10 aug 2025·8 min
Hoe LLMs omgaan met bedrijfsregels en workflow-redenering
Lees hoe LLMs bedrijfsregels interpreteren, workflowstate bijhouden en beslissingen verifiëren met prompts, tools, tests en menselijke review — niet alleen met code.
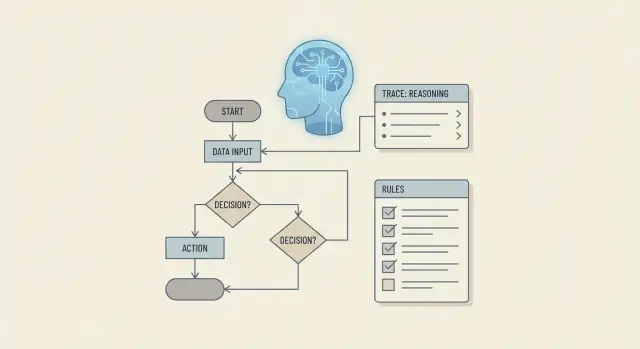
Waarom redeneren over bedrijfsregels meer is dan codegeneratie
Als mensen vragen of een LLM kan “redeneren over bedrijfsregels”, bedoelen ze meestal iets veeleisenders dan “kan het een if/else-statement schrijven.” Redeneren over bedrijfsregels is het vermogen om beleid consequent toe te passen, beslissingen uit te leggen, uitzonderingen af te handelen en afgestemd te blijven op de huidige workflowstap—vooral wanneer invoer onvolledig, rommelig of veranderlijk is.
Redeneren versus code uitgeven
Codegeneratie draait grotendeels om het produceren van geldige syntaxis in een doeltaal. Regelredenering gaat over het behouden van intentie.
Een model kan perfect geldige code genereren die toch het verkeerde zakelijke resultaat oplevert omdat:
- De beleidstekst ambigu is (“recente klant”, “hoog risico”, “goedgekeurde documenten”).
- Regels conflicteren en de prioriteit onduidelijk is.
- Randgevallen niet zijn vermeld (gedeeltelijke terugbetalingen, duplicaten, weekenden/feestdagen).
- Workflowstate bepaalt wat er vervolgens moet gebeuren (aanmelding versus beoordeling versus definitieve goedkeuring).
Met andere woorden: correctheid is niet “compileert het?” maar “komt het overeen met wat het bedrijf elke keer zou beslissen, en kunnen we het bewijzen?”
Wat je van LLMs mag verwachten
LLM's kunnen helpen beleid om te zetten in gestructureerde regels, beslissingstrajecten voorstellen en verklaringen voor mensen opstellen. Maar ze weten niet automatisch welke regel gezaghebbend is, welke gegevensbron vertrouwd is of in welke stap de zaak zich bevindt. Zonder beperkingen kunnen ze vol vertrouwen een plausibel antwoord kiezen in plaats van het geregelde antwoord.
Het doel is dus niet om “het model te laten beslissen”, maar om het structuur en controles te geven zodat het betrouwbaar kan assisteren.
Wat de rest van dit artikel zal doen
Een praktische aanpak ziet eruit als een pijplijn:
- Zet beleidstekst om naar bruikbare regelrepresentaties.
- Houd workflowstate bij zodat beslissingen consistent blijven over stappen heen.
- Gebruik promptpatronen om prioriteiten, uitzonderingen en verklaringen af te dwingen.
- Onderbouw beslissingen met tools en retrieval (alleen goedgekeurde gegevens gebruiken).
- Beperk uitvoer met schema's om ambiguïteit te verminderen.
- Valideer, test en monitor zodat fouten worden opgemerkt vóór uitrol.
Dat is het verschil tussen een slim codefragment en een systeem dat echte bedrijfsbeslissingen kan ondersteunen.
Bedrijfsregels en workflows: een korte, begrijpelijke opfrisser
Voordat we bespreken hoe een LLM “redeneert”, helpt het om twee dingen te scheiden die teams vaak samenvoegen: bedrijfsregels en workflows.
Wat zijn bedrijfsregels?
Bedrijfsregels zijn de beslissingsuitspraken die jouw organisatie consequent wil handhaven. Ze verschijnen als beleid en logica zoals:
- Geschiktheid: Wie komt in aanmerking voor een voordeel, plan of functie?
- Prijzen: Welke korting geldt en wanneer?
- Goedkeuringen: Wanneer is managerreview vereist?
- Naleving: Wat moet worden gelogd, geredigeerd of geblokkeerd?
Regels worden meestal geformuleerd als “ALS X, DAN Y” (soms met uitzonderingen) en moeten een duidelijk resultaat opleveren: goedkeuren/afwijzen, prijs A/prijs B, meer info vragen, enzovoort.
Wat zijn workflows?
Een workflow is het proces dat werk van begin tot eind verplaatst. Het gaat minder over wat is toegestaan en meer over wat gebeurt er vervolgens. Workflows bevatten vaak:
- Staten: ingediend → in beoordeling → goedgekeurd/afgewezen → voltooid
- Stappen en overdrachten: klantenservice → financiën → klant
- Tijdgebaseerde gebeurtenissen: herinneringen, SLA's, automatische annulering na 14 dagen
- Artefacten: formulieren, bijlagen, redencodes, auditnotities
Een klein voorbeeld: restitutieaanvragen
Stel je een restitutieaanvraag voor.
Regelvoorbeeld: “Restituties zijn toegestaan binnen 30 dagen na aankoop. Uitzondering: digitale downloads zijn niet-restitueerbaar zodra ze zijn geopend. Uitzondering: chargebacks moeten worden geëscaleerd.”
Workflowvoorbeeld:
- Klant dient verzoek in (staat: ingediend).
- Systeem controleert aankoopdatum en producttype (staat: in beoordeling).
- Als in aanmerking, voer restitutie uit en informeer klant (staat: voltooid).
- Bij chargeback, routeer naar financiën voor onderzoek (staat: geëscaleerd).
Waarom regels lastiger zijn dan ze lijken
Regels worden complex wanneer ze conflicteren (“VIP-klanten krijgen altijd restitutie” vs. “digitale downloads nooit”), afhankelijk zijn van ontbrekende context (is de download geopend?) of verborgen randgevallen hebben (bundels, gedeeltelijke terugbetalingen, regionale wetten). Workflows voegen nog een laag toe: beslissingen moeten consistent blijven met de huidige staat, eerdere acties en deadlines.
Hoe LLMs “redeneren”: patroonmatching met nuttige structuur
LLM's “begrijpen” bedrijfsregels niet zoals een mens dat doet. Ze genereren de volgende waarschijnlijke woorden op basis van patronen die geleerd zijn uit grote hoeveelheden tekst. Daarom kan een LLM overtuigend klinken, ook wanneer het raadt—of ontbrekende details invult die niet zijn gegeven.
Die beperking is belangrijk voor workflows en beslissingslogica. Een model kan een regel toepassen die goed klinkt (“medewerkers hebben altijd managergoedkeuring nodig”) terwijl het echte beleid uitzonderingen heeft (“alleen boven $500” of “alleen voor aannemers”). Dit is een veelvoorkomende faalmodus: vol vertrouwen maar onjuist toepassen van regels.
Waarom ze toch nuttig zijn voor bedrijfsregels
Zelfs zonder echt “begrip” kunnen LLMs helpen wanneer je ze als gestructureerde assistent inzet:
- Beleidsstukken samenvatten naar helderere taal voor review
- Rommelige tekst mappen naar consistente velden (wie, wat, drempel, uitzondering, ingangsdatum)
- Een voorgestelde beslissing controleren aan de hand van vermelde regels (“welke clausule ondersteunt dit?”)
Belangrijk is het model in een positie te plaatsen waarin het niet makkelijk afdwaalt in improvisatie.
Beperk het model zodat het niet dwaalt
Een praktische manier om ambiguïteit te verminderen is geconstrueerde uitvoer: laat het LLM antwoorden in een vast schema of sjabloon (bijv. JSON met specifieke velden, of een tabel met verplichte kolommen). Wanneer het model rule_id, conditions, exceptions en decision moet invullen, wordt het makkelijker om hiaten te zien en automatisch te valideren.
Geconstrueerde formaten maken ook duidelijker wanneer het model iets niet weet. Als een verplicht veld ontbreekt, kun je een vervolgvraag forceren in plaats van een onzekere uitkomst te accepteren.
De conclusie: LLM-“redenering” is het beste te zien als patroongebaseerde generatie gestuurd door structuur—nuttig voor ordenen en kruiscontrole van regels, maar riskant als je het als onfeilbare beslisser ziet.
Rommelige beleidstekst omzetten naar bruikbare regelrepresentaties
Beleidsdocumenten zijn geschreven voor mensen: ze mengen doelen, uitzonderingen en “gezond verstand” in dezelfde alinea. Een LLM kan die tekst samenvatten, maar het volgt regels betrouwbaarder wanneer je het beleid omzet in expliciete, testbare inputs.
Hoe “bruikbare” regels eruitzien
Goede regelrepresentaties hebben twee kenmerken: ze zijn eenduidig en ze zijn controleerbaar.
Schrijf regels als uitspraken die je kunt testen:
- IF/THEN voor beslissingen (geschiktheid, routering, goedkeuringen)
- MUST / MUST NOT voor harde beperkingen
- MAY voor toegestane opties (vaak heeft dit een beslisser nodig)
Regels kunnen aan het model worden aangeboden in verschillende vormen:
- Korte bullets in gewone taal (snelste, nog steeds gestructureerd)
- Een tabel (goed voor drempelgebaseerd beleid)
- YAML/JSON (beste wanneer je ook geconfigureerde uitvoer en geautomatiseerde validatie wilt)
Omgaan met conflicten en prioriteit
Echt beleid conflicteert. Wanneer twee regels elkaar tegenspreken, heeft het model een duidelijk prioriteitsschema nodig. Veelgebruikte benaderingen:
- Specifiek verslaat algemeen (een uitzondering overschrijft de standaard)
- Hoger gezag wint (juridisch/naleving boven teamvoorkeur)
- Nieuwste wint (nieuwere beleidsversie overschrijft oudere)
- Explíciete prioriteitsnummers (meest betrouwbaar)
Stel de conflictregel direct vast, of codeer hem (bijv. priority: 100). Anders kan het LLM de regels “gemiddeld” toepassen.
Voorbeeld: een alinea omzetten naar een regelslijst
Oorspronkelijke beleidstekst:
“Restituties zijn beschikbaar binnen 30 dagen voor jaarabonnementen. Maandabonnementen zijn niet-restitueerbaar na 7 dagen. Als het account fraude of buitensporige chargebacks laat zien, geef dan geen restitutie. Enterprise-klanten hebben goedkeuring van Financiën nodig voor restituties boven $5.000.”
Gestructureerde regels (YAML):
rules:
- id: R1
statement: "IF plan_type = annual AND days_since_purchase <= 30 THEN refund MAY be issued"
priority: 10
- id: R2
statement: "IF plan_type = monthly AND days_since_purchase > 7 THEN refund MUST NOT be issued"
priority: 20
- id: R3
statement: "IF fraud_flag = true OR chargeback_rate = excessive THEN refund MUST NOT be issued"
priority: 100
- id: R4
statement: "IF customer_tier = enterprise AND refund_amount > 5000 THEN finance_approval MUST be obtained"
priority: 50
conflict_resolution: "Higher priority wins; MUST NOT overrides MAY"
Nu raadt het model niet meer wat belangrijk is—het past een regelset toe die je kunt reviewen, testen en versiebeheer op toepassen.
Workflowstate bijhouden zodat het model consistent blijft
Een workflow is niet alleen een set regels; het is een reeks gebeurtenissen waarbij eerdere stappen bepalen wat er daarna moet gebeuren. Die “geheugen” is state: de actuele feiten over de zaak (wie wat heeft ingediend, wat al is goedgekeurd, wat wacht en welke deadlines gelden). Als je state niet expliciet bijhoudt, breken workflows op voorspelbare manieren—dubbele goedkeuringen, verplichte controles overslaan, beslissingen terugdraaien of de verkeerde regel toepassen omdat het model niet weet wat eerder gebeurde.
Wat “state” in gewone taal betekent
Zie state als het scorebord van de workflow. Het beantwoordt: Waar staan we nu? Wat is gedaan? Wat mag er nu gebeuren? Voor een LLM voorkomt een duidelijke statesamenvatting dat het eerdere stappen opnieuw bespreekt of gaat raden.
Hoe je state aan het model doorgeeft
Als je het model aanroept, voeg dan een compacte state-payload toe naast het gebruikersverzoek. Nuttige velden zijn:
- Stapnaam en status (bijv.
manager_review: approved,finance_review: pending) - Stabiele ID's (request ID, employee ID) zodat het model zaken niet door elkaar haalt
- Timestamps (ingediend op, laatst bijgewerkt) om “nieuwste wint”-situaties op te lossen
- Flags (belemming voor beleid, ontbrekende documenten, escalatie vereist)
Vermijd het dumpen van elk historisch bericht. Geef in plaats daarvan de huidige state plus een korte audittrail van sleuteltransities.
Houd één enkele bron van waarheid
Behandel de workflow-engine (database, ticketsysteem of orkestrator) als de single source of truth. Het LLM moet die state lezen en het volgende actievoorstel doen, maar het systeem moet de autoriteit zijn die transities vastlegt. Dit vermindert “state drift”, waarbij het verhaal van het model afwijkt van de werkelijkheid.
Voorbeeld: snapshot van een goedkeuringsflow
{
"request_id": "TRV-10482",
"workflow": "travel_reimbursement_v3",
"current_step": "finance_review",
"step_status": {
"submission": "complete",
"manager_review": "approved",
"finance_review": "pending",
"payment": "not_started"
},
"actors": {
"employee_id": "E-2291",
"manager_id": "M-104",
"finance_queue": "FIN-AP"
},
"amount": 842.15,
"currency": "USD",
"submitted_at": "2025-12-12T14:03:22Z",
"last_state_update": "2025-12-13T09:18:05Z",
"flags": {
"receipt_missing": false,
"policy_exception_requested": true,
"needs_escalation": false
}
}
Met zo'n snapshot blijft het model consistent: het zal niet opnieuw om managergoedkeuring vragen, het richt zich op financiële controles en kan beslissingen uitleggen in termen van de huidige flags en stap.
Promptpatronen die regeltoepassing en beslissingen verbeteren
Snel uitrollen en itereren
Lever je workflow-assistent uit en itereren met hosting en deployment op één plek.
Een goede prompt vraagt niet alleen om een antwoord—het stelt verwachtingen over hoe het model je regels moet toepassen en hoe het het resultaat moet rapporteren. Het doel is herhaalbare beslissingen, niet bewonderenswaardige proza.
1) Rolprompting: geef een taak, geen sfeer
Geef het model een concrete rol gekoppeld aan je proces. Drie rollen werken goed samen:
- Policy-analist: interpreteert de regeltekst en mapt die naar de huidige zaak.
- Validator: controleert de beslissing tegen vereisten en markeert ontbrekende invoer.
- Agent: neemt de volgende workflowactie (maak een ticket, stel een e-mail op, zet een status).
Je kunt deze sequentieel laten lopen (“analist → validator → agent”) of alle drie outputs in één gestructureerd antwoord vragen.
2) Stappen-voor-stap instructies (zonder te vragen om verborgen redenering)
Vraag niet om “chain-of-thought”, maar specificeer zichtbare stappen en artefacten:
- Identificeer relevante regels.
- Extraheer benodigde inputs uit de zaak.
- Pas regels toe in prioriteitsvolgorde.
- Produceer een beslissing en de volgende stap.
Dit houdt het model georganiseerd en gericht op leverbare resultaten: welke regels zijn gebruikt en welke uitkomst volgt.
3) Vraag om een gestructureerde rationale: regel-ID's + bewijs
Vrije-formaat verklaringen dwalen af. Eis een compacte rationale die naar bronnen verwijst:
- Gebruikte regel-ID's (bijv. R-12, R-18)
- Bewijs (geciteerde fragmenten uit beleidsdocumenten en specifieke casusvelden)
- Aannames (alleen als een invoer ontbreekt)
Dat versnelt reviews en helpt bij het debuggen van meningsverschillen.
4) Checklist-promptpatroon: inputs, beslissing, uitzonderingen, volgende stap
Gebruik elke keer een vast sjabloon:
- Ontvangen inputs: …
- Ontbrekende inputs: …
- Beslissing: approve/deny/needs-review
- Regelreferenties: [R-…]
- Overwogen uitzonderingen: …
- Volgende workflowstap: update status / request info / escalate
Het sjabloon vermindert ambiguïteit en dwingt het model om hiaten bloot te leggen voordat het een onjuiste actie uitvoert.
Tools en retrieval gebruiken om beslissingen op echte data te baseren
Een LLM kan een overtuigend antwoord schrijven, zelfs als belangrijke feiten ontbreken. Dat is bruikbaar voor concepten, maar riskant voor bedrijfsregels. Als het model moet raden naar de status van een account, het klantniveau, een regionale belasting of of een limiet al is bereikt, krijg je voluit foute resultaten.
Tools lossen dat op door van “redeneren” een twee-staps proces te maken: haal eerst bewijs op, beslis daarna.
Veelvoorkomende tools die het model eerlijk houden
In systemen met veel regels en workflows doen een paar eenvoudige tools het meeste werk:
- Database lookup (klantprofiel, accountstatus, entitlements, gebruikstotalen)
- Policy-/regelstore (goedgekeurde regeltekst, versiebeheer, uitzonderingslijsten)
- Rekenmodule (kosten, proratering, belastingen, tijdvensters, drempels)
- Ticketing / workflow-API (openstaande zaken, SLA-timers, goedkeuringen, stapvoltooiing)
Belangrijk is dat het model geen operationele feiten “uitvindt”—het vraagt erom.
Retrieval: alleen de regels ophalen die relevant zijn
Zelfs als je al het beleid centraal bewaart, wil je zelden alles in de prompt plakken. Retrieval helpt door alleen de meest relevante fragmenten voor de huidige zaak te selecteren—bijvoorbeeld:
- Het annuleringsbeleid voor het plan van de klant
- De regionale nalevingsclausule op basis van land/staat
- De uitzonderingsregel die geldt bij een lopende chargeback
Dit vermindert tegenstrijdigheden en voorkomt dat het model een verouderde regel volgt alleen omdat die eerder in de context stond.
Tooluitvoer behandelen als beslissingsbewijs
Een betrouwbaar patroon is om toolresultaten als bewijs te behandelen dat het model moet citeren in zijn beslissing. Bijvoorbeeld:
- Tool:
get_account(account_id)→status="past_due",plan="Business",usage_this_month=12000 - Tool:
retrieve_policies(query="overage fee Business plan")→ retourneert regel: “Overage fee applies above 10,000 units at $0.02/unit.” - Tool:
calculate_overage(usage=12000, threshold=10000, rate=0.02)→$40.00
Nu is de beslissing geen gok: het is een conclusie verankerd in specifieke inputs (“past_due”, “12,000 units”, “$0.02/unit”). Bij een latere audit kun je precies zien welke feiten en welke regelversie zijn gebruikt—en het juiste onderdeel aanpassen wanneer iets verandert.
Beperkte uitvoer: schema's die ambiguïteit verminderen
Rol met vertrouwen terug
Bescherm releases met snapshots en rollback wanneer regels of prompts veranderen.
Vrije tekst is flexibel, maar ook de makkelijkste manier waarop een workflow kan breken. Een model kan een “redelijk” antwoord geven dat onmogelijk te automatiseren is (“lijkt in orde”), of inconsistent is tussen stappen (“approve” vs “approved”). Beperkte uitvoer lost dat op door elke beslissing in een voorspelbare vorm te dwingen.
Retourneer beslissingen als JSON
Een praktisch patroon is het model te verplichten te reageren met één JSON-object dat je systeem kan parseren en routeren:
{
"decision": "needs_review",
"reasons": [
"Applicant provided proof of income, but the document is expired"
],
"next_action": "request_updated_document",
"missing_info": [
"Income statement dated within the last 90 days"
],
"assumptions": [
"Applicant name matches across documents"
]
}
Deze structuur maakt de uitvoer bruikbaar, zelfs als het model niet volledig kan beslissen. missing_info en assumptions veranderen onzekerheid in concrete vervolgstappen, in plaats van verborgen giswerk.
Gebruik enumeraties om uitkomsten te beperken
Om variabiliteit te verminderen, definieer toegestane waarden (enums) voor sleutelvelden. Bijvoorbeeld:
decision:approved|denied|needs_reviewnext_action:approve_case|deny_case|request_more_info|escalate_to_human
Met enums hoeven downstream-systemen geen synoniemen, interpunctie of toon te interpreteren. Ze sturen simpelweg op bekende waarden.
Waarom schema's workflows veiliger maken
Schema's werken als vangrails. Ze:
- Voorkomen "gedeeltelijke antwoorden" door verplichte velden af te dwingen.
- Maken het makkelijker om te auditen waarom een beslissing werd genomen (via
reasons). - Stellen betrouwbare automatisering in staat: wachtrijen, meldingen en taakcreatie kunnen direct vanaf
decisionennext_actionworden getriggerd. - Ondersteunen validatie: je kunt uitvoer afkeuren die niet aan het schema voldoet en het model laten herhalen.
Het resultaat is minder ambiguïteit, minder randgevalfouten en beslissingen die consistent door een workflow kunnen bewegen.
Validatiestrategieën: fouten vangen voordat ze uitrollen
Zelfs een goed ge-prompt model kan overtuigend klinken terwijl het stiekem een regel schendt, een verplichte stap overslaat of een waarde verzint. Validatie is het vangnet dat een aannemelijke uitkomst verandert in een betrouwbare beslissing.
Pre-checks: valideer invoer vóór redeneren
Begin met verifiëren dat je de minimale informatie hebt om de regels toe te passen. Pre-checks moeten draaien voordat het model een besluit neemt.
Typische pre-checks omvatten verplichte velden (bijv. klanttype, ordertotaal, regio), basisformaten (datums, ID's, valuta) en toegestane bereiken (niet-negatieve bedragen, percentages tot 100%). Als iets faalt, retourneer dan een duidelijke, uitvoerbare fout (“Ontbreekt 'regio'; kan geen belastingregels kiezen”) in plaats van het model te laten raden.
Post-checks: valideer de beslissing tegen de regels
Nadat het model een uitkomst produceert, valideer dat deze consistent is met je regelset.
Focus op:
- Regeldekking: Heeft de beslissing de toepasselijke regels geciteerd of gemapt, of is een verplichte beleidsregel overgeslagen?
- Tegenstrijdigheid: Komt de uitvoer niet overeen met de gegeven inputs (bijv. “goedgekeurd” terwijl een harde blokkering van kracht is)?
- Grensgevallen: Test randen zoals drempels (exact $10.000), lege staten (“geen eerdere overtredingen”) en “net iets boven”-scenario's.
Tweede controlepass: een bewuste reviewstap
Voeg een “tweede pas” toe die het eerste antwoord opnieuw evalueert. Dit kan een tweede modelaanroep zijn of hetzelfde model met een validatorprompt die alleen compliance controleert, niet creativiteit.
Een eenvoudig patroon: eerste pass produceert een beslissing + rationale; tweede pass retourneert of het valid is of een gestructureerde lijst van fouten (ontbrekende velden, geschonden constraints, ambigu interpretatie van regels).
Logging: maak beslissingen auditeerbaar
Log voor elke beslissing de gebruikte inputs, de regel-/beleidversie en de validatieresultaten (inclusief tweede-pass bevindingen). Als er iets misgaat kun je zo exact reproduceren welke condities golden, de regelmapping aanpassen en de correctie verifiëren—zonder te moeten raden wat het model “bedoelde”.
Testen en monitoren voor betrouwbaarheid van regels en workflows
Het testen van LLM-functies die regels en workflows aansturen gaat minder over “heeft het iets gegenereerd?” en meer over “nam het dezelfde beslissing die een zorgvuldige mens zou nemen, om de juiste reden, elke keer?” Het goede nieuws: je kunt het testen met dezelfde discipline als voor traditionele beslissingslogica.
Unit-tests voor bedrijfsregels (kleine, voorspelbare checks)
Behandel elke regel als een functie: gegeven inputs moet die een uitkomst teruggeven die je kunt asserten.
Bijvoorbeeld, voor een restitutieregel als “restituties zijn toegestaan binnen 30 dagen voor ongeopende items”, schrijf gerichte gevallen met verwachte uitkomsten:
- Orderleeftijd = 10 dagen, ongeopend = true → approve
- Orderleeftijd = 10 dagen, ongeopend = false → deny
- Orderleeftijd = 45 dagen, ongeopend = true → deny
- Randgevallen: precies 30 dagen, ontbrekend veld “ongeopend”, conflicterende signalen
Deze unittests vangen fouten zoals off-by-one, ontbrekende velden en “behulpzaam” modelgedrag waarin het onbekenden invult.
Scenario-tests voor workflows (meerstaps, tijdsgevoelige paden)
Workflows falen wanneer state inconsistente wordt over stappen heen. Scenario-tests simuleren echte trajecten:
- Padtests: claim indienen → documenten aanvragen → documenten ontvangen → beslissing
- Tijdgebaseerde randen: “als geen antwoord in 7 dagen, stuur herinnering”, “als 30 dagen verstrijken, sluit zaak”
- Vertakkingen: klant escaleert, beleidsuitzondering gevraagd, duplicaatzaak gedetecteerd
Het doel is verifiëren dat het model de huidige state respecteert en alleen toegestane transities uitvoert.
Bouw een “gold set” van bekende goede gevallen
Maak een gecureerde dataset van echte, geanonimiseerde voorbeelden met overeengekomen uitkomsten (en korte rationales). Houd het geversioneerd en review het bij beleidswijzigingen. Een kleine gold set (zelfs 100–500 gevallen) is krachtig omdat het de rommelige realiteit weerspiegelt—ontbrekende data, ongebruikelijke formuleringen, grensbeslissingen.
Monitoring in productie (vang drift voordat klanten het merken)
Volg beslissingsdistributies en kwaliteitsindicatoren in de tijd:
- Drift: goedkeurings-/afwijzingspercentages veranderen zonder beleidsupdate
- Stijgingen in needs_review of overdracht naar mensen (vaak een prompt-, retrieval- of upstream-gegevensprobleem)
- Foutenclusters per product, regio of beleidscategorie
Koppel monitoring aan veilige rollback: bewaar een eerdere prompt/regelpakket, feature-flag nieuwe versies en wees klaar om snel terug te draaien wanneer metrics verslechteren. Voor operationele playbooks en releasegating, zie /blog/validation-strategies.
Waar Koder.ai in deze pijplijn past
Zet snel full-stack op
Genereer een React-app met een Go-backend en PostgreSQL vanuit één gesprek.
Als je de bovenstaande patronen implementeert, bouw je meestal een klein systeem rond het model: state-opslag, toolcalls, retrieval, schema-validatie en een workflow-orkestrator. Koder.ai is een praktische manier om dat soort workflow-ondersteunde assistent sneller te prototypen en te leveren: je kunt de workflow in chat beschrijven, een werkende webapp (React) plus backendservices (Go met PostgreSQL) genereren en veilig itereren met snapshots en rollback.
Dit is belangrijk voor redeneerwerk over bedrijfsregels omdat de “vangrails” vaak in de applicatie leven, niet in de prompt:
- Planningmodus helpt je het flowontwerp (staten, toegestane transities, escalatiepaden) te maken vóór uitvoering.
- Schema-geconstrueerde antwoorden kunnen aan de API-grens worden afgedwongen, zodat je alleen parseerbare beslissingen accepteert.
- Tooling-hooks (DB-reads, beleidsretrieval, calculators, ticketupdates) kunnen als expliciete endpoints worden geïmplementeerd, waardoor “haal eerst bewijs, beslis daarna” de standaard wordt.
- Broncode-export voorkomt vendor lock-in zodra het prototype kritiek wordt voor productie.
Grenzen, veilig gebruik en wanneer een mens moet ingrijpen
LLM's kunnen verrassend goed alledaagse beleidsregels toepassen, maar ze zijn geen deterministische regelsmotor. Behandel ze als een beslissingsassistent die vangrails nodig heeft, niet als de uiteindelijke autoriteit.
Waar LLMs moeite mee hebben
Drie faalpatronen komen regelmatig terug in regelzware workflows:
- Zeldzame uitzonderingen en randgevallen: Als een uitzondering eenmaal per jaar voorkomt, kan die ondervertegenwoordigd zijn in trainingsdata en makkelijk gemist worden tenzij expliciet in de prompt of uit beleid opgehaald.
- Lange contexten en “verborgen” beperkingen: Wanneer belangrijke details verspreid staan over veel pagina's of berichten, kan het model het recentste of meest opvallende tekstdeel overgewicht geven en eerder genoemde beperkingen ondertoepassen.
- Numerieke precisie en strikte berekeningen: Totalen, proraties, drempels en afrondingsregels kunnen afwijken. Gebruik tools voor rekenen en eis dat het model de exacte nummers citeert die het gebruikte.
Wanneer menselijke review verplicht te maken
Voeg verplichte review toe wanneer:
- De uitkomst hoog risico is (geldstromen, naleving, veiligheid, juridische verplichtingen, klantkrediet/geschiktheid).
- Het model lage confidentie aangeeft (het moet raden naar ontbrekende invoer, vindt geen beleidsbasis of produceert tegenstrijdige redenering).
- De zaak nieuw is (nieuw product, nieuwe regio, recent beleidswijziging) of uitzonderlijk gevoelig.
Escalatiepaden die dingen laten doorgaan
In plaats van het model “iets te laten verzinnen”, definieer duidelijke vervolgstappen:
- Stel verhelderende vragen (ontbrekende datums, klantniveau, jurisdictie, goedkeuringsstatus).
- Routeer naar een agent met de geëxtraheerde feiten, voorgestelde beslissing en citaten.
- Maak een ticket wanneer beleid ambigu of conflicterend is, zodat het aan de bron kan worden opgelost (en later automatisch opgehaald).
Een eenvoudig adoptiekader
Gebruik LLMs in regelzware workflows wanneer je op de meeste van deze vragen “ja” kunt antwoorden:
- Kunnen we beslissingen onderbouwen met goedgekeurde beleidstekst of systeembedragen?
- Kunnen we uitvoer beperken (schema, toegestane acties, verplichte citaten)?
- Kunnen we valideren (checks, drempels, unittests, sampling) vóór uitvoering?
- Hebben we een menselijke escalatie route voor risicovolle of onzekere gevallen?
Zo niet, houd het LLM in een concept-/assistentrol totdat die controles bestaan.