28 dec 2025·7 min
Claude Code voor prestatieonderzoek: een meetbare workflow
Gebruik Claude Code voor prestatieonderzoek met een herhaalbare cyclus: meet, formuleer een hypothese, wijzig weinig en meet opnieuw voordat je uitrolt.
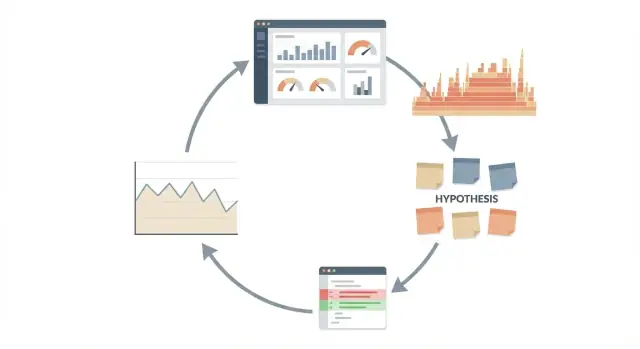
Gebruik Claude Code voor prestatieonderzoek met een herhaalbare cyclus: meet, formuleer een hypothese, wijzig weinig en meet opnieuw voordat je uitrolt.
Prestatiebugs nodigen uit tot giswerk. Iemand merkt dat een pagina traag aanvoelt of dat een API time-outs geeft, en de snelste stap is om code te "schoonmaken", caching toe te voegen of een lus te herschrijven. Het probleem is dat "voelt traag" geen metric is en "netter" niet per se sneller betekent.
Zonder meten verslijten teams uren aan het veranderen van de verkeerde dingen. Het hot path kan in de database, het netwerk of een onverwachte allocatie zitten, terwijl het team code oppoetst die nauwelijks invloed heeft. Erger nog: een wijziging die slim lijkt kan de prestaties verslechteren: extra logging in een strakke lus, een cache die druk op geheugen verhoogt, of parallel werk dat lock-contentie creëert.
Giswerk brengt ook risico's voor correcte werking met zich mee. Als je code verandert om het sneller te maken, kun je resultaten, foutafhandeling, ordering of retries veranderen. Als je correctheid en snelheid niet samen controleert, kun je een benchmark "winnen" en tegelijk een bug deployen.
Behandel prestatie als een experiment, niet als een debat. De cyclus is eenvoudig en herhaalbaar:
Veel overwinningen zijn bescheiden: 8% van p95-latentie weghalen, piekgeheugen met 50 MB verlagen of één databasequery schrappen. Die overwinningen tellen nog steeds, maar alleen als ze gemeten, geverifieerd en reproduceerbaar zijn.
Dit werkt het beste als een lus, niet als een eenmalig "maak het sneller"-verzoek. De lus houdt je eerlijk omdat elke actie terug te voeren is op bewijs en een cijfer dat je kunt volgen.
Een duidelijke sequence:
Elke stap beschermt je tegen een ander soort zelf-bedrog. Eerst meten stopt je ervan iets te "fixen" dat geen echt probleem was. Een opgeschreven hypothese voorkomt dat je vijf dingen tegelijk verandert en vervolgens raadt welk ding effect had. Minimale wijzigingen verkleinen het risico op het breken van gedrag of het toevoegen van nieuwe bottlenecks. Her-meten vangt placebo-wins (zoals snellere runs door een warme cache) en onthult regressies.
"Klaar" is geen gevoel. Het is een resultaat: de doelmetric bewoog in de juiste richting en de wijziging veroorzaakte geen duidelijke regressies (fouten, hoger geheugen, slechtere p95-latentie of tragere endpoints in de buurt).
Weten wanneer te stoppen hoort ook bij de workflow. Stop wanneer winst afvlakt, wanneer de metric goed genoeg is voor gebruikers, of wanneer de volgende stap grote refactors vereist voor kleine winst. Prestatiewerk heeft altijd opportunity cost; de lus helpt je tijd te besteden waar het rendeert.
Als je vijf dingen tegelijk meet, weet je niet wat verbeterde. Kies één primaire metric voor dit onderzoek en behandel alles anders als ondersteunende signalen. Voor veel gebruikersgerichte problemen is die metric latentie. Voor batchwerk kan het throughput, CPU-tijd, geheugenverbruik of zelfs kosten per run zijn.
Wees specifiek over het scenario. "De API is traag" is te vaag. "POST /checkout met een typische winkelwagen van 3 items" is meetbaar. Houd inputs stabiel zodat de cijfers iets betekenen.
Schrijf de baseline en de omgevingsdetails op voordat je code aanraakt: datasetgrootte, machinetype, build-mode, feature flags, concurrency en warmup. Deze baseline is je anker. Zonder die anchor kan elke verandering als vooruitgang lijken.
Voor latentie vertrouw je op percentielen, niet alleen op een gemiddelde. p50 toont de typische ervaring, terwijl p95 en p99 de pijnlijke staart blootleggen waar gebruikers over klagen. Een wijziging die p50 verbetert maar p99 verslechtert kan nog steeds als trager aanvoelen.
Bepaal vooraf wat "betekenisvol" is zodat je geen ruis viert:
Als deze regels zijn vastgesteld, kun je ideeën testen zonder het doel te verplaatsen.
Begin met het eenvoudigste signaal dat je vertrouwt. Eén enkele timing rond een request kan je vertellen of je een echt probleem hebt en grofweg hoe groot het is. Diepere profilering bewaar je voor wanneer je moet uitleggen waarom het traag is.
Goed bewijs komt meestal uit een mix van bronnen:
Gebruik simpele metrics voor de vraag "is het trager, en hoeveel?" Gebruik profilering wanneer de vraag is "waar gaat de tijd heen?" Als p95-latentie verdubbelde na een deploy, begin met timings en logs om de regressie te bevestigen en af te bakenen. Als timings laten zien dat het merendeel van de vertraging in je app-code zit (niet de DB), dan kan een CPU-profiler of flame graph naar de exacte functie wijzen die gegroeid is.
Houd metingen veilig. Verzamel wat je nodig hebt om prestatie te debuggen, niet user content. Geef de voorkeur aan aggregaten (duur, aantallen, groottes) boven ruwe payloads en redacteer identifiers standaard.
Ruis is echt, dus neem meerdere samples en noteer outliers. Voer hetzelfde request 10 tot 30 keer uit en registreer mediaan en p95 in plaats van één beste run.
Schrijf het exacte testrecept op zodat je het na wijzigingen kunt herhalen: omgeving, dataset, endpoint, request-bodygrootte, concurrency-niveau en hoe je resultaten hebt vastgelegd.
Begin met een symptoom dat je kunt benoemen: "p95-latentie stijgt van 220 ms naar 900 ms tijdens verkeerspieken", "CPU staat op 95% op twee cores" of "geheugen groeit met 200 MB per uur." Vage symptomen zoals "het voelt traag" leiden tot willekeurige wijzigingen.
Vertaal vervolgens wat je hebt gemeten naar een verdachte zone. Een flame graph kan laten zien dat de meeste tijd in JSON-encodering zit, een trace kan een traag call path tonen of database-statistieken kunnen één query aanwijzen die de meeste tijd opslokt. Kies het kleinste gebied dat het grootste deel van de kosten verklaart: een functie, één SQL-query of één externe aanroep.
Een goede hypothese is één zin, toetsbaar en gekoppeld aan een voorspelling. Je vraagt hulp om een idee te testen, niet om een tool alles sneller te laten maken.
Gebruik dit format:
Voorbeeld: "Omdat het profiel 38% van de CPU in SerializeResponse laat zien, veroorzaakt het aanmaken van een nieuwe buffer per request CPU-spikes. Als we een buffer hergebruiken, zou p95-latentie met ongeveer 10–20% moeten dalen en CPU onder gelijke load met 15% moeten afnemen."
Houd jezelf eerlijk door alternatieven te benoemen voordat je code aanraakt. Misschien is het trage deel juist een upstream dependency, lock-contentie, een hogere cache-missrate of een rollout die payload-grootte heeft verhoogd.
Schrijf 2 tot 3 alternatieve verklaringen op en kies de verklaring die het beste door je bewijs wordt ondersteund. Als je wijziging de metric niet beweegt, heb je meteen de volgende hypothese klaar.
Claude is het meest nuttig in prestatiewerk wanneer je het behandelt als een zorgvuldige analist, niet als een orakel. Houd elk voorstel gekoppeld aan wat je hebt gemeten en zorg dat elke stap weerlegbaar is.
Geef het echte inputs, geen vage omschrijving. Plak klein, gefocust bewijs: een profileringssamenvatting, enkele logregels rond de trage request, een queryplan en het specifieke codepad. Voeg "voor"-cijfers toe (p95-latentie, CPU-tijd, DB-tijd) zodat het je baseline kent.
Vraag het uit te leggen wat de data suggereert en wat het niet ondersteunt. Forceer concurrerende verklaringen. Een bruikbare prompt eindigt met: "Geef me 2–3 hypothesen, en voor elk, vertel wat het zou falsificeren." Dat voorkomt verankering op het eerste plausibele verhaal.
Voordat je iets verandert, vraag om het kleinst mogelijke experiment dat de leidende hypothese kan valideren. Houd het snel en omkeerbaar: voeg één timer rond een functie toe, zet één profiler-flag aan of voer één DB-query met EXPLAIN uit.
Als je een strakke structuur voor de output wil, vraag dan om:
Als het geen specifieke metric, locatie en her-testplan kan noemen, ga je terug naar giswerk.
Nadat je bewijs en een hypothese hebt, weersta de drang om "alles schoon te maken." Prestatiewerk is het makkelijkst te vertrouwen wanneer de codewijziging klein en eenvoudig te herstellen is.
Verander één ding tegelijk. Als je in één commit een query tweak, caching en refactor doet, weet je niet wat hielp (of schade aanrichtte). Single-variable-wijzigingen maken de volgende meting betekenisvol.
Schrijf vooraf op wat je numeriek verwacht. Voorbeeld: "p95-latentie zou moeten dalen van 420 ms naar onder de 300 ms en DB-tijd met ongeveer 100 ms verminderen." Als het resultaat die doelstelling mist, leer je snel dat de hypothese zwak of onvolledig was.
Houd wijzigingen omkeerbaar:
"Minimaal" betekent niet "triviaal." Het betekent gefocust: cache één dure functie, verwijder één herhaalde allocatie in een strakke lus of stop met werk voor requests die het niet nodig hebben.
Voeg lichte timing toe rond het vermoedelijke bottleneck zodat je kunt zien wat er bewoog. Eén timestamp voor en na een aanroep (gelogd of als metric vastgelegd) kan bevestigen of je wijziging het trage deel raakte of dat je tijd elders verschuift.
Na een wijziging voer je exact hetzelfde scenario uit dat je voor de baseline gebruikte: dezelfde inputs, omgeving en load shape. Als je test van caches of warm-up afhangt, maak dat expliciet (bijvoorbeeld: "eerste run koud, volgende 5 runs warm"). Anders "vind" je verbeteringen die puur geluk waren.
Vergelijk resultaten met dezelfde metric en percentielen. Gemiddelden kunnen pijn verbergen, dus houd p95 en p99 in de gaten, plus throughput en CPU-tijd. Voer genoeg herhalingen uit om te bepalen of de cijfers zich stabiliseren.
Controleer voor je juicht op regressies die niet in één kopnummer verschijnen:
Beslis vervolgens op basis van bewijs, niet hoop. Als de verbetering echt is en je geen regressies hebt geïntroduceerd, houd de wijziging. Als de resultaten gemengd of rumoerig zijn, revert en vorm een nieuwe hypothese of isoleer de wijziging verder.
Als je op een platform werkt zoals Koder.ai, kan het nemen van een snapshot vóór experimenten rollback tot één stap maken, wat het veiliger maakt om gedurfde ideeën te testen.
Schrijf tenslotte op wat je geleerd hebt: de baseline, de wijziging, de nieuwe cijfers en de conclusie. Dit korte verslag voorkomt dat de volgende ronde dezelfde doodlopende paden betreedt.
Prestatiewerk ontspoort vaak wanneer de lijn tussen wat je mat en wat je veranderde verloren raakt. Houd een schone bewijsketen zodat je met vertrouwen kunt zeggen wat het verschil maakte.
De herhalende fouten:
Een klein voorbeeld: een endpoint lijkt traag, dus je tuneert de serializer omdat die hot is in een profiel. Je test daarna met een kleinere dataset en het lijkt sneller. In productie wordt p99 slechter omdat de database nog steeds de bottleneck is en je wijziging de payloadgrootte verhoogde.
Als je Claude Code gebruikt om fixes voor te stellen, houd het kort en concreet. Vraag om 1–2 minimale wijzigingen die bij het verzamelde bewijs passen, en eis een her-meetplan voordat je een patch accepteert.
Snelheidsclaims vallen uit elkaar als de test vaag is. Voordat je viert, zorg dat je kunt uitleggen wat je mat, hoe je het mat en wat je veranderde.
Begin met het noemen van één metric en het opschrijven van de baseline. Voeg details toe die cijfers beïnvloeden: machinetype, CPU-load, datasetgrootte, build-mode (debug vs release), feature flags, cache-state en concurrency. Als je de setup morgen niet kunt reproduceren, heb je geen betrouwbare baseline.
Checklist:
Als de cijfers beter lijken, doe dan snel een regressiecheck: controleer correctheid (zelfde outputs), foutpercentage en timeouts. Let op bijwerkingen zoals hoger geheugen, CPU-spikes, tragere startup of meer DB-belasting. Een wijziging die p95 verbetert maar geheugen verdubbelt kan een verkeerde trade-off zijn.
Een team meldt dat GET /orders in dev prima voelt, maar in staging traag wordt bij matige load. Gebruikers klagen over time-outs, maar gemiddelde latentie lijkt nog "ok", wat een klassieke val is.
Eerst: leg een baseline vast. Onder een stabiele load-test (zelfde dataset, dezelfde concurrency, dezelfde duur) registreer je:
Verzamel bewijs. Een snelle trace toont dat het endpoint een hoofdquery uitvoert voor orders en vervolgens per order gerelateerde items ophaalt in een lus. Je merkt ook dat de JSON-respons groot is, maar DB-tijd domineert.
Zet dat om in een hypotheselijst die je kunt testen:
Vraag om een minimale wijziging die bij het sterkste bewijs past: haal één duidelijke N+1-call weg door items in één query op te halen keyed op order-IDs (of voeg de ontbrekende index toe als het queryplan een full scan toont). Houd het omkeerbaar en in een gefocuste commit.
Her-meten met dezelfde load-test. Resultaten:
Beslissing: deploy de fix (duidelijke winst), en start vervolgens een tweede cyclus gericht op de resterende kloof en CPU-spikes, aangezien DB nu niet langer de limiter is.
De snelste manier om beter te worden in prestatieonderzoek is elke run te behandelen als een klein experiment dat je kunt herhalen. Als het proces consistent is, worden resultaten makkelijker te vertrouwen, vergelijken en delen.
Een simpele één-pagina template helpt:
Bepaal waar deze notities leven zodat ze niet verdwijnen. Een gedeelde plek is belangrijker dan het perfecte hulpmiddel: een map in de repo naast de service, een team-doc of ticket-notities. Het belangrijkste is vindbaarheid. Iemand moet later "p95-latentie spike na caching-wijziging" kunnen vinden.
Maak veilige experimenten tot gewoonte. Gebruik snapshots en makkelijke rollback zodat je een idee kunt proberen zonder angst. Als je met Koder.ai bouwt, kan Planning Mode een handige plek zijn om het meetplan te schetsen, de hypothese te definiëren en de wijziging te begrenzen voordat je een strakke diff genereert en her-meet.
Stel een cadence in. Wacht niet op incidenten. Voeg kleine prestatiechecks toe na wijzigingen zoals nieuwe queries, nieuwe endpoints, grotere payloads of dependency-upgrades. Een 10-minuten baseline-check nu kan een dag giswerk later besparen.
Begin met één getal dat past bij de klacht: meestal p95-latentie voor een specifiek endpoint en input. Leg een baseline vast onder dezelfde omstandigheden (datagrootte, concurrentie, warm/koud cache), wijzig dan één ding en meet opnieuw.
Als je de baseline niet kunt reproduceren, meet je nog niet — dan raadpleeg je het gissen.
Een goede baseline bevat:
Schrijf dit op voordat je code aanraakt zodat je het doel niet verplaatst.
Percentielen weerspiegelen de gebruikerservaring beter dan een gemiddelde. p50 is “typisch”, maar gebruikers klagen over de trage staart: dat is p95/p99.
Als p50 verbetert maar p99 verslechtert, kan het systeem nog steeds trager aanvoelen ondanks een betere gemiddelde.
Gebruik eenvoudige timings/logs wanneer je vraagt “is het trager en hoeveel?” Gebruik profilering wanneer je vraagt “waar gaat de tijd naartoe?”
Een praktische volgorde is: bevestig de regressie met request-timings, profileer pas nadat je weet dat de vertraging echt en afgebakend is.
Kies één primaire metric en behandel de rest als bewakingswaarden. Een veelgebruikte set is:
Dat voorkomt dat je “wint” op één grafiek terwijl je ongemerkt timeouts, geheugenstijging of slechtere tail-latency veroorzaakt.
Schrijf een eendelige hypothese gekoppeld aan bewijs en een voorspelling:
Als je het bewijs en de verwachte metrische beweging niet kunt noemen, is de hypothese niet toetsbaar.
Maak het klein, gefocust en makkelijk ongedaan te maken:
Kleine diffs maken de volgende meting betekenisvol en verkleinen de kans dat je gedrag breekt terwijl je snelheid nastreeft.
Draai exact hetzelfde scenario opnieuw dat je voor de baseline gebruikte: dezelfde inputs, omgeving en load shape. Als je test afhankelijk is van caches of warm-up, maak dat expliciet (bijvoorbeeld: “eerste run koud, volgende 5 runs warm”). Anders ‘vind’ je verbeteringen die puur geluk waren.
Vergelijk resultaten met dezelfde metric en percentielen. Gemiddelden kunnen pijn verbergen, dus let op p95 en p99, plus throughput en CPU-tijd. Voer genoeg herhalingen uit om te zien of waarden stabiliseren.
Controleer vóór het juichen op regressies die niet in één kopnummer verschijnen:
Geef het concrete inputs, geen vage omschrijving. Plak klein, gefocust bewijs: een profileringssamenvatting, een paar logregels rond de trage request, een queryplan en het specifieke codepad. Voeg ‘voor’ cijfers toe (p95, CPU-tijd, DB-tijd) zodat het de baseline kent.
Vraag het uit te leggen wat de data suggereert en wat het niet ondersteunt. Forceer concurrerende verklaringen. Een goede prompt eindigt met: “Geef me 2–3 hypothesen, en voor elke hypothese, wat zou die falsificeren.” Dat voorkomt vastklampen aan het eerste plausibele verhaal.
Vraag vóór codewijziging om het kleinste experiment dat de leidende hypothese valideert. Houd het snel en omkeerbaar: voeg één timer toe rond een functie, zet één profiler-flag aan of voer één DB-query met EXPLAIN uit.
Als de output geen specifieke metric, locatie en verwacht resultaat kan noemen, ga je terug naar gissen.
Meet eerst, maak een hypothese en verander slechts weinig. Belangrijk:
Schrijf een korte notitie met baseline, de wijziging, de nieuwe cijfers en de conclusie — dat voorkomt dat de volgende ronde in dezelfde doodlopende straat eindigt.
Als de verbetering echt is en er zijn geen regressies, houd de wijziging. Bij gemengde of rumoerige resultaten: revert en vorm een nieuwe hypothese of isoleer de wijziging verder.