03 okt 2025·7 min
Gegevens buiten versus binnen — lessen van Pat Helland voor apps
Leer Pat Helland's onderscheid tussen data buiten en binnen om heldere grenzen te stellen, idempotente calls te ontwerpen en state te reconciliëren bij netwerkfouten.
Leer Pat Helland's onderscheid tussen data buiten en binnen om heldere grenzen te stellen, idempotente calls te ontwerpen en state te reconciliëren bij netwerkfouten.
Als je een app bouwt, is het makkelijk om je voor te stellen dat verzoeken netjes één voor één en in de juiste volgorde binnenkomen. Echte netwerken gedragen zich niet zo. Een gebruiker tikt twee keer op “Betalen” omdat het scherm vastliep. Een mobiele verbinding valt weg direct na het drukken op een knop. Een webhook arriveert te laat, of komt twee keer. Soms komt hij helemaal niet.
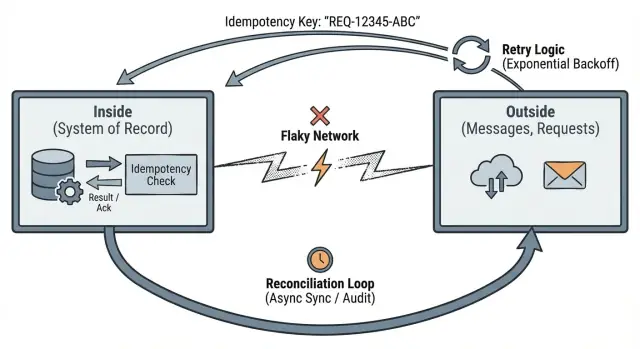
Het idee van Pat Helland over data on the outside vs inside is een heldere manier om dat rommeltje te benaderen.
“Buiten” is alles wat je systeem niet bestuurt. Het is waar je met andere mensen en systemen praat en waar bezorging onzeker is: HTTP‑verzoeken van browsers en mobiele apps, berichten uit queues, third‑party webhooks (betalingen, e-mail, verzending) en retries die door clients, proxies of achtergrondjobs worden gestart.
Ga ervan uit dat berichten buiten vertraagd, gedupliceerd of in de verkeerde volgorde aankomen. Zelfs als iets “meestal betrouwbaar” is, ontwerp voor de dag dat het dat niet is.
“Binnen” is wat je systeem betrouwbaar kan maken. Het is de duurzame staat die je opslaat, de regels die je afdwingt en de feiten die je later kunt bewijzen:
Binnen is waar je invarianties beschermt. Als je belooft “één betaling per order”, moet die belofte binnen worden afgedwongen, omdat je buiten de controle niet kunt vertrouwen.
De mentaliteitsverschuiving is simpel: ga er niet van uit dat levering of timing perfect is. Behandel elke buiteninteractie als een onbetrouwbaar voorstel dat herhaald kan worden, en laat het binnen veilig reageren.
Dit is belangrijk, ook voor kleine teams en eenvoudige apps. De eerste keer dat een netwerkfout een dubbele afschrijving of een vastzittende order veroorzaakt, wordt het geen theorie meer maar een terugbetaling, een supportticket en verlies van vertrouwen.
Een concreet voorbeeld: een gebruiker drukt op “Bestelling plaatsen”, de app stuurt een verzoek en de verbinding valt weg. De gebruiker probeert het opnieuw. Als je binnen geen manier hebt om te herkennen “dit is dezelfde poging”, kun je twee bestellingen aanmaken, twee keer voorraad reserveren of twee bevestigingsmails sturen.
Helland’s punt is glashelder: de buitenwereld is onzeker, maar het binnenste van je systeem moet consistent blijven. Netwerken verliezen pakketten, telefoons verliezen signaal, klokken lopen uiteen en gebruikers drukken op refresh. Je app kan dat allemaal niet controleren. Wat je wel kunt controleren is wat je accepteert als “waar” zodra data een duidelijke grens overschrijdt.
Stel je iemand voor die onderweg is naar kantoor en koffie bestelt op z’n telefoon in een gebouw met slechte Wi‑Fi. Ze tikken op “Betalen”. De spinner draait. Het netwerk valt weg. Ze tikken opnieuw.
Misschien bereikte het eerste verzoek je server, maar keerde het antwoord nooit terug. Of misschien kwam geen van beide verzoeken aan. Vanuit het perspectief van de gebruiker lijken beide mogelijkheden hetzelfde.
Dat is tijd en onzekerheid: je weet nog niet wat er gebeurde, en je leert het misschien later. Je systeem moet verstandig reageren terwijl het wacht.
Zodra je accepteert dat de buitenkant onbetrouwbaar is, worden een paar “vreemde” gedragingen normaal:
Buitenste data is een claim, geen feit. “Ik heb betaald” is slechts een statement over een onbetrouwbaar kanaal. Het wordt een feit pas nadat je het binnen je systeem op een duurzame, consistente manier vastlegt.
Dit stuurt je richting drie praktische gewoonten: definieer duidelijke grenzen, maak retries veilig met idempotentie en plan voor reconciliatie wanneer de realiteit niet klopt.
Het “buiten vs binnen”‑idee begint met een praktische vraag: waar begint en eindigt de waarheid van je systeem?
Binnen de grens kun je sterke garanties geven omdat je de data en de regels beheert. Buiten de grens doe je je best en ga je ervan uit dat berichten verloren, gedupliceerd, vertraagd of in de verkeerde volgorde aankomen.
In echte apps verschijnt die grens vaak op plekken zoals:
Zodra je die lijn trekt, bepaal welke invarianties binnen absoluut niet onderhandelbaar zijn. Voorbeelden:
De grens heeft ook heldere taal nodig voor “waar we staan”. Veel fouten ontstaan in de kloof tussen “we hebben je gehoord” en “we zijn klaar”. Een nuttig patroon is om drie betekenissen te scheiden:
Als teams dit overslaan, ontstaan bugs die alleen optreden onder load of tijdens partiële storingen. Het ene systeem gebruikt “betaald” om geld afgeschreven te betekenen; een ander gebruikt het om een betaalpoging gestart aan te duiden. Die mismatch veroorzaakt duplicaten, vastzittende orders en supporttickets die niemand kan reproduceren.
Idempotentie betekent: als hetzelfde verzoek twee keer wordt gestuurd, behandelt het systeem het alsof het één verzoek is en geeft het dezelfde uitkomst terug.
Retries zijn normaal. Timeouts gebeuren. Clients herhalen zichzelf. Als de buitenkant kan herhalen, moet je binnen die herhaling omzetten in stabiele statuswijzigingen.
Een eenvoudig voorbeeld: een mobiele app stuurt “betaal €20” en de verbinding valt weg. De app probeert het opnieuw. Zonder idempotentie kan de klant twee keer worden afgeschreven. Met idempotentie geeft het tweede verzoek het resultaat van de eerste terug.
De meeste teams gebruiken een van deze patronen (soms een mix):
Idempotency-Key: ...). De server slaat de key en het uiteindelijke antwoord op.Als een duplicaat aankomt, is het beste gedrag meestal geen “409 conflict” of een generieke fout. Het is het teruggeven van hetzelfde resultaat dat je de eerste keer gaf, inclusief dezelfde resource‑ID en status. Dat maakt retries veilig voor clients en achtergrondjobs.
Het idempotency‑record moet binnen je grens in duurzame opslag leven, niet in geheugen. Als je API herstart en alles vergeet, verdwijnt de veiligheidsgarantie.
Bewaar records lang genoeg om realistische retries en vertraagde leveringen te dekken. Het venster hangt af van business‑risico: minuten tot uren voor laag‑risico creates, dagen voor betalingen/e‑mails/verzendingen waar duplicaten kostbaar zijn, en langer als partners voor langere periodes kunnen retryen.
Gedistrubueerde transacties klinken geruststellend: één grote commit over services, queues en databases. In de praktijk zijn ze vaak onbeschikbaar, traag of te fragiel om op te vertrouwen. Zodra een netwerkhop betrokken is, kun je niet aannemen dat alles samen commit.
Een veelgemaakte valkuil is een workflow bouwen die alleen werkt als elke stap nu meteen slaagt: save order, charge card, reserve inventory, send confirmation. Als stap 3 time‑out, is het mislukt of geslaagd? Als je opnieuw probeert, charge je dan dubbel of reserveer je twee keer?
Twee praktische benaderingen vermijden dit:
Kies per workflow één stijl en houd je eraan. Het mixen van “soms doen we een outbox” met “soms veronderstellen we synchronisch succes” creëert edgecases die lastig te testen zijn.
Een eenvoudige regel helpt: als je niet atomair over grenzen kunt committen, ontwerp dan voor retries, duplicaten en vertragingen.
Reconciliatie is het toegeven van een basiswaarheid: wanneer je app met andere systemen via een netwerk praat, zullen jullie soms van mening verschillen over wat er gebeurde. Verzoeken timen‑out, callbacks komen te laat en mensen herhalen acties. Reconciliatie is hoe je mismatches detecteert en na verloop van tijd repareert.
Behandel externe systemen als onafhankelijke bronnen van waarheid. Je app houdt zijn eigen interne record bij, maar je hebt een manier nodig om dat record te vergelijken met wat partners, providers en gebruikers daadwerkelijk deden.
De meeste teams gebruiken een klein setje saaie tools (saai is goed): een worker die pending acties opnieuw probeert en externe status controleert, een geplande scan op inconsistenties en een kleine admin‑repareeractie voor support om opnieuw te proberen, te annuleren of als beoordeeld te markeren.
Reconciliatie werkt alleen als je weet wat te vergelijken: interne grootboek versus provider‑grootboek (betalingen), order‑staat versus verzending‑staat (fulfillment), abonnements‑staat versus billing‑staat.
Maak staten herstelbaar. In plaats van meteen van “created” naar “completed” te springen, gebruik houd‑staten zoals pending, on hold of needs review. Dat maakt het veilig om te zeggen “we weten het nog niet” en geeft reconciliatie een duidelijke plaats om te landen.
Leg een kleine audittrail vast bij belangrijke wijzigingen:
Voorbeeld: als je app een verzendlabel aanvraagt en het netwerk wegvalt, kun je intern “geen label” hebben terwijl de vervoerder er wel één heeft aangemaakt. Een recon‑worker kan zoeken op correlation ID, het label vinden en de order vooruit zetten (of markeren voor review als details niet overeenkomen).
Als je ervan uitgaat dat het netwerk faalt, verandert het doel. Je probeert niet elke stap in één keer te laten slagen. Je probeert elke stap veilig herhaalbaar en makkelijk te repareren te maken.
Schrijf een eendelige grensverklaring. Wees expliciet over wat je systeem bezit (de bron van waarheid), wat het weerspiegelt en wat het alleen van anderen opvraagt.
Maak een lijst met faalmodi vóór het happy path. Minimaal: timeouts (je weet niet of het werkte), dubbele verzoeken, gedeeltelijk succes (één stap gebeurde, de volgende niet) en events in verkeerde volgorde.
Kies een idempotentie‑strategie voor elke input. Voor synchrone API's is dat vaak een idempotency‑key plus een opgeslagen resultaat. Voor berichten/events is het meestal een unieke message‑ID en een "heb ik dit verwerkt?"‑record.
Persisteer intent, en handel dan. Sla eerst iets duurs op zoals PaymentAttempt: pending of ShipmentRequest: queued, voer dan de externe call uit en sla daarna de uitkomst op. Geef een stabiele referentie‑ID terug zodat retries naar dezelfde intent wijzen in plaats van een nieuwe te maken.
Bouw reconciliatie en een reparatiepad, en maak ze zichtbaar. Reconciliatie kan een job zijn die "pending te lang" records scant en externe status navraagt. Het reparatiepad kan een veilige admin‑actie zijn zoals "retry", "cancel" of "mark resolved", met een audit‑notitie. Voeg basis observability toe: correlation IDs, duidelijke statusvelden en een paar tellers (pending, retries, failures).
Voorbeeld: als checkout time‑out gaat direct nadat je een payment provider aanriep, gok dan niet. Sla de poging op, retourneer het attempt‑ID en laat de gebruiker opnieuw proberen met dezelfde idempotency‑key. Later kan reconciliatie bevestigen of de provider heeft afgeschreven en de poging bijwerken zonder dubbel af te schrijven.
Een klant tikt op “Bestelling plaatsen”. Je service stuurt een betaalverzoek naar een provider, maar het netwerk is wankel. De provider heeft zijn eigen waarheid, en jouw database heeft de jouwe. Ze zullen uit elkaar lopen tenzij je er voor ontwerpt.
Vanuit jouw perspectief is de buitenkant een stroom van berichten die laat, herhaald of afwezig kunnen zijn:
Geen van die stappen garandeert "exactly once". Ze garanderen alleen "misschien".
Binnen je grens sla je duurzame feiten op en het minimum dat nodig is om buitengebeurtenissen aan die feiten te koppelen.
Wanneer de klant de bestelling plaatst, maak je een order‑record aan in een duidelijke staat zoals pending_payment. Maak ook een payment_attempt‑record met een unieke provider‑referentie en een idempotency_key gekoppeld aan de klantactie.
Als de client time‑out gaat en opnieuw probeert, zou je API geen tweede order moeten aanmaken. Het moet de idempotency_key opzoeken en hetzelfde order_id en de huidige staat teruggeven. Die ene keuze voorkomt duplicaten bij netwerkfouten.
Nu arriveert de webhook twee keer. De eerste callback werkt payment_attempt bij naar authorized en zet de order op paid. De tweede callback raakt dezelfde handler, maar je detecteert dat je dat provider‑event al hebt verwerkt (door de provider event‑ID op te slaan of door de huidige staat te checken) en doet niets. Je kunt nog steeds 200 OK teruggeven, omdat het resultaat al waar is.
Ten slotte regelt reconciliatie de rommelige gevallen. Als de order na enige tijd nog pending_payment staat, vraagt een achtergrondjob de provider opnieuw op basis van de opgeslagen referentie. Als de provider “authorized” zegt maar jij de webhook miste, werk je je records bij. Als de provider “failed” zegt maar jij het als betaald markeerde, markeer je het voor review of start je een compenserende actie zoals terugbetaling.
De meeste dubbele records en vastlopende workflows komen voort uit het verwarren van wat buiten je systeem gebeurde (een verzoek kwam aan, een bericht werd ontvangen) met wat je veilig in je systeem hebt gecommit.
Een klassiek falen: een client stuurt "place order", je server begint te werken, het netwerk valt weg en de client probeert het opnieuw. Als je elke retry als compleet nieuwe waarheid behandelt, krijg je dubbele afschrijvingen, duplicaatorders of meerdere e‑mails.
De gebruikelijke oorzaken zijn:
Eén probleem maakt alles erger: geen audittrail. Als je velden overschrijft en alleen de laatste staat bewaart, verlies je het bewijs dat je later nodig hebt om te reconciliëren.
Een goede sanitycheck is: "Als ik deze handler twee keer uitvoer, krijg ik hetzelfde resultaat?" Als het antwoord nee is, zijn duplicaten geen zeldzame edgecase. Ze zijn gegarandeerd.
Als je één ding onthoudt: je app moet correct blijven, ook als berichten te laat komen, twee keer aankomen of helemaal niet.
Gebruik deze checklist om zwakke plekken te vinden voordat ze leiden tot duplicaten, ontbrekende updates of vastzittende workflows:
Als je één van deze niet snel kunt beantwoorden, is dat nuttig. Meestal betekent het dat een grens vaag is of een state‑transitie ontbreekt.
Praktische vervolgstappen:
Schets eerst grenzen en staten. Definieer een kleine set staten per workflow (bijvoorbeeld: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
Voeg idempotentie toe waar het het meest nodig is. Begin met de hoogst‑risico writes: create order, capture payment, issue refund. Sla idempotency‑keys op in PostgreSQL met een unieke constraint zodat duplicaten veilig worden geweigerd.
Behandel reconciliatie als een normale feature. Plan een job die "pending te lang" records zoekt, externe systemen opnieuw controleert en lokale staat repareert.
Iterateer veilig. Pas transities en retry‑regels aan en test door bewust hetzelfde verzoek opnieuw te sturen en hetzelfde event opnieuw te verwerken.
Als je snel bouwt op een chatgestuurde platform zoals Koder.ai (koder.ai), is het nog steeds de moeite waard deze regels vroeg in je gegenereerde services in te bouwen: snelheid komt door automatisering, maar betrouwbaarheid door duidelijke grenzen, idempotente handlers en reconciliatie.
"Buiten" is alles wat je niet controleert: browsers, mobiele netwerken, queues, third‑party webhooks, retries en timeouts. Ga ervan uit dat berichten vertraagd, gedupliceerd, verloren of in de verkeerde volgorde aankomen.
"Binnen" is wat je wél controleert: je opgeslagen staat, je regels en de feiten die je later kunt aantonen (meestal in je database).
Omdat het netwerk je misleidt.
Een client die timed‑out raakt, betekent niet dat je server het verzoek niet heeft verwerkt. Een webhook die twee keer binnenkomt, betekent niet dat de provider de actie twee keer heeft uitgevoerd. Als je elk bericht als “nieuwe waarheid” behandelt, creëer je dubbele bestellingen, dubbele afschrijvingen en vastzittende workflows.
Een duidelijke grens is het punt waar een onbetrouwbaar bericht een duurzaam feit wordt.
Veelvoorkomende grenzen zijn:
Zodra data de grens passeert, handhaaf je binnen de invarianties (zoals "een order kan slechts eenmaal betaald worden").
Gebruik idempotentie. De vuistregel is: dezelfde intentie moet hetzelfde resultaat opleveren, zelfs als deze meerdere keren wordt gestuurd.
Praktische patronen:
Bewaar het niet alleen in geheugen. Sla het binnen je grens op (bijvoorbeeld in PostgreSQL) zodat restarts je bescherming niet wissen.
Retentie‑vuistregel:
Bewaar het lang genoeg om realistische retries en vertraagde callbacks te dekken.
Gebruik staten die onzekerheid toelaten.
Een simpele, praktische set:
pending_* (we accepteerden de intentie maar kennen het resultaat nog niet)succeeded / failed (we hebben een definitief resultaat vastgelegd)needs_review (we detecteerden een mismatch die een mens of speciale job vereist)Omdat je niet atomair kunt committen over meerdere systemen via een netwerk.
Als je synchroon doet “save order → charge card → reserve inventory” en stap 2 time‑out, weet je niet of je moet retryen. Retries kunnen duplicaten veroorzaken; niet retryen kan werk onafgemaakt laten.
Ontwerp voor gedeeltelijk succes: persisteer intent eerst, voer dan externe acties uit en registreer daarna de uitkomst.
Het outbox/inbox‑patroon maakt messaging tussen systemen betrouwbaar zonder te doen alsof het netwerk perfect is.
Reconciliatie is hoe je herstelt wanneer jouw records en een extern systeem het oneens zijn.
Goede defaults:
needs_reviewHet is niet optioneel voor betalingen, fulfillment, abonnementen of alles met webhooks.
Ja. Snel bouwen haalt je niet weg van netwerkfouten — het brengt je er alleen sneller naartoe.
Als je services genereert met Koder.ai, bouw deze defaults vroeg in:
Zo worden retries en dubbele callbacks saai in plaats van duur.
Dit voorkomt gokken tijdens timeouts en maakt reconciliatie eenvoudiger.