Definieer doelen en adoptiesignalen
Voordat je een customer adoption healthscore bouwt, bepaal wat de score voor de business moet doen. Een score die churnrisico moet triggeren ziet er anders uit dan eentje die onboarding, klanttraining of productverbetering moet sturen.
Definieer wat “adoptie” betekent voor jouw product
Adoptie is niet alleen “recent ingelogd.” Schrijf de paar gedragingen op die echt aangeven dat klanten waarde bereiken:
- Activatie: het eerste moment dat een gebruiker een betekenisvol resultaat bereikt (bijv. “nodigde een collega uit”, “koppelde een datasource”, “publiceerde een rapport”).
- Kernacties: herhaalbare, hoge-signaal gedragingen die correleren met succesvolle accounts (bijv. wekelijkse exports, automation-runs, dashboards bekeken door meerdere gebruikers).
- Retentie: blijvend gebruik met de juiste cadans voor jouw product (dagelijks, wekelijks, maandelijks), bij voorkeur door meer dan één gebruiker binnen het account.
Dit worden je initiële adoptiesignalen voor featuregebruik-analyses en later cohortanalyse.
Maak een lijst van beslissingen die je app moet mogelijk maken
Wees expliciet over wat er gebeurt wanneer de score verandert:
- Wie krijgt een melding als een account onder een drempel valt?
- Welke playbooks moeten gestart worden (outreach, training, support check-in)?
- Welke inzichten moeten product adoptie-monitoring voeden (frictiepunten, onderbenutte features, time-to-value)?
Als je geen beslissing kunt noemen, meet die metriek nog niet.
Identificeer gebruikers, rollen en tijdvensters
Maak helder wie het customer success dashboard gebruikt:
- CS-managers hebben prioritering en accountcontext nodig.
- Product heeft patronen, cohorten en feature-niveaumetingen nodig.
- Support heeft recente activiteit rond tickets en incidenten nodig.
- Leiding heeft een begrijpelijke samenvatting en trend nodig.
Kies standaardvensters—laatste 7/30/90 dagen—en overweeg lifecycle-stadia (trial, onboarding, steady-state, renewal). Dit voorkomt dat je een splinternieuw account met een volwassen account vergelijkt.
Stel succescriteria op
Definieer “klaar” voor je healthscore-model:
- Nauwkeurigheid: voorspelt het risico en expansiesignalen beter dan je huidige aanpak?
- Uitlegbaarheid: kan een CSM binnen één minuut uitleggen waarom de score hoog/laag is?
- Gebruiksgemak: bespaart het tijd en leidt het tot consistente acties?
Deze doelen sturen alles daarna: event tracking, scoringslogica en de workflows rond de score.
Selecteer metrics voor je healthscore
Het kiezen van metrics is waar je healthscore een behulpzaam signaal wordt of een lawaaierig getal. Streef naar een kleine set indicatoren die echte adoptie weerspiegelen—niet alleen activiteit.
Begin met product adoptiesignalen
Kies metrics die laten zien of gebruikers herhaaldelijk waarde krijgen:
- Logins / actieve gebruikers: bijv. weekly active users (WAU) en de trend over de laatste 4–8 weken.
- Actieve dagen: hoeveel afzonderlijke dagen het account actief was in een week/maand (helpt valse positiefs door “één grote sessie” te vermijden).
- Featurediepte: gebruik van je “value features” (de acties die correleren met succes), niet elke knopklik.
- Aangesloten integraties: vooral als integraties overstapkosten verhogen of belangrijke workflows ontgrendelen.
- Seat-utilisatie: percentage van gekochte seats dat is uitgenodigd, geactiveerd en daadwerkelijk actief.
Houd de lijst gefocust. Als je niet in één zin kunt uitleggen waarom een metric ertoe doet, is het waarschijnlijk geen kerninput.
Voeg zakelijke context toe (zodat scores eerlijk zijn)
Adoptie moet in context worden geïnterpreteerd. Een team van 3 seats gedraagt zich anders dan een rollout van 500 seats.
Veelvoorkomende contextsignalen:
- Planniveau en feature-entitlements
- Contractgrootte / ARR-band
- Lifecycle stadium: trial vs net betaald vs renew
Deze hoeven geen “punten” toe te voegen, maar helpen realistische verwachtingen en drempels per segment in te stellen.
Beslis over leading vs. lagging indicators
Een bruikbare score mengt:
- Leading indicators (voorspellen toekomstig succes): toenemende actieve dagen, voltooiing onboarding, eerste integratie verbonden.
- Lagging indicators (bevestigen uitkomsten): verlenging, expansie, langetermijnretentie.
Vermijd het te zwaar wegen van lagging metrics; die vertellen je wat al gebeurd is.
Als je ze hebt, kunnen NPS/CSAT, support-ticketvolume en CSM-notities nuance toevoegen. Gebruik deze als modifiers of flags—niet als basis—omdat kwalitatieve data schaars en subjectief kan zijn.
Maak een simpele datawoordenlijst
Voordat je grafieken bouwt, stem namen en definities af. Een lichte datawoordenlijst moet bevatten:
- Metricnaam (bijv.
active_days_28d)
- Duidelijke definitie (wat telt, wat niet)
- Tijdsvenster en refresh-cadans
- Bron-systeem (product events, CRM, support)
Dit voorkomt later verwarring van “dezelfde metric, andere betekenis” bij implementatie van dashboards en alerts.
Ontwerp een uitlegbaar healthscore-model
Een adoptiescore werkt alleen als je team het vertrouwt. Streef naar een model dat je in één minuut aan een CSM en in vijf minuten aan een klant kunt uitleggen.
Begin simpel: gewogen punten (voor ML)
Start met een transparante, regels-gebaseerde score. Kies een kleine set adoptiesignalen (bijv. actieve gebruikers, key feature-gebruik, ingeschakelde integraties) en ken gewichten toe die de “aha”-momenten van je product reflecteren.
Voorbeeldweging:
- Wekelijkse actieve gebruikers per seat: 0–40 punten
- Frequentie key feature-gebruik: 0–35 punten
- Breedte van gebruikte features: 0–15 punten
- Tijd sinds laatste betekenisvolle activiteit: 0–10 punten
Houd gewichten verdedigbaar. Je kunt ze later herzien—wacht niet op een perfect model.
Normaliseer om bias te verminderen
Ruwe aantallen benadelen kleine accounts en verhullen grote accounts. Normaliseer waar het telt:
- Per seat (gebruik / gelicentieerde seats)
- Per accountleeftijd (nieuw vs volwassen accounts)
- Per planniveau (featurebeschikbaarheid)
Dit helpt dat je adoptie-gezondheidsscore gedrag weerspiegelt, niet alleen grootte.
Definieer groen/geel/rood met duidelijke redenering
Stel drempels in (bijv. Groen ≥ 75, Geel 50–74, Rood < 50) en documenteer waarom elke cutoff bestaat. Koppel drempels aan verwachte uitkomsten (renewal risk, onboarding completion, expansion readiness) en bewaar de notities in je interne docs of /blog/health-score-playbook.
Maak het uitlegbaar: bijdragers en trend
Elke score moet tonen:
- De top 3 bijdragers (wat hielp/benadeelde)
- De verandering over tijd (laatste 7/30 dagen)
- Een platte-taal samenvatting (“Feature X gebruik daalde 35% week-op-week”)
Plan voor iteratie: versiebeheer van het model
Behandel scoren als een product. Versioneer het (v1, v2) en meet impact: Werden churnalerts nauwkeuriger? Handelden CSMs sneller? Sla de scoreversie op bij elke berekening zodat je resultaten over tijd kunt vergelijken.
Instrumenteer productevents en databronnen
Een healthscore is slechts zo betrouwbaar als de activiteitsdata erachter. Voordat je scoringslogica bouwt, verifieer dat de juiste signalen consistent in alle systemen worden vastgelegd.
Kies je eventbronnen
De meeste adoptieprogramma’s halen data uit een mix van:
- Frontend-events (pageviews, clicks, featureinteracties)
- Backend-acties (API-calls, jobs voltooid, records aangemaakt)
- Billing (plan, renewals, betalingsstatus, seat counts)
- Support en success tools (tickets, CSAT, onboarding-mijlpalen)
Een praktische regel: track kritische acties server-side (moeilijker te vervalsen, minder gevoelig voor adblockers) en gebruik frontend-events voor UI-engagement en discovery.
Definieer een duidelijke eventschema
Houd een consistent contract zodat events makkelijk te joinen, te query'en en uit te leggen zijn aan stakeholders. Een gangbare basis:
event_nameuser_idaccount_idtimestamp (UTC)properties (feature, plan, device, workspace_id, enz.)
Gebruik een gecontroleerd vocabulaire voor event_name (bijv. project_created, report_exported) en documenteer het in een eenvoudige trackingplan.
Beslis SDK vs server-side (of beide)
- SDK-tracking is snel te leveren en goed voor UI-events.
- Server-side tracking is beter voor system-of-record acties.
Veel teams doen beide, maar zorg dat je niet hetzelfde echte-wereld-actie dubbel telt.
Handel identiteit correct af
Healthscores worden meestal op account-niveau gerold, dus je hebt betrouwbare user→account mapping nodig. Plan voor:
- Gebruikers die bij meerdere accounts horen
- Account-merges (overnames, workspace-consolidatie)
- Geanonimiseerde IDs voor pre-login gedrag (met veilige merge na signup)
Bouw kwaliteitschecks voor data in
Monitor minimaal missende events, duplicate bursts en timezone-consistentie (sla UTC op; converteer voor weergave). Flag anomalieën vroeg zodat je churnalerts niet afgaan omdat tracking stuk is.
Modelleer je data en opslag
Een customer adoption healthscore-app leeft of sterft door hoe goed je modelleert “wie deed wat en wanneer.” Het doel is veelgestelde vragen snel te beantwoorden: Hoe doet dit account het deze week? Welke features stijgen of dalen? Goed datamodel houdt scoren, dashboards en alerts eenvoudig.
Kernentiteiten om te modelleren
Begin met een kleine set “bron-van-waarheid” tabellen:
- Accounts: account_id, plan, segment, lifecycle stage, CSM-eigenaar
- Users: user_id, account_id, rol/persoonatype, created_at, status
- Subscriptions (of contracts): account_id, start/end, seats, MRR, renewal date
- Features: feature_id, naam, categorie (activation, collaboration, admin, enz.)
- Events: event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores: account_id, score_date (of computed_at), overall_score, component_scores, explanation fields
Houd deze entiteiten consistent door overal stabiele IDs (account_id, user_id) te gebruiken.
Split opslag: relationeel + analytics
Gebruik een relationele database (bv. Postgres) voor accounts/users/subscriptions/scores—dingen die je vaak update en joinet.
Bewaar high-volume events in een warehouse/analytics store (bv. BigQuery/Snowflake/ClickHouse). Dit houdt dashboards en cohortanalyses responsief zonder je transactionele DB te overladen.
Sla aggregaten op voor snelheid
In plaats van alles van raw events te herberekenen, onderhoud:
- Dagelijkse accountsamenvattingen (één rij per account per dag): actieve gebruikers, key event-tellingen, laatste activiteit, adoptie-mijlpalen
- Feature-tellers: per account/dag/feature gebruikstellingen, unieke gebruikers, bestede tijd (indien beschikbaar)
Deze tabellen voeden trendgrafieken, “wat veranderde”-inzichten en componenten van de healthscore.
Retentie, partitionering en queryprestaties
Voor grote eventtabellen plan retentie (bijv. 13 maanden raw, langer voor aggregaten) en partitioneer per datum. Cluster/indexeer op account_id en timestamp/date om “account over time”-queries te versnellen.
Indexeer in relationele tabellen op veelgebruikte filters en joins: account_id, (account_id, date) op summaries, en gebruik foreign keys om data schoon te houden.
Plan de webapp-architectuur
Plan je model duidelijk
Breng events, metrics en drempels in kaart vóór je begint met coderen, en bouw vervolgens vanuit het plan in één flow.
Je architectuur moet het makkelijk maken om een betrouwbare v1 te leveren en daarna te groeien zonder rewrite. Begin met zo min mogelijk onderdelen.
Monolith vs services (houd v1 simpel)
Voor de meeste teams is een modulair monolith de snelste route: één codebase met duidelijke grenzen (ingestion, scoring, API, UI), één deployable en minder operationele verrassingen.
Ga naar services pas als er een duidelijke reden is—onafhankelijke schaalbehoeften, strikte data-isolatie of verschillende teams. Vroegtijdige opsplitsing verhoogt faalpunten en vertraagt iteratie.
Definieer de kerncomponenten
Plan minimaal deze verantwoordelijkheden (ook als ze in één app leven):
- Ingestion: ontvangt productevents (SDK, Segment, webhook, batch imports).
- Aggregation: zet raw events om in dagelijkse/weken gebruiksfacts per account/user.
- Scoring: berekent de customer adoption healthscore en bijbehorende verklaringen.
- API: levert scores, trends en “waarom”-inzichten aan de UI en integraties.
- UI: customer success dashboard met accountviews, cohorten en drill-down.
Als je snel wilt prototypen, kan een vibe-coding aanpak helpen zonder in te steken op veel scaffolding. Bijvoorbeeld, Koder.ai kan een React-gebaseerde UI en een Go + PostgreSQL backend genereren uit een korte beschrijving van je entiteiten (accounts, events, scores), endpoints en schermen—gebruikbaar om snel een v1 neer te zetten waar je CS-team op kan reageren.
Geplande jobs vs streaming
Batchscoring (bijv. elk uur/‘s nachts) is meestal voldoende voor adoptie-monitoring en veel eenvoudiger te beheren. Streaming is zinvol voor near-real-time alerts (bijv. plotselinge gebruiksafname) of zeer hoog eventvolume.
Een praktisch hybride: ingest events continu, aggregate/scoring volgens schema, en reserveer streaming voor een klein stel urgente signalen.
Omgevingen, secrets en niet-functionele behoeften
Zet dev/stage/prod vroeg op, met sample-accounts in stage om dashboards te valideren. Gebruik een managed secrets store en roteer credentials.
Documenteer vereisten vooraf: verwacht eventvolume, score-versheid (SLA), API-latency targets, beschikbaarheid, dataretentie en privacybeperkingen (PII-hantering en toegangscontrols). Dit voorkomt dat architectuurkeuzes te laat—onder druk—worden gemaakt.
Bouw de datapijplijn en scoring-jobs
Je healthscore is zo betrouwbaar als de pijplijn die hem produceert. Behandel scoren als een productie-systeem: reproduceerbaar, observeerbaar en makkelijk uit te leggen als iemand vraagt: “Waarom is dit account vandaag gezakt?”
Een simpele pijplijn: raw → validated → aggregates
Begin met een staged flow die data versmalt naar iets dat je veilig kunt scoren:
- Raw events: append-only ingest van je app, mobile, integraties en billing/CRM-exports.
- Validated events: events die schema-checks doorstaan (vereiste velden, correcte types), identity-checks (user → account mapping) en deduplicatie.
- Daily aggregates: rollups per account (en optioneel workspace/team) zoals actieve gebruikers, key event-tellingen, time-to-value mijlpalen en trenddeltas.
Deze structuur houdt je scoring-jobs snel en stabiel, omdat ze op schone, compacte tabellen werken in plaats van miljarden raw-rijen.
Herberekeningsschema’s en backfills
Bepaal hoe “vers” de score moet zijn:
- Elk uur scoren werkt voor high-touch motions waar CSMs snel handelen.
- Dagelijks scoren is vaak genoeg voor SMB/self-serve en houdt kosten laag.
Maak de scheduler zo dat hij backfills ondersteunt (bijv. de laatste 30/90 dagen) wanneer je tracking repareert, gewichten wijzigt of een nieuw signaal toevoegt. Backfills moeten een first-class feature zijn, geen noodscript.
Idempotentie: voorkom dubbele telling
Scoring-jobs worden herhaald. Imports worden opnieuw uitgevoerd. Webhooks worden dubbel afgeleverd. Ontwerp hierop.
Gebruik een idempotency key voor events (event_id of een stabiele hash van timestamp + user_id + event_name + properties) en handhaaf uniciteit op het validated-niveau. Voor aggregaten, upsert op (account_id, date) zodat recomputatie eerdere resultaten vervangt in plaats van optelt.
Monitoring en anomaliechecks
Voeg operationele monitoring toe voor:
- Job success/failure en retry-aantallen
- Data lag (hoe ver achter “nu” je nieuwste aggregaten zijn)
- Volume-anomalieën (plotselinge dalingen/pieken in events, actieve gebruikers, key acties)
Zelfs eenvoudige thresholds (bv. “events 40% lager vs 7-daags gemiddelde”) voorkomen dat stillezende fouten je customer success dashboard misleiden.
Audit-trails voor elke score
Sla een auditrecord op per account per scoring-run: inputmetrics, afgeleide features (zoals week-op-week verandering), modelversie en uiteindelijke score. Als een CSM op “Waarom?” klikt, kun je precies tonen wat er veranderde en wanneer—zonder het uit logs te moeten reconstrueren.
Maak een veilige API voor health en inzichten
Genereer de app-skeleton
Beschrijf je entiteiten en schermen en laat Koder.ai de React UI en Go-backend genereren.
Je webapp leeft of sterft aan zijn API. Het is het contract tussen je scoring-jobs, je UI en downstream tools (CS-platforms, BI, data-exports). Streef naar een API die snel, voorspelbaar en veilig is.
Kernendpoints om echte workflows te ondersteunen
Ontwerp endpoints rond hoe Customer Success adoptie daadwerkelijk onderzoekt:
- Account health:
GET /api/accounts/{id}/health retourneert de laatste score, statusband (bijv. Groen/Geel/Rood) en laatst berekende timestamp.
- Trends:
GET /api/accounts/{id}/health/trends?from=&to= voor score over tijd en key metric-deltas.
- Drivers (“waarom”):
GET /api/accounts/{id}/health/drivers om top positieve/negatieve factoren te tonen (bijv. “wekelijkse actieve seats -35%”).
- Cohorten:
GET /api/cohorts/health?definition= voor cohortanalyse en peer-benchmarks.
- Exports:
POST /api/exports/health om CSV/Parquet met consistente schema’s te genereren.
Filtering, paginatie en caching
Maak lijstendpoints makkelijk te snijden:
- Filters:
plan, segment, csm_owner, lifecycle_stage en date_range zijn essentieel.
- Paginatie: gebruik cursor-gebaseerde paginatie (
cursor, limit) voor stabiliteit als data verandert.
- Caching: cache zware queries (cohort rollups, trendseries) en retourneer
ETag/If-None-Match om herhaalde loads te verminderen. Zorg dat cache-keys filters en permissies meenemen.
Beveiliging met role-based access control
Bescherm data op accountniveau. Implementeer RBAC (bijv. Admin, CSM, Read-only) en handhaaf dit server-side op elk endpoint. Een CSM mag alleen accounts zien die hij/zij bezit; finance-rollen mogen plan-aggregaten zien maar niet per-gebruiker details.
Geef altijd uitlegbaarheid terug
Naast de numerieke customer adoption healthscore, retourneer “waarom” velden: top drivers, getroffen metrics en de vergelijkingsbaseline (vorige periode, cohort-median). Dit maakt product adoptie-monitoring tot actie, niet alleen rapportage, en verhoogt vertrouwen in je customer success dashboard.
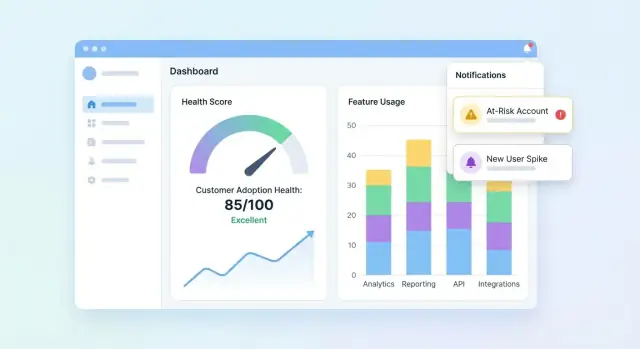
Ontwerp dashboards en accountviews
Je UI moet drie vragen snel beantwoorden: Wie is gezond? Wie verslechtert? Waarom? Begin met een dashboard dat het portfolio samenvat en laat gebruikers doorklikken naar een account om het verhaal achter de score te begrijpen.
Portfolio-dashboard essentials
Neem een compact aantal tegels en grafieken op die CS-teams in seconden kunnen scannen:
- Scoreverdeling (histogram of buckets zoals Healthy / Watch / At-risk)
- At-risk lijst met de weinige velden die nodig zijn om te handelen (account, eigenaar, score, laatste activiteit, top driver)
- Scoretrend over tijd (lijngrafiek) met filteroptie per segment
Maak de at-risk lijst klikbaar zodat een gebruiker een account opent en direct ziet wat er veranderde.
Accountweergave: verklaar de score
De accountpagina moet als een tijdlijn van adoptie lezen:
- Tijdlijn van key events (onboarding-stappen voltooid, integraties verbonden, admin-wijzigingen, major feature first-use)
- Belangrijkste metrics (actieve gebruikers, key feature-acties, tijd sinds laatste betekenisvolle activiteit)
- Feature adoption breakdown die toont welke features geadopteerd, genegeerd of regressief zijn
Voeg een “Waarom deze score?” paneel toe: klikken op de score onthult de bijdragende signalen (positief en negatief) met platte-taal uitleg.
Cohort- en segmentweergaven
Bied cohortfilters aan die overeenkomen met hoe teams accounts beheren: onboarding cohorts, plan tiers en industries. Combineer elk cohort met trendlijnen en een kleine tabel van toppers zodat teams uitkomsten kunnen vergelijken en patronen zien.
Toegankelijke, betrouwbare visuals
Gebruik duidelijke labels en eenheden, vermijd dubbelzinnige iconen en bied kleurveilige statusindicatoren (bv. tekstlabels + vormen). Behandel grafieken als beslis-tools: annoteer pieken, toon datumbereiken en maak drill-down gedrag consistent.
Voeg alerts, taken en workflows toe
Een healthscore is alleen nuttig als hij tot actie leidt. Alerts en workflows zetten “interessante data” om in tijdige outreach, onboarding-fixes of productnudges—zonder dat je team continu dashboards hoeft te volgen.
Definieer alertrules die matchen met echt risico
Begin met een kleine set high-signal triggers:
- Score-dalingen (bijv. -15 punten week-op-week)
- Rode status (kritische drempel overschreden)
- Plotselinge gebruiksafname (key feature gebruik onder baseline)
- Mislukte onboardingstap (gestagneerde checklist, integratie niet voltooid)
Maak elke regel expliciet en uitlegbaar. Alert op “Geen activiteit in Feature X gedurende 7 dagen + onboarding onaf” in plaats van “Slechte gezondheid”.
Teams werken verschillend, bouw kanaalondersteuning en voorkeuren:
- E-mail voor account-eigenaren en managers
- Slack voor teamzichtbaarheid en snelle reactie
- In-app taken binnen je customer success dashboard zodat werk niet verloren raakt
Laat elk team configureren: wie wordt geïnformeerd, welke regels aanstaan en welke drempels “urgent” maken.
Verminder ruis met guardrails
Alertmoeheid doodt adoptie-monitoring. Voeg controles toe zoals:
- Cooldown windows (niet opnieuw alerten voor hetzelfde account binnen N uren/dagen)
- Minimum data-drempels (sla alerts over als account te weinig recente data heeft)
- Batching/digests voor niet-dringende signalen (dagelijkse/weekelijkse samenvattingen)
Voeg context en vervolgstappen toe
Elke alert moet beantwoorden: wat veranderde, waarom het ertoe doet en wat te doen. Voeg recente score-drivers toe, een korte tijdlijn (bv. laatste 14 dagen) en voorgestelde taken zoals “Plan onboarding-gesprek” of “Stuur integratiehandleiding”. Link naar de accountweergave (bijv. /accounts/{id}).
Volg uitkomsten om de cirkel te sluiten
Behandel alerts als werkitems met statussen: acknowledged, contacted, recovered, churned. Rapportage over uitkomsten helpt regels te verfijnen, playbooks te verbeteren en te bewijzen dat de healthscore retentie beïnvloedt.
Zorg voor datakwaliteit, privacy en governance
Verminder bouwkosten
Verlaag bouwkosten door je proces te delen of collega’s naar Koder.ai te verwijzen.
Als je healthscore op onbetrouwbare data bouwt, stoppen teams met vertrouwen en handelen. Behandel kwaliteit, privacy en governance als producteigenschappen, niet als bijzaak.
Zet geautomatiseerde datachecks op
Begin met lichte validatie bij elke overdracht (ingest → warehouse → scoring output). Enkele hoog-signaal tests vangen de meeste problemen vroeg:
- Schema-checks: verwachte kolommen bestaan, types zijn gelijk gebleven, enums zijn geldig.
- Range-checks: onmogelijke waarden (negatieve sessies, timestamps in de toekomst) falen snel.
- Null-checks: verplichte velden (
account_id, event_name, occurred_at) mogen niet leeg zijn.
Als tests falen, blokkeer de scoring-job (of markeer resultaten als “stale”) zodat een kapotte pijplijn niet stilletjes misleidende churnalerts genereert.
Handel veelvoorkomende randgevallen expliciet af
Healthscoring faalt bij “raar maar normaal” scenario’s. Definieer regels voor:
- Nieuwe accounts met weinig data: toon “onvoldoende data” of gebruik een ramp-up baseline in plaats van een lage score.
- Seizoensgebonden gebruik: vergelijk met de eerdere periode van het account of cohort-benchmarks in plaats van een universele drempel.
- Storingen en tracking-gaps: markeer beïnvloede vensters en voorkom dat klanten gestraft worden voor jouw downtime.
Voeg permissies en privacycontrols toe
Beperk PII standaard: sla alleen op wat je nodig hebt voor adoptie-monitoring. Pas role-based toegang toe in de webapp, log wie data bekeek/geëxporteerd heeft en redacteer exports wanneer velden niet nodig zijn (bijv. verberg e-mails in CSV-downloads).
Schrijf runbooks en governance-habits
Schrijf korte runbooks voor incidentresponse: hoe scoring te pauzeren, data backfills te draaien en historische jobs opnieuw te runnen. Review customer success metrics en score-gewichten regelmatig—maandelijks of per kwartaal—om drift te voorkomen naarmate je product evolueert. Voor procesafstemming, verwijs naar je interne checklist uit /blog/health-score-governance.
Valideer, iterateer en schaal de healthscore
Validatie is waar een healthscore stopt met een “leuke grafiek” en begint met genoeg vertrouwen om acties te sturen. Behandel je eerste versie als een hypothese, niet als het eindantwoord.
Run een pilot en kalibreer tegen menselijke inschatting
Begin met een pilotgroep accounts (bijv. 20–50 verdeeld over segmenten). Vergelijk voor elk account de score en risico-reden met de beoordeling van de CSM.
Let op patronen:
- Scores die consequent hoger/lager zijn dan CSM-inschatting (kalibratie)
- “False alarms” (hoog risico maar account is ok) vs “misses” (gezonde score maar account churnt)
- Redenen die niet kloppen (uitlegbaarheidsgaten)
Meet of het echt nuttig is
Nauwkeurigheid helpt, maar bruikbaarheid betaalt zich terug. Meet operationele uitkomsten zoals:
- Time-to-detect risk (hoe vroeg flag je een probleem)
- Outreach success rate (percentage risicovolle accounts dat verbetert na interventie)
- Churn-reductie-proxy's (beweging in renewal likelihood, expansiesignalen, supportlastverandering)
Test veranderingen veilig met versiebeheer
Wanneer je drempels, gewichten of nieuwe signalen aanpast, behandel ze als een nieuwe modelversie. A/B-test versies op vergelijkbare cohorten of segmenten en bewaar historische versies zodat je kunt verklaren waarom scores veranderden.
Verzamel feedback in de UI
Voeg een lichte controle toe zoals “Score voelt niet goed” plus een reden (bijv. “recent onboarding niet weerspiegeld”, “gebruik is seizoensgebonden”, “verkeerde accountmapping”). Routeer deze feedback naar je backlog en tag het aan account en scoreversie voor snellere debugging.
Schaal met een roadmap
Als de pilot stabiel is, plan opschaalwerk: diepere integraties (CRM, billing, support), segmentatie (per plan, industrie, lifecycle), automatisering (taken en playbooks) en self-serve instellingen zodat teams views kunnen aanpassen zonder engineering.
Als je opschaalt, hou de build/iterate-lus kort. Teams gebruiken vaak Koder.ai om snel nieuwe dashboardpagina’s te maken, API-shapes te verfijnen of workflowfeatures (taken, exports en rollback-klare releases) toe te voegen direct vanuit chat—handig wanneer je model versieert en UI + backend tegelijk moet uitrollen zonder de CS-feedbackcyclus te vertragen.