Wat je bouwt: de IDP-webapp in eenvoudige bewoordingen
Een IDP-webapp is de interne “voordeur” naar je engineering-systeem. Het is de plek waar ontwikkelaars kunnen ontdekken wat er al bestaat (services, libraries, omgevingen), de geprefereerde manier volgen om software te bouwen en draaien, en wijzigingen aanvragen zonder door een dozijn tools te hoeven zoeken.
Net zo belangrijk: het is geen alles-in-één vervanging voor Git, CI, cloudconsoles of ticketing. Het doel is wrijving te verminderen door te orkestreren wat je al gebruikt—zodat het juiste pad ook het gemakkelijkste pad wordt.
De problemen die het moet oplossen
De meeste teams bouwen een IDP-webapp omdat het dagelijkse werk vertraagt door:
- Tool-spreiding: de kennis van “waar te klikken” leeft in tribale kennis.
- Langzame onboarding: nieuwe engineers besteden weken aan het leren van processen in plaats van te leveren.
- Inconsistente standaarden: services worden verschillend gemaakt en beheerd, wat betrouwbaarheid en veiligheid bemoeilijkt.
De webapp moet deze problemen omzetten in herhaalbare workflows en duidelijke, doorzoekbare informatie.
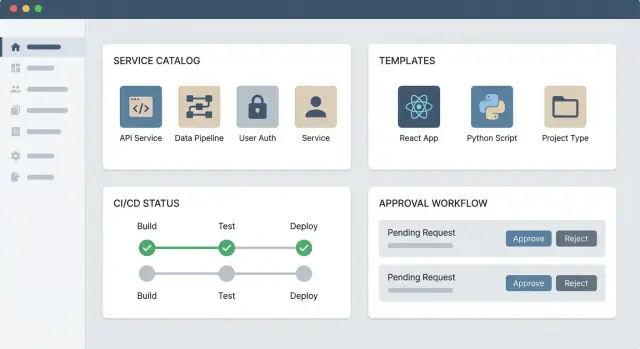
Kernbouwstenen
Een praktische IDP-webapp heeft meestal drie delen:
- Portal-UI: een servicecatalogus, documentatie-entrances en selfservice-formulieren (bijv. “maak een service”, “vraag toegang aan”, “voorzie een database”).
- Backend-API's: de businesslogica die verzoeken valideert, beleid toepast en acties vastlegt.
- Integraties: connectors naar je toolchain (Git-hosting, CI/CD, infrastructuurtools, secrets, incidentmanagement) zodat acties plaatsvinden in de systemen van record.
Wie is eigenaar (en wie niet)
Het platformteam is doorgaans eigenaar van het portalproduct: de ervaring, de API's, de sjablonen en de guardrails.
Productteams zijn eigenaar van hun services: metadata actueel houden, docs/runbooks onderhouden en de aangeboden sjablonen adopteren. Een gezond model is gedeelde verantwoordelijkheid: het platformteam bouwt de geasfalteerde weg; productteams rijden erop en helpen hem te verbeteren.
Gebruikers, use-cases en succesmetrics
Een IDP-webapp slaagt of faalt op basis van of hij de juiste mensen bedient met de juiste “happy paths.” Voordat je tooling kiest of architectuurdiagrammen tekent, wees helder over wie het portaal zal gebruiken, wat ze willen bereiken en hoe je vooruitgang meet.
Primaire gebruikers (en wat ze belangrijk vinden)
De meeste IDP-portals hebben vier kernpublieken:
- Applicatieontwikkelaars: willen snelle, veilige defaults om services te maken en te draaien zonder tickets af te wachten.
- SRE / ops: willen standaardisatie, minder verrassende wijzigingen en duidelijke eigenaarschap bij incidenten.
- Security / compliance: willen consistente controles (toegangreviews, secrets-beheer, auditsporen) zonder de levering te blokkeren.
- Engineeringmanagers / productleads: willen zichtbaarheid—wat bestaat, wie het bezit en of teams betrouwbaar opleveren.
Als je niet in één zin kunt beschrijven hoe elke groep profiteert, bouw je waarschijnlijk een portaal dat optioneel voelt.
Breng 5–10 sleutelreizen in kaart
Kies reizen die wekelijks gebeuren (niet jaarlijks) en maak ze echt end-to-end:
- Maak een nieuwe service vanaf een sjabloon (repo + CI + eigenaarschap + tags).
- Vraag een omgeving aan (dev/stage) met guardrails.
- Bekijk servicegezondheid (deploy-status, alerts, afhankelijkheden).
- Roteer sleutels / secrets met een auditable workflow.
- Vraag toegang aan tot een systeem of dataset met goedkeuringen.
Schrijf elke journey als: trigger → stappen → systemen geraakt → verwacht resultaat → faalmodi. Dit wordt je productbacklog en je acceptatiecriteria.
Definieer succesmetrics die je echt kunt meten
Goede metrics hangen direct samen met tijdsbesparing en verwijderde wrijving:
- Time-to-first-deploy voor een nieuwe service (mediaan, p90).
- Handmatige ticketvolume voor veelvoorkomende verzoeken (en tijd-tot-oplossing).
- Adoptiepercentage: % services geregistreerd, % teams die sjablonen gebruiken.
- Change failure rate en mean time to restore (als het portaal levering standaardiseert).
Schrijf een “versie 1” scope statement
Houd het kort en zichtbaar:
V1 scope: “Een portal die ontwikkelaars in staat stelt een service te creëren vanaf goedgekeurde sjablonen, deze registreert in de servicecatalogus met een eigenaar, en deploy- + gezondheidsstatus toont. Bevat basis RBAC en auditlogs. Sluit op maat gemaakte dashboards, volledige CMDB-vervanging en bespoke workflows uit.”
Dat statement is je filter tegen feature-creep—en je roadmapanker voor wat daarna komt.
MVP-scope en roadmap voor een intern portal
Een intern portal slaagt als het één pijnlijk probleem end-to-end oplost, en dan het recht verdient uit te breiden. De snelste weg is een smalle MVP naar een echt team binnen weken—niet kwartalen.
Een smalle MVP die toch “volledig” voelt
Begin met drie bouwstenen:
- Servicecatalogus: één plek om te ontdekken wat er is, wie het bezit en waar operationele links te vinden zijn.
- Één self-service workflow: kies een hoogfrequente aanvraag (bijv. “maak een nieuwe servicerepo” of “voorzie een standaardomgeving”) en automatiseer die.
- Docs/links-hub: migreer niet alles—link naar bestaande bronnen van waarheid (CI/CD, incidenttools, runbooks) terwijl je leert wat mensen echt gebruiken.
Deze MVP is klein, maar levert een duidelijk resultaat: “Ik kan mijn service vinden en één belangrijke actie uitvoeren zonder in Slack te vragen.”
Als je de UX en workflow-“happy path” snel wilt valideren, kan een vibe-coding platform zoals Koder.ai nuttig zijn om de portal-UI en orkestratieschermen te prototypen op basis van een geschreven workflownorm. Omdat Koder.ai een React-gebaseerde webapp kan genereren met een Go + PostgreSQL-backend en source-code-export ondersteunt, kunnen teams snel itereren en toch langetermijneigendom van de codebasis behouden.
Backlog-structuur: ontdekken, creëren, opereren, govern
Om de roadmap georganiseerd te houden, groepeer werk in vier bakken:
- Ontdekken: zoeken, tags, eigenaarschap, teampagina's, afhankelijkheidsviews.
- Creëren: sjablonen, scaffolding, provisioning van omgevingen, standaardconfiguraties.
- Opereren: links naar dashboards/runbooks, on-call info, SLO-samenvattingen, veelvoorkomende acties.
- Govern: RBAC, goedkeuringsstappen, auditlogs, policy-checks.
Deze structuur voorkomt een portaal dat “alleen catalogus” of “alleen automatisering” is zonder samenhang.
Nu automatiseren vs. linken
Automatiseer alleen wat aan minstens één van deze criteria voldoet: (1) wekelijks herhaald, (2) foutgevoelig bij handmatige uitvoering, (3) vereist multi-team coördinatie. Alles wat anders is, kan een goed samengestelde link naar het juiste tool zijn, met duidelijke instructies en eigenaarschap.
Progressieve verbetering zonder redesign
Ontwerp het portaal zodat nieuwe workflows plug-and-play zijn als extra “acties” op een service- of omgevingspagina. Als elke nieuwe workflow een navigatieherschikking vereist, stokt de adoptie. Behandel workflows als modules: consistente inputs, consistente status, consistente geschiedenis—zodat je meer kunt toevoegen zonder het mentale model te veranderen.
Referentie-architectuur: UI, API's en integraties
Een praktische IDP-portalarchitectuur houdt de gebruikersbeleving simpel en behandelt “rommelige” integratiewerkzaamheden betrouwbaar achter de schermen. Het doel is ontwikkelaars één webapp te geven, ook al strekken acties zich vaak uit over Git, CI/CD, cloud-accounts, ticketing en Kubernetes.
Kies een deploymentmodel
Er zijn drie veelvoorkomende patronen; de juiste keuze hangt af van hoe snel je wilt leveren en hoeveel teams het portaal gaan uitbreiden:
- Enkele app (monolith): snelste MVP. UI, API en integratielogica worden samen geleverd. Goed als het platformteam de meeste features beheert.
- Modulaire services: scheidt UI, core API en een paar integratieservices. Makkelijker schaalbaar en duidelijker eigenaarschap naarmate het portaal groeit.
- Plugin-gebaseerd: een stabiele “core” plus plugins voor catalogusbronnen, scaffolding, docs en workflows. Beste wanneer veel teams bijdragen.
Kerncomponenten (wat waar draait)
Minimaal kun je rekenen op deze bouwblokken:
- Web UI (developer portal): catalogusbrowsen, gouden paden, formulieren, statuspagina's.
- Backend API (vaak achter een API-gateway): auth, RBAC-checks, validatie, orkestratie.
- Integratieworkers: langlopende taken (repo-aanmaak, provisioning) die asynchroon worden uitgevoerd.
- Database: portalconfiguratie, gecachte catalogviews, workflowgeschiedenis, audit-events.
Waar moet state leven
Bepaal vroeg wat het portaal “beheert” versus wat het slechts toont:
- Hou bron-van-waarheid in bestaande systemen (Git, cloud IAM, CI/CD, Kubernetes, ticketing).
- Sla in de portal DB: workflowverzoeken, status, goedkeuringen, auditlogs en gecachte indexen die de UI snel maken.
Betrouwbaarheid voor integraties
Integraties falen om normale redenen (rate limits, tijdelijke outages, gedeeltelijk succes). Ontwerp voor:
- Retries met backoff en duidelijke foutmeldingen
- Idempotentie (het opnieuw uitvoeren van een verzoek mag geen duplicaten creëren)
- Timeouts en annulering
- Duurzame workflowgeschiedenis zodat gebruikers zien wat er gebeurde en veilig kunnen herstellen
Datamodel: servicecatalogus en eigenaarschap
Je servicecatalogus is de bron van waarheid voor wat er is, wie het bezit en hoe het in het systeem past. Een helder datamodel voorkomt “mystery services”, dubbele entries en kapotte automatiseringen.
Definieer de kern-Service entiteit
Begin met overeenstemming over wat een “service” betekent in jouw organisatie. Voor de meeste teams is het een deploybaar onderdeel (API, worker, website) met een lifecycle.
Model minimaal deze velden:
- Naam + beschrijving (menselijk leesbaar)
- Eigenaren: een primair team, plus optionele secundaire contactpersonen (on-call groep, tech lead)
- Bronrepositories: één of meerdere repo-links/IDs
- Runtime-omgevingen: dev/stage/prod, of regio-specifieke varianten
- Afhankelijkheden: upstream/downstream services en gedeelde libraries
Voeg praktische metadata toe die portals aandrijft:
- Lifecycle (experimental, active, deprecated)
- Criticality/tier (voor supportverwachtingen en governance)
- Links (runbooks, dashboards, SLO's, incidentkanaal)
Modelleer relaties expliciet
Behandel relaties als eersteklas, niet alleen als tekstvelden:
- Services ↔ teams: veel services per team; soms gedeeld eigenaarschap (gebruik
primary_owner_team_id plus additional_owner_team_ids).
- Services ↔ resources: verbind met cloudresources (Kubernetes-namespaces, queues, databases) zodat mensen kunnen beantwoorden “wat gebruikt deze service?”
- Service tiers: sla tier op als een gestructureerde enum en koppel het aan policy (bijv. tier-0 vereist on-call en auditlogs).
Deze relationele structuur maakt pagina's mogelijk zoals “alles in bezit van Team X” of “alle services die deze database aanraken.”
Identifiers en naamgevingsregels
Beslis vroeg over de canonieke ID zodat duplicaten niet verschijnen na imports. Veelvoorkomende patronen:
- Een stabiele slug (bijv.
payments-api) die als uniek wordt afgedwongen
- Een immuteerbare UUID plus een mensvriendelijke slug
- Optioneel: een repo-afgeleide sleutel (
github_org/repo) als repos 1:1 met services zijn
Documenteer naamgevingsregels (toegestane karakters, uniciteit, hernoembeleid) en valideer ze bij creatie.
Plan hoe data actueel blijft
Een servicecatalogus faalt wanneer hij verouderd raakt. Kies één of combineer:
- Geplande imports (nachtelijke sync van Git, CI/CD, cloud-inventory)
- Webhooks (update bij repo-wijzigingen, deploys, eigendomswijzigingen)
- Event streams (publiceer events zoals “service.created” of “dependency.updated”)
Bewaar last_seen_at en data_source per record zodat je versheid kunt tonen en conflicten kunt debuggen.
Authenticatie, autorisatie en auditability
Test de Portal-UX Snel
Bouw een React-portal-UI en iterereer op formulieren en navigatie in uren, niet weken.
Als je IDP-webapp vertrouwd moet worden, heeft het drie zaken nodig die samenwerken: authenticatie (wie ben je?), autorisatie (wat mag je doen?) en auditability (wat is er gebeurd en door wie?). Krijg deze zaken vroeg goed en je voorkomt herwerk later—vooral wanneer het portaal productie-wijzigingen gaat uitvoeren.
Standaardiseer op SSO met groepsmapping
De meeste bedrijven hebben al identity-infrastructuur. Gebruik die.
Maak SSO via OIDC of SAML de standaard inlogweg en haal groepslidmaatschap uit je IdP (Okta, Azure AD, Google Workspace, etc.). Map groepen naar rollen en teamlidmaatschap in het portaal.
Dit vereenvoudigt onboarding (“log in en je zit meteen in de juiste teams”), voorkomt wachtwoordopslag en laat IT globale policies afdwingen zoals MFA en sessietimeouts.
Definieer duidelijke rollen (en wat ze mogen)
Vermijd een vaag “admin vs iedereen”-model. Een praktisch setje rollen voor een intern developer platform is:
- Developer: browse het portal, gebruik sjablonen en self-service workflows binnen toegestane scopes.
- Service Owner: beheer een servicecatalogus-entry (metadata, on-call, links, lifecycle), zie service-specifieke geschiedenis.
- Approver: keur gevoelige verzoeken goed of af (prod-toegang, nieuwe omgevingen, kostverhogende resources).
- Platform Admin: beheer sjablonen, integraties, globale instellingen en policy-standaarden.
- Auditor: read-only toegang tot auditlogs, goedkeuringen en configuratiegeschiedenis.
Houd rollen klein en begrijpelijk. Je kunt altijd uitbreiden, maar een verwarrend model verlaagt adoptie.
RBAC plus resource-niveau permissies
Role-based access control (RBAC) is noodzakelijk, maar niet voldoende. Je portaal heeft ook resource-niveau permissies nodig: toegang moet geschaald zijn naar een team, een service of een omgeving.
Voorbeelden:
- Een ontwikkelaar kan een “maak sandbox-omgeving” workflow starten voor de services van zijn/haar team, maar niet voor anderen.
- Een service-eigenaar kan de servicecatalogus-entry voor hun services bewerken.
- Een approver kan alleen verzoeken goedkeuren voor specifieke cost centers of production-namespaces.
Implementeer dit met een eenvoudige policy-pattern: (principal) can (action) on (resource) if (condition). Begin met team/service-scoping en breid uit.
Auditsporen voor gevoelige acties
Behandel auditlogs als een eersteklasse feature, niet als backend-detail. Je portaal moet vastleggen:
- Wie een self-service workflow initieerde (en van waar)
- Ingediende parameterwaarden (secrets redigeerd)
- Wie goedkeurde/weigerde en eventuele opmerkingen
- Resulterende wijzigingen (links naar CI/CD-runs, tickets of infrastructuurwijzigingen)
- Wijzigingen aan sjablonen, permissies en integraties
Maak auditsporen gemakkelijk toegankelijk vanuit de plekken waar mensen werken: een servicepagina in het developer portal, een workflow-“History” tab en een admin-view voor compliance. Dit versnelt ook incidentreviews wanneer iets stukgaat.
UX-design voor ontwikkelaars: maak het juiste pad gemakkelijk
Een goed IDP-portal-UX draait niet om uiterlijk, maar om het verminderen van wrijving bij het shippen. Ontwikkelaars moeten snel drie vragen kunnen beantwoorden: Wat bestaat er? Wat kan ik aanmaken? Wat heeft nu aandacht nodig?
Ontwerp navigatie rond echte taken
In plaats van menu's te organiseren per backend-systeem (“Kubernetes,” “Jira,” “Terraform”), structureer het portaal rond het werk dat ontwikkelaars echt doen:
- Ontdekken: vind services, API's, docs, eigenaren, runbooks
- Creëren: start een nieuwe service, voeg een endpoint toe, vraag een database aan
- Opereren: bekijk gezondheid, incidenten, deploy-status, recente wijzigingen
- Govern: permissies, compliance-checks, policy-excepties
Deze taakgebaseerde navigatie maakt onboarding ook makkelijker: nieuwe teamleden hoeven je toolchain niet te kennen om aan de slag te gaan.
Maak eigenaarschap onmogelijk te missen
Elke servicepagina moet duidelijk tonen:
- Eigentem en teamkanaal
- On-call-rotatie en escalatiepad
- Primaire repo('s) en deploymenttarget
Plaats dit “Wie bezit dit?”-paneel bovenaan, niet verborgen in een tab. Bij incidenten telt elke seconde.
Zoek, filters en status die overeenkomen met hoe mensen denken
Snelle zoekfunctie is het krachtigste kenmerk van het portaal. Ondersteun filters die ontwikkelaars natuurlijk gebruiken: team, lifecycle (experimental/production), tier, taal, platform en “in mijn bezit.” Voeg duidelijke statusindicatoren toe (healthy/degraded, SLO at risk, blocked by approval) zodat gebruikers snel kunnen scannen.
Vraag bij het creëren alleen wat echt nu nodig is. Gebruik sjablonen (“gouden paden”) en defaults om vermijdbare fouten te voorkomen—naamconventies, logging/metrics hooks en standaard CI-instellingen moeten vooraf ingevuld zijn, niet opnieuw getypt. Als een veld optioneel is, verberg het dan onder “Geavanceerde opties” zodat de happy path snel blijft.
Self-service workflows: sjablonen, goedkeuringen en geschiedenis
Voldoe aan Regionale Compliance
Draai je app in het land dat je nodig hebt om aan privacy-eisen te voldoen.
Self-service is waar een intern developer platform vertrouwen verdient: ontwikkelaars moeten veelvoorkomende taken end-to-end kunnen afronden zonder tickets te openen, terwijl platformteams controle houden over veiligheid, compliance en kosten.
Kies eerst de workflow-types die ertoe doen
Begin met een kleine set workflows die veel voorkomen en veel wrijving geven. Typische “eerste vier”:
- Create service: scaffold een repo, registreer in de servicecatalogus, stel eigenaarschap in en bootstrap CI/CD.
- Provision environment: draai een dev/stage-omgeving op met standaardnetwerk, logging en budgetten.
- Request access: geef least-privilege toegang tot een systeem (database, queue, third-party API) met een vervaldatumoptie.
- Rotate secrets: start rotatie, update downstream configuraties en valideer dat applicaties nadien gezond zijn.
Deze workflows moeten gedecideerd zijn en je gouden pad weerspiegelen, terwijl gecontroleerde keuzes mogelijk blijven (taal/runtime, regio, tier, data-classificatie).
Definieer een workflowcontract (zodat sjablonen voorspelbaar blijven)
Behandel elke workflow als een product-API. Een duidelijk contract maakt workflows herbruikbaar, testbaar en makkelijker te integreren met je toolchain.
Een praktisch contract bevat:
- Inputs: getypte velden met defaults (bijv. service name, owner team, environment, data sensitivity).
- Validatie: naamgevingsregels, toegestane regio's, quota-checks en “bestaat dit al?”-checks.
- Stappen: een reeks acties (draai een sjabloon, roep CI/CD aan, maak cloudresources aan, update de servicecatalogus).
- Outputs: artefacten en links die ontwikkelaars nodig hebben (repo-URL, deployment-URL, runbook-link, aangemaakte resources).
Houd de UX gefocust: toon alleen inputs die de ontwikkelaar daadwerkelijk kan bepalen en leid de rest af uit de servicecatalogus en policy.
Goedkeuringen die snel, duidelijk en afdwingbaar zijn
Goedkeuringen zijn onvermijdelijk voor bepaalde acties (productietoegang, gevoelige data, kostenverhogingen). Het portaal moet goedkeuringen voorspelbaar maken:
- Wie keurt wat goed: definieer regelgebaseerde approvers (team owner, systeem-eigenaar, security) in plaats van ad-hoc pings.
- Tijdslimieten: stel een SLA voor goedkeuring en laat verlopen verzoeken automatisch vervallen.
- Escalatie: als de primaire approver afwezig is, routeer naar een backupgroep of on-call-rotatie.
Belangrijk: goedkeuringen moeten deel uitmaken van de workflow-engine, niet een handkanaal. De ontwikkelaar moet status, volgende stappen en reden van goedkeuring zien.
Sla geschiedenis en resultaten op zodat teams zelf kunnen debuggen
Elke workflowrun moet een permanent record opleveren:
- Gebruikte inputs, validatieresultaten en approver-beslissingen
- Stapsgewijze logs (met secrets geredigeerd)
- Eindsresultaten, aangemaakte resources en eventuele rollback-acties
Deze geschiedenis wordt je “paper trail” en je support-systeem: wanneer iets faalt, kunnen ontwikkelaars precies zien waar en waarom—vaak lossen ze problemen op zonder een ticket te maken. Het geeft platformteams ook data om sjablonen te verbeteren en terugkerende fouten te signaleren.
Een IDP-portaal voelt pas “echt” wanneer het kan lezen uit en handelen op de systemen die ontwikkelaars al gebruiken. Integraties veranderen een catalogusentry in iets dat je kunt deployen, observeren en ondersteunen.
Begin met een duidelijk integratie-checklist
De meeste portals hebben een basisset verbindingen nodig:
- Git (repos, default branches, CODEOWNERS, pull requests)
- CI/CD (pipelines, build-status, artefacten, promoties)
- Kubernetes (clusters, namespaces, workloads, rollouts)
- Cloud (accounts/projects, netwerken, managed services)
- IAM (teams, groepen, SSO, rol-mapping)
- Secrets (vaults, secret-referenties, rotatiestatus)
Wees expliciet over wat read-only is (bijv. pipeline-status) versus wat write is (bijv. trigger een deployment).
Geef de voorkeur aan API-first; gebruik webhooks of sync waar nodig
API-first integraties zijn makkelijker te testen en te begrijpen: je kunt auth, schema's en foutafhandeling valideren.
Gebruik webhooks voor near-real-time events (PR gemerged, pipeline klaar). Gebruik geplande sync voor systemen die geen push ondersteunen of waar eventual consistency acceptabel is (bijv. nachtelijke import van cloudaccounts).
Bouw een connectorlaag (bake vendors niet in je core)
Maak een dunne “connector” of “integratieservice” die vendor-specifieke details normaliseert naar een stabiel intern contract (bijv. Repository, PipelineRun, Cluster). Dit isoleert veranderingen wanneer je tools migreert en houdt je portal UI/API schoon.
Een praktisch patroon is:
- Portaal roept je connector aan
- Connector handelt auth, rate limits, retries en mapping af
- Connector retourneert genormaliseerde data + actieerbare links (bijv.
/deployments/123)
Documenteer faalmodi en wat gebruikers moeten doen
Elke integratie moet een kleine runbook hebben: wat “gedegradeerd” betekent, hoe het in de UI wordt getoond en wat te doen.
Voorbeelden:
- Git API rate-limited: portaal toont gecachte repo-data; gebruiker kan nog steeds de catalogus bladeren, maar “Maak vanaf sjabloon” is uitgeschakeld.
- CI/CD down: portaal biedt een handmatige fallback (link naar pipeline-UI) en legt retry-timing uit.
- Secrets manager onbereikbaar: blokkeer wijzigingen die nieuwe secrets vereisen; sta read-only toegang toe tot servicemetadata.
Houd deze docs dicht bij het product (bijv. /docs/integrations) zodat ontwikkelaars niet hoeven te gokken.
Observability: monitoring van het portaal en zijn automatiseringen
Je IDP-portaal is niet alleen een UI—het is een orkestratielaag die CI/CD-jobs triggert, cloudresources maakt, een servicecatalogus bijwerkt en goedkeuringen afdwingt. Observability stelt je in staat snel en zeker te antwoorden: “Wat gebeurde?”, “Waar is het misgegaan?” en “Wie moet nu handelen?”
Traceer elk verzoek over stappen heen
Instrumenteer elke workflowrun met een correlatie-ID die het verzoek volgt van de portal-UI via backend-API's, goedkeuringschecks en externe tools (Git, CI, cloud, ticketing). Voeg request tracing toe zodat één weergave het volledige pad en de timing van elke stap toont.
Vul traces aan met gestructureerde logs (JSON) die bevatten: workflownaam, run-ID, stapnaam, doelservice, omgeving, actor en resultaat. Dit maakt het makkelijk te filteren op “alle mislukte deploy-template runs” of “alles dat Service X beïnvloedt.”
Metrics die ontwikkelaarspijn weerspiegelen
Basale infra-metrics zijn niet genoeg. Voeg workflow-metrics toe die aan echte uitkomsten gelinkt zijn:
- Aantal runs, slagingspercentage en duur per workflow en stap
- Wachtijd voor goedkeuring versus uitvoeringstijd (helpt knelpunten te identificeren)
- Retries, timeouts en rate limits van connectors
Operationele weergaven in het portaal
Geef platformteams “in één oogopslag” pagina's:
- Workflow-queue: running, queued, failed, awaiting approval
- Connector-gezondheid: token-validiteit, laatste succesvolle call, errorrate
- Sync-status: laatste catalogus-sync, gedetecteerde drift, backloggrootte
Koppel elke status aan detailpagina's en de exacte logs/traces voor die run.
Alerts, retentie en audit
Stel alerts in voor gebroken integraties (bijv. herhaalde 401/403), vastgelopen goedkeuringen (geen actie voor N uur) en sync-fouten. Plan dataretentie: bewaar high-volume logs korter, maar bewaar audit-events langer voor compliance en onderzoeken, met duidelijke toegangscontroles en exportopties.
Security en governance zonder teams te vertragen
Verlaag Kosten terwijl je Leert
Verdien credits door te delen wat je hebt gebouwd of anderen uit te nodigen Koder.ai te proberen.
Security in een IDP-portaal werkt het beste wanneer het aanvoelt als “guardrails”, niet als poorten. Het doel is risicovolle keuzes te verminderen door het veilige pad het makkelijkste pad te maken—terwijl teams autonomie behouden om te leveren.
De meeste governance kan plaatsvinden op het moment dat een ontwikkelaar iets aanvraagt (een nieuwe service, repository, omgeving of cloudresource). Behandel elk formulier en elke API-call als onbetrouwbare input.
Dwing standaarden af in code, niet in docs:
- Vereis eigenaarschap (team, on-call en escalatiecontact) en blokkeer creatie als dit ontbreekt.
- Valideer naamgevingsconventies (servicenamen, repo-namen, omgevingen) om botsingen en verwarring te voorkomen.
- Vereis tags/metadata voor kostenallocatie, compliance en discovery.
- Weiger verzoeken die niet aan minimaal beleid voldoen (bijv. “publieke blootstelling” vereist extra review).
Dit houdt je servicecatalogus schoon en maakt audits later veel eenvoudiger.
Bescherm secrets by design
Een portaal raakt vaak credentials (CI-tokens, cloudtoegang, API-keys). Behandel secrets als radioactief:
- Log nooit secrets of neem ze op in foutmeldingen.
- Geef de voorkeur aan kortdurende tokens (OIDC, gefedereerde toegang, tijdgebonden credentials) boven langlevende sleutels.
- Sla secrets alleen op in een dedicated secretmanager; het portaal verwijst ernaar, kopieert ze niet.
Zorg er ook voor dat je auditlogs vastleggen wie wat en wanneer deed—zonder secretwaarden op te nemen.
Threatmodel realistische fouten
Focus op realistische risico's:
- Privilege-escalatie door verkeerd geconfigureerde RBAC en te brede permissies.
- Gespoofte webhooks of callbacks die acties triggeren zonder verificatie.
- Data-lekken via debug-endpoints, te verbos logs of te ruime zoekmogelijkheden.
Beperk risico's met ondertekende webhook-verificatie, least-privilege rollen en strikte scheiding tussen “read” en “change” operaties.
Verschuif checks naar links met CI en permissiereviews
Draai securitychecks in CI voor je portalcode en voor gegenereerde sjablonen (linting, policy-checks, dependency-scans). Plan vervolgens regelmatige reviews van:
- RBAC-rollen en groepsmapping
- Sjabloonpermissies (wie kan wat maken)
- “Break-glass” admin-toegang en rotatieprocedures
Governance is houdbaar als het routinematig, geautomatiseerd en zichtbaar is—niet een eenmalig project.
Rollout, adoptie en langetermijnonderhoud
Een developer portal levert alleen waarde als teams het daadwerkelijk gebruiken. Behandel rollout als een productlancering: begin klein, leer snel en schaal op basis van bewijs.
Begin met een gefocuste pilot
Piloteer met 1–3 teams die gemotiveerd en representatief zijn (één “greenfield”-team, één legacy-zwaar team, één met strengere compliance-eisen). Observeer hoe zij echte taken uitvoeren—services registreren, infra aanvragen, een deploy triggeren—and fix frictie direct. Het doel is niet feature-volledigheid; het doel is bewijzen dat het portaal tijd bespaart en fouten vermindert.
Maak migratie saai en voorspelbaar
Bied migratiestappen die in een normale sprint passen. Bijvoorbeeld:
- registreer een bestaande service in de servicecatalogus,
- koppel eigenaarschap en on-call-info,
- verbind CI/CD,
- neem één sjabloon aan (repo, pipeline of infra) voor het volgende nieuw component.
Houd “day 2”-upgrades eenvoudig: laat teams geleidelijk metadata toevoegen en vervang bespoke scripts door portal-workflows.
Docs en in-product help die mensen zullen lezen
Schrijf beknopte docs voor de workflows die ertoe doen: “Registreer een service,” “Vraag een database aan,” “Rol een rollback uit.” Voeg in-product hulp toe naast formuliervelden en link naar /docs/portal en /support voor diepere context. Behandel docs als code: versioneer ze, review ze en snoei ze.
Eigenaarschap is een langetermijnverplichting
Plan doorlopend eigenaarschap vanaf het begin: iemand moet de backlog triageren, connectors naar externe tools onderhouden en gebruikers ondersteunen als automatiseringen falen. Definieer SLA's voor portal-incidenten, stel een regelmatige cadence in voor connectorupdates en review auditlogs om terugkerende pijnpunten en beleidslacunes te ontdekken.
Naarmate je portaal volwassen wordt, wil je waarschijnlijk mogelijkheden zoals snapshots/rollback voor portalconfiguratie, voorspelbare deployments en eenvoudige omgevingpromotie over regio's. Als je snel bouwt of experimenteert, kan Koder.ai teams ook helpen interne apps op te zetten met planning mode, deployment/hosting en code-export—handig om portalfeatures te piloten voordat je ze in harde platformcomponenten vastlegt.