseline: vang huidige metrics, topqueries en top zero‑results queries voor de categorie.
- Dag 2–3: Ship een kleine woordenlijst: voeg een beperkte set synoniemen en Hinglish transliteraties toe voor de top 50 queries plus de top 20 merk‑ of verpakkingspatronen.
- Dag 4: Guardrails: voeg exclusies toe waar betekenis verandert (bijv. “atta” mag niet matchen met “ATA” als dat een merk of code is).
- Dag 5–6: Monitor: volg wins (minder zero results, meer klikken) en verliezen (meer irrelevante klikken, hoger terug‑zoeken).
- Dag 7: Beslis: behouden, bijstellen of terugrollen en plan de volgende batch op basis van wat verbeterde.
Maak wijzigingen omkeerbaar. Behandel synoniemen en typregels als code: versieer ze, maak snapshots en houd een heldere rollback‑route. Als een nieuwe regel plots “face wash” naar “dishwash liquid” laat gaan, moet je in minuten kunnen terugdraaien.
Eigenaarschap weegt zwaarder dan slimme regels. Wijs één persoon aan voor een wekelijkse 30‑minuten review: top nieuwe zero‑results, top “good saves” (herstelde typos) en pieken in kwaliteitsarme klikken.
Als je sneller wilt itereren, kan Koder.ai helpen bij het implementeren van de zoeklaag met een chatgestuurde build, planningstools om regels en metrics in kaart te brengen, en exporteerbare broncode zodat je team uiteindelijk zelf eigenaar is. Het ondersteunt snapshots en rollback, ideaal als een zoekwijziging snel ongedaan moet.
Plan je volgende iteratie op basis van meetbare uitkomsten. Bijvoorbeeld: als “zeera rice” begon te converteren maar “jeera” nu matcht met ongerelateerde “zera” producten, is je volgende actie duidelijk: verscherp die regel, niet alles herschrijven.