Wat er misgaat met usage-billing, in eenvoudige bewoordingen
Usage-billing faalt wanneer het nummer op de factuur niet overeenkomt met wat je product daadwerkelijk leverde. Het verschil kan aanvankelijk klein zijn (een paar ontbrekende API-aanroepen), en groeien naar terugbetalingen, boze supporttickets en een financieel team dat dashboards niet meer vertrouwt.
De oorzaken zijn meestal voorspelbaar. Events verdwijnen omdat een service crashte voordat het gebruik werd gerapporteerd, een queue down was, of een client offline ging. Events worden dubbel geteld omdat retries gebeurden, workers hetzelfde bericht herkenden, of een importjob opnieuw draaide. Tijd voegt zijn eigen problemen toe: klokdrift tussen servers, tijdzones, zomertijd, en laat binnenkomende events die gebruik in de verkeerde facturatieperiode duwen.
Een kort voorbeeld: een chatproduct dat per AI-generatie rekent kan één event uitzenden wanneer een verzoek start en nog één wanneer het klaar is. Als je factureert vanaf het start-event kun je fouten belasten. Als je factureert vanaf het finish-event, kun je gebruik missen wanneer de finale callback nooit arriveert. Als beide in rekening worden gebracht, dubbel je de charge.
Meerdere teams moeten hetzelfde cijfer vertrouwen:
- Klanten hebben facturen nodig die overeenkomen met wat zij vinden dat ze gebruikt hebben.
- Support heeft een duidelijke spoor nodig om “waarom ben ik gefactureerd?” snel te beantwoorden.
- Finance heeft totalen nodig waarmee ze de boeken kunnen sluiten, geen schattingen.
- Engineering heeft signalen nodig die metering-bugs vangen voordat ze geld raken.
Het doel is niet alleen accurate totalen. Het is uitlegbaarheid van facturen en snelle afhandeling van geschillen. Als je een regelitem niet kunt terugleiden naar raw usage, kan één storing je facturering veranderen in giswerk — en dan worden billing-bugs echte incidenten.
Definieer de billable units en de factureringsregels
Begin met één eenvoudige vraag: waar reken je precies voor? Als je de eenheid en de regels niet binnen een minuut kunt uitleggen, zal het systeem gaan raden en zullen klanten het merken.
Kies één primaire billable unit per meter. Veelvoorkomende keuzes zijn API-aanroepen, requests, tokens, minuten compute, GB opgeslagen, GB getransfereerd, of seats. Vermijd samengestelde units (zoals “actieve gebruikers-minuten”) tenzij je ze echt nodig hebt — ze zijn moeilijker te auditen en uit te leggen.
Definieer de grenzen van gebruik. Wees specifiek over wanneer gebruik begint en eindigt: omvat een trial gemeten overages, of is het gratis tot een limiet? Als je een respijtperiode aanbiedt, wordt gebruik tijdens die periode later gefactureerd of vergeven? Wijzigingen in plannen zijn plekken waar verwarring piekt. Beslis of je prorate, allowances direct reset of wijzigingen pas bij de volgende factuur toepast.
Schrijf afrondingsregels en minimums op in plaats van ze impliciet te laten. Bijvoorbeeld: rond omhoog af naar de dichtstbijzijnde seconde, minuut of 1.000 tokens; pas een dagelijkse minimumcharge toe; of handhaaf een minimum factureerbaar increment (zoals 1 MB). Kleine regels zoals deze veroorzaken grote “waarom werd ik gefactureerd?”-tickets.
Regels die het waard zijn vroeg vast te leggen:
- De billable unit en de exacte definitie ervan.
- Wanneer tellen start en stopt (trial, respijt, annulering, planwijziging).
- Afrondingsregels, minimumcharges en gratis tiers.
- Hoe refunds, credits en goodwill-aanpassingen op overages van toepassing zijn.
Voorbeeld: een team zit op Pro en upgradeert halverwege de maand. Als je allowances op upgrade reset, krijgen ze effectief twee gratis allowances in één maand. Als je niet reset, kunnen ze zich gestraft voelen voor upgraden. Beide keuzes kunnen valide zijn, maar het moet consistent, gedocumenteerd en testbaar zijn.
Welke events te tracken (en welke velden je later zult missen)
Bepaal wat telt als een billable event en beschrijf het als data. Als je het verhaal “wat is er gebeurd” niet alleen uit events kunt reconstrueren, ga je tijdens geschillen gokken.
Eventtypes om te registreren
Track meer dan alleen “er was gebruik”. Je hebt ook de events nodig die veranderen wat de klant zou moeten betalen.
- Verbruik (de billable actie: API-call, token, minuut, seat-day, enz.)
- Toegekende credit (promo, make-good, referral)
- Refund of aanpassing (handmatig of geautomatiseerd)
- Planwijziging (upgrade, downgrade, start/einde trial)
- Annulering (en een eventuele einde-dienst timestamp)
Velden die je later gaat missen
De meeste billing-bugs komen door ontbrekende context. Leg de saaie velden nu vast zodat support, finance en engineering later vragen kunnen beantwoorden.
- Tenant- of account-ID, plus optionele user-ID (wie betaalt, wie het triggerde).
- Precisie timestamp in UTC (en een aparte ingest-timestamp).
- Hoeveelheid en eenheid (10 requests, 3.2 GB-uren, 1 seat-day).
- Bron (servicenaam, omgeving en de exacte feature-naam).
- Een stabiele idempotency key (uniek per reële actie) om duplicaten te voorkomen.
Support-waardige metadata betaalt zich terug: request ID of trace ID, regio, app-versie en de versie van de prijsregels die van toepassing waren. Als een klant zegt “ik ben twee keer om 14:03 gefactureerd”, zijn die velden wat je nodig hebt om te bewijzen wat er gebeurde, het veilig terug te draaien en herhaling te voorkomen.
Waar events uit te zenden zodat ze betrouwbaar zijn
De eerste regel is eenvoudig: zend billable events vanuit het systeem dat echt weet dat het werk is gebeurd. Meestal is dat je server, niet de browser of mobiele app.
Client-side tellers zijn makkelijk te faken en makkelijk te verliezen. Gebruikers kunnen requests blokkeren, replayen of oude code draaien. Zelfs zonder kwade opzet crashen mobiele apps, draaien klokken anders en gebeuren retries. Als je een client-signaal moet lezen, behandel het dan als een hint, niet als de factuur.
Een praktische aanpak is om gebruik te emitten wanneer je backend een onomkeerbaar punt passeert, zoals wanneer je een record persistent opslaat, een job voltooit of een response levert die je kunt bewijzen. Vertrouwde emissiepunten zijn onder meer:
- Na een succesvolle write naar de primaire database (de actie is nu duurzaam)
- Nadat een background job is voltooid (niet wanneer deze in de queue staat)
- Bij een API-gateway of backend-endpoint vlak na autorisatie (met de finale statuscode)
- Bij de worker die daadwerkelijk compute verbruikte of een betaalde derde partij API aanriep
- In de billing-service zelf, wanneer deze bevestigt dat een betaalde feature is vrijgegeven
Offline mobiel is de belangrijkste uitzondering. Als een Flutter-app zonder verbinding moet werken, kan die lokaal gebruik bijhouden en later uploaden. Voeg guardrails toe: includeer een uniek event-ID, device-ID en een monotone sequentienummer en laat de server valideren wat mogelijk is (accountstatus, planlimieten, dubbele IDs, onmogelijke timestamps). Wanneer de app weer verbinding heeft, moet de server events idempotent accepteren zodat retries niet dubbel belasten.
Event-timing hangt af van wat gebruikers verwachten te zien. Real-time werkt voor API-calls waar klanten het gebruik in een dashboard volgen. Near-real-time (elke paar minuten) is vaak genoeg en goedkoper. Batch kan werken voor signals met hoog volume (zoals storage-scans), maar wees duidelijk over vertragingen en gebruik dezelfde bron-van-de-waarheid regels zodat late data niet stilletjes oude facturen verandert.
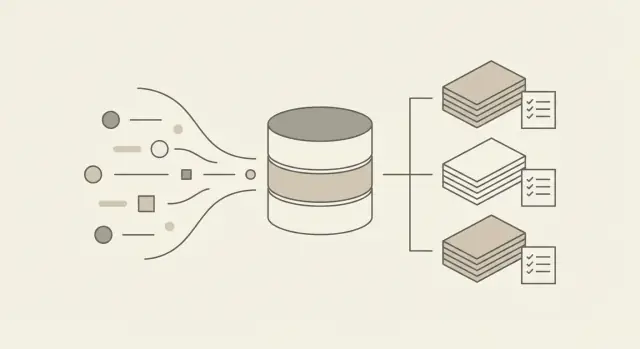
Waar totalen te berekenen: raw events vs geaggregeerd gebruik
Je hebt twee dingen nodig die redundant aanvoelen maar je later helpen: onveranderlijke raw events (wat er gebeurde) en afgeleide totalen (wat je factureert). Raw events zijn je bron van de waarheid. Geaggregeerd gebruik is wat je snel opvraagt, uitlegt aan klanten en omzet naar facturen.
Je kunt totalen op twee gebruikelijke plekken berekenen. In de database (SQL-jobs, materialized tables, geplande queries) rekenen is in het begin eenvoudiger te beheren en houdt de logica dichtbij de data. Een dedicated aggregator-service (een kleine worker die events leest en rollups schrijft) is makkelijker te versieën, testen en schalen, en kan consistente regels afdwingen over producten heen.
Waarom je beide lagen zou moeten houden
Raw events beschermen je tegen bugs, refunds en disputen. Aggregaten beschermen je tegen trage facturen en dure queries. Als je alleen aggregaten opslaat, kan één verkeerde regel geschiedenis permanent beschadigen.
Een praktisch opzet:
- Bewaar append-only raw events.
- Bouw rollups (per uur en per dag) voor snelle rapportage.
- Bouw een factureringsperiode-totaal dat alleen voor facturering wordt gebruikt.
Maak aggregatievensters expliciet. Kies een facturatietijdzone (vaak die van de klant, of UTC voor iedereen) en houd je eraan. “Dag”-grenzen veranderen met tijdzones, en klanten merken het als gebruik tussen dagen verschuift.
Late en out-of-order events zijn normaal (mobiel offline, retries, queuevertragingen). Verander niet stilletjes een oude factuur omdat een laat event binnenkwam. Gebruik een close-and-freeze-regel: zodra een facturatieperiode gefactureerd is, schrijf correcties als een aanpassing op de volgende factuur met een duidelijke reden.
Voorbeeld: als API-calls maandelijks worden gefactureerd, kun je uurlijkse tellingen voor dashboards rollen, dagelijkse tellingen voor alerts en een maandtotaal voor facturering bevriezen. Als 200 calls twee dagen te laat arriveren, registreer ze, maar factureer ze als een +200-aanpassing volgende maand, niet door de factuur van vorige maand te herschrijven.
Een eenvoudige stap-voor-stap metering-pijplijn
Een werkende usage-pijplijn is vooral datastroom met strikte guardrails. Zet de volgorde goed en je kunt later prijzen wijzigen zonder alles handmatig opnieuw te verwerken.
Stap 1: maak events consistent voordat je ze vertrouwt
Wanneer een event binnenkomt, valideer en normaliseer het direct. Controleer verplichte velden, converteer eenheden (bytes naar GB, seconden naar minuten) en klem timestamps vast tot een heldere regel (event time vs ontvangen tijd). Als iets ongeldig is, sla het op als afgewezen met een reden in plaats van het stilletjes te droppen.
Na normalisatie, houd een append-only mindset en “fix” nooit geschiedenis ter plekke. Raw events zijn je bron van de waarheid.
Stappen 2–6 in de praktijk
Deze flow werkt voor de meeste producten:
- Sla immutable raw events op (append-only), inclusief de genormaliseerde payload en de originele payload.
- Dedupe met een idempotency key en een uniciteitsregel (bijvoorbeeld: account_id + event_name + idempotency_key).
- Agregeer in totalen per klant per facturatieperiode (uurlijkse of dagelijkse rollups zijn vaak genoeg).
- Prijs de totalen om naar factuurrij-klaar regels (tiers, inbegrepen bundels, minimums, kortingen).
- Genereer een conceptfactuur die verwijst naar de exacte aggregatieversie die is gebruikt.
Bevries vervolgens de factuurversie. “Bevriezen” betekent een audittrail bewaren die antwoordt: welke raw events, welke dedupe-regel, welke aggregatiecode-versie en welke prijsregels deze regels hebben geproduceerd. Als je later een prijs verandert of een bug fixeert, maak een nieuwe factuurrevisie, geen stille edit.
Hoe dubbele kosten en missend gebruik te voorkomen
Dubbele kosten en missend gebruik komen meestal uit hetzelfde kernprobleem: je systeem kan niet bepalen of een event nieuw, gedupliceerd of kwijt is. Dit gaat minder over slimme billinglogica en meer over strikte controles rond event-identity en validatie.
Idempotency-keys zijn de eerste verdedigingslinie. Genereer een sleutel die stabiel is voor de reële wereldactie, niet de HTTP-request. Een goede sleutel is deterministisch en uniek per billable unit, bijvoorbeeld: tenant_id + billable_action + source_record_id + time_bucket (gebruik een time bucket alleen wanneer de unit tijd-gebaseerd is). Handhaaf dit bij de eerste duurzame schrijf, typisch je ingest-database of eventlog, met een unique constraint zodat duplicaten niet binnenkomen.
Retries en timeouts zijn normaal, dus ontwerp er voor. Een client kan hetzelfde event opnieuw versturen na een 504, zelfs als jij het al ontving. Je regel moet zijn: accepteer herhalingen, maar tel ze niet dubbel. Houd ontvangen apart van tellen: neem eenmaal op (idempotent), aggregeer daarna van opgeslagen events.
Validatie voorkomt “onmogelijke usage” die totalen corrumpeert. Valideer bij ingest en nogmaals bij aggregatie, want bugs gebeuren op beide plekken.
- Weiger negatieve hoeveelheden tenzij je product echt credits of refunds als een apart eventtype ondersteunt.
- Lock eenheden naar één canonieke vorm (seconden vs milliseconden, tokens vs karakters).
- Vereis valuta-achtige precisie-regels (bijvoorbeeld alleen gehele eenheden) waar mogelijk.
- Sta alleen bekende meters en bekende plan-mappingen toe.
Missend gebruik is het moeilijkst te detecteren, behandel ingest-fouten als first-class data. Sla gefaalde events apart op met dezelfde velden als succesvolle (inclusief idempotency key), plus een foutreden en retry-teller.
Reconciliatiecontroles die billing-bugs vroeg vangen
Reconciliatiecontroles zijn de saaie guardrails die “we hebben te veel gefactureerd” en “we hebben usage gemist” vangen voordat klanten het merken.
Begin met het reconciliëren van hetzelfde tijdvenster op twee plekken: raw events en geaggregeerd gebruik. Kies een vast venster (bijvoorbeeld gisteren in UTC), en vergelijk aantallen, sommen en unieke IDs. Kleine verschillen gebeuren (late events, retries), maar ze moeten verklaard worden door bekende regels, niet mysterieus zijn.
Vervolgens reconcilieer je wat je factureerde tegen wat je geprijsd hebt. Een factuur moet reproduceerbaar zijn uit een geprijsde usage-snapshot: de exacte usage-totalen, de exacte prijsregels, de exacte valuta en de exacte afronding. Als de factuur verandert wanneer je de berekening later opnieuw draait, heb je geen factuur maar een schatting.
Dagelijkse sanity-checks vangen issues die geen “verkeerde wiskunde” zijn maar “vreemde realiteit”:
- Nul-verbruik voor een normaal actieve klant (mogelijke ingest-fout).
- Plotselinge pieken (mogelijke dubbele events of retry-storm).
- Plotselinge dalen direct na een deploy (mogelijke meter-naamwijziging of filterbug).
- Uitschieters vergeleken met de eigen historie van de klant (mogelijke tijdvensterfout).
- Uitschieters vergeleken met vergelijkbare klanten (mogelijke prijs-tier mapping-bug).
Als je een probleem vindt, heb je een backfill-proces nodig. Backfills moeten opzettelijk en gelogd zijn. Registreer wat er veranderde, welk venster, welke klanten, wie het triggerde en waarom. Behandel aanpassingen als boekhoudposten, niet als stille edits.
Een eenvoudige geschillenworkflow houdt support rustig. Als een klant een charge betwist, moet je hun factuur kunnen reproduceren uit raw events met dezelfde snapshot en prijsversie. Dat verandert een vaag complaint in een oplosbare bug.
Algemene fouten en valkuilen (zodat jij ze niet in productie leert)
De meeste factureringsbranden worden niet veroorzaakt door complexe wiskunde. Ze komen van kleine aannames die alleen breken op het slechtste moment: het einde van de maand, na een upgrade, of tijdens een retry-storm. Voorzichtig blijven gaat meestal over het kiezen van één waarheid voor tijd, identiteit en regels, en daar niet vanaf wijken.
Valkuilen die verkeerde facturen creëren
Deze komen keer op keer voor, zelfs bij volwassen teams:
- De verkeerde timestamp gebruiken: Als je factureert op ingest-tijd in plaats van event-tijd, kan een vertraagde batch echt gebruik naar de volgende maand duwen. Kies één “facturatietijd”-veld, documenteer het en houd ingest-tijd alleen voor debugging.
- Dezelfde actie twee keer tellen: Het is makkelijk om te meter-en bij de API-gateway en ook binnen de app-service. Als beide billable events uitzenden, double charge je. Beslis welke laag de waarheid is voor elke unit.
- Planwijzigingen die totalen breken: Upgrades halverwege de cyclus kunnen een maand in twee regelsplitsen. Als je de nieuwe prijs op de hele maand toepast, merken klanten het. Je hebt prorateregels en duidelijke “effective from”-tijden nodig.
- Geschiedenis per ongeluk herschrijven: Als je prijsregels niet versieert, kunnen reruns en backfills oude facturen met nieuwe prijzen herrekenen. Sla de prijsversie op die voor elke factuurregel is gebruikt.
- De realiteit van falen niet testen: Retries, partial failures, concurrency en backfills zijn normaal. Als je pijplijn niet idempotent is, kan hetzelfde event dubbel gefactureerd of stilletjes weggegooid worden.
Voorbeeld: een klant upgradeert op de 20e en je event-processor probeert een dag data opnieuw na een timeout. Zonder idempotency-keys en versieering van regels kun je de 19e dupliceren en het 1–19-interval tegen het nieuwe tarief prijzen.
Voorbeeld: echte usage-events omzetten naar een factuur
Hier is een simpel voorbeeld voor één klant, Acme Co, gefactureerd op drie meters: API-calls, opslag (GB-days) en premium feature-runs.
Dit zijn de events die je app op één dag (5 jan) uitstuurde. Let op de velden die het verhaal later makkelijk te reconstrueren maken: event_id, customer_id, occurred_at, meter, quantity en een idempotency key.
{"event_id":"evt_1001","customer_id":"cust_acme","occurred_at":"2026-01-05T09:12:03Z","meter":"api_calls","quantity":1,"idempotency_key":"req_7f2"}
{"event_id":"evt_1002","customer_id":"cust_acme","occurred_at":"2026-01-05T09:12:03Z","meter":"api_calls","quantity":1,"idempotency_key":"req_7f2"}
{"event_id":"evt_1003","customer_id":"cust_acme","occurred_at":"2026-01-05T10:00:00Z","meter":"storage_gb_days","quantity":42.0,"idempotency_key":"daily_storage_2026-01-05"}
{"event_id":"evt_1004","customer_id":"cust_acme","occurred_at":"2026-01-05T15:40:10Z","meter":"premium_runs","quantity":3,"idempotency_key":"run_batch_991"}
Aan het einde van de maand groepeert je aggregatiejob raw events op customer_id, meter en facturatieperiode. De totalen voor januari zijn sommen over de maand: API-calls tellen op naar 1.240.500; storage GB-days naar 1.310.0; premium runs naar 68.
Nu arriveert er op 2 febr een laat event dat bij 31 jan hoort (een mobiele client was offline). Omdat je aggregeert op occurred_at (niet ingest-tijd), veranderen de januari-totals. Je kiest of (a) je een aanpassingsregel genereert op de volgende factuur of (b) je januari heruitgeeft als je beleid dat toestaat.
Reconciliatie vangt hier een bug: evt_1001 en evt_1002 delen dezelfde idempotency_key (req_7f2). Je check markeert “twee billable events voor één request” en markeert er één als duplicate voordat je factureert.
Support kan het simpel uitleggen: “We zagen hetzelfde API-verzoek twee keer gerapporteerd door een retry. We verwijderden het dubbele event, dus je wordt één keer gefactureerd. Je factuur bevat een aanpassing die het gecorrigeerde totaal weergeeft.”
Snelle checklist voordat je usage-billing live zet
Behandel je usagesysteem als een klein financieel grootboek. Als je niet dezelfde raw data kunt replayen en hetzelfde totaal krijgt, ga je nachten besteden aan het achtervolgen van “onmogelijke” charges.
Gebruik deze checklist als laatste gate:
- Elk event is compleet en traceerbaar. Elk record bevat klant-ID, timestamp (met tijdzone), eenheidsnaam, hoeveelheid, bron (service/job naam) en een idempotency key zodat retries geen extra usage maken.
- Raw events zijn append-only. Geen edits, geen deletes. Als iets gecorrigeerd moet worden, schrijf een nieuwe aanpassing event. Aggregaten moeten afgeleid zijn van raw events en reproduceerbaar zijn vanaf nul.
- Totalen komen overeen op drie plekken. Voor een steekproef van klanten en dagen matchen raw-event-totalen je geaggregeerde tabellen en beide komen overeen met de “invoice snapshot” die bij facturering is opgeslagen.
- Planwijzigingen en geldbewegingen zijn expliciete events. Upgrades, downgrades, halverwege-prorations, refunds en credits zijn gemodelleerd als events (of grootboekposten), niet verborgen logica in een billing-script.
- Je hebt veiligheidsalarms. Alerts triggeren bij ontbrekende ingest (geen events wanneer er wel zouden moeten zijn), plotselinge pieken of dalen, negatieve totalen en herhaalde idempotency-keys. Neem een dagelijkse reconciliatiejob op die deltas rapporteert, niet alleen pass/fail.
Een praktische test: kies één klant, replay de laatste 7 dagen raw events in een schone database en genereer usage en een factuur. Als het resultaat verschilt van productie, heb je een determinismeprobleem, geen rekenprobleem.
Volgende stappen: veilig uitrollen en itereren zonder verrassingen
Behandel de eerste release als een pilot. Kies één billable unit (bijvoorbeeld “API-calls” of “GB opgeslagen”) en één reconciliatierapport dat vergelijkt wat je verwachtte te factureren vs wat je daadwerkelijk factureerde. Zodra dat een hele cyclus stabiel blijft, voeg je de volgende unit toe.
Maak support en finance succesvol op dag één door ze een eenvoudige interne pagina te geven die beide zijden toont: raw events en de berekende totalen die op de factuur terechtkomen. Als een klant vraagt “waarom ben ik gefactureerd?”, wil je één scherm dat het in minuten beantwoordt.
Voordat je echt geld int, replay reality. Gebruik staging-data om een volledige maand usage te simuleren, run je aggregatie, genereer facturen en vergelijk met wat je handmatig zou verwachten voor een kleine steekproef accounts. Kies een paar klanten met verschillende patronen (laag, piek, stabiel) en verifieer dat hun totalen consistent zijn tussen raw events, dagelijkse aggregaten en factuurregels.
Als je de metering-service zelf bouwt, kan een vibe-coding platform zoals Koder.ai (koder.ai) een snelle manier zijn om een intern admin-UI prototype te maken en een Go + PostgreSQL backend, en daarna de broncode te exporteren zodra de logica stabiel is.
Wanneer prijsregels wijzigen, verlaag het risico met een release-routine:
- Maak een snapshot van de huidige regels en aggregatielogica voordat je verandert.
- Doe een volledige-maandreplay in staging met de nieuwe regels.
- Vergelijk oude vs nieuwe facturen voor dezelfde periode.
- Roll back snel als totalen afwijken of reconciliatie faalt.
- Breid naar nieuwe units pas uit na één schone facturatiecyclus.