21 sep 2025·8 min
Hoe C en C++ nog steeds het hart vormen van besturingssystemen, databases en game-engines
Ontdek hoe C en C++ nog steeds de kern vormen van besturingssystemen, databases en game-engines — door controle over geheugen, snelheid en toegang op laag niveau.
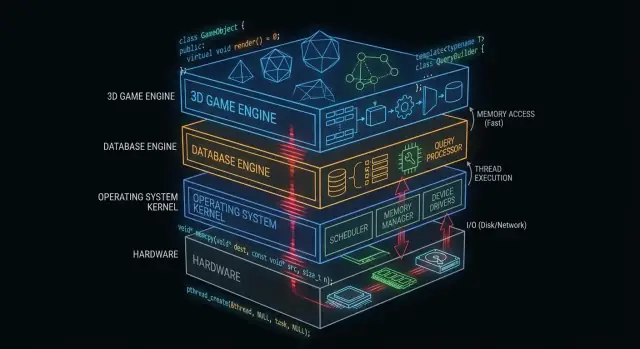
Waarom C en C++ nog steeds achter de schermen belangrijk zijn
"Onder de motorkap" is alles waarop je app vertrouwt maar zelden direct mee werkt: kernels van besturingssystemen, device drivers, storage-engines van databases, netwerkstacks, runtimes en prestatiekritische bibliotheken.
Daartegenover staat dat veel applicatieontwikkelaars dagelijks vooral het oppervlak zien: frameworks, API's, managed runtimes, package managers en clouddiensten. Die lagen zijn ontworpen om veilig en productief te zijn—ook wanneer ze complexiteit bewust verbergen.
Waarom sommige lagen dicht bij de hardware moeten blijven
Sommige softwarecomponenten stellen eisen die lastig zijn te halen zonder directe controle:
- Voorspelbare performance en latency (bijv. CPU-scheduling, afhandelen van interrupts, streamen van assets)
- Precieze geheugencoupling (layout, alignment, cachegedrag, voorkomen van pauzes)
- Directe hardwaretoegang (registers, DMA, drivers, filesystems en block devices)
- Kleine, draagbare binaries die vroeg in het bootproces of in beperkte omgevingen kunnen draaien
C en C++ komen hier nog vaak voor omdat ze naar native code compileren met minimale runtime-overhead en ontwikkelaars fijne controle geven over geheugen en systeemcalls.
Waar C en C++ vandaag de dag het meest voorkomen
Op een hoog niveau vind je C en C++ in:
- Kernen van besturingssystemen en low-level libraries
- Drivers en embedded firmware
- Database-engines (query-uitvoering, opslag, indexering)
- Game-engines en real-time subsystemen (rendering, physics, audio)
- Compilers, toolchains en taalruntimes waarop andere talen vertrouwen
Wat dit artikel wel (en niet) behandelt
Dit artikel richt zich op de mechanica: wat deze "achter de schermen" componenten doen, waarom ze profiteren van native code, en welke afwegingen bij die kracht horen.
Het beweert niet dat C/C++ de beste keuze is voor elk project, en het ontwikkelt zich niet tot een taalruzie. Het doel is praktische duidelijkheid over waar deze talen nog steeds hun waarde bewijzen—en waarom moderne softwarestacks erop blijven bouwen.
Wat C en C++ geschikt maakt voor systeemsoftware
C en C++ worden veel gebruikt voor systeemssoftware omdat ze "dicht op het metaal" programma's mogelijk maken: klein, snel en nauw geïntegreerd met het OS en de hardware.
Gecompileerd naar native code (in gewone taal)
Wanneer C/C++-code gecompileerd wordt, wordt het machine-instructies die de CPU direct kan uitvoeren. Er is geen vereiste runtime die instructies tijdens uitvoering vertaalt.
Dat is van belang voor infrastructuurcomponenten—kernels, database-engines, game-engines—waar zelfs kleine overheads zich kunnen opstapelen onder belasting.
Voorspelbare performance voor kerninfrastructuur
Systeemssoftware heeft vaak consistente timing nodig, niet alleen een goede gemiddelde snelheid. Bijvoorbeeld:
- Een scheduler van een besturingssysteem moet snel reageren onder load.
- Een database moet latency stabiel houden terwijl veel gebruikers tegelijk query's uitvoeren.
- Een game-engine moet binnen een frametijdbudget blijven (bijv. ~16 ms voor 60 FPS).
C/C++ bieden controle over CPU-gebruik, geheugenlayout en datastructuren, wat engineers helpt voorspelbare performance te bereiken.
Directe geheugen- en pointertoegang
Pointers laten je direct met geheugensadressen werken. Die macht klinkt intimiderend, maar maakt mogelijkheden mogelijk die veel hogere talen abstraheren:
- Aangepaste allocators afgestemd op specifieke workloads
- Compacte in-memory formaten (handig in databases en caches)
- Zero-copy I/O-patronen waarbij data niet steeds wordt gedupliceerd
Zorgvuldig gebruikt kan dit niveau van controle dramatische efficiëntiewinsten opleveren.
Afwegingen: veiligheid, complexiteit en ontwikkelingstijd
Dezelfde vrijheid brengt ook risico's met zich mee. Veelvoorkomende afwegingen zijn:
- Veiligheid: fouten kunnen crashes, datacorruptie of beveiligingslekken veroorzaken.
- Complexiteit: handmatig geheugenbeheer en undefined behavior vragen discipline.
- Ontwikkeltijd: testen, review en tooling worden onmisbaar voor betrouwbaarheid.
Een veelgebruikte aanpak is het performance-kritieke hart in C/C++ te houden en deze te omringen met veiligere talen voor productfeatures en UX.
C/C++ in besturingssysteemkernels
De kernel van een besturingssysteem zit het dichtst bij de hardware. Wanneer je laptop wakker wordt, je browser opent of een programma meer RAM vraagt, coördineert de kernel die verzoeken en bepaalt wat er gebeurt.
Wat een kernel in de praktijk doet
In de praktijk behandelt een kernel een paar kerntaken:
- Scheduling: beslissen welk programma (en welke thread) CPU-tijd krijgt en hoe lang.
- Geheugenbeheer: geheugen toewijzen aan processen, isolatie handhaven en geheugen veilig terugwinnen.
- Apparaatbeheer: communiceren met hardware via drivers (disk, netwerk, keyboard, GPU, enz.).
- Beveiligingsgrenzen: permissies afdwingen zodat het ene programma niet het andere kan lezen of corrupt maken.
Omdat deze verantwoordelijkheden centraal in het systeem zitten, is kernelcode zowel performance-gevoelig als correctheidsgevoelig.
Waarom strakke controle C (en soms C++) bevoordeelt
Kernelontwikkelaars hebben precieze controle nodig over:
- Geheugenlayout: vaste-waarde structuren, alignment en voorspelbaar allocatiegedrag.
- CPU-instructies en calling conventions: omgaan met interrupts, context switches en low-level synchronisatie.
- Hardwareregisters: specifieke adressen lezen/schrijven en speciale CPU-modi afhandelen.
C blijft een veelgebruikte "kernentaal" omdat het netjes op machineconcepten mappt en tegelijk leesbaar en portabel blijft over architecturen. Veel kernels gebruiken ook assembly voor de kleinst mogelijke, hardware-specifieke delen, terwijl C het grootste deel doet.
C++ kan in kernels voorkomen, maar meestal in een beperkte stijl (beperkte runtime-features, zorgvuldige exception-beleid en strikte regels rond allocatie). Waar het gebruikt wordt, is het vaak om abstractie te verbeteren zonder controle op te geven.
Kernel-gerelateerde code die vaak in C/C++ geschreven is
Zelfs als de kernel voorzichtig is, zijn veel aangrenzende componenten C/C++:
- Device drivers (vooral prestatiekritische)
- Standaardbibliotheken en runtimes (delen van libc, low-level threading)
- Bootloaders en vroege opstartcode
- Systeemservices die native snelheid nodig hebben (bijv. netwerk- of opslaghelpers)
Voor meer over hoe drivers software en hardware verbinden, zie /blog/device-drivers-and-hardware-access.
Device drivers en hardwaretoegang
Device drivers vertalen tussen een besturingssysteem en fysieke hardware—netwerkkaarten, GPU's, SSD-controleurs, audioapparaten en meer. Wanneer je op "play" klikt, een bestand kopieert of verbinding maakt met Wi‑Fi, is een driver vaak de eerste code die moet reageren.
Omdat drivers op het hot path van I/O liggen, zijn ze extreem prestatiegevoelig. Een paar extra microseconden per pakket of schijfopdracht telt snel op op drukke systemen. C en C++ blijven hier gebruikelijk omdat ze rechtstreeks OS-kernel-API's kunnen aanroepen, geheugenlayout precies kunnen controleren en met minimale overhead kunnen draaien.
Interrupts, DMA en waarom low-level API's ertoe doen
Hardware wacht niet keurig op zijn beurt. Devices signaleren de CPU via interrupts—dringende meldingen dat er iets is gebeurd (er kwam een pakket binnen, een transfer is klaar). Drivercode moet deze events snel en correct afhandelen, vaak onder strikte timing- en threading-constraints.
Voor hoge throughput vertrouwen drivers ook op DMA (Direct Memory Access), waarbij devices systeemgeheugen lezen/schrijven zonder dat de CPU elke byte kopieert. DMA-setup omvat meestal:
- Buffers voorbereiden in het juiste formaat en met de juiste alignment
- Devices fysieke adressen of gemapte descriptors geven
- Eigendom van geheugen tussen device en CPU synchroniseren
Deze taken vereisen low-level interfaces: memory-mapped registers, bitflags en zorgvuldige lees-/schrijfreeksen. C/C++ maken het praktisch om dit soort "dicht op het metaal" logica uit te drukken en toch draagbaar te blijven tussen compilers en platforms.
Stabiliteit is niet onderhandelbaar
In tegenstelling tot een normale app kan een driverfout het hele systeem laten crashen, data corrupt maken of beveiligingslekken openen. Dat risico bepaalt hoe drivercode geschreven en reviewed wordt.
Teams verkleinen gevaar met strikte coding-standaarden, defensieve checks en gelaagde reviews. Veelgebruikte praktijken zijn het beperken van onveilig pointergebruik, valideren van input van hardware/firmware en statische analyse in CI draaien.
Geheugenbeheer: kracht en valkuilen
Keep native code isolated
Prototypeer een FFI-grens en koppel je app aan bestaande C- of C++-code.
Geheugenbeheer is een van de grootste redenen waarom C en C++ delen van besturingssystemen, databases en game-engines domineren. Het is ook een van de gemakkelijkste plekken om subtiele bugs te introduceren.
Wat "geheugenbeheer" betekent
In de praktijk omvat geheugenbeheer:
- Alloceren van geheugen (een blok krijgen om data in op te slaan)
- Vrijgeven daarvan (teruggeven wanneer je klaar bent)
- Omgaan met fragmentatie (overgebleven gaten die toekomstige allocaties trager of moeilijker maken)
In C gebeurt dit vaak expliciet (malloc/free). In C++ kan het expliciet zijn (new/delete) of verpakt in veiligere patronen.
Waarom handmatige controle een voordeel kan zijn
In prestatiekritische componenten kan handmatige controle een voordeel zijn:
- Je kunt onvoorspelbare pauzes door garbage collection vermijden.
- Je kunt kiezen waar en hoe geheugen wordt toegewezen (bijv. pooled of arena-allocators), wat consistentie verbetert.
- Je kunt allocatiepatronen afstemmen op echte workloads (veel kleine objecten versus grote aaneengesloten buffers).
Dit is belangrijk wanneer een database stabiele latency moet behouden of een game-engine een frametijdbudget moet halen.
Veelvoorkomende foutmodi (en waarom ze ernstig zijn)
Dezelfde vrijheid creëert klassieke problemen:
- Memory leaks: vergeten geheugen vrij te geven, waardoor gebruik groeit totdat performance degradeert of het proces crasht.
- Buffer overflows: voorbij het einde van een array schrijven, data corruptie of exploits mogelijk maken.
- Use-after-free: een pointer gebruiken nadat het vrijgegeven is, wat tot moeilijk reproduceerbare crashes leidt.
Deze bugs zijn vaak subtiel omdat het programma "leek prima" te werken totdat een specifieke workload falen veroorzaakt.
Hoe moderne praktijken helpen
Modern C++ reduceert risico zonder controle op te geven:
- RAII (Resource Acquisition Is Initialization) koppelt resource-lifetime aan scope zodat cleanup automatisch gebeurt.
- Smart pointers (zoals
std::unique_ptrenstd::shared_ptr) maken ownership expliciet en voorkomen veel leaks. - Sanitizers (AddressSanitizer, UndefinedBehaviorSanitizer) en statische analyse vangen problemen vroeg, vaak in CI.
Goed gebruikt houden deze tools C/C++ snel terwijl ze geheugenbugs minder waarschijnlijk naar productie laten lekken.
Concurrency en multicore-prestaties
Moderne CPU's worden niet dramatisch sneller per core—ze krijgen meer cores. Daardoor verschuift de prestatievraag van "Hoe snel is mijn code?" naar "Hoe goed kan mijn code parallel draaien zonder elkaar in de weg te zitten?" C en C++ zijn populair omdat ze low-level controle over threading, synchronisatie en geheugen gedrag geven met zeer weinig overhead.
Threads, cores en scheduling
Een thread is de eenheid waarmee je programma werk doet; een CPU-core is waar dat werk draait. De OS-scheduler mapt runnable threads op beschikbare cores en maakt continu afwegingen.
Kleine scheduling-details doen er toe in prestatiekritische code: een thread op het verkeerde moment pauzeren kan een pipeline stallen, wachtrijen laten oplopen of stop-and-go gedrag veroorzaken. Voor CPU-bound werk vermindert het vaak thrashing wanneer actieve threads ongeveer gelijk zijn aan het aantal cores.
Locking basics: mutexes, atomics en contention
- Mutexes zijn makkelijk te begrijpen, maar veel gedeeld gebruik veroorzaakt contention—tijd die gespendeerd wordt met wachten in plaats van werken.
- Atomics kunnen sneller zijn voor kleine gedeelde updates, maar vereisen zorgvuldige ontwerp om subtiele correctness-bugs te vermijden.
Het praktische doel is niet "nooit locken" maar: minder en slimmer locken—houd kritieke secties klein, vermijd globale locks en reduceer gedeelde mutabele staat.
Waarom latency-spikes ertoe doen
Databases en game-engines geven niet alleen om gemiddelde snelheid, maar om worst-case pauzes. Een lock-convoy, page fault of vastgelopen worker kan zichtbare stutter of een trage query veroorzaken die SLA's schendt.
Veelvoorkomende C/C++-patronen
Veel high-performance systemen gebruiken:
- Threadpools om workers te hergebruiken en scheduling voorspelbaar te houden
- Work-stealing queues om load over cores te balanceren
- Lock-free queues (in selecte hot paths) om blokkeren te verminderen—gebruik met zorg, omdat correctheid lastiger te bewijzen is
Deze patronen streven naar consistente throughput en consistente latency onder druk.
Database-engines: waar C/C++ snelheid levert
Een database-engine is meer dan "rijen opslaan." Het is een strakke lus van CPU- en I/O-werk die miljoenen keren per seconde draait, waarbij kleine inefficiënties snel optellen. Daarom zijn veel engines en kerncomponenten nog grotendeels in C of C++ geschreven.
De hoofdtaken van de engine: parsen, plannen, uitvoeren
Wanneer je SQL stuurt, doet de engine:
- Parsen (tekst omzetten naar een gestructureerde representatie)
- Plannen (een efficiënte manier kiezen om de query te beantwoorden)
- Uitvoeren (scans, index-lookups, joins, sorts, aggregaties en rijen teruggeven)
Elke fase profiteert van zorgvuldige controle over geheugen en CPU-tijd. C/C++ maken snelle parsers mogelijk, minder allocaties tijdens planning en een zuinig uitvoerpad—vaak met aangepaste datastructuren voor de workload.
Storage-engines: pages, indexes, buffering
Onder de SQL-laag regelt de storage-engine de essentiële details:
- Pages: data wordt in vaste blokken gelezen en geschreven, niet rij-voor-rij.
- Indexes: B-trees, LSM-trees en aanverwante structuren moeten efficiënt geüpdatet worden.
- Buffering: een buffer pool bepaalt wat in geheugen blijft, wat wordt uitgezet en hoe reads/writes worden gebatcht.
C/C++ zijn hier een goede match omdat deze componenten vertrouwen op voorspelbare geheugenlayout en directe controle van I/O-grenzen.
Cachevriendelijke datastructuren (en waarom dat telt)
Moderne performance hangt vaak meer van CPU-caches af dan van ruwe CPU-snelheid. Met C/C++ kunnen ontwikkelaars veelgebruikte velden naast elkaar plaatsen, kolommen in aaneengesloten arrays opslaan en pointer-chasing minimaliseren—patronen die data dicht bij de CPU houden en stalls verminderen.
Waar hogere talen toch opduiken
Zelfs in C/C++-zware databases gebruiken teams hogere talen voor admin-tools, backups, monitoring, migraties en orkestratie. De prestatiekritieke kern blijft native; het omliggende ecosysteem kiest iteratiesnelheid en gebruiksgemak.
Opslag, caching en I/O in databases
Build the mobile surface
Maak een Flutter mobiele app en houd productiteratie los van laag-niveau optimalisatiewerk.
Databases lijken direct te reageren omdat ze hard werken om disk te vermijden. Zelfs op snelle SSD's is lezen van opslag orders of grootte langzamer dan lezen uit RAM. Een database-engine in C of C++ kan elke stap van die wachttijd controleren—en vaak vermijden.
Buffer pool en page cache in alledaagse bewoordingen
Zie data op schijf als dozen in een magazijn. Een doos ophalen (disk read) kost tijd, dus je houdt meest gebruikte items op een bureau (RAM).
- Buffer pool: de database's eigen "bureau" met recent gebruikte pages (vaste blokken van tabellen en indexes).
- Page cache: het OS-bureau dat recent gelezen bestanddata cachet.
Veel databases beheren hun eigen buffer pool om te voorspellen wat hot moet blijven en te voorkomen dat ze met het OS over geheugen concurreren.
Waarom disk traag is—en hoe caching het verbergt
Opslag is niet alleen traag; het is ook onvoorspelbaar. Latency-spikes, wachtrijen en random access voegen vertraging toe. Caching verbergt dit door:
- Reads meestal uit RAM te serveren
- Writes te batchen in minder, grotere I/O-operaties
- Pages voor te laden die waarschijnlijk vervolgd nodig zijn (bijv. tijdens indexscans)
Ontwerpkeuzes die profiteren van laag-niveau controle
C/C++ laten database-engines details tunen die bij hoge throughput belangrijk zijn: aligned reads, direct I/O vs. buffered I/O, aangepaste evictionpolicies en zorgvuldig gestructureerde in-memory layouts voor indexes en logbuffers. Deze keuzes kunnen kopieën verminderen, contention vermijden en CPU-caches met nuttige data voeden.
Compressie en checksums kunnen CPU-bound zijn
Caching vermindert I/O, maar verhoogt CPU-werk. Pages decompressen, checksums berekenen, logs versleutelen en records valideren kunnen bottlenecks worden. Omdat C en C++ controle bieden over geheugenpatronen en SIMD-vriendelijke lussen, worden ze vaak gebruikt om meer werk uit elke core te persen.
Game-engines: real-time eisen
Game-engines werken met strikte real-time verwachtingen: de speler beweegt de camera, drukt op een knop en de wereld moet direct reageren. Dat wordt gemeten in frametijd, niet in gemiddelde throughput.
Frame-budgets: waarom milliseconden tellen
Bij 60 FPS heb je ongeveer 16,7 ms om een frame te produceren: simulatie, animatie, physics, audio-mixing, culling, rendering-submission en vaak asset streaming. Bij 120 FPS daalt dat budget naar 8,3 ms. Overschrijding van het budget leidt tot stotteren, input-lag of inconsistente pacing.
Dit is waarom C-programmering en C++-programmering nog steeds veel voorkomen in enginekernen: voorspelbare performance, lage overhead en fijne controle over geheugen en CPU-gebruik.
Kernsubsystemen vaak in C/C++
De meeste engines gebruiken native code voor zware onderdelen:
- Rendering (scene traversal, draw-call building, GPU-resource management)
- Physics (collision detection, constraints, rigid bodies)
- Animatie (skeletal blending, IK, pose-evaluatie)
- Audio (real-time mixing, spatialization)
Deze systemen draaien elk frame, dus kleine inefficiënties vermenigvuldigen zich snel.
Strakke lussen en data-layout
Veel game-performance draait om strakke lussen: entiteiten itereren, transforms updaten, botsingen testen, vertices skinnen. C/C++ maken het eenvoudiger geheugen in te richten voor cache-efficiëntie (aaneengesloten arrays, minder allocaties, minder virtuele indirections). Data-layout kan even belangrijk zijn als algoritmekeuze.
Waar scripting past (en waar niet)
Veel studio's gebruiken scriptingtalen voor gameplaylogica—quests, UI-regels, triggers—omdat iteratiesnelheid telt. De engine-kern blijft native en scripts roepen C/C++-systemen aan via bindings. Een gangbaar patroon: scripts orkestreren; C/C++ voert de dure delen uit.
Compilers, toolchains en interoperabiliteit
Go from code to running
Deploy en host wat je bouwt, en verbeter het daarna met dezelfde chatworkflow.
C en C++ "lopen" niet zomaar—ze worden gebouwd tot native binaries die bij een specifieke CPU en OS passen. Die build-pijplijn is een belangrijke reden dat deze talen centraal staan in OS'en, databases en game-engines.
Wat er daadwerkelijk tijdens een build gebeurt
Een typische build kent enkele stappen:
- Compiler: zet C/C++-bron om in machine-specifieke objectbestanden.
- Linker: naait objecten en libraries samen tot een executable of shared library.
- Binary output: het uiteindelijke artifact dat het OS direct kan laden (vaak met aparte debug-symbolen).
In de linkerfase komen veel praktische issues naar boven: ontbrekende symbolen, mismatchende libraryversies of incompatibele build-instellingen.
Waarom toolchains en platformondersteuning ertoe doen
Een toolchain is de volledige set: compiler, linker, standaardbibliotheek en buildtools. Voor systeemssoftware is platformdekking vaak doorslaggevend:
- Console- en mobiele SDK's kunnen specifieke compilers en linkers vereisen.
- Databases en backendsoftware hebben stabiele builds nodig over Linux-distributies en CPU-types.
- OS- en driverwerk kan cross-compilers, strikte flags en ABI-discipline vereisen.
Teams kiezen vaak C/C++ mede omdat toolchains volwassen en beschikbaar zijn in vele omgevingen—van embedded devices tot servers.
Interfacen met andere talen (FFI)
C wordt vaak behandeld als de "universele adapter." Veel talen kunnen C-functies aanroepen via FFI, dus teams plaatsen prestatiekritische logica in een C/C++-bibliotheek en exposen een kleine API naar hogere taalcode. Daarom wrappen Python, Rust, Java en anderen vaak bestaande C/C++-componenten in plaats van ze volledig te herschrijven.
Debuggen en profileren: wat teams meten
C/C++-teams meten doorgaans:
- CPU-tijd (hot functions, call stacks)
- Geheugengebruik (allocaties, leaks, fragmentatie)
- Latency (frametijd in games, querytijd in databases)
- I/O-gedrag (cache-misses, disk-reads, syscalls)
De workflow is consistent: vind de bottleneck, bevestig met data, optimaliseer vervolgens het kleinste stukje dat er toe doet.
C/C++ kiezen vandaag: praktische besliswijzer
C en C++ zijn nog steeds uitstekende tools—wanneer je software bouwt waar een paar milliseconden, een paar bytes of een specifieke CPU-instructie echt belangrijk zijn. Ze zijn niet automatisch de beste keuze voor elk onderdeel of team.
Wanneer C/C++ de juiste keuze is
Kies C/C++ als de component prestatiekritisch is, strakke geheugencontrole nodig heeft of nauw met het OS of hardware moet integreren.
Typische toepassingen:
- Hot paths waar latency zichtbaar is (parsen, compressie, rendering, query-executie)
- Low-level modules die voorspelbaar moeten zijn (allocators, schedulers, netwerkprimitives)
- Cross-platform libraries waar native code het product is (SDK's, engines, embedded)
- Situaties waar draagbaarheid tussen compilers/toolchains een harde eis is
Wanneer je andere talen moet prefereren
Kies een hoger-niveau taal wanneer prioriteit ligt bij veiligheid, iteratiesnelheid of onderhoudbaarheid op schaal.
Het is vaak verstandiger Rust, Go, Java, C#, Python of TypeScript te gebruiken wanneer:
- Het team groot is en personeelsverloop verwacht wordt (minder voetguns helpt)
- De feature vaak verandert en correctheid belangrijker is dan seconden winnen
- Je sterke geheugenveiligheidsgaranties nodig hebt
- Productiviteit en de hiringpool belangrijker zijn dan ruwe snelheid
In de praktijk zijn de meeste producten een mix: native libraries voor het kritieke pad en hogere-level services en UIs voor de rest.
Een praktische noot voor app-teams (waar Koder.ai past)
Als je vooral web-, backend- of mobiele features bouwt, hoef je meestal geen C/C++ te schrijven om er van te profiteren—je gebruikt het via je OS, database, runtime en dependencies. Platforms zoals Koder.ai spelen in op die scheiding: je kunt snel React-webapps, Go + PostgreSQL-backends of Flutter-mobileapps maken via een chatgestuurde workflow, en toch native componenten integreren wanneer dat nodig is (bijv. aanroepen van een bestaande C/C++-bibliotheek via een FFI-grens). Zo blijft een groot deel van je product snel iterateerbaar, zonder de plekken te negeren waar native code de juiste tool is.
Praktische checklist (component per component)
Stel deze vragen voordat je je vastlegt:
- Staat dit op het kritieke pad? Meet eerst; gok niet.
- Wat zijn de faalwijzen? Geheugencorruptie in C/C++ kan catastrofaal zijn.
- Wat is de interfacegrens? Kun je native code isoleren achter een kleine API?
- Heb je de expertise? Review, testen en profileren zijn ononderhandelbaar.
- Wat is het deploymentdoel? Consoles, embedded, kernels en drivers neigen naar C/C++.
- Hoe ga je het testen en profileren? Plan tooling en CI vanaf dag één.
Aangeraden volgende lectuur
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing