Waarom caching helpt — en waarom het systemen bemoeilijkt
Caching houdt een kopie van data dicht bij waar het nodig is, zodat requests sneller beantwoord kunnen worden zonder telkens naar core-systemen te hoeven. Het resultaat is meestal een mix van snelheid (lagere latency), kosten (minder dure databasereads of upstream calls) en stabiliteit (origin-services overleven verkeerspieken).
Het voordeel: minder werk voor de origin
Wanneer een cache een request kan beantwoorden, doet je “origin” (app-servers, databases, third-party APIs) minder. Die reductie kan dramatisch zijn: minder queries, minder CPU-cycli, minder netwerk-hops en minder kans op timeouts.
Caching dempt ook pieken—waardoor systemen die op gemiddelde load zijn afgesteld piekmomenten kunnen verwerken zonder meteen te schalen (of te falen).
De verborgen ruil: meer werk voor engineers
Caching verwijdert werk niet; het verplaatst het naar ontwerp en operatie. Je krijgt nieuwe vragen:
- Wat moet er gecached worden?
- Hoe lang?
- Wat gebeurt er als data verandert?
- Hoe voorkom je verouderde of onjuiste resultaten?
- Hoe debug je problemen als een cache het gedrag van de origin “verbergt”?
Elke cachinglaag voegt configuratie, monitoring en randgevallen toe. Een cache die 99% van de requests sneller maakt, kan nog steeds pijnlijke incidenten veroorzaken in die 1%: gesynchroniseerde expiraties, inconsistente gebruikerservaringen of plotselinge influx naar de origin.
Cachinglaag vs. een enkele cache
Een enkele cache is één opslag (bijvoorbeeld een in-memory cache naast je applicatie). Een cachinglaag is een apart checkpoint in het requestpad—CDN, browsercache, applicatiecache, databasecache—elk met eigen regels en faalwijzen.
Dit artikel richt zich op de praktische complexiteit die meerdere lagen introduceren: correctheid, invalidatie en operatie (niet op low-level cache-algoritmen of vendor-specifieke tuning).
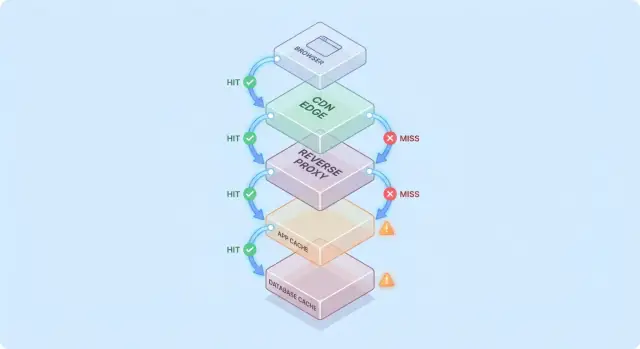
Een simpel model: request-flow door meerdere lagen
Caching wordt makkelijker te begrijpen als je je een request voorstelt dat een stapel “misschien heb ik het al” checkpoints doorloopt.
Typisch requestpad
Een gangbaar pad ziet er zo uit:
- Client → Edge (CDN) → App → Database
Op elke hop kan het systeem ofwel een gecachte response teruggeven (hit) of het request doorsturen naar de volgende laag (miss). Hoe eerder de hit plaatsvindt (bijv. aan de edge), hoe meer load je voorkomt dieper in de stack.
Hits zijn fijn; misses zijn de echte test
Hits laten dashboards goed uitzien. Misses zijn waar complexiteit verschijnt: ze triggeren echt werk (app-logica, databasequeries) en voegen overhead toe (cache-lookups, serialisatie, cache-writes).
Een nuttig mentaal model is: elke miss betaalt dubbel voor de cache—je doet nog steeds het oorspronkelijke werk, plus het caching-werk eromheen.
Hoe lagen knelpunten verplaatsen
Een extra cachelaag elimineert zelden een bottleneck; vaak verplaatst het die:
- Een CDN kan druk van de app wegnemen, maar verhoogt de gevoeligheid voor cacheconfiguratie en purge-snelheid.
- Een applicatiecache kan database-load verminderen, maar maakt app-tier CPU/geheugen de nieuwe beperkende factor.
- Databasecaching (buffer pools, plan caches) kan trage queries verbergen totdat de working set niet meer past.
Eenvoudig "tweemaal gecached" voorbeeld
Stel dat je productpagina 5 minuten bij de CDN gecached is, en de app daarnaast productdetails 30 minuten in Redis cached.
Als een prijs verandert, kan de CDN snel verversen terwijl Redis de oude prijs blijft serveren. Nu hangt de “waarheid” af van welke laag het request beantwoordde—een vroeg voorbeeld waarom cachelagen load verminderen maar systeemcomplexiteit verhogen.
Veelvoorkomende cachinglagen en waar ze goed in zijn
Caching is geen enkelvoudige feature—het is een stapel plekken waar data opgeslagen en hergebruikt kan worden. Elke laag kan load verminderen, maar heeft verschillende regels voor versheid, invalidatie en zichtbaarheid.
Browser- en OS-caches (wat je controleert vs. wat niet)
Browsers cachen afbeeldingen, scripts, CSS en soms API-responses op basis van HTTP-headers (zoals Cache-Control en ETag). Dit kan herhaalde downloads volledig elimineren—goed voor performance en het verlagen van CDN/origin traffic.
Het nadeel: zodra een response client-side gecached is, heb je niet volledige controle over revalidatietiming. Sommige gebruikers houden oudere assets langer (of legen de cache onverwacht), dus versie-URL's (bijv. app.3f2c.js) zijn een veelgebruikt vangnet.
CDN/edge-caching voor statische en semi-statische content
Een CDN cachet content dichtbij gebruikers. Het blinkt uit voor statische bestanden, publieke pagina's en “meestal stabiele” responses zoals productafbeeldingen, documentatie of rate-limited API-endpoints.
CDN's kunnen ook semi-statische HTML cachen als je zorgvuldig omgaat met variatie (cookies, headers, geo, device). Verkeerd ingestelde variationregels zijn een veelvoorkomende bron van het serveren van de verkeerde content aan de verkeerde gebruiker.
Reverse proxy caching (gateway-niveau)
Reverse proxies (zoals NGINX of Varnish) zitten voor je applicatie en kunnen hele responses cachen. Dit is nuttig als je centrale controle wilt, voorspelbare eviction en snelle bescherming van origin-servers tijdens traffic-pieken.
Het is meestal minder wereldwijd gedistribueerd dan een CDN, maar makkelijker af te stemmen op je app-routes en headers.
Applicatie-level caching (in-memory, Redis, Memcached)
Deze cache richt zich op objecten, berekende resultaten en dure calls (bijv. “user profile by id” of “pricing rules for region”). Het is flexibel en kan bewust gemaakt worden van businesslogica.
Het introduceert ook meer beslispunten: key-design, TTL-keuzes, invalidatielogica en operationele behoeften zoals sizing en failover.
Databasecaching en query/result-caching
De meeste databases cachen pagina's, indexen en queryplannen automatisch; sommige ondersteunen result-caching. Dit kan herhaalde queries versnellen zonder dat je applicatiecode hoeft te veranderen.
Bekijk het als een bonus, niet als een garantie: databasecaches zijn meestal het minst voorspelbaar bij diverse querypatronen, en ze nemen de kosten van writes, locks of contentie niet weg zoals upstream caches dat kunnen.
Waar caching de grootste loadreductie oplevert
Caching loont het meest wanneer het herhaalde, dure backend-operaties verandert in een goedkope lookup. De kunst is de cache te matchen met workloads waar requests genoeg op elkaar lijken—en stabiel genoeg zijn—zodat hergebruik hoog is.
Read-heavy workloads en dure berekeningen
Als je systeem veel meer reads dan writes serveert, kan caching een groot deel van database- en applicatiewerk wegnemen. Productpagina's, publieke profielen, helpcenter-artikelen en vaak gevraagde zoek-/filterresultaten krijgen vaak dezelfde parameters.
Caching helpt ook bij “dure” werkzaamheden die niet strikt database-gebonden zijn: PDF-generatie, afbeeldingen schalen, templates renderen of aggregaten berekenen. Zelfs een korte cache (seconden tot minuten) kan herhaalde berekening tijdens drukte samenvoegen.
Spiky traffic en burst-bescherming
Caching is vooral effectief bij ongelijk verkeer. Als een marketingmail, nieuwsbericht of social post een stroom gebruikers naar dezelfde URL's stuurt, kan een CDN of edge-cache het merendeel van die piek absorberen.
Dit vermindert load niet alleen door snellere responses: het voorkomt autoscale-thrashing, database connection exhaustion en koopt tijd voor rate limits en backpressure om te werken.
Hoge latency backends en cross-region gebruikers
Als je backend ver van je gebruikers staat—letterlijk (cross-region) of logisch (een trage dependency)—kan caching zowel load als ervaren traagheid verminderen. Content serveren vanuit een CDN-cache dicht bij de gebruiker vermijdt herhaalde lange reizen naar de origin.
Interne caching helpt ook als de bottleneck een hoge-latency store is (een remote database, third-party API of shared service). Minder calls verlagen concurrency-druk en verbeteren tail-latency.
Wanneer caching weinig zin heeft
Caching levert minder op als responses sterk gepersonaliseerd zijn (per-user data, gevoelige accountdetails) of als onderliggende data constant verandert (live dashboards, snel wijzigende voorraden). In die gevallen zijn hitrates laag, invalidatiekosten hoog en de bespaarde backend-arbeid marginaal.
Een praktische regel: caching is het meest waardevol wanneer veel gebruikers binnen een tijdsvenster om hetzelfde vragen en dat “zelfde” geldig blijft. Als die overlap ontbreekt, kan een extra cachinglaag complexiteit toevoegen zonder veel load te reduceren.
Cache invalidatie: de belangrijkste bron van complexiteit
Caching is eenvoudig als data nooit verandert. Zodra het dat doet, krijg je het moeilijkste deel: beslissen wanneer gecachte data onbetrouwbaar wordt en hoe elke cachelaag leert dat iets veranderd is.
TTL-expiratie: simpel, maar zelden “juist”
Time-to-live (TTL) is verleidelijk omdat het één getal is en geen coördinatie vereist. Het probleem is dat de “juiste” TTL afhangt van hoe de data gebruikt wordt.
Als je een TTL van 5 minuten op een productprijs zet, zullen sommige gebruikers na een prijswijziging een oude prijs zien—potentieel een juridisch of support-probleem. Zet je het op 5 seconden, dan reduceer je mogelijk de load nauwelijks. Nog erger: verschillende velden in dezelfde response veranderen met verschillende snelheid (voorraad vs. beschrijving), dus één TTL dwingt een compromis af.
Event-driven invalidatie: accuraat, maar veel coördinatie
Event-driven invalidatie zegt: wanneer de bron van waarheid verandert, publiceer een event en purge/update alle getroffen cache-keys. Dit kan zeer correct zijn, maar het creëert nieuw werk:
- Elk write-pad moet events betrouwbaar uitsturen.
- Elke cachelaag moet subscriben, retryen, dedupliceren en out-of-order levering afhandelen.
- Je hebt een duidelijke mapping nodig van “wat veranderde” naar “welke keys ongeldig maken.”
Die mapping is waar “de twee moeilijke dingen: namen en invalidatie” pijnlijk praktisch wordt. Als je /users/123 cachet en ook “top contributors” lijsten, raakt een gebruikersnaamwijziging meerdere keys. Zonder relaties te tracken serveer je gemengde realiteit.
Patronen: cache-aside vs write-through vs write-back
Cache-aside (app leest/schrijft DB, vult cache) is gebruikelijk, maar invalidatie ligt bij jou.
Write-through (schrijf naar cache en DB samen) vermindert stalenisrisico, maar voegt latency en failure-handling complexiteit toe.
Write-back (schrijf eerst naar cache, flush later) versnelt, maar maakt correctheid en recovery veel moeilijker.
Stale-while-revalidate: doelbewust “goed genoeg”
Stale-while-revalidate serveert licht verouderde data terwijl het op de achtergrond ververst. Het dempt pieken en beschermt de origin, maar is ook een productbeslissing: je kiest expliciet voor “snel en grotendeels actueel” boven “altijd de nieuwste”.
Consistentie-afwegingen en gebruikerszichtbare correctheid
Prototypeer veilig met caching
Bouw een testapp en probeer CDN- plus app-cache regels voordat je productie aanraakt.
Caching verandert wat “correct” betekent. Zonder cache zien gebruikers meestal de laatst gecommitte data (onder normale databasegedragingen). Met caches kunnen gebruikers data zien die iets achterloopt—of inconsistent is tussen schermen—soms zonder duidelijke foutmelding.
Sterke vs eventual consistency (en wat gebruikers echt merken)
Sterke consistentie streeft naar “read-after-write”: als een gebruiker zijn afleveradres bijwerkt, moet de volgende pagina overal het nieuwe adres tonen. Dit voelt intuïtief, maar kan duur zijn als elke write meerdere caches meteen moet purge/refreshen.
Eventual consistency staat korte veroudering toe: de update verschijnt snel, maar niet direct. Gebruikers accepteren dit voor laag-stakes content (zoals view counts), maar niet voor geld, permissies of alles wat direct hun acties beïnvloedt.
Race-condities tussen writes en cache-refresh
Een veelvoorkomend euvel is een write gelijktijdig met cache-repopulatie:
- Gebruiker update een profiel.
- Cache wordt invalidated.
- Een andere request repopuleert de cache vanaf een replica die de update nog niet heeft.
Nu bevat de cache oude data voor de volledige TTL, ook al is de database correct.
Multi-layer inconsistentie: edge zegt A, app zegt B
Met meerdere cachinglagen kunnen verschillende delen van het systeem het oneens zijn:
- CDN retourneert een oudere HTML (“Address: Old St”).
- Applicatiecache retourneert nieuwere JSON (“Address: New St”).
- De UI wordt een mix van beide.
Gebruikers interpreteren dit als “het systeem is kapot”, niet als “het systeem is eventually consistent”.
Versionering vermindert ambiguïteit:
- ETags laten clients/CDN efficiënt revalideren en voorkomen het serveren van verouderde representaties als die veranderd zijn.
- Versioned cache keys (bijv.
user:123:v7) laten je veilig vooruitgaan: een write bumpt de versie en reads schuiven natuurlijk naar de nieuwe key zonder perfect getimede deletes.
Acceptabele veroudering per feature definiëren
De sleutelbeslissing is niet “is verouderde data slecht?” maar waar het slecht is.
Stel expliciete verouderingsbudgetten per feature vast (seconden/minuten/uren) en stem die af op gebruikersverwachting. Zoekresultaten kunnen een minuut achterlopen; rekeningsaldi en toegangscontrole niet. Dit maakt “cache-correctheid” tot een productvereiste die je kunt testen en monitoren.
Faalwijzen: stampedes, hot keys en cache-uitval
Caching faalt vaak op manieren die voelen als “alles werkte, en ineens is alles kapot”. Deze falen betekenen niet dat caching slecht is—ze betekenen dat caches verkeerspatronen concentreren, waardoor kleine veranderingen grote effecten kunnen veroorzaken.
Cold starts en ongelijkmatige load na deploys
Na een deploy, autoscale event of cache-flush kan je cache grotendeels leeg zijn. De volgende verkeersgolf forceert veel requests om direct de database of upstream APIs te raken.
Dit is pijnlijk als verkeer snel toeneemt, omdat de cache dan geen tijd heeft gehad om populaire items te warmen. Als deploys samenvallen met piekgebruik, kun je per ongeluk je eigen load-test creëren.
Cache stampedes (thundering herd)
Een stampede gebeurt wanneer veel gebruikers hetzelfde item opvragen precies als het expiret (of nog niet gecached is). In plaats van één request dat de waarde recomputet, doen honderden of duizenden dat—waardoor de origin overbelast raakt.
Veelvoorkomende mitigaties zijn:
- Request coalescing: laat het eerste request recomputen terwijl anderen wachten op het resultaat.
- Locks / single-flight: handhaaf “slechts één builder” per cache-key.
- Jittered TTLs: randomiseer expiraties zodat keys niet allemaal tegelijk expireren.
Als correctheid het toelaat, kan stale-while-revalidate ook pieken afvlakken.
Hot keys en ongelijke distributie
Sommige keys worden buitenproportioneel populair (een homepage payload, een trending product, een globale configuratie). Hot keys creëren ongelijke load: één cache-node of één backend-pad wordt gehamerd terwijl anderen stil blijven.
Mitigaties omvatten het opsplitsen van grote “globale” keys in kleinere, sharding/partitioning toevoegen, of cachen op een andere laag (bijv. publieke content dichter bij gebruikers via een CDN).
Als de cache down is: kies je fallback
Cache-uitval kan erger zijn dan geen cache, omdat applicaties soms afhankelijk zijn van de cache. Bepaal van tevoren:
- Fail open (omzeil cache, hit origin): betere beschikbaarheid, hoger load-risico.
- Fail closed (geef fouten terug): beschermt origin, slechtere UX.
- Graceful degradation (serveer stale/defaults): vaak het beste compromis.
Wat je ook kiest, rate limits en circuit breakers helpen voorkomen dat een cache-fout een origin-outage wordt.
Operationele overhead: meer bewegende delen om te beheren
Experimenteer met snelle rollback
Gebruik snapshots en rollback om iteraties op caching veilig te maken zonder vast te lopen.
Caching kan load op je origin verminderen, maar vergroot het aantal services dat je dagelijks beheert. Zelfs “managed” caches vragen planning, tuning en incidentrespons.
Meer componenten om te runnen
Een nieuwe cachinglaag is vaak een nieuwe cluster (of in ieder geval een nieuwe tier) met eigen capaciteitslimieten. Teams moeten memory-sizing, eviction-policy en gedrag onder druk bepalen. Als de cache te klein is, ontstaat churn: hitrate daalt, latency stijgt en de origin wordt alsnog gehamsterd.
Configuratie-drift over lagen heen
Caching leeft zelden op één plek. Je kunt een CDN-cache, een applicatiecache en databasecaching hebben—allemaal die regels verschillend interpreteren.
Kleine mismatches stapelen zich op:
- CDN respecteert headers, app-cache gebruikt hard-coded TTLs.
- De ene laag bypassed bij cookies terwijl de andere dat niet doet.
- Purge-regels bestaan op de ene plek maar niet op de andere.
Na verloop van tijd wordt “waarom is dit request gecached?” een archeologisch project.
Operationele taken die je eerder niet had
Caches creëren terugkerend werk: kritische keys warmen na deploys, purgen of revalideren bij datawijziging, resharding bij node-wijzigingen en oefenen wat er gebeurt na een volledige flush.
On-call-complexiteit tijdens incidenten
Wanneer gebruikers verouderde data of plotselinge traagheid melden, hebben responders nu meerdere verdachten: de CDN, de cache-cluster, de app’s cache-client en de origin. Debuggen betekent vaak hitrates, eviction-spikes en timeouts over lagen heen checken—en dan beslissen om te bypassen, te purgen of te schalen.
Observeerbaarheid: aantonen dat de cache echt helpt
Caching is alleen een winst als het backend-werk vermindert en de gebruikers-perceptie verbetert. Omdat requests door meerdere lagen kunnen worden bediend (edge/CDN, applicatiecache, databasecache), heb je observability nodig die antwoordt op:
- Welke laag diende dit request?
- Wat veranderde toen het dat niet deed?
Metrics die echt uitkomst geven
Een hoge hitratio klinkt goed, maar kan problemen verbergen (zoals trage cache-leesacties of constante churn). Volg een kleine set metrics per laag:
- Hit ratio en miss ratio, gesplitst per endpoint of cache-namespace
- Latency per laag (cache read-tijd vs origin-tijd), bij voorkeur p50/p95/p99
- Eviction rate en item age (hoe lang entries blijven voordat ze verwijderd worden)
- Backend load indicators (DB QPS, CPU, connection pool-saturatie) gecorreleerd met cache-hits
Als hitratio stijgt maar totale latency niet verbetert, is de cache mogelijk traag, te geserialiseerd of levert hij te grote payloads terug.
Tracing over lagen heen
Distributed tracing moet laten zien of een request aan de edge, door de app-cache of door de database is bediend. Voeg consistente tags toe zoals cache.layer=cdn|app|db en cache.result=hit|miss|stale zodat je traces kunt filteren en hit-path vs miss-path timing kunt vergelijken.
Logs en alerts zonder data te lekken
Log cache-keys zorgvuldig: vermijd ruwe gebruikersidentifiers, e-mails, tokens of volledige URL's met querystrings. Geef de voorkeur aan genormaliseerde of gehashte keys en log alleen een korte prefix.
Alert op abnormale miss-rate spikes, plotselinge latency-stijgingen bij misses en stampede-signalen (veel gelijktijdige misses voor hetzelfde key-patroon). Scheid dashboards in edge, app en database weergaven, plus één end-to-end paneel dat ze verbindt.
Beveiligings- en privacyrisico's in gecachte responses
Caching herhaalt antwoorden snel—maar kan ook het verkeerde antwoord aan de verkeerde persoon herhalen. Caching-gerelateerde beveiligingsincidenten zijn vaak stil: alles lijkt snel en gezond terwijl data lekt.
Hoe gevoelige data in caches belandt
Een veelvoorkomende fout is het cachen van gepersonaliseerde of vertrouwelijke content (accountdetails, facturen, supporttickets, admin-pagina's). Dit kan op elke laag gebeuren—CDN, reverse proxy of applicatiecache—vooral met brede “cache alles” regels.
Een subtiele lekkage ontstaat als responses session-state bevatten (bijv. een Set-Cookie header) en die gecachte response later aan andere gebruikers wordt geserveerd.
Autorisatiefouten: juiste request, verkeerde kijker
Een klassiek bugpatroon is het cachen van de HTML/JSON voor Gebruiker A en die later serveren aan Gebruiker B omdat de cache-key geen gebruikerscontext bevatte. In multi-tenant systemen moet tenant-identiteit ook in de key zitten.
Vuistregel: als de response afhangt van authenticatie, rollen, geografische locatie, pricing tier, feature flags of tenant, moet je cache-key (of bypass-logic) die afhankelijkheid weerspiegelen.
HTTP-cachinggedrag wordt sterk gestuurd door headers:
Cache-Control: voorkom accidentele opslag met private / no-store waar nodigVary: zorg dat caches responses scheiden op relevante request-headers (bijv. Authorization, Accept-Language)Set-Cookie: vaak een indicatie dat de response niet publiek gecached moet worden
Wanneer helemaal geen caching
Als compliance of risico hoog is—PII, gezondheids-/financiële data, juridische documenten—gebruik dan Cache-Control: no-store en optimaliseer server-side. Voor gemengde pagina's cache alleen niet-gevoelige fragmenten of statische assets en houd gepersonaliseerde data uit gedeelde caches.
Verdedig tegen stampedes
Simuleer stampedes en voeg single-flight of jittered TTL-logica toe in een gecontroleerde omgeving.
Cachinglagen kunnen origin-load verminderen, maar het is zelden “gratis performance”. Beschouw elke nieuwe cache als een investering: je koopt lagere latency en minder backendwerk in ruil voor geld, engineeringtijd en een groter correctheidsoppervlak.
Wat je betaalt vs wat je bespaart
Extra infrastructuurkosten vs verminderde originkosten. Een CDN kan egress en database-reads reduceren, maar je betaalt voor CDN-requests, cache-opslag en soms invalidatiecalls. Een applicatiecache (Redis/Memcached) voegt clusterkosten, upgrades en on-call last toe. Besparingen kunnen zich vertalen naar minder database-replicas, kleinere instance-types of uitgestelde scaling.
Latencywinst vs fresness-kosten. Elke cache introduceert de vraag “hoe verouderd is acceptabel?”. Strikte versheid vereist meer invalidatie-plumbing (en meer misses). Getolereerde veroudering bespaart compute maar kan gebruikersvertrouwen kosten—vooral bij prijzen, beschikbaarheid of permissies.
Engineeringtijd: feature-velocity vs reliability-werk. Een nieuwe laag betekent meestal extra codepaden, meer testing en meer incidentklassen om te voorkomen (stampedes, hot keys, gedeeltelijke invalidatie). Budgetteer doorlopende onderhoudskosten, niet alleen initiële implementatie.
Voer kleine experimenten uit om ROI te meten
Voer een beperkte trial uit voordat je breed uitrolt:
- Kies één endpoint of pagina met duidelijke load (bijv. top 5% traffic).
- Definieer succesmetrics: p95 latency, database QPS, error rate, cache hit ratio.
- Rampie geleidelijk; volg kostenveranderingen naast performance.
- Timebox het experiment en houd een rollback-schakelaar klaar.
Een eenvoudige beslischecklist
Voeg een nieuwe cachinglaag alleen toe als:
- De bottleneck bewezen is (niet geraden) via metrics.
- Er een duidelijk doel is (bijv. DB-reads met 40% verminderen).
- Verouderings- en invalidatieregels expliciet acceptabel zijn.
- Je het kunt monitoren (hit rate, evictions, latency, errors).
- De verwachte besparingen opwegen tegen extra operationele en engineeringkosten op realistische termijn.
Praktische richtlijnen om complexiteit te verminderen bij caching
Caching betaalt het snelst wanneer je het als een productfeature behandelt: het heeft een eigenaar, duidelijke regels en een veilige manier nodig om uit te schakelen.
Begin klein, wijs eigenaarschap toe
Voeg één cachinglaag tegelijk toe (bijv. eerst CDN of applicatiecache), en wijs een direct verantwoordelijke teampersoon aan.
Definieer wie verantwoordelijk is voor:
- configuratiewijzigingen (TTL, bypass-regels)
- capaciteit en eviction-gedrag
- incidentrespons (wat te doen als het fout gaat)
Maak cache-keys saai en voorspelbaar
De meeste cache-bugs zijn eigenlijk “key-bugs”. Gebruik een gedocumenteerde conventie die de inputs bevat die de response veranderen: tenant/user-scope, locale, device-class en relevante feature-flags.
Voeg expliciete key-versioning toe (bijv. product:v3:...) zodat je veilig kunt invalidaten door een versie te verhogen in plaats van miljoenen entries te proberen verwijderen.
Geef de voorkeur aan begrensde veroudering boven perfecte versheid
Proberen alles perfect vers te houden duwt complexiteit in elke write-path.
Bepaal in plaats daarvan wat “acceptabel verouderd” betekent per endpoint (seconden, minuten of “tot volgende refresh”), en codeer dat met:
- TTLs die passen bij zakelijke verwachtingen
- achtergrondverversing (serveer licht verouderd terwijl je bijwerkt)
- event-driven invalidatie alleen voor echt gevoelige data
Bouw veilige defaults voor falen
Ga ervan uit dat de cache traag, onjuist of down kan zijn.
Gebruik timeouts en circuit breakers zodat cache-calls je requestpad niet platleggen. Maak graceful degradation expliciet: als de cache faalt, val terug op origin met rate limits, of serveer een minimale response.
Rol uit met controls en runbooks
Ship caching achter een canary of percentage rollout, en houd een bypass-schakelaar (per route of header) voor snelle troubleshooting.
Documenteer runbooks: hoe te purgen, hoe key-versies te bumpen, hoe caching tijdelijk uit te schakelen en waar metrics te checken. Koppel ze aan je interne runbooks zodat on-call snel kan handelen.
Prototypen van cachingwijzigingen zonder release-vertraging
Cachingwerk stagneert vaak omdat veranderingen meerdere lagen raken (headers, app-logic, datamodellen en rollback-plannen). Eén manier om iteratiekosten te verlagen is het prototypen van het volledige requestpad in een gecontroleerde omgeving.
Met Koder.ai kunnen teams snel een realistische app-stack opzetten (React op het web, Go-backends met PostgreSQL en zelfs Flutter mobile clients) via een chat-gedreven workflow, en dan cachingbeslissingen (TTL, key-design, stale-while-revalidate) end-to-end testen. Features zoals planning mode helpen het beoogde cachinggedrag te documenteren voordat je implementeert, en snapshots/rollback maken het veiliger om met cacheconfiguratie of invalidatielogica te experimenteren. Wanneer je klaar bent kun je source code exporteren of deployen/hosten met custom domains—handig voor performance-tests die productieverkeer moeten nabootsen.
Als je zo'n platform gebruikt, behandel het als een aanvulling op productie-grade observability: het doel is snellere iteratie op cachingontwerp met behoud van correctheidseisen en rollback-procedures.