27 sep 2025·8 min
Blue/Green & Canary Deployments: een duidelijke release-strategie
Leer wanneer je Blue/Green of Canary moet gebruiken, hoe verkeer verschuiven werkt, wat je moet monitoren en praktische stappen voor uitrol en rollback voor veiligere releases.
Wat Blue/Green en Canary deployments betekenen
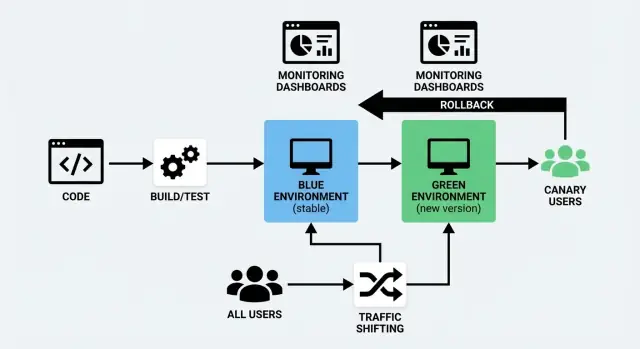
Het uitrollen van nieuwe code is riskant om één eenvoudige reden: je weet niet echt hoe het zich gedraagt totdat echte gebruikers ermee werken. Blue/Green en Canary zijn twee veelgebruikte manieren om dat risico te verminderen terwijl je downtime dichtbij nul houdt.
Blue/Green in eenvoudige woorden
Een Blue/Green deployment gebruikt twee aparte maar vergelijkbare omgevingen:
- Blue: de versie die momenteel gebruikers bedient (de “live” omgeving).
- Green: een tweede, kant-en-klare omgeving waar je de nieuwe versie deployt.
Je bereidt de Green-omgeving in de achtergrond voor — deployt de nieuwe build, voert checks uit, warmt hem op — en schakelt dan het verkeer van Blue naar Green zodra je vertrouwen hebt. Gaat er iets mis, dan kun je snel terugschakelen.
Het kernidee is niet “twee kleuren”, maar een schone, omkeerbare omschakeling.
Canary in eenvoudige woorden
Een canary release is een geleidelijke uitrol. In plaats van iedereen tegelijk over te zetten, stuur je de nieuwe versie eerst naar een klein deel van de gebruikers (bijvoorbeeld 1–5%). Ziet alles er goed uit, dan breid je de uitrol stap voor stap uit totdat 100% van het verkeer op de nieuwe versie zit.
Het kernidee is leren van echt verkeer voordat je volledig commit.
Het gedeelde doel: veiligere releases met minder downtime
Beide benaderingen zijn deploymentstrategieën die gericht zijn op:
- het beperken van de impact op gebruikers wanneer er iets misgaat
- het ondersteunen van een deploy zonder zichtbare downtime (of zo dicht mogelijk daarbij)
- het minder stressvol en beter voorspelbaar maken van rollbacks
Ze doen dat op verschillende manieren: Blue/Green richt zich op een snelle switch tussen omgevingen, terwijl Canary zich richt op gecontroleerde blootstelling via verkeer verschuiven.
Er is geen universeel “beste” optie
Geen van beide benaderingen is automatisch superieur. De juiste keuze hangt af van hoe je product wordt gebruikt, hoe zeker je bent van je tests, hoe snel je feedback nodig hebt en wat voor soort fouten je wilt voorkomen.
Veel teams combineren ook: ze gebruiken Blue/Green voor operationele eenvoud en Canary-technieken voor geleidelijke gebruikersblootstelling.
In de volgende secties vergelijken we ze direct en tonen we wanneer welke aanpak meestal het beste werkt.
Blue/Green vs Canary: snelle vergelijking
Blue/Green en Canary zijn beide manieren om wijzigingen uit te rollen zonder gebruikers te onderbreken — maar ze verschillen in hoe het verkeer naar de nieuwe versie beweegt.
Hoe verkeer schakelt
Blue/Green draait twee volledige omgevingen: “Blue” (actueel) en “Green” (nieuw). Je valideert Green en zet daarna al het verkeer in één keer om — alsof je één gecontroleerde schakelaar omdraait.
Canary zet de nieuwe versie eerst naar een klein deel van de gebruikers (bijvoorbeeld 1–5%) en verplaatst het verkeer geleidelijk terwijl je de prestaties in de echte wereld observeert.
Belangrijke voor- en nadelen
| Factor | Blue/Green | Canary |
|---|---|---|
| Snelheid | Zeer snelle omschakeling na validatie | Langzamer van opzet (gefaseerde uitrol) |
| Risico | Middel: een slechte release treft iedereen na de switch | Lager: problemen duiken vaak op voordat volledige uitrol |
| Complexiteit | Gemiddeld (twee omgevingen, schone switch) | Hoger (verkeerssplitsing, analyse, gefaseerde stappen) |
| Kosten | Hoger (je draait praktisch dubbele capaciteit tijdens uitrol) | Vaak lager (je kunt rampen binnen bestaande capaciteit uitvoeren) |
| Best voor | Grote, gecoördineerde wijzigingen | Frequente, kleine verbeteringen |
Een eenvoudige beslisgids
Kies Blue/Green wanneer je een schone, voorspelbare omschakeling wilt — vooral bij grotere wijzigingen, migraties of releases die een duidelijke “oud vs nieuw” scheiding nodig hebben.
Kies Canary wanneer je vaak uitrolt, veilig van echt gebruik wilt leren en de blast radius wilt beperken door met metrics elke stap te sturen.
Als je twijfelt, begin met Blue/Green voor operationele eenvoud en voeg Canary toe voor services met groter risico zodra monitoring en rollback-routines op orde zijn.
Wanneer Blue/Green de juiste keuze is
Blue/Green is een sterke optie wanneer je releases wilt laten voelen als het “omzetten van een schakelaar”. Je draait twee productie-achtige omgevingen: Blue (huidig) en Green (nieuw). Zodra Green geverifieerd is, routeer je gebruikers erheen.
Je hebt bijna geen downtime nodig
Als je product geen zichtbare onderhoudsvensters kan verdragen — checkoutflows, boekingssystemen, ingelogde dashboards — helpt Blue/Green omdat de nieuwe versie draait, opgewarmd en gecontroleerd wordt voordat echte gebruikers erheen gestuurd worden. Het meeste van de “deploytijd” gebeurt naast de gebruikers, niet voor ze.
Je wilt de eenvoudigste rollback
Rollback is vaak gewoon verkeer terug naar Blue routeren. Dat is waardevol wanneer:
- een release binnen enkele minuten omkeerbaar moet zijn
- je noodpatches onder druk wilt vermijden
- je een duidelijke, herhaalbare foutreactie wilt
Het belangrijkste voordeel is dat rollback geen rebuild of redeploy vereist — het is een verkeersswitch.
Je databasemigraties kunnen compatibel blijven
Blue/Green is het makkelijkst wanneer databasemigraties achterwaarts compatibel zijn, omdat Blue en Green kort tegelijk kunnen bestaan (en mogelijk beide lezen/schrijven, afhankelijk van routing en job-setup).
Geschikte veranderingen zijn bijvoorbeeld:
- additionele schemawijzigingen (nieuwe nullable-kolommen, nieuwe tabellen)
- uitbreidingen van dataformaten die oude code kan negeren
Risicovolle wijzigingen zijn het verwijderen van kolommen, hernoemen van velden of betekenisveranderingen — die kunnen de “terugschakelen”-belofte breken tenzij je meerstapsmigraties plant.
Je kunt dubbele omgevingen en routing betalen
Blue/Green vereist extra capaciteit (twee stacks) en een manier om verkeer te sturen (load balancer, ingress of platformrouting). Als je al automatisering hebt voor het provisionen van omgevingen en een schone routinghevel, wordt Blue/Green een praktisch standaardpatroon voor betrouwbare, lage-dramatische releases.
Wanneer Canary-releases logischer zijn
Een canary release is een strategie waarbij je een wijziging eerst naar een klein deel van echte gebruikers uitrolt, leert van wat er gebeurt en dan uitbreidt. Het is de juiste keuze als je risico wilt verminderen zonder alles te stoppen voor één grote uitrol.
Je hebt veel verkeer — en duidelijke signalen
Canary werkt het beste voor apps met veel verkeer omdat zelfs 1–5% van het verkeer snel betekenisvolle data kan opleveren. Als je al duidelijke metrics volgt (error rate, latency, conversie, checkout completion, API-timeouts), kun je de release valideren op echt gebruik in plaats van alleen te vertrouwen op testomgevingen.
Je bent bezorgd over prestaties en edge cases
Sommige problemen komen alleen naar voren onder echt verkeer: trage databasequeries, cache-misses, regionale latency, ongewone devices of zeldzame gebruikersstromen. Met een canary kun je bevestigen dat de wijziging geen errors verhoogt of prestaties degradeert voordat iedereen er last van heeft.
Je hebt gefaseerde uitrols nodig, geen enkele omschakeling
Als je product vaak uitrolt, meerdere teams bijdraagt of wijzigingen bevat die geleidelijk geïntroduceerd kunnen worden (UI-aanpassingen, prijsexperimenten, aanbevelingslogica), passen canary-uitrollen goed. Je kunt uitbreiden van 1% → 10% → 50% → 100% op basis van wat je ziet.
Feature flags horen bij je gereedschap
Canary werkt bijzonder goed met feature flags: je kunt code veilig deployen en functionaliteit daarna inschakelen voor een subset van gebruikers, regio’s of accounts. Rollbacks zijn minder dramatisch — vaak kun je een flag gewoon uitzetten in plaats van opnieuw te deployen.
Als je richting progressive delivery bouwt, zijn canary-releases vaak het flexibelste startpunt.
Zie ook: /blog/feature-flags-and-progressive-delivery
Basisprincipes van verkeer verschuiven (zonder vakjargon)
Verkeer verschuiven betekent simpelweg bepalen wie de nieuwe versie van je app krijgt en wanneer. In plaats van iedereen in één keer over te zetten, verplaats je verzoeken geleidelijk (of selectief) van de oude naar de nieuwe versie. Dit is het praktische hart van zowel een Blue/Green deployment als een Canary release — en het maakt een deploy zonder downtime realistisch.
Het “stuurwiel”: waar het verkeer naartoe wordt gericht
Je kunt verkeer op een paar gebruikelijke punten in je stack verschuiven. De juiste keuze hangt af van wat je al gebruikt en hoe fijnmazig je controle moet zijn.
- Load balancer: splitst inkomende verzoeken tussen twee omgevingen of servergroepen.
- Ingress controller (Kubernetes): routeert verkeer naar verschillende Services op basis van regels.
- Service mesh: beheert verkeer tussen services met precieze regels en betere zichtbaarheid.
- CDN / edge-routing: handig wanneer je routingbeslissingen dicht bij gebruikers wilt nemen, vaak voor webverkeer.
Je hoeft niet elke laag te gebruiken. Kies één “source of truth” voor routingbeslissingen zodat je releasebeheer geen giswerk wordt.
Veelgebruikte manieren om verkeer te splitsen
De meeste teams gebruiken één (of een mix) van deze benaderingen voor verkeer verschuiven:
- Percentage-gebaseerd: 1% → 5% → 25% → 50% → 100%. Dit is het klassieke canary-patroon.
- Header-gebaseerd: routeer verzoeken met een specifieke header (bijv. van QA-tools of interne testers) naar de nieuwe versie.
- Gebruikerscohorten: zet eerst bepaalde groepen om — medewerkers, beta-gebruikers, een regio of een klantniveau.
Percentage is het makkelijkst uit te leggen, maar cohorten zijn vaak veiliger omdat je kunt bepalen welke gebruikers de wijziging zien (en zo je grootste klanten in de eerste uren niet verrast).
Sessies en caches: de twee veelvoorkomende valkuilen
Twee dingen breken vaak anders solide deploymentplannen:
Sticky sessions (session affinity). Als je systeem een gebruiker aan één server/versie bindt, gedraagt een 10% split zich mogelijk niet als 10%. Het kan ook verwarrende bugs veroorzaken als gebruikers halverwege tussen versies wisselen. Gebruik waar mogelijk gedeelde sessie-opslag of zorg dat routing een gebruiker consistent bij één versie houdt.
Cache warming. Nieuwe versies slaan vaak koude caches (CDN, applicatiecache, databasequery-cache). Dat kan lijken op een prestatieverslechtering, zelfs als de code prima is. Plan tijd om caches op te warmen voordat je verkeer omhoog schuift, vooral voor drukbezochte pagina’s en dure endpoints.
Maak verkeerswijzigingen een gecontroleerde operatie
Behandel routingwijzigingen als productiewijzigingen, niet als een ad-hoc knop.
Documenteer:
- wie bevoegd is om verkeersverdelingen te wijzigen
- hoe het goedgekeurd wordt (on-call? release manager? change ticket?)
- waar het gedaan wordt (load balancer-config, ingress-regels, mesh-policy)
- wat “stop” betekent (de trigger om de uitrol te pauzeren en het rollback-plan te volgen)
Deze kleine governance voorkomt dat goedbedoelende mensen "even naar 50% schuiven" terwijl je nog aan het bepalen bent of de canary gezond is.
Wat je moet monitoren tijdens een uitrol
Lanceer op je domein
Ga live op je eigen domein wanneer je klaar bent om een nieuwe versie te promoten.
Een uitrol is niet alleen “is de deploy gelukt?” Het is “krijgen echte gebruikers een slechtere ervaring?” Het makkelijkste om rustig te blijven tijdens Blue/Green of Canary is een kleine set signalen te volgen die je vertellen: is het systeem gezond en schaadt de wijziging klanten?
De vier kernsignalen: errors, latency, saturatie, gebruikersimpact
Error rate: volg HTTP 5xx, verzoekfouten, timeouts en afhankelijkheidsfouten (database, betalingen, externe APIs). Een canary die “kleine” fouten verhoogt kan toch veel supportwerk veroorzaken.
Latency: let op p50 en p95 (en p99 als je die hebt). Een wijziging die gemiddelde latency stabiel houdt kan wel langstaart-tragepaden creëren die gebruikers merken.
Saturatie: kijk hoe “vol” je systeem is — CPU, geheugen, disk IO, DB-verbindingen, queue-diepte, threadpools. Saturatieproblemen laten zich vaak zien vóór totale uitval.
Gebruikersimpact-signalen: meet wat gebruikers daadwerkelijk ervaren — mislukte checkouts, inlogsuccespercentages, zoekresultaten, app-crashrate, laadtijden van belangrijke pagina’s. Deze zijn vaak betekenisvoller dan alleen infrastructuurstatistieken.
Bouw een “release-dashboard” dat iedereen kan lezen
Maak een klein dashboard dat op één scherm past en gedeeld wordt in je release-kanaal. Houd het consistent bij elke uitrol zodat mensen geen tijd verspillen aan het zoeken naar grafieken.
Neem op:
- error rate (algemeen + sleutelendpoints)
- latency (p50/p95 voor kritieke paden)
- saturatie (top 3 knelpunten in je stack, bijv. app CPU, DB-verbindingen, queue-diepte)
- gebruikersimpact-KPI’s (je 1–3 belangrijkste bedrijfsflows)
Als je een canary release draait, segmenteer metrics per versie/instancegroep zodat je canary en baseline direct kunt vergelijken. Voor Blue/Green vergelijk je de nieuwe omgeving met de oude tijdens het omschakelvenster.
Stel duidelijke drempels voor pauze/rollback-beslissingen
Bepaal de regels voordat je verkeer gaat schuiven. Voorbeeld drempels kunnen zijn:
- error rate stijgt met X% ten opzichte van baseline gedurende Y minuten
- p95 latency overschrijdt een vaste limiet (of stijgt X% boven baseline)
- een gebruikers-KPI daalt onder een minimum accepteerbare waarde
De exacte cijfers hangen af van je service, maar het belangrijke is overeenstemming. Als iedereen het rollback-plan en de triggers kent, voorkom je discussies terwijl klanten worden geraakt.
Alerts die gericht zijn op het uitrolvenster
Voeg alerts toe (of verscherp ze tijdelijk) tijdens uitrolvensters:
- onverwachte pieken in 5xx/timeouts
- plotselinge latency-regressie op sleutelpaden
- snelle groei in saturatie-signalen (connection pools, queues)
Houd alerts actiegericht: “wat is er veranderd, waar, en wat te doen.” Als alerting luidruchtig is, missen mensen het signaal dat ertoe doet terwijl verkeer verschoven wordt.
Pre-release checks die problemen vroeg vangen
De meeste uitrolfouten worden niet door “grote bugs” veroorzaakt. Het zijn kleine mismatchen: een ontbrekende configwaarde, een foutieve databasemigratie, een verlopen certificaat of een integratie die zich anders gedraagt in de nieuwe omgeving. Pre-release checks zijn je kans om die issues te vangen terwijl de blast radius nog klein is.
Begin met health checks en smoke tests
Voordat je verkeer verschuift (of het nu een blue/green switch of een kleine canary is), bevestig dat de nieuwe versie min of meer leeft en verzoeken kan afhandelen.
- Zorg dat app-health endpoints OK rapporteren (niet alleen “proces draait”)
- Valideer afhankelijkheden: database, cache, queue, object storage, e-mail/SMS-providers
- Controleer of secrets en environment variables aanwezig en correct gescopeerd zijn
Run korte end-to-end tests tegen de nieuwe omgeving
Unit-tests zijn goed, maar bewijzen niet dat het gedeployde systeem werkt. Draai een korte, geautomatiseerde end-to-end suite tegen de nieuwe omgeving die in minuten klaar is, niet uren.
Focus op flows die servicegrenzen overschrijden (web → API → database → externe dienst) en includeer ten minste één “echt” verzoek per belangrijke integratie.
Verifieer kritieke gebruikerspaden (de betalende flows)
Automatische tests missen soms het voor de hand liggende. Doe een gerichte, mensvriendelijke verificatie van je kernworkflows:
- inloggen en wachtwoord-reset
- checkout- of betalingsflow (inclusief foutpaden)
- kern acties zoals aanmaken / bijwerken / verwijderen die gebruikers dagelijks doen
Als je meerdere rollen ondersteunt (admin vs klant), test minimaal één pad per rol.
Houd een pre-release readiness checklist bij
Een checklist zet impliciete kennis om in een herhaalbare deploymentstrategie. Houd hem kort en uitvoerbaar:
- databasemigraties toegepast en omkeerbaar (of duidelijk veilig)
- observability klaar: logs, dashboards, alerts voor sleutelmetrics
- rollback-plan doorgenomen (wie, hoe en wat “stop” betekent)
Als deze checks routine zijn, wordt verkeer verschuiven een gecontroleerde stap — geen sprong in het diepe.
Blue/Green-uitrol: een praktische speelgids
Leer en krijg beloningen
Krijg credits door te delen wat je bouwt en leert met Koder.ai.
Een blue/green-uitrol is het makkelijkst als je het als checklist behandelt: voorbereiden, deployen, valideren, switchen, observeren en opruimen.
1) Deploy naar Green (zonder gebruikers te raken)
Deploy de nieuwe versie naar de Green-omgeving terwijl Blue het echte verkeer blijft bedienen. Houd configs en secrets gelijk zodat Green een echte spiegel is.
2) Valideer Green voordat je verkeer schakelt
Doe snelle, hoge-signaal checks eerst: de app start schoon op, belangrijke pagina’s laden, betalingen/inloggen werken en logs zien er normaal uit. Als je geautomatiseerde smoke-tests hebt, draai die nu. Dit is ook het moment om monitoringdashboards en alerts voor Green te verifiëren.
3) Plan databasemigraties veilig (expand/contract)
Blue/green wordt lastig als de database verandert. Gebruik een expand/contract-benadering:
- Expand: voeg nieuwe kolommen/tabellen toe op een achterwaarts compatibele manier.
- Deploy Green zodat hij met zowel oude als nieuwe schema kan werken.
- Contract: verwijder oude velden pas nadat Blue retired is en je zeker bent dat de nieuwe code stabiel is.
Dit voorkomt een “Green werkt, Blue faalt” situatie tijdens de switch.
4) Warm caches op en regel achtergrondjobs
Voordat je verkeer schakelt, warm kritieke caches op (homepagina, veelgevraagde queries) zodat gebruikers niet de “cold start”-kost betalen.
Voor achtergrondjobs/cron-workers beslis wie ze draait:
- voer jobs in één omgeving alleen uit tijdens de cutover om dubbele verwerking te vermijden
5) Schakel verkeer en observeer
Zet routing om van Blue naar Green (load balancer/DNS/ingress). Kijk naar error rate, latency en businessmetrics gedurende een korte periode.
6) Post-switch verificatie en opruimen
Doe een real-user style steekproef en houd Blue kort beschikbaar als fallback. Zodra het stabiel is, stop je Blue-jobs, archiveer logs en deprovisioneer Blue om kosten en verwarring te verminderen.
Canary-uitrol: een praktische speelgids
Een canary-uitrol draait om veilig leren. In plaats van alle gebruikers tegelijk naar de nieuwe versie te sturen, stel je een klein deel van het echte verkeer bloot, kijk je goed en breid je alleen uit als het veilig blijkt. Het doel is niet “traag gaan” — het doel is “bewijzen dat het veilig is” met bewijs bij elke stap.
Een eenvoudig rampschema (1–5% → 25% → 50% → 100%)
- Bereid de canary voor
Deploy de nieuwe versie naast de huidige stabiele versie. Zorg dat je een bepaald percentage verkeer naar elk kunt routeren en dat beide versies zichtbaar zijn in monitoring (verschillende dashboards of tags helpen).
- Fase 1: 1–5%
Begin klein. Hier verschijnen snelle problemen: kapotte endpoints, ontbrekende configs, databasemigratie-verrassingen of onverwachte latency-pieken.
Houd notities per fase:
- wat er veranderde in deze release (ook “kleine” configwijzigingen)
- wat je verwachtte
- wat je observeerde (errors, latency, gebruikersimpact)
- Fase 2: 25%
Als fase 1 schoon is, verhoog dan naar ongeveer een kwart van het verkeer. Je ziet nu meer variatie uit de echte wereld: verschillende gebruikersgedragingen, long-tail devices, edge cases en hogere concurrency.
- Fase 3: 50%
Bij de helft van het verkeer worden capaciteit en performanceproblemen duidelijker. Als je tegen schaalgrenzen aanloopt, zie je hier vaak de eerste signalen.
- Fase 4: 100% (promotie)
Wanneer metrics stabiel zijn en gebruikersimpact acceptabel, verplaats je al het verkeer naar de nieuwe versie en declareer je de promotie.
Hoe lang wachten per stap
De timing hangt af van risico en verkeersvolume:
- Hoge-risico wijziging of laag verkeer: wacht langer per fase om voldoende signaal te krijgen (bijv. 30–60 minuten of meer). Diensten met weinig verkeer hebben uren nodig om patronen te laten zien.
- Lage-risico wijziging met veel verkeer: kortere fases kunnen werken (bijv. 5–15 minuten), omdat je snel data verzamelt.
Houd ook rekening met businesscycli. Als je product pieken kent (lunchtijd, weekends, facturatie), laat de canary lang genoeg draaien om die omstandigheden af te dekken.
Automatiseer promotie en rollback
Handmatige uitrollen creëert twijfel en inconsistentie. Automatiseer waar mogelijk:
- promotie wanneer sleutelmetrics binnen drempels blijven voor een gedefinieerd venster
- rollback wanneer drempels worden overschreden (bijv. error rate of latency)
Automatisering neemt het oordeel niet weg — het vermindert vertraging.
Behandel elke fase als een experiment
Voor elke rampstap noteer:
- wijzigingssamenvatting (wat precies anders is)
- succeskriteria (welke metrics stabiel moeten blijven)
- geobserveerde resultaten (wat je zag, inclusief “niets ongewoons”)
- beslissing (promote, hold of rollback) en waarom
Deze notities veranderen je uitrolgeschiedenis in een playbook voor de volgende release en maken toekomstige incidenten makkelijker te diagnosticeren.
Rollback-plannen en foutafhandeling
Rollbacks zijn het makkelijkst als je van tevoren bepaalt wat “slecht” is en wie de knop mag indrukken. Een rollback-plan is geen pessimisme — het voorkomt dat kleine issues uitdraaien op langdurige outages.
Definieer duidelijke rollback-triggers
Kies een korte lijst signalen en stel expliciete drempels zodat je niet hoeft te discussiëren tijdens een incident. Veelvoorkomende triggers zijn:
- error rate: pieken in 5xx-fouten, mislukte checkouts, inlogfouten of API-timeouts
- latency: p95/p99 hoger dan afgesproken limiet voor een aanhoudend venster (bijv. 5–10 minuten)
- business KPI’s: plotselinge daling in conversie, betalingssucces, aanmeldingen of stijging in annuleringen
Maak de trigger meetbaar (“p95 > 800ms gedurende 10 minuten”) en koppel het aan een owner (on-call, release manager) met toestemming om direct te handelen.
Houd rollback snel (en saai)
Snelheid is belangrijker dan elegantie. Je rollback moet één van deze acties zijn:
- keer de verkeersshift om (typisch voor blue/green en canary): zet verkeer terug naar de vorige, bekende goede versie
- redeploy de vorige versie: als infra veranderde, push de laatste stabiele build en draai health checks opnieuw
Vermijd “handmatig fixen en dan verder gaan” als eerste stap. Stabiliseer eerst, onderzoek daarna.
Plan voor gedeeltelijke uitrollen
Met een canary kunnen sommige gebruikers data hebben gegenereerd onder de nieuwe versie. Bepaal van tevoren:
- Krijgen “canary”-gebruikers meteen weer het oude pad, of blijven ze op de canary terwijl je beoordeelt?
- Als dataformaten veranderden, is de database achterwaarts compatibel? Zo niet, kan rollback aanvullende mitigatie vereisen.
After-action review om de volgende release te verbeteren
Als het stabiel is, schrijf een korte nabeschouwing: wat de rollback veroorzaakte, welke signalen ontbraken en wat je in de checklist verandert. Zie het als productverbetering voor je releaseproces, geen schuldspel.
Feature flags en progressive delivery
Deel Koder.ai
Nodig teamgenoten of collega’s uit en verdien credits wanneer ze beginnen met Koder.ai.
Feature flags laten je deploy (code naar productie brengen) scheiden van release (het inschakelen voor gebruikers). Dat is belangrijk omdat je dezelfde deploymentpipeline — Blue/Green of Canary — kunt gebruiken terwijl je blootstelling met een eenvoudige schakel regelt.
Deploy zonder druk, release met intentie
Met flags kun je mergen en deployen, zelfs als een feature nog niet voor iedereen klaar is. De code staat in productie, maar is inactief. Als je vertrouwen hebt, schakel je de flag geleidelijk in — vaak sneller dan een nieuwe build pushen — en als er iets misgaat, zet je de flag weer uit.
Gericht inschakelen (niet alles-of-niets)
Progressive delivery draait om gecontroleerde toegang. Een flag kan ingeschakeld worden voor:
- een specifieke gebruikersgroep (intern personeel, beta-gebruikers, betaald niveau)
- een regio (begin met één land of datacenter)
- een percentage gebruikers (1% → 10% → 50% → 100%)
Dit is vooral handig wanneer een canary laat zien dat de nieuwe versie gezond is, maar je het feature-risico apart wilt beheren.
Guardrails tegen “flag debt”
Feature flags zijn krachtig, maar alleen als ze beheerd worden. Een paar regels houden ze netjes en veilig:
- eigenaarschap: elke flag heeft een verantwoordelijke team of persoon
- vervaldatum: zet een verwijderdatum (of reviewdatum) zodat oude flags niet opstapelen
- documentatie: beschrijf wat de flag doet, wie hij treft en hoe terug te draaien
Een praktische regel: als iemand niet kan uitleggen “wat er gebeurt als we dit uitzetten?”, is de flag nog niet klaar.
Voor diepere begeleiding over flags als onderdeel van een release-strategie, zie /blog/feature-flags-release-strategy.
Hoe je een strategie kiest en begint
Kiezen tussen Blue/Green en Canary draait niet om “wat is beter”. Het gaat om welk risico je wilt beheersen en wat je realistisch kunt runnen met je huidige team en tooling.
Een snelle manier om te beslissen
Als je hoogste prioriteit een schone, voorspelbare cutover is met een simpele “terug naar oud”-knop, is Blue/Green meestal het eenvoudigste.
Als je hoogste prioriteit is de blast radius verkleinen en veilig leren van echt verkeer voordat je verder uitrolt, is Canary veiliger — vooral wanneer wijzigingen frequent zijn of lastig volledig vooraf te testen.
Een praktische regel: kies de aanpak die je team consistently kan uitvoeren om 02:00 ’s nachts wanneer er iets misgaat.
Begin klein: pilot één ding
Kies één service (of één gebruikersworkflow) en voer een pilot uit voor een paar releases. Kies iets dat belangrijk genoeg is om ertoe te doen, maar niet zo kritisch dat iedereen bevriest. Het doel is om spierherinnering op te bouwen rond verkeer verschuiven, monitoring en rollback.
Schrijf een eenvoudig runbook (en ken eigenaarschap toe)
Houd het kort — één pagina is prima:
- wat “goed” betekent (sleutelmetrics en drempels)
- wie verantwoordelijk is tijdens een uitrol
- hoe te pauzeren, rollbacken en communiceren
Zorg dat eigenaarschap duidelijk is. Een strategie zonder eigenaar blijft een suggestie.
Gebruik eerst wat je al hebt
Voeg nieuwe platforms pas toe als ze echte frictie wegnemen die je in de pilot voelde. Begin met tools die je al gebruikt: load balancer-instellingen, deployment-scripts, bestaande monitoring en je incidentproces.
Als je snel nieuwe services bouwt en uitrolt, kunnen platformen die app-generatie met deployment-controles combineren ook operationele lasten verminderen. Bijvoorbeeld, Koder.ai is een vibe-coding platform dat teams laat web-, backend- en mobiele apps maken vanuit een chatinterface — en die vervolgens deployen en hosten met praktische veiligheidstools zoals snapshots en rollback, plus ondersteuning voor custom domains en source code export. Die mogelijkheden passen goed bij het kernidee van dit artikel: maak releases herhaalbaar, observeerbaar en omkeerbaar.
Voorgestelde vervolgstappen
Als je implementatieopties en ondersteunde workflows wilt bekijken, review /pricing en /docs/deployments. Plan daarna je eerste pilotrelease, noteer wat werkte en verbeter je runbook na elke uitrol.