23 dec 2025·8 min
Hoe je een webapp bouwt voor segmentatie en cohortanalyse
Een praktische, stap-voor-stap gids voor het bouwen van een webapp voor klantsegmentatie en cohortanalyse: datamodel, pijplijnen, UI, metrics en deployment.
Een praktische, stap-voor-stap gids voor het bouwen van een webapp voor klantsegmentatie en cohortanalyse: datamodel, pijplijnen, UI, metrics en deployment.
Voordat je tabellen ontwerpt of tools kiest, wees specifiek over welke vragen de app moet beantwoorden. “Segmentatie en cohorts” kan van alles betekenen; duidelijke use-cases voorkomen dat je een functievol product bouwt dat alsnog niemand helpt beslissingen te nemen.
Begin met het opschrijven van de exacte beslissingen die mensen willen nemen en de cijfers die ze vertrouwen om die beslissingen te nemen. Veelvoorkomende vragen zijn:
Noteer voor elke vraag het tijdsvenster (dagelijks/weekelijks/maandelijks) en de granulariteit (gebruiker, account, abonnement). Dit houdt de rest van de bouw op één lijn.
Identificeer de primaire gebruikers en hun workflows:
Leg ook praktische behoeften vast: hoe vaak ze dashboards bekijken, wat “one click” voor hen betekent en welke data ze als gezaghebbend beschouwen.
Definieer een minimum levensvatbare versie die de top 2–3 vragen betrouwbaar beantwoordt. Typische MVP-scope: kernsegmenten, een paar cohortweergaven (retentie, omzet) en deelbare dashboards.
Bewaar “nice to have”-items voor later, zoals geplande exports, alerts, automatiseringen, of complexe multi-step segmentlogica.
Als snelheid naar de eerste versie cruciaal is, overweeg dan het scaffolden van de MVP met een vibe-coding platform zoals Koder.ai. Je kunt de segmentbouwer, cohortheatmap en basis ETL-behoeften in de chat beschrijven en een werkende React-frontend plus een Go + PostgreSQL-backend genereren—en daarna itereren met planning mode, snapshots en rollback terwijl stakeholders definities verfijnen.
Succes moet meetbaar zijn. Voorbeelden:
Deze metrics worden je noordster wanneer later compromissen optreden.
Voordat je schermen ontwerpt of ETL-jobs schrijft, beslis wat “een klant” en “een actie” betekenen in je systeem. Cohort- en segmentatieresultaten zijn alleen zo betrouwbaar als de definities eronder.
Kies één primaire identifier en documenteer hoe alles daaraan wordt gekoppeld:
Wees expliciet over identity stitching: wanneer merge je anonymous en bekende profielen, en wat gebeurt er als een gebruiker tot meerdere accounts behoort?
Begin met de bronnen die je use-cases beantwoorden en voeg later meer toe:
Noteer voor elke bron het systeem van registratie en de verversingsfrequentie (real-time, elk uur, dagelijks). Dit voorkomt later discussies over “waarom komen deze cijfers niet overeen?”.
Stel één tijdzone in voor rapportage (vaak de bedrijfstijdzone of UTC) en definieer wat “dag”, “week” en “maand” betekenen (ISO-weken vs zondag-beginnende weken). Als je omzet verwerkt, kies valutaregels: opgeslagen valuta, rapportagevaluta en timing van wisselkoersen.
Schrijf definities op in gewone taal en hergebruik ze overal:
Behandel dit woordenboek als een productvereiste: het zou zichtbaar moeten zijn in de UI en worden gerefereerd in rapporten.
Een segmentatie-app leeft of sterft door zijn datamodel. Als analisten geen veelvoorkomende vragen met een eenvoudige query kunnen beantwoorden, wordt elk nieuw segment een engineering-taak.
Gebruik een consistent event-structuur voor alles wat je trackt. Een praktisch baseline is:
event_name (bijv. signup, trial_started, invoice_paid)timestamp (sla op in UTC)user_id (de actor)properties (JSON voor flexibele details zoals utm_source, device, feature_name)Houd event_name gecontroleerd (een gedefinieerde lijst) en houd properties flexibel—maar documenteer verwachte keys. Dit geeft consistentie voor rapportage zonder productveranderingen te blokkeren.
Segmentatie is vooral “gebruikers/accounts filteren op attributen.” Zet die attributen in aparte tabellen in plaats van alleen in event-properties.
Veelvoorkomende attributen zijn:
Dit stelt niet-experts in staat om segmenten te bouwen zoals “SMB gebruikers in EU op Pro verworven via partner” zonder in raw events te zoeken.
Veel attributen veranderen in de tijd—vooral plan. Als je alleen de huidige planwaarde opslaat op het user/account-record, zullen historische cohortresultaten verschuiven.
Twee veelvoorkomende patronen:
account_plan_history(account_id, plan, valid_from, valid_to).Kies bewust op basis van query-snelheid versus opslag en complexiteit.
Een simpel, query-vriendelijk kernmodel is:
user_id, account_id, event_name, timestamp, properties)user_id, created_at, region, etc.)account_id, plan, industry, etc.)Deze structuur mappt schoon op zowel klantsegmentatie als cohort/retentieanalyse, en schaalt als je meer producten, teams en rapportagebehoeften toevoegt.
Cohortanalyse is alleen zo betrouwbaar als haar regels. Voordat je de UI bouwt of queries optimaliseert, schrijf de exacte definities op die je app zal gebruiken zodat elke grafiek en export overeenkomt met wat stakeholders verwachten.
Begin met te kiezen welke cohorttypes je product nodig heeft. Veelvoorkomende opties zijn:
Elk type moet mapen naar één eenduidig anker-event (en soms een property), omdat dat anker de cohortlidmaatschap bepaalt. Beslis of cohortlidmaatschap immutabel is (eenmaal toegewezen, nooit wijzigen) of kan veranderen als historische data wordt gecorrigeerd.
Definieer vervolgens hoe je de cohortindex berekent (de kolommen zoals week 0, week 1…). Maak deze regels expliciet:
Kleine keuzes hier kunnen cijfers genoeg verschuiven om discussies te veroorzaken over “waarom komt dit niet overeen?”.
Definieer wat elke cohorttabelcel voorstelt. Typische metrics zijn:
Specificeer ook de noemer voor ratio-metrics (bijv. retentiegraad = actieve gebruikers in week N ÷ cohortgrootte in week 0).
Cohorts worden ingewikkeld aan de randen. Beslis regels voor:
Documenteer deze beslissingen in eenvoudige taal; je toekomstige zelf (en je gebruikers) zullen je dankbaar zijn.
Je segmentatie en cohortanalyse zijn alleen zo betrouwbaar als de data die binnenkomt. Een goede pijplijn maakt data voorspelbaar: dezelfde betekenis, dezelfde vorm en het juiste detailniveau elke dag.
De meeste producten gebruiken een mix van bronnen zodat teams niet door één integratie geblokkeerd worden:
Een praktische regel: definieer een kleine set “must-have” events die kerncohorts aandrijven (bijv. signup, first value action, purchase), en breid daarna uit.
Voeg validatie toe zo dicht mogelijk bij ingestie zodat slechte data zich niet verspreidt.
Focus op:
Wanneer je records afkeurt of fixeert, schrijf de beslissing naar een auditlog zodat je kunt uitleggen “waarom de cijfers zijn veranderd.”
Raw data is inconsistent. Transformeer het naar schone, consistente analytische tabellen:
Draai jobs op schema (of streaming) met duidelijke operationele guardrails:
Behandel de pijplijn als een product: meet het, bewaak het, en houd het saai betrouwbaar.
Waar je analytics-data opslaat bepaalt of je cohort-dashboard direct aanvoelt of pijnlijk traag. De juiste keuze hangt af van datavolume, query-patronen en hoe snel je resultaten nodig hebt.
Voor veel vroege producten is PostgreSQL voldoende: bekend, goedkoop in onderhoud en ondersteunt SQL goed. Het werkt het beste wanneer je eventvolume gematigd is en je zorgvuldig indexeert en partitioneert.
Als je zeer grote eventstromen verwacht (honderden miljoenen tot miljarden rijen) of veel gelijktijdige dashboardgebruikers, overweeg een data warehouse (bijv. BigQuery, Snowflake, Redshift) voor flexibele analytics op schaal, of een OLAP store (bijv. ClickHouse, Druid) voor extreem snelle aggregaties en slicing.
Een praktische regel: als je “retentie per week, gefilterd op segment”-query seconden kost in Postgres zelfs na tuning, dan zit je in warehouse/OLAP-territorium.
Bewaar raw events, maar voeg een aantal analyticsvriendelijke structuren toe:
Deze scheiding stelt je in staat cohorts/segmenten opnieuw te berekenen zonder je hele events-table te herschrijven.
De meeste cohortqueries filteren op tijd, entiteit en eventtype. Prioriteer:
(event_name, event_time))Dashboards herhalen dezelfde aggregaties: retentie per cohort, tellingen per week, conversies per segment. Precompute deze op schema (uurlijks/dagelijks) in samenvattingstabellen zodat de UI enkele duizenden rijen leest — niet miljarden.
Houd raw data beschikbaar voor drill-down, maar maak de standaardervaring afhankelijk van snelle samenvattingen. Dat is het verschil tussen “vrij verkennen” en “wachten op een spinner.”
Een segmentbouwer bepaalt het succes van segmentatie. Als het voelt als SQL schrijven, zal het merendeel van teams het niet gebruiken. Je doel is een “vraagbouwer” die iemand laat beschrijven wie ze bedoelen, zonder te hoeven weten hoe de data is opgeslagen.
Begin met een kleine set regeltypes die aansluiten op echte vragen:
Country = United States, Plan is Pro, Acquisition channel = AdsTenure is 0–30 days, Revenue last 30 days > $100Used Feature X at least 3 times in the last 14 days, Completed onboarding, Invited a teammateRender elke regel als een zin met dropdowns en vriendelijke veldnamen (verberg interne kolomnamen). Waar mogelijk, toon voorbeelden (bijv. “Tenure = dagen sinds eerste aanmelding”).
Niet-experts denken in groepen: “US en Pro en used Feature X,” plus uitzonderingen zoals “(US of Canada) en niet churned.” Houd het benaderbaar:
Laat gebruikers segmenten opslaan met een naam, beschrijving en optionele eigenaar/team. Opgeslagen segmenten moeten herbruikbaar zijn in dashboards en cohortweergaven, en versioned zodat wijzigingen oude rapporten niet stilletjes veranderen.
Toon altijd een geschatte of exacte segmentgrootte direct in de builder, die bijwerkt zodra regels veranderen. Als je sampling gebruikt voor snelheid, wees expliciet:
Toon ook wat is inbegrepen: “Gebruikers één keer geteld” vs “events geteld”, en het tijdsvenster dat voor gedragsregels wordt gebruikt.
Maak vergelijkingen een eersteklas optie: kies Segment A vs Segment B in hetzelfde scherm (retentie, conversie, omzet). Vermijd dat gebruikers grafieken moeten dupliceren.
Een eenvoudig patroon: een “Compare to…” selector die een ander opgeslagen segment of een ad-hoc segment accepteert, met duidelijke labels en consistente kleuren in de UI.
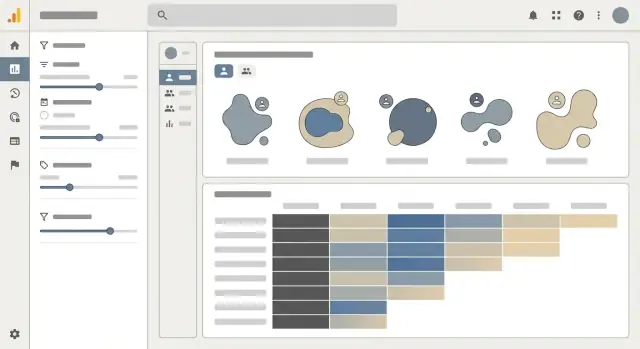
Een cohort-dashboard slaagt als het snel één vraag beantwoordt: “Behouden we mensen (of verliezen we ze), en waarom?” De UI moet patronen zichtbaar maken en lezers in staat stellen door te klikken zonder SQL te hoeven kennen of datamodel.
Gebruik een cohort-heatmap als kernweergave, maar label het als een rapport — niet als een puzzel. Elke rij moet duidelijk de cohortdefinitie en grootte tonen (bijv. “Week van 7 okt — 3.214 gebruikers”). Elke cel moet ondersteuning bieden om te wisselen tussen retentie % en absolute aantallen, omdat percentages schaal verbergen en aantallen snelheid verbergen.
Houd kolomkoppen consistent (“Week 0, Week 1, Week 2…” of daadwerkelijke datums), en toon de cohortgrootte naast het rijlabel zodat de lezer het vertrouwen kan inschatten.
Voeg tooltips toe op elk metriclabel (Retentie, Churn, Omzet, Actieve gebruikers) die aangeven:
Een korte tooltip is beter dan een lange help-pagina; het voorkomt misinterpretatie op het beslissingsmoment.
Zet de meest voorkomende filters boven de heatmap en maak ze omkeerbaar:
Toon actieve filters als chips en voeg een “Reset” met één klik toe zodat mensen niet bang zijn om te verkennen.
Bied CSV-export voor de huidige weergave (inclusief filters en of de tabel % of aantallen toont). Bied ook deelbare links die de configuratie bewaren. Bij delen, handhaaf permissies: een link mag nooit toegang uitbreiden buiten wat de kijker al heeft.
Als je een “Kopieer link” actie opneemt, toon dan een korte bevestiging en verwijs naar /settings/access voor het beheren van wie wat kan zien.
Segmentatie- en cohorttools raken vaak klantdata, dus beveiliging en privacy mogen geen bijzaak zijn. Behandel ze als productfeatures: ze beschermen gebruikers, verminderen supportlast en houden je compliant tijdens schaalvergroting.
Begin met authenticatie die bij je publiek past (SSO voor B2B, email/wachtwoord voor SMB, of beide). Handhaaf daarna eenvoudige, voorspelbare rollen:
Houd permissies consistent in UI en API. Als een endpoint cohortdata kan exporteren, is alleen UI-permissie niet genoeg—handhaaf controles server-side.
Als je app meerdere workspaces/klanten ondersteunt, ga ervan uit dat “iemand zal proberen data van een andere workspace te zien” en ontwerp voor isolatie:
Dit voorkomt per ongeluk datalekken tussen tenants, vooral wanneer analisten aangepaste filters maken.
De meeste segmentatie- en retentieanalyses werken zonder ruwe persoonsgegevens. Minimaliseer wat je inneemt:
Versleutel data in rust en tijdens transport en bewaar secrets (API-keys, database-credentials) in een echte secrets manager.
Definieer retentiepolicies per workspace: hoe lang raw events, afgeleide tabellen en exports worden bewaard. Implementeer verwijderworkflows die data echt verwijderen:
Een duidelijke, gedocumenteerde workflow voor retentie en gebruikersverwijdering is net zo belangrijk als de cohortgrafieken zelf.
Het testen van een analytics-app gaat niet alleen over “laadt de pagina?” Je brengt beslissingen uit. Een kleine rekenfout in cohortretentie of een subtiele filterbug in segmentatie kan een heel team misleiden.
Begin met unittests die je cohortberekeningen en segmentlogica verifiëren met kleine, bekende fixtures. Maak een klein datasetje waar het “juiste antwoord” duidelijk is (bijv. 10 gebruikers melden zich aan in week 1, 4 komen terug in week 2 → 40% retentie). Test dan:
Deze tests moeten in CI draaien zodat elke wijziging in querylogica of aggregaties automatisch wordt gecontroleerd.
De meeste analytics-fouten zijn dataproblemen. Voeg geautomatiseerde checks toe die bij elke load of ten minste dagelijks draaien:
Wanneer een check faalt, waarschuw met genoeg context om te handelen: welk event, welk tijdsvenster en hoe ver het van baseline afweek.
Voer prestatie-tests uit die echt gebruik nabootsen: grote datumbereiken, meerdere filters, hoge-cardinaliteitsproperties en geneste segmenten. Houd p95/p99 querytijden bij en handhaaf budgetten (bijv. segmentpreview onder 2 seconden, dashboard onder 5 seconden). Als tests slechter worden, weet je het vóór de volgende release.
Doe tenslotte user acceptance tests met product- en marketingcollega’s. Verzamel een set “echte vragen” die ze vandaag stellen en definieer verwachte antwoorden. Als de app geen vertrouwde resultaten kan reproduceren (of kan uitleggen waarom het afwijkt), is het nog niet klaar om te lanceren.
Het uitrollen van je segmentatie- en cohortanalyse-app gaat minder over één grote lancering en meer over het opzetten van een veilige lus: releasen, observeren, leren en verfijnen.
Kies de weg die past bij de vaardigheden van je team en de behoeften van je app.
Managed hosting (bijv. een platform dat uit Git deployt) is vaak de snelste manier om betrouwbare HTTPS, rollbacks en autoscaling te krijgen met minimale ops-werkzaamheden.
Containers passen goed wanneer je consistente runtime-gedragingen over omgevingen nodig hebt of verwacht te verplaatsen tussen cloudproviders.
Serverless kan werken voor spiky gebruik (bijv. dashboards die vooral tijdens kantooruren worden gebruikt), maar let op cold starts en langlopende ETL-jobs.
Als je een end-to-end pad wilt van prototype naar productie zonder je stack later te hoeven herbouwen, ondersteunt Koder.ai het genereren van de app (React + Go + PostgreSQL), deployen en hosten ervan, het koppelen van aangepaste domeinen en het gebruiken van snapshots/rollback om risico’s tijdens iteraties te verminderen.
Gebruik drie omgevingen: dev, staging en productie.
In dev en staging, vermijd het gebruik van ruwe klantdata. Laad veilige sample-datasets die nog steeds lijken op productie (zelfde kolommen, dezelfde eventtypes, dezelfde randgevallen). Dit houdt testen realistisch zonder privacyproblemen.
Maak van staging je “generale repetitie”: productie-achtige infrastructuur, maar geïsoleerde credentials, aparte databases en featureflags om nieuwe cohortregels te testen.
Monitor wat breekt en wat vertraagt:
Voeg eenvoudige alerts toe (email/Slack) voor mislukte ETL-runs, stijgende error-rates of plotselinge toename in query-timeouts.
Plan maandelijkse (of tweewekelijkse) releases op basis van feedback van niet-experts: verwarrende filters, ontbrekende definities of “waarom zit deze gebruiker in deze cohort?”-vragen.
Prioriteer toevoegingen die nieuwe beslissingen mogelijk maken — nieuwe cohorttypes (bijv. acquisitiekanaal, plantier), betere UX-standaarden en duidelijkere uitleg — zonder bestaande rapporten te breken. Featureflags en versioned calculations helpen je veilig te evolueren.
Als je team inzichten openbaar deelt, wees je ervan bewust dat sommige platforms (inclusief Koder.ai) programma’s aanbieden waarbij je credits kunt verdienen door content over je build te maken of anderen door te verwijzen — handig als je snel iteraties wilt doen en experimentkosten laag wilt houden.
Begin met 2–3 specifieke beslissingen die de app moet ondersteunen (bijv. week-1 retentie per kanaal, churnrisico per plan), en definieer vervolgens:
Bouw de MVP om die vragen betrouwbaar te beantwoorden voordat je alerts, automatiseringen of complexe logica toevoegt.
Schrijf definities in gewone taal en hergebruik ze overal (UI-tooltips, exports, docs). Definieer minimaal:
Standaardiseer daarna , en zodat grafieken en CSV's overeenkomen.
Kies een primaire identifier en documenteer expliciet hoe anderen daarop mappen:
user_id voor persoonsniveau-retentie/gebruikaccount_id voor B2B-rollups en abonnementsstatistiekenanonymous_id voor gedrag vóór aanmeldingDefinieer wanneer identity stitching plaatsvindt (bijv. bij login) en wat er gebeurt bij randgevallen (één gebruiker in meerdere accounts, merges, duplicaten).
Een praktisch uitgangspunt is een events + users + accounts-model:
event_name, timestamp (UTC), , , (JSON)Als attributen zoals plan of lifecycle-status in de tijd veranderen, zal het alleen opslaan van de ‘huidige’ waarde historische cohorts laten afwijken.
Veelgebruikte aanpakken:
plan_history(account_id, plan, valid_from, valid_to)Kies op basis van of je query-snelheid of opslag/ETL-eenvoud prioriteert.
Kies cohorttypes die naar een enkel anker-event verwijzen (signup, eerste aankoop, eerste key feature gebruik). Specificeer daarna:
Bepaal ook of cohortlidmaatschap immutabel is of kan wijzigen als late/gerelateerde gegevens binnenkomen.
Beslis vooraf hoe je omgaat met:
Zet deze regels in tooltips en exportmetadata zodat belanghebbenden resultaten consistent kunnen interpreteren.
Begin met ingestiepaden die bij je source-of-truth passen:
Voeg vroege validatie toe (vereiste velden, timestamp-sanity, dedupe-keys) en houd een auditlog bij van afgewezen/gefixte records zodat je veranderingen in cijfers kunt verklaren.
Voor matige volumes kan PostgreSQL volstaan met zorgvuldige indexering/partitionering. Voor zeer grote eventstromen of hoge gelijktijdigheid, overweeg een data warehouse (BigQuery/Snowflake/Redshift) of een OLAP store (ClickHouse/Druid).
Om dashboards snel te houden, precompute veelvoorkomende resultaten in:
segment_membership (met geldigheidsvensters als lidmaatschap verandert)Gebruik eenvoudige, voorspelbare RBAC en handhaaf die server-side:
Voor multi-tenant apps, voeg overal toe en pas row-level scoping (RLS of equivalent) toe. Minimaliseer PII, mask standaardwaarden en implementeer verwijderworkflows die zowel raw als afgeleide data verwijderen (of aggregaten markeren als verouderd voor verversing).
user_idaccount_idpropertiesHoud event_name gecontroleerd (een bekende lijst) en properties flexibel maar gedocumenteerd. Deze combinatie ondersteunt zowel cohortberekeningen als niet-technische segmentatie.
Houd raw events voor drill-down, maar laat de standaard UI op samenvattingen leunen.
workspace_id