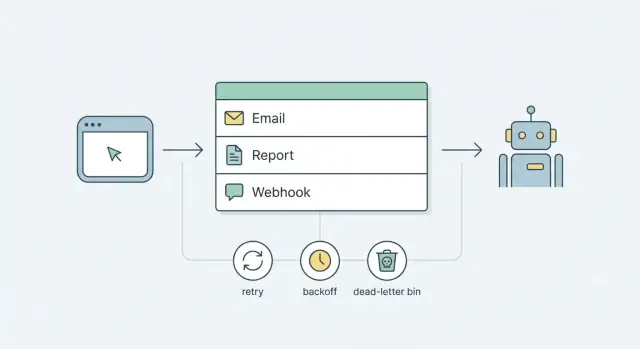
Waarom je achtergrondtaken nodig hebt (en waarom het snel rommelig wordt)
Werk dat langer dan een seconde of twee kan duren, moet niet binnen een gebruikersrequest draaien. E-mails verzenden, rapporten genereren en webhooks leveren hangen allemaal af van netwerken, externe diensten of trage queries. Soms haperen ze, falen ze of duren ze gewoon langer dan je verwacht.
Als je dat werk doet terwijl de gebruiker wacht, merken mensen het direct. Pagina's hangen, de "Opslaan"-knop draait, en requests time'en out. Retries kunnen ook op de verkeerde plek gebeuren. Een gebruiker ververst de pagina, je load balancer probeert opnieuw, of je frontend stuurt het formulier nogmaals en je krijgt dubbele e-mails, dubbele webhook-aanroepen of twee rapportruns die elkaar beconcurreren.
Achtergrondtaken lossen dit op door requests klein en voorspelbaar te houden: accepteer de actie, registreer een job om later uit te voeren, en reageer snel. De job draait buiten het request, met regels die jij controleert.
Het lastige is betrouwbaarheid. Zodra werk uit het request pad gaat, moet je nog steeds vragen beantwoorden zoals:
- Wat als de e-mailprovider 3 minuten down is?
- Wat als een webhook-endpoint 500 teruggeeft, of time-out?
- Wat als de job twee keer draait?
- Hoe merk je vastgelopen jobs voordat gebruikers klagen?
Veel teams reageren door "zware infrastructuur" toe te voegen: een message broker, aparte worker-fleets, dashboards, alerting en playbooks. Die tools zijn nuttig als je ze echt nodig hebt, maar ze voegen ook nieuwe bewegende onderdelen en nieuwe faalwijzen toe.
Een beter startdoel is eenvoudiger: betrouwbare jobs met onderdelen die je al hebt. Voor de meeste producten betekent dat een database-backed queue plus een klein workerproces. Voeg een duidelijke retry- en backoffstrategie toe en een dead-letterpatroon voor jobs die blijven falen. Je krijgt voorspelbaar gedrag zonder vanaf dag één aan een complex platform vast te zitten.
Ook als je snel bouwt met een chatgestuurde tool zoals Koder.ai blijft deze scheiding belangrijk. Gebruikers moeten nu een snelle response krijgen en je systeem moet langzaam, foutgevoelig werk veilig op de achtergrond afronden.
Wat een queue in eenvoudige termen is
Een queue is een wachtlijst voor werk. In plaats van trage of onbetrouwbare taken tijdens een gebruikersrequest uit te voeren (een e-mail sturen, een rapport opbouwen, een webhook aanroepen), zet je een klein record in een queue en geef je snel antwoord. Later pakt een apart proces dat record op en doet het werk.
Een paar woorden die je vaak ziet:
- Job: één eenheid werk, zoals "stuur welkomstmail naar gebruiker 123".
- Worker: de code die jobs ophaalt en uitvoert.
- Attempt: één poging om een job uit te voeren.
- Schedule: wanneer de job moet draaien (nu of later).
- Queue: waar jobs wachten totdat een worker ze pakt.
De simpelste flow ziet er zo uit:
-
Enqueue: je app slaat een jobrecord op (type, payload, runtime).
-
Claim: een worker vindt de volgende beschikbare job en "lockt" die zodat slechts één worker hem uitvoert.
-
Run: de worker voert de taak uit (verzenden, genereren, leveren).
-
Finish: markeer het als klaar, of registreer een fout en stel de volgende runtijd in.
Als je jobvolume bescheiden is en je al een database hebt, is een database-backed queue vaak voldoende. Het is makkelijk te begrijpen, makkelijk te debuggen en voldoet aan veelvoorkomende behoeften zoals e-mailtaakverwerking en betrouwbare webhook-levering.
Streamingplatformen beginnen zinvol te worden als je zeer hoge throughput nodig hebt, veel onafhankelijke consumers of de mogelijkheid om enorme eventgeschiedenissen te replayen naar vele systemen. Als je tientallen services draait met miljoenen events per uur, kunnen tools zoals Kafka helpen. Tot die tijd dekt een databasetabel plus een workerloop een groot deel van echte wereldqueues.
De minimale gegevens die je voor elke job moet bijhouden
Een database-queue blijft alleen beheersbaar als elk jobrecord snel drie vragen beantwoordt: wat te doen, wanneer opnieuw proberen, en wat gebeurde de vorige keer. Krijg dat goed en operations worden saai (wat het doel is).
Wat je in de payload moet opslaan (en wat niet)
Sla de kleinste input op die nodig is om het werk te doen, niet de volledig gerenderde output. Goede payloads zijn IDs en een paar parameters, zoals { "user_id": 42, "template": "welcome" }.
Vermijd grote blobs (volledige HTML-e-mails, grote reportdata, enorme webhook-lichamen). Dat laat je database sneller groeien en maakt debuggen lastiger. Als de job een groot document nodig heeft, sla dan een referentie op: report_id, export_id of een file key. De worker kan de volledige data ophalen wanneer hij draait.
De velden die zichzelf terugbetalen
Maak minimaal ruimte voor:
- job_type + payload:
job_type selecteert de handler (send_email, generate_report, deliver_webhook). payload bevat kleine inputs zoals IDs en opties.
- status: houd het expliciet (bijvoorbeeld:
queued, running, succeeded, failed, dead).
- attempt tracking:
attempt_count en max_attempts zodat je stopt met retryen wanneer het duidelijk niet werkt.
- tijdfvelden:
created_at en next_run_at (wanneer het in aanmerking komt). Voeg started_at en finished_at toe als je betere zichtbaarheid in trage jobs wilt.
- idempotency + last error: een
idempotency_key om dubbele effecten te voorkomen, en last_error zodat je ziet waarom het faalde zonder door stapels logs te hoeven graven.
Idempotency klinkt chique, maar het idee is simpel: als dezelfde job twee keer draait, moet de tweede run detecteren dat en niets gevaarlijks doen. Bijvoorbeeld kan een webhook-delivery-job een idempotency key gebruiken zoals webhook:order:123:event:paid zodat je hetzelfde event niet twee keer levert als een retry overlapt met een timeout.
Leg ook een paar basisnummers vroeg vast. Je hoeft geen groot dashboard te hebben om te beginnen, alleen queries die je vertellen: hoeveel jobs staan er in de wachtrij, hoeveel falen er, en wat is de leeftijd van de oudste job.
Stap voor stap: een eenvoudige database-queue die je vandaag kunt bouwen
Als je al een database hebt, kun je een achtergrondqueue starten zonder nieuwe infrastructuur. Jobs zijn rijen, en een worker is een proces dat steeds due rijen pakt en het werk doet.
1) Maak een jobs-tabel
Houd de tabel klein en saai. Je wilt genoeg velden om jobs later te runnen, retryen en te debuggen.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued',
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Als je op Postgres bouwt (gebruikelijk bij Go-backends), is jsonb een praktische manier om jobdata op te slaan zoals { "user_id":123,"template":"welcome" }.
2) Enqueue veilig (vooral bij gebruikersacties)
Wanneer een gebruikersactie een job moet triggeren (e-mail verzenden, webhook afvuren), schrijf de jobrij in dezelfde database-transactie als de hoofdwijziging wanneer mogelijk. Dat voorkomt "gebruiker gemaakt maar job ontbreekt" als er een crash gebeurt direct na de hoofdwrite.
Voorbeeld: wanneer een gebruiker zich aanmeldt, insert je de user-rij en een send_welcome_email job in één transactie.
3) Draai een workerloop die kan schalen
Een worker herhaalt dezelfde cyclus: vind één due job, claim hem zodat niemand anders hem neemt, verwerk hem, en markeer hem daarna als klaar of plan een retry.
In de praktijk betekent dat:
- Pak één job waar
status='queued' en next_run_at <= now().
- Claim hem atomair (in Postgres is
SELECT ... FOR UPDATE SKIP LOCKED een gebruikelijke aanpak).
- Zet
status='running', locked_at=now(), locked_by='worker-1'.
- Verwerk de job.
- Markeer hem afgerond (bijvoorbeeld
done/succeeded), of registreer last_error en plan de volgende poging.
Meerdere workers kunnen tegelijk draaien. De claim-stap voorkomt dubbel pakken.
4) Handel shutdown af zonder jobs te breken
Bij shutdown: stop met nieuwe jobs aannemen, maak de huidige af en sluit af. Als een proces midden in een job sterft, gebruik dan een simpele regel: behandel jobs die running staan en ouder zijn dan een timeout als weer-eligible om opnieuw in de wachtrij te worden gezet door een periodieke "reaper" taak.
Als je in Koder.ai bouwt, is dit database-queuepatroon een solide standaard voor e-mails, rapporten en webhooks voordat je gespecialiseerde queueservices toevoegt.
Retries en backoff die geen chaos veroorzaken
Modelleer jobtypes overzichtelijk
Maak aparte jobtypes voor e-mails, webhooks en rapporten met heldere regels per handler.
Retries zijn hoe een queue kalm blijft als de echte wereld rommelig is. Zonder duidelijke regels worden retries een lawaaierige lus die gebruikers spamt, API's bestookt en de echte bug verbergt.
Begin met beslissen wat moet retryen en wat snel moet falen.
Retry tijdelijke problemen: netwerktimeouts, 502/503-fouten, rate limits of een korte database-verbindingblip.
Fail snel wanneer de job nooit zal slagen: een ontbrekend e-mailadres, een 400-respons van een webhook omdat de payload ongeldig is, of een rapportaanvraag voor een verwijderde account.
Backoff is de pauze tussen pogingen. Lineaire backoff (5s, 10s, 15s) is simpel, maar kan nog steeds verkeersgolven creëren. Exponentiële backoff (5s, 10s, 20s, 40s) spreidt de load beter en is meestal veiliger voor webhooks en derde partijen. Voeg jitter toe (een kleine willekeurige extra vertraging) zodat duizend jobs niet exact op hetzelfde moment tegelijk opnieuw proberen na een outage.
Regels die goed werken in productie:
- Retry alleen bij duidelijk tijdelijke fouten (timeouts, 429, 5xx).
- Gebruik exponentiële backoff met jitter.
- Beperk pogingen en markeer de job daarna als failed.
- Stel een timeout per poging in zodat workers niet vastlopen.
- Maak elke job idempotent zodat retries geen duplicaten maken.
Max attempts beperkt schade. Voor veel teams zijn 5 tot 8 pogingen genoeg. Daarna stop je met retryen en parkeer je de job voor review (een dead-letter flow) in plaats van eeuwig door te blijven draaien.
Timeouts voorkomen "zombie" jobs. E-mails kunnen timeouts hebben van 10–20 seconden per poging. Webhooks hebben vaak een kortere limiet, zoals 5–10 seconden, omdat de ontvanger down kan zijn en je door wilt gaan. Rapportgeneratie mag enkele minuten toestaan, maar moet nog steeds een harde cutoff hebben.
Als je dit in Koder.ai bouwt, behandel should_retry, next_run_at en een idempotency key als first-class velden. Die kleine details houden het systeem stil als er iets misgaat.
Dead-letter-afhandeling en eenvoudige operatie
Een dead-letterstatus is waar jobs heen gaan wanneer retries niet langer veilig of nuttig zijn. Het maakt stil falen zichtbaar: iets dat je kunt zoeken en waar je op kunt acteren.
Wat je opslaat bij een dead-letter job
Sla genoeg op om te begrijpen wat er gebeurde en om de job te replayen zonder te moeten raden, maar wees voorzichtig met geheimen.
Bewaar:
- De jobinputs (payload) precies zoals gebruikt, plus jobtype en versie
- Het laatste foutbericht en een korte stacktrace (of een errorcode als je geen stacks hebt)
- Pogingentelling, eerste runtijd, laatste runtijd en next_run_time (als die gepland was)
- De worker-identiteit (servicenaam, host) en een correlatie-ID voor logs
- Een dead-letter reden (timeout, validatiefout, 4xx van vendor, enz.)
Als de payload tokens of persoonlijke data bevat, redacteer of versleutel deze voordat je opslaat.
Een eenvoudige triage workflow
Wanneer een job dead-letter raakt, neem snel een beslissing: retry, fix of negeren.
Retry is voor externe outages en timeouts. Fix is voor slechte data (ontbrekend e-mailadres, verkeerde webhook-URL) of een bug in je code. Negeer moet zeldzaam zijn, maar kan geldig zijn wanneer de job niet meer relevant is (bijvoorbeeld: de klant verwijderde zijn account). Als je negeert, noteer een reden zodat het niet lijkt alsof de job verdwenen is.
Manuele requeue is het veiligst wanneer het een nieuwe job creëert en de oude immutable houdt. Markeer de dead-letter job met wie hem requeued heeft, wanneer en waarom, en enqueue vervolgens een frisse kopie met een nieuw ID.
Voor alerting: houd signalen in de gaten die meestal echt pijn betekenen: snel stijgend aantal dead-letters, dezelfde fout die zich over veel jobs herhaalt, en oude queued jobs die niet geclaimd worden.
Als je Koder.ai gebruikt, kunnen snapshots en rollback helpen als een slechte release plotseling fouten doet stijgen, omdat je snel terug kunt draaien terwijl je onderzoekt.
Tenslotte: voeg veiligheidskleppen toe voor vendor-outages. Rate-limit verzendingen per provider en gebruik een circuit breaker: als een webhook-endpoint hard faalt, pauzeer nieuwe pogingen voor een korte periode zodat je hun servers (en die van jezelf) niet overstroomt.
Patronen voor e-mails, rapporten en webhooks
Breng de request–job-scheiding live
Genereer een React- en Go-app die aanvragen snel houdt en langzaam werk naar workers verplaatst.
Een queue werkt het beste wanneer elk jobtype duidelijke regels heeft: wat telt als succes, wat moet retryen, en wat mag nooit twee keer gebeuren.
E-mails. De meeste e-mailfouten zijn tijdelijk: providertimeouts, rate limits of korte outages. Behandel die als retryable met backoff. Het grootste risico is dubbele verzendingen, dus maak e-mailjobs idempotent. Sla een stabiele dedupe key op zoals user_id + template + event_id en weiger te verzenden als die key al als verzonden is gemarkeerd.
Het is ook de moeite waard om template-naam en -versie op te slaan (of een hash van het gerenderde onderwerp/body). Als je jobs ooit opnieuw moet draaien, kun je kiezen of je exact dezelfde inhoud opnieuw stuurt of opnieuw renderen met de nieuwste template. Als de provider een message ID teruggeeft, sla die op zodat support kan achterhalen wat er gebeurde.
Rapporten. Rapporten falen anders. Ze kunnen minuten duren, paginering tegenkomen of out-of-memory gaan als je alles in één keer doet. Verdeel werk in kleinere stukken. Een veelgebruikt patroon is: één "report request" job maakt veel "page" (of "chunk") jobs, die elk een deel van de data verwerken.
Sla resultaten op voor later downloaden in plaats van de gebruiker te laten wachten. Dat kan een databasetabel zijn op sleutel report_run_id, of een filereferentie plus metadata (status, aantal rijen, created_at). Voeg progressvelden toe zodat de UI "processing" vs "ready" kan tonen zonder te raden.
Webhooks. Webhooks gaan over leveringsbetrouwbaarheid, niet snelheid. Onderteken elk verzoek (bijvoorbeeld HMAC met een gedeeld geheim) en voeg een timestamp toe om replay te voorkomen. Retry alleen wanneer de ontvanger later kan slagen.
Een simpele regelsuite:
- Retry bij timeouts en 5xx-responses, met backoff en een maximaal aantal pogingen.
- Behandel de meeste 4xx-responses als permanente fouten en stop met retryen.
- Registreer de laatste statuscode en een korte response body voor debugging.
- Gebruik een idempotency key zodat ontvangers veilig duplicaten kunnen negeren.
- Beperk payloadgrootte en log wat je daadwerkelijk stuurde.
Ordering en prioriteit. De meeste jobs hebben geen strikte ordering nodig. Wanneer ordering belangrijk is, is het meestal per key (per gebruiker, per factuur, per webhook-endpoint). Voeg een group_key toe en draai slechts één in-flight job per key.
Voor prioriteit scheid je urgent werk van traag werk. Een grote rapportachterstand mag wachtwoord-reset e-mails niet vertragen.
Voorbeeld: na een aankoop enqueue je (1) een orderbevestigingsmail, (2) een partner-webhook, en (3) een rapportupdatejob. De e-mail kan snel retryen, de webhook retryt langer met backoff, en het rapport draait later op lage prioriteit.
Een realistisch voorbeeld: signupflow plus webhook plus nightly report
Een gebruiker meldt zich aan voor je app. Drie dingen moeten gebeuren, maar geen van hen mag de signup-pagina vertragen: stuur een welkomstmail, informeer je CRM via een webhook en neem de gebruiker op in een nightly activity report.
Wat er bij signup in de wachtrij komt
Direct nadat je de gebruiker rij hebt aangemaakt, schrijf je drie jobrijen naar je database-queue. Elke rij heeft een type, een payload (zoals user_id), een status, een pogingentelling en een next_run_at timestamp.
Een typische lifecycle ziet er zo uit:
queued: aangemaakt en wacht op een workerrunning: een worker heeft het geclaimdsucceeded: klaar, geen werk meerfailed: gefaald, gepland voor later of buiten retriesdead: te vaak gefaald en heeft menselijke aandacht nodig
De welkomstmail-job bevat een idempotency key zoals welcome_email:user:123. Voordat je verzendt, controleert de worker een tabel met voltooide idempotency keys (of handhaaft een unique constraint). Als de job twee keer draait vanwege een crash, ziet de tweede run de key en slaat hij het verzenden over. Geen dubbele welkomstmails.
Een fout en hoe die herstelt
Stel dat het CRM-webhook-endpoint down is. De webhook-job faalt met een timeout. Je worker plant een retry met backoff (bijvoorbeeld: 1 minuut, 5 minuten, 30 minuten, 2 uur) plus wat jitter zodat veel jobs niet exact tegelijk opnieuw proberen.
Na het maximaal aantal pogingen wordt de job dead. De gebruiker is nog steeds aangemaakt, kreeg de welkomstmail en het nightly report kan normaal draaien. Alleen de CRM-notificatie zit vast en is zichtbaar.
De volgende ochtend kan support (of degene met dienst) het zonder uren in logs zoeken afhandelen:
- Filter dead jobs op type (bijvoorbeeld
webhook.crm).
- Lees het laatste foutbericht en bevestig dat de payload er goed uitziet.
- Controleer of de CRM weer online is.
- Requeue de job (dead -> queued, reset attempts) of schakel die bestemming tijdelijk uit.
Als je apps bouwt op een platform zoals Koder.ai, geldt hetzelfde patroon: houd de gebruikersflow snel, duw neveneffecten naar jobs en maak fouten eenvoudig te inspecteren en opnieuw te draaien.
Veelgemaakte fouten die queues onbetrouwbaar maken
Genereer een Go-worker-loop
Laat Koder.ai een Go-worker genereren met veilige jobclaiming en timeouts.
De snelste manier om een queue te breken is hem als optioneel te behandelen. Teams beginnen vaak met "stuur de e-mail deze ene keer in het request" omdat dat eenvoudiger voelt. Dan verspreidt het zich: wachtwoordresets, bonnen, webhooks, rapportexports. Voor je het weet voelt de app traag, timeouts stijgen en elke derde partij hapering wordt jouw outage.
Een andere valkuil is het overslaan van idempotency. Als een job twee keer kan draaien, mag het niet twee resultaten maken. Zonder idempotency veranderen retries in dubbele e-mails, herhaalde webhook-events of erger.
Een derde probleem is zichtbaarheid. Als je alleen via supporttickets over fouten hoort, schaadt de queue al gebruikers. Zelfs een basis intern overzicht dat jobcounts per status toont plus doorzoekbare last_error bespaart veel tijd.
Betrouwbaarheidskillers om op te letten
Enkele problemen die vroeg opduiken, zelfs in eenvoudige queues:
- Direct opnieuw proberen bij falen. Als een provider down is, veroorzaken snelle retries je eigen traffic spike.
- Slow jobs mengen met urgente jobs. Een 10-minuten rapport kan een "verifieer je e-mail" bericht blokkeren.
- Fouten eeuwig als tijdelijk behandelen. Jobs die nooit zullen slagen blijven draaien en verbergen echte problemen.
- Geen eigenaarschap van payloadversies. Als je de jobvorm verandert, kunnen oude jobs gaan falen.
- Rate limits negeren. Queues kunnen providers overstroomen die je throttlen.
Backoff voorkomt zelfgemaakte outages. Zelfs een basis schema zoals 1 minuut, 5 minuten, 30 minuten, 2 uur maakt falen veiliger. Stel ook een max attempts in zodat een kapotte job stopt en zichtbaar wordt.
Als je op een platform zoals Koder.ai bouwt, helpt het om deze basics tegelijk met de feature te leveren, niet weken later als schoonmaakproject.
Snel checklist en volgende stappen
Voordat je meer tooling toevoegt, zorg dat de basics solide zijn. Een database-backed queue werkt goed wanneer elke job makkelijk te claimen, makkelijk te retryen en makkelijk te inspecteren is.
Een korte betrouwbaarheid-checklist:
- Elke job heeft: id, type, payload, status, attempts, max_attempts, run_at/next_run_at en last_error.
- Workers claimen jobs veilig (één worker krijgt één job) en herstellen na crashes (lock timeout + reaper).
- Elke job heeft een duidelijke timeout zodat vast werk retryable wordt in plaats van voor altijd te hangen.
- Retries zijn beperkt en de vertraging tussen pogingen groeit (backoff) om thundering herds te vermijden.
- Er is een dead-letter state (of tabel) plus een duidelijke manier om jobs opnieuw uit te voeren of weg te gooien.
Kies daarna je eerste drie jobtypes en beschrijf hun regels. Bijvoorbeeld: wachtwoordreset-e-mail (snelle retries, korte max), nightly report (weinig retries, langere timeouts), webhook-levering (meer retries, langere backoff, stop bij permanente 4xx).
Als je twijfelt wanneer een database-queue niet meer genoeg is, let op signalen zoals row-level contention door veel workers, strikte orderingbehoeften over veel jobtypes, grote fan-out (één event triggert duizenden jobs) of cross-service consumptie waarbij verschillende teams verschillende workers beheren.
Als je een snel prototype wilt, kun je de flow schetsen in Koder.ai (koder.ai) met planning mode, de jobs-tabel en workerloop genereren en itereren met snapshots en rollback voordat je uitrolt.