15 sep 2025·8 min
David Patterson, RISC-denken en de blijvende impact van co-design
Ontdek hoe David Patterson's RISC-denken en hardware–software co-design de prestaties per watt verbeterden, CPU's vormgaven en RISC-V vandaag beïnvloeden.
Ontdek hoe David Patterson's RISC-denken en hardware–software co-design de prestaties per watt verbeterden, CPU's vormgaven en RISC-V vandaag beïnvloeden.
David Patterson wordt vaak voorgesteld als “een RISC-pionier”, maar zijn blijvende invloed is breder dan elk afzonderlijk CPU-ontwerp. Hij hielp een praktische manier van denken over computers populair te maken: behandel prestaties als iets dat je kunt meten, vereenvoudigen en verbeteren end-to-end — van de instructies die een chip begrijpt tot de softwaretools die die instructies genereren.
RISC (Reduced Instruction Set Computing) is het idee dat een processor sneller en voorspelbaarder kan draaien als hij zich richt op een kleinere set eenvoudige instructies. In plaats van een enorm menu met ingewikkelde operaties in hardware te bouwen, maak je de veelvoorkomende operaties snel, uniform en gemakkelijk te pipelinen. De winst is niet “minder capaciteit” — het betekent dat eenvoudige bouwstenen, efficiënt uitgevoerd, vaak winnen in echte workloads.
Patterson pleitte ook voor hardware–software co-design: een feedbackloop waarin chiparchitecten, compilerbouwers en systeemontwerpers samen itereren.
Als een processor ontworpen is om eenvoudige patronen goed uit te voeren, kunnen compilers betrouwbaar die patronen produceren. Als compilers onthullen dat echte programma’s tijd in bepaalde operaties doorbrengen (zoals geheugenaccessen), kan hardware worden aangepast om die gevallen beter af te handelen. Daarom verbinden discussies over een instructiesetarchitectuur (ISA) zich vanzelf met compileroptimalisaties, caching en pipelining.
Je leert waarom RISC-ideeën samenhangen met prestaties per watt (niet alleen ruwe snelheid), hoe “voorspelbaarheid” moderne CPU's en mobiele chips efficiënter maakt, en hoe deze principes terugkomen in de apparaten van vandaag — van laptops tot cloudservers.
Als je eerst een kaart van de kernconcepten wilt voordat je dieper duikt, sla dan vooruit naar /blog/key-takeaways-and-next-steps.
Vroege microprocessors werden gebouwd onder strakke beperkingen: chips hadden beperkte ruimte voor schakelingen, geheugen was duur en opslag was traag. Ontwerpers probeerden computers te leveren die betaalbaar en “snel genoeg” waren, vaak met kleine caches (of geen), bescheiden kloksnelheden en veel minder hoofdgeheugen dan de software wilde.
Een populair idee was dat als de CPU krachtigere, hoog-niveau instructies bood — die meerdere stappen tegelijk konden doen — programma’s sneller zouden draaien en makkelijker te schrijven zouden zijn. Als één instructie “het werk van meerdere” kon doen, zo dacht men, heb je minder instructies nodig en bespaar je tijd en geheugen.
Dat is de intuïtie achter veel CISC (complex instruction set computing)-ontwerpen: geef programmeurs en compilers een gereedschapskist vol geavanceerde operaties.
De adderende factor was dat echte programma’s (en de compilers die ze vertaalden) die complexiteit niet consequent benutten. Veel van de meest uitgebreide instructies werden zelden gebruikt, terwijl een kleine set eenvoudige operaties — data laden, data opslaan, optellen, vergelijken, branchen — steeds terugkwamen.
Tegelijk maakte het ondersteunen van een enorm menu aan complexe instructies CPU's moeilijker te bouwen en trager om te optimaliseren. Complexiteit verbruikte chipoppervlak en ontwerpinspanning die anders gebruikt hadden kunnen worden om de veelvoorkomende paden voorspelbaar en snel te maken.
RISC was een reactie op die kloof: richt de CPU op wat software daadwerkelijk het grootste deel van de tijd doet, maak die paden snel — en laat compilers meer van het orkestratiewerk op een systematische manier doen.
Een eenvoudige manier om CISC vs RISC te zien is door te vergelijken met een gereedschapskist.
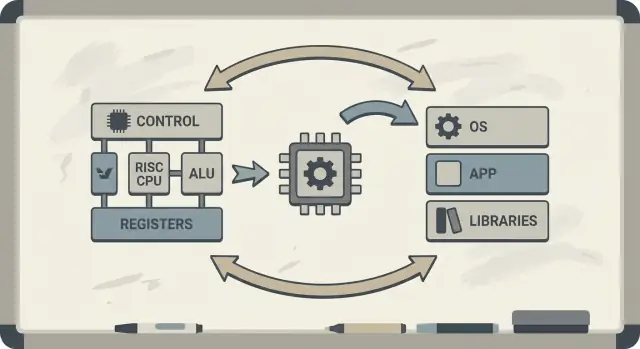
CISC (Complex Instruction Set Computing) is als een werkplaats vol gespecialiseerde, geavanceerde gereedschappen — elk kan veel in één beweging doen. Eén “instructie” kan data uit geheugen laden, een berekening uitvoeren en het resultaat opslaan, alles in één keer.
RISC (Reduced Instruction Set Computing) is als het dragen van een kleinere set betrouwbare gereedschappen die je constant gebruikt — hamer, schroevendraaier, duimstok — en alles opbouwt uit herhaalbare stappen. Elke instructie doet meestal één kleine, duidelijke taak.
Als instructies eenvoudiger en uniformer zijn, kan de CPU ze uitvoeren met een schonere assemblagelijn (een pipeline). Die assemblagelijn is makkelijker te ontwerpen, makkelijker om op hogere kloksnelheden te laten draaien en eenvoudiger om continu bezet te houden.
Met CISC-achtige “do-veel” instructies moet de CPU vaak een complexe instructie decoderen en intern in kleinere stappen opsplitsen. Dat voegt complexiteit toe en maakt het moeilijker om de pipeline vloeiend te houden.
RISC streeft naar voorspelbare instructietijden — veel instructies duren ongeveer even lang. Voorspelbaarheid helpt de CPU werk efficiënt in te plannen en helpt compilers code te genereren die de pipeline vult in plaats van doet vastlopen.
RISC heeft meestal meer instructies nodig om dezelfde taak uit te voeren. Dat kan betekenen:
Maar dat kan alsnog een goede ruil zijn als elke instructie snel is, de pipeline soepel blijft en het ontwerp eenvoudiger is.
In de praktijk kunnen goed geoptimaliseerde compilers en goede caching het nadeel van “meer instructies” compenseren — en de CPU kan meer tijd besteden aan nuttig werk en minder tijd aan het ontwarren van ingewikkelde instructies.
Berkeley RISC was niet alleen een nieuwe instructieset. Het was een onderzoeksattitude: begin niet met wat elegant lijkt op papier — begin met wat programma’s daadwerkelijk doen en vorm de CPU rond die realiteit.
Conceptueel streefde het Berkeley-team naar een CPU-core die simpel genoeg was om heel snel en voorspelbaar te draaien. In plaats van de hardware vol te proppen met ingewikkelde instructietrucs vertrouwden ze op de compiler om meer van het werk te doen: kies eenvoudige instructies, scheduleer ze goed en houd data zoveel mogelijk in registers.
Die taakverdeling was belangrijk. Een kleinere, zuivere core is makkelijker effectief te pipelinen, makkelijker te doorgronden en vaak sneller per transistor. De compiler, die het hele programma ziet, kan vooruit plannen op manieren die hardware niet eenvoudig on the fly kan doen.
David Patterson benadrukte meten omdat computerontwerp vol verleidelijke mythes zit — features die nuttig klinken maar zelden in echte code voorkomen. Berkeley RISC drong aan op het gebruik van benchmarks en workload-traces om de hete paden te vinden: loops, functie-aanroepen en geheugenaccessen die de runtime domineren.
Dat sluit direct aan bij het principe “maak de common case snel”. Als de meeste instructies eenvoudige bewerkingen en loads/stores zijn, levert optimalisatie van die frequente gevallen meer op dan het versnellen van zeldzame, complexe instructies.
De blijvende les is dat RISC zowel een architectuur als een mindset was: vereenvoudig wat frequent is, valideer met data en behandel hardware en software als één systeem dat samen af te stemmen is.
Hardware–software co-design is het idee dat je een CPU niet geïsoleerd ontwerpt. Je ontwerpt de chip en de compiler (en soms het besturingssysteem) met elkaar in gedachten, zodat echte programma’s snel en efficiënt draaien — niet alleen synthetische “beste geval” instructiesequenties.
Co-design werkt als een engineeringlus:
ISA-keuzes: de instructiesetarchitectuur (ISA) bepaalt wat de CPU gemakkelijk kan uitdrukken (bijv. “load/store” geheugenaccess, veel registers, eenvoudige adresseringsmodi).
Compilerstrategieën: de compiler past zich aan — houdt hot-variabelen in registers, herschikt instructies om stalls te vermijden en kiest calling conventions die overhead verminderen.
Workloadresultaten: je meet echte programma’s (compilers, databases, graphics, OS-code) en ziet waar tijd en energie naartoe gaan.
Volgend ontwerp: je past de ISA en microarchitectuur aan (pipeline-diepte, aantal registers, cachegroottes) op basis van die metingen.
Hier is een klein lusje (C) dat de relatie benadrukt:
for (int i = 0; i < n; i++)
sum += a[i];
Op een RISC-stijl ISA houdt de compiler typisch sum en i in registers, gebruikt eenvoudige load-instructies voor a[i], en voert instruction scheduling uit zodat de CPU bezig blijft terwijl een load onderweg is.
Als een chip complexe instructies of speciale hardware toevoegt die compilers zelden gebruiken, verbruikt dat gebied nog steeds stroom en ontwerpinspanning. Ondertussen kunnen de “saaie” dingen waarop compilers vertrouwen — genoeg registers, voorspelbare pipelines, efficiënte calling conventions — ondergefinancierd raken.
Patterson’s RISC-denken benadrukte het besteden van silicium waar echte software daadwerkelijk van kan profiteren.
Een kernidee van RISC was de CPU-"productielijn" makkelijker bezet te houden. Die productielijn is de pipeline: in plaats van één instructie helemaal af te maken voordat de volgende start, splitst de processor werk in fasen (fetch, decode, execute, write-back) en laat ze overlappen. Wanneer alles vloeit, rond je bijna één instructie per cycle af — zoals auto’s die door stations in een fabriek bewegen.
Pipelines werken het beste wanneer elk item op de lijn op elkaar lijkt. RISC-instructies zijn ontworpen om relatief uniform en voorspelbaar te zijn (vaak vaste lengte, met eenvoudige adressering). Dat vermindert “speciale gevallen” waarbij een instructie extra tijd of ongebruikelijke resources nodig heeft.
Echte programma’s zijn niet perfect glad. Soms hangt een instructie af van het resultaat van een vorige (je kunt een waarde niet gebruiken voordat die berekend is). Andere keren moet de CPU wachten op data uit geheugen, of weet hij nog niet welke branch genomen wordt.
Deze situaties veroorzaken stalls — korte pauzes waarbij een deel van de pipeline stilzit. De intuïtie is simpel: stalls gebeuren wanneer de volgende fase geen nuttig werk kan doen omdat iets wat het nodig heeft nog niet is aangekomen.
Hier komt hardware–software co-design duidelijk naar voren. Als de hardware voorspelbaar is, kan de compiler helpen door instructievolgordes te herschikken (zonder de betekenis van het programma te veranderen) om “gaten” op te vullen. Bijvoorbeeld: terwijl je wacht op een waarde, plant de compiler een onafhankelijke instructie in die niet van die waarde afhankelijk is.
De winst is gedeelde verantwoordelijkheid: de CPU blijft eenvoudiger en snel in de veelvoorkomende gevallen, terwijl de compiler meer plant. Samen verminderen ze stalls en verhogen ze de doorvoer — vaak met betere reële prestaties zonder een ingewikkelder instructieset.
Een CPU kan eenvoudige bewerkingen in een paar cycles uitvoeren, maar het ophalen van data uit hoofdgeheugen (DRAM) kan honderden cycles kosten. Die kloof bestaat omdat DRAM fysiek verder weg zit, geoptimaliseerd is voor capaciteit en kostprijs, en beperkt wordt door zowel latency (hoe lang één verzoek duurt) als bandwidth (hoeveel bytes per seconde je kunt verplaatsen).
Naarmate CPU's sneller werden, hield geheugen die snelheid niet bij — deze groeiende mismatch wordt vaak de memory wall genoemd.
Caches zijn kleine, snelle geheugens dicht bij de CPU om te voorkomen dat je bij elke toegang de DRAM-penalty betaalt. Ze werken omdat echte programma’s localiteit hebben:
Moderne chips stapelen caches (L1, L2, L3) om de “working set” van code en data dicht bij de core te houden.
Hier verdient hardware–software co-design zich terug. De ISA en de compiler samen vormen hoeveel cache-druk een programma veroorzaakt.
In dagelijkse termen is de memory wall de reden waarom een CPU met een hoge kloksnelheid toch traag kan aanvoelen: het openen van een grote app, uitvoeren van een databasequery, scrollen door een feed of verwerken van een groot dataset bottleneckt vaak op cache-misses en geheugenbandbreedte — niet op pure rekenkracht.
Lang leek de discussie over CPU's op een race: welke chip een taak het snelst afhandelt “wint”. Maar echte computers leven binnen fysieke grenzen — batterijcapaciteit, warmte, ventilatorgewaar, en elektriciteitskosten.
Daarom werd prestaties per watt een kernmaatstaf: hoeveel nuttig werk krijg je voor de energie die je besteedt.
Denk eraan als efficiëntie, niet als pieksterkte. Twee processors kunnen in dagelijks gebruik vergelijkbaar snel aanvoelen, maar de één kan het doen terwijl hij minder stroom trekt, koeler blijft en langer op dezelfde batterij draait.
In laptops en telefoons beïnvloedt dit direct batterijduur en comfort. In datacenters beïnvloedt het kosten voor stroom en koeling, plus hoe dicht je servers kunt plaatsen zonder oververhitting.
RISC-denken duwde CPU-ontwerp richting het doen van minder in hardware, maar voorspelbaarder. Een simpelere core kan energie besparen op een aantal manieren:
Het punt is niet dat “simpel altijd beter is.” Het is dat complexiteit een energiekost heeft, en een goed gekozen instructieset en microarchitectuur kunnen wat slimmigheid inruilen voor veel efficiëntie.
Telefoons geven om batterij en warmte; servers geven om stroomvoorziening en koeling. Verschillende omgevingen, dezelfde les: de snelste chip is niet altijd de beste computer. Winnaars zijn vaak ontwerpen die continue throughput leveren terwijl ze het energiegebruik onder controle houden.
RISC wordt vaak samengevat als “eenvoudigere instructies winnen”, maar de blijvende les is subtieler: de instructieset doet ertoe, maar veel reële winst kwam door hoe chips werden gebouwd, niet alleen door hoe de ISA er op papier uitzag.
Vroege RISC-argumenten suggereerden dat een schonere, kleinere instructieset automatisch computers sneller zou maken. In de praktijk kwamen de grootste snelheidswinst vaak voort uit implementatiekeuzes die RISC vergemakkelijkte: eenvoudigere decodering, dieper pipelining, hogere clocks en compilers die werk voorspelbaar konden scheduleen.
Daarom kunnen twee CPU's met verschillende ISA's verrassend dicht bij elkaar in prestaties uitkomen als hun microarchitectuur, cachegroottes, branch prediction en fabricageproces verschillen. De ISA stelt de regels; de microarchitectuur speelt het spel.
Een belangrijke verschuiving uit Patterson’s tijd was ontwerpen op basis van data, niet van aannames. In plaats van instructies toe te voegen omdat ze handig leken, maten teams wat programma’s daadwerkelijk deden en optimaliseerden de common case.
Die mindset overtrof vaak “feature-driven” ontwerp, waarbij complexiteit sneller groeit dan de baten. Het maakt ook afwegingen duidelijker: een instructie die een paar regels code spaart kan extra cycles, energie of chipruimte kosten — en die kosten doen zich overal gelden.
RISC-denken heeft niet alleen RISC-chips gevormd. In de loop der tijd adopteerden veel CISC-CPU's RISC-achtige interne technieken (bijv. het opsplitsen van complexe instructies in eenvoudiger interne operaties) terwijl ze hun compatibele ISA behielden.
Het resultaat was dus geen "RISC versloeg CISC" maar een evolutie naar ontwerpen die meten, voorspelbaarheid en strakke hardware–softwarecoördinatie waarderen — ongeacht het ISA-logo.
RISC bleef niet in het lab. Een duidelijke lijn van vroeg onderzoek naar moderne praktijk loopt van MIPS naar RISC-V — twee ISA's die eenvoud en duidelijkheid als feature, niet als beperking beschouwden.
MIPS wordt vaak herinnerd als een onderwijs-ISA, en met reden: de regels zijn eenvoudig uit te leggen, instructieformaten zijn consistent en het load/store-model bemoeit zich niet in de weg van de compiler.
Die eenvoud was niet alleen academisch. MIPS-processors werden jarenlang in echte producten geleverd (van workstations tot embedded systemen), deels omdat een overzichtelijke ISA het makkelijker maakte om snelle pipelines, voorspelbare compilers en efficiënte toolchains te bouwen. Wanneer hardwaregedrag regelmatig is, kan software eromheen plannen.
RISC-V blies nieuw leven in RISC-denken door een belangrijke stap te zetten die MIPS nooit deed: het is een open ISA. Dat verandert de prikkels. Universiteiten, startups en grote bedrijven kunnen experimenteren, silicon shippen en tooling delen zonder te onderhandelen over toegang tot de instructieset zelf.
Voor co-design is die openheid belangrijk omdat de “softwarekant” (compilers, besturingssystemen, runtimes) publiekelijk tegelijk met de “hardwarekant” kan evolueren, met minder kunstmatige barrières.
Een andere reden dat RISC-V goed aansluit op co-design is de modulaire aanpak. Je begint met een kleine basis-ISA en voegt dan extensies toe voor specifieke behoeften — zoals vectorbewerkingen, embedded constraints of beveiligingsfuncties.
Dit stimuleert een gezondere afweging: in plaats van alle mogelijke features in één monolithisch ontwerp te stoppen, kunnen teams hardwarefuncties afstemmen op de software die ze daadwerkelijk draaien.
Als je een uitgebreider primer wilt, zie /blog/what-is-risc-v.
Co-design is geen historische voetnoot uit het RISC-tijdperk — het is hoe moderne computing blijft versnellen en efficiënter wordt. Het kernidee is nog steeds Patterson-achtig: je wint niet met alleen hardware of alleen software. Je wint als de twee op elkaars sterktes en beperkingen zijn afgestemd.
Smartphones en veel embedded apparaten leunen zwaar op RISC-principes (vaak ARM-gebaseerd): eenvoudigere instructies, voorspelbare uitvoering en sterke nadruk op energiegebruik.
Die voorspelbaarheid helpt compilers efficiënte code te genereren en ontwerpers cores te bouwen die zuinig zijn tijdens scrollen, maar kunnen opschalen voor een camera-pijplijn of game.
Laptops en servers streven steeds vaker naar hetzelfde doel — vooral prestaties per watt. Zelfs wanneer de instructieset niet traditioneel “RISC” is, richten veel interne ontwerpkeuzes zich op RISC-achtige efficiëntie: diepe pipelining, brede uitvoering en agressief powermanagement afgestemd op echt softwaregedrag.
GPU's, AI-accelerators (TPU's/NPUs) en media-engines zijn praktische vormen van co-design: in plaats van al het werk door een algemene CPU te dwingen, biedt het platform hardware die bij veelvoorkomende rekenpatronen past.
Wat dit co-design maakt (niet alleen “extra hardware”) is de omliggende softwarestack:
Als de software de accelerator niet target, blijft de theoretische snelheid theoretisch.
Twee platforms met vergelijkbare specificaties kunnen heel verschillend aanvoelen omdat het “echte product” compilers, libraries en frameworks omvat. Een goed geoptimaliseerde math-library (BLAS), een goede JIT of een slimmere compiler kan grote winsten opleveren zonder de chip te veranderen.
Daarom wordt modern CPU-ontwerp vaak benchmark-gedreven: hardwareteams kijken naar wat compilers en workloads daadwerkelijk doen en passen dan features aan (caches, branch prediction, vectorinstructies, prefetching) om de common case sneller te maken.
Wanneer je een platform evalueert (telefoon, laptop, server of embedded board), let op co-design-signalen:
Moderne voortgang in computing draait minder om één “snellere CPU” en meer om een compleet hardware-plus-softwaresysteem dat is gevormd — gemeten en vervolgens ontworpen — rond echte workloads.
RISC-denken en Patterson’s bredere boodschap zijn te herleiden tot enkele duurzame lessen: vereenvoudig wat snel moet zijn, meet wat werkelijk gebeurt en behandel hardware en software als één systeem — want gebruikers ervaren het geheel, niet de onderdelen.
Ten eerste is eenvoud een strategie, geen esthetiek. Een schone instructiesetarchitectuur (ISA) en voorspelbare uitvoering maken het makkelijker voor compilers om goede code te genereren en voor CPU's om die code efficiënt uit te voeren.
Ten tweede verslaat meten intuïtie. Benchmarks met representatieve workloads, profileringsdata verzamelen en echte bottlenecks leidend laten zijn voor ontwerpkeuzes — of je nu compileroptimalisaties tunet, een CPU-SKU kiest of een kritisch hot path herontwerpt.
Ten derde stapelen de winsten zich op bij co-design. Pipeline-vriendelijke code, cache-bewuste datastructuren en realistische prestaties-per-watt-doelen leveren vaak meer praktische snelheid dan het najagen van piektheoretische doorvoer.
Als je een platform selecteert (x86, ARM of RISC-V-gebaseerd), evalueer het zoals je gebruikers dat zullen doen:
Als een deel van je werk deze metingen in verzonden software omzetten is, kan het helpen de build–measure-lus te verkorten. Teams gebruiken bijvoorbeeld Koder.ai om prototypes en echte applicaties te bouwen via een chat-gestuurde workflow (web, backend en mobiel) en daarna dezelfde end-to-end benchmarks opnieuw uit te voeren na elke wijziging. Functies zoals planning mode, snapshots en rollback ondersteunen dezelfde “meet, daarna ontwerp” discipline die Patterson aanmoedigde — toegepast op modern productontwikkeling.
Voor een dieper primer over efficiëntie, zie /blog/performance-per-watt-basics. Als je omgevingen vergelijkt en een eenvoudige manier nodig hebt om kosten/performancetrade-offs te schatten, verwijst materiaal naar /pricing.
De blijvende conclusie: de ideeën — eenvoud, meten en co-design — blijven renderen, zelfs terwijl implementaties evolueren van MIPS-tijdperk pipelining naar moderne heterogene cores en nieuwe ISA's zoals RISC-V.
RISC (Reduced Instruction Set Computing) benadrukt een kleinere set eenvoudige, regelmatige instructies die makkelijk te pipelinen en te optimaliseren zijn. Het doel is niet “minder mogelijkheden”, maar meer voorspelbare, efficiënte uitvoering van de bewerkingen die echte programma’s het meest gebruiken (loads/stores, rekenwerk, branches).
CISC biedt veel complexe, gespecialiseerde instructies die soms meerdere stappen in één instructie samenvoegen. RISC gebruikt eenvoudigere bouwstenen (vaak load/store + ALU-operaties) en vertrouwt meer op compilers om die blokken efficiënt te combineren. In moderne CPU's is de grens wazig omdat veel CISC-chips complexe instructies naar eenvoudiger interne operaties vertalen.
Eenvoudigere, uniformere instructies maken het makkelijker om een vloeiende pipeline te bouwen (een “productielijn” voor instructie-uitvoering). Dat kan de doorvoer verbeteren (dicht bij één instructie per cycle) en de tijd verminderen die aan speciale gevallen wordt besteed, wat zowel prestaties als energiegebruik ten goede komt.
Een voorspelbare ISA en uitvoeringsmodel stelt compilers in staat om betrouwbaar:
Dat vermindert pipeline-bubbels en verspilde cycles, en verbetert reële prestaties zonder ingewikkelde hardwarefuncties toe te voegen die de software toch niet gebruikt.
Hardware–software co-design is een iteratieve lus waarbij ISA-keuzes, compilerstrategieën en gemeten workload-resultaten elkaar informeren. In plaats van een CPU geïsoleerd te ontwerpen stemmen teams hardware, toolchain en soms OS/runtime op elkaar af zodat echte programma’s sneller en efficiënter draaien.
Stalls ontstaan wanneer de pipeline niet verder kan omdat hij ergens op moet wachten:
RISC-achtige voorspelbaarheid helpt zowel hardware als compilers om de frequentie en kosten van deze pauzes te verminderen.
De “memory wall” is de groeiende kloof tussen snelle CPU-uitvoering en trage hoofdgeheugen-toegang (DRAM). Caches (L1/L2/L3) mitigeren dit door localiteit te benutten (temporale en spatiale), maar cache-misses kunnen nog steeds runtime domineren—waardoor programma’s zelfs op snelle cores geheugen-gebonden raken.
Het is een maat voor efficiëntie: hoeveel nuttig werk je krijgt per eenheid energie. In de praktijk beïnvloedt het batterijduur, warmte, ventilatorgeluid en de kosten voor stroom/koeling in datacenters. Ontwerpen beïnvloed door RISC-denken richten zich vaak op voorspelbare uitvoering en minder verspilde schakelingen, wat de prestaties per watt kan verbeteren.
Veel CISC-ontwerpen implementeerden uiteindelijk RISC-achtige interne technieken (pipelining, eenvoudiger micro-ops, sterke nadruk op caches en voorspelling) terwijl ze hun compatibele ISA behielden. De langere termijn winst was dus eerder een mindset: meet echte workloads, optimaliseer het veelvoorkomende en stem hardware op compiler-/softwaregedrag af, ongeacht het ISA-logo.
RISC-V is een open ISA met een kleine basis en modulaire extensies, wat het uitermate geschikt maakt voor co-design: teams kunnen hardwarefuncties afstemmen op specifieke softwarebehoeften en toolchains publiekelijk laten evolueren. Het is een moderne voortzetting van de “simpel core + sterke tools + meten” benadering in het artikel. Zie ook de tekst over /blog/what-is-risc-v.