Wat maakt in-app zoeken traag of waardeloos
Mensen zeggen dat zoeken direct moet aanvoelen, maar ze bedoelen zelden nul milliseconden. Ze bedoelen dat ze snel een duidelijke reactie krijgen, genoeg om nooit te twijfelen of de app hen hoorde. Als er binnen ongeveer een seconde iets zichtbaars gebeurt (resultaten updaten, een laadhint, of een stabiele ‘zoeken’ status), blijven de meeste gebruikers vertrouwend en blijven typen.
Zoeken voelt traag wanneer de UI je in stilte laat wachten of chaotisch reageert. Een snelle backend helpt niet als het invoerveld hapert, de lijst rondspringt of resultaten blijven resetten terwijl iemand typt.
De meest voorkomende slechte zoek-symptomen
Een paar patronen komen telkens terug:
- Typvertraging: de cursor haperen omdat de app te veel werk doet bij elke toetsaanslag.
- Flikkering: de lijst wordt herhaaldelijk geleegd en opnieuw gevuld, waardoor de gebruiker zijn plek verliest.
- Verouderde resultaten: de UI toont resultaten voor een oudere query omdat responses uit volgorde terugkomen.
- Verkeerde matches: het bovenste resultaat lijkt willekeurig, dus gebruikers verliezen vertrouwen.
- Doodlopende paden: geen-resultaten geven geen richting, dus gebruikers weten niet wat ze vervolgens moeten proberen.
Dit doet ertoe, zelfs bij kleine datasets. Met slechts een paar honderd items gebruiken mensen zoeken nog steeds als een snelkoppeling, niet als een laatste redmiddel. Als het onbetrouwbaar aanvoelt, schakelen ze over op scrollen, filters, of geven ze op. Kleine datasets leven ook vaak op mobiel en in energiearme apparaten, waar onnodig werk bij elke toetsaanslag sterker opvalt.
Je kunt veel oplossen voordat je een speciale zoekengine toevoegt. Het meeste van de snelheid en bruikbaarheid komt van UX en verzoekcontrole, niet van slimme indexering.
Maak de interface eerst voorspelbaar: houd het invoerveld responsief, vermijd het te vroeg leegmaken van resultaten, en toon een rustige laadstatus alleen wanneer dat nodig is. Verminder daarna verspild werk met debounce en annulering zodat je niet bij elke druk op de toets zoekt. Voeg een kleine cache toe zodat herhaalde queries direct aanvoelen (zoals wanneer gebruikers backspacen). Gebruik ten slotte eenvoudige rangschikkingsregels (exacte match boven gedeeltelijke match, starts-with boven contains) zodat de bovenste resultaten logisch zijn.
Stel eenvoudige doelen en grenzen voor versie 1
Snelheidsfixes helpen niet als je zoekfunctie probeert alles te doen. Versie 1 werkt het beste wanneer scope, kwaliteitsnorm en limieten expliciet zijn.
Kies een scope die bij de taak past
Bepaal waar zoeken voor is. Is het een snelle picker om een bekend item te vinden, of is het bedoeld om veel content te verkennen?
Voor de meeste apps is zoeken in een paar verwachte velden voldoende: titels, namen en belangrijkste identificatoren. In een CRM kan dat contactnaam, bedrijf en e-mail zijn. Full-text zoeken in notities kan wachten tot je bewijs ziet dat mensen het nodig hebben.
Definieer “goed genoeg” relevantie
Je hebt geen perfecte ranking nodig om uit te brengen. Wel resultaten die eerlijk aanvoelen.
Gebruik regels die je kunt uitleggen als iemand vraagt waarom iets verscheen:
- Exacte match eerst ("Alex Kim" verslaat "Alexandra")
- Starts-with daarna ("pro" matcht "Project")
- Contains daarna ("jet" matcht "Budget")
- Recent gebruikte of vastgezette items krijgen een kleine boost
- Breek gelijke scores op alfabet of recentie
Deze basis verwijdert verrassingen en vermindert het gevoel van willekeur.
Stel limieten vroeg vast (en laat ze zien in de UI)
Grenzen beschermen de performance en voorkomen dat randgevallen de ervaring kapotmaken.
Bepaal vroeg dingen als maximaal aantal resultaten (vaak 20–50), maximale querylengte (bijv. 50–100 tekens) en minimale querylengte voordat je zoekt (vaak 2). Als je resultaten limiteert tot 25, zeg dat dan (bijvoorbeeld "Top 25 resultaten") in plaats van te impliceren dat je alles hebt doorzocht.
Plan voor offline en slechte verbindingen
Als de app op treinen, in liften of op zwakke Wi-Fi gebruikt kan worden, definieer dan wat er nog werkt. Een praktische versie 1 keuze is: recente items en een kleine gecachte lijst zijn offline doorzoekbaar, terwijl alles anders een verbinding nodig heeft.
Bij een slechte verbinding, vermijd het leegmaken van het scherm. Houd de laatste goede resultaten zichtbaar en toon een duidelijke boodschap dat resultaten mogelijk verouderd zijn. Dat voelt rustiger dan een lege staat die op falen lijkt.
Debounce en verzoekcontrole zonder vertraging
De snelste manier om in-app zoeken traag te laten voelen is een netwerkverzoek bij elke toetsaanslag sturen. Mensen typen in bursts en de UI begint te flikkeren tussen gedeeltelijke resultaten. Debounce lost dit op door even te wachten na de laatste toetsaanslag voordat er gezocht wordt.
Een goed startpunt is 150–300ms. Korter kan nog steeds verzoeken spammen, langer begint te voelen alsof de app invoer negeert. Als je data grotendeels lokaal is (al in geheugen), kun je lager gaan. Als elke query de server raakt, blijf dichter bij 250–300ms.
Debounce werkt het beste met een minimum querylengte. Voor veel apps zijn 2 tekens genoeg om nutteloze zoekopdrachten als "a" te vermijden die alles teruggeven. Als gebruikers vaak zoeken op korte codes (zoals "HR" of "ID"), sta 1–2 tekens toe, maar alleen nadat ze even gepauzeerd hebben.
Verzoekcontrole is even belangrijk als debounce. Zonder controle arriveren langzame responses uit volgorde en overschrijven ze nieuwere resultaten. Als een gebruiker "car" typt en snel nog een "d" toevoegt tot "card", kan de "car" response als laatste binnenkomen en de UI terugduwen.
Gebruik een van deze patronen:
- Annuleer lopende verzoeken wanneer een nieuwe query start.
- Volg een request-ID en render alleen resultaten van het nieuwste verzoek.
- Houd de laatste querystring bij en negeer responses die er niet bij passen.
Geef tijdens het wachten directe feedback zodat de app responsief aanvoelt voordat resultaten binnen zijn. Blokkeer typen niet. Toon een klein inline spinner in het resultatengebied of een korte hint zoals "Zoeken...". Als je de vorige resultaten op het scherm houdt, label ze subtiel (bijvoorbeeld "Toont eerdere resultaten") zodat gebruikers niet in de war raken.
Een praktisch voorbeeld: in een CRM-contactzoekfunctie, houd de lijst zichtbaar, debounce op 200ms, zoek pas vanaf 2 tekens en annuleer het oude verzoek wanneer de gebruiker blijft typen. De UI blijft rustig, resultaten flikkeren niet en gebruikers voelen controle.
Cache-basics die het versnellen zonder risico
Caching is een van de eenvoudigste manieren om zoeken direct te laten voelen, want veel zoekopdrachten herhalen zich. Mensen typen, backspacen, proberen dezelfde query opnieuw of schakelen tussen een paar filters.
Cache met een sleutel die precies overeenkomt met wat de gebruiker vroeg. Een veelvoorkomende bug is alleen cachen op de tekstquery en dan verkeerde resultaten tonen als filters veranderen.
Een praktische cache-sleutel bevat meestal de genormaliseerde querystring plus actieve filters en sortering. Als je pagineert, neem dan pagina of cursor op. Als permissies per gebruiker of workspace verschillen, voeg dat ook toe.
Houd de cache klein en kortdurend. Bewaar alleen de laatste 20–50 zoekopdrachten en laat entries na 30–120 seconden verlopen. Dat is genoeg voor heen-en-weer typen, maar kort genoeg dat wijzigingen de UI niet lang fout doen voelen.
Je kunt de cache ook warm maken door deze vooraf te vullen met wat de gebruiker net zag: recente items, laatst geopende project of het standaardresultaat voor lege query (vaak "alle items" gesorteerd op recentie). In een kleine CRM maakt het cachen van de eerste pagina van Klanten de eerste zoekinteractie direct.
Cache fouten niet op dezelfde manier als successen. Een tijdelijke 500 of timeout mag de cache niet vergiftigen. Als je fouten toch bewaart, leg ze apart vast met een veel kortere TTL.
Bepaal ten slotte hoe cache-items ongeldig worden als data verandert. Maak op zijn minst relevante cache-items leeg wanneer de huidige gebruiker iets maakt, bewerkt of verwijdert dat in de resultaten kan verschijnen, wanneer permissies veranderen of wanneer de gebruiker van workspace/account wisselt.
Relevantiebasics met eenvoudige, uitlegbare regels
Als resultaten willekeurig aanvoelen, verliezen mensen vertrouwen. Je krijgt solide relevantie zonder speciale zoekengine door een paar regels die je kunt uitleggen.
Een eenvoudig score-recept
Begin met match-prioriteit:
- Exacte match (het hele veld matcht de query)
- Prefix-match (begint met de query)
- Contains-match (query verschijnt ergens)
- Token-match (een woord in de query matcht een woord in het veld)
Verhoog daarna belangrijke velden. Titels wegen meestal zwaarder dan omschrijvingen. ID's of tags kunnen het belangrijkst zijn wanneer iemand ze plakt. Houd de gewichten klein en consistent zodat je er over kunt redeneren.
In deze fase is lichte foutafhandeling vooral normalisatie, geen zware fuzzy matching. Normaliseer zowel de query als de tekst waarin je zoekt: lowercase, trim, meerdere spaties samenvoegen en accenten verwijderen als je publiek ze gebruikt. Dit lost al veel "waarom vond hij het niet" klachten op.
Bepaal vroeg hoe je symbolen en cijfers behandelt, want die veranderen verwachtingen. Een eenvoudige policy is: behoud hashtags als onderdeel van het token, behandel koppeltekens en underscores als spaties, behoud cijfers en verwijder de meeste interpunctie (maar behoud @ en . als je e-mails of gebruikersnamen doorzoekt).
Maak ranking uitlegbaar. Een simpele truc is een korte debug-rede per resultaat in logs op te slaan: "prefix in titel" verslaat "contains in omschrijving".
Lokaal vs server zoeken: een praktische verdeling
Een snelle zoekervaring komt vaak neer op één keuze: wat kun je op het apparaat filteren en wat moet je op de server vragen.
Lokaal filteren werkt het beste als de data klein is, al op het scherm staat of recent gebruikt is: de laatste 50 chats, recente projecten, opgeslagen contacten of items die je al voor een lijstweergave hebt opgehaald. Als de gebruiker het net zag, verwachten ze dat zoeken het direct vindt.
Serverzoeken is voor enorme datasets, data die vaak verandert, of alles wat privé is en je niet wilt downloaden. Het is ook nodig wanneer resultaten afhangen van permissies en gedeelde workspaces.
Een praktisch patroon dat stabiel blijft:
- Toon eerst lokale matches uit wat je al hebt.
- Start op de achtergrond een serveraanvraag voor bredere dekking.
- Merge resultaten wanneer de response binnenkomt (dedupe op ID).
- Houd de hoogte van het resultatenvak stabiel zodat de pagina niet springt.
- Houd de focus in het zoekveld.
Voorbeeld: een CRM kan direct recent bekeken klanten lokaal filteren terwijl iemand "ann" typt, en stil de volledige serverresultaten voor "Ann" over de database laden.
Om layoutverschuivingen te vermijden, reserveer ruimte voor resultaten en update rijen ter plaatse. Als je schakelt van lokaal naar serverresultaten, is een subtiele "Resultaten bijgewerkt" hint vaak voldoende. Keyboard-gedrag moet ook consistent blijven: pijltjestoetsen bewegen door de lijst, Enter selecteert, Escape wist of sluit.
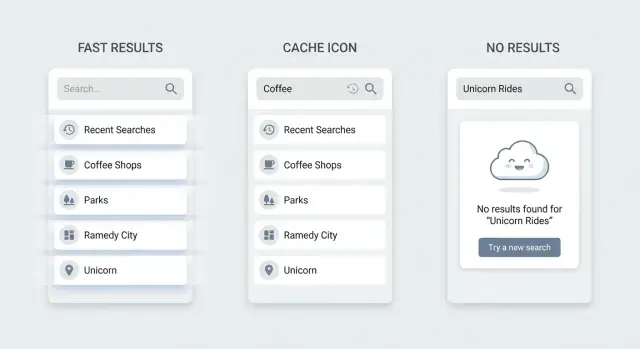
Lege, laden en geen-resultaten toestanden die mensen kunnen gebruiken
De meeste frustratie rond zoeken gaat niet over ranking. Het gaat om wat het scherm doet als de gebruiker tussen acties in zit: voordat ze typen, terwijl resultaten updaten en wanneer niets matcht.
Als het vak leeg is: geef een startpunt
Een lege zoekpagina dwingt gebruikers te raden wat werkt. Betere defaults zijn recente zoekopdrachten (zodat ze een taak kunnen herhalen) en een korte set populaire items of categorieën (zodat ze kunnen browsen zonder te typen). Houd het klein, scanbaar en één tikbaar.
Tijdens laden: houd context, vermijd flikkering
Mensen interpreteren flikkering als traag. Het leegmaken van de lijst bij elke toetsaanslag maakt de UI onstabiel, zelfs als de backend snel is.
Houd vorige resultaten op het scherm en toon een kleine laadhint bij het invoergebied (of een subtiele spinner daarin). Als je langere wachttijden verwacht, voeg een paar skeleton-rijen onderaan toe terwijl je de bestaande lijst behoudt.
Als een verzoek faalt, toon een inline bericht en behoud de oude resultaten zichtbaar.
Geen resultaten: verander doodlopende paden in volgende stappen
Een lege pagina met "Geen resultaten" is een doodlopend pad. Stel voor wat je vervolgens kunt proberen op basis van wat je UI ondersteunt. Als filters actief zijn, bied een één-tap Filters wissen. Als je multi-woord queries ondersteunt, suggereer minder woorden. Als je bekende synoniemen hebt, stel een alternatief woord voor.
Geef ook een fallback-weergave zodat de gebruiker kan doorgaan (recente items, topitems of categorieën), en voeg een Maak nieuw actie toe als je product dat ondersteunt.
Concreet scenario: iemand zoekt "invoice" in een CRM en krijgt niets omdat items gelabeld zijn als "billing". Een behulpzame staat kan suggereren "Probeer: billing" en de Billing-categorie tonen.
Log geen-resultaten queries (met actieve filters) zodat je synoniemen kunt toevoegen, labels kunt verbeteren of ontbrekende content kunt creëren.
Stappenplan: bouw een direct-aanvoelende zoekfunctie in een week
Direct-aanvoelend zoeken komt van een kleine, duidelijke versie 1. De meeste teams blijven hangen omdat ze op dag één alle velden, alle filters en perfecte ranking willen ondersteunen.
Begin met één use case. Voorbeeld: in een kleine CRM zoeken mensen meestal klanten op naam, e-mail en bedrijf, en filteren dan op status (Actief, Proef, Vertrokken). Schrijf die velden en filters op zodat iedereen hetzelfde bouwt.
Een praktisch één-week plan:
- Dag 1: Lock de scope. Kies 3–5 doorzoekbare velden, 0–2 filters en één sorteeregel (bijv. eerst exact match, dan prefix).
- Dag 2: Maak typen veilig. Voeg debounce toe (vaak 150–250ms) en annuleer oude verzoeken zodat late responses nieuwe niet overschrijven.
- Dag 3: Voeg eenvoudige ranking en highlighting toe. Gebruik uitlegbare regels (exacte match > starts-with > contains). Highlight matches zodat gebruikers zien waarom een resultaat verscheen.
- Dag 4: Voeg een kleine cache toe. Cache recente queries en resultaten voor korte tijd (zoals 30–120 seconden) en hergebruik ze wanneer de gebruiker backspacet of een query herhaalt.
- Dag 5: Maak de UI-toestanden af. Voeg een lichte laadstatus en een geen-resultaten staat met een volgende actie toe.
Houd invalidatie simpel. Maak cache leeg bij uitloggen, workspace-wissel en na elke actie die de onderliggende lijst verandert (aanmaken, verwijderen, statuswijziging). Als je wijzigingen niet betrouwbaar kunt detecteren, gebruik dan een korte TTL en behandel de cache als snelheidshulp, niet als bron van waarheid.
Gebruik de laatste dag om te meten. Volg tijd tot eerste resultaat, geen-resultaten percentage en foutpercentage. Als tijd tot eerste resultaat goed is maar geen-resultaten hoog, moeten je velden, filters of woordkeuze worden aangepast.
Veelgemaakte fouten die zoeken frustrerend maken
De meeste klachten over traag zoeken gaan eigenlijk over feedback en correctheid. Mensen kunnen een seconde wachten als de UI levendig aanvoelt en de resultaten logisch zijn. Ze haken af wanneer het vak vast lijkt te zitten, resultaten rond springen of de app impliceert dat zij iets fout deden.
Een veelgemaakte val is debounce te hoog te zetten. Als je 500–800ms wacht voordat je iets doet, voelt het invoerveld traag, vooral bij korte queries als "hr" of "tax". Houd de vertraging klein en toon directe UI-feedback zodat typen nooit genegeerd lijkt.
Een andere frustratie is oude verzoeken laten winnen. Als een gebruiker eerst "app" typt en snel een "l" toevoegt, kan de "app" response als laatste binnenkomen en de "appl" resultaten overschrijven. Annuleer het vorige verzoek wanneer je een nieuwe start of negeer responses die niet bij de nieuwste query passen.
Caching kan tegenwerken wanneer sleutels te vaag zijn. Als je cache-sleutel alleen de querytekst is, maar je hebt ook filters (status, datumbereik, categorie), toon je verkeerde resultaten en verliezen gebruikers vertrouwen. Behandel query + filters + sort als één identiteit.
Rankingfouten zijn subtiel maar pijnlijk. Mensen verwachten exacte matches eerst. Een simpele, consistente set regels is vaak beter dan een slimme:
- Exacte match op naam of ID eerst
- Prefix-match daarna
- Daarna gedeeltelijke match overal
- Fuzzy-match alleen als niets anders past
- Recente of frequente items mogen gelijke scores breken, maar niet exacte matches overrulen
Geen-resultaat schermen doen vaak niets. Toon wat er gezocht werd, bied filters wissen, suggereer een bredere query en toon een paar populaire of recente items.
Voorbeeld: een oprichter zoekt klanten, typt "Ana", heeft alleen de Actief-filter aan en krijgt niets. Een behulpzame lege staat zou zeggen "Geen actieve klanten voor 'Ana'" en een één-tap Toon alle statussen actie aanbieden.
Snelle checklist en vervolgstappen
Voordat je een speciale zoekengine toevoegt, zorg dat de basis rustig aanvoelt: typen blijft soepel, resultaten springen niet rond en de UI vertelt altijd wat er gebeurt.
Een korte checklist voor versie 1:
- Typen hapert nooit. Debounce werk ná invoer, niet de invoer zelf.
- Resultaten updaten op volgorde. Annuleer of negeer oudere verzoeken zodat je nooit verouderde resultaten toont.
- Laden is duidelijk maar zacht. Houd de huidige lijst zichtbaar en toon een kleine updatehint.
- Geen-resultaten helpt mensen herstellen. Bied een volgende actie zoals filters wissen of een kortere query proberen.
- Rankingregels zijn opgeschreven en consistent.
Controleer daarna of je cache meer helpt dan schaadt. Houd het klein (alleen recente queries), cache de uiteindelijke resultatenlijst en invalideer bij onderliggende datawijzigingen. Als je wijzigingen niet betrouwbaar kunt detecteren, verkort dan de cachelevensduur.
Vervolgstappen
Ga in kleine, meetbare stappen vooruit:
- Voeg een klein testplan toe: 5 veelvoorkomende queries, 2 randgevallen en 1 geen-resultaten geval.
- Log alleen wat je nodig hebt: querylengte, tijd tot eerste resultaat en annuleringspercentage (vermijd persoonlijke tekst indien mogelijk).
- Kies één verbetering per week: betere ranking, beter lege staat of betere caching.
- Voeg een echte zoekbackend pas toe nadat je kunt uitleggen wat er vandaag mist.
Als je een app bouwt op Koder.ai (koder.ai), is het de moeite waard zoeken als een first-class feature te behandelen in je prompt- en acceptatiechecks: definieer de regels, test de toestanden en zorg dat de UI vanaf dag één rustig gedraagt.