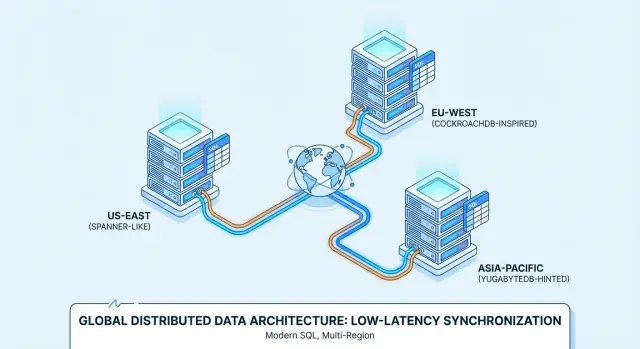
Wat “Distributed SQL” betekent (zonder de hype)
“Distributed SQL” is een database die aanvoelt als een traditionele relationele database—tabellen, rijen, joins, transacties en SQL—maar die is ontworpen om als een cluster over veel machines (en vaak over meerdere regio's) te draaien terwijl hij zich gedraagt als één logisch database.
Die combinatie is belangrijk omdat het drie dingen tegelijk probeert te leveren:
- SQL en relationeel modelleren: vertrouwde schema's, constraints en querytools.
- Horizontale schaal: knooppunten toevoegen om capaciteit te vergroten, in plaats van een "grotere server kopen."
- Sterke consistentie: reads en writes volgen duidelijke transactionele regels, zelfs wanneer data verspreid is.
Tussen klassieke RDBMS en NoSQL
Een klassieke RDBMS (zoals PostgreSQL of MySQL) is meestal het gemakkelijkst te beheren wanneer alles op één primaire node leeft. Je kunt reads schalen met replica's, maar writes schalen en regionale uitval overleven vereist vaak extra architectuur (sharding, handmatige failover en zorgvuldige applicatielogica).
Veel NoSQL-systemen kozen de tegenovergestelde benadering: eerst schaal en hoge beschikbaarheid, soms door consistency-garanties te versoepelen of eenvoudigere querymodellen te bieden.
Distributed SQL zoekt een middenweg: behoud het relationele model en ACID-transacties, maar distribueer data automatisch om groei en fouten af te handelen.
Wat het probeert op te lossen
Distributed SQL-databases zijn gebouwd voor problemen zoals:
- Globale applicaties met gebruikers in meerdere regio's, waar zowel latentie als uptime ertoe doen.
- Hoge beschikbaarheid zonder complexe, handmatige failoverprocedures.
- Groeiverlening over tijd, waarbij je capaciteit incrementeel wilt uitbreiden en één enkel database-interface wilt behouden.
Daarom worden producten zoals Google Spanner, CockroachDB en YugabyteDB vaak beoordeeld voor multi-region implementaties en always-on services.
Stel verwachtingen (het is niet de standaard)
Distributed SQL is niet automatisch "beter." Je accepteert meer bewegende delen en andere performance-realiteiten (netwerk hops, consensus, cross-region latentie) in ruil voor veerkracht en schaal.
Als je workload op een enkele goed beheerde database met een eenvoudige replicatie-opzet past, kan een conventionele RDBMS eenvoudiger en goedkoper zijn. Distributed SQL verdient zijn plaats wanneer het alternatief custom sharding, complexe failover of zakelijke eisen die multi-region consistentie en uptime vereisen, is.
Hoe Distributed SQL onder de motorkap werkt
Distributed SQL probeert aan te voelen als een vertrouwde SQL-database terwijl het data over meerdere machines (en vaak meerdere regio's) verspreidt. Het lastige deel is het coördineren van veel computers zodat ze zich gedragen als één betrouwbaar systeem.
Replicatie + consensus: hoe nodes het eens worden
Elk stukje data wordt typisch naar meerdere nodes gekopieerd (replicatie). Als één node faalt, kan een andere kopie nog steeds reads bedienen en writes accepteren.
Om te voorkomen dat replica's uit elkaar drijven, gebruiken Distributed SQL-systemen consensus-protocollen—meestal Raft (CockroachDB, YugabyteDB) of Paxos (Spanner). Op hoofdlijnen betekent consensus:
- Eén replica fungeert als “leider” voor een groep replica's.
- Writes gaan naar die leider.
- De leider bevestigt de write pas nadat een meerderheid van replica's het heeft erkend.
Die “meerderheidsstemming” geeft je sterke consistentie: zodra een transactie commit, zullen andere clients geen oudere versie van de data zien.
Sharding/partitioning: waar data leeft
Geen enkele machine kan alles bevatten, dus tabellen worden opgesplitst in kleinere stukken die shards/partities heten (Spanner noemt ze splits; CockroachDB noemt ze ranges; YugabyteDB noemt ze tablets).
Elke partitie wordt gerepliceerd (via consensus) en op specifieke nodes geplaatst. Plaatsing is niet willekeurig: je kunt het beïnvloeden met policies (bijvoorbeeld: houd EU-klantgegevens in EU-regio's, of plaats hot-partities op snellere nodes). Goede plaatsing vermindert cross-network trips en houdt performance voorspelbaarder.
Transacties over nodes heen (en waarom dat latentie toevoegt)
Bij een single-node database kan een transactie vaak committen met lokale schijfacties. In Distributed SQL kan een transactie meerdere partities raken—mogelijk op verschillende nodes.
Veilig committen vereist meestal extra coördinatie:
- Locking of validatie van data op de betrokken partities
- Repliceren van writes via consensus (meerderheidsacknowledgements)
- Een commit-beslissing finaliseren zodat alle deelnemers het eens zijn
Die stappen introduceren netwerk roundtrips, daarom voegen gedistribueerde transacties meestal latentie toe—vooral als data regio's overspant.
Multi-region gedrag: locality-aware reads en writes
Wanneer deployments regio's overspannen, proberen systemen operaties “dichtbij” gebruikers te houden:
- Locality-aware reads kunnen vanaf dichtbij gelegen replica's serveren wanneer dat veilig is.
- Locality-aware writes kunnen naar leiders in een gekozen regio routeren, of leiders plaatsen nabij de primaire schrijvers.
Dit is de kern van de multi-region balans: je kunt optimaliseren voor lokale reactietijd, maar sterke consistentie over grote afstanden betaalt nog steeds een netwerkprijs.
Wanneer je het echt nodig hebt (en wanneer niet)
Voordat je voor distributed SQL kiest, check je basiseisen. Als je één primaire regio hebt, voorspelbare load en een klein ops-team, is een conventionele relationele database (of een managed Postgres/MySQL) meestal de eenvoudigste manier om snel features uit te rollen. Je kunt vaak een single-region setup ver rekken met read replica's, caching en zorgvuldig schema/indexwerk.
Duidelijke triggers: wanneer distributed SQL zijn kosten waard is
Distributed SQL is het overwegen waard wanneer één (of meer) van deze waar is:
- Je hebt echte gebruikers in meerdere regio's en je wilt de database dichtbij hen zonder complexe app-level sharding te bouwen.
- Uptime-eisen zijn hoog (bijv. je moet zone-/regio-fouten overleven) en één primaire regio is een onaanvaardbaar risico.
- Datavolume of write-throughput groeit voorbij verticale schaalbaarheid, en je wilt horizontaal schalen terwijl je SQL-semantiek behoudt.
- Je hebt sterke consistentie nodig over nodes/regio's voor kerntransacties (bestellingen, saldi, reserveringen) zonder meerdere systemen aan elkaar te hoeven plakken.
- Compliance dwingt geografische plaatsing (dataresidency) terwijl je toch één logisch database wilt.
Anti-triggers: wanneer het meestal niet de juiste keuze is
Gedistribueerde systemen voegen complexiteit en kosten toe. Wees voorzichtig als:
- Je team klein is en geen tijd heeft om nieuwe faalpatronen en operationele gewoonten te leren.
- Verkeer laag of sporadisch is en je waarschijnlijk niet snel uit een single-region database groeit.
- Je zeer strakke latentie-eisen hebt voor single-key writes en je de coördinatie-overhead van sterke consistentie niet kunt verdragen.
- Je workload analytics-zwaar is (grote scans, complexe rapporten). Het kan beter zijn OLTP en analytics te scheiden.
Snelle beslischecklist
Als je op twee of meer vragen “ja” kunt antwoorden, is distributed SQL waarschijnlijk het overwegen waard:
- Heb je multi-region gebruikers met consistente data nodig?
- Heb je automatische failover nodig over zones/regio's?
- Wordt schalen een terugkerende crisis?
- Zou sharding meer engineeringoverhead zijn dan de database zelf?
- Moet je dataresidency afdwingen met één operationeel model?
Consistentie, Beschikbaarheid en Latentie: de kernafwegingen
Distributed SQL klinkt als “alles tegelijk krijgen”, maar echte systemen dwingen keuzes af—vooral wanneer regio's elkaar niet betrouwbaar kunnen bereiken.
CAP, uitgelegd voor productbeslissingen
Zie een netwerkpartition als "de verbinding tussen regio's is wankel of weg." In dat moment kan een database prioriteit geven aan:
- Consistentie: iedereen ziet hetzelfde, up-to-date antwoord (of de operatie faalt).
- Beschikbaarheid: de app blijft reads/writes accepteren in elke regio (ook als antwoorden tijdelijk uiteenlopen).
Distributed SQL-systemen zijn meestal gebouwd om consistentie te prefereren voor transacties. Dat is vaak wat teams willen—totdat een partition betekent dat bepaalde operaties moeten wachten of falen.
Sterke consistentie (en waarom geld en voorraad ertoe doen)
Sterke consistentie betekent dat zodra een transactie commit, elke volgende read die gecommitte waarde teruggeeft—geen “het werkte in één regio maar niet in een andere.” Dit is cruciaal voor:
- Betalingen en saldi (voorkomt double-spend of onjuiste totalen)
- Voorraad / reserveringen (voorkomt overselling van het laatste item)
Als je productbelofte is “als we het bevestigen, is het echt”, dan is sterke consistentie een feature, geen luxe.
Read-your-writes en isolatie in echte apps
Twee praktische gedragingen zijn belangrijk:
- Read-your-writes: nadat een gebruiker zijn profiel bijwerkt (of een bestelling plaatst), moet het volgende scherm de nieuwe staat laten zien, niet een oudere replica.
- Transaction isolation: bepaalt hoe gelijktijdige acties met elkaar omgaan. Met sterkere isolatie vermijd je subtiele fouten zoals twee klanten die allebei succesvol dezelfde stoel boeken.
De latentieprijs van cross-region consensus
Sterke consistentie over regio's vereist meestal consensus (meerdere replica's moeten akkoord zijn voordat er gecommit wordt). Als replica's continenten overspannen, wordt de lichtsnelheid een productbegrenzing: elke cross-region write kan tientallen tot honderden milliseconden toevoegen.
De afweging is eenvoudig: meer geografische veiligheid en correctheid betekent vaak hogere write-latentie, tenzij je zorgvuldig kiest waar data leeft en waar transacties mogen committen.
Spanner vs CockroachDB vs YugabyteDB: een praktische samenvatting
Google Spanner is een distributed SQL-database die voornamelijk als managed service op Google Cloud wordt aangeboden. Hij is ontworpen voor multi-region deployments wanneer je één logisch database wilt met data gerepliceerd over nodes en regio's. Spanner ondersteunt twee SQL-dialectopties—GoogleSQL (het native dialect) en een PostgreSQL-compatibele dialect—dus portabiliteit verschilt afhankelijk van welke je kiest en welke features je app gebruikt.
CockroachDB is een distributed SQL-database die bekend wil aanvoelen voor teams die gewend zijn aan PostgreSQL. Het gebruikt het PostgreSQL wire-protocol en ondersteunt een groot deel van PostgreSQL-achtige SQL, maar het is geen byte-for-byte vervanging van Postgres (sommige extensies en randgebruiken verschillen). Je kunt het als managed service (CockroachDB Cloud) draaien of zelf hosten.
YugabyteDB is een distributed database met een PostgreSQL-compatibele SQL API (YSQL) en een aanvullende Cassandra-compatibele API (YCQL). Net als CockroachDB wordt het vaak geëvalueerd door teams die Postgres-achtige ontwikkelergonomie willen en tegelijk willen opschalen over nodes en regio's. Het is zowel self-hosted als managed (YugabyteDB Managed) beschikbaar, met deploys van single-region HA tot multi-region.
Managed vs self-hosted: wat verandert
Managed services verminderen doorgaans operationeel werk (upgrades, backups, monitoring-integraties), terwijl self-hosting meer controle geeft over networking, instance types en waar data fysiek draait. Spanner wordt meestal als managed op GCP gebruikt; CockroachDB en YugabyteDB zie je vaak zowel managed als self-hosted, inclusief multi-cloud en on-prem opties.
SQL-compatibiliteit in de praktijk
Alle drie spreken “SQL”, maar dagelijkse compatibiliteit hangt af van dialectkeuze (Spanner), Postgres-featuredekking (CockroachDB/YugabyteDB) en of je app afhankelijk is van specifieke Postgres-extensies, functies of transactionele semantiek.
Plan hier tijd voor: test je queries, migraties en ORM-gedrag vroeg in plaats van uit te gaan van drop-in gelijkheid.
Use Case: Global SaaS met regionale gebruikers
Oefen failover vroeg
Zet een testomgeving op en voer failuredrills uit tegen realistisch verkeer.
Een klassieke match voor distributed SQL is een B2B SaaS-product met klanten in Noord-Amerika, Europa en APAC—denk aan supporttools, HR-platforms, analyticsdashboards of marktplaatsen.
De zakelijke eis is eenvoudig: gebruikers willen lokale app-responsiviteit, terwijl het bedrijf één logisch database wil dat altijd beschikbaar is.
Dataresidency en per-tenant plaatsing
Veel SaaS-teams eindigen met een mix van eisen:
- EU-klanten verwachten dat hun data in de EU blijft (GDPR, contractuele verplichtingen).
- Sommige klanten vereisen opslag binnen het land (bijv. Duitsland, Australië, Singapore).
- Anderen geven er niet om, maar willen wel lage latentie.
Distributed SQL kan dit schoon modelleren met per-tenant locality: plaats de primaire data van elke tenant in een specifieke regio (of set regio's) terwijl je het schema en querymodel consistent houdt over het hele systeem. Dat voorkomt de “één database per regio” explosie terwijl je residency-eisen naleeft.
Latentie minimaliseren: regionale reads en write-plaatsing
Om de app snel te houden, mik je meestal op:
- Regionale reads: read-heavy queries serveren vanaf replicas dichtbij de gebruiker.
- Write-plaatsing: plaats de write-leider (of primaire replica-set) in de regio waar de tenant het vaakst schrijft.
Dit is belangrijk omdat cross-region roundtrips de gebruikerswaargenomen latentie domineren. Zelfs met sterke consistentie zorgt goede locality ervoor dat de meeste requests geen intercontinentale netwerkprijzen betalen.
Operationele realiteit
De technische winst telt alleen als operations beheersbaar blijven. Voor global SaaS plan je voor:
- Online schema changes die tabellen niet overal blokkeren.
- Tenant-migraties (een tenant van regio wisselen met minimale downtime).
- Monitoring en alerting voor replicatievertraging, hotspots, trage queries en regio-incidenten.
Goed gedaan geeft distributed SQL je één productervaring die toch lokaal aanvoelt—zonder je engineeringteam in een “EU stack” en een “APAC stack” te splitsen.
Use Case: Financiële workflows en grootboeken
Financiële systemen zijn plekken waar “eventueel consistent” echt geld kan kosten. Als een klant een bestelling plaatst, een betaling wordt geautoriseerd en een balans aangepast, moeten die stappen op één waarheid uitkomen—direct.
Sterke consistentie voorkomt dat twee regio's (of twee services) elk een “redelijke” beslissing maken die resulteert in een incorrect grootboek.
Waarom sterke consistentie niet onderhandelbaar is
In een typische workflow—order aanmaken → fonds reserveren → betaling capturen → balans/grootboek bijwerken—wil je garanties zoals:
- Een order mag niet als “betaald” worden gemarkeerd als de betaling niet is vastgelegd.
- Een balans mag niet negatief gaan omdat twee transacties elkaar passeerden.
- Een refund mag niet twee keer worden toegepast doordat twee workers dezelfde job opnieuw probeerden.
Distributed SQL past hier omdat het ACID-transacties en constraints over nodes (en vaak regio's) biedt, zodat je grootboekinvarianten blijven gelden, zelfs tijdens fouten.
Idempotentie en patronen tegen dubbele afschrijving
De meeste betaalintegraties zijn retry-intensief: timeouts, webhook-retries en job-reprocessing komen voor. De database moet helpen retries veilig te maken.
Een praktische aanpak is application-level idempotency keys combineren met door de database afgedwongen uniciteit:
- Sla per klant/betalingspoging een
idempotency_key op.
- Voeg een unique constraint toe op
(account_id, idempotency_key).
- Wikkel “maak betaling aan + pas grootboekregels toe” in één transactie.
Zo wordt een tweede poging een onschadelijke no-op in plaats van een dubbele afschrijving.
Omgaan met pieken zonder correctheid te breken
Sales-events en payroll-runs kunnen plotselinge write-bursts veroorzaken (autorisaties, captures, transfers). Met distributed SQL kun je horizontaal schalen door knooppunten toe te voegen om write-throughput te verhogen, terwijl je hetzelfde consistentiemodel behoudt.
Het belangrijkste is anticiperen op hot keys (bijv. één merchant-account die al het verkeer krijgt) en schema-patronen gebruiken die load verdelen.
Compliance, audits en retentie
Financiële workflows vereisen vaak onveranderlijke audittrails, traceerbaarheid (wie/wat/wanneer) en voorspelbare retentiepolicies. Zonder specifieke wetgeving te noemen, ga ervan uit dat je nodig hebt: append-only grootboekregels, tijdgestampte records, gecontroleerde toegang en retentie/archiveringsregels die auditbaarheid niet ondermijnen.
Use Case: Voorraad, boekingen en reserveringen
Modelleer betrouwbare events
Schets een transactionele outbox-workflow en iterer snel op schema en handlers.
Voorraad en reserveringen lijken eenvoudig totdat meerdere regio's dezelfde schaarse resource bedienen: de laatste concertstoel, een "limited drop" product of een hotelkamer voor een specifieke nacht.
Het lastige is niet availability lezen—het is voorkomen dat twee mensen bijna tegelijk hetzelfde item claimen.
Waar conflicten vandaan komen
In een multi-region setup zonder sterke consistentie kan elke regio tijdelijk denken dat voorraad beschikbaar is op basis van licht verouderde data. Als twee gebruikers in verschillende regio's tegelijk afrekenen, kunnen beide transacties lokaal worden geaccepteerd en later conflicteren tijdens reconciliatie.
Zo ontstaat cross-region oversell: niet omdat het systeem “fout” is, maar omdat het korte momenten toestond waarbij waarheden uiteenlopen.
Distributed SQL wordt hier vaak gekozen omdat het één gezaghebbende uitkomst voor writes kan afdwingen—dus “de laatste stoel” wordt echt éénmaal toegewezen, zelfs als requests van verschillende continenten komen.
Concrete voorbeelden
- Zetelreservering: twee gebruikers klikken op dezelfde stoel. Met sterke consistentie commit slechts één transactie; de andere faalt direct en de UI kan een refresh vragen.
- Limited drops: 500 items gaan live en duizenden proberen af te rekenen. Je wilt atomische decrement-en-toewijzing, geen "best effort" met latere refunds.
- Hotelreserveringen: de eenheid van voorraad is niet alleen de kamer, maar de room-night. Dubbele boeking van een datumbereik is kostbaar en moeilijk terug te draaien.
Veelvoorkomende patronen die goed passen bij Distributed SQL
Hold + confirm: plaats een tijdelijke hold (een reserveringsrecord) in een transactie, bevestig betaling in een tweede stap.
Expiratietimers: holds horen automatisch te verlopen (bijv. na 10 minuten) zodat voorraad niet geblokkeerd blijft als een gebruiker de checkout verlaat.
Transactionele outbox: wanneer een reservering bevestigd is, schrijf in dezelfde transactie een “event to send” rij en lever die asynchroon aan e-mail, fulfillment, analytics of een message bus—zonder het risico van een “geboekt maar geen bevestiging verzonden” gat.
De conclusie: als je bedrijf dubbele toewijzing over regio's niet kan tolereren, worden sterke transactionele garanties een productfeature, geen technisch luxe.
Use Case: Hoge beschikbaarheid en disaster recovery
Hoge beschikbaarheid (HA) past goed bij Distributed SQL wanneer downtime duur is, onvoorspelbare uitval onacceptabel is en je onderhoud saai wilt maken.
Het doel is niet “nooit falen”—het is het halen van duidelijke SLO's (bijv. 99.9% of 99.99% uptime) zelfs wanneer nodes sterven, zones uitvallen of je upgrades uitvoert.
“Always-on” in de praktijk: SLO's, onderhoud, fouten
Begin met het vertalen van “always-on” naar meetbare verwachtingen: maximale maandelijkse downtime, recovery time objective (RTO) en recovery point objective (RPO).
Distributed SQL-systemen kunnen reads/writes blijven serveren door veel voorkomende fouten heen, maar alleen als je topologie overeenkomt met je SLO en je app transient errors (retries, idempotentie) netjes afhandelt.
Ook gepland onderhoud telt. Rolling upgrades en instance-replacements zijn makkelijker als de database leiderschap/replica's kan verplaatsen weg van getroffen nodes zonder het hele cluster offline te halen.
Multi-zone vs multi-region redundantie
Multi-zone deployments beschermen je tegen een enkele AZ/zone-uitval en veel hardwarefouten, meestal tegen lagere latentie en kosten. Vaak voldoende als compliance en gebruikersbasis vooral in één regio zitten.
Multi-region deployments beschermen tegen een volledige regionale uitval en ondersteunen regionale failover. De afweging is hogere write-latentie voor sterk-consistente transacties die regio's overspannen, plus complexere capaciteitsplanning.
Failoververwachtingen (en testen met game days)
Ga er niet vanuit dat failover instant of onopgemerkt is. Definieer wat “failover” betekent voor je service: korte foutpieken? read-only periodes? een paar seconden verhoogde latentie?
Voer "game days" uit om het te bewijzen:
- Kill een node, daarna een zone; verifieer je SLO-dashboards en client error budgets.
- Simuleer netwerkpartities en verifieer leider/replica-gedrag.
- Oefen regio-evacuatie en meet echte RTO.
Replicatie is geen backup
Zelfs met synchrone replicatie, houd backups en oefen restore. Backups beschermen tegen menselijke fouten (foute migraties, per ongeluk wissen), applicatiebugs en corruptie die zou kunnen repliceren.
Valideer point-in-time recovery (als beschikbaar), restoresnelheid en het vermogen om te herstellen naar een schone omgeving zonder productie te raken.
Use Case: Dataresidency en compliance-gedreven architecturen
Dataresidency-eisen komen voor wanneer regelgeving, contracten of interne beleidsregels zeggen dat bepaalde records binnen een bepaald land of regio moeten worden opgeslagen (en soms verwerkt).
Dit kan gelden voor persoonsgegevens, gezondheidsinformatie, betalingsdata, overheidsworkloads of “klant-eigendom” datasets waarbij het contract voorschrijft waar data leeft.
Distributed SQL wordt vaak overwogen omdat het één logisch database kan behouden terwijl het data fysiek in verschillende regio's plaatst—zonder dat je per geografie een volledig aparte applicatiestack hoeft te draaien.
Waarom residency-regels het databaseontwerp veranderen
Als een regulator of klant vereist dat "data in de regio blijft", is lage-latentie replica's alleen niet genoeg. Je moet soms garanderen dat:
- De primaire kopie (of alle kopieën) van specifieke data alleen in goedgekeurde regio's wordt opgeslagen
- Backups en snapshots dezelfde regels volgen
- Operators en services buiten de regio geen toegang hebben tot ruwe data
Dit duwt teams naar architecturen waarbij locatie een eersteklas zorg is, niet een bijzaak.
Per-klant plaatsing en toegangscontroles (hoog niveau)
Een veelgebruikt patroon in SaaS is per-tenant data-plaatsing. Bijvoorbeeld: EU-klanten rijmen op EU-regio's, US-klanten op US-regio's.
Op hoofdlijnen combineer je meestal:
- Dataplaatsingsregels (waar data van een tenant mag liggen)
- Identity en toegangscontrole (welke services en mensen mogen het lezen)
- Encryptie en key management (soms met regio-gebonden sleutels)
Het doel is het moeilijk maken om per ongeluk residency te schenden via operationele toegang, backup-restores of cross-region replicatie.
Juridische eisen verschillen—haal juridisch advies
Residency- en complianceverplichtingen verschillen sterk per land, sector en contract. Ze veranderen ook in de tijd.
Behandel database-topologie als onderdeel van je complianceprogramma en valideer aannames met gekwalificeerd juridisch advies (en, waar relevant, je auditors).
Hoe multi-region topologie rapportage en analytics beïnvloedt
Residency-vriendelijke topologieën kunnen een "global view" van de business compliceren. Als klantdata bewust in aparte regio's blijft, kunnen analytics en reporting:
- Regionale rapportagepijplijnen nodig hebben (compute draait waar de data zit)
- Geaggregeerde exports gebruiken (alleen toegestane metrics verlaten de regio)
- Hogere latentie accepteren voor cross-region dashboards, omdat globale queries regio's kunnen overspannen of op gerepliceerde/afgeleide datasets vertrouwen
In de praktijk scheiden veel teams operationele workloads (sterk-consistent, residency-aware) van analytics (region-scoped warehouses of zorgvuldig beheerde geaggregeerde datasets) om compliance beheersbaar te houden zonder dagelijkse productrapportage te vertragen.
Kosten- en prestatieplanning voor Distributed SQL
Simuleer voorraadconflicten
Bouw een minimale boekings-app en stress-test contentie, hot keys en consistentiegedrag.
Distributed SQL kan je behoeden voor pijnlijke uitval en regionale beperkingen, maar bespaart zelden geld standaard. Vroege planning helpt je te voorkomen dat je betaalt voor verzekering die je niet nodig hebt.
De belangrijkste kostenfactoren
De meeste budgetten vallen uiteen in vier posten:
- Nodes (compute): je betaalt voor het online houden van meerdere replica's—vaak 3+ per regio—plus extra capaciteit voor failover. Multi-region ontwerpen vereisen doorgaans meer headroom dan single-region Postgres.
- Opslag: replicatie vermenigvuldigt databestandgrootte. Een dataset van 2 TB met drie replica's is ~6 TB voordat backups, indexes en overhead meespelen.
- Inter-region verkeer: cross-region replicatie, reads en clientverkeer kunnen een materiële post worden. Dit is vaak de eerste “verrassing” wanneer je active-active gaat.
- Ops-tijd: zelfs managed aanbiedingen vragen werk: schema- en query-tuning, incident response, capaciteitsplanning, upgrade-testing en governance (vooral rond residency/compliance).
Latentie-impact inschatten op gebruikersreizen
Distributed SQL-systemen voegen coördinatie toe—vooral voor sterk-consistente writes die door een quorum bevestigd moeten worden.
Een praktische manier om impact te schatten:
- Kies 2–3 sleutelreizen (checkout, booking, "wijzigingen opslaan").
- Tel hoeveel write-transacties en read-after-write stappen in het kritieke pad zitten.
- Voor elke stap, ga uit van een multi-region roundtrip waar coördinatie nodig is. Als cross-region RTT 80–120 ms is, kunnen twee opeenvolgende write-stappen 160–240 ms aan applicatietijd toevoegen.
Dit betekent niet "doe het niet", maar wel dat je journeys moet ontwerpen om sequentiële writes te verminderen (batching, idempotente retries, minder chatty transacties).
Complexiteit vs simpelere alternatieven
Als je gebruikers grotendeels in één regio zitten, kan een single-region Postgres met read replica's, goede backups en een geteste failover-plan goedkoper en eenvoudiger zijn—en snel.
Distributed SQL verdient zijn kosten wanneer je echt multi-region writes, strakke RPO/RTO of residency-aware plaatsing nodig hebt.
Een eenvoudige ROI-kadering
Behandel de uitgave als een afweging:
- Vermeden risico: minder omzetverlies door outages, minder dataverlies, minder "global incident" weekends.
- Beschermde omzet: hogere conversie door lagere latentie voor regionale gebruikers, sterkere enterprise-positie (SLA, compliance).
- Uitgave: baseline cluster + replicatie-overhead + verkeer + engineeringtijd.
Als het vermeden verlies (downtime + churn + compliance-risico) groter is dan de meerprijs, is het multi-region ontwerp gerechtvaardigd. Zo niet, begin simpeler—en houd een pad open om later te evolueren.
Adoptie-checklist en volgende stappen
Adopteren van distributed SQL draait minder om "lift-and-shift" van een database en meer om bewijzen dat je specifieke workload goed gedraagt wanneer data en consensus verspreid zijn over nodes (en mogelijk regio's). Een licht plan helpt verrassingen te vermijden.
Een gefocuste proof-of-concept (PoC)
Kies één workload die echte pijn representeert: bijv. checkout/booking, account provisioning of grootboekposting.
Definieer succesmetingen vooraf:
- Correctheid: geen dubbele boekingen, geen verloren updates, voorspelbaar transactiegedrag
- Latency SLO's: p50/p95 voor de top 3 queries (inclusief cross-region targets indien van toepassing)
- Throughput: duurzame QPS tijdens piek + veiligheidsmarge (vaak 2–3×)
- Veerkracht: gedrag tijdens node-falen en (indien relevant) regioverlies
- Operationele inspanning: tijd om een gesimuleerd incident te detecteren, diagnosticeren en herstellen
Als je sneller wilt in PoC-fase, helpt het om een kleine "realistische" app-surface te bouwen (API + UI) in plaats van alleen synthetische benchmarks. Teams gebruiken soms Koder.ai om snel een lichte React + Go + PostgreSQL baseline-app via chat op te zetten, en wisselen dan de databasis naar CockroachDB/YugabyteDB (of verbinden met Spanner) om transactiepaden, retries en falen end-to-end te testen. Het doel is niet het starterstack zelf—maar de lus van "idee" naar "meetbare workload" verkorten.
Ontwerp-checklist (de dingen die later pijn doen)
- Schema: kies primary keys die writes verspreiden; vermijd sequentiële “hot” keys
- Indexes: houd alleen wat nodig is; begrijp write-amplification van secundaire indexen
- Partitioning/placement: bepaal partition keys (en geo/zone plaatsingsregels) op basis van access-patronen
- Hot spots: identificeer “celebrity rows” (globale tellers, single-tenant tabellen) en herontwerp vroeg
- Migraties: plan online schema changes en backfills; test rollback-paden
Operationele basics voor dag één
Monitoring en runbooks zijn net zo belangrijk als SQL:
- Dashboards voor latency, retries, contention, replicatie/consensus-gezondheid, disk en compactions
- Incident-runbooks: trage queries, node-restarts, falende replica's, oneven load
- Loadtesting die productie nabootst (read/write mix, bursts, lange transacties)
- Backups + restore-drills (inclusief point-in-time recovery als ondersteund)
Volgende stappen
Begin met een PoC-sprint, plan daarna tijd voor een production readiness review en een geleidelijke cutover (dual writes of shadow reads waar mogelijk).
Als je hulp nodig hebt bij het scopen van kosten of tiers, zie /pricing. Voor meer praktische walkthroughs en migratiepatronen, bekijk /blog.
Als je je PoC-resultaten, architectuurafwegingen of migratielessen documenteert, overweeg ze met je team te delen (en openbaar als mogelijk): platforms zoals Koder.ai bieden soms manieren om credits te verdienen voor het maken van educatieve content of het doorverwijzen van andere builders, wat de experimentkosten kan compenseren terwijl je opties evalueert.