05 mei 2025·8 min
Datadog en de platformverschuiving: telemetrie, integraties en workflows
Lees hoe Datadog een platform wordt wanneer telemetrie, integraties en workflows het product vormen — en praktische ideeën die je op je stack kunt toepassen.
Lees hoe Datadog een platform wordt wanneer telemetrie, integraties en workflows het product vormen — en praktische ideeën die je op je stack kunt toepassen.
Een observability-tool helpt je specifieke vragen over een systeem te beantwoorden—meestal door grafieken, logs of een queryresultaat te tonen. Je “gebruikt” het wanneer er een probleem is.
Een observability-platform is breder: het standardiseert hoe telemetrie wordt verzameld, hoe teams het onderzoeken en hoe incidenten end-to-end worden afgehandeld. Het wordt iets dat je organisatie elke dag "draait", over veel services en teams heen.
De meeste teams beginnen met dashboards: CPU-grafieken, foutpercentages, misschien een paar log-zoekopdrachten. Dat is nuttig, maar het echte doel is niet mooiere grafieken—het is snellere detectie en snellere oplossing.
Een platformverschuiving gebeurt wanneer je stopt met vragen: “Kunnen we dit grafisch weergeven?” en begint te vragen:
Dat zijn uitkomstgerichte vragen en ze vereisen meer dan visualisatie. Ze vereisen gedeelde datastandaarden, consistente integraties en workflows die telemetrie aan actie koppelen.
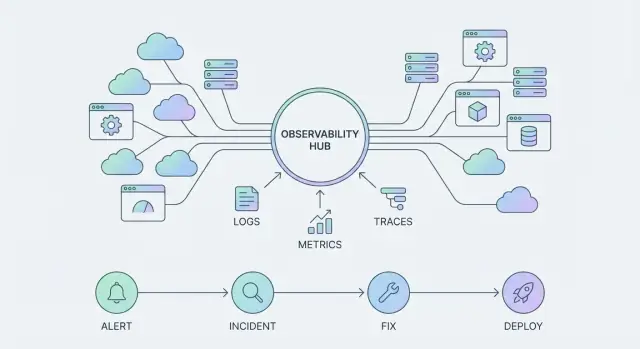
Naarmate platforms zoals het Datadog observability platform evolueren, is het “productoppervlak” niet alleen dashboards. Het zijn drie onlosmakelijk verbonden pijlers:
Een enkel dashboard helpt één team. Een platform wordt sterker met elke service die wordt aangesloten, elke toegevoegde integratie en elk gestandaardiseerd workflow. In de loop van de tijd componeert dit zich tot minder blinde vlekken, minder gedupliceerde tooling en kortere incidenten—omdat elke verbetering herbruikbaar wordt, niet eenmalig.
Wanneer observability verschuift van “een tool die we bevragen” naar “een platform waarop we bouwen”, stopt telemetrie met ruwe uitlaat en wordt het het productoppervlak. Wat je kiest om te emitten—en hoe consistent je dat doet—bepaalt wat je teams kunnen zien, automatiseren en vertrouwen.
De meeste teams standaardiseren rond een kleine set signalen:
Individueel is elk signaal nuttig. Samen vormen ze een enkele interface naar je systemen—wat je ziet in dashboards, alerts, incident-tijdlijnen en postmortems.
Een veelvoorkomend faalpatroon is alles verzamelen maar het inconsistent benoemen. Als de ene service userId gebruikt, de andere uid en een derde niets logt, kun je data niet betrouwbaar snijden, signalen niet samenvoegen of herbruikbare monitors bouwen.
Teams halen meer waarde door enkele conventies af te spreken—servicenamen, env-tags, request IDs en een standaardset attributen—dan door ingestie te verdubbelen.
High-cardinality velden zijn attributen met veel mogelijke waarden (zoals user_id, order_id of session_id). Ze zijn krachtig om te debuggen als iets “slechts één klant” treft, maar ze kunnen ook kosten verhogen en queries vertragen als je ze overal gebruikt.
De platformaanpak is intentioneel: houd high-cardinality waar het duidelijk onderzoeksoordeel toevoegt, en vermijd het op plekken bedoeld voor globale aggregaten.
Het rendement is snelheid. Wanneer metrics, logs, traces, events en profiles dezelfde context delen (service, versie, regio, request ID), besteden engineers minder tijd aan het aan elkaar knopen van bewijs en meer tijd aan het oplossen van het daadwerkelijke probleem. In plaats van tussen tools te springen en te gokken, volg je één draad van symptoom naar root cause.
De meeste teams beginnen aan observability door gewoon “data binnen te krijgen.” Dat is noodzakelijk, maar het is geen strategie. Een telemetriestrategie houdt onboarding snel en maakt je data consistent genoeg om gedeelde dashboards, betrouwbare alerts en betekenisvolle SLOs te voeden.
Datadog ontvangt telemetrie doorgaans via een paar praktische routes:
In het begin wint snelheid: teams installeren een agent, zetten enkele integraties aan en zien meteen waarde. Het risico is dat elk team zijn eigen tags, servicenamen en logformaten uitvindt—waardoor cross-service views rommelig worden en alerts moeilijk te vertrouwen zijn.
Een simpele regel: sta “quick start” onboarding toe, maar eis “standaardiseer binnen 30 dagen.” Dat geeft teams momentum zonder chaos vast te leggen.
Je hebt geen enorme taxonomie nodig. Begin met een kleine set die elk signaal (logs, metrics, traces) moet dragen:
service: kort, stabiel, lowercase (bijv. checkout-api)env: prod, staging, devteam: eigenaarsteam identifier (bijv. payments)version: deployversie of git SHAAls je er nog één wilt toevoegen die snel rendeert, voeg tier toe (frontend, backend, data) om filteren te vereenvoudigen.
Kostenproblemen komen meestal door te royale defaults:
Het doel is niet minder verzamelen—maar het juiste data consistent verzamelen, zodat je gebruik kunt schalen zonder verrassingen.
De meeste mensen denken bij observability aan “iets dat je installeert.” In de praktijk verspreidt het zich door een organisatie zoals goede connectors: één integratie tegelijk.
Een integratie is niet alleen een datapijp. Het heeft meestal drie delen:
Dat laatste onderdeel verandert integraties in distributie. Als de tool alleen leest, is het een dashboardbestemming. Als het ook schrijft, wordt het onderdeel van het dagelijkse werk.
Goede integraties verminderen setup-tijd omdat ze met verstandige defaults komen: kant-en-klare dashboards, aanbevolen monitors, parsingregels en veelvoorkomende tags. In plaats van dat elk team zijn eigen “CPU-dashboard” of “Postgres-alerts” uitvindt, krijg je een standaard uitgangspunt dat best practices volgt.
Teams passen nog steeds aan—maar ze passen aan vanaf een gedeelde basislijn. Deze standaardisatie telt wanneer je tools consolideert: integraties creëren herhaalbare patronen die nieuwe services kunnen kopiëren, wat groei beheersbaar houdt.
Vraag bij evaluatie: kan het signalen ontvangen en actie ondernemen? Voorbeelden zijn het openen van incidenten in je ticketingsysteem, het bijwerken van incidentkanalen of het toevoegen van een trace-link terug in een PR of deploy-weergave. Bidirectionele setups zijn waar workflows echt “native” voelen.
Begin klein en voorspelbaar:
Een vuistregel: geef prioriteit aan integraties die direct incidentrespons verbeteren, niet aan die alleen meer grafieken toevoegen.
Standaardweergaven zijn waar een observability-platform dagelijk bruikbaar wordt. Wanneer teams hetzelfde mentale model delen—wat een “service” is, wat “gezond” betekent en waar je als eerste op klikt—wordt debuggen sneller en overdracht duidelijker.
Kies een kleine set “golden signals” en koppel elke signal aan een concrete, herbruikbare dashboard. Voor de meeste services is dat:
Het cruciale is consistentie: één dashboardindeling die werkt over services heen verslaat tien slimme bespoke dashboards.
Een servicecatalogus (zelfs een lichte) verandert “iemand moet hier naar kijken” in “dit team is er eigenaar van”. Wanneer services zijn getagd met eigenaren, env en afhankelijkheden, kan het platform basisvragen direct beantwoorden: Welke monitors gelden voor deze service? Welke dashboards moet ik openen? Wie wordt gepaged?
Die duidelijkheid vermindert Slack-pingpong tijdens incidenten en helpt nieuwe engineers zelfbediening.
Behandel deze als standaardartefacten, geen optionele extra’s:
Vanity-dashboards (mooie grafieken zonder beslissingen erachter), one-off alerts (snel aangemaakt, nooit getuned) en ongedocumenteerde queries (slechts één persoon begrijpt de magische filter) creëren platformruis. Als een query belangrijk is, sla hem op, geef hem een naam en koppel hem aan een service-view die anderen kunnen vinden.
Observability wordt pas “echt” voor de business wanneer het de tijd tussen een probleem en een betrouwbare oplossing verkort. Dat gebeurt door workflows—herhaalbare paden die je brengen van signaal naar actie, en van actie naar leren.
Een schaalbare workflow is meer dan iemand pagineren.
Een alert zou een gefocuste triage-lus moeten openen: bevestig impact, identificeer de getroffen service en haal de meest relevante context erbij (recente deploys, afhankelijkheidsgezondheid, foutpieken, saturatiesignalen). Vanaf daar verandert communicatie een technisch incident in een gecoördineerde respons—wie is eigenaar van het incident, wat zien gebruikers en wanneer is de volgende update gepland.
Mitigatie is waar je “veilige stappen” bij de hand wilt hebben: feature flags, traffic shifting, rollback, rate limits of een bekende workaround. Tenslotte sluit leren de cirkel met een lichte review die vastlegt wat veranderde, wat werkte en wat geautomatiseerd moet worden.
Platforms zoals het Datadog observability platform voegen waarde toe wanneer ze gedeeld werk ondersteunen: incidentkanalen, statusupdates, overdrachten en consistente tijdlijnen. ChatOps-integraties kunnen alerts veranderen in gestructureerde gesprekken—incident creëren, rollen toewijzen en sleutelgrafieken en queries direct in de thread posten zodat iedereen hetzelfde bewijs ziet.
Een bruikbaar runbook is kort, stellend en veilig. Het moet bevatten: het doel (service herstellen), duidelijke eigenaren/on-call-rotaties, stapsgewijze checks, links naar de juiste dashboards/monitors en “veilige acties” die risico verminderen (met rollback-stappen). Als het niet veilig is om ’s nachts om 03:00 uit te voeren, is het niet klaar.
De root cause vind je sneller als incidenten automatisch worden gecorreleerd met deploys, config-wijzigingen en feature-flag flips. Maak “wat is er veranderd?” een eersteklas weergave zodat triage begint met bewijs, niet met giswerk.
Een SLO (Service Level Objective) is een eenvoudige belofte over gebruikerservaring over een tijdsvenster—zoals “99.9% van de requests slaagt in 30 dagen” of “p95 paginaladingen < 2 seconden”.
Dat verslaat een “groen dashboard” omdat dashboards vaak systeemgezondheid laten zien (CPU, geheugen, queue-diepte) in plaats van klantimpact. Een service kan groen lijken en toch gebruikers falen (bijv. een afhankelijkheid timeouts of fouten geconcentreerd in één regio). SLOs dwingen teams te meten wat gebruikers daadwerkelijk voelen.
Een error budget is de toegestane hoeveelheid onbetrouwbaarheid die je SLO toelaat. Als je 99.9% succes over 30 dagen belooft, mag je ongeveer 43 minuten fouten hebben in die periode.
Dit creëert een praktisch operating system voor beslissingen:
In plaats van meningen in een release-meeting te debatteren, debatteer je over een getal dat iedereen kan zien.
SLO-alerting werkt het beste als je alarmeert op burn rate (hoe snel je je error budget verbruikt), niet op ruwe fouttellingen. Dat vermindert ruis:
Veel teams gebruiken twee vensters: een snelle burn (snel pagineren) en een langzame burn (ticket/notificatie).
Begin klein—twee tot vier SLOs die je daadwerkelijk gebruikt:
Als deze stabiel zijn, kun je uitbreiden—anders bouw je alleen maar nog een muur van dashboards. Voor meer, zie /blog/slo-monitoring-basics.
Alerting is waar veel observability-programma's vastlopen: de data is er, de dashboards zien er goed uit, maar de on-call ervaring wordt luid en onbetrouwbaar. Als mensen leren alerts te negeren, verliest je platform zijn vermogen om het bedrijf te beschermen.
De meest voorkomende oorzaken zijn verrassend consistent:
In Datadog-termen verschijnen gedupliceerde signalen vaak wanneer monitors vanuit verschillende “oppervlakken” (metrics, logs, traces) worden gemaakt zonder te bepalen welke de canonieke pagina is.
Alerting schalen begint met routingregels die voor mensen logisch zijn:
Een bruikbare default is: alert op symptomen, niet op elke metrische verandering. Pagineer op zaken die gebruikers voelen (error rate, mislukte checkouts, aanhoudende latency, SLO-burn), niet op “inputs” (CPU, pod-aantal) tenzij die betrouwbaar impact voorspellen.
Maak alert-hygiëne onderdeel van operations: maandelijkse pruning en tuning van monitors. Verwijder monitors die nooit afgaan, pas drempels aan die te vaak afgaan en merge duplicaten zodat elk incident één primaire pagina heeft plus ondersteunende context.
Goed gedaan, wordt alerting een workflow die mensen vertrouwen—geen achtergrondruis-generator.
Observability een “platform” noemen gaat niet alleen over veel logs, metrics, traces en integraties op één plek. Het impliceert ook governance: consistentie en stuurregels die het systeem bruikbaar houden wanneer het aantal teams, services, dashboards en alerts vermenigvuldigt.
Zonder governance kan Datadog (of elk observability-platform) veranderen in een rommelig plakboek—honderden net iets andere dashboards, inconsistente tags, onduidelijk eigenaarschap en alerts die niemand vertrouwt.
Goede governance maakt duidelijk wie beslist en wie verantwoordelijk is wanneer het platform rommelig wordt:
Enkele lichte controles doen meer dan lange beleidsdocumenten:
service, env, team, tier) plus duidelijke regels voor optionele tags. Handhaaf in CI waar mogelijk.De snelste manier om kwaliteit op te schalen is delen wat werkt:
Als je wilt dat dit blijft plakken, maak de gereguleerde weg de gemakkelijke weg—minder klikken, snellere setup en duidelijker eigenaarschap.
Zodra observability zich als een platform gedraagt, volgt het platform-economie: hoe meer teams het adopteren, hoe meer telemetrie geproduceerd wordt en hoe nuttiger het wordt.
Dat creëert een flywheel:
De keerzijde is dat dezelfde lus ook kosten verhoogt. Meer hosts, containers, logs, traces, synthetics en custom metrics kunnen sneller groeien dan je budget als je het niet doelbewust beheert.
Je hoeft niet “alles uit te zetten.” Begin met het vormen van data:
Houd een kleine set metrics bij die laten zien of het platform rendeert:
Maak er een productreview van, geen audit. Nodig platformeigenaren, enkele service-teams en finance uit. Review:
Het doel is gedeeld eigenaarschap: kosten worden een input voor betere instrumentatiebeslissingen, niet een reden om observatie te stoppen.
Als observability verandert in een platform, stopt je “toolstack” een verzameling point solutions te zijn en wordt het meer gedeelde infrastructuur. Die verschuiving maakt tool-sprawl meer dan een ergernis: het veroorzaakt gedupliceerde instrumentatie, inconsistente definities (wat telt als een error?) en hogere on-call last omdat signalen niet op elkaar aansluiten over logs, metrics, traces en incidenten.
Consolidatie betekent niet per se “één vendor voor alles.” Het betekent minder systemen van registratie voor telemetrie en respons, duidelijker eigenaarschap en minder plekken waar mensen tijdens een outage moeten kijken.
Tool-sprawl verbergt doorgaans kosten op drie plekken: tijd verloren aan UI-springen, kwetsbare integraties die je moet onderhouden en gefragmenteerde governance (naamgeving, tags, retentie, toegang).
Een meer geconsolideerde platformaanpak kan contextswitching verminderen, service-views standaardiseren en incident-workflows herhaalbaar maken.
Bij het evalueren van je stack (inclusief Datadog of alternatieven), toets:
Kies een of twee services met echte traffic. Definieer een succesmaat zoals “tijd om root cause te vinden daalt van 30 minuten naar 10” of “verminder luidruchtige alerts met 40%.” Instrumenteer alleen wat nodig is en beoordeel resultaten na twee weken.
Houd interne documentatie gecentraliseerd zodat leren zich opstapelt—link de pilot-runbook, taggingregels en dashboards vanaf één plek (bijv. /blog/observability-basics als intern startpunt).
Je “rolt Datadog niet uit” in één keer. Je begint klein, stelt vroege standaarden vast en schaalt dan wat werkt.
Dagen 0–30: Onboard (snel waarde bewijzen)
Kies 1–2 kritieke services en één klantgerichte journey. Instrumenteer logs, metrics en traces consistent en koppel de integraties die je al gebruikt (cloud, Kubernetes, CI/CD, on-call).
Dagen 31–60: Standardiseer (maak het herhaalbaar)
Zet wat je leerde om in defaults: service-naming, tagging, dashboard-templates, monitor-naming en eigenaarschap. Maak “golden signals” views (latency, traffic, errors, saturation) en een minimale SLO-set voor de belangrijkste endpoints.
Dagen 61–90: Scale (breid uit zonder chaos)
Onboard extra teams met dezelfde templates. Introduceer governance (tagregels, verplichte metadata, reviewproces voor nieuwe monitors) en begin kosten versus gebruik te volgen zodat het platform gezond blijft.
Zodra je observability als een platform behandelt, wil je vaak kleine “glue”-apps eromheen: een servicecatalogus-UI, een runbook-hub, een incident-tijdlijnpagina of een intern portaal dat eigenaren → dashboards → SLOs → playbooks koppelt.
Dit zijn lichte interne tools die je snel kunt bouwen op Koder.ai—een vibe-coding platform waarmee je via chat webapps genereert (vaak React frontend, Go + PostgreSQL backend), met broncode-export en deployment/hosting-ondersteuning. In de praktijk gebruiken teams het om operationele oppervlakken te prototypen en te leveren zonder een volledig productteam van de roadmap te halen.
Geef twee sessies van 45 minuten: (1) “Hoe we hier queryen” met gedeelde querypatronen (per service, env, regio, versie) en (2) “Troubleshooting playbook” met een simpel proces: bevestig impact → check deploy markers → beperk tot service → inspecteer traces → controleer afhankelijkheidsgezondheid → beslis rollback/mitigatie.
Een observability tool is iets waar je naar kijkt tijdens een probleem (dashboards, log-search, een query). Een observability platform is iets dat je continu runt: het standaardiseert telemetrie, integraties, toegang, eigenaarschap, alerting en incident-workflows over teams heen zodat de uitkomsten verbeteren (snellere detectie en oplossing).
Omdat de grootste winst uit uitkomsten komt, niet uit visuals:
Grafieken helpen, maar je hebt gedeelde standaarden en workflows nodig om consequent MTTD/MTTR te verlagen.
Begin met een verplichte basis die elk signaal moet dragen:
serviceenv (prod, staging, )High-cardinality velden (zoals user_id, order_id, session_id) zijn ideaal om issues te debuggen die “slechts één klant” treffen, maar ze kunnen kosten verhogen en queries vertragen als je ze overal gebruikt.
Gebruik ze doelbewust:
De meeste teams standaardiseren op:
Een praktisch uitgangspunt is:
Kies het pad dat bij jullie controlebehoefte past en handhaaf daarna dezelfde naam-/tagregels overal.
Doe beide:
Dat voorkomt dat elk team zijn eigen schema uitvindt, terwijl je adoptie-voortgang behoudt.
Omdat integraties meer zijn dan datapijpen — ze bevatten:
Prioriteer bidirectionele integraties die zowel signalen opnemen als acties triggeren, zodat observability onderdeel van dagelijks werk wordt, niet alleen een bestemmings-UI.
Zet in op consistentie en herbruikbaarheid:
Vermijd vanity-dashboards en one-off alerts. Als een query belangrijk is, sla hem op, geef hem een naam en koppel hem aan een service-view zodat anderen hem vinden.
Alert op burn rate (hoe snel je het error budget verbruikt), niet op elk tijdelijk piekje. Een veelgebruikt patroon:
Houd de starterset klein (2–4 SLOs per service) en breid pas uit als teams ze echt gebruiken. Voor basics, zie /blog/slo-monitoring-basics.
devteamversion (deployversie of git SHA)Voeg tier (frontend, backend, data) toe als je een simpele extra filter wilt die snel rendeert.
Het belangrijkste is dat deze signalen dezelfde context delen (service/env/version/request ID) zodat correlatie snel gaat.