05 mei 2025·8 min
Bouw een webapp om klantescalatie-tijdlijnen te beheren
Stapsgewijs plan om een webapp te bouwen die klantescalaties, deadlines, SLA's, eigenaarschap en meldingen bijhoudt—plus rapportage en integraties.
Stapsgewijs plan om een webapp te bouwen die klantescalaties, deadlines, SLA's, eigenaarschap en meldingen bijhoudt—plus rapportage en integraties.
Voordat je schermen ontwerpt of een techstack kiest, maak duidelijk wat “escalatie” in jouw organisatie betekent. Is het een supportcase die ouder wordt, een incident dat de uptime bedreigt, een klacht van een belangrijke klant, of elk verzoek dat een ernstniveau overschrijdt? Als teams het woord verschillend gebruiken, zal je app die verwarring vastleggen.
Schrijf een één-zinsdefinitie waar je hele team het over eens kan zijn en voeg een paar voorbeelden toe. Bijvoorbeeld: “Een escalatie is elk klantprobleem dat een hoger supportniveau of managementbetrokkenheid vereist en een tijdgebonden verplichting heeft.”
Geef ook aan wat geen escalatie is (bijv. routinematige tickets, interne taken) zodat v1 niet opbolt.
Succescriteria moeten weerspiegelen wat je wilt verbeteren—niet alleen wat je wilt bouwen. Veel voorkomende kernuitkomsten zijn:
Kies 2–4 metrics die je vanaf dag één kunt volgen (bijv. breach-rate, tijd in elke escalatiefase, aantal hertoewijzingen).
Maak een lijst van primaire gebruikers (agents, teamleads, managers) en secundaire stakeholders (accountmanagers, engineering on-call). Noteer voor ieder wat ze snel moeten doen: eigenaarschap nemen, een deadline verlengen met reden, zien wat er hierna komt of status samenvatten voor een klant.
Leg huidige faalmodes vast met concrete verhalen: gemiste overdrachten tussen tiers, onduidelijke doorlooptijden na herverdeling, “wie heeft de verlenging goedgekeurd?”-discussies.
Gebruik deze verhalen om must-haves (tijdlijn + eigenaarschap + auditbaarheid) te scheiden van latere toevoegingen (geavanceerde dashboards, complexe automatisering).
Met doelen helder, beschrijf hoe een escalatie door je team beweegt. Een gedeelde workflow voorkomt dat “speciale gevallen” leiden tot inconsistente afhandeling en gemiste SLA's.
Begin met een eenvoudig aantal stages en toegestane overgangen:
Documenteer wat elke fase betekent (ingangscriteria) en wat waar moet zijn om eruit te gaan (uitgangscriteria). Dit voorkomt ambiguïteit zoals “Resolved maar nog in afwachting van klant”.
Escalaties moeten worden aangemaakt door regels die je in één zin kunt uitleggen. Veelvoorkomende triggers:
Bepaal of triggers automatisch een escalatie aanmaken, een suggestie doen aan een agent, of goedkeuring vereisen.
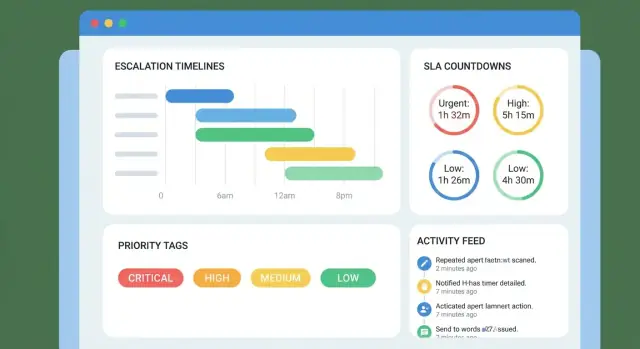
Je tijdlijn is alleen zo goed als zijn gebeurtenissen. Leg minimaal vast:
Schrijf regels voor eigenaarswijzigingen: wie kan herverdelen, wanneer zijn goedkeuringen nodig (bijv. cross-team of vendor handoff), en wat gebeurt er als een eigenaar van dienst afgaat.
Map tenslotte afhankelijkheden die timing beïnvloeden: on-call roosters, tier levels (T1/T2/T3), en externe vendors (inclusief hun responstijdvensters). Dit stuurt later je tijdlijnberekeningen en escalatiematrix.
Een betrouwbare escalatie-app is grotendeels een datavraagstuk. Als tijdlijnen, SLA's en geschiedenis niet duidelijk gemodelleerd zijn, zullen UI en notificaties altijd “off” aanvoelen. Begin met het benoemen van de kernentiteiten en relaties.
Minimaal plan voor:
Behandel elke mijlpaal als een timer met:
start_at (wanneer de klok begint)due_at (berekende deadline)paused_at / pause_reason (optioneel)completed_at (wanneer voldaan)Sla waarom een due date bestaat op (de regel), niet alleen de berekende timestamp. Dat maakt latere geschillen makkelijker op te lossen.
SLA's betekenen zelden “altijd”. Modelleer een kalender per SLA-beleid: kantooruren versus 24/7, feestdagen en regio-specifieke schema's.
Bereken deadlines in een consistente servertijd (UTC), maar sla altijd de case tijdzone (of klanttijdzone) op zodat je UI deadlines correct kan weergeven en gebruikers erover kunnen redeneren.
Bepaal vroeg of je kiest voor:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), ofVoor naleving en verantwoording verdient een eventlog de voorkeur (zelfs als je ook 'current state' kolommen houdt voor performance). Iedere wijziging moet vastleggen wie, wat er veranderde, wanneer, en bron (UI, API, automatisering), plus een correlatie-ID voor tracing van gerelateerde acties.
Permissies zijn waar escalatietools vertrouwen verdienen—of ze worden omzeild met bijbehorende spreadsheets. Definieer wie wat kan doen vroeg, en dwing dat consistent af in UI, API en exports.
Houd v1 simpel met rollen die overeenkomen met hoe supportteams werken:
Maak rolchecks expliciet in het product: deactiveer controls in plaats van gebruikers op fouten te laten klikken.
Escalaties bestrijken vaak meerdere groepen (Tier 1, Tier 2, CSM, incident response). Plan multi-team support door zichtbaarheid te scopen met één of meer dimensies:
Een goede default: gebruikers hebben toegang tot cases waar ze assignee, watcher zijn, of tot het eigenaarsteam behoren—plus accounts expliciet gedeeld met hun rol.
Niet alle data mag voor iedereen zichtbaar zijn. Veelvoorkomende gevoelige velden: klant-PII, contractdetails en interne notities. Implementeer veldniveau-permissies zoals:
Voor v1 is e-mail/wachtwoord met MFA meestal toereikend. Ontwerp het gebruikersmodel zodat je later SSO (SAML/OIDC) kunt toevoegen zonder permissies te herschrijven (bv. sla rollen/teams intern op en map SSO-groepen bij login).
Behandel permissiewijzigingen als auditbare acties. Registreer events zoals rolupdates, teamreassignments, exportdownloads en configuratiewijzigingen—wie deed het, wanneer en wat veranderde. Dit helpt tijdens incidenten en maakt access reviews eenvoudiger.
Je escalatie-app wint of verliest op de dagelijkse schermen: wat een supportlead als eerste ziet, hoe snel iemand een case kan begrijpen en of de volgende deadline onmogelijk te missen is.
Begin met een kleine set pagina's die 90% van het werk dekken:
Houd navigatie voorspelbaar: linkerzijbalk of top-tabs met “Queue”, “My Cases”, “Reports”. Maak de queue de standaard landingspagina.
In de case-lijst toon je alleen velden die helpen beslissen wat nu te doen. Een goede default-rij bevat: customer, prioriteit, huidige eigenaar, status, next due date, en een waarschuwingsindicator (bv. “Nog 2u” of “Overdue met 1d”).
Voeg snelle, praktische filters en zoeken toe:
Ontwerp voor scanbaarheid: consistente kolombreedtes, duidelijke statuschips en één highlightkleur die alleen bij urgentie gebruikt wordt.
De case-view moet in één oogopslag beantwoorden:
Plaats snelle acties bovenaan (niet weggestopt in menu's): Reassign, Escalate, Add milestone, Add note, Set next deadline. Elke actie moet bevestigen wat er veranderde en de tijdlijn meteen bijwerken.
Je tijdlijn moet als een duidelijke volgorde van verplichtingen lezen. Toon:
Gebruik progressive disclosure: toon eerst de nieuwste events, met de optie oudere geschiedenis uit te klappen. Als je een audittrail hebt, link er dan vanuit de tijdlijn naar (bv. “Bekijk wijzigingslog”).
Gebruik voldoende kleurcontrast, combineer kleur met tekst (“Overdue”), zorg dat alle acties via toetsenbord bereikbaar zijn en schrijf labels in de gebruikersspraak (“Stel volgende klantupdate-deadline in”, niet “Update SLA”). Dit voorkomt misklikken onder druk.
Alerts zijn het “hartslag”-systeem van een escalatietijdlijn: ze houden cases in beweging zonder dat mensen constant dashboards hoeven te bekijken. Het doel is simpel—waarschuw de juiste persoon op het juiste moment met zo min mogelijk ruis.
Begin met een klein aantal events die direct tot actie leiden:
Voor v1 kies je kanalen die je betrouwbaar kunt leveren en meten:
SMS of chattools kunnen later, zodra regels en volumes stabiel zijn.
Representeer escalatie als tijdgebaseerde drempels gekoppeld aan de case-tijdlijn:
Maak de matrix configureerbaar per prioriteit/wachtrij zodat P1-incidenten niet hetzelfde patroon volgen als facturatievragen.
Implementeer deduplicatie (“stuur niet twee keer dezelfde alert”), batching (digest vergelijkbare alerts), en quiet hours die niet-kritieke herinneringen uitstellen maar wel loggen.
Elke alert moet ondersteunen:
Sla deze acties op in je audittrail zodat rapportage kan onderscheiden tussen “niemand zag het” en “iemand zag het en stelde het uit.”
De meeste escalatietools falen wanneer mensen gegevens opnieuw moeten intypen die al elders bestaan. Voor v1 integreer alleen wat nodig is om tijdlijnen accuraat te houden en notificaties op tijd te versturen.
Bepaal welke kanalen een escalatiecase kunnen aanmaken of bijwerken:
Houd inkomende payloads klein: case ID, customer ID, huidige status, prioriteit, tijdstempels en een korte samenvatting.
Je app moet andere systemen informeren wanneer iets belangrijk gebeurt:
Gebruik webhooks met ondertekende requests en een event-ID voor deduplicatie.
Als je beide richtingen sync't, declareer per veld een source of truth (bv. ticketingtool bezit status; jouw app bezit SLA-timers). Definieer conflictoplossingsregels (“last write wins” is zelden correct) en voeg retry-logica met backoff plus een dead-letter queue toe voor failures.
Voor v1 importeer klanten en contacten met stabiele externe ID's en een minimaal schema: accountnaam, tier, sleutelcontacten en escalatievoorkeuren. Vermijd diepe CRM-mirroring.
Documenteer een korte checklist (auth-methode, vereiste velden, rate-limieten, retries, testomgeving). Publiceer een minimaal API-contract (zelfs één pagina) en versieer het zodat integraties niet onverwacht breken.
Je backend moet twee dingen goed doen: escalatietiming nauwkeurig houden en snel blijven naarmate case-volume groeit.
Kies de eenvoudigste architectuur die je team kan onderhouden. Een klassiek MVC-app met een REST API is vaak genoeg voor v1. Als je al goed werkt met GraphQL kan dat ook, maar voeg het niet toe “omdat het kan.” Koppel het aan een managed database (bv. Postgres) zodat je tijd besteedt aan escalatielogica, niet database-operaties.
Als je de workflow end-to-end wilt valideren voordat je weken aan engineering besteedt, kan een vibe-coding platform zoals Koder.ai helpen om de kernloop (queue → case detail → timeline → notifications) te prototypen vanuit een chatinterface, vervolgens in planningsmodus te itereren en broncode te exporteren wanneer je klaar bent. De default stack (React op web, Go + PostgreSQL op backend) past praktisch bij dit soort audit-zware apps.
Escalaties hangen af van gepland werk, dus je hebt background processing nodig voor:
Maak jobs idempotent (veilig om twee keer te draaien) en retryable. Sla een “last evaluated at” timestamp per case/tijdlijn op om dubbele acties te voorkomen.
Bewaar alle timestamps in UTC. Converteer naar de gebruiker zijn tijdzone alleen aan de UI/API-grens. Voeg tests toe voor edge-cases: zomer-/wintertijd, schrikkeldagen en “pauze”-klokken (bv. SLA gepauzeerd wanneer er op klant wordt gewacht).
Gebruik paginatie voor queues en audittrail-weergaven. Voeg indexen toe die bij je filters en sorts passen—vaak (due_at), (status), (owner_id) en samengestelde indexen zoals (status, due_at).
Plan file storage apart van je DB: handhaaf size/type-limieten, scan uploads (of gebruik provider-integratie) en stel retentie-regels in (bv. verwijderen na 12 maanden tenzij legal hold). Houd metadata in je case-managementtabellen; sla het bestand op in object storage.
Rapportage is waar je escalatie-app stopt met een gedeelde inbox en start met managementinformatie. Voor v1 mik op één rapportagepagina die twee vragen beantwoordt: “Halen we SLA's?” en “Waar blijven escalaties hangen?” Houd het simpel, snel en gebaseerd op definities waar iedereen het over eens is.
Een rapport is zo betrouwbaar als de onderliggende definities. Leg deze in eenvoudige taal vast en reflecteer ze in je datamodel:
Bepaal ook welke SLA-klok je rapporteert: first response, next update of resolution (of alle drie).
Je dashboard kan lichtgewicht maar bruikbaar zijn:
Voeg operationele weergaven toe voor dag-tot-dag load balancing:
CSV-export is meestal genoeg voor v1. Koppel exports aan permissies (team-based toegang, rolchecks) en schrijf een auditlog-record voor elke export (wie, wanneer, gebruikte filters, aantal rijen). Dit voorkomt “mystery spreadsheets” en ondersteunt compliance.
Lever de eerste rapportagepagina snel, review wekelijks met supportleads gedurende een maand. Verzamel feedback over ontbrekende filters, verwarrende definities en “ik kan X niet beantwoorden”—dat zijn de beste inputs voor v2.
Het testen van een escalatie-tijdlijnapp gaat niet alleen over “werkt het?” maar “gedraagt het zich zoals supportteams verwachten onder druk?” Focus op realistische scenario's die je tijdlijnregels, notificaties en case-handoffs belasten.
Besteed het grootste deel van je testinspanning aan tijdlijnberekeningen; kleine fouten hier leiden tot grote SLA-discussies.
Deeltests omvatten kantoorurenberekeningen, feestdagen en tijdzones. Voeg tests toe voor pauzes (wachten op klant, engineering), prioriteitswijzigingen halverwege een case en escalaties die target-responstijden verschuiven. Test ook edge-cases: een case aangemaakt één minuut voor sluiting, of een pauze die precies op een SLA-grens begint.
Notificaties falen vaak in de kieren tussen systemen. Schrijf integratietests die verifiëren:
Als je e-mail, chat of webhooks gebruikt, controleer payloads en timing, niet alleen dat “iets is verzonden”.
Maak realistische voorbeelddata die UX-problemen vroeg onthult: VIP-klanten, langlopende cases, veel herverdelingen, heropende incidenten en piekmomenten voor queues. Dit helpt valideren dat queues, case-view en tijdlijn leesbaar zijn zonder uitleg.
Voer een pilot uit met één team gedurende 1–2 weken. Verzamel dagelijks issues: ontbrekende velden, verwarrende labels, notificatieruis en uitzonderingen op tijdlijnregels.
Volg wat gebruikers buiten de app doen (spreadsheets, bijkanalen) om gaten te vinden.
Leg vast wat “klaar” betekent vóór brede uitrol: de belangrijkste SLA-metrics komen overeen met verwachte resultaten, kritieke notificaties zijn betrouwbaar, audittrails compleet en het pilotteam kan escalaties end-to-end uitvoeren zonder workarounds.
Het uitbrengen van de eerste versie is niet het einde. Een escalatietijdlijnapp wordt “echt” pas wanneer hij dagelijkse fouten overleeft: gemiste jobs, trage queries, misconfiguraties van notificaties en onvermijdelijke wijzigingen in SLA-regels. Behandel deployment en operatie als onderdeel van het product.
Houd je releaseproces saai en herhaalbaar. Documenteer en automatiseer minimaal:
Als je een staging-omgeving hebt, vul die met realistische (gesanitiseerde) data zodat tijdlijngedrag en notificaties voor productie geverifieerd kunnen worden.
Traditionele uptime-checks vangen niet de ergste problemen. Voeg monitoring toe waar escalaties stil kunnen breken:
Maak een klein on-call playbook: “Als escalatie-herinneringen niet verzenden, controleer A → B → C.” Dit verkort downtime tijdens hoge druk.
Escalatiedata bevat vaak klantnamen, e-mails en gevoelige notities. Definieer beleid vroeg:
Maak retentie configureerbaar zodat je geen codewijzigingen nodig hebt voor beleidupdates.
Zelfs in v1 hebben admins manieren nodig om het systeem gezond te houden:
Schrijf korte, taakgerichte docs: “Maak een escalatie aan”, “Pauzeer een tijdlijn”, “Override de SLA”, “Audit wie wat veranderde.”
Voeg een lichte onboarding-flow in de app toe die gebruikers naar queues, case view en timeline-acties leidt, plus een verwijzing naar een helppagina voor naslag.
Versie 1 moet de kernloop bewijzen: een case heeft een duidelijke tijdlijn, de SLA-klok gedraagt zich voorspelbaar en de juiste mensen krijgen notificaties. Versie 2 kan kracht toevoegen zonder van v1 een ingewikkeld “alles-in-één”-systeem te maken. Houd een korte, expliciete backlog met upgrades die je pas oppakt als je echte gebruikspatronen ziet.
Een goede v2-item reduceert handmatig werk op schaal of voorkomt kostbare fouten. Als het vooral extra configuratie-opties toevoegt, parkeer het totdat meerdere teams bewijzen dat ze het nodig hebben.
SLA-kalenders per klant betalen zich vaak als eerste uit: verschillende kantooruren, feestdagen of contractueel afgesproken responstijden.
Daarna: playbooks en templates—vooraf ingestelde escalatiestappen, aanbevolen stakeholders en berichten-voorinstellingen die reacties consistent maken.
Als toewijzing een bottleneck wordt, overweeg skills-based routing en on-call roosters. Houd de eerste iteratie simpel: een klein aantal skills, een fallback-eigenaar en duidelijke override-controls.
Auto-escalatie kan triggeren op signalen (severity-wijzigingen, keywords, sentiment, herhaalde contacten). Begin met “gesuggereerde escalatie” (een prompt) voordat je “automatische escalatie” invoert, en log elke triggerreden voor vertrouwen en auditability.
Voeg verplichte velden toe vóór escalatie (impact, severity, klanttier) en goedkeuringsstappen voor hoge-severity escalaties. Dit vermindert ruis en houdt rapportage accuraat.
Als je automatiseringspatronen wilt verkennen voordat je ze bouwt, zie blog/workflow-automation-basics. Als je scope aan packaging wilt toetsen, check pricing.
Begin met een eenduidige, één-zinsdefinitie waar iedereen het over eens is (plus een paar voorbeelden). Voeg expliciet toe wat géén escalatie is (routine tickets, interne taken) zodat v1 niet verandert in een algemeen ticketingsysteem.
Schrijf daarna 2–4 succesmetrics op die je direct kunt meten, zoals SLA-breukpercentage, tijd in elke fase of aantal hertoewijzingen.
Kies uitkomsten die operationele verbetering laten zien, niet alleen afgeronde features. Praktische v1-metrics zijn onder andere:
Kies een klein aantal dat je vanaf dag één uit tijdstempels kunt berekenen.
Gebruik een kleine, gedeelde set stages met duidelijke entry- en exitcriteria, zoals:
Schrijf vast wat waar moet zijn om elke fase te betreden en te verlaten. Dit voorkomt ambiguïteit zoals “Resolved maar nog in afwachting van de klant.”
Leg minimaal de gebeurtenissen vast die nodig zijn om de tijdlijn te reconstrueren en SLA-beslissingen te onderbouwen:
Als je niet kunt uitleggen hoe een timestamp wordt gebruikt, verzamel die dan niet in v1.
Modelleer elke mijlpaal als een timer met:
start_atdue_at (berekend)paused_at en pause_reason (optioneel)completed_atSla ook de regel op die produceerde (beleid + kalender + reden). Dat maakt audits en geschillen veel eenvoudiger dan alleen de einddatum opslaan.
Bewaar alle tijdstempels in UTC, maar houd een case-/klanttijdzone voor weergave en gebruikerscontext. Modelleer SLA-kalenders expliciet (24/7 versus kantooruren, feestdagen, regionschema's).
Test edge-cases zoals zomer-/wintertijd, tickets vlak voor sluiting en een pauze die precies op de grens begint.
Houd v1-rollen eenvoudig en afgestemd op werkpraktijken:
Voeg scope-regels toe (team/region/account) en veldniveau-controles voor gevoelige data zoals interne notities en PII.
Ontwerp eerst de dagelijkse schermen:
Optimaliseer voor snel scannen; snelle acties mogen niet in menu's weggestopt zitten.
Begin met een klein set hoog-signaal notificaties:
Kies 1–2 kanalen voor v1 (meestal in-app + e-mail). Maak een escalatiematrix met duidelijke drempels (T–2h, T–0h, T+1h). Voorkom alert-fatigue met dedupe, batching en quiet hours, en maak acknowledge/snooze auditabel.
Integreer alleen wat nodig is om tijdlijnen accuraat te houden:
Bij tweerichtingssync: definieer per veld een source of truth en conflictregels (vermijd 'last write wins'). Publiceer een minimale, versie-beheerde API-contract zodat integraties niet onverwacht breken. Zie blog/workflow-automation-basics en pricing voor meer context.
due_at