Waarom geheugenbeheer invloed heeft op prestaties en veiligheid
Geheugenbeheer zijn de regels en mechanismen die een programma gebruikt om geheugen aan te vragen, te gebruiken en terug te geven. Elk draaiend programma heeft geheugen nodig voor dingen zoals variabelen, gebruikersdata, netwerkbuffers, afbeeldingen en tussenresultaten. Omdat geheugen beperkt is en gedeeld met het besturingssysteem en andere applicaties, moeten talen beslissen wie verantwoordelijk is voor het vrijgeven en wanneer dat gebeurt.
Die keuzes bepalen twee uitkomsten waar de meeste mensen om geven: hoe snel een programma aanvoelt, en hoe betrouwbaar het zich gedraagt onder belasting.
Performance is geen enkel getal. Geheugenbeheer kan invloed hebben op:
- Throughput: hoeveel werk je per seconde kunt afhandelen (verwerkte requests, gerenderde frames, verwerkte bestanden).
- Latency: hoe lang een individuele bewerking duurt, vooral tail-latency pieken veroorzaakt door pauzes of trage allocaties.
- Geheugengebruik: hoeveel RAM het programma vasthoudt tijdens uitvoering, wat kosten, batterijduur en swap-gedrag beïnvloedt.
Een taal die snel aligneert maar af en toe pauzeert om op te ruimen, kan er goed uitzien in benchmarks maar schokkerig aanvoelen in interactieve apps. Een ander model dat pauzes vermijdt, kan meer zorgvuldige ontwerpkeuzes vereisen om lekken en fouten in levensduur te voorkomen.
Wat “veiligheid” hier betekent
Veiligheid gaat over het voorkomen van geheugen-gerelateerde fouten, zoals:
- Crashes (toegang tot ongeldig geheugen)
- Datacorruptie (schrijven op plekken waar je dat niet zou moeten)
- Beveiligingslekken (bugs die aanvallers tot exploits kunnen maken)
Veel ernstige beveiligingsproblemen zijn terug te voeren op geheugenfouten zoals use-after-free of buffer overflows.
Deze gids is een niet-technische rondleiding langs de belangrijkste geheugenmodellen die populaire talen gebruiken, wat ze optimaliseren en welke afwegingen je maakt bij je keuze.
Kernbegrippen: stack, heap en objectlevensduren
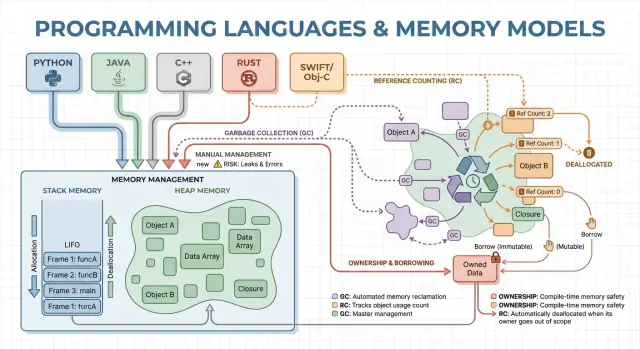
Geheugen is waar je programma data bewaart terwijl het draait. De meeste talen organiseren dit rond twee hoofdgebieden: de stack en de heap.
Stack: snel, tijdelijk opslag
Zie de stack als een opgeruimd stapeltje notities voor de huidige taak. Wanneer een functie start, krijgt ze een klein “frame” op de stack voor lokale variabelen. Wanneer de functie eindigt, wordt dat hele frame in één keer verwijderd.
Dit is snel en voorspelbaar—maar werkt alleen voor waarden waarvan de grootte bekend is en waarvan de levensduur eindigt met de functie-aanroep.
Heap: flexibel, langerlevende opslag
De heap is meer een opslagruimte waar je objecten kunt bewaren zolang je ze nodig hebt. Het is ideaal voor dynamisch formaat lijsten, strings of objecten die met verschillende delen van een programma worden gedeeld.
Omdat heap-objecten langer kunnen leven dan één functie, wordt de kernvraag: wie is verantwoordelijk voor het vrijgeven en wanneer? Die verantwoordelijkheid is het “geheugenbeheermodel” van een taal.
Levensduren en waarom pointers/referenties belangrijk zijn
Een pointer of referentie is een manier om een object indirect te benaderen—zoals het hebben van het plankenummer voor een doos in de opslag. Als de doos wordt weggegooid maar je hebt nog het plankenummer, kun je rommel lezen of crashen (een klassiek use-after-free-bug).
Een eenvoudig voorbeeldscenario
Stel je een lus voor die een klantrecord aanmaakt, een bericht formatteert en het weggooit:
- Op de stack: kleine tijdelijke variabelen die alleen tijdens het formatteren gebruikt worden.
- Op de heap: het klantrecord en de berichttekst (variabele groottes).
Sommige talen verbergen deze details (automatische opruiming), terwijl andere ze blootleggen (je geeft geheugen expliciet vrij, of je moet regels volgen over wie een object bezit). De rest van dit artikel verkent hoe die keuzes snelheid, pauzes en veiligheid beïnvloeden.
Handmatig geheugenbeheer: controle met hoger risico
Handmatig geheugenbeheer betekent dat het programma (en dus de ontwikkelaar) expliciet geheugen aanvraagt en later vrijgeeft. In de praktijk zie je dat met malloc/free in C, of new/delete in C++. Het komt nog vaak voor in systems-programmering waar je precieze controle nodig hebt over wanneer geheugen wordt verworven en teruggegeven.
Waar expliciete allocatie/free voor wordt gebruikt
Je allocateert meestal geheugen wanneer een object langer moet leven dan de huidige functie-aanroep, dynamisch groeit (bijv. een resizable buffer), of een specifieke layout nodig heeft voor interoperabiliteit met hardware, OS of netwerkprotocollen.
Zonder een garbage collector op de achtergrond zijn er minder onverwachte pauzes. Allocatie en deallocatie kunnen zeer voorspelbaar worden gemaakt, vooral in combinatie met custom allocators, pools of fixed-size buffers.
Handmatige controle kan ook overhead verminderen: er is geen traceerfase, geen write barriers en vaak minder metadata per object. Met zorgvuldig ontwerp kun je strakke latencydoelen halen en het geheugen binnen strikte grenzen houden.
Veiligheidsrisico’s: klassieke foutmodi
De keerzijde is dat het programma fouten kan maken die de runtime niet automatisch voorkomt:
- Geheugenlekken (vergeten vrij te geven)
- Double-free (twee keer vrijgeven)
- Use-after-free (toegang na vrijgave)
Deze bugs kunnen crashes, datacorruptie en beveiligingsproblemen veroorzaken.
Gebruikelijke mitigaties
Teams beperken risico door te beperken waar ruwe allocatie is toegestaan en te vertrouwen op patronen zoals:
- RAII in C++ (resources worden automatisch vrijgegeven als objecten uit scope gaan)
- Smart pointers (bijv.
std::unique_ptr) om eigendom te coderen
- Coding standards, code reviews, sanitizers en statische analyse
Wanneer het goed past
Handmatig geheugenbeheer is vaak een sterke keuze voor embedded software, realtime systemen, OS-componenten en performance-kritische libraries—plaatsen waar strakke controle en voorspelbare latency belangrijker zijn dan ontwikkelaarsgemak.
Garbage collection: productiviteit en voorspelbare veiligheid
Garbage collection (GC) is automatische geheugenopruiming: in plaats van zelf free te moeten doen, houdt de runtime bij welke objecten nog bereikbaar zijn en maakt de rest vrij. In de praktijk kun je je meer concentreren op gedrag en datastromen terwijl het systeem de meeste allocatie- en deallocatiebeslissingen afhandelt.
Hoe GC ongebruikte objecten vindt
De meeste collectors werken door eerst levende objecten te identificeren en daarna de rest vrij te geven.
Tracing GC begint bij “roots” (zoals stackvariabelen, globale referenties en registers), volgt referenties om alles bereikbaars te markeren en veegt vervolgens de heap om ongemarkeerde objecten vrij te geven. Als niets naar een object wijst, komt het in aanmerking voor collectie.
Veelvoorkomende GC-stijlen (hoog niveau)
Generational GC is gebaseerd op de observatie dat veel objecten jong sterven. Het splitst de heap in generaties en verzamelt jongere gebieden vaker, wat meestal goedkoper is en de efficiëntie verbetert.
Concurrent GC voert delen van de collectie naast applicatiedraadjes uit om lange pauzes te verminderen. Dit vraagt vaak extra administratie om het geheugenconsistent te houden terwijl de applicatie doorloopt.
Prestatieafwegingen
GC ruilt typisch handmatige controle in voor runtime-werk. Sommige systemen prioriteren constante throughput (veel werk per seconde) maar kunnen stop-the-world-pauzes introduceren. Andere minimaliseren pauzes voor latency-gevoelige apps, maar voegen overhead toe tijdens normale uitvoering.
Waarom ontwikkelaars het prettig vinden
GC verwijdert een hele klasse van levensduur-bugs (vooral use-after-free) omdat objecten niet worden opgeruimd zolang ze nog bereikbaar zijn. Het vermindert ook lekken door gemiste deallocaties (hoewel je nog steeds kunt “leaken” door referenties langer vast te houden dan bedoeld). In grote codebases waar eigendom lastig handmatig te volgen is, versnelt dit vaak de iteratie.
Waar je het tegenkomt
Garbage-gebaseerde runtimes komen veel voor in de JVM (Java, Kotlin), .NET (C#, F#), Go en JavaScript-engines in browsers en Node.js.
Referentietelling: directe opruiming met nadelen
Krijg code die je kunt beheren
Genereer een baseline-implementatie en exporteer vervolgens de broncode om lokaal te optimaliseren.
Referentietelling is een strategie waarbij elk object bijhoudt hoeveel “eigenaren” (referenties) ernaar wijzen. Als de teller op nul komt, wordt het object onmiddellijk vrijgegeven. Die directheid voelt intuïtief: zodra niets meer naar een object kan wijzen, wordt het geheugen teruggewonnen.
Hoe het werkt (en waarom het aantrekkelijk is)
Elke keer dat je een referentie kopieert of opslaat, verhoogt de runtime de teller; als een referentie verdwijnt, verlaagt hij die. Bij nul vindt direct opruiming plaats.
Dit maakt resourcebeheer eenvoudig: objecten geven vaak geheugen vrij vlak nadat je ze niet meer gebruikt, wat piekgeheugen kan verminderen en vertraagde opruiming voorkomt.
Prestatiekenmerken
Referentietelling heeft doorgaans een constante, voorspelbare overhead: increment-/decrement-operaties gebeuren bij veel toewijzingen en functieaanroepen. Die overhead is meestal klein, maar aanwezig.
Het voordeel is dat je doorgaans geen grote stop-the-world-pauzes krijgt zoals bij sommige tracing-GC’s. De latency voelt vaak vloeiender, hoewel er nog steeds golven van deallocatie kunnen optreden wanneer grote objectgrafen hun laatste eigenaar verliezen.
Het grote probleem: cycli
Referentietelling kan geen objecten opruimen die in een cyclus zitten. Als A naar B verwijst en B naar A, blijven beide tellers boven nul zelfs als niets anders ernaar verwijst—waardoor een geheugenlek ontstaat.
Ecosystemen lossen dit op via:
- Weak references (niet-eigenaarsreferenties) om cycli te doorbreken in veelvoorkomende patronen
- Cycledetectie bovenop referentietelling (een tracing-pass die onbereikbare cycli opspoort)
Waar je het ziet
- Swift / Objective-C gebruiken ARC (Automatic Reference Counting), met “strong/weak/unowned” verwijzingen om cycli te beheren.
- Python gebruikt referentietelling voor directe opruiming, plus een cycledetector om cyclische garbage op te ruimen.
Eigendom en lenen: compile-time geheugenveiligheid
Ownership en borrowing is een model dat sterk wordt geassocieerd met Rust. Het idee: de compiler handhaaft regels die het moeilijk maken om dangling pointers, double-frees en veel data-raceklassen te maken—zonder op een garbage collector tijdens runtime te vertrouwen.
Ownership: één duidelijke eigenaar, deterministische opruiming
Elke waarde heeft op elk moment precies één “eigenaar”. Wanneer die eigenaar uit scope gaat, wordt de waarde onmiddellijk en voorspelbaar opgeruimd. Dat geeft deterministisch resourcebeheer (geheugen, file handles, sockets) vergelijkbaar met handmatig beheer, maar met veel minder mogelijkheden om fouten te maken.
Eigendom kan ook verplaatsen: een waarde toewijzen aan een nieuwe variabele of doorgeven aan een functie kan verantwoordelijkheid overdragen. Na een move kan de oude binding niet meer gebruikt worden, wat use-after-free voorkomt door ontwerp.
Borrowing: tijdelijke toegang zonder eigenaar te worden
Borrowing laat je een waarde gebruiken zonder eigenaar te worden.
Een gedeelde borrow geeft alleen-lezen toegang en kan vrij gekopieerd worden.
Een mutabele borrow laat wijzigen toe, maar moet exclusief zijn: zolang die bestaat, mag niemand anders hetzelfde waarde lezen of schrijven. Deze “één schrijver of vele lezers”-regel wordt door de compiler gecontroleerd.
Veiligheidsvoordelen—en de kosten
Omdat levensduren worden gevolgd, kan de compiler code afkeuren die langer leeft dan de data waarnaar ze verwijst, waardoor veel dangling-reference fouten verdwijnen. Dezelfde regels voorkomen ook veel racecondities in concurrerende code.
De afweging is een leercurve en enkele ontwerpbeperkingen. Je moet mogelijk datastromen herstructureren, duidelijkere eigendomsgrenzen introduceren of gespecialiseerde types gebruiken voor gedeelde mutabele staat.
Waar het uitblinkt
Dit model past goed bij systemenprogramma’s—services, embedded, netwerken en performance-gevoelige componenten—waar je voorspelbare opruiming en lage latency wilt zonder GC-pauzes.
Arenas, regions en pools: snelle allocatiepatronen
Als je veel kortlevende objecten maakt—AST-nodes in een parser, entiteiten in een game-frame, tijdelijke data tijdens een webrequest—kan de overhead van elk object apart alloceren en vrijgeven de runtime domineren. Arenas (regions) en pools zijn patronen die fijne-grained frees omruilen voor snelle bulkbeheer.
Wat arenas/regions zijn
Een arena is een geheugen“zone” waarin je veel objecten aligneert en die je vervolgens allemaal tegelijk vrijgeeft door de arena te droppen of te resetten.
In plaats van elke levensduur individueel te volgen, koppel je levensduren aan een duidelijke grens: “alles dat voor dit request isAllocated”, of “alles dat tijdens het compileren van deze functie is aangemaakt.”
Waarom het snel kan zijn
Arenas zijn vaak snel omdat ze:
- minder allocator-aanroepen nodig hebben (vaak alleen pointer bumping)
- per-object free-kosten vermijden
- cache-locatie verbeteren door gerelateerde objecten dicht bij elkaar te houden
Dit kan throughput verbeteren en latencypieken verminderen veroorzaakt door frequente frees of allocator-contentie.
Typische gebruikssituaties
Arenas en pools komen voor in:
- parsers en compilers (syntax trees, symbol tables)
- request-gescoped serverdata (allocate tijdens request, vrijgeven aan het einde)
- games (per-frame allocaties die elk frame gereset worden)
- simulaties en batchverwerkingsjobs
Veiligheidsoverwegingen
De hoofdregel is simpel: laat referenties niet ontsnappen uit de regio die het geheugen bezit. Als iets uit een arena globaal wordt opgeslagen of wordt geretourneerd voorbij de levensduur van de arena, riskeer je use-after-free bugs.
Talen en libraries gaan hier verschillend mee om: sommige vertrouwen op discipline en API’s, andere kunnen de regiogrens in types coderen.
Hoe het andere benaderingen aanvult
Arenas en pools zijn geen vervanging voor GC of ownership—ze vullen elkaar vaak aan. GC-talen gebruiken pools voor hete paden; ownership-talen kunnen arenas gebruiken om allocaties te groeperen en levensduren expliciet te maken. Met zorg gebruikt leveren ze “snel standaard” allocatie zonder onduidelijkheid over wanneer geheugen wordt vrijgegeven.
Compiler- en runtime-optimalisaties die het beeld veranderen
Prototypeer een mobiele versie
Probeer dezelfde workflow in Flutter om geheugenbelasting op mobiele apparaten te vergelijken.
Het geheugenmodel van een taal is slechts een deel van het verhaal over performance en veiligheid. Moderne compilers en runtimes herschrijven je programma om minder te alloceren, sneller vrij te geven en extra administratie te vermijden. Daarom kloppen vuistregels als “GC is traag” of “handmatig geheugen is het snelst” vaak niet in echte toepassingen.
Escape-analyse: wanneer de heap niet nodig is
Veel allocaties bestaan alleen om data tussen functies door te geven. Met escape-analyse kan een compiler bewijzen dat een object nooit de huidige scope ontgroeit en het op de stack houden in plaats van de heap.
Dat kan een heapallocatie helemaal weghalen, samen met bijbehorende kosten (GC-tracking, referentietellingsupdates, allocatorlocks). In managed talen is dit een belangrijke reden dat kleine objecten goedkoper kunnen zijn dan je zou verwachten.
Inlining en allocatieverwijdering
Wanneer een compiler een functie inline zet (de oproep vervangt door de functiebody), ziet hij soms door lagen van abstractie heen. Die zichtbaarheid maakt optimalisaties mogelijk zoals:
- tijdelijke objecten elimineren
- scalar replacement (een object vervangen door enkele lokale variabelen)
- referentietellingsverkeer verwijderen wanneer levensduren duidelijker worden
Goed ontworpen API’s kunnen na optimalisatie “zero-cost” zijn, ook al lijken ze in broncode allocatie-intensief.
JIT versus ahead-of-time compilatie
Een JIT kan optimaliseren op basis van echte productiegegevens: welke paden hot zijn, typische objectgroottes en allocatiepatronen. Dat verbetert vaak throughput, maar kan opwarmtijd en af en toe pauzes voor hercompilatie of GC toevoegen.
Ahead-of-time compilers moeten meer raden, maar leveren voorspelbare startup en stabielere latency.
Runtime-tuninglevers (en wanneer je eraan trekt)
GC-gebaseerde runtimes bieden instellingen zoals heapgrootte, gewenste pauzetijden en generatie-drempels. Pas die aan wanneer je gemeten bewijs hebt (bijv. latencypieken of geheugenstress), niet als eerste stap.
Waarom hetzelfde algoritme zich anders gedraagt
Twee implementaties van hetzelfde algoritme kunnen verschillen in verborgen allocaties, tijdelijke objecten en pointer-chasing. Die verschillen beïnvloeden optimalisaties, de allocator en cachegedrag—dus prestatievergelijkingen vereisen profilering, geen aannames.
Prestatieafwegingen: throughput, latency en geheugengebruik
Geheugenbeheerkeuzes veranderen niet alleen hoe je code schrijft—ze veranderen wanneer werk gebeurt, hoeveel geheugen je moet reserveren en hoe consistent de performance voelt voor gebruikers.
Throughput versus latency (een concreet voorbeeld)
Throughput is “hoeveel werk per tijdseenheid.” Denk aan een nachtelijke batchjob die 10 miljoen records verwerkt: als GC of referentietelling kleine overheads toevoegt maar de ontwikkelaarssnelheid verhoogt, kun je alsnog het snelst klaar zijn.
Latency is “hoe lang één bewerking duurt end-to-end.” Voor een webrequest schaadt een enkele trage respons de gebruikerservaring, zelfs als de gemiddelde throughput hoog is. Een runtime die af en toe pauzeert om geheugen vrij te maken kan prima zijn voor batchverwerking, maar storend in interactieve apps.
Geheugengebruik: kosten en snelheid
Een groter memory footprint verhoogt cloudkosten en kan programma’s vertragen. Als je working set niet goed in CPU-caches past, wacht de CPU vaker op data uit RAM. Sommige strategieën ruilen extra geheugen voor snelheid (bijv. object pools), terwijl andere geheugen besparen maar meer administratie vragen.
Fragmentatie en cache-locatie (in gewone taal)
Fragmentatie ontstaat wanneer vrij geheugen in veel kleine gaten is verdeeld—alsof je een busje wilt parkeren in een parkeerplaats met alleen losse kleine plekken. Allocators kunnen meer tijd besteden aan het zoeken naar ruimte en het geheugen kan groeien ondanks dat er “genoeg” vrij is.
Cache-locality betekent dat gerelateerde data dicht bij elkaar staat. Pool/arena-allocatie verbetert vaak locality (objecten die samen zijn aangemaakt liggen bij elkaar), terwijl langlevende heaps met gemengde objectgroottes minder cachevriendelijk kunnen worden.
Voorspelbare timingseisen
Als je consistente reactietijden nodig hebt—games, audio-apps, trading-systemen, embedded of realtime-controllers—kan “meestal snel maar af en toe langzaam” slechter zijn dan “iets langzamer maar consequent.” Hier zijn voorspelbare deallocatiepatronen en strakke controle over allocaties belangrijk.
Meet-checklist
- Benchmark zowel throughput (jobs/sec) als tail latency (p95/p99 requesttijd)
- Profile allocaties: allocatiesnelheid, pauzetijd en tijd besteed aan alloc/free
- Gebruik representatieve lasten (echte verkeerspatronen, datagroottes, gelijktijdigheid)
- Volg geheugen: piek RSS, heapgrootte in de tijd, fragmentatiemetrics (indien beschikbaar)
- Herhaal runs om variabiliteit te vangen (warm-up effecten, achtergrond-GC-cycli)
Veiligheid en beveiliging: hoe geheugenmodellen veelvoorkomende bugs voorkomen
Deploy en valideer gedrag
Implementeer een werkende app en observeer hoe het geheugenverbruik verandert onder realistisch verkeer.
Geheugenfouten zijn niet alleen “programmeurfouten.” In veel systemen leiden ze tot beveiligingsproblemen: plotselinge crashes (DoS), onbedoelde data-exposure (lezen van vrijgegeven of niet-geïnitialiseerd geheugen) of exploitabele situaties waarin aanvallers gedrag kunnen sturen.
Hoe bugs zich verhouden tot geheugenmodellen
Verschillende geheugenstrategieën falen op verschillende manieren:
- Handmatig geheugenbeheer (C/C++) loopt vaak risico op use-after-free, double free en buffer overflows—problemen die geheugen kunnen corrumperen en te misbruiken zijn.
- Garbage collection verwijdert de meeste UAF-achtige fouten omdat objecten niet worden vrijgegeven zolang ze bereikbaar zijn, maar je kunt nog steeds geheugenlekken hebben door referenties te lang vast te houden en risico’s bij onveilige native interop.
- Referentietelling geeft voorspelbare opruiming, maar kan lijden aan cycli (lekken) en subtiele levensduurkwesties bij gedeelde mutabele staat.
- Ownership/borrowing (bijv. Rust) voorkomt veel UAF- en datastracedangen door compile-time regels die dangling references en ongesynchroniseerde gedeelde mutatie moeilijk maken.
Thread-safety en concurrentie
Concurrentie verandert het dreigingsbeeld: geheugen dat in één thread “veilig” is, kan gevaarlijk worden wanneer een andere thread het vrijgeeft of wijzigt. Modellen die regels afdwingen rond delen (of expliciete synchronisatie vereisen) verkleinen de kans op racecondities die leiden tot corrupte staat, datalekken en intermitterende crashes.
Defense in depth blijft belangrijk
Geen enkel geheugenmodel neemt alle risico’s weg—logische fouten (auth-fouten, onveilige defaults, gebrekkige validatie) blijven bestaan. Sterke teams leggen meerdere lagen bescherming in: sanitizers in testen, veilige standaardbibliotheken, strikte code reviews, fuzzing en strikte grenzen rond unsafe/FFI-code. Geheugenveiligheid vermindert het aanvalsoppervlak aanzienlijk, maar is geen garantie.
Geheugenproblemen zijn makkelijker te repareren als je ze dicht bij de invoer van de verandering vangt. Belangrijk is eerst meten, dan het probleem afbakenen met het juiste gereedschap.
Profiling basics: wat te meten (en wanneer)
Begin met bepalen of je achter snelheid of geheugenstijging aanzit.
Voor performance meet je wall-clock tijd, CPU-tijd, allocatiesnelheid (bytes/sec) en tijd besteed aan GC of allocator. Voor geheugen volg je piek RSS, steady-state RSS en objectaantallen over tijd. Draai dezelfde workload met consistente inputs; kleine variaties kunnen allocatie-churn verbergen.
- CPU + allocatie-profilers: tonen waar tijd wordt besteed en welke paden de meeste allocaties doen. Goed om “dood door duizend kleine allocaties” te vinden.
- Leak detectors: rapporteren geheugen dat is aangemaakt maar nooit vrijgegeven of nooit onbereikbaar is geworden voor GC.
- Sanitizers: vangen use-after-free, buffer overflows, data races en undefined behavior vroeg in tests.
- Fuzzing: voert onverwachte inputs uit om crashes en geheugenbeschadiging op te roepen die normale tests missen.
Vind allocatie-hotspots en reduceer churn
Veelvoorkomende signalen: een enkele request allocateert veel meer dan verwacht, of geheugen groeit met verkeer terwijl throughput stabiel blijft. Fixes omvatten vaak buffers hergebruiken, arena/pool-allocatie inzetten voor kortlevende objecten, en objectgrafen vereenvoudigen zodat minder objecten over cycli blijven bestaan.
Praktische workflow voor lekken en crashes
Reproduceer met minimale input, zet de strengste runtime-checks aan (sanitizers/GC-verificatie), en capture:
- een profiel (CPU + allocaties), 2) een heap-snapshot of leakrapport, 3) een stacktrace bij de fout.
Behandel de eerste fix als een experiment; voer opnieuw met metingen uit om te bevestigen dat de wijziging allocaties heeft verminderd of geheugenstabiliteit heeft verbeterd—zonder het probleem ergens anders te verplaatsen. Voor meer interpretatie van afwegingen, zie de sectie over performance-afwegingen rond throughput, latency en geheugen.