18 mei 2025·8 min
Bouw een webapp om zakelijke aannames in de tijd bij te houden
Leer hoe je een webapp ontwerpt en bouwt die zakelijke aannames vastlegt, bewijs koppelt, wijzigingen over de tijd bijhoudt en teams aanzet tot review en validatie.
Welk probleem lost de app op (en wie gebruikt het)
Een zakelijke aanname is een overtuiging waarop je team handelt voordat die volledig bewezen is. Het kan gaan over:
- Markt: “Dit segment groeit snel genoeg om ons product te ondersteunen.”
- Klant: “Gebruikers stappen over van spreadsheets als de setup minder dan 10 minuten duurt.”
- Prijsstelling: “Teams betalen $49/maand voor deze set features.”
- Operaties: “Support kan onboarding aan met één persoon.”
- Risico's: “Deze aanpak veroorzaakt geen compliance-problemen.”
Deze aannames verschijnen overal—pitch decks, roadmap-discussies, salesgesprekken, gangenpraatjes—en verdwijnen vervolgens stilletjes.
Waarom teams aannames kwijtraken
De meeste teams verliezen aannames niet omdat het ze geen zorg is. Ze verliezen ze omdat documentatie afwijkt, mensen van rol veranderen en kennis tribaal wordt. De “laatste waarheid” eindigt verspreid over een document, een Slack-thread, een paar tickets en iemands geheugen.
Als dat gebeurt, herhalen teams dezelfde debatten, voeren ze dezelfde experimenten opnieuw uit, of nemen ze beslissingen zonder te beseffen wat nog onbewezen is.
Gewenste uitkomsten
Een eenvoudige assumption-tracking app geeft je:
- Duidelijkheid: wat je gelooft, wat bewezen is en wat nog openstaat
- Aansprakelijkheid: wie elke aanname beheert en wanneer die voor het laatst is beoordeeld
- Sneller leren: kortere lussen tussen hypothesen, experimenten en bewijs
- Minder herhaalde discussies: een gedeeld overzicht dat cirkelvormige gesprekken vermindert
Wie het gebruikt (en hoe groot het moet zijn)
Productmanagers, oprichters, growth-teams, onderzoekers en salesleiders profiteren—iedereen die weddenschappen aangaat. Begin met een lichte “assumption log” die eenvoudig actueel te houden is, en breid functies alleen uit als het gebruik erom vraagt.
Definieer het kern-datamodel
Voordat je schermen ontwerpt of een techstack kiest, bepaal wat de “dingen” zijn die je app opslaat. Een duidelijk datamodel houdt het product consistent en maakt rapportage later mogelijk.
Kernobjecten (houd het klein)
Begin met vijf objecten die aansluiten op hoe teams ideeën valideren:
- Assumption: de bewering waarvan je gelooft dat die waar is (tot het tegendeel is bewezen)
- Evidence: links, notities, bestanden of metrics die een aanname ondersteunen of verzwakken
- Experiment: een gestructureerde test (interview, enquête, A/B-test, prototype) die bewijs oplevert
- Review: een periodieke checkpoint waarin iemand de nieuwste status/vertrouwen bevestigt
- Comment: lichte discussie gekoppeld aan een aanname (en optioneel aan evidence/experiments)
Aanbevolen velden voor Assumption
Een Assumption-record moet snel aan te maken zijn, maar rijk genoeg om actiegericht te zijn:
- Statement (vereist): één testbare zin
- Category (vereist): bijv. customer, problem, pricing, channel, feasibility
- Owner (vereist): wie het voortgang geeft
- Confidence (vereist): low/medium/high (of 1–5)
- Status (vereist): draft, active, validated, invalidated, archived
Voeg tijdstempels toe zodat de app review-workflows kan aansturen:
- Created at, Last updated at (systeemgegenereerd)
- Last reviewed at, Next review date (bewerkbaar of afgeleid)
Relaties
Modelleer de validatiestroom:
- One Assumption → many Evidence items
- One Assumption → many Experiments
- One Assumption → many Reviews and Comments
Verplicht vs. optioneel (verminder frictie)
Maak alleen het noodzakelijke verplicht: statement, category, owner, confidence, status. Laat details zoals tags, impact en links optioneel zodat mensen aannames snel kunnen loggen—en ze later verbeteren naarmate bewijs binnenkomt.
Stel status-, confidence- en reviewregels in
Als je assumption-log nuttig wil blijven, heeft elke invoer een duidelijke betekenis in één oogopslag: waar het zich in de levenscyclus bevindt, hoe sterk je erin gelooft en wanneer het opnieuw moet worden gecontroleerd. Deze regels voorkomen ook dat teams stilletjes gissingen als feiten behandelen.
Een eenvoudige, consistente levenscyclus
Gebruik één statusflow voor elke aanname:
Draft → Active → Validated / Invalidated → Archived
- Draft: vastgelegd, maar nog niet overeengekomen als iets dat gevolgd wordt.
- Active: het team is ervan afhankelijk (of kan erop gaan vertrouwen) en heeft de intentie om het te testen of te monitoren.
- Validated: bewijs voldoet aan je minimumstandaard (onder gedefinieerd).
- Invalidated: bewijs spreekt het duidelijk tegen; bewaar het voor leermomenten.
- Archived: niet langer relevant (product veranderde, markt verschoof, strategie aangepast).
Confidence-score (1–5)
Kies een 1–5 schaal en definieer die in gewone taal:
- Speculatie (geen bewijs)
- Zwak signaal (één datapunt)
- Enige ondersteuning (meerdere signalen, nog hiaten)
- Sterke ondersteuning (consistent bewijs, weinig twijfel)
- Zeer sterk (herhaalbare resultaten, stabiel in de tijd)
Maak “confidence” over de sterkte van het bewijs—niet over hoe graag iemand wil dat het waar is.
Besluitimpact: wat eerst valideren
Voeg Decision impact: Low / Medium / High toe. Hoog-impact aannames moeten eerder getest worden omdat ze prijsstelling, positionering, go-to-market of grote bouwbeslissingen bepalen.
Definieer wat “gevalideerd” betekent
Schrijf expliciete criteria per aanname: welk resultaat telt en wat het minimale bewijs is (bijv. 30+ enquête-antwoorden, 10+ salesgesprekken met een consistent patroon, A/B-test met een vooraf bepaalde succesmetric, 3 weken retentiedata).
Herzien en reviewregels
Stel automatische review-triggers in:
- Review High-impact aannames elke 2–4 weken
- Review wanneer kernmetrics verschuiven (conversie, churn, CAC)
- Review na grote product- of marktveranderingen
Dit voorkomt dat “gevalideerd” verandert in “voor altijd waar”.
Ontwerp de gebruikerservaring en sleutel-schermen
Een assumption-tracking app slaagt wanneer het sneller voelt dan een spreadsheet. Ontwerp rond de paar acties die mensen wekelijks herhalen: voeg een aanname toe, werk bij wat je gelooft, voeg toe wat je geleerd hebt en zet de volgende reviewdatum.
Primaire flows (houd ze één-klik)
Streef naar een krappe lus:
- Create assumption: begin vanuit een template (Problem, Customer, Pricing, Channel) met verstandige defaults.
- Update status: verplaats snel tussen Draft → Active → Validated/Invalidated, met een optionele opmerking.
- Attach evidence: sleep een bestand of plak een link, tag het vervolgens aan één of meer aannames.
- Schedule review: stel “next review” direct na een wijziging in, zodat niets veroudert.
Kernschermen die je echt nodig hebt
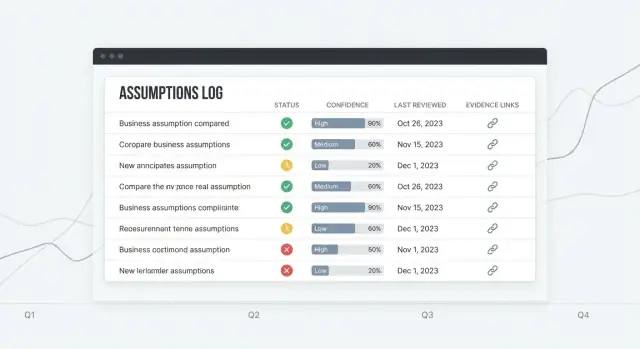
Assumptions-lijst moet de thuisbasis zijn: een leesbare tabel met duidelijke kolommen (Status, Confidence, Owner, Last reviewed, Next review). Voeg een opvallende “Quick add”-rij toe zodat nieuwe items geen volledig formulier vereisen.
Assumption-detail is waar beslissingen genomen worden: een korte samenvatting bovenaan, gevolgd door een tijdlijn van updates (statuswijzigingen, confidence-wijzigingen, commentaren) en een speciaal Evidence-paneel.
Evidentiabibliotheek helpt bij het hergebruiken van leerervaringen: zoek op tag, bron en datum en koppel bewijs aan meerdere aannames.
Dashboard moet antwoord geven op: “Wat heeft aandacht nodig?” Toon aankomende reviews, recent gewijzigde aannames en hoog-impact items met laag vertrouwen.
Filteren, zoeken en rommelbeheersing
Maak filters persistent en snel: category, owner, status, confidence, last reviewed date. Verminder rommel met templates, standaardwaarden en progressieve onthulling (geavanceerde velden verborgen totdat ze nodig zijn).
Toegankelijkheidsbasisregels
Gebruik tekst met hoog contrast, duidelijke labels en toetsenbordvriendelijke bediening. Tabellen moeten rij-focus ondersteunen, sorteerbare headers en leesbare tussenruimte—vooral voor status- en confidence-badges.
Kies een praktische tech stack
Een assumptions-tracking app bestaat vooral uit formulieren, filtering, zoeken en een audittrail. Dat is goed nieuws: je kunt waarde leveren met een eenvoudige, degelijke stack en je energie besteden aan de workflow (reviewregels, bewijs, beslissingen) in plaats van infrastructuur.
Een eenvoudige stack die werkt
Een gangbare, praktische opzet is:
- Frontend: React, vaak via Next.js (snelle UI, routing, server rendering waar nuttig)
- Backend: Node.js (Express/Nest) of Python (FastAPI/Django)
- Database: Postgres
Als je team al één van deze kent, kies die—consistentie wint van nieuwigheid.
Als je snel wilt prototypen zonder alles handmatig te koppelen, kan een low-code/vice platform zoals Koder.ai je snel naar een werkend intern hulpmiddel brengen: beschrijf je datamodel en schermen in de chat, iteratieer in Planning Mode, en genereer een React-UI met een productieklare backend (Go + PostgreSQL) die je later als broncode kunt exporteren als je besluit het zelf te onderhouden.
Waarom Postgres een goede keuze is
Postgres verwerkt de “verbonden” aard van assumption-management goed: aannames horen bij workspaces, hebben owners, koppelen aan bewijs en relateren aan experimenten. Een relationele database houdt deze koppelingen betrouwbaar.
Het is ook index-vriendelijk voor de queries die je vaak draait (op status, confidence, due-for-review, tag, owner), en audit-vriendelijk als je versiegeschiedenis en wijzigingslogs toevoegt. Je kunt wijzigingsgebeurtenissen in een aparte tabel opslaan en ze doorzoekbaar houden voor rapportage.
Houd hosting en ops licht
Streef naar managed services:
- Managed Postgres (automatische backups, upgrades, read replicas later)
- App hosting voor Next.js en je API (of een enkele full-stack Next.js-app)
Dit vermindert het risico dat “het draaiende houden” je week opeet.
Als je de infra in het begin niet zelf wilt runnen, kan Koder.ai ook deployment en hosting verzorgen, plus gemakken als custom domains en snapshots/rollback terwijl je workflows met echte gebruikers verfijnt.
API-aanpak: eerst REST
Begin met REST endpoints voor CRUD, zoeken en activiteitfeeds. Het is makkelijk te debuggen en documenteren. Overweeg GraphQL alleen als je echt complexe, client-gedreven queries nodig hebt over vele gerelateerde objecten.
Gebruik duidelijke omgevingen
Plan vanaf dag één voor drie omgevingen:
- Local (ontwikkelaarsmachines)
- Staging (veilige plek om imports, notificaties en permissies te testen)
- Production (echte data, strengere toegang, monitoring)
Deze opzet ondersteunt business-assumption-tracking zonder je assumption-log webapp te overengineeren.
Implementeer authenticatie, rollen en workspaces
Maak geschiedenis gemakkelijk navolgbaar
Voeg vanaf het begin audit-vriendelijke tijdlijnen en wijzigingslogboeken toe, zonder alles handmatig te koppelen.
Als je assumption-log gedeeld wordt, moet toegangscontrole saai en voorspelbaar zijn. Mensen moeten exact weten wie kan zien, bewerken of goedkeuren—zonder het team te vertragen.
Authenticatie: begin simpel, voeg SSO toe wanneer nodig
Voor de meeste teams is e-mail + wachtwoord genoeg om te lanceren en te leren. Voeg Google of Microsoft SSO toe wanneer je grotere organisaties, strikte IT-beleid of veel onboarding/offboarding verwacht. Als je beide ondersteunt, laat admins kiezen per workspace.
Houd de login-ervaring minimaal: registratie, inloggen, wachtwoordherstel en (optioneel) afgedwongen MFA later.
Rollen en permissies (Admin / Editor / Viewer)
Definieer rollen één keer en maak ze consistent door de app heen:
- Admin: beheert workspace-instellingen, leden, rollen en integraties; kan records verwijderen (of verwijderverzoeken indienen).
- Editor: maakt en bewerkt aannames, koppelt bewijs, logt experimenten en verandert status/confidence.
- Viewer: read-only toegang tot aannames, bewijs, experimentresultaten en dashboards.
Voer permissiecontroles server-side uit (niet alleen in de UI). Als je later “goedkeuring” toevoegt, behandel het als een permissie, niet als een nieuwe rol.
Workspaces: scheid teams, producten en klanten
Een workspace is de grens voor data en membership. Elke aanname, evidence-item en experiment behoort tot precies één workspace, zodat agencies, multi-product bedrijven of startups met meerdere initiatieven georganiseerd blijven en per ongeluk delen voorkomen.
Uitnodigingen, offboarding en minimale audit
Gebruik e-mailgebaseerde uitnodigingen met een vervalvenster. Bij offboarding verwijder toegang maar behoud de geschiedenis: eerdere bewerkingen moeten nog steeds de oorspronkelijke actor tonen.
Sla minimaal een audit trail op: wie wat en wanneer veranderde (user ID, timestamp, object en actie). Dit ondersteunt vertrouwen, verantwoordelijkheid en makkelijker debuggen wanneer beslissingen later ter discussie staan.
Bouw CRUD met versiegeschiedenis en wijzigingslogs
CRUD is waar je assumption-log webapp ophoudt een document te zijn en begint een systeem te worden. Het doel is niet alleen aannames aanmaken en bewerken—het is om elke wijziging begrijpelijk en omkeerbaar te maken.
CRUD-endpoints en UI-acties
Ondersteun minimaal deze acties voor aannames en bewijsstukken:
- Maak, bekijk, bewerk, archiveer (soft-delete) en herstel aannames
- Koppel evidence-items (links, bestanden, notities) en bewerk hun metadata
- Verander status (bijv. Draft → Active → Validated/Invalidated)
In de UI houd je deze acties dichtbij de assumption-detailpagina: een duidelijke “Edit”, een speciale “Change status” en een “Archive”-actie die expres lastiger te klikken is.
Versiebeheer: revisies vs. append-only logs
Je hebt twee praktische strategieën:
-
Sla volledige revisies op (een snapshot per opslaan). Dit maakt “herstel vorige” eenvoudig.
-
Append-only wijzigingslog (event stream). Elke wijziging schrijft een event zoals “statement changed”, “confidence changed”, “evidence attached.” Dit is ideaal voor auditing maar vraagt meer werk om oudere staten opnieuw op te bouwen.
Veel teams doen een hybride: snapshots voor grote bewerkingen + events voor kleine acties.
Maak geschiedenis leesbaar (niet alleen opgeslagen)
Voorzie een tijdlijn op elke aanname:
- Wie wat wanneer wijzigde
- Een diff-weergave voor tekstvelden (statement, hypothesis, success criteria)
- Een Restore previous-knop op eerdere versies (met bevestiging)
Context: commentaren en besluitnotities
Vereis een korte “waarom”-notitie bij betekenisvolle bewerkingen (status/confidence-wijzigingen, archiveren). Behandel het als een lichtgewicht besluitlog: wat veranderde, welk bewijs het veroorzaakte en wat je hierna doet.
Voorkom per ongeluk bewerken
Voeg bevestigingen toe voor destructieve acties:
- Statuswijzigingen die een aanname sluiten
- Archiveren
- Herstellen van een oude versie (waarschuw dat dit een nieuwe revisie maakt)
Dit houdt je versiegeschiedenis betrouwbaar—ook als mensen snel werken.
Koppel bewijs en volg experimenten
Aannames worden gevaarlijk wanneer ze “waar” klinken maar nergens naar te verwijzen is. Je app moet teams in staat stellen bewijs te koppelen en lichte experimenten te draaien zodat elke bewering een spoor heeft.
Evidence: wat op te slaan (zonder rommel)
Ondersteun veelvoorkomende bewijs-types: interviewnotities, enquête-resultaten, product- of omzetmetrics, documenten (PDFs, presentaties) en simpele links (bijv. analytics-dashboards, supporttickets).
Als iemand bewijs toevoegt, leg dan een klein aantal metadata vast zodat het maanden later bruikbaar blijft:
- Source (klantnaam, dataset, tool of interne documenteigenaar)
- Date collected (en optioneel datum geüpload)
- Method (interview, usability test, A/B-test, desk research, enz.)
- Quality / strength rating (meer hierover hieronder)
Om dubbele uploads te vermijden, modelleer evidence als een apart entiteit en koppel het many-to-many: één interviewnotitie kan drie aannames ondersteunen, en één aanname kan tien bewijsstukken hebben. Sla het bestand één keer op (of alleen een link), en relateren het waar nodig.
Experiment-tracking: maak van “we moeten dit testen” een record
Voeg een “Experiment”-object toe dat makkelijk in te vullen is:
- Hypothesis (wat je verwacht en waarom)
- Method (wat je gaat doen)
- Key metric (het getal dat je volgt)
- Result (wat er gebeurde)
- Conclusion (behoud, wijzig of laat los de aanname)
Koppel experimenten aan de aannames die ze testen, en koppel optioneel automatisch gegenereerd bewijs (grafieken, notities, metric-snapshots).
Bewijssterkte: richtlijnen die valse zekerheid voorkomen
Gebruik een eenvoudige rubric (bijv. Weak / Moderate / Strong) met tooltips:
- Weak: meningen, enkele anekdote, ongeverifieerde link
- Moderate: meerdere interviews, consistent enquête-signaal, vroege metric-trend
- Strong: herhaalde resultaten over segmenten, duidelijke metric-impact, gecontroleerd experiment
Het doel is geen perfectie—maar om vertrouwen expliciet te maken zodat beslissingen niet op intuïtie leunen.
Voeg herinneringen en review-workflows toe
Vervang de spreadsheet-lus
Zet je templates en filters om in een bruikbare app die beter is dan een spreadsheet voor wekelijkse updates.
Aannames worden stilletjes verouderd. Een eenvoudige review-workflow houdt je log nuttig door “dit moeten we herbekijken” in een voorspelbare gewoonte te veranderen.
Stel een review-cadans in die past bij risico
Koppel reviewfrequentie aan impact en confidence zodat je niet elke aanname hetzelfde behandelt.
- Wekelijks: hoog impact + laag vertrouwen (bijv. kernprijsstelling, hoofdacquisitiekanaal)
- Maandelijks: hoog impact + gemiddeld vertrouwen, of medium impact + laag vertrouwen
- Kwartaalsgewijs (optioneel): laag impact + hoog vertrouwen
Sla de volgende reviewdatum op in de aanname en herbereken deze automatisch wanneer impact/confidence verandert.
Herinneringen zonder spam te worden
Ondersteun zowel e-mail als in-app notificaties. Houd standaardinstellingen conservatief: één herinnering bij achterstand, daarna een vriendelijke opvolging.
Maak notificaties configureerbaar per gebruiker en workspace:
- kanaalvoorkeuren (email/in-app)
- herinnerfrequentie (dagelijks/wekelijks)
- stille uren / tijdzone
- opt-out voor low-impact items
Digest-weergaven die tot actie aanzetten
In plaats van mensen een lange lijst te sturen, maak gefocuste digests:
- Needs review (overdue of binnenkort)
- High impact + low confidence (hoogste risico)
- Recent changes (aannames bewerkt, confidence gedaald, bewijs verwijderd)
Deze moeten eersteklas filters in de UI zijn zodat dezelfde logica zowel dashboard als notificaties aanstuurt.
Eenvoudige escalatieregels
Escalatie moet voorspelbaar en licht zijn:
- Informeer de owner wanneer iets achterstallig is.
- Als het na X dagen nog achterstallig is, informeer de team lead (of workspace-admin).
Log elke herinnering en escalatie in de activiteitengeschiedenis van de aanname zodat teams kunnen zien wat er wanneer gebeurde.
Maak dashboards en rapportage
Dashboards maken je assumption-log tot iets dat teams daadwerkelijk raadplegen. Het doel is niet fancy analytics—maar snelle zichtbaarheid in wat risicovol, wat verouderd is en wat verandert.
Dashboard-KPI's die antwoord geven op “Zijn we veilig?”
Begin met een kleine set tegels die automatisch bijwerken:
- Assumptions per status (Draft, Active, Validated, Invalidated, Archived)
- Confidence-distributie (hoeveel zijn 1–5, of Low/Medium/High)
- Achterstallige reviews (aantal + directe link naar de achterstallijst)
Koppel elke KPI aan een doorklik-weergave zodat mensen kunnen handelen, niet alleen observeren.
Trendgrafieken (nuttig, maar eerlijk)
Een eenvoudige lijngrafiek met validations vs. invalidations over time helpt teams zien of leren versnelt of stagneert. Houd de communicatie voorzichtig:
- Behandel trends als signalementen, geen bewijs van prestatie.
- Toon de steekproefgrootte (bijv. “8 outcomes deze maand”) zodat één week geen doorbraak lijkt.
Opgeslagen weergaven voor verschillende stakeholders
Verschillende rollen stellen andere vragen. Bied opgeslagen filters zoals:
- Product: aannames gekoppeld aan actieve discovery, gegroepeerd per productgebied
- Sales/CS: aannames over prijsstelling, bezwaren, doelsegmenten
- Leadership: hoogste impact items, top-risico's, review-gezondheid
Opgeslagen weergaven moeten deelbaar zijn via een stabiele URL (bijv. /assumptions?view=leadership-risk).
Risico benadrukken: hoog impact + zwak bewijs
Maak een “Risk Radar”-tabel die items toont waar Impact High maar evidence strength Low (of confidence low) is. Dit wordt je agenda voor planning en pre-mortems.
Exporteerbare samenvattingen voor vergaderingen
Maak rapportage draagbaar:
- Eén-klik export naar PDF/CSV
- Een “Weekly Assumption Summary” die topwijzigingen, nieuwe invalidations en achterstallige reviews opsomt
Dit houdt de app relevant in planning zonder iedereen te dwingen tijdens de meeting in te loggen.
Ondersteun imports, exports en integraties
Prototypeer kernschermen
Prototypeer de kernschermen — lijst, detail, evidentiabibliotheek en dashboard — op één plek.
Een tracking-app werkt alleen als het past bij hoe teams al werken. Imports en exports helpen snel te beginnen en eigenaarschap van data te behouden, terwijl lichte integraties handmatig kopiëren verminderen—zonder je MVP te veranderen in een integratieplatform.
Exports die mensen echt gebruiken
Begin met CSV-export voor drie tabellen: assumptions, evidence/experiments en change logs. Houd de kolommen voorspelbaar (IDs, statement, status, confidence, tags, owner, last reviewed, timestamps).
Voeg kleine UX-details toe:
- Exporteer huidige weergave (filters toegepast) en volledige workspace
- Laat gebruikers kiezen of gearchiveerde items worden meegenomen
- Voeg een stabiele Assumption ID toe zodat spreadsheets later samengevoegd kunnen worden
Importeren vanuit spreadsheets (zonder pijn)
De meeste teams beginnen met een rommelige Google Sheet. Bied een importflow die ondersteunt:
- Upload CSV
- Kolomtoewijzing (bijv. “Hypothesis” → Statement, “Risk” → Impact)
- Validatie met duidelijke fouten (ontbrekende verplichte velden, onbekende statussen, ongeldige datums)
- Een preview die toont hoeveel aannames worden aangemaakt vs. bijgewerkt
Behandel import als een eersteklas feature: het is vaak de snelste manier om adoptie te krijgen. Documenteer het verwachte formaat en regels in /help/assumptions.
Optionele integraties: simpel, niet eindeloos
Houd integraties optioneel zodat de kernapp simpel blijft. Twee praktische patronen:
- Webhooks: stuur events zoals
assumption.created,status.changed,review.overdue. - Link-out references: bewaar URL's voor Jira-tickets, Notion-documenten of onderzoeksfolders als “Related links” op een aanname.
Voor directe waarde, bied een basis Slack-alert integratie (via webhook-URL) die post wanneer een hoog-impact aanname van status verandert of wanneer reviews achterstallig zijn. Dit geeft teams awareness zonder ze van tool te laten wisselen.
Behandel basisprincipes van beveiliging, privacy en gegevensbescherming
Beveiliging en privacy zijn productfeatures voor een assumption-log. Mensen plakken links, notities van gesprekken en interne beslissingen—ontwerp dus standaard voor “veilig”, zelfs in een vroege versie.
Basisgegevensbescherming
Gebruik TLS overal (alleen HTTPS). Redirect HTTP naar HTTPS en stel veilige cookies in (HttpOnly, Secure, SameSite).
Sla wachtwoorden op met een modern hashalgoritme zoals Argon2id (voorkeur) of bcrypt met een sterke cost-factor. Sla nooit plaintext-wachtwoorden op en log geen authenticatietokens.
Pas het principe van least-privilege toe doorheen het systeem:
- Scheid rollen (admin, editor, viewer) en controleer permissies bij elke schrijfactie.
- Gebruik gescopeerde API-sleutels voor integraties en laat gebruikers ze intrekken.
- Beperk database-credentials zodat de app geen tabellen kan bereiken die niet nodig zijn.
Row-level toegangsregels (workspaces)
De meeste datalekken in multi-tenant apps zijn autorisatiefouten. Maak workspace-isolatie een hoofdregel:
- Elk record (assumption, evidence, experiment, comment) moet
workspace_idbevatten. - Handhaaf toegang op databaseniveau met row-level security (RLS) of gelijkwaardige policies, niet alleen in applicatiecode.
- Maak in tests twee workspaces en verifieer dat een gebruiker uit workspace A niet kan lezen, zoeken, exporteren of IDs raden van workspace B.
Backups en retentie (wat je implementeert)
Definieer een eenvoudig plan dat je kunt uitvoeren:
- Geautomatiseerde dagelijkse databasebackups opgeslagen op een aparte locatie.
- Een retentiebeleid (bijv.: bewaar 30 dagen aan dagelijkse backups en 12 maanden aan maandelijkse backups).
- Een kwartaallijkse restore-oefening: herstel naar staging en valideer kernflows.
Logging en omgaan met gevoelige data
Wees selectief in wat je opslaat. Vermijd het plaatsen van geheimen in evidence-notities (API-sleutels, wachtwoorden, privélinks). Als gebruikers die toch plakken, toon waarschuwingen en overweeg automatische redactie voor veelvoorkomende patronen.
Houd logs minimaal: log niet volledige request bodies voor endpoints die notities of bijlagen accepteren. Als je diagnostiek nodig hebt, log metadata (workspace ID, record ID, foutcodes) in plaats daarvan.
Privacy bij het opslaan van interviewnotities
Interviewnotities kunnen persoonlijke gegevens bevatten. Bied de mogelijkheid om:
- Velden te markeren als “bevat persoonlijke gegevens” en te beperken wie ze kan bekijken.
- Notities te verwijderen of te anonimiseren op verzoek.
- Kort te documenteren wat je opslaat en waarom in een privacy-opmerking (vermeld vanaf
/settingsof/help).
Lanceer, monitor en plan de volgende iteratie
Een assumption-app uitbrengen gaat minder over “klaar” en meer over het veilig in echte workflows brengen en vervolgens leren van gebruik.
Een praktisch deployment-checklist
Voer, voordat je gebruikers uitnodigt, een beknopte checklist uit:
- Voer database-migraties uit (en verifieer dat ze omkeerbaar zijn).
- Laad seed-data (statussen, confidence-levels, review-cadansen).
- Maak het eerste admin-account en een default workspace aan.
- Bevestig e-mail-/notificatie-instellingen voor review-herinneringen.
- Schakel basisbackups in en verifieer herstel één keer.
Als je een staging-omgeving hebt, oefen de release daar eerst—vooral alles dat versiegeschiedenis en wijzigingslogs raakt.
Monitor fouten en performance (lichtgewicht)
Begin eenvoudig: je wilt zichtbaarheid zonder weken aan setup.
Gebruik een error-tracker (bijv. Sentry/Rollbar) om crashes, mislukte API-calls en achtergrondjob-fouten te vangen. Voeg basis performance-monitoring (APM of servermetrics) toe om trage pagina's zoals dashboards en rapporten te signaleren.
Tests die kernregels beschermen
Richt tests op plekken waar fouten zwaar wegen:
- Unit-tests voor status-transities, confidence-regels en review-scheduling.
- Integratietests voor de hoofdflows: create assumption → attach evidence → log experiment → change status → zie audit trail.
Onboarding die de app “klik” maakt
Voorzie templates en voorbeeldaannames zodat nieuwe gebruikers niet tegen een leeg scherm aankijken. Een korte guided tour (3–5 stappen) moet de volgende punten belichten: waar bewijs toe te voegen, hoe reviews werken en hoe je het besluitlog leest.
Plan de volgende iteratie
Na lancering prioriteer je verbeteringen op basis van echt gedrag:
- Scoringmodellen (impact × onzekerheid, of aangepaste confidence-formules).
- Goedkeuringsflows voor high-risk wijzigingen.
- Optionele AI-geassisteerde samenvattingen van bewijs en experimentresultaten.
Als je snel iterereert, overweeg tooling die de doorlooptijd van “we moeten deze workflow toevoegen” naar “het staat live” verkort. Teams gebruiken vaak Koder.ai om nieuwe schermen en backend-wijzigingen vanuit een chatbrief te ontwerpen, en vertrouwen op snapshots en rollback om experimenten veilig te lanceren—en exporteren de code zodra de productrichting duidelijk is.
Veelgestelde vragen
Wat is een zakelijke aanname in de context van een assumption-tracking app?
Noteer één testbare veronderstelling waarop je team handelt voordat die volledig bewezen is (bijv. marktvraag, betalingsbereidheid, onboarding-haalbaarheid). Het doel is om het expliciet, toegewezen en herzienbaar te maken, zodat gissingen niet stilletjes ‘feiten’ worden.
Waarom verliezen teams het overzicht over aannames (en hoe helpt een app)?
Omdat aannames verspreid raken over documenten, tickets en chat en vervolgens verschuiven als mensen van rol veranderen. Een speciale log centraliseert de “laatste waarheid”, voorkomt herhaalde debatten/experimenten en maakt zichtbaar wat nog niet bewezen is.
Wie zou een assumption-tracking app moeten gebruiken en hoe omvangrijk moet de MVP zijn?
Begin met een lichte “assumption log” die wekelijks wordt gebruikt door product, oprichters, growth, onderzoek of sales-leiders.
Houd de MVP klein:
- Leg aannames snel vast
- Koppel bewijs/experimenten
- Plan reviews
- Toon wat aandacht nodig heeft (dashboard)
Breid alleen uit wanneer echt gebruik daartoe aanleiding geeft.
Welk kern-datamodel moet ik eerst implementeren?
Een praktisch kernmodel bevat vijf objecten:
- Assumption (de bewering)
- Evidence (links/bestanden/notities/metrics)
- Experiment (gestructureerde test die bewijs oplevert)
- Review (periodieke checkpoint)
- Comment (lichte discussie)
Welke velden moeten verplicht vs. optioneel zijn op een Assumption?
Vereis alleen wat een aanname actiegericht maakt:
- Statement, Category, Owner, Confidence, Status
Maak de rest optioneel (tags, impact, links) om wrijving te verminderen. Voeg tijdstempels toe zoals en om herinneringen en workflow aan te sturen.
Hoe definieer ik status, vertrouwen en impact zodat het team ze consequent gebruikt?
Gebruik één consistente flow en definieer die duidelijk:
- Draft → Active → Validated / Invalidated / Archived
Koppel dit aan een confidence-schaal (bijv. 1–5) gebaseerd op bewijssterkte, niet op wensdenken. Voeg Decision impact (Low/Medium/High) toe om te prioriteren wat eerst getest moet worden.
Wat betekent “gevalideerd” en hoe stellen we bewijscriteria op?
Schrijf per aanname expliciete validatiecriteria voordat je test.
Voorbeelden van minimaal bewijs:
- 30+ enquête-antwoorden met een consistent signaal
- 10+ salesgesprekken die hetzelfde patroon tonen
- Een A/B-test met een vooraf bepaalde succesmetric
- retentiedata die aan de doelwaarde voldoen
Welke schermen en gebruikersstromen zijn essentieel voor een eerste versie?
Inclusief:
- Assumptions-lijst (tabel + quick add)
- Assumption-detail (samenvatting + tijdlijn + bewijspanel)
- Evidentiabibliotheek (doorzoekbaar, herbruikbaar)
- Dashboard (te beoordelen items, hoog-impact/laag-vertrouwen)
Optimaliseer voor wekelijkse acties: toevoegen, status/vertrouwen bijwerken, bewijs koppelen, volgende review plannen.
Welke tech stack is praktisch voor dit soort app?
Gebruik een betrouwbare, eenvoudige stack:
- Frontend: React / Next.js
- Backend: Node.js (Express/Nest) of Python (FastAPI/Django)
- DB: Postgres
Postgres past goed bij relationele links (assumptions ↔ evidence/experiments) en ondersteunt audit trails en geindexeerde queries. Begin met REST voor CRUD en activity feeds.
Hoe moet ik authenticatie, rollen en workspace-beveiliging behandelen?
Implementeer de basis vroeg:
- Auth: e-mail/wachtwoord eerst; voeg Google/Microsoft SSO later toe
- Rollen: Admin / Editor / Viewer met server-side checks
- Workspaces: strikte databoundary (elk record heeft
workspace_id) - Audit trail: wie wat veranderde en wanneer