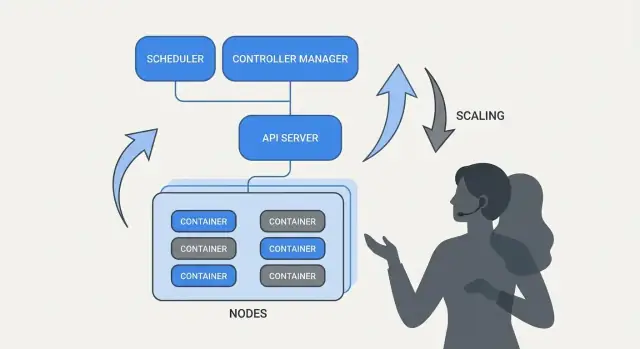
Waarom Kubernetes de dagelijkse operatie veranderde
Kubernetes introduceerde niet alleen een nieuw gereedschap — het veranderde hoe “dagelijkse ops” eruitziet wanneer je tientallen (of honderden) services draait. Voor de komst van orchestration plakte teams vaak scripts, handmatige runbooks en mondelinge kennis aan elkaar om dezelfde terugkerende vragen te beantwoorden: Waar moet deze service draaien? Hoe rollen we een wijziging veilig uit? Wat gebeurt er als een node om 02:00 uitvalt?
Wat orkestratie eigenlijk oplost
In de kern is orkestratie de coördinatielaag tussen je intentie (“draai deze service zoals dit”) en de rommelige realiteit van falende machines, verschuivend verkeer en continue deploys. In plaats van elke server als een speciale uitzondering te behandelen, ziet orkestratie compute als een pool en workloads als schedulbare eenheden die kunnen verplaatsen.
Kubernetes populariseerde een model waarin teams beschrijven wat ze willen en het systeem continu werkt om de realiteit aan die beschrijving te laten voldoen. Die verschuiving is belangrijk omdat operaties minder over heldendaden gaan en meer over herhaalbare processen.
Drie uitkomsten die teams meteen voelden
Kubernetes standaardiseerde operationele uitkomsten die de meeste serviceteams nodig hebben:
- Deployment: een consistente manier om te declareren wat er moet draaien, het bij te werken en te verifiëren dat het gezond is.
- Schaalbaarheid: een praktische route van één instantie naar vele, zonder de service te herontwerpen of machines handmatig te voorzien.
- Service-operations: stabiele manieren voor services om elkaar te vinden, verkeer te routeren en te blijven werken terwijl instances veranderen.
Een opmerking over scope en bronnen
Dit artikel concentreert zich op de ideeën en patronen rond Kubernetes (en leiders als Brendan Burns), niet op een persoonlijke biografie. Als we spreken over “hoe het begon” of “waarom het zo is ontworpen”, baseren we die beweringen op openbare bronnen — conferentietalks, designdocumenten en upstream documentatie — zodat het verhaal verifieerbaar blijft in plaats van mythisch.
Brendan Burns in het origin story van Kubernetes (hoog niveau)
Brendan Burns wordt algemeen erkend als een van de drie oorspronkelijke mede-oprichters van Kubernetes, samen met Joe Beda en Craig McLuckie. In het vroege werk aan Kubernetes bij Google hielp Burns zowel de technische richting als de manier waarop het project aan gebruikers werd uitgelegd vormgeven — vooral rond “hoe je software opereert” in plaats van alleen “hoe je containers runt.” (Bronnen: Kubernetes: Up & Running, O’Reilly; Kubernetes project repository AUTHORS/maintainers listings)
Open source samenwerking vormde het ontwerp
Kubernetes werd niet simpelweg “uitgebracht” als een afgerond intern systeem; het werd in het openbaar gebouwd met een groeiende groep bijdragers, use cases en beperkingen. Die openheid duwde het project naar interfaces die in verschillende omgevingen zouden standhouden:
- duidelijke, geversioneerde API's in plaats van verborgen implementatiedetails
- draagbare gedragingen over cloudproviders en on-premises omgevingen
- extensiepunten zodat de kern relatief klein kon blijven terwijl veel behoeften ondersteund werden
Deze samenwerkingsdruk is belangrijk omdat het beïnvloedde waar Kubernetes voor optimaliseerde: gedeelde primitieve onderdelen en herhaalbare patronen waar veel teams het over eens konden worden, zelfs als ze het niet eens waren over tools.
Wat “gestandaardiseerd” hier echt betekent
Wanneer men zegt dat Kubernetes deployment en operatie “gestandaardiseerd” heeft, bedoelen ze meestal niet dat elk systeem identiek werd. Ze bedoelen dat het een gemeenschappelijk vocabulaire en een set workflows bood die teams keer op keer konden herhalen:
- “deployment”, “service”, “ingress”, “job”, “namespace” als gedeelde termen
- een consistent model om te declareren wat je wilt (en het systeem het te laten realiseren)
- voorspelbare manieren om wijzigingen uit te rollen, te schalen en te herstellen van fouten
Dat gedeelde model maakte het makkelijker om documentatie, tooling en teampraktijken van het ene bedrijf naar het andere over te dragen.
Kubernetes het project versus het ecosysteem
Het is nuttig om Kubernetes (het open-source project) te scheiden van het Kubernetes-ecosysteem.
Het project is de kern-API en control plane componenten die het platform implementeren. Het ecosysteem is alles wat eromheen groeide — distributions, managed services, add-ons en aanpalende CNCF-projecten. Veel echte “Kubernetes-features” waar mensen op vertrouwen (observability stacks, policy engines, GitOps-tools) leven in dat ecosysteem, niet in het kernproject zelf.
Het kernidee: declaratieve gewenste staat
Declaratieve configuratie is een simpele verschuiving in hoe je systemen beschrijft: in plaats van de stappen op te sommen, geef je aan wat je als eindresultaat wilt.
In Kubernetes-termen zeg je niet tegen het platform “start een container, open dan een poort, herstart als hij crasht.” Je declareert “er moeten drie kopieën van deze app draaien, bereikbaar op deze poort, met deze containerimage.” Kubernetes neemt de verantwoordelijkheid om de realiteit met die declaratie in overeenstemming te brengen.
Gewenste staat versus imperatieve scripts
Imperatieve operaties lijken op een runbook: een reeks commando's die de vorige keer werkte, en die je opnieuw uitvoert wanneer iets verandert.
Gewenste staat is meer een contract. Je legt het bedoelde resultaat vast in een configuratiebestand en het systeem werkt continu naar dat resultaat toe. Als iets afwijkt — een instantie sterft, een node verdwijnt, een handmatige wijziging sluipt binnen — detecteert het platform de mismatch en corrigeert het.
Voor/na: runbook-commando's versus YAML
Voorheen (imperatief runbook-denken):
- SSH naar een server
- Haal de nieuwe containerimage binnen
- Stop het oude proces
- Start het nieuwe proces
- Update een load balancer-regel
- Bij trafficpieken: herhaal op meer servers
Deze aanpak werkt, maar geeft makkelijk “snowflake” servers en een lange checklist die maar door een paar mensen wordt vertrouwd.
Daarna (declaratieve gewenste staat):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Je past het bestand aan (bijvoorbeeld image of replicas updaten), past het toe en Kubernetes' controllers werken om te reconciliëren wat draait met wat is gedeclareerd.
Waarom het werk en drift vermindert
Declaratieve gewenste staat verlaagt operationele lasten door “do deze 17 stappen” te veranderen in “houd het zo.” Het vermindert ook configuratiedrift omdat de bron van waarheid expliciet en reviewbaar is — vaak in versiebeheer — waardoor verrassingen makkelijker te vinden, auditen en rollbacken zijn.
Controllers en reconciliatie: het systeem dat dingen waar houdt
Kubernetes voelt “zelfbeherend” omdat het is gebouwd rond een eenvoudig patroon: je beschrijft wat je wilt en het systeem werkt continu om de realiteit daarmee in lijn te brengen. De motor achter dat patroon is de controller.
Wat een controller is (in gewone taal)
Een controller is een lus die de huidige staat van de cluster bewaakt en die vergelijkt met de gewenste staat die je in YAML hebt gedeclareerd (of via een API-call). Wanneer hij een verschil ziet, onderneemt hij actie om dat verschil te verkleinen.
Het is geen eenmalig script en het wacht niet op een mens om op een knop te drukken. Het draait herhaaldelijk — observeren, beslissen, handelen — zodat het op elk moment op verandering kan reageren.
Reconciliatie: hoe Kubernetes “dingen waar houdt”
Dat herhaalde vergelijk- en corrigeergedrag heet reconciliatie. Het is het mechanisme achter de veelgebruikte belofte van “self-healing.” Het systeem voorkomt geen falen; het merkt afwijking op en corrigeert het.
Drift kan om alledaagse redenen gebeuren:
- een proces crasht
- een node verdwijnt
- iemand schaalt iets op of neer
- een deployment wordt bijgewerkt
Reconciliatie betekent dat Kubernetes die gebeurtenissen ziet als signalen om je intentie opnieuw te controleren en te herstellen.
De uitkomsten waar mensen echt om geven
Controllers vertalen zich naar vertrouwde operationele resultaten:
- Vervang gefaalde pods: als een pod sterft, merkt een controller dat je hem nog steeds wilt en plant een nieuwe.
- Houd replica-aantallen stabiel: als je om 5 replicas vroeg en er maar 4 draaien, creëert Kubernetes de ontbrekende.
- Beheer rollout-voortgang: tijdens updates verplaatsen controllers het systeem naar de nieuwe versie terwijl de gewenste beschikbaarheid behouden blijft.
Het belangrijke is dat je niet handmatig symptomen achterna hoeft te rennen. Je declareert het doel en de controlelussen doen het continue “het zo houden”-werk.
Waarom dit verder schaalt dan één feature
Deze aanpak is niet beperkt tot één type resource. Kubernetes gebruikt hetzelfde controller-en-reconciliatie-idee over veel objecten — Deployments, ReplicaSets, Jobs, Nodes, Endpoints en meer. Die consistentie is een grote reden dat Kubernetes een platform werd: zodra je het patroon begrijpt, kun je voorspellen hoe het systeem zich gedraagt als je nieuwe mogelijkheden toevoegt (inclusief custom resources die dezelfde lus volgen).
Scheduling als productfeature, niet handmatig werk
Ga live op je domein
Zet je project op een custom domein wanneer je klaar bent om het te delen.
Als Kubernetes alleen "containers draaien" deed, bleef het moeilijkste deel: bepalen waar elke workload moet draaien. Scheduling is het ingebouwde systeem dat Pods automatisch op de juiste nodes plaatst, op basis van resourcebehoeften en regels die je definieert.
Dat is belangrijk omdat plaatsingsbeslissingen direct uptime en kosten beïnvloeden. Een web-API op een overbelaste node kan traag worden of crashen. Een batchjob naast latency-kritische services kan noisy-neighbor problemen veroorzaken. Kubernetes maakt dit tot een herhaalbare productcapaciteit in plaats van een spreadsheet-en-SSH routine.
Waar de scheduler op optimaliseert
Op basisniveau zoekt de scheduler nodes die aan de Pod-eisen voldoen.
- CPU-/geheugenrequests: requests reserveren capaciteit voor plaatsingsbeslissingen. Als je 500m CPU en 1Gi geheugen aangeeft, overweegt Kubernetes alleen nodes met voldoende vrije capaciteit.
Deze gewoonte — realistische requests instellen — vermindert vaak willekeurige instabiliteit omdat kritieke services dan minder met alles concurreren.
Veelvoorkomende constraints die teams gebruiken
Naast resources gebruiken productieklusters meestal een paar praktische regels:
- Affinity / anti-affinity: “plaats deze samen” (voor caching-localiteit) of “houd deze uit elkaar” (om te voorkomen dat één node-fout alle replicas treft).
- Taints en tolerations: markeer bepaalde nodes als speciaal (GPU-nodes, systeemnodes, compliance-nodes) en laat alleen goedgekeurde workloads daar landen.
Hoe dit storingen vermindert
Scheduling-functies helpen teams operationele intentie vast te leggen:
- Verspreid replicas over nodes om node-fouten te overleven.
- Isoleer “spiky” jobs van klantgerichte services.
- Voorkom dat dure nodes (zoals GPU) door verkeerde workloads worden gebruikt.
De praktische conclusie: behandel schedulingregels als productvereisten — schrijf ze op, review ze en pas ze consistent toe — zodat betrouwbaarheid niet afhankelijk is van iemand die zich het “juiste node” herinnert om 02:00.
Schalen: van één instantie naar duizenden zonder herontwerpen
Een van de meest praktische ideeën van Kubernetes is dat schalen je applicatiecode of deployment-aanpak niet opnieuw hoeft uit te vinden. Als de app als één container kan draaien, kan dezelfde workload-definitie meestal groeien naar honderden of duizenden kopieën.
Schalen heeft twee lagen
Kubernetes splitst schalen in twee gerelateerde beslissingen:
- Hoeveel pods draaien (meer kopieën van je app voor meer doorvoer of redundantie).
- Hoeveel cluster-capaciteit je hebt (genoeg nodes — en de juiste grootte nodes — om die pods te plaatsen).
Die scheiding is belangrijk: je kunt om 200 pods vragen, maar als de cluster maar plek heeft voor 50, wordt “schalen” een rij van pending werk.
Autoscaling, conceptueel (HPA, VPA, Cluster Autoscaler)
Kubernetes gebruikt vaak drie autoscalers, elk gericht op een andere hendel:
- Horizontal Pod Autoscaler (HPA): verandert het aantal pods op basis van signalen zoals CPU-gebruik, geheugen of custom applicatie-metrics.
- Vertical Pod Autoscaler (VPA): past pod resource requests/limits aan zodat elke pod meer (of minder) CPU/geheugen krijgt.
- Cluster Autoscaler: voegt nodes toe of verwijdert ze zodat de scheduler ruimte heeft om de pods te plaatsen die je hebt gevraagd.
Samen zetten ze schalen om in beleid: “houd latency stabiel” of “houd CPU rond X%,” in plaats van een handmatig alarmritueel.
Waar “goed schalen” vanaf hangt
Schaalbaarheid werkt alleen zo goed als de inputs:
- Metrics: CPU is makkelijk maar niet altijd betekenisvol; request-rate, queue-depth en latency passen vaak beter bij echte belasting.
- Resource requests/limits: die vertellen de scheduler wat een pod nodig heeft. Zonder die informatie worden plaatsing en autoscaling gokwerk.
- Loadpatronen: piekverkeer, trage warm-ups en zware achtergrondjobs veranderen hoe snel schaling moet reageren.
Veelvoorkomende valkuilen
Twee fouten komen vaak terug: schalen op de verkeerde metric (CPU laag terwijl requests time-outs veroorzaken) en ontbrekende resource requests (autoscalers kunnen capaciteit niet voorspellen, pods worden te dicht op elkaar gezet en prestaties worden inconsistent).
Veilige deploys: rollouts, health checks en rollbacks
Een grote verschuiving die Kubernetes populair maakte, is het behandelen van “deployen” als een doorlopend regelprobleem, niet als een eenmalig script dat je vrijdagavond om 17:00 uitvoert. Rollouts en rollbacks zijn eersteklas gedragingen: je declareert welke versie je wilt en Kubernetes beweegt het systeem daarheen terwijl het continu controleert of de wijziging daadwerkelijk veilig is.
Rollouts als gecontroleerde transitie
Met een Deployment is een rollout een geleidelijke vervanging van oude Pods door nieuwe. In plaats van alles stoppen en opnieuw starten, kan Kubernetes in stappen updaten — capaciteit beschikbaar houden terwijl de nieuwe versie bewijst dat hij met echt verkeer om kan gaan.
Als de nieuwe versie begint te falen, is rollback geen noodprocedure. Het is een normale operatie: je kunt terugschakelen naar een vorige ReplicaSet (de laatst bekende goede versie) en de controller het oude herstellen laten uitvoeren.
Probes: voorkomen van “slecht maar draaiend” releases
Health checks veranderen rollouts van hoop-gedreven naar meetbaar.
- Readiness probes bepalen of een Pod verkeer mag ontvangen. Een container kan wel draaien maar niet klaar zijn (caches warmen, afhankelijkheden bereiken). Readiness voorkomt dat gebruikers naar een instantie worden gestuurd die niet correct kan antwoorden.
- Liveness probes detecteren wanneer een container vastzit of ongezond is en herstart moeten worden. Dit voorkomt het langzaam falen waarbij een proces wel ‘alive’ is maar niet functioneert.
Goed gebruik van probes vermindert false positives — deploys die lijken te slagen omdat Pods gestart zijn, maar in werkelijkheid requests falen.
Deployment-strategieën: rolling, blue/green, canary
Kubernetes ondersteunt een rolling update standaard, maar teams leggen er vaak extra patronen overheen:
- Blue/green: twee volledige omgevingen houden en verkeer van oud (blue) naar nieuw (green) schakelen zodra green is geverifieerd.
- Canary: een klein percentage van het verkeer naar de nieuwe versie sturen, metrics monitoren en dan geleidelijk uitbreiden.
Meetbare (en automatiseerbare) veiligheid
Veilige deploys hangen af van signalen: error rate, latency, saturatie en gebruikersimpact. Veel teams koppelen rollout-beslissingen aan SLO's en error budgets — als een canary te veel budget verbrandt, stopt de promotie.
Het doel is geautomatiseerde rollback-triggers gebaseerd op echte indicatoren (mislukte readiness, stijgende 5xx, latencypieken), zodat “rollback” een voorspelbare systeemreactie wordt — niet een nachtelijke heldendaad.
Service-operations: discovery, routing en stabiele netwerken
Lever een nette backend op
Maak een Go API met PostgreSQL-modellen die past bij herhaalbare deployment-workflows.
Een containerplatform voelt alleen “automatisch” als andere delen van het systeem je app nog steeds kunnen vinden nadat die is verplaatst. In productieve clusters worden pods continu aangemaakt, verwijderd, verplaatst en geschaald. Als elke wijziging vereiste dat IP-adressen in configuraties werden aangepast, zou operatie constant werk zijn — en zouden storingen routine worden.
Waarom service discovery ertoe doet
Service discovery is de praktijk om clients een betrouwbare manier te geven om een veranderende set backends te bereiken. In Kubernetes stop je met individuele instances targeten ("bel 10.2.3.4") en target je in plaats daarvan een naamgegeven service ("bel checkout"). Het platform handelt af welke pods die naam momenteel bedienen.
Services, selectors en endpoints (in gewoon Nederlands)
Een Service is een stabure voordeur voor een groep pods. Het heeft een consistente naam en virtueel adres binnen de cluster, ook als de onderliggende pods veranderen.
Een selector bepaalt welke pods “achter” die voordeur staan. Meestal matcht het labels, zoals app=checkout.
Endpoints (of EndpointSlices) zijn de levende lijst van daadwerkelijke pod IP's die momenteel aan de selector voldoen. Wanneer pods schalen, uitrollen of worden verplaatst, werkt die lijst automatisch bij — clients blijven dezelfde Service-naam gebruiken.
Stabiele adressen, load balancing en routering
Operationeel levert dit:
- Stabiele adressering: apps praten met een Service DNS-naam in plaats van Pod-IP's na te jagen.
- Load balancing: verkeer wordt verdeeld over gezonde pods achter de Service.
- Voorspelbare routering: je kunt scheiden wie verkeer zou moeten ontvangen (labels/selectors) van waar de pods toevallig draaien.
Voor north–south verkeer (van buiten de cluster) gebruikt Kubernetes meestal een Ingress of de nieuwere Gateway-aanpak. Beide bieden een gecontroleerd toegangspunt waar je op hostname of pad kunt routeren en vaak zorgen zoals TLS-terminatie centraliseren. Het kernidee blijft: houd externe toegang stabiel terwijl de backends daaronder veranderen.
Zelfherstel: wat het echt betekent in productie
“Self-healing” in Kubernetes is geen magie. Het is een set geautomatiseerde reacties op falen: herstart, verplaats en vervang. Het platform bewaakt wat je zei dat je wilde (je gewenste staat) en duwt de realiteit voortdurend terug naar dat doel.
Herstart: wanneer een container crasht
Als een proces stopt of een container ongezond wordt, kan Kubernetes het op dezelfde node herstarten. Dit wordt meestal aangestuurd door:
- Liveness probes: “functioneert deze container nog?” Zo niet, herstart.
- Restart policies: regels wanneer herstarts moeten plaatsvinden.
Een veelvoorkomend productiemodel is: één container crasht → Kubernetes herstart hem → je Service blijft alleen naar gezonde Pods routeen.
Verplaatsen en vervangen: wanneer een node faalt
Als een volledige node uitvalt (hardwareprobleem, kernel panic, netwerkverlies), detecteert Kubernetes de node als onbeschikbaar en begint het werk elders te plaatsen. Globaal gezien:
- De node wordt als unhealthy/not ready gemarkeerd.
- Pods die daar draaiden worden als verloren beschouwd.
- Controllers maken vervangende Pods op andere gezonde nodes om het gewenste replica-aantal te herstellen.
Dit is zelfherstel op clusterniveau: het systeem vervangt capaciteit in plaats van te wachten op een mens met SSH.
Observability: hoe je weet dat het herstelt
Zelfherstel doet er alleen toe als je het kunt verifiëren. Teams kijken typisch naar:
- Logs (app-logs en platformevents) om te zien wat herstartte en waarom
- Metrics zoals restart-aantallen, mislukte probes en node-readiness
- Alerts wanneer herstel faalt (bijv. herhaalde CrashLoopBackOff, replica-tekort of te veel evictions)
Misconfiguraties die zelfherstel breken
Zelfs met Kubernetes kan “healing” falen als de guardrails verkeerd staan:
- Slechte of ontbrekende liveness/readiness probes (false positives of nooit-ready Pods)
- Geen resource requests/limits, wat leidt tot onvoorspelbare scheduling of OOM-kills
- Te weinig replicas (een enkele Pod biedt geen continuïteit)
- Te agressieve probe-timings die restart-stormen veroorzaken
- Workloads die vertrouwen op node-lokale state zonder duurzame opslagstrategie
Wanneer zelfherstel goed is ingericht, worden storingen kleiner en korter — en, belangrijker, meetbaar.
Plan de rollout eerst
Gebruik Planning Mode om services, API's en rollouts in kaart te brengen voordat je code wijzigt.
Kubernetes won niet alleen omdat het containers kon draaien. Het won omdat het standaard-API's bood voor de meest voorkomende operationele behoeften — deployen, schalen, netwerken en observeren van workloads. Als teams het eens zijn over dezelfde “vorm” van objecten (zoals Deployments, Services, Jobs), kunnen tools worden gedeeld tussen organisaties, is training eenvoudiger en stoppen overdrachten tussen dev en ops met te vertrouwen op mondelinge kennis.
Waarom standaard-API's teamworkflows veranderen
Een consistente API betekent dat je deployment-pijplijn niet de eigenaardigheden van elke app hoeft te kennen. Het kan dezelfde handelingen uitvoeren — create, update, roll back en check health — met dezelfde Kubernetes-concepten.
Het verbetert ook afstemming: security-teams kunnen guardrails als policies uitdrukken; SRE's kunnen runbooks standaardiseren rond gemeenschappelijke health-signalen; ontwikkelaars kunnen releases bespreken met een gedeeld vocabulaire.
Kubernetes uitbreiden: CRD's en Operators
De “platform”-verschuiving wordt duidelijk met Custom Resource Definitions (CRD's). Een CRD laat je een nieuw type object toevoegen aan de cluster (bijvoorbeeld Database, Cache of Queue) en het te beheren met dezelfde API-patronen als ingebouwde resources.
Een Operator koppelt die custom objects aan een controller die continu realiteit naar gewenste staat reconcileert — en taken automatiseert die vroeger handmatig waren, zoals backups, failovers of versie-upgrades. Het belangrijkste voordeel is geen magische automatisering; het is hergebruik van dezelfde control loop-aanpak die Kubernetes op alles toepast.
Pasvorm met GitOps, CI/CD en policy checks
Omdat Kubernetes API-gedreven is, integreert het soepel met moderne workflows:
- GitOps: de gewenste staat leeft in Git; wijzigingen worden als code beoordeeld.
- CI/CD: pipelines kunnen manifests toepassen, wachten op readiness en versies promoten.
- Policy checks: admission controllers kunnen risicovolle configuraties blokkeren voordat ze in productie komen.
Als je meer praktische deployment- en ops-gidsen wilt die op deze ideeën bouwen, blader dan naar /blog.
Wat teams vandaag kunnen toepassen (ook buiten Kubernetes)
De grootste Kubernetes-ideeën — veel ervan geassocieerd met Brendan Burns’ vroege framing — vertalen goed, zelfs als je op VMs, serverless of een kleinere containeromgeving draait.
Patronen die de dagelijkse operatie verbeteren
Leg de “gewenste staat” vast en laat automatisering die afdwingen. Of het nu Terraform, Ansible of een CI-pijplijn is, behandel configuratie als de bron van waarheid. Het resultaat is minder handmatige deploy-stappen en veel minder “het werkte op mijn machine”-verrassingen.
Gebruik reconciliatie, geen eenmalige scripts. In plaats van scripts die één keer draaien en op hoop vertrouwen, bouw lussen die continu belangrijke eigenschappen verifiëren (versie, config, aantal instances, health). Zo krijg je herhaalbare ops en voorspelbaar herstel na fouten.
Maak scheduling en schalen expliciete productfeatures. Definieer wanneer en waarom je capaciteit toevoegt (CPU, queue-diepte, latency SLO's). Zelfs zonder Kubernetes-autoscaling kunnen teams schaalregels standaardiseren zodat groei geen herschrijven van de app of nachtelijke oproepen vereist.
Standaardiseer rollouts. Rollende updates, health checks en snelle rollback-procedures verminderen het risico van wijzigingen. Je kunt dit implementeren met load balancers, feature flags en deployment-pijplijnen die releases op echte signalen gate.
Een veilige adoptie-checklist
- Definieer de gewenste staat van een service: versie, config, afhankelijkheden en minimaal aantal instanties
- Voeg health endpoints toe (liveness- en readiness-equivalenten) en koppel ze aan je load balancer of deployment-pijplijn
- Automatiseer rollout-stappen: deploy, verifieer, verschuif verkeer en rollback bij falen
- Maak een kleine “reconciler”: geplande checks die drift corrigeren (verkeerde config, ontbrekende instances)
- Voeg schaaltriggers toe met duidelijke limieten (max instanties, cooldowns, goedkeuringsregels)
Wat dit niet oplost
Deze patronen lossen geen slecht app-design, onveilige datamigraties of kostenbeheersing op. Je hebt nog steeds versiebeheerde API's, migratieplannen, budgettering/limieten en observability nodig die deploys koppelt aan klantimpact.
Volgende stappen
Kies één customer-facing service en voer de checklist end-to-end uit, breid daarna uit.
Als je nieuwe services bouwt en sneller naar “iets deployables” wilt, kan Koder.ai je helpen een volledige web/backend/mobiele app te genereren vanuit een chat-gestuurde specificatie — typisch React voor frontend, Go met PostgreSQL voor backend en Flutter voor mobiel — en daarna de broncode exporteren zodat je dezelfde Kubernetes-patronen kunt toepassen die hier besproken zijn (declaratieve configs, herhaalbare rollouts en rollback-vriendelijke operaties). Voor teams die kosten en governance evalueren, kun je ook /pricing reviewen.