27 jul 2025·8 min
Hoe talen, databases en frameworks als één systeem samenwerken
Leer hoe talen, databases en frameworks als één systeem samenwerken. Vergelijk afwegingen, integratiepunten en praktische manieren om een samenhangende stack te kiezen.
Leer hoe talen, databases en frameworks als één systeem samenwerken. Vergelijk afwegingen, integratiepunten en praktische manieren om een samenhangende stack te kiezen.
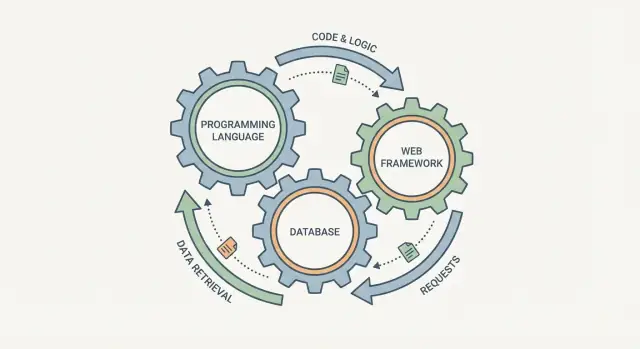
Het is verleidelijk om een programmeertaal, een database en een webframework als drie onafhankelijke vinkjes te kiezen. In de praktijk werken ze meer als verbonden tandwielen: verander je één onderdeel, dan merkt de rest het ook.
Een webframework bepaalt hoe requests behandeld worden, hoe data gevalideerd wordt en hoe fouten zichtbaar worden. De database bepaalt wat “makkelijk op te slaan” betekent, hoe je informatie opvraagt en welke garanties je krijgt als meerdere gebruikers tegelijk handelingen uitvoeren. De taal zit ertussenin: die bepaalt hoe veilig je regels kunt uitdrukken, hoe je concurrency beheert en welke libraries en tooling je kunt gebruiken.
De stack als één systeem beschouwen betekent dat je niet elk deel los optimaliseert. Je kiest een combinatie die:
Dit artikel blijft praktisch en bewust niet te technisch. Je hoeft geen databasetheorie of taal-internals te onthouden—zie gewoon hoe keuzes door het hele applicatiebeeld heen doorwerken.
Een kort voorbeeld: een schema-loze database gebruiken voor sterk gestructureerde, rapportgerichte bedrijfsdata leidt vaak tot verspreide “regels” in applicatiecode en verwarrende analytics later. Een betere match is datzelfde domein koppelen aan een relationele database en een framework dat consistente validatie en migraties aanmoedigt, zodat je data coherent blijft naarmate het product groeit.
Als je de stack samen plant, ontwierp je één set afwegingen—niet drie afzonderlijke weddenschappen.
Een handige manier om over een “stack” te denken is als één pijplijn: een gebruiker doet een verzoek, en er komt een response (plus opgeslagen data) uit. Programmeertaal, webframework en database zijn geen losse keuzes—het zijn drie onderdelen van dezelfde reis.
Stel je voor dat een klant zijn afleveradres bijwerkt.
/account/address). Validatie controleert of de input compleet en zinnig is.Als deze drie op één lijn zitten, loopt een request soepel. Als ze dat niet doen, ontstaat frictie: onhandige data-access, lekkende validatie en subtiele consistentiebugs.
De meeste “stack”-debates beginnen met taal- of databasemerken. Een beter startpunt is je datamodel—want dat dicteert stilletjes wat overal natuurlijk (of pijnlijk) aanvoelt: validatie, queries, API's, migraties en zelfs teamworkflow.
Applicaties jongleren meestal met vier vormen tegelijk:
Een goede match is wanneer je niet je dagen besteedt aan het vertalen tussen vormen. Als je kerndata sterk verbonden is (gebruikers ↔ bestellingen ↔ producten), houden rijen en joins de logica eenvoudig. Als je data meestal “één blob per entiteit” is met variabele velden, kunnen documenten ceremonie verminderen—totdat je cross-entity rapportage nodig hebt.
Wanneer de database een sterk schema heeft, kunnen veel regels dicht bij de data leven: types, constraints, foreign keys, uniqueness. Dat vermindert vaak gedupliceerde checks over services heen.
Bij flexibele structuren verplaatsen regels zich naar de applicatie: validatiecode, versioned payloads, backfills en zorgvuldige leeslogica (“als veld bestaat, dan…”). Dit kan goed werken wanneer productvereisten wekelijks veranderen, maar het vergroot de last op je framework en testen.
Je model bepaalt of je code vooral bestaat uit:
Dat beïnvloedt weer taal- en frameworkbehoeften: sterke typing kan subtiele drift in JSON-velden voorkomen, terwijl volwassen migratietools belangrijker worden wanneer schema's vaak veranderen.
Kies eerst het model; de “juiste” framework- en databasekeuze wordt daarna vaak duidelijker.
Transacties zijn de "alles-of-niets" garanties waarop je app stilletjes vertrouwt. Als een checkout slaagt, verwacht je dat orderrecord, betalingsstatus en voorraadupdate óf allemaal gebeuren, óf helemaal niet. Zonder die belofte ontstaan de moeilijkste bugs: zeldzaam, duur en lastig te reproduceren.
Een transactie groepeert meerdere databasehandelingen in één eenheid van werk. Als er halverwege iets fout gaat (validatiefout, timeout, gecrashte process), kan de database terugrollen naar de vorige veilige staat.
Dit is belangrijk buiten geldstromen: accountaanmaak (user row + profile row), content publiceren (post + tags + zoekindexwijzers) of elke workflow die meer dan één tabel aanraakt.
Consistentie betekent “reads komen overeen met de werkelijkheid.” Snelheid betekent “iets snel teruggeven.” Veel systemen maken hier afwegingen:
De veelvoorkomende fout is een eventually-consistent setup kiezen en vervolgens coderen alsof het sterk consistent is.
Frameworks en ORMs starten niet automatisch transacties alleen omdat je meerdere save-methoden hebt aangeroepen. Sommige vereisen expliciete transaction blocks; andere starten een transactie per request, wat performanceproblemen kan verbergen.
Retries zijn ook lastig: ORMs kunnen opnieuw proberen bij deadlocks of tijdelijke fouten, maar je code moet veilig zijn om dubbel uitgevoerd te worden.
Partiële schrijfacties ontstaan wanneer je A bijwerkt en faalt voordat je B bijwerkt. Dubbele acties ontstaan wanneer een request opnieuw wordt geprobeerd na een timeout—vooral als je een kaart belast of een e-mail stuurt voordat de transactie commit.
Een eenvoudige regel helpt: laat bijwerkingen (e-mails, webhooks) ná de databasecommit gebeuren, en maak acties idempotent door unieke constraints of idempotency keys te gebruiken.
Dit is de “vertalingslaag” tussen je applicatiecode en je database. De keuzes hier beïnvloeden vaak het dagelijks werk meer dan het database-merk zelf.
Een ORM (Object-Relational Mapper) laat je tabellen als objecten behandelen: maak een User, update een Post, en de ORM genereert SQL achter de schermen. Het kan productief zijn omdat het repetitieve taken standaardiseert en boilerplate verbergt.
Een query builder is explicieter: je bouwt een SQL-achtig statement met code (chains of functies). Je denkt nog steeds in “joins, filters, groups,” maar krijgt parameterveiligheid en composeerbaarheid.
Raw SQL is het echte SQL zelf schrijven. Het is het meest direct en vaak het helderst voor complexe rapportagequeries—ten koste van meer handwerk en conventions.
Talen met sterke typing (TypeScript, Kotlin, Rust) duwen je vaak richting tools die queries en resultshapes vroeg valideren. Dat vermindert runtime verrassingen, maar dwingt teams vaak om data-access te centraliseren zodat types niet wegdrijven.
Talen met flexibele metaprogrammering (Ruby, Python) maken ORMs vaak natuurlijk en snel om mee te itereren—totdat verborgen queries of impliciet gedrag moeilijk te doorgronden worden.
Migraties zijn geversioneerde scripts voor je schema: voeg een kolom toe, maak een index, backfill data. Het doel is simpel: iedereen kan de app deployen en dezelfde database-structuur krijgen. Behandel migraties als code: review ze, test ze en rollback waar nodig.
ORMs kunnen ongemerkt N+1 queries genereren, enorme rijen ophalen die je niet nodig hebt of joins onhandig maken. Query builders kunnen onleesbare "chains" worden. Raw SQL kan gedupliceerd en inconsistent raken.
Een goede vuistregel: gebruik het eenvoudigste gereedschap dat intentie duidelijk houdt—en inspecteer voor kritieke paden altijd de SQL die daadwerkelijk draait.
Mensen geven vaak de database de schuld wanneer een pagina traag aanvoelt. Maar zichtbare latentie is meestal de som van meerdere kleine wachttijden over het hele requestpad.
Een enkele request betaalt typisch voor:
Zelfs als je database in 5 ms antwoordt, voelt een app die 20 queries per request doet, blokkeert op I/O en 30 ms besteedt aan serialiseren nog steeds traag.
Een nieuwe databaseconnectie openen is duur en kan de database overweldigen onder load. Een connection pool hergebruikt bestaande connecties zodat requests die setupkost niet telkens betalen.
De catch: de “juiste” poolgrootte hangt af van je runtime-model. Een zeer concurrente async server kan enorme gelijktijdige vraag creëren; zonder pool-limieten krijg je wachtrijen, timeouts en lawaaierige fouten. Met te strakke poollimieten wordt je app zelf de bottleneck.
Caching kan in de browser zitten, een CDN, een in-process cache of een gedeelde cache (zoals Redis). Het helpt wanneer veel requests dezelfde resultaten nodig hebben.
Maar caching lost niet op:
Je programmeertaal-runtime bepaalt throughput. Thread-per-request modellen kunnen middelen verspillen tijdens I/O-wachten; async-modellen vergroten concurrency, maar maken backpressure (zoals poollimieten) essentieel. Daarom is performance-tuning een stack-beslissing, geen database-beslissing.
Beveiliging is geen plugin die je "toevoegt" met een framework of database-instelling. Het is de overeenkomst tussen je taal/runtime, je webframework en je database over wat altijd waar moet zijn—zelfs wanneer een ontwikkelaar een fout maakt of een nieuwe endpoint wordt toegevoegd.
Authenticatie (wie is dit?) leeft meestal aan de rand van het framework: sessies, JWTs, OAuth-callbacks, middleware. Autorisatie (wat mag diegene doen?) moet consequent worden afgedwongen in zowel applicatielogica áls databaserules.
Een gangbaar patroon: de app bepaalt intentie (“gebruiker mag dit project bewerken”), en de database handhaaft grenzen (tenant IDs, ownership-constraints en, waar zinvol, row-level policies). Als autorisatie alleen in controllers bestaat, kunnen achtergrondjobs en interne scripts deze per ongeluk omzeilen.
Framework-validatie geeft snelle feedback en goede foutmeldingen. Database-constraints bieden een laatste veiligheidsnet.
Gebruik beide wanneer het ertoe doet:
CHECK-constraints, NOT NULL.Dit vermindert “onmogelijke toestanden” die verschijnen wanneer twee requests racen of een nieuwe service data anders schrijft.
Secrets moeten door runtime en deployment workflow worden beheerd (env vars, secret managers), niet hardcoded in code of migraties. Encryptie kan in de app gebeuren (field-level encryptie) en/of in de database (at-rest encryptie, managed KMS), maar je moet duidelijkheid hebben over wie sleutels roteert en hoe herstel werkt.
Auditing is ook gedeeld: de app zou betekenisvolle events moeten emitten; de database zou immutabele logs moeten bewaren waar passend (bijv. append-only audit-tabellen, beperkte toegang).
Te veel vertrouwen op applicatielogica is klassiek: missende constraints, stille nulls, admin-flags zonder checks. De remedie is simpel: ga ervan uit dat bugs gebeuren en ontwerp de stack zo dat de database onveilige writes kan weigeren—zelfs van je eigen code.
Schaalproblemen falen zelden omdat "de database het niet aankan." Ze falen omdat de hele stack slecht reageert als de load van vorm verandert: één endpoint wordt populair, één query wordt heet, één workflow begint opnieuw te proberen.
De meeste teams stoten op dezelfde vroege bottlenecks:
Of je snel kunt reageren hangt af van hoe goed je framework en database-tooling queryplannen, migraties, connection pooling en veilige cachingpatronen blootgeven.
Veelvoorkomende schaalstappen komen meestal in deze volgorde:
Een schaalbare stack heeft eersteklas ondersteuning voor achtergrondtaken, scheduling en veilige retries.
Als je job-systeem geen idempotentie kan afdwingen (dezelfde job draait twee keer zonder dubbelleveringen), schaal je naar datacorruptie. Vroege keuzes—zoals vertrouwen op impliciete transacties, zwakke uniekheidsconstraints of ondoorzichtige ORM-gedragingen—kunnen het introduceren van queues, outbox-patronen of “exactly-once-achtige” workflows later blokkeren.
Vroege afstemming betaalt zich uit: kies een database die bij je consistentiebehoeften past en een framework-ecosysteem dat de volgende schaalstap (replica's, queues, partitionering) ondersteunt in plaats van een rewrite te forceren.
Een stack voelt “makkelijk” als development en operations dezelfde aannames delen: hoe je de app start, hoe data verandert, hoe tests draaien en hoe je weet wat er gebeurde als iets faalt. Als die stukken niet op één lijn liggen, verspillen teams tijd aan lijmcode, breekbare scripts en handmatige runbooks.
Snelle lokale setup is een feature. Geef de voorkeur aan een workflow waarin een nieuwe teammate kan clonen, installeren, migraties draaien en realistische testdata heeft in minuten—niet uren.
Dat betekent meestal:
Als het migratietooling van je framework met je databasekeuze vecht, wordt elke schemawijziging een klein project.
Je stack moet het natuurlijk maken om te schrijven:
Een vaak voorkomend falen: teams vertrouwen op unit tests omdat integratie-tests traag of pijnlijk op te zetten zijn. Dat is vaak een stack/ops-mismatch—test-database provisioning, migraties en fixtures zijn niet gestroomlijnd.
Als latentie piekt, moet je één request door het framework kunnen volgen en in de database kunnen zien welke queries er liepen.
Zoek naar consistente gestructureerde logs, basis metrics (request-rate, errors, DB-tijd) en traces met querytiming. Zelfs een simpele correlatie-ID in app-logs en database-logs kan van "gissen" naar "vinden" veranderen.
Operaties is geen los onderdeel van development; het is het vervolg ervan.
Kies tooling die ondersteunt:
Als je een restore of migratie niet lokaal kunt oefenen, doe je het onder druk niet goed.
Stack kiezen gaat minder over het vinden van de “beste” tools en meer over het kiezen van tools die samen passen bij je echte constraints. Gebruik deze checklist om vroeg afstemming af te dwingen.
Time-box naar 2–5 dagen. Bouw één dunne verticale slice: één kernworkflow, één achtergrondjob, één rapportachtige query en basis-auth. Meet ontwikkelfrictie, migratie-ergonomie, queryhelderheid en hoe makkelijk te testen.
Als je deze stap wilt versnellen, kan een vibe-coding tool zoals Koder.ai handig zijn om snel een werkende verticale slice (UI, API en database) te genereren vanuit een chat-gedreven spec—en vervolgens te itereren met snapshots/rollback en de broncode te exporteren als je klaar bent om een richting vast te leggen.
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks \u0026 mitigations:
When we’ll revisit:
Zelfs sterke teams eindigen met stack-mismatches—keuzes die op zichzelf redelijk lijken maar wrijving creëren zodra het systeem gebouwd is. Het goede nieuws: de meeste zijn voorspelbaar en je kunt ze vermijden met een paar checks.
Een klassieke geur is een database of framework kiezen omdat het trending is terwijl je eigen datamodel nog vaag is. Een andere is vroegtijdig schalen: optimaliseren voor miljoenen gebruikers voordat je betrouwbaar honderden kunt bedienen, wat vaak leidt tot extra infra en meer faalmodes.
Let ook op stacks waar het team niet kan uitleggen waarom elk hoofdonderdeel bestaat. Als het antwoord meestal is “iedereen gebruikt het”, stapel je risico op.
Veel problemen duiken op bij de naden:
Dit zijn geen puur “database” of “framework” problemen—het zijn systeemproblemen.
Geef de voorkeur aan minder bewegende delen en één duidelijk pad voor veelvoorkomende taken: één migratie-aanpak, één query-stijl voor de meeste features en consistente conventies over services heen. Als je framework een patroon aanmoedigt (request lifecycle, dependency injection, job-pipeline), leun daar op in plaats van stijlen te mixen.
Herzie keuzes als je terugkerende productie-incidenten ziet, aanhoudende ontwikkelfrictie of als nieuwe productvereisten je datatoegangspatronen fundamenteel veranderen.
Verander veilig door de naad te isoleren: introduceer een adapterlaag, migreer incrementeel (dual-write of backfill indien nodig) en bewijs pariteit met geautomatiseerde tests voordat je het verkeer omschakelt.
Een programmeertaal, een webframework en een database kiezen zijn geen drie onafhankelijke beslissingen—het is één systeemontwerpbeslissing die op drie plekken tot uitdrukking komt. De “beste” optie is de combinatie die aansluit bij je datavorm, je consistentiebehoeften, de workflow van je team en de manier waarop je verwacht dat het product groeit.
Schrijf de redenen achter je keuzes neer: verwachte verkeerspatronen, acceptabele latentie, bewaarbeleid, faalmodes die je kunt tolereren en wat je expliciet nú niet optimaliseert. Dit maakt afwegingen zichtbaar, helpt toekomstige teammates het “waarom” te begrijpen en voorkomt dat architectuur ongemerkt afdrijft als eisen veranderen.
Loop je huidige setup langs de checklist en noteer waar beslissingen niet op één lijn zitten (bijv. een schema dat tegen de ORM ingaat, of een framework dat achtergrondwerk lastig maakt).
Als je een nieuwe richting verkent, kunnen tools zoals Koder.ai je helpen stack-aannames snel te vergelijken door een basisapp te genereren (vaak React voor web, Go-services met PostgreSQL, en Flutter voor mobiel) die je kunt inspecteren, exporteren en verder uitbouwen—zonder je direct aan een lang bouwtraject te binden.
Voor diepere follow-up, bekijk gerelateerde gidsen in /blog, zoek implementatiedetails in /docs of vergelijk support- en deployopties op /pricing.
Behandel ze als één pijplijn voor elke request: framework → code (taal) → database → response. Als één onderdeel patronen aanmoedigt die de anderen tegenwerken (bijv. schema-loze opslag + zware rapportage), besteed je tijd aan lijmcode, gedupliceerde regels en moeilijk te debuggen consistentieproblemen.
Begin bij je kern-datamodel en de bewerkingen die je het vaakst doet:
Als het model duidelijk is, worden de database- en frameworkfeatures die je nodig hebt meestal vanzelf duidelijk.
Als de database een sterk schema afdwingt, kunnen veel regels dicht bij de data leven:
NOT NULL, uniqueCHECK-constraints voor geldige bereiken/statenBij flexibele structuren verschuiven meer regels naar applicatiecode (validatie, versioned payloads, backfills). Dat versnelt vroege iteratie, maar vergroot de testlast en het risico op drift tussen services.
Gebruik transacties wanneer meerdere schrijfhandelingen samen moeten slagen of falen (bijv. order + betalingsstatus + voorraadwijziging). Zonder transacties loop je risico op:
Doe bij bijwerkingen (e-mails/webhooks) alles na commit en maak operaties idempotent (veilig om opnieuw uit te voeren).
Kies de simpelste optie die intentie duidelijk houdt:
N+1-queries en impliciet gedrag verbergenVoor kritieke endpoints: inspecteer altijd de SQL die daadwerkelijk wordt uitgevoerd.
Houd schema en code synchroon met migraties die je behandelt als productcode:
Als migraties handmatig of fragiel zijn, drijven omgevingen uiteen en worden deploys risicovol.
Profileer het volledige requestpad, niet alleen de database:
Een database die in 5 ms antwoordt helpt niet als de app 20 queries doet of blokkeert op I/O.
Gebruik een connection pool om vermeerderde connectiekosten per request te vermijden en de database te beschermen onder belasting.
Praktische tips:
Slecht ingestelde pools tonen zich als timeouts en luide fouten bij verkeerspieken.
Gebruik beide lagen:
NOT NULL, CHECK)Dit voorkomt “onmogelijke staten” wanneer requests racen, achtergrondjobs schrijven of een nieuwe endpoint een check vergeet.
Time-box een kleine proof of concept (2–5 dagen) die de echte naden raakt:
Schrijf daarna een één-pagina beslissingsoverzicht zodat toekomstige wijzigingen doelbewust zijn (zie gerelateerde guides in /docs en /blog).