Wat consistentie en beschikbaarheid in de praktijk betekenen
Wanneer een database over meerdere machines (replicas) is verdeeld, krijg je snelheid en veerkracht—maar je introduceert ook periodes waarin die machines het niet perfect eens zijn of niet betrouwbaar met elkaar kunnen praten.
Consistentie (platte betekenis)
Consistentie betekent: na een succesvolle write leest iedereen dezelfde waarde. Als je je profiel-e-mail bijwerkt, geeft de volgende read—ongeacht welke replica antwoordt—de nieuwe e-mail terug.
In de praktijk kunnen systemen die prioriteit geven aan consistentie sommige verzoeken uitstellen of weigeren tijdens storingen om te voorkomen dat tegenstrijdige antwoorden worden teruggegeven.
Beschikbaarheid (platte betekenis)
Beschikbaarheid betekent: het systeem antwoordt op elk verzoek, zelfs als sommige servers down of gedesynchroniseerd zijn. Je krijgt misschien niet de meest recente data, maar je krijgt een antwoord.
In de praktijk accepteren systemen die beschikbaarheid prioriteren soms writes en bedienen ze reads zelfs als replicas het oneens zijn, en reconciliëren ze verschillen later.
Wat de afweging betekent voor echte applicaties
Een afweging betekent dat je niet in elke foutsituatie beide doelen maximaal kunt nastreven. Als replicas niet kunnen coördineren, moet de database ofwel:
- Wachten/falen op sommige verzoeken om een enkele, overeengekomen waarheid te beschermen (consistentie), of
- Blijven reageren naar gebruikers, ook als dat risico geeft op verouderde of conflicterende data (beschikbaarheid)
Een eenvoudig voorbeeld: winkelwagen versus bankoverschrijving
- Winkelwagen: Als het aantal in je winkelwagen even op een ander apparaat één verkeerd is, is dat vervelend maar meestal acceptabel. Veel teams kiezen hier voor hogere beschikbaarheid en reconciliëren later.
- Bankoverschrijving: Als je $500 verplaatst en je saldo tijdelijk twee verschillende waarden toont, is dat een serieus probleem. Hier is sterkere consistentie vaak de moeite waard, ondanks af en toe een “probeer het later nog eens”-fout.
Geen enkele beste keuze
De juiste balans hangt af van welke fouten je kunt verdragen: een korte storing, of een korte periode van verkeerde/verouderde data. De meeste echte systemen kiezen een middenweg—en maken de afweging expliciet.
Waarom distributie de regels verandert
Een database is “gedistribueerd” wanneer hij data op meerdere machines (nodes) opslaat en serveert die via een netwerk coördineren. Voor een applicatie kan het nog steeds als één database aanvoelen—maar onder de motorkap kunnen verzoeken door verschillende nodes op verschillende plekken worden afgehandeld.
Replicatie: waarom teams knooppunten toevoegen
De meeste gedistribueerde databases repliceren data: hetzelfde record staat op meerdere nodes. Teams doen dit om:
- de dienst draaiende te houden als een machine uitvalt
- latentie te verlagen door gebruikers vanuit een dichtbijzijnde node te bedienen
- reads (en soms writes) op meerdere machines te schalen
Replicatie is krachtig, maar het stelt meteen de vraag: als twee nodes elk een kopie van dezelfde data hebben, hoe garandeer je dan dat ze altijd overeenkomen?
Gedeeltelijk falen is normaal, niet uitzonderlijk
Op één server is “down” meestal duidelijk: de machine draait of niet. In een gedistribueerd systeem is falen vaak gedeeltelijk. Eén node kan leven maar traag zijn. Een netwerkverbinding kan pakketten verliezen. Een heel rack kan zijn connectiviteit verliezen terwijl de rest van de cluster blijft draaien.
Dit is belangrijk omdat nodes niet direct kunnen weten of een andere node echt down is, tijdelijk onbereikbaar is of gewoon vertraging heeft. Terwijl ze wachten om dat uit te zoeken, moeten ze beslissen wat te doen met binnenkomende reads en writes.
Guarantees veranderen wanneer communicatie niet gegarandeerd is
Met één server is er één bron van waarheid: elke read ziet de laatste succesvolle write.
Met meerdere nodes hangt “laatste” af van coördinatie. Als een write slaagt op node A maar node B niet bereikbaar is, zou de database moeten:
- de write blokkeren totdat B het bevestigt (consistentie beschermen), of
- de write toch accepteren (beschikbaarheid beschermen)?
Die spanning—gemaakt door onvolmaakte netwerken—is waarom distributie de regels verandert.
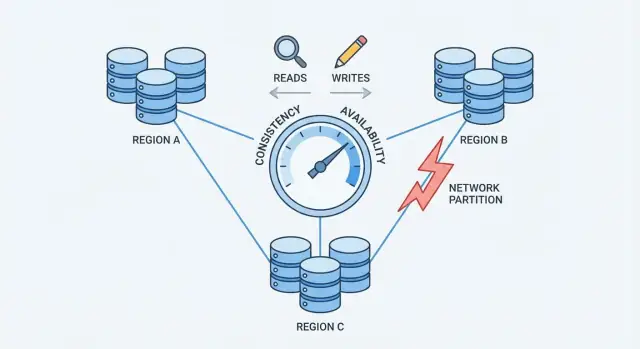
Netwerkpartities: het kernprobleem
Een netwerkpartitie is een breuk in communicatie tussen nodes die als één database zouden moeten werken. De nodes kunnen nog steeds draaien en gezond lijken, maar ze kunnen niet betrouwbaar berichten uitwisselen—door een defecte switch, een overbelaste link, een foutieve routering, een verkeerd ingestelde firewallregel, of zelfs een lawaaierige buur in een cloudnetwerk.
Waarom partities op schaal onvermijdelijk zijn
Zodra een systeem verspreid is over meerdere machines (vaak over racks, zones of regio’s), beheers je niet meer elke hop ertussen. Netwerken verliezen pakketten, introduceren vertragingen en splijten soms in “eilanden”. Op kleine schaal zijn zulke gebeurtenissen zeldzaam; op grote schaal zijn ze routine. Zelfs een korte verstoring is genoeg om te gelden, omdat databases constante coördinatie nodig hebben om te weten wat er gebeurd is.
Hoe partities conflicterende “laatste” data creëren
Tijdens een partitie blijven beide zijden verzoeken ontvangen. Als gebruikers aan beide zijden kunnen schrijven, accepteert elke kant mogelijk updates die de andere kant niet ziet.
Voorbeeld: Node A werkt iemands adres bij naar “Nieuwe Straat”. Tegelijkertijd werkt Node B het bij naar “Oude Straat Apt 2”. Elke kant denkt dat zijn write de meest recente is—omdat er geen manier is om in realtime aantekeningen te vergelijken.
Door de gebruiker zichtbare symptomen
Partities verschijnen niet als nette foutmeldingen; ze verschijnen als verwarrend gedrag:
- Timeouts: de database wacht op een bevestiging van een andere node voor een write of read.
- Verouderde reads: je ververst en ziet nog steeds oude data omdat je terechtkomt bij een replica die updates gemist heeft.
- Split-brain gedrag: verschillende gebruikers zien verschillende “waarheden”, afhankelijk van welke kant ze bereiken.
Dit is het drukpunt dat een keuze afdwingt: wanneer het netwerk communicatie niet kan garanderen, moet een gedistribueerde database kiezen of hij consistentie of beschikbaarheid prioriteert.
CAP-theorema zonder jargon
CAP is een compacte manier om te beschrijven wat er gebeurt wanneer een database over meerdere machines is verspreid.
De drie termen (in gewone taal)
- Consistentie (C): nadat je een waarde schrijft, geeft elke latere read diezelfde waarde terug.
- Beschikbaarheid (A): elk verzoek krijgt een niet-foutief antwoord, zelfs als sommige servers problemen hebben.
- Partitietolerantie (P): het systeem blijft functioneren, ook als het netwerk splitst en servers niet betrouwbaar met elkaar kunnen praten.
De kernboodschap
Wanneer er geen partitie is, kunnen veel systemen zowel consistent als beschikbaar lijken.
Wanneer er wel een partitie is, moet je kiezen wat je prioriteert:
- Kies consistentie: weiger of stel sommige requests uit totdat servers het eens zijn.
- Kies beschikbaarheid: accepteer requests aan elke kant van de splitsing, ook als antwoorden tijdelijk kunnen verschillen.
Een eenvoudig tijdlijnvoorbeeld
- 10:00 Client schrijft
balance = 100 naar Server A.
- 10:01 Netwerkpartitie: Server A kan Server B niet bereiken.
- 10:02 Client leest vanaf Server B.
- Als je consistentie prioriteert, moet Server B weigeren of wachten.
- Als je beschikbaarheid prioriteert, antwoordt Server B, maar het kan nog steeds
balance = 80 tonen.
Veelvoorkomend misverstand
CAP betekent niet dat je permanent “twee van de drie” moet kiezen. Het betekent dat tijdens een partitie je niet zowel Consistentie als Beschikbaarheid kunt garanderen. Buiten partities kun je vaak dicht bij beide komen—totdat het netwerk faalt.
Consistentie kiezen: wat je wint en wat je verliest
Kiezen voor consistentie betekent dat de database “iedereen ziet dezelfde waarheid” boven “altijd antwoorden” stelt. In de praktijk wijst dit vaak op sterke consistentie, vaak beschreven als lineariseerbaar gedrag: zodra een write bevestigd is, geeft elke latere read (van waar dan ook) die waarde terug, alsof er één actuele kopie bestaat.
Wat er gebeurt tijdens een partitie
Wanneer het netwerk splitst en replicas niet betrouwbaar met elkaar kunnen praten, kan een sterk consistent systeem niet veilig onafhankelijke updates aan beide zijden accepteren. Om correctheid te beschermen doet het meestal:
- Requests blokkeren terwijl er op coördinatie gewacht wordt, of
- Requests weigeren (errors/timeouts) als het niet de vereiste replicas of leider kan bereiken.
Voor de gebruiker kan dit als een outage aanvoelen, ook al draaien sommige machines nog.
Wat je wint
Het grootste voordeel is eenvoudiger redenatie. Applicatiecode kan zich gedragen alsof hij met één database praat, niet met meerdere replicas die het oneens kunnen zijn. Dit vermindert “vreemde momenten” zoals:
- Direct na een succesvolle update oudere data lezen
- Twee verschillende waarden zien voor hetzelfde record afhankelijk van welke replica je raakt
- Verlies van invarianten (bijv. overselling van voorraad) door concurrerende, conflicterende writes
Je krijgt ook schonere mentale modellen voor auditing, facturatie en alles wat de eerste keer correct moet zijn.
Wat je verliest
Consistentie heeft echte kosten:
- Hogere latentie: veel operaties moeten wachten op coördinatie (vaak over machines of regio’s).
- Meer fouten tijdens storingen: partities, trage replicas of leiderproblemen kunnen leiden tot timeouts of “probeer later opnieuw”.
Als je product geen mislukte requests tijdens gedeeltelijke uitval kan verdragen, kan sterke consistentie duur aanvoelen—ook als het de juiste keuze is voor correctheid.
Beschikbaarheid kiezen: wat je wint en wat je verliest
Bouw en deel voor credits
Deel wat je bouwt met Koder.ai en verdien credits terwijl je anderen opleidt.
Kiezen voor beschikbaarheid betekent dat je optimaliseert voor een eenvoudige belofte: het systeem reageert, zelfs als delen van de infrastructuur ongezond zijn. In de praktijk is “hoge beschikbaarheid” geen garantie voor “nooit fouten”—maar de meeste requests krijgen nog steeds een antwoord tijdens knooppuntuitval, overbelaste replicas of verbroken netwerkverbindingen.
Wat er gebeurt tijdens een netwerkpartitie
Wanneer het netwerk splitst, kunnen replicas niet betrouwbaar met elkaar praten. Een beschikbaarheidsgericht systeem blijft doorgaans verkeer bedienen vanaf de bereikbare kant:
- Reads worden lokaal beantwoord met de data die de replica momenteel heeft.
- Writes worden lokaal geaccepteerd en later in de wachtrij gezet/gerepliceerd wanneer de connectiviteit terugkomt.
Dit houdt applicaties draaiende, maar betekent ook dat verschillende replicas tijdelijk verschillende waarheden kunnen accepteren.
Wat je wint
Je krijgt betere uptime: gebruikers kunnen nog browsen, items in een winkelwagen plaatsen, reacties posten of events vastleggen, zelfs als een regio geïsoleerd is.
Je krijgt ook een soepelere gebruikerservaring onder stress. In plaats van timeouts kan je app blijven werken met een redelijke boodschap (“je update is opgeslagen”) en later synchroniseren. Voor veel consumententoepassingen en analytics-werkbelastingen is die afweging het waard.
Wat je verliest
De prijs is dat de database mogelijk verouderde reads retourneert. Een gebruiker kan een profiel bijwerken op één replica en direct daarna vanaf een andere replica lezen en de oude waarde zien.
Je loopt ook het risico op write-conflicten. Twee gebruikers (of dezelfde gebruiker op twee locaties) kunnen hetzelfde record bijwerken op verschillende zijden van een partitie. Wanneer de partitie geneest, moet het systeem verschillende geschiedenissen reconciliëren. Afhankelijk van de regels kan één write “winnen”, kunnen velden samengevoegd worden, of kan de applicatie in actie moeten komen.
Beschikbaarheid-first ontwerp accepteert tijdelijke onenigheid zodat het product blijft reageren—en investeert vervolgens in detectie en herstel van die onenigheid.
Quorums en stemmen: een middenweg
Quorums zijn een praktische “stemmings”-techniek die veel gerepliceerde databases gebruiken om consistentie en beschikbaarheid in balans te brengen. In plaats van één replica te vertrouwen vraagt het systeem genoeg replicas om akkoord te gaan.
Het (N, R, W)-idee
Je ziet quorums vaak beschreven met drie getallen:
- N: hoeveel replicas er zijn voor een stukje data
- W: hoeveel replicas een write moeten bevestigen voordat die als succesvol geldt
- R: hoeveel replicas geraadpleegd worden voor een read
Een veelgebruikte vuistregel is: als R + W > N, dan overlapt elke read een recente succesvolle write op minstens één replica, wat de kans op verouderde reads verkleint.
Intuïtieve voorbeelden
Als je N=3 replicas hebt:
- Single-replica benadering (R=1, W=1): Snel en zeer beschikbaar, maar je kunt gemakkelijk een verouderde replica lezen.
- Meerderheidsstemming (R=2, W=2): Een write moet 2 replicas bereiken, en een read raadpleegt 2 replicas. Dit vergroot de kans dat je de nieuwste waarde ziet omdat de read- en write-sets overlappen.
Sommige systemen gaan verder met W=3 (alle replicas) voor sterkere consistentie, maar dat kan meer write-fouten veroorzaken wanneer een replica traag of down is.
Wat quorums doen tijdens partities
Quorums elimineren partitieproblemen niet—ze definiëren wie vooruit mag gaan. Als het netwerk 2–1 splitst, kan de zijde met 2 replicas nog steeds voldoen aan R=2 en W=2, terwijl de geïsoleerde enkele replica dat niet kan. Dat vermindert conflicterende updates, maar betekent dat sommige clients fouten of timeouts zullen zien.
De afwegingen
Quorums betekenen meestal hogere latentie (meer nodes contacteren), hogere kosten (meer cross-node verkeer) en genuanceerder faalgedrag (timeouts kunnen op onbeschikbaarheid lijken). Het voordeel is een afstelbare middenweg: je kunt R en W bijstellen richting recentere reads of hogere writesucces afhankelijk van wat het belangrijkst is.
Eventual consistency en veelvoorkomende anomalieën
Eventual consistency betekent dat replicas tijdelijk uit sync mogen zijn, zolang ze later naar dezelfde waarde convergeren.
Een concreet analogie
Denk aan een keten van koffiezaken die een gedeeld “uitverkocht”-bordje bijwerken voor een gebakje. Eén winkel markeert het als uitverkocht, maar de update bereikt andere winkels een paar minuten later. In die tussentijd kan een andere winkel nog “beschikbaar” tonen en het laatste exemplaar verkopen. Niemand’s systeem is “kapot”—de updates lopen gewoon achter.
Veelvoorkomende anomalieën die je zult opmerken
Wanneer data nog aan het propagëren is, kunnen clients gedrag zien dat verrassend aanvoelt:
- Verouderde reads: je leest oude data van een replica die de laatste write nog niet heeft ontvangen.
- Read-your-writes gaps: je schrijft een update en leest direct daarna vanaf een andere replica (of na een failover) en ziet je eigen wijziging niet.
- Volgordeproblemen bij updates: twee updates komen in verschillende volgordes aan op verschillende replicas, wat tijdelijk inconsistente weergaven veroorzaakt.
Technieken die helpen replicas te laten convergeren
Eventual-consistency systemen voegen meestal achtergrondmechanismen toe om de onenigheidsvensters te verkleinen:
- Read repair: als een read mismatches tussen replicas detecteert, werkt het systeem verouderde replicas in de achtergrond bij.
- Hinted handoff: als een replica down is, bewaart een andere node tijdelijk “hints” van writes om door te geven wanneer de eerste terugkomt.
- Anti-entropy (sync): periodieke reconciliatie (vaak via merkle-bomen of checksums) om drift te vinden en te herstellen.
Wanneer eventual consistency goed werkt
Het past goed wanneer beschikbaarheid belangrijker is dan perfect actueel zijn: activity feeds, view-counters, aanbevelingen, cached profielen, logs/telemetrie en andere niet-kritieke data waar “binnen een moment correct” acceptabel is.
Conflictoplossing: hoe uiteenlopende writes worden verzoend
Plan je architectuur in chat
Breng je datamodel, endpoints en consistentieregels in kaart voordat je gaat implementeren.
Wanneer een database writes op meerdere replicas accepteert, kan dat leiden tot conflicten: twee (of meer) updates naar hetzelfde item die onafhankelijk zijn gebeurd op verschillende replicas voordat die replicas konden synchroniseren.
Een klassiek voorbeeld is een gebruiker die het verzendadres bijwerkt op het ene apparaat terwijl hij het telefoonnummer op een ander verandert. Als elke update tijdens een tijdelijke disconnect op een andere replica binnenkomt, moet het systeem bepalen wat het “juiste” record is zodra replicas weer gegevens uitwisselen.
Last-write-wins (LWW): simpel, maar riskant
Veel systemen beginnen met last-write-wins: welke update ook de nieuwste timestamp heeft, overschrijft de anderen.
Het is aantrekkelijk omdat het eenvoudig te implementeren en snel te berekenen is. Het nadeel is dat het stilletjes data kan verliezen. Als “nieuwste” wint, wordt een oudere maar belangrijke wijziging overschreven—zelfs als de twee updates verschillende velden raakten.
Het gaat er ook van uit dat timestamps betrouwbaar zijn. Klokscheefstand tussen machines (of clients) kan ervoor zorgen dat de “verkeerde” update wint.
Geschiedenis bijhouden: versievectoren en aanverwante ideeën
Veiliger conflictbeheer vereist meestal het bijhouden van causale geschiedenis.
Conceptueel hangen versievectoren (en eenvoudigere varianten) een klein stukje metadata aan elk record dat samenvat “welke replica welke updates heeft gezien”. Wanneer replicas versies uitwisselen, kan de database detecteren of de ene versie de andere omvat (geen conflict) of dat ze gedivergeerd zijn (conflict dat opgelost moet worden).
Sommige systemen gebruiken logische timestamps (bijv. Lamport-klokken) of hybride logische klokken om minder afhankelijk te zijn van wall-clock tijd en toch een ordeningshint te geven.
Samenvoegen in plaats van overschrijven
Zodra een conflict is gedetecteerd, heb je keuzes:
- App-level merges: je applicatie beslist hoe velden gecombineerd worden, gebruikers worden gevraagd te kiezen, of beide versies worden bewaard ter review.
- CRDTs (Conflict-Free Replicated Data Types): datastructuren die ontworpen zijn om automatisch en deterministisch samen te voegen (nuttig voor tellers, sets, collaboratieve tekst, enz.). Ze vermijden vaak “winner-takes-all”-gedrag terwijl ze toch hoog beschikbaar blijven.
De beste aanpak hangt af van wat “correct” betekent voor jouw data—soms is het accepteren van het verlies van een write oké, soms is het een bedrijfskritische fout.
Hoe te kiezen voor jouw use case
Het kiezen van een consistentie/beschikbaarheidshouding is geen filosofisch debat—het is een productbeslissing. Begin met de vraag: wat kost het om even ongelijk te hebben, en wat kost het om gebruikers te vragen “probeer later opnieuw”?
Breng bedrijfsrisico in kaart naar consistentiebehoefte
Sommige domeinen hebben een enkele, gezaghebbende uitkomst bij write-tijd nodig omdat “bijna correct” nog steeds verkeerd is:
- Geld en facturatie: dubbele afschrijvingen, debetstanden en terugbetalingen vragen meestal sterke consistentie.
- Identiteit en permissies: inloggen, wachtwoordherstel, toegangscontrole en rolwijzigingen moeten split-brain-gedrag vermijden.
- Voorraad en capaciteit: als overselling onacceptabel is (tickets, beperkte voorraad), neig naar consistentie—of ontwerp expliciete reserveringen.
Als de impact van een tijdelijke mismatch klein of omkeerbaar is, kun je meestal meer op beschikbaarheid leunen.
Bepaal hoeveel verouderde data je kunt tolereren
Veel UX-ervaringen kunnen werken met licht verouderde reads:
- Feeds en tijdlijnen: een post die een paar seconden later verschijnt is meestal acceptabel.
- Analytics en dashboards: batch- of vertraagde cijfers zijn gebruikelijk en verwacht.
- Caches en zoekindexen: gebruikers accepteren “nog niet bijgewerkt” als het snel en stabiel is.
Wees expliciet over hoe oud acceptabel is: seconden, minuten of uren. Dat tijdsbudget stuurt je replicatie- en quorumkeuzes.
Kies de faaltoestand die gebruikers het minst haten
Wanneer replicas het niet eens kunnen worden, eindig je meestal met één van drie UX-uitkomsten:
- Spinner / wachten (correctheid prioriteren, kan traag aanvoelen)
- Fout / retry (eerlijk, maar disruptief)
- Verouderd resultaat (vloeiend, maar af en toe verrassend)
Kies per feature wat het minst schadelijke resultaat is, niet globaal.
Snelle checklist
Leun C (consistentie) als: verkeerde resultaten financiële/juridische risico’s, beveiligingsproblemen of onomkeerbare acties veroorzaken.
Leun A (beschikbaarheid) als: gebruikers responsiviteit waarderen, verouderde data toelaatbaar is en conflicten later veilig op te lossen zijn.
Als je twijfelt, split het systeem: hou kritieke records sterk consistent en laat afgeleide weergaven (feeds, caches, analytics) optimaliseren voor beschikbaarheid.
Ontwerppatronen om de pijn van de afweging te verminderen
Valideer lange workflows
Prototypeer een saga-workflow met compenserende acties om gedeeltelijke fouten netjes af te handelen.
Je hoeft zelden een enkele “consistentie-instelling” voor een heel systeem te kiezen. Veel moderne gedistribueerde databases laten je consistentie per operatie kiezen—en slimme applicaties gebruiken dat om de gebruikerservaring soepel te houden zonder te doen alsof de afweging niet bestaat.
Gebruik per-operatie consistentieniveaus
Behandel consistentie als een draaiknop die je opendraait afhankelijk van wat de gebruiker doet:
- Kritieke updates (betalingen, voorraaddecrements, wachtwoordwijzigingen): gebruik sterkere consistentie (bv. quorum/linearizable writes).
- Niet-kritische reads (feeds, dashboards, “laatst gezien”): sta zwakkere reads toe (lokaal/één replica/eventual) voor snelheid en veerkracht.
Zo betaal je niet de prijs van de sterkste consistentie voor alles, maar bescherm je wel de operaties die het echt nodig hebben.
Mix sterk en zwak in één flow
Een veelvoorkomend patroon is sterk voor writes, zwakker voor reads:
- Schrijf met een streng niveau zodat het systeem een gezaghebbend record heeft.
- Lees met een lossere instelling, en als je iets “raars” detecteert (missend item, verouderde teller), refresh dan met een sterkere read of toon een “nog aan het bijwerken”-hint.
In sommige gevallen werkt het omgekeerd: snelle writes (gequeue/eventual) plus sterke reads wanneer je een resultaat bevestigt (“Is mijn bestelling geplaatst?”).
Ontwerp voor retries: idempotentie
Wanneer netwerken wiebelen, doen clients retries. Maak retries veilig met idempotency keys zodat “bestelling indienen” twee keer uitvoeren niet twee bestellingen creëert. Bewaar en hergebruik het eerste resultaat wanneer dezelfde sleutel opnieuw verschijnt.
Lange workflows: sagas en compensatie
Voor multi-step acties over services, gebruik een saga: elke stap heeft een bijbehorende compenserende actie (terugbetaling, vrijgave van reservering, annulering van verzending). Dit houdt het systeem herstelbaar, zelfs als delen tijdelijk verschillen of falen.
Testen en observeerbaarheid voor consistentie vs beschikbaarheid
Je kunt de afweging niet beheren als je hem niet kunt zien. Productieproblemen lijken vaak op “willekeurige fouten” totdat je de juiste metingen en tests toevoegt.
Wat te meten (en waarom)
Begin met een kleine set metrics die direct op gebruikersimpact map:
- Latentie (p50/p95/p99): let op pieken tijdens failovers, leiderwissels of quorum-retries.
- Foutrate: onderscheid “harde” fouten (timeouts, 5xx) van “zachte” fouten (bediend vanuit een fallback, gedeeltelijke resultaten).
- Verouderde read-rate: percentage reads dat data teruggeeft ouder dan je target (bijv. ouder dan 2 seconden).
- Conflict-rate: hoe vaak gelijktijdige writes reconciliatie vereisen (inclusief LWW-overschrijvingen).
Als het kan, tag metrics naar consistentiemodus (quorum vs lokaal) en regio/zone om te zien waar gedrag afwijkt.
Test partities opzettelijk
Wacht niet op de echte storing. Voer in staging chaos-experimenten uit die simuleren:
- verloren pakketten en hoge latentie tussen replicas
- één regio die onbereikbaar wordt
- gedeeltelijke partities waar alleen sommige nodes kunnen praten
Verifieer niet alleen “het systeem blijft draaien”, maar welke garanties blijven gelden: blijven reads vers, blokkeren writes, krijgen clients duidelijke fouten?
Alerting die de afweging vroeg vangt
Voeg alerts toe voor:
- replicatievertraging die je toegestane verouderingswindow overschrijdt
- quorum-fouten (niet genoeg replicas bereikbaar) en stijgende retry-aantallen
- toenemende write-conflicten of achterstanden in reconciliatie
Maak tenslotte de garanties expliciet: documenteer wat je systeem belooft tijdens normale operatie en tijdens partities, en leer product- en supportteams wat gebruikers kunnen zien en hoe te reageren.
Prototypen van CAP-keuzes sneller (zonder alles opnieuw te bouwen)
Als je deze afwegingen in een nieuw product onderzoekt, helpt het om aannames vroeg te valideren—vooral rond faalmodi, retry-gedrag en hoe “verouderd” eruitziet in de UI.
Een praktische aanpak is een klein prototype van de workflow (write-pad, read-pad, retry/idempotentie en een reconciliatiejob) bouwen voordat je je commit aan een volledige architectuur. Met Koder.ai kunnen teams webapps en backends opzetten via een chatgestuurde workflow, snel itereren op datamodellen en API’s, en verschillende consistentiepatronen testen (bijv. strikte writes + ontspannen reads) zonder de overhead van een traditioneel buildproces. Als het prototype het gewenste gedrag laat zien, kun je de broncode exporteren en naar productie evolueren.