09 sep 2025·8 min
Hoe je een SaaS-statuswebsite maakt met incidenthistorie
Leer hoe je een SaaS-statuspagina met incidenthistorie, duidelijke berichten en abonnementen plant, bouwt en publiceert zodat klanten tijdens storingen geïnformeerd blijven.
Leer hoe je een SaaS-statuspagina met incidenthistorie, duidelijke berichten en abonnementen plant, bouwt en publiceert zodat klanten tijdens storingen geïnformeerd blijven.
Een SaaS-statuspagina is een publieke (of alleen-klant) website die laat zien of je product op dit moment werkt—en wat je doet als dat niet het geval is. Het wordt de enkele bron van waarheid tijdens incidenten, los van social media, supporttickets en geruchten.
Het helpt meer mensen dan je misschien verwacht:
Een goede service status-website bevat meestal drie gerelateerde (maar verschillende) lagen:
Het doel is helderheid: realtime status beantwoordt “Kan ik het product gebruiken?” terwijl geschiedenis antwoordt op “Hoe vaak gebeurt dit?” en postmortems antwoord geven op “Waarom gebeurde dit en wat is er veranderd?”
Een statuspagina werkt wanneer updates snel, in gewone taal en eerlijk over impact zijn. Je hoeft geen perfecte diagnose te hebben om te communiceren. Je hebt wel tijdstempels, scope (wie is getroffen) en het tijdstip van de volgende update nodig.
Je zult erop vertrouwen tijdens storingen, vertraagde prestaties (trage logins, vertraagde webhooks) en gepland onderhoud dat korte onderbrekingen of risico kan veroorzaken.
Zodra je de statuspagina behandelt als een productoppervlak (niet als een eenmalige ops-pagina), wordt de rest van de inrichting veel eenvoudiger: je kunt eigenaren definiëren, templates bouwen en monitoring koppelen zonder het wiel bij elk incident opnieuw uit te vinden.
Voordat je een tool kiest of een layout ontwerpt, bepaal wat je statuspagina moet doen. Een duidelijk doel en een duidelijke eigenaar zorgen dat statuspagina's nuttig blijven tijdens een incident—wanneer iedereen druk is en informatie rommelig.
De meeste SaaS-teams maken een statuspagina met drie praktische uitkomsten in gedachten:
Schrijf 2–3 meetbare signalen op die je na lancering kunt volgen: minder dubbele tickets tijdens storingen, snellere tijd-tot-eerste-update, of meer klanten die zich abonneren.
Je primaire lezer is meestal een niet-technische klant die wil weten:
Dat betekent dat je jargon moet minimaliseren. Geef bij voorkeur “Sommige klanten kunnen niet inloggen” in plaats van “Verhoogde 5xx-rates op auth.” Als je technische details moet delen, houd die dan als een korte secundaire zin.
Kies een toon die je onder druk kunt volhouden: kalm, feitelijk en transparant. Beslis van tevoren:
Maak eigenaarschap expliciet: de statuspagina mag niet “ieders taak” zijn, anders wordt het ieders taak tot niemand’s taak.
Je hebt twee gebruikelijke opties:
Als je hoofdapp kan uitvallen, is een losstaande statussite meestal veiliger. Je kunt er nog steeds prominent naar linken vanuit je app en helpcentrum (bijvoorbeeld /help).
Een statuspagina is alleen zo nuttig als de “kaart” erachter. Voordat je kleuren kiest of copy schrijft, bepaal waar je eigenlijk over rapporteert. Het doel is te weerspiegelen hoe klanten je product ervaren—niet hoe je organisatie is georganiseerd.
Maak een lijst van de onderdelen die een klant zou noemen als hij zegt “het werkt niet.” Voor veel SaaS-producten is een praktisch startsetje:
Als je meerdere regio's of niveaus aanbiedt, leg dat ook vast (bijv. “API – US” en “API – EU”). Houd namen klantvriendelijk: “Login” is duidelijker dan “IdP Gateway.”
Kies een groepering die aansluit bij hoe klanten over je service denken:
Probeer een eindeloze lijst te vermijden. Als je tientallen integraties hebt, overweeg één oudercomponent (“Integraties”) plus een paar impactvolle kinderen (bijv. “Salesforce,” “Webhooks”).
Een eenvoudig, consistent model voorkomt verwarring tijdens incidenten. Veelvoorkomende niveaus zijn:
Schrijf interne criteria voor elk niveau (ook als je die niet publiceert). Bijvoorbeeld: “Partial Outage = één regio uitgevallen” of “Degraded = p95-latency boven X gedurende Y minuten.” Consistentie bouwt vertrouwen.
De meeste storingen omvatten derde partijen: cloudhosting, e-mailbezorging, betalingsverwerkers of identity providers. Documenteer deze afhankelijkheden zodat je incident-updates accuraat zijn.
Of je ze publiekelijk toont hangt af van je publiek. Als klanten direct getroffen kunnen worden (bijv. betalingen), kan het tonen van een afhankelijkheidscomponent handig zijn. Als het ruis toevoegt of een schuldspel uitlokt, houd afhankelijkheden intern maar verwijs ernaar in updates wanneer relevant (bijv. “We onderzoeken verhoogde fouten bij onze betalingsprovider”).
Zodra je dit componentmodel hebt, wordt de rest van de statuspagina-inrichting veel gemakkelijker: elk incident krijgt vanaf het begin een duidelijke “waar” (component) en “hoe ernstig” (status).
Een statuspagina is het meest nuttig wanneer het de vragen van klanten binnen seconden beantwoordt. Mensen arriveren vaak gestrest en willen duidelijkheid—niet veel navigatie.
Prioriteer de essentie bovenaan:
Schrijf in gewone taal. “Verhoogde foutpercentages op API-aanvragen” is duidelijker dan “Partial outage in upstream dependency.” Als je technische termen gebruikt, voeg dan een korte vertaling toe (“Sommige aanvragen kunnen mislukken of time-outs geven”).
Een betrouwbaar patroon is:
Voor de componentlijst, houd labels klantgericht. Als je interne service “k8s-cluster-2” heet, hebben klanten waarschijnlijk “API” of “Background Jobs” nodig.
Maak de pagina leesbaar onder druk:
Plaats een kleine set links bovenaan (header of net onder de banner):
Het doel is vertrouwen: klanten moeten direct begrijpen wat er gebeurt, wat het beïnvloedt en wanneer ze weer van je horen.
Wanneer een incident ontstaat, organiseert je team diagnose, mitigatie en klantvragen tegelijk. Templates halen het giswerk weg zodat updates consistent, duidelijk en snel blijven—vooral wanneer verschillende mensen posten.
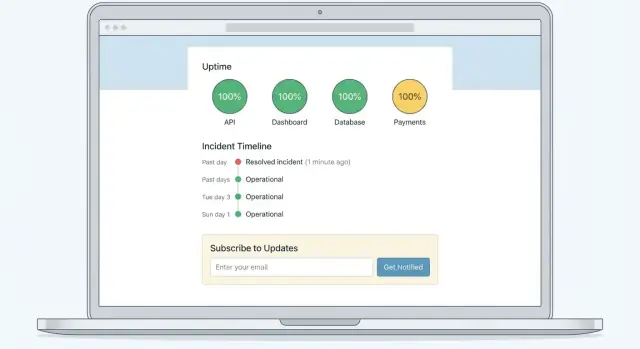
Een goede update begint elke keer met dezelfde kernfeiten. Minimaal standaardiseer je deze velden zodat klanten snel begrijpen wat er aan de hand is:
Als je een incidenthistorie-pagina publiceert, maakt consistentie deze incidenten makkelijk te scannen en te vergelijken.
Streef naar korte updates die elke keer dezelfde vragen van klanten beantwoorden. Hier is een praktische template die je in je statuspagetool kunt kopiëren:
Title: Kort, specifiek samenvattend (bijv. “API-fouten voor EU-regio”)
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: Wat gebruikers zien (fouten, time-outs, vertraagde prestaties) en wie getroffen is
What we know: Eén zin over de oorzaak als die bevestigd is (vermijd speculatie)
What we’re doing: Concreet acties (rollback, schalen, vendor-escalatie)
Next update: Tijd waarop je opnieuw post
Updates:
Klanten willen niet alleen informatie—they willen voorspelbaarheid.
Gepland onderhoud moet rustig en gestructureerd aanvoelen. Standaardiseer onderhoudsposten met:
Houd onderhoudstaal specifiek (wat verandert, wat gebruikers kunnen merken) en vermijd overbeloftes—klanten waarderen nauwkeurigheid boven optimisme.
Een incidenthistorie-pagina is meer dan een log—het is een manier voor klanten (en je eigen team) om snel te begrijpen hoe vaak issues gebeuren, welke typen problemen terugkeren en hoe je reageert.
Een duidelijke geschiedenis bouwt vertrouwen door transparantie. Het creëert ook zicht op trends: als je terugkerende “API-latency” incidenten iedere paar weken ziet, is dat een signaal om in performance te investeren (en om je post-incident reviewproces te prioriteren). Consistente rapportage kan na verloop van tijd supporttickets verminderen omdat klanten zelf antwoorden kunnen vinden.
Kies een retentiewindow dat past bij klantverwachtingen en productrijpheid.
Wat je ook kiest, vermeld het duidelijk (bijv. “Incidenthistorie wordt 12 maanden bewaard”).
Consistentie maakt scannen makkelijk. Gebruik een voorspelbaar naamformaat zoals:
YYYY-MM-DD — Korte samenvatting (bijv. “2025-10-14 — Vertraagde e-mailbezorging”)
Toon voor elk incident ten minste:
Als je postmortems publiceert, link dan vanaf de incidentdetailpagina naar de uitwerking (bijv. “Lees de postmortem” verwijzend naar /blog/postmortems/2025-10-14-email-delays). Dit houdt de tijdlijn schoon terwijl het toch detail biedt voor klanten die meer willen weten.
Een statuspagina is nuttig wanneer klanten eraan denken hem te bekijken. Abonnementen keren dat om: klanten krijgen automatisch updates zonder de pagina te verversen of support te mailen voor bevestiging.
De meeste teams verwachten ten minste een paar opties:
Als je meerdere kanalen ondersteunt, houd de aanmeldflow consistent zodat klanten niet het gevoel hebben dat ze zich op vier verschillende manieren aanmelden.
Abonnementen moeten altijd opt-in zijn. Wees expliciet over wat mensen ontvangen voordat ze bevestigen—vooral bij SMS.
Geef abonnees controle over:
Deze voorkeuren verminderen alert fatigue en houden je notificaties betrouwbaar. Als je nog geen component-level subscriptions hebt, begin dan met “Alle updates” en voeg filtering later toe.
Tijdens een incident stijgt het aantal berichten en derde-partijproviders kunnen throttlen. Controleer:
Het is de moeite waard om een geplande test (bijv. elk kwartaal) te draaien om te verzekeren dat subscriptions nog werken zoals verwacht.
Voeg een opvallende callout toe op de statushomepage—boven de vouw indien mogelijk—zodat klanten zich kunnen abonneren voordat het volgende incident plaatsvindt. Zorg dat het zichtbaar is op mobiel en voeg het toe op plaatsen waar klanten hulp zoeken (zoals een link vanuit je supportportaal of /help center).
De keuze hoe je de statuspagina bouwt gaat minder over “kunnen we het bouwen?” en meer over wat je wilt optimaliseren: snelheid van lancering, betrouwbaarheid tijdens incidenten en doorlopende onderhoudsinspanning.
Een hosted tool is meestal de snelste weg. Je krijgt een kant-en-klare statuspagina, abonnementen, incidenttijdlijnen en vaak integraties met gangbare monitoringsystemen.
Waar je op moet letten bij een hosted tool:
DIY kan een goede keuze zijn als je volledige controle wilt over design, dataretentie en hoe incidenthistorie wordt gepresenteerd. De afweging is dat je zelf verantwoordelijk bent voor betrouwbaarheid en operatie.
Een praktisch DIY-architectuurvoorstel:
Als je zelf host, plan dan falingsscenario's: wat gebeurt er als je primaire database onbeschikbaar is, of je deploypipeline down is? Veel teams houden de statuspagina op aparte infrastructuur (of zelfs een andere provider) dan het hoofdproduct.
Als je de controle van DIY wilt zonder alles opnieuw te bouwen, kan een vibe-coding platform zoals Koder.ai je helpen snel een aangepaste statussite op te zetten (web-UI plus een kleine incident-API) vanuit een chat-gedreven spec. Dat is vooral nuttig voor teams die maatwerk componentmodellen, aangepaste incidenthistorie-UX of interne adminworkflows willen—terwijl ze toch de broncode kunnen exporteren, deployen en snel itereren.
Hosted tools hebben voorspelbare maandprijzen; DIY kost engineeringtijd, hosting/CDN-kosten en doorlopend onderhoud. Als je opties vergelijkt, schets dan de verwachte maandelijkse kosten en de interne tijd die je nodig hebt—en check dat tegen je budget (zie /pricing).
Een statuspagina is alleen nuttig als deze de realiteit snel weerspiegelt. De makkelijkste manier is systemen die problemen detecteren (monitoring) te verbinden met systemen die je respons coördineren (incidentworkflow), zodat updates consistent en tijdig zijn.
De meeste teams combineren drie datastromen:
Een praktische regel: monitoring detecteert; incidentworkflow coördineert; de statuspagina communiceert.
Automatisering kan minuten besparen wanneer het ertoe doet:
Houd het eerste publieke bericht conservatief. “We onderzoeken verhoogde fouten” is veiliger dan “Storing bevestigd” als je nog aan het valideren bent.
Volledig geautomatiseerde berichtgeving kan tegenwerken:
Gebruik automatisering om te draften en updates voor te stellen, maar vereis een menselijke goedkeuring voor klantgerichte formuleringen—vooral voor Identified, Mitigated en Resolved staten.
Behandel de statuspagina als een klantgericht logboek. Zorg dat je kunt beantwoorden:
Deze audittrail helpt bij post-incident reviews, vermindert verwarring tijdens overdrachten en bouwt vertrouwen als klanten verduidelijking vragen.
Een statuspagina helpt alleen als hij bereikbaar is wanneer je product dat niet is. De meest voorkomende fout is de statussite op dezelfde infrastructuur als de app bouwen—zodat bij uitval van de app ook de statuspagina verdwijnt, en klanten zonder bron van waarheid achterblijven.
Host de statuspagina bij voorkeur op een andere provider dan je productieapp (of in ieder geval in een andere regio/account). Het doel is blast-radius scheiding: een storing in je appplatform mag niet ook je incidentcommunicatie platleggen.
Overweeg ook DNS te scheiden. Als de DNS van je hoofddomein in dezelfde plaats wordt beheerd als je app edge/CDN, kan een DNS- of certificaatprobleem beide blokkeren. Veel teams gebruiken een dedicated subdomein (bijvoorbeeld status.yourcompany.com) met DNS onafhankelijk gehost.
Houd assets lichtgewicht: minimale JavaScript, gecomprimeerde CSS en geen afhankelijkheden die je app-API's nodig hebben om te renderen. Zet een CDN voor de statuspagina en schakel caching in voor statische bronnen zodat hij ook bij zware traffic laadt tijdens incidenten.
Een praktisch vangnet is een fallback statische modus:
Klanten hoeven niet in te loggen om servicestatus te zien. Houd de statuspagina openbaar, maar zet admin/editor-tools achter authenticatie (SSO als je dat hebt), met sterke toegangscontrole en auditlogs.
Test ten slotte faalscenario's: blokkeer tijdelijk je app-origin in een stagingomgeving en bevestig dat de statuspagina nog steeds oplost, snel laadt en bijgewerkt kan worden wanneer je hem het meest nodig hebt.
Een statuspagina bouwt alleen vertrouwen als hij consistent wordt bijgewerkt tijdens echte incidenten. Die consistentie gebeurt niet vanzelf—je hebt duidelijk eigenaarschap, simpele regels en een voorspelbare cadans nodig.
Houd het kernteam klein en expliciet:
Als je een klein team bent, kan één persoon twee rollen combineren—maar besluit dat van tevoren. Documenteer roloverdrachten en escalatiepaden in je on-call handbook (zie /docs/on-call).
Wanneer een alert verandert in een klantimpacterend incident, volg dan een herhaalbare flow:
Een praktische regel: plaats de eerste update binnen 10–15 minuten, daarna elke 30–60 minuten zolang impact aanhoudt—zelfs als het bericht is “Geen verandering, nog steeds aan het onderzoeken.”
Binnen 1–3 werkdagen, voer een lichte post-incident review uit:
Werk daarna de incidentvermelding bij met de definitieve samenvatting zodat je incidenthistorie bruikbaar blijft—niet alleen een log van “resolved”-berichten.
Een statuspagina is alleen nuttig als hij makkelijk te vinden is, te vertrouwen is en consequent wordt bijgewerkt. Voordat je hem aankondigt, loop een korte “production-ready” controle door—en zet daarna een lichtgewicht cadans op om hem in de loop van de tijd te verbeteren.
Copy en structuur
Branding en vertrouwen
Toegang en permissies
Test de volledige workflow
Maak het bekend
Als je je eigen statussite bouwt, voer dezelfde launch-checklist eerst in een stagingomgeving uit. Tools zoals Koder.ai kunnen deze iteratielus versnellen door de web-UI, adminschermen en backend-endpoints vanuit één spec te genereren—en je vervolgens de code te laten exporteren en deployen waar nodig.
Volg een paar eenvoudige uitkomsten en evalueer ze maandelijks:
Houd een basis-taxonomie bij zodat geschiedenis actiegericht wordt:
In de loop der tijd compenseren kleine verbeteringen—helderdere formuleringen, snellere updates, betere categorisatie—tot minder onderbrekingen, minder tickets en meer klantvertrouwen.
Een SaaS-statuspagina is een speciale pagina die in één canonieke plek de huidige status van de dienst en incident-updates toont. Het is belangrijk omdat het de vraag “Is het down?” bij de support vermindert, verwachtingen tijdens storingen stelt en vertrouwen opbouwt met duidelijke, tijdgestempelde communicatie.
Realtime status beantwoordt “Kan ik het product nu gebruiken?” met component-niveaustatussen.
Incidenthistorie beantwoordt “Hoe vaak gebeurt dit?” met een tijdlijn van eerdere incidenten en onderhoud.
Postmortems beantwoorden “Waarom gebeurde het en wat is er veranderd?” met de oorzaakanalyse en preventiestappen (vaak gelinkt vanaf de incidentvermelding).
Begin met 2–3 meetbare uitkomsten:
Schrijf deze doelen op en evalueer ze maandelijks zodat de pagina niet veroudert.
Wijs een expliciete eigenaar en een back-up aan (vaak de on-call rotatie). Veel teams gebruiken:
Definieer ook regels van tevoren: wie mag publiceren, of goedkeuring vereist is, en de minimale update-cadans (bijvoorbeeld elke 30–60 minuten tijdens grote incidenten).
Kies componenten op basis van hoe klanten problemen beschrijven, niet op basis van interne servicenames. Veelvoorkomende componenten zijn:
Als betrouwbaarheid per regio verschilt, splits dan per regio (bijvoorbeeld “API – US” en “API – EU”).
Gebruik een klein, consistent setje niveaus en documenteer interne criteria voor elk:
Consistentie is belangrijker dan perfecte precisie. Klanten moeten door herhaald gebruik leren wat elk niveau betekent.
Een praktische incident-update moet altijd bevatten:
Ook zonder root cause kun je scope, impact en wat je vervolgens doet communiceren.
Plaats snel een eerste “Investigating”-update (vaak binnen 10–15 minuten na bevestigd impact). Daarna:
Als je de cadence niet haalt, plaats dan een korte notitie die de verwachting bijstelt in plaats van stil te blijven.
Hosted tools optimaliseren voor snelheid en betrouwbaarheid (blijven vaak online als je app down is) en bevatten meestal subscriptions en integraties.
DIY geeft volledige controle maar je moet ontwerpen voor veerkracht:
Bied de kanalen aan die klanten al gebruiken (meestal email en SMS, plus Slack/Teams of RSS). Houd subscriptions opt-in en verduidelijk:
Test bezorgbaarheid en rate limits periodiek zodat notificaties blijven werken wanneer het verkeer spike tijdens een incident.