21 mei 2025·8 min
Bouw een webapp voor gecentraliseerde SLA-rapportage
Leer hoe je een multi-client webapp plant, bouwt en lanceert die SLA-data verzamelt, metrics normaliseert en dashboards, meldingen en exporteerbare rapporten levert.
Leer hoe je een multi-client webapp plant, bouwt en lanceert die SLA-data verzamelt, metrics normaliseert en dashboards, meldingen en exporteerbare rapporten levert.
Gecentraliseerde SLA-rapportage bestaat omdat SLA-evidence zelden op één plek staat. Uptime kan in een monitoringtool zitten, incidenten op een statuspagina, tickets in een helpdesk en escalatienotities in e-mail of chat. Wanneer elke klant een iets andere stack heeft (of verschillende naamgevingsconventies), wordt maandelijkse rapportage handmatig spreadsheetwerk — en ontstaan er vaak meningsverschillen over “wat er werkelijk is gebeurd”.
Een goede SLA-rapportage-webapp bedient meerdere doelgroepen met verschillende doelen:
De app moet dezelfde onderliggende waarheid op verschillende detailniveaus tonen, afhankelijk van de rol.
Een gecentraliseerd SLA-dashboard moet opleveren:
In de praktijk moet elk SLA-getal traceerbaar zijn tot ruwe events (alerts, tickets, incidenttijdlijnen) met timestamps en eigenaarschap.
Voordat je iets bouwt, definieer wat in scope en out of scope is. Bijvoorbeeld:
Duidelijke grenzen voorkomen discussies later en houden rapportage consistent over klanten heen.
Minimaal moet gecentraliseerde SLA-rapportage vijf workflows ondersteunen:
Ontwerp vanuit deze workflows vanaf dag één en de rest van het systeem (datamodel, integraties en UX) blijft afgestemd op echte rapportagebehoeften.
Voordat je schermen of pipelines bouwt, beslis wat je app zal meten en hoe die cijfers geïnterpreteerd moeten worden. Het doel is consistentie: twee mensen die hetzelfde rapport lezen moeten tot dezelfde conclusie komen.
Begin met een kleine set die de meeste klanten herkennen:
Wees expliciet over wat elke metric meet en wat het niet meet. Een korte definitiesectie in de UI (en een verwijzing naar /help/sla-definitions) voorkomt misverstanden later.
Regels zijn waar SLA-rapportage meestal faalt. Documenteer ze in zinnen die je klant kan valideren, en zet ze daarna om in logica.
Behandel de essentie:
Kies standaardperiodes (maandelijks en per kwartaal zijn gebruikelijk) en of je aangepaste reeksen ondersteunt. Verduidelijk de gebruikte tijdzone voor cutoffs.
Voor breaches definieer je:
Voor elke metric, maak een lijst met vereiste inputs (monitoring-events, incidentrecords, tickettimestamps, onderhoudsvensters). Dit wordt je blauwdruk voor integraties en data quality checks.
Voordat je dashboards of KPI's ontwerpt, wees duidelijk waar SLA-evidence werkelijk staat. De meeste teams ontdekken dat hun “SLA-data” verdeeld is over tools, eigendom bij verschillende groepen en met licht verschillende betekenissen.
Begin met een eenvoudige lijst per klant (en per service):
Noteer voor elk systeem de eigenaar, retentieperiode, API-limieten, tijdresolutie (seconden vs minuten) en of data klantgescopeerd of gedeeld is.
De meeste SLA-rapportage-webapps gebruiken een combinatie:
Een praktische regel: gebruik webhooks waar actualiteit telt, en API-pulls waar volledigheid telt.
Verschillende tools beschrijven hetzelfde op verschillende manieren. Normaliseer naar een klein set events waarop je app kan vertrouwen, zoals:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolvedNeem consistente velden op: client_id, service_id, source_system, external_id, severity en timestamps.
Sla alle timestamps op in UTC, en converteer bij weergave op basis van de voorkeurstijdzone van de klant (vooral voor maandelijkse rapportagecutoffs).
Plan ook voor gaten: sommige klanten hebben geen statuspagina's, sommige services worden niet 24/7 gemonitord en sommige tools kunnen events verliezen. Maak “deels dekking” zichtbaar in rapporten (bijv. “monitoringdata niet beschikbaar voor 3 uur”) zodat SLA-resultaten niet misleidend zijn.
Als je app SLA's voor meerdere klanten rapporteert, bepalen architectuurbeslissingen of je veilig kunt schalen zonder datakruising tussen klanten.
Begin met het benoemen van de lagen die je moet ondersteunen. Een “klant” kan zijn:
Schrijf deze vroeg op, want ze beïnvloeden permissies, filters en hoe je configuratie opslaat.
De meeste SLA-rapportage-apps kiezen één van deze:
tenant_id. Kosteneffectief en eenvoudiger te beheren, maar vereist strikte querydiscipline.Een veelvoorkomend compromis is een gedeelde DB voor de meeste tenants en dedicated DB's voor “enterprise” klanten.
Isolatie moet gelden over:
tenant_id meenemen zodat resultaten niet naar de verkeerde tenant worden geschrevenGebruik guardrails zoals row-level security, verplichte queryscopes en geautomatiseerde tests voor tenantgrenzen.
Verschillende klanten hebben verschillende targets en definities. Plan voor per-tenant instellingen zoals:
Interne gebruikers moeten vaak “impersonate” kunnen doen. Implementeer een bewuste switch (geen vrije filter), toon de actieve tenant duidelijk, log switches voor audit en voorkom links die tenantchecks kunnen omzeilen.
Een gecentraliseerde SLA-rapportage-webapp leeft of sterft aan zijn datamodel. Als je alleen “SLA % per maand” modelleert, wordt het moeilijk om resultaten uit te leggen, geschillen af te handelen of berekeningen later bij te werken. Als je alleen ruwe events modelleert, wordt rapporteren traag en duur. Het doel is beide te ondersteunen: traceerbaar bewijs en snelle, klantklare rollups.
Houd een heldere scheiding tussen wie gerapporteerd wordt, wat gemeten wordt en hoe het berekend wordt:
Ontwerp tabellen (of collecties) voor:
SLA-logica verandert: bedrijfstijden worden bijgewerkt, uitsluitingen worden verduidelijkt, afrondingsregels evolueren. Voeg een calculation_version (en bij voorkeur een referentie naar de ‘rule set’) toe aan elk berekend resultaat. Zo kun je oude rapporten exact reproduceren, zelfs nadat je verbeteringen hebt doorgevoerd.
Neem auditvelden op waar ze ertoe doen:
Klanten vragen vaak “laat zien waarom”. Plan een schema voor bewijsstukken:
Deze structuur houdt de app uitlegbaar, reproduceerbaar en snel — zonder het onderliggende bewijs te verliezen.
Als je inputs rommelig zijn, wordt je SLA-dashboard dat ook. Een betrouwbare pijplijn zet incident- en ticketdata uit meerdere tools om in consistente, auditeerbare SLA-resultaten — zonder dubbel tellen, gaten of stille fouten.
Behandel ingestie, normalisatie en rollups als aparte fasen. Laat ze draaien als achtergrondjobs zodat de UI snel blijft en je veilig kunt retryen.
Deze scheiding helpt ook wanneer de bron van één klant uitvalt: ingestie kan falen zonder bestaande berekeningen te corrumperen.
Externe API's timen uit. Webhooks kunnen dubbel binnenkomen. Je pijplijn moet idempotent zijn: het verwerken van dezelfde input meer dan eens mag de uitkomst niet veranderen.
Gebruikelijke benaderingen:
Over klanten en tools heen kunnen “P1”, “Critical” en “Urgent” hetzelfde betekenen — of juist niet. Bouw een normalisatielaag die standaardiseert:
Bewaar zowel de originele waarde als de genormaliseerde waarde voor traceerbaarheid.
Voeg validatieregels toe (missende timestamps, negatieve duur, onmogelijke statusovergangen). Gooi slechte data niet stilletjes weg — routeer het naar een quarantainequeue met reden en een “fix of map”-workflow.
Bereken voor elke klant en bron “last successful sync”, “oudste onverwerkte event” en “rollup up-to date through”. Toon dit als een eenvoudige data freshness-indicator zodat klanten de cijfers vertrouwen en je team vroegtijdig issues ziet.
Als klanten je portal gebruiken om SLA-prestaties te beoordelen, moeten authenticatie en permissies net zo zorgvuldig ontworpen worden als de SLA-wiskunde. Het doel is simpel: elke gebruiker ziet alleen wat hij zou moeten zien — en je kunt dat later bewijzen.
Begin met een kleine, duidelijke set rollen en breid alleen uit als daar sterke redenen voor zijn:
Hanteer least privilege als standaard: nieuwe accounts moeten standaard viewer zijn tenzij expliciet opgewaardeerd.
Voor interne teams vermindert SSO accountsprawl en offboarding-risico. Ondersteun OIDC (gebruikelijk met Google Workspace/Azure AD/Okta) en waar nodig SAML.
Voor klanten, bied SSO aan als upgradepad, maar laat e-mail/wachtwoord met MFA toe voor kleinere organisaties.
Handhaaf tenantgrenzen op elk laag:
Log toegang tot gevoelige pagina's en downloads: wie heeft wat geopend, wanneer en van waar. Dit helpt bij compliance en klantvertrouwen.
Bouw een onboardingflow waarin admins of client editors gebruikers kunnen uitnodigen, rollen kunnen toewijzen, e-mailverificatie vereisen en toegang onmiddellijk kunnen intrekken wanneer iemand vertrekt.
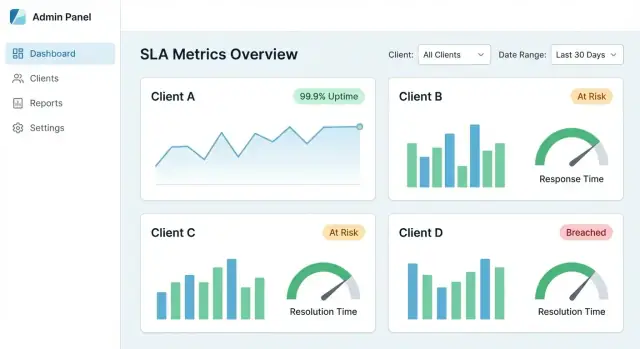
Een gecentraliseerd SLA-dashboard slaagt als een klant drie vragen in minder dan een minuut kan beantwoorden: Halen we de SLA's? Wat is er veranderd? Wat veroorzaakte de misses? Je UX moet ze van een hoog-over beeld naar bewijs leiden — zonder dat ze je interne datamodel hoeven te leren.
Begin met een kleine set tegels en charts die passen bij gangbare SLA-gesprekken:
Maak elke kaart klikbaar zodat het een deur naar details wordt, geen dood eind.
Filters moeten consistent zijn over alle pagina's en “blijven plakken” tijdens navigatie.
Aanbevolen defaults:
Toon actieve filterchips bovenaan zodat gebruikers altijd begrijpen wat ze bekijken.
Elke metric moet een pad naar “waarom” hebben. Een sterke drill-down flow:
Als een cijfer niet met bewijs kan worden uitgelegd, wordt het betwist — vooral tijdens QBRs.
Voeg tooltips of een “info”-paneel toe voor elke KPI: hoe het berekend wordt, uitsluitingen, tijdzone en data-freshness. Voeg voorbeelden toe zoals “Maintenance windows uitgesloten” of “Uptime gemeten bij de API-gateway.”
Maak gefilterde weergaven deelbaar via stabiele URL's (bijv. /reports/sla?client=acme&service=api&range=30d). Dit verandert je gecentraliseerde SLA-dashboard in een klantklaar rapportageportaal dat terugkerende check-ins en audit-trails ondersteunt.
Een gecentraliseerd SLA-dashboard is nuttig in het dagelijks werk, maar klanten willen vaak iets dat ze intern kunnen doorsturen: een PDF voor leidinggevenden, een CSV voor analisten en een link die ze kunnen bookmarken.
Ondersteun drie outputs uit dezelfde onderliggende SLA-resultaten:
Voor link-gebaseerde rapporten maak filters expliciet (datumbereik, service, severity) zodat de klant precies weet wat de cijfers representeren.
Voeg scheduling toe zodat elke klant rapporten automatisch kan ontvangen — wekelijks, maandelijks en per kwartaal — verzonden naar een klant-specifieke lijst of gedeelde inbox. Houd schema's tenant-gescopeerd en auditeerbaar (wie het heeft aangemaakt, laatst verzonden tijd, volgende run).
Als startpunt: lanceer met een “maandelijkse samenvatting” plus een één-klik download van /reports.
Bouw sjablonen die lezen als QBR/MBR-slides in geschreven vorm:
Reële SLA's bevatten uitzonderingen (onderhoudsvensters, storingen van derden). Laat gebruikers compliance-notities toevoegen en uitzonderingen markeren die goedkeuring vereisen, met een goedkeuringstrail.
Exports moeten tenant-isolatie en rolpermissies respecteren. Een gebruiker mag alleen exporteren wat hij mag zien — en de export moet exact overeenkomen met de portalweergave (geen extra kolommen die verborgen data lekken).
Alerts zijn waar een SLA-rapportage-webapp verandert van “interessant dashboard” naar een operationeel hulpmiddel. Het doel is niet meer berichten te sturen — het is de juiste mensen vroegtijdig te laten handelen, vast te leggen wat er gebeurde en klanten te informeren.
Begin met drie categorieën:
Koppel elke alert aan een duidelijke definitie (metric, tijdvenster, drempel, klantscope) zodat ontvangers erop kunnen vertrouwen.
Bied meerdere afleveropties zodat teams klanten kunnen bereiken waar ze al werken:
Voor multi-client rapportage routeer notificaties met tenantregels (bijv. “Client A breaches naar Channel A; interne breaches naar on-call”). Vermijd het sturen van klant-specifieke details naar gedeelde kanalen.
Alert-fatigue vernietigt adoptie. Implementeer:
Elke alert moet ondersteunen:
Dit creëert een lichte audittrail die je kunt hergebruiken in klantklare samenvattingen.
Voorzie een basisregelseditor voor per-klant drempels en routing (zonder complexe querylogica bloot te stellen). Guardrails helpen: defaults, validatie en preview (“deze regel zou 3 keer afgelopen maand hebben getriggerd”).
Een gecentraliseerde SLA-rapportage-webapp wordt snel mission-critical omdat klanten hem gebruiken om servicekwaliteit te beoordelen. Dat maakt snelheid, veiligheid en bewijs (voor audits) net zo belangrijk als de grafieken zelf.
Grote klanten kunnen miljoenen tickets, incidenten en monitoringevents genereren. Om pagina's responsief te houden:
Ruwe events zijn waardevol voor onderzoek, maar alles eeuwig bewaren verhoogt kosten en risico.
Stel duidelijke regels zoals:
Voor elk klantrapportageportaal, ga uit van gevoelige content: klantnamen, timestamps, ticketnotities en soms PII.
Zelfs als je niet voor een specifieke standaard gaat, bouwt goede operationele evidentie vertrouwen.
Onderhoud:
Het lanceren van een SLA-rapportage-webapp gaat minder om een big-bang release en meer om het aantonen van nauwkeurigheid en vervolgens herhaalbaar opschalen. Een sterk lanceringsplan vermindert geschillen door resultaten makkelijk te verifiëren en reproduceerbaar te maken.
Kies één klant met een beheersbare set services en databronnen. Laat de berekeningen van je app parallel draaien aan hun bestaande spreadsheets, ticketexports of vendorportaal-rapporten.
Focus op veelvoorkomende mismatch-gebieden:
Documenteer verschillen en beslis of de app de huidige aanpak van de klant moet matchen of moet vervangen door een duidelijker standaard.
Maak een herhaalbare onboardingchecklist zodat elke nieuwe klantervaring voorspelbaar is:
Een checklist helpt ook bij het inschatten van inspanning en ondersteunt gesprekken over /pricing.
SLA-dashboards zijn alleen geloofwaardig als ze vers en compleet zijn. Voeg monitoring toe voor:
Stuur eerst interne alerts; zodra stabiel kun je klantzichtbare statusnotities introduceren.
Verzamel feedback over waar verwarring ontstaat: definities, geschillen (“waarom is dit een breach?”) en “wat is er veranderd” sinds vorige maand. Prioriteer kleine UX-verbeteringen zoals tooltips, wijzigingslogs en duidelijke voetnoten over uitsluitingen.
Als je snel een interne MVP wilt afleveren (tenantmodel, integraties, dashboards, exports) zonder weken aan boilerplate te besteden, kan een vibe-coding-aanpak helpen. Bijvoorbeeld, Koder.ai laat teams een multi-tenant webapp schetsen en itereren via chat — en daarna de broncode exporteren en implementeren. Dat past praktisch bij SLA-rapportageproducten, waar de kerncomplexiteit domeinregels en datanormalisatie is in plaats van UI-scaffolding.
Je kunt Koder.ai’s planning mode gebruiken om entiteiten uit te lijnen (tenants, services, SLA-definities, events, rollups), en vervolgens een React-UI en een Go/PostgreSQL-backendbasis genereren die je kunt uitbreiden met specifieke integraties en berekeningslogica.
Houd een levend document met vervolgstappen: nieuwe integraties, exportformaten en audittrails. Verwijs naar gerelateerde gidsen op /blog zodat klanten en teammates zelf details kunnen vinden.
Gecentraliseerde SLA-rapportage moet één bron van waarheid creëren door uptime, incidenten en tickettijdlijnen samen te brengen in één doorzoekbaar en verifieerbaar overzicht.
In de praktijk moet het:
Begin klein met metrics die de meeste klanten herkennen, en breid alleen uit als je ze kunt uitleggen en auditen.
Veelvoorkomende startmetrics:
Voor elke metric: documenteer wat het meet, wat het uitsluit en welke datagegevens nodig zijn.
Schrijf regels eerst in gewone taal en zet ze daarna om in logica.
Je moet typisch definiëren:
Als twee mensen het niet eens kunnen worden over de tekstversie, zal de codeversie later ook betwist worden.
Sla alle timestamps op in UTC en converteer voor weergave met de door de tenant gewenste tijdzone.
Bepaal ook vooraf:
Wees expliciet in de UI (bijv. “Reporting period cutoffs are in America/New_York”).
Gebruik een mix van integratiemethoden, afhankelijk van actualiteit versus volledigheid:
Praktische regel: webhooks waar actualiteit telt, API-pulls waar volledigheid telt.
Definieer een klein canoniek setje genormaliseerde events zodat verschillende tools naar dezelfde concepten mappen.
Voorbeelden:
incident_opened / incident_closedKies een multi-tenancy-model en handhaaf isolatie verder dan alleen de UI.
Belangrijke beschermingen:
tenant_idVeronderstel dat exports en achtergrondjobs de plaatsen zijn waar data het makkelijkst kan lekken als je geen tenantcontext ontwerpt.
Bewaar zowel ruwe events als afgeleide resultaten zodat je snel kunt zijn én uitlegbaar.
Een praktische splitsing:
Voeg een toe zodat oude rapporten exact te reproduceren zijn na regelwijzigingen.
Maak de pijplijn in fasen en idempotent:
Voor betrouwbaarheid:
Neem drie categorieën alerts op zodat het systeem operationeel is en niet alleen een dashboard:
Verminder ruis met deduplicatie, stille uren en escalatie, en maak elke alert actiegericht met acknowledgment en resolutienotities.
downtime_started / downtime_endedticket_created / first_response / resolvedNeem consistente velden op zoals tenant_id, service_id, source_system, external_id, severity en UTC-timestamps.
calculation_version