25 jul 2025·8 min
Hoe LLM's eenvoudige Engelse ideeën omzetten in full-stack apps
Hoe LLM's eenvoudige Engelstalige productideeën omzetten in web-, mobiel- en backend-apps: vereisten, UI-flows, datamodellen, API's, testen en deployment.
Hoe LLM's eenvoudige Engelstalige productideeën omzetten in web-, mobiel- en backend-apps: vereisten, UI-flows, datamodellen, API's, testen en deployment.
Een “platte Engelstalige productidee” begint meestal als een mix van intentie en hoop: voor wie het is, welk probleem het oplost, en wat succes betekent. Het kan een paar zinnen zijn (“een app om hondenuitlaters in te plannen”), een ruwe workflow (“klant vraagt aan → uitlater accepteert → betaling”), en een paar must-haves (“pushmeldingen, beoordelingen”). Dat is genoeg om over een idee te praten—maar niet genoeg om consistent te bouwen.
Als men zegt dat een LLM een idee kan “vertalen” naar een app, is de bruikbare betekenis: vage doelen omzetten in concrete, toetsbare beslissingen. Het “vertalen” is niet alleen herschrijven—het voegt structuur toe zodat je het kunt beoordelen, uitdagen en implementeren.
LLM's zijn goed in het produceren van een eerste versie van de kernbouwstenen:
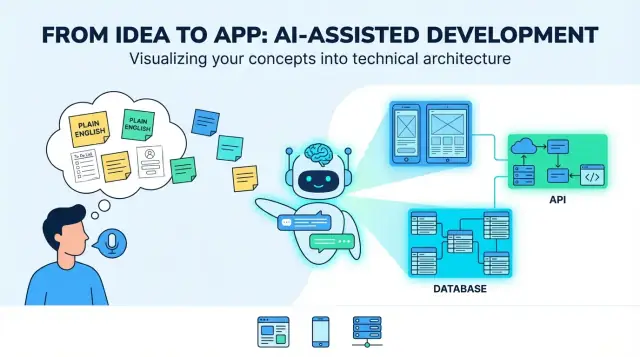
Het typische “eindresultaat” lijkt op een blauwdruk voor een full-stack product: een web-UI (vaak voor admins of desktop-zware taken), een mobiele UI (voor gebruikers onderweg), backend-services (auth, business logic, notificaties) en dataopslag (database plus file/media storage).
LLM's kunnen je niet betrouwbaar helpen bij het kiezen van productafwegingen, omdat de juiste antwoorden afhankelijk zijn van context die je mogelijk niet hebt beschreven:
Behandel het model als een systeem dat opties en standaarden voorstelt, niet als de definitieve waarheid.
De grootste faalmodi zijn voorspelbaar:
Het echte doel van “vertaling” is aannames zichtbaar te maken—zodat je ze kunt bevestigen, herzien of verwerpen voordat ze in code worden omgezet.
Voordat een LLM “Bouw voor mij een app voor X” kan omzetten in schermen, API's en datamodellen, heb je een productbrief nodig die specifiek genoeg is om tegen te ontwerpen. Deze stap draait om het omzetten van vage intentie naar een gedeeld doel.
Schrijf de probleemstelling in één of twee zinnen: wie heeft er moeite, met wat en waarom doet het ertoe. Voeg daarna meetbare succesmetrics toe.
Bijvoorbeeld: “Verminder de tijd die een kliniek nodig heeft om vervolgafspraken in te plannen.” Metrics kunnen gemiddelde planningsduur, no-show percentage of % patiënten die via self-service boeken zijn.
Noem de primaire gebruikersgroepen (niet iedereen die het systeem kan raken). Geef elk een toptaak en een korte scenario.
Een nuttige prompttemplate is: “Als [rol], wil ik [doen] zodat [voordeel].” Streef naar 3–7 kernuse-cases die de MVP beschrijven.
Beperkingen maken het verschil tussen een nette prototype en een release-klaar product. Vermeld:
Wees expliciet over wat in de eerste release zit en wat wordt uitgesteld. Een eenvoudige regel: MVP-functies moeten de primaire use-cases end-to-end ondersteunen zonder handmatige workarounds.
Als je wilt, leg dit vast op één pagina en bewaar het als de “source of truth” voor de volgende stappen (vereisten, UI-flows en architectuur).
Een eenvoudig idee is meestal een mix van doelen (“help mensen lessen boeken”), aannames (“gebruikers loggen in”) en vage scope (“maak het simpel”). Een LLM is nuttig omdat het rommelige input kan omzetten in vereisten die je kunt beoordelen, corrigeren en goedkeuren.
Begin met het herschrijven van elke zin als een user story. Dit dwingt duidelijkheid af over wie wat nodig heeft en waarom:
Als een story geen gebruikerstype of voordeel noemt, is hij waarschijnlijk nog te vaag.
Groepeer vervolgens stories in features en label elk als must-have of nice-to-have. Dit helpt scope creep te voorkomen voordat design en engineering beginnen.
Voorbeeld: “pushmeldingen” kan nice-to-have zijn, terwijl “een boeking annuleren” meestal must-have is.
Voeg eenvoudige, testbare regels toe onder elke story. Goede acceptatiecriteria zijn specifiek en observeerbaar:
LLM's standaardiseren vaak op het “happy path”, vraag dus expliciet om randgevallen zoals:
Dit pakket met vereisten wordt de bron van waarheid die je gebruikt om latere outputs (UI-flows, API's en tests) te beoordelen.
Een eenvoudig idee wordt uitvoerbaar wanneer het verandert in gebruikersreizen en schermen verbonden door duidelijke navigatie. In deze stap kies je nog geen kleuren—je definieert wat mensen kunnen doen, in welke volgorde en wat succes is.
Begin met het opsommen van de paden die het meest belangrijk zijn. Voor veel producten kun je ze structureren als:
Het model kan deze flows als stapsgewijze sequenties opstellen. Jouw taak is te bevestigen wat optioneel is, wat verplicht is en waar gebruikers veilig kunnen stoppen en later weer verdergaan.
Vraag om twee deliverables: een scherminventaris en een navigatiekaart.
Een goede output benoemt schermen consistent (bijv. “Order Details” vs “Order Detail”), definieert entry points en beschrijft empty states (geen resultaten, geen opgeslagen items).
Zet vereisten om in formuliervelden met regels: verplicht/optioneel, formats, limieten en vriendelijke foutmeldingen. Voorbeeld: wachtwoordregels, betalingsadresformats of “datum moet in de toekomst liggen.” Zorg dat validatie zowel inline (tijdens typen) als bij submit plaatsvindt.
Neem leesbare tekstgroottes op, duidelijke contrasten, volledige toetsenbordondersteuning op het web en foutmeldingen die uitleggen hoe het probleem op te lossen (niet alleen “Ongeldige invoer”). Zorg ook dat elk formulierveld een label heeft en dat de focusvolgorde logisch is.
Een “architectuur” is het bouwplan van de app: welke onderdelen bestaan er, wat is de verantwoordelijkheid van elk onderdeel en hoe communiceren ze. Als een LLM een architectuur voorstelt, is jouw taak te zorgen dat het simpel genoeg is om nu te bouwen en duidelijk genoeg om later uit te breiden.
Voor de meeste nieuwe producten is een enkele backend (een monolith) de juiste start: één codebase, één deploy, één database. Het is sneller te bouwen, makkelijker te debuggen en goedkoper in exploitatie.
Een modulair monolith is vaak de gulden middenweg: nog steeds één deploy, maar georganiseerd in modules (Auth, Billing, Projects, etc.) met duidelijke grenzen. Je stelt service-splits pas uit tot er echte noodzaak is—bijv. veel verkeer of teams die onafhankelijk willen deployen.
Als het LLM meteen “microservices” voorstelt, vraag het dan om die keuze te onderbouwen met concrete redenen, niet hypothetische toekomstscenario's.
Een goed architectuuroverzicht noemt de essenties:
Het model moet ook aangeven waar elk stuk draait (backend vs mobiel vs web) en definiëren hoe clients met de backend praten (meestal REST of GraphQL).
Architectuur blijft vaag tenzij je basics vastlegt: backend-framework, database, hosting en mobile-aanpak (native vs cross-platform). Laat het model deze als “Aannames” opschrijven zodat iedereen weet waartegen ontworpen wordt.
In plaats van grote herontwerpen, geef de voorkeur aan kleine “escape hatches”: caching voor hot reads, een queue voor achtergrondwerk en stateloze app-servers zodat je later makkelijk extra instances kunt toevoegen. De beste architectuursuggesties leggen deze opties uit en houden v1 eenvoudig.
Een productidee zit vol zelfstandige naamwoorden: “users”, “projects”, “tasks”, “payments”, “messages.” Datamodellering is de stap waarin een LLM die zelfstandige naamwoorden omzet in een gedeeld beeld van wat de app moet opslaan—en hoe dingen met elkaar verbonden zijn.
Begin met het opsommen van de belangrijkste entiteiten en vraag: wat hoort bij wat?
Bijvoorbeeld:
Definieer dan relaties en constraints: kan een taak zonder project bestaan, kunnen opmerkingen bewerkt worden, kunnen projecten gearchiveerd worden en wat gebeurt er met taken als een project wordt verwijderd?
Vervolgens stelt het model een eerste schema voor (SQL-tabellen of NoSQL-collecties). Houd het simpel en gefocust op beslissingen die gedrag beïnvloeden.
Een typische eerste opzet kan bevatten:
Belangrijk: leg statusvelden, timestamps en unieke constraints vroeg vast (zoals unieke e-mail). Die details sturen UI-filters, notificaties en rapportages later.
De meeste echte apps hebben duidelijke regels over wie wat kan zien. Een LLM moet eigendom expliciet maken (owner_user_id) en toegang modelleren (membership/roles). Voor multi-tenant producten (veel bedrijven in één systeem) introduceer een tenant/organization-entiteit en voeg tenant_id toe aan alles wat geïsoleerd moet worden.
Definieer ook hoe permissies worden afgedwongen: per rol (admin/member/viewer), per eigendom, of een combinatie.
Ten slotte bepaal wat gelogd moet worden en wat verwijderd. Voorbeelden:
Deze keuzes voorkomen onaangename verrassingen als compliance-, support- of facturatievragen later opduiken.
Backend-API's zijn waar de beloften van je app echte acties worden: “sla mijn profiel op”, “toon mijn bestellingen”, “zoek listings”. Een goede output begint bij gebruikersacties en zet die om in een kleine set heldere endpoints.
Som de belangrijkste objecten op waarmee gebruikers werken (bijv. Projects, Tasks, Messages). Definieer voor elk wat de gebruiker kan doen:
Dat mapt doorgaans op endpoints als:
POST /api/v1/tasks (create)GET /api/v1/tasks?status=open&q=invoice (list/search)GET /api/v1/tasks/{taskId} (read)PATCH /api/v1/tasks/{taskId} (update)DELETE /api/v1/tasks/{taskId} (delete)Create a task: gebruiker stuurt titel en dueDate.
POST /api/v1/tasks
{
"title": "Send invoice",
"dueDate": "2026-01-15"
}
Het antwoord retourneert het opgeslagen record (inclusief servergegenereerde velden):
201 Created
{
"id": "tsk_123",
"title": "Send invoice",
"dueDate": "2026-01-15",
"status": "open",
"createdAt": "2025-12-26T10:00:00Z"
}
Laat het model consistente fouten produceren:
Voor retries geef je de voorkeur aan idempotency keys op POST en duidelijke aanwijzingen zoals “retry after 5 seconds.”
Mobiele clients updaten langzaam. Gebruik een versiepad (/api/v1/...) en vermijd breaking changes:
GET /api/version)Beveiliging is geen taak voor later. Wanneer een LLM je idee omzet in app-specs, wil je veilige defaults expliciet zien—zodat de eerste gegenereerde versie niet per ongeluk openstaat voor misbruik.
Vraag het model een primaire login-methode en een fallback aan te bevelen, plus wat er gebeurt als het misgaat (toegang verloren, verdacht inloggen). Gebruikelijke keuzes:
Laat het ook sessiegedrag specificeren (kortdurende access tokens, refresh tokens, device logout) en of je multi-factor authenticatie ondersteunt.
Authenticatie identificeert de gebruiker; autorisatie beperkt toegang. Moedig het model aan één duidelijk patroon te kiezen:
project:edit, invoice:export) voor flexibele productenEen goede output bevat voorbeeldregels zoals: “Alleen project-eigenaren kunnen een project verwijderen; samenwerkers kunnen bewerken; kijkers kunnen commentaar geven.”
Laat het model concrete beschermingen opsommen, geen vage beloften:
Vraag ook om een baseline dreigingschecklist: CSRF/XSS-bescherming, veilige cookies en veilige bestandsuploads indien relevant.
Default naar minimale dataverzameling: alleen wat een functie echt nodig heeft en zo kort mogelijk bewaren.
Laat het LLM platte- taaltekst opstellen voor:
Als je analytics toevoegt, eist dat een opt-out (of opt-in waar vereist) en documenteer dat duidelijk in instellingen en beleidspagina's.
Een goed LLM kan je vereisten omzetten in een testplan dat verrassend bruikbaar is—mits je het dwingt alles te koppelen aan acceptatiecriteria, niet aan vage “moet werken”-statements.
Begin door het model je functielijst en acceptatiecriteria te geven, vraag het vervolgens tests per criterium te genereren. Een solide output bevat:
Als een test niet terug te voeren is op een specifiek criterium, is het waarschijnlijk ruis.
LLM's kunnen ook fixtures voorstellen die lijken op echt gebruik: rommelige namen, ontbrekende velden, tijdzones, lange tekst en “bijna duplicaten”. Vraag om:
Laat het model een mobiele checklist toevoegen:
LLM's zijn goed in het opstellen van testskeletten, maar je moet beoordelen:
Behandel het model als een snelle testauteur, niet als de laatste QA-aftekenaar.
Een model kan veel code genereren, maar gebruikers profiteren pas als het veilig wordt uitgerold en je kunt zien wat er na lancering gebeurt. Deze stap draait om herhaalbare releases: steeds dezelfde stappen met zo min mogelijk verrassingen.
Zet een eenvoudige CI-pijplijn op die op elke pull request en op merges naar main draait:
Zelfs als het LLM de code schreef, vertelt CI je of het nog werkt na een wijziging.
Gebruik drie omgevingen met duidelijke doelen:
Configuratie hoort via omgevingsvariabelen en secrets te gaan (niet hard-coded). Een goede vuistregel: als iets veranderen code vereist, is het waarschijnlijk verkeerd geconfigureerd.
Voor een typische full-stack app:
Plan voor drie signalen:
Dit is waar AI-ondersteund ontwikkelen operationeel wordt: je genereert niet alleen code—je runt een product.
LLM's kunnen een vaag idee omzetten in iets wat op een volledig plan lijkt—maar verzorgde tekst kan hiaten verbergen. De meest voorkomende fouten zijn voorspelbaar en je kunt ze voorkomen met een paar herhaalbare gewoontes.
De meeste zwakke outputs liggen aan vier oorzaken:
Geef het model concreet materiaal:
Vraag checklists per deliverable. Bijvoorbeeld: vereisten zijn niet “klaar” totdat ze acceptatiecriteria, foutstaten, rollen/permissies en meetbare succesmetrics bevatten.
LLM-outputs drijven als specificaties, API-notities en UI-ideeën in aparte threads leven. Houd één levend document (zelfs een simpele markdown) die linkt naar:
Wanneer je opnieuw promt, plak dan het laatste excerpt en zeg: “Werk alleen secties X en Y bij; laat de rest ongewijzigd.”
Als je tijdens implementatie werkt, helpt een workflow die snelle iteratie ondersteunt zonder traceerbaarheid te verliezen. Bijvoorbeeld: Koder.ai’s “planning mode” past hier goed: je kunt de spec vergrendelen (aannames, open vragen, acceptatiecriteria), de web/mobiele/backend scaffolding vanuit één chat genereren en vertrouwen op snapshots/rollback als een wijziging regressies veroorzaakt. Source code-export is vooral handig als je wilt dat de gegenereerde architectuur en je repo synchroon blijven.
Zo kan “LLM-vertaling” er end-to-end uitzien—plus de checkpoints waar een mens vertraagt en echte beslissingen neemt.
Eenvoudig idee: “Een pet-sitting marktplaats waar eigenaren verzoeken plaatsen, sitters solliciteren en betalingen vrijkomen nadat het klusje is afgerond.”
Een LLM kan dat omzetten in een eerste ontwerp zoals:
POST /requests, GET /requests/{id}, POST /requests/{id}/apply, GET /requests/{id}/applications, POST /messages, POST /checkout/session, POST /jobs/{id}/complete, POST /reviews.Dat is nuttig—maar niet “klaar.” Het is een gestructureerd voorstel dat validatie behoeft.
Productbeslissingen: Wat maakt een “applicatie” geldig? Mag een eigenaar direct een sitter uitnodigen? Wanneer is een verzoek “gevuld”? Deze regels beïnvloeden elk scherm en elke API.
Beveiliging & privacy review: Bevestig role-based toegang (eigenaren mogen geen chats van andere eigenaren lezen), bescherm betalingen en definieer dataverwijdering (bijv. chat verwijderen na X maanden). Voeg misbruikbeperkingen toe: rate limits, spampreventie, auditlogs.
Prestatie-afwegingen: Bepaal wat snel en schaalbaar moet zijn (zoeken/filteren van verzoeken, chat). Dit beïnvloedt caching, paginatie, indexering en achtergrondtaken.
Na een pilot vragen gebruikers misschien om “herhaal een verzoek” of “annuleer met gedeeltelijke restitutie.” Geef dat terug als bijgewerkte vereisten, genereer of patch de getroffen flows en voer tests en security-checks opnieuw uit.
Leg het “waarom” vast, niet alleen het “wat”: kern-businessregels, permissiematrix, API-contracten, foutcodes, databasemigraties en een kort runbook voor releases en incident response. Dit houdt gegenereerde code begrijpelijk zes maanden later.
In deze context betekent “vertalen” dat je een vaag idee omzet in specifieke, toetsbare beslissingen: rollen, journeys, vereisten, data, API's en succescriteria.
Het is niet alleen herformuleren—het maakt aannames expliciet zodat je ze kunt bevestigen of verwerpen voordat je gaat bouwen.
Een praktische eerste versie bevat doorgaans:
Zie het als een conceptueel blauwdruk die je moet beoordelen, niet als een definitieve specificatie.
Omdat een LLM je echte wereldbeperkingen en afwegingen niet betrouwbaar kent zonder dat jij ze opgeeft, moeten mensen nog steeds beslissen over:
Gebruik het model om opties voor te stellen en maak daarna bewuste keuzes.
Geef het model genoeg context om tegen te ontwerpen:
Als je dit niet aan een collega kunt geven met dezelfde interpretatie, is het nog niet klaar.
Richt je op het omzetten van doelen in user stories + acceptatiecriteria.
Een sterk pakket bevat meestal:
Dit wordt je “single source of truth” voor UI, API's en tests.
Vraag twee concrete deliverables:
Controleer daarna:
Begin met de default: monolith of modular monolith voor de meeste v1-producten.
Als het model meteen met microservices komt, vraag dan om concrete redenen (verkeer, onafhankelijke deploys, schaalverschillen). Geef de voorkeur aan “escape hatches” zoals:
Hou v1 eenvoudig om te bouwen en te debuggen.
Laat het model expliciet opschrijven:
Deze data-beslissingen bepalen UI-filters, notificaties, rapportages en beveiliging.
Eis consistentie en mobiel-vriendelijk gedrag:
/api/v1/...)POST verzoekenVermijd breaking changes; voeg optionele velden toe en houd een deprecatieperiode aan.
Laat het model een plan opstellen en beoordeel dat vervolgens aan de hand van acceptatiecriteria:
Vraag ook om realistische fixtures: tijdzones, lange teksten, bijna-duplicaten, onbetrouwbare netwerken. Zie gegenereerde tests als vertrekpunt, niet als vervanging van QA.
Je ontwerpt gedrag, geen visuals.