13 mei 2025·8 min
Bouw een webapp om productadoptie per accountniveau te volgen
Leer hoe je data, events en dashboards ontwerpt om productadoptie per accounttier te meten, en hoe je op inzichten reageert met meldingen en automatisering.
Leer hoe je data, events en dashboards ontwerpt om productadoptie per accounttier te meten, en hoe je op inzichten reageert met meldingen en automatisering.
Voordat je dashboards bouwt of events instrumenteert, wees duidelijk over waar de app voor is, wie hem gebruikt en hoe accounttiers gedefinieerd zijn. De meeste “adoptietracking”-projecten mislukken omdat ze bij data beginnen en eindigen met meningsverschillen.
Een praktische regel: als twee teams “adoptie” niet in één zin hetzelfde kunnen definiëren, zullen ze later het dashboard niet vertrouwen.
Noem de primaire doelgroepen en wat ieder moet doen nadat ze de data gezien hebben:
Een nuttige lakmoesproef: elk publiek moet binnen één minuut het antwoord op “en nu?” kunnen geven.
Adoptie is geen enkele metric. Schrijf een definitie waar je team het over eens kan zijn—meestal als een reeks:
Houd het gegrond in klantwaarde: welke acties signaleren dat klanten werkelijk resultaat behalen en niet enkel aan het verkennen zijn.
Noem je tiers en maak toewijzing deterministisch. Veelvoorkomende tiers zijn SMB / Mid-Market / Enterprise, Free / Trial / Paid, of Bronze / Silver / Gold.
Documenteer de regels in gewone taal (en later in code):
Schrijf de beslissingen op die de app moet mogelijk maken. Bijvoorbeeld:
Gebruik deze als acceptatiecriteria:
Accounttiers gedragen zich verschillend, dus één enkele “adoptie”-metric zal kleine klanten bestraffen of risico bij grote klanten verbergen. Begin met definiëren wat succes per tier is, en kies dan metrics die die realiteit reflecteren.
Kies één primair resultaat dat echte waarde aangeeft:
Je north-star moet telbaar zijn, per tier segmenteerbaar en moeilijk te manipuleren.
Schrijf je adoptiefunnel als stappen met expliciete regels—zodat een dashboardantwoord niet afhangt van interpretatie.
Voorbeeldstadia:
Tier-verschillen zijn belangrijk: enterprise-“Activated” kan zowel een admin-actie en minimaal één eindgebruikeractie vereisen.
Gebruik leading indicators om vroege momentum te spotten:
Gebruik lagging indicators om duurzame adoptie te bevestigen:
Targets moeten rekening houden met verwachte time-to-value en organisatorische complexiteit. Bijvoorbeeld: SMB kan targeten op activatie binnen 7 dagen; enterprise kan targeten op integratie binnen 30–60 dagen.
Schrijf targets op zodat alerts en scorecards consistent blijven over teams heen.
Een duidelijk datamodel voorkomt “mysterie-wiskunde” later. Je wilt eenvoudige vragen kunnen beantwoorden—wie gebruikte wat, in welk account, onder welke tier, op dat moment—zonder ad-hoc logica in elk dashboard.
Begin met een klein setje entiteiten die matchen hoe klanten daadwerkelijk kopen en gebruiken:
account_id), naam, status en lifecycle-velden (created_at, churned_at).user_id, email-domein (handig voor matching), created_at, last_seen_at.workspace_id en een foreign key naar account_id.Wees expliciet over het analytics-“grain”:
Een praktisch uitgangspunt is events op user-niveau te tracken (met account_id eraan gekoppeld), en daarna te aggregeren naar account-niveau. Vermijd account-only events tenzij er geen user bestaat (bv. systeemimports).
Events vertellen je wat er gebeurde; snapshots vertellen je wat waar was.
Schrijf niet over de “huidige tier” en verlies context. Maak een account_tier_history-tabel:
account_id, tier_idvalid_from, valid_to (nullable voor de huidige)source (billing, sales override)Zo kun je adoptie berekenen terwijl het account Team was, ook al is het later geüpgraded.
Schrijf definities één keer en behandel ze als productvereisten: wat telt als “actieve gebruiker”, hoe attribueer je events aan accounts en hoe ga je om met tier-wijzigingen halverwege een maand. Dit voorkomt dat twee dashboards twee verschillende waarheden tonen.
Je adoptieanalytics is zo goed als de events die je verzamelt. Begin met het in kaart brengen van een klein setje “critical path” acties die echte progressie voor elk accounttier aangeven, en instrumenteer die consistent over web, mobiel en backend.
Focus op events die betekenisvolle stappen representeren—niet elke klik. Een praktisch startersetje:
signup_completed (account aangemaakt)user_invited en invite_accepted (teamgroei)first_value_received (jouw “aha”-moment; definieer expliciet)key_feature_used (herhaalbare waardeactie; kan meerdere events per feature zijn)integration_connected (als integraties stickiness drijven)Elk event moet genoeg context bevatten om te slicen op tier en rol:
account_id (vereist)user_id (vereist wanneer een persoon betrokken is)tier (vastgelegd op eventtijd)plan (billingplan/SKU indien relevant)role (bijv. owner/admin/member)workspace_id, feature_name, source (web/mobile/api), timestampGebruik een voorspelbaar schema zodat dashboards geen woordenboekproject worden:
snake_case werkwoorden, verleden tijd (report_exported, dashboard_shared)account_id, niet acctId)invoice_sent) óf één event met feature_name; kies één benadering en hou je eraan.Ondersteun zowel anonieme als geauthenticeerde activiteit:
anonymous_id toe bij het eerste bezoek, link daarna aan user_id bij login.workspace_id en map dit server-side naar account_id om client-bugs te vermijden.Instrumenteer systeemacties op de backend zodat kernmetrics niet van browsers of adblockers afhangen. Voorbeelden: subscription_started, payment_failed, seat_limit_reached, audit_log_exported.
Deze server-side events zijn ook ideale triggers voor meldingen en workflows.
Hier wordt tracking een systeem: events komen uit je app, worden opgeschoond, veilig opgeslagen en omgezet in metrics die je team daadwerkelijk kan gebruiken.
De meeste teams gebruiken een mix:
Wat je ook kiest, behandel ingestie als een contract: als een event niet geïnterpreteerd kan worden, moet het in quarantaine geplaatst worden—niet stilletjes geaccepteerd.
Standaardiseer bij ingestie de velden die downstream rapportage betrouwbaar maken:
account_id, user_id en (indien nodig) workspace_id.event_name, tier, plan, feature_key) en voeg defaults alleen toe wanneer expliciet.Bepaal waar raw events blijven op basis van kosten en querypatronen:
Bouw dagelijkse/uurelijkse aggregatiejobs die tabellen produceren zoals:
Houd rollups deterministisch zodat je ze opnieuw kunt draaien wanneer tier-definities of backfills veranderen.
Stel duidelijke retenties in voor:
Een adoptiescore geeft drukbezette teams één nummer om te monitoren, maar het werkt alleen als het simpel en uitlegbaar blijft. Streef naar een 0–100 score die zinvol gedrag reflecteert (geen vanity-activiteiten) en op te delen is in “waarom dit veranderde”.
Begin met een gewogen checklist van gedragingen, gecapped op 100 punten. Houd gewichten stabiel voor een kwartaal zodat trends vergelijkbaar blijven.
Voorbeeldweging (pas aan naar je product):
Elk gedrag moet aan een duidelijke eventregel gekoppeld zijn (bv. “gebruikte core feature” = core_action op 3 losse dagen). Wanneer de score verandert, sla bijdragende factoren op zodat je kunt laten zien: “+15 omdat je 2 gebruikers uitnodigde” of “-10 omdat kerngebruik onder 3 dagen zakte.”
Bereken de score per account (dagelijks of wekelijks snapshot), en aggregeer vervolgens per tier met distributies, niet alleen gemiddelden:
Houd wekelijkse verandering en 30-dagen verandering per tier bij, maar vermijd het mengen van tier-groottes:
Dit maakt kleine tiers leesbaar zonder dat grote tiers het verhaal domineren.
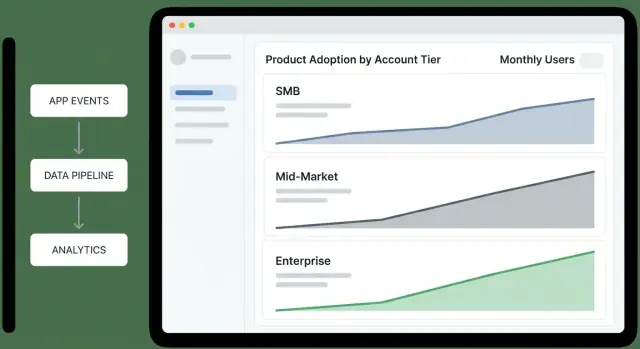
Een tier-overzichtsdashboard moet een exec in onder één minuut het antwoord laten krijgen: “Welke tiers verbeteren, welke verslechteren, en waarom?” Zie het als een beslisscherm, niet als een rapportage-scrapbook.
Tier funnel (Awareness → Activation → Habit): “Waar blijven accounts steken per tier?” Houd de stappen consistent met je product (bv. “Uitgenodigde gebruikers” → “Eerste sleutelactie voltooid” → “Wekelijks actief”).
Activatiegraad per tier: “Bereiken nieuwe of heractiveerde accounts eerste waarde?” Geef een rate samen met de noemer (accounts die in aanmerking komen) zodat leiders signaal onderscheiden van kleine-sample ruis.
Retentie per tier (bv. 7/28/90-dagen): “Blijven accounts gebruiken na de eerste winst?” Toon een simpele lijn per tier; vermijd over-segmentatie op het overzicht.
Diepte van gebruik (feature-breedte): “Adopteren ze meerdere productgebieden of blijven ze oppervlakkig?” Een gestapelde balk per tier werkt goed: % dat 1 gebied gebruikt, 2–3 gebieden, 4+ gebieden.
Voeg twee vergelijkingen overal toe:
Gebruik consistente delta’s (absolute percentagepunt-veranderingen) zodat execs snel kunnen scannen.
Beperk filters, maak ze globaal en sticky:
Als een filter de metricdefinitie zou veranderen, bied het dan niet op het overzicht—duw het naar drill-down views.
Voeg een klein paneel per tier toe: “Wat is in deze periode het meest geassocieerd met hogere adoptie?” Voorbeelden:
Houd het uitlegbaar: geef de voorkeur aan “Accounts die X binnen de eerste 3 dagen instelden behouden 18pp beter” boven ondoorzichtige modeloutputs.
Plaats Tier KPI-cards bovenaan (activatie, retentie, diepte), één scherm met trendcharts in het midden, en drivers + volgende acties onderaan. Elke widget moet één vraag beantwoorden—anders hoort hij niet op de executive summary.
Een tier-dashboard is fijn voor prioritering, maar het echte werk gebeurt als je kunt doorklikken naar waarom een tier bewoog en wie aandacht nodig heeft. Ontwerp drill-downs als een begeleide route: tier → segment → account → gebruiker.
Begin met een tier-overzichtstabel en laat gebruikers het opsplitsen in zinvolle segmenten zonder custom rapporten te hoeven bouwen. Veelgebruikte segmentfilters:
Elke segmentpagina moet beantwoorden: “Welke accounts drijven deze tier’s adoptiescore omhoog of omlaag?” Voeg een geranglijst toe van accounts met scoreverandering en topbijdragende features.
Je accountprofiel moet aanvoelen als een dossier:
Houd het scanbaar: toon deltas (“+12 deze week”) en annoteer pieken met het feature/event dat ze veroorzaakte.
Vanaf de accountpagina: lijst gebruikers op recente activiteit en rol. Klik op een gebruiker om hun featuregebruik en last-seen-context te zien.
Voeg cohort-views toe om patronen te verklaren: aanmeldmaand, onboardingprogramma en tier bij aanmelding. Dit helpt CS vergelijkbaar-met-vergelijkbaar te vergelijken in plaats van nieuwe accounts met volwassen accounts te mixen.
Voeg een “Wie gebruikt wat”-view per tier toe: adoptiegraad, frequentie en trendende features, met een doorkliklijst van accounts die een feature wel of niet gebruiken.
Voor CS en Sales: voeg export/share opties toe: CSV-export, opgeslagen views en deelbare interne paden zoals /accounts/{id} die openen met filters toegepast.
Dashboards zijn goed om adoptie te begrijpen, maar teams handelen wanneer ze op het juiste moment een duwtje krijgen. Meldingen moeten gekoppeld zijn aan accounttier zodat CS en Sales niet overspoeld worden met laagwaarde-noise—or erger, kritieke issues bij je meest waardevolle accounts missen.
Begin met een klein setje “er is iets mis” signalen:
Maak deze signalen tier-aware. Bijv. Enterprise kan alerten bij een 15% week-op-week daling in een core workflow, terwijl SMB mogelijk 40% vereist om churn-noise te vermijden.
Uitbreidingsalerts moeten accounts highlighten die in meer waarde groeien:
Wederom verschillen thresholds per tier: één power user kan voor SMB belangrijk zijn; Enterprise-uitbreiding vereist multi-team adoptie.
Routeer alerts naar waar het werk gebeurt:
Houd de payload actiegericht: accountnaam, tier, wat veranderde, vergelijkingsvenster en een link naar de drill-down view zoals /accounts/{account_id}.
Elke alert heeft een eigenaar en een korte playbook nodig: wie reageert, de eerste 2–3 checks (datafreshness, recente releases, admin-wijzigingen) en aanbevolen outreach of in-app guidance.
Documenteer playbooks naast metricdefinities zodat reacties consistent blijven en alerts vertrouwd zijn.
Als adoptiemetrics beslissingen op tier-niveau aansturen (CS-outreach, prijsdiscussies, roadmap-keuzes), moet de data die ze voedt houvast hebben. Een klein setje checks en governance-gewoontes voorkomt “mysterie-dalingen” in dashboards en houdt stakeholders aligned over wat nummers betekenen.
Valideer events zo vroeg mogelijk (client SDK, API-gateway of ingestieworker). Weiger of plaats verdachte events in quarantaine.
Voer checks in zoals:
account_id of user_id (of waarden die niet bestaan in je accounttabel)Houd een quarantine-tabel zodat je slechte events kunt inspecteren zonder analytics te vervuilen.
Adoptietracking is tijdgevoelig; late events vertekenen wekelijkse actieve gebruiks- en tier-rollups. Monitor:
Routeer monitors naar een on-call kanaal, niet naar iedereen.
Retries gebeuren (mobiele netwerken, webhook-redelivery, batch-replays). Maak ingestie idempotent met een idempotency_key of een stabiel event_id, en dedupe binnen een tijdvenster.
Je aggregaties moeten veilig opnieuw te draaien zijn zonder dubbel tellen.
Maak een woordenlijst (glossary) die elke metric definieert (inputs, filters, tijdvenster, tier-attributieregels) en behandel het als de enige bron van waarheid. Link dashboards en docs aan die glossary (bv. /docs/metrics).
Voeg auditlogs toe voor metricdefinities en adoptiescoringsregelwijzigingen—wie wat veranderde, wanneer en waarom—zodat trendverschuivingen snel verklaard kunnen worden.
Adoptieanalytics is alleen nuttig als mensen het vertrouwen. De veiligste aanpak is je tracking-app ontwerpen om adoptievragen te beantwoorden met zo min mogelijk gevoelige data, en “wie wat mag zien” tot een kernfunctie te maken.
Begin met identifiers die genoeg zijn voor adoptie-inzichten: account_id, user_id (of een gepseudonimiseerde id), timestamp, feature en een klein setje gedragsproperties (plan, tier, platform). Vermijd namen, e-mailadressen, vrije-tekstvelden of alles dat per ongeluk secrets kan bevatten.
Als je user-niveau analyse nodig hebt, sla PII apart op en koppel alleen wanneer noodzakelijk. Behandel IP-adressen en device-identifiers als gevoelig; als je ze niet nodig hebt voor scoring, bewaar ze dan niet.
Definieer duidelijke toegangsrollen:
Stel standaard in op geaggregeerde views. Maak user-level drill-down expliciet permissiegebonden en verberg gevoelige velden (emails, volledige namen, externe ids) tenzij een rol ze écht nodig heeft.
Ondersteun verwijderverzoeken door iemands eventgeschiedenis te verwijderen of te anonimiseren en accountdata te verwijderen aan het einde van een contract.
Implementeer retentieregels (bijvoorbeeld raw events N dagen bewaren, aggregaten langer) en documenteer ze in je beleid. Leg toestemming en dataverwerkingsverantwoordelijkheden vast waar van toepassing.
De snelste weg naar waarde is een architectuur kiezen die bij de plekken past waar je data al staat. Je kunt later evolueren—wat telt is vertrouwde tier-niveau inzichten snel bij mensen krijgen.
Warehouse-first analytics: events stromen naar een warehouse (bv. BigQuery/Snowflake/Postgres), daarna bereken je adoptiemetrics en serveer je ze naar een lichte webapp. Dit is ideaal als je al op SQL vertrouwt, analisten hebt of één bron van waarheid met andere rapportage wilt delen.
App-first analytics: je webapp schrijft events naar de eigen database en berekent metrics in de applicatie. Sneller voor een klein product, maar je groeit er makkelijker uit wanneer eventvolume toeneemt en historische reprocessing nodig is.
Een praktisch default voor de meeste SaaS-teams is warehouse-first met een kleine operationele DB voor configuratie (tiers, metricdefinities, alerregels).
Lever een eerste versie met:
3–5 metrics (bv. actieve accounts, sleutelfeaturegebruik, adoptiescore, wekelijkse retentie, time-to-first-value).
Één tier-overzicht pagina: adoptiescore per tier + trend over tijd.
Één accountview: huidige tier, laatste activiteit, top gebruikte features en een simpele “waarom is de score wat hij is.”
Voeg feedbackloops vroeg toe: laat Sales/CS “dit lijkt onjuist” flaggen direct vanuit het dashboard. Versioneer je metricdefinities zodat je formules kunt veranderen zonder geschiedenis stilletjes te herschrijven.
Rol geleidelijk uit (één team → hele organisatie) en houd een changelog van metricupdates in de app (bv. /docs/metrics) zodat stakeholders altijd weten wat ze zien.
Als je van “spec” naar een werkende interne app wilt, kan een vibe-coding aanpak helpen—zeker voor de MVP-fase waarin je definities valideert, niet perfecte infrastructuur bouwt.
Met Koder.ai kunnen teams een adoptie-analytics webapp prototypen via een chatinterface terwijl er echte, bewerkbare code gegenereerd wordt. Dat past goed bij dit soort projecten omdat de scope cross-cutting is (React UI, een API-laag, een Postgres datamodel en geplande rollups) en vaak snel evolueert terwijl stakeholders op definities komen.
Een veelvoorkomend workflow:
Omdat Koder.ai deployment/hosting, custom domeinen en code-export ondersteunt, kan het een praktische manier zijn om snel tot een geloofwaardige interne MVP te komen terwijl je je lange-termijn architectuurkeuzes (warehouse-first vs app-first) openhoudt.
Begin met een gedeelde definitie van adoptie als een opeenvolging:
Maak het vervolgens tier-gevoelig (bijv. SMB-activatie binnen 7 dagen vs. Enterprise-activatie die admin- én eindgebruikeracties vereist).
Omdat tiers zich anders gedragen. Eén enkele metric kan:
Segmentatie per tier laat je realistische doelen stellen, de juiste north-star per tier kiezen en passende meldingen triggeren voor accounts met hoge waarde.
Gebruik een deterministische, gedocumenteerde regelset:
valid_from / valid_to.Dit voorkomt dat dashboards van betekenis veranderen wanneer accounts upgraden of downgraden.
Kies één primair resultaat per tier dat echte waarde weerspiegelt:
Zorg dat het telbaar is, moeilijk te manipuleren en duidelijk gekoppeld aan klantuitkomsten — niet aan klikken.
Definieer expliciete stages en kwalificatieregels zodat interpretatie niet verschuift. Voorbeeld:
Instrumenteer een klein setje kritieke-path-events:
signup_completeduser_invited, invite_acceptedfirst_value_received (definieer je “aha” nauwkeurig)Neem properties op die slicing en attributie betrouwbaar maken:
Gebruik beide:
Snapshots bevatten doorgaans actieve gebruikers, sleutelfeature-tellingen, componenten van de adoptiescore en de tier voor die dag—zodat tier-wijzigingen de historische rapportage niet herschrijven.
Maak het simpel, uitlegbaar en stabiel:
core_action op 3 aparte dagen in 14 dagen).Rol op per tier met distributies (mediaan, percentielen, % boven een drempel), niet alleen gemiddelden.
Maak meldingen tier-specifiek en actiegericht:
Routeer notificaties naar waar het werk plaatsvindt (Slack/email voor urgent, wekelijkse digest voor lage urgentie) en neem het essentiële mee: wat veranderde, vergelijkingsvenster en een drill-down verwijzing zoals /accounts/{account_id}.
Pas stage-eisen aan per tier (Enterprise-activatie kan zowel admin- als eindgebruikeracties vereisen).
key_feature_used (of per-feature events)integration_connectedPrioriteer events die progressie naar uitkomsten vertegenwoordigen, niet elke UI-interactie.
account_id (vereist)user_id (vereist wanneer een persoon betrokken is)tier (vastgelegd op eventtijd)plan / SKU (indien relevant)role (owner/admin/member)workspace_id, feature_name, source, timestampHoud naming consistent (snake_case) zodat queries geen vertaalproject worden.