26 dec 2025·8 min
Interne ontwikkeltools met Claude Code: veilige CLI-dashboards
Bouw interne ontwikkeltools met Claude Code om logsearch, feature toggles en datacontroles op te lossen, terwijl je least-privilege en duidelijke guardrails afdwingt.
Welk probleem moet je interne tool eigenlijk oplossen?
Interne tools beginnen vaak als een snelkoppeling: één commando of één pagina die het team 20 minuten bespaart tijdens een incident. Het risico is dat diezelfde snelkoppeling ongemerkt verandert in een bevoorrecht achterdeurtje als je het probleem en de grenzen niet van tevoren definieert.
Teams grijpen meestal naar een tool wanneer dezelfde pijn zich elke dag herhaalt, bijvoorbeeld:
- Logzoeken dat traag, inconsistent of verspreid over systemen is
- Feature toggles die een risicovolle handmatige aanpassing of directe databasewrite vereisen
- Datacontroles die afhankelijk zijn van één persoon die een script vanaf zijn laptop uitvoert
- On-call-taken die eenvoudig zijn, maar om 02:00 gemakkelijk misgaan
Die problemen lijken klein totdat de tool productie-logs kan lezen, klantgegevens kan opvragen of een vlag kan omzetten. Dan krijg je te maken met toegangscontrole, auditsporen en onbedoelde schrijfacties. Een tool die "alleen voor engineers" is, kan nog steeds een outage veroorzaken als hij een brede query uitvoert, de verkeerde omgeving raakt of de staat verandert zonder duidelijke bevestiging.
Definieer succes in smalle, meetbare termen: snellere bediening zonder permissies te verruimen. Een goede interne tool verwijdert stappen, geen waarborgen. In plaats van iedereen brede database-toegang te geven om een vermoedelijk factureringsprobleem te controleren, bouw een tool die één vraag beantwoordt: "Toon de mislukte factureringsevenementen van vandaag voor account X," met read-only, gespecificeerde credentials.
Voordat je een interface kiest, bepaal wat mensen op dat moment nodig hebben. Een CLI is geweldig voor herhaalbare taken tijdens on-call. Een webdashboard is beter wanneer resultaten context en gedeelde zichtbaarheid nodig hebben. Soms lever je beide, maar alleen als het dunne views zijn boven dezelfde afgeschermde operaties. Het doel is één goed gedefinieerde mogelijkheid, niet een nieuw admin-oppervlak.
Kies één pijnpunt en houd de scope klein
De snelste manier om een interne tool nuttig (en veilig) te maken, is één duidelijke taak kiezen en die goed uitvoeren. Als hij vanaf dag één logs, feature flags, datafixes en gebruikersbeheer probeert te behandelen, groeit hij naar verborgen gedrag en verrast hij mensen.
Begin met één vraag die een gebruiker in echt werk stelt. Bijvoorbeeld: "Gegeven een request-ID, toon de fout en de omliggende regels over services heen." Dat is smal, toetsbaar en makkelijk uit te leggen.
Wees expliciet over voor wie de tool bedoeld is. Een ontwikkelaar die lokaal debugt heeft andere opties nodig dan iemand on-call, en beide verschillen van support of een analist. Als je publiek mengt, eindig je met "krachtige" commando's die de meeste gebruikers nooit mogen gebruiken.
Schrijf inputs en outputs op als een klein contract.
Inputs moeten expliciet zijn: request-ID, tijdsbereik, omgeving. Outputs moeten voorspelbaar zijn: overeenkomende regels, servicenaam, timestamp, aantal. Vermijd verborgen bijwerkingen zoals "poetst ook cache" of "probeert ook de job opnieuw". Dat zijn de functies die ongelukken veroorzaken.
Stel standaard in op read-only. Je kunt de tool nog steeds waardevol maken met zoeken, diff, valideren en rapporteren. Voeg schrijfacties alleen toe wanneer je een echte scenario kunt benoemen waarvoor het nodig is en je het strak kunt beperken.
Een eenvoudige scope-verklaring die teams scherp houdt:
- Eén primaire taak, één primair scherm of commando
- Eén gegevensbron (of één logisch overzicht), niet "alles"
- Expliciete flags voor omgeving en tijdsbereik
- Eerst read-only, geen achtergrondacties
- Als er schrijfacties zijn: bevestiging en logging van elke wijziging
Breng gegevensbronnen en gevoelige operaties vroeg in kaart
Voordat Claude Code iets schrijft, schrijf op wat de tool zal aanraken. De meeste beveiligings- en betrouwbaarheidproblemen verschijnen hier, niet in de UI. Behandel deze mapping als een contract: het vertelt reviewers wat in scope is en wat off-limits is.
Begin met een concreet overzicht van gegevensbronnen en eigenaren. Bijvoorbeeld: logs (app, gateway, auth) en waar ze staan; de exacte databasetabellen of views die de tool mag query'en; je feature flag-store en naamgevingsregels; metrics en traces en welke labels veilig zijn om op te filteren; en of je aantekeningen naar ticket- of incidentsystemen wilt schrijven.
Noem vervolgens de operaties die de tool mag uitvoeren. Vermijd het label "admin" als permissie. Definieer in plaats daarvan controleerbare werkwoorden. Veelvoorkomende voorbeelden zijn: read-only zoeken en exporteren (met limieten), annoteren (een notitie toevoegen zonder historie te wijzigen), het togglen van specifieke flags met een TTL, begrensde backfills (datumbereik en recordaantal), en dry-run-modi die impact laten zien zonder data te veranderen.
Gevoelige velden hebben expliciete behandeling nodig. Beslis wat gemaskeerd moet worden (e-mails, tokens, session IDs, API-keys, klantidentifiers) en wat alleen afgekort mag worden getoond. Bijvoorbeeld: toon de laatste 4 tekens van een ID, of hash het consistent zodat mensen events kunnen correleren zonder de ruwe waarde te zien.
Kom ten slotte overeen over retentie- en auditregels. Als een gebruiker een query uitvoert of een vlag omzet, registreer wie het deed, wanneer, welke filters werden gebruikt en het resultaat-aantal. Bewaar auditlogs langer dan applicatielogs. Zelfs een eenvoudige regel zoals "queries 30 dagen bewaren, auditrecords 1 jaar" voorkomt pijnlijke discussies tijdens een incident.
Least-privilege toegangsmodel dat eenvoudig blijft
Least privilege is het makkelijkst wanneer je het model saai houdt. Begin met opschrijven wat de tool kan doen en label elk actie als read-only of write. De meeste interne tools hebben voor de meeste mensen alleen leesrechten nodig.
Voor een webdashboard gebruik je je bestaande identity-systeem (SSO met OAuth). Vermijd lokale wachtwoorden. Voor een CLI geef je de voorkeur aan kortlevende tokens die snel verlopen en scope ze naar alleen de acties die de gebruiker nodig heeft. Langdurige gedeelde tokens worden vaak in tickets geplakt, in shellhistory opgeslagen of naar persoonlijke machines gekopieerd.
Houd RBAC klein. Als je meer dan een paar rollen nodig hebt, doet de tool waarschijnlijk te veel. Veel teams redden zich goed met drie:
- Viewer: alleen lezen, veilige defaults
- Operator: lezen plus een kleine set laag-risico acties
- Admin: hoog-risico acties, zelden gebruikt
Scheid omgevingen vroeg, zelfs als de UI er hetzelfde uitziet. Maak het moeilijk om per ongeluk in prod te werken. Gebruik verschillende credentials per omgeving, verschillende configbestanden en verschillende API-endpoints. Als iemand alleen staging ondersteunt, mag die niet eens kunnen authenticeren tegen productie.
Hoog-risico acties verdienen een goedkeuringsstap. Denk aan data verwijderen, feature flags veranderen, services herstarten of zware queries draaien. Voeg een second-person check toe wanneer de blast radius groot is. Praktische patronen zijn getypte bevestigingen die de target (servicenaam en omgeving) bevatten, registreren wie vroeg en wie goedkeurde, en een korte vertraging of gepland venster voor de gevaarlijkste operaties.
Als je de tool genereert met Claude Code, maak er een regel van dat elk endpoint en commando zijn vereiste rol van tevoren declareert. Die gewoonte houdt permissies controleerbaar naarmate de tool groeit.
Guardrails die ongelukken en slechte queries voorkomen
Iterate without surprises
Keep experiments separate while you iterate on scope, validation, and safe defaults.
De meest voorkomende foutmodus voor interne tools is geen aanvaller. Het is een vermoeide collega die het "juiste" commando met de verkeerde inputs draait. Behandel guardrails als productfeatures, geen afwerking.
Veilige defaults
Begin met een veilige houding: standaard read-only. Zelfs als de gebruiker admin is, moet de tool openen in een modus die alleen data kan ophalen. Maak schrijfacties opt-in en duidelijk zichtbaar.
Voor elke operatie die de staat verandert (toggle een vlag, backfill data, record verwijderen), vereist expliciete type-to-confirm. "Weet je het zeker? y/N" is te makkelijk voor muscle memory. Vraag de gebruiker iets specifiek te hertypen, zoals de naam van de omgeving plus de target-ID.
Strikte inputvalidatie voorkomt de meeste rampen. Accepteer alleen de vormen die je echt ondersteunt (IDs, datums, omgevingen) en verwerp alles vroeg. Voor zoekopdrachten beperk je de kracht: cap het aantal resultaten, handhaaf redelijke datumbereiken en gebruik een allow-list-benadering in plaats van willekeurige patronen naar je logstore te sturen.
Om runaway-queries te vermijden, voeg timeouts en rate limits toe. Een veilige tool faalt snel en legt uit waarom, in plaats van te hangen en je database te belasten.
Een set guardrails die in de praktijk goed werkt:
- Standaard read-only, met een duidelijke "write mode"-schakelaar
- Type-to-confirm voor writes (inclusief env + target)
- Strikte validatie voor IDs, datums, limieten en toegestane patronen
- Query-timeouts plus per-gebruiker rate limits
- Geheimen maskeren in output en in de eigen logs van de tool
Output-hygiëne
Ga ervan uit dat de output van de tool in tickets en chat gekopieerd wordt. Masker standaard geheimen (tokens, cookies, API-keys, en zo nodig e-mails). Maak ook schoon wat je opslaat: auditlogs moeten vastleggen wat geprobeerd werd, niet de ruwe data die terugkwam.
Voor een logsearch-dashboard geef een korte preview en een aantal terug, geen volledige payloads. Als iemand echt het volledige event nodig heeft, maak dat een aparte, duidelijk afgeschermde actie met eigen bevestiging.
Hoe je met Claude Code werkt zonder de controle te verliezen
Behandel Claude Code als een snelle junior-collega: behulpzaam, maar geen gedachtenlezer. Jouw taak is het werk begrensd, controleerbaar en eenvoudig ongedaan te maken te houden. Dat is het verschil tussen tools die veilig aanvoelen en tools die je om 02:00 verrassen.
Begin met een specificatie die het model kan volgen
Voordat je om code vraagt, schrijf een kleine spec die de gebruikersactie en het verwachte resultaat benoemt. Houd het over gedrag, niet over framework-details. Een goede spec past meestal op een halve pagina en behandelt:
- Commando's of schermen (exacte namen)
- Inputs (flags, velden, formaten, limieten)
- Outputs (wat verschijnt, wat wordt opgeslagen)
- Foutgevallen (ongeldige input, timeouts, geen resultaten)
- Permissiechecks (wat gebeurt er bij toegang geweigerd)
Bijvoorbeeld: als je een logsearch-CLI bouwt, definieer één commando end-to-end: logs search --service api --since 30m --text \"timeout\", met een harde cap op resultaten en een duidelijke "geen toegang"-melding.
Vraag om kleine incrementen die je kunt verifiëren
Vraag eerst om een skelet: CLI-wiring, configladen en een gestubde datacall. Vraag dan precies één feature volledig af (inclusief validatie en fouten). Kleine diffs maken reviews echt.
Na elke wijziging, vraag om een platte-taal uitleg van wat er veranderde en waarom. Als de uitleg niet overeenkomt met het diff, stop en formuleer het gedrag en de veiligheidsbeperkingen opnieuw.
Genereer tests vroeg, vóórdat je meer features toevoegt. Minimaal: de happy path, ongeldige inputs (foute datums, missende flags), permissie geweigerd, geen resultaten, en rate limit of backend-timeouts.
CLI vs webdashboard: kies de juiste interface
Een CLI en een intern webdashboard kunnen hetzelfde probleem oplossen, maar ze falen op verschillende manieren. Kies de interface die het veilige pad het makkelijkst maakt.
Een CLI is meestal het beste wanneer snelheid telt en de gebruiker al weet wat hij wil. Het past ook goed bij read-only workflows, omdat je permissies smal kunt houden en knoppen die per ongeluk writes triggeren vermijdt.
Een CLI is een sterke keuze voor snelle on-call queries, scripts en automatisering, expliciete auditsporen (elk commando staat letterlijk), en lage rollout-kosten (één binary, één config).
Een webdashboard is beter wanneer gedeelde zichtbaarheid of begeleide stappen nodig zijn. Het kan fouten verminderen door mensen naar veilige defaults te duwen zoals tijdsbereiken, omgevingen en vooraf goedgekeurde acties. Dashboards werken ook goed voor team-brede statusviews, afgeschermde acties die bevestiging vereisen, en ingebouwde uitleg wat een knop doet.
Gebruik indien mogelijk dezelfde backend-API voor beide. Leg auth, rate limits, querylimieten en auditlogging in die API, niet in de UI. Dan worden CLI en dashboard verschillende clients met verschillende ergonomie.
Bepaal ook waar het draait, want dat verandert je risico. Een CLI op een laptop kan tokens lekken. Draaien op een bastion-host of in een intern cluster kan blootstelling verminderen en logs en beleidshandhaving makkelijker maken.
Voorbeeld: voor logsearch is een CLI geweldig voor een on-call engineer die de laatste 10 minuten van één service wil ophalen. Een dashboard is beter voor een gedeelde incidentroom waar iedereen dezelfde gefilterde view nodig heeft, plus een begeleide "export voor postmortem"-actie die permissie-gecontroleerd is.
Een realistisch voorbeeld: logsearch-tool voor on-call
Keep your tool reviewable
Get the full source code so your team can review and own every change.
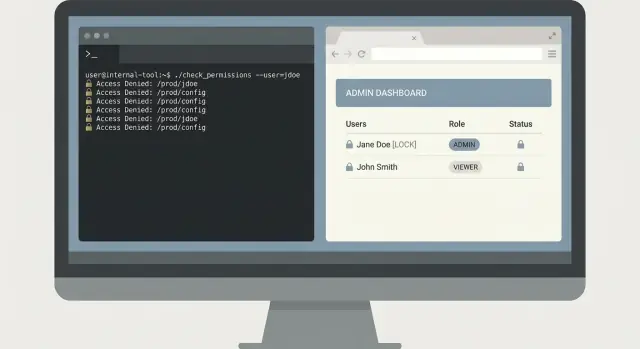
Het is 02:10 en on-call krijgt een melding: "Betalen werkt soms niet voor één klant." Support heeft een screenshot met een request-ID, maar niemand wil willekeurige queries in een logsystem met admin-rechten plakken.
Een kleine CLI kan dit veilig oplossen. De sleutel is het smal houden: vind de fout snel, toon alleen wat nodig is en laat productiedata ongewijzigd.
Een minimale CLI-flow
Begin met één commando dat tijdslimieten en een specifieke identifier afdwingt. Vereis een request-ID en een tijdsvenster, en default naar een kort venster.
oncall-logs search --request-id req_123 --since 30m --until now
Geef eerst een samenvatting terug: servicenaam, foutklasse, aantal en de top 3 overeenkomende berichten. Sta dan een expliciete expand-stap toe die volledige logregels print alleen wanneer de gebruiker erom vraagt.
oncall-logs show --request-id req_123 --limit 20
Dit twee-staps ontwerp voorkomt per ongeluk data-dumps. Het maakt reviews ook makkelijker omdat de tool een duidelijk safe-by-default-pad heeft.
Optionele vervolgactie (geen writes)
On-call moet vaak een spoor achterlaten voor de volgende persoon. In plaats van in de database te schrijven, voeg een optionele actie toe die een ticket-notitiepayload creëert of een tag toepast in het incident-systeem, maar nooit klantrecords aanraakt.
Om least privilege te behouden, moet de CLI een read-only logtoken gebruiken en een aparte, gespecificeerde token voor de ticket- of tag-actie.
Bewaar een auditrecord voor elke run: wie het uitvoerde, welke request-ID, welke tijdsgrenzen werden gebruikt en of ze details uitbreidden. Dat auditlog is je veiligheidsnet als er iets misgaat of als toegang beoordeeld moet worden.
Veelgemaakte fouten die beveiliging en betrouwbaarheid schaden
Kleine interne tools beginnen vaak als "even snel een helper". Juist daarom eindigen ze met risicovolle defaults. De snelste manier om vertrouwen te verliezen is één slecht incident, zoals een tool die data verwijdert terwijl het alleen lezen had moeten zijn.
De fouten die het vaakst voorkomen:
- De tool productie-database schrijfaccess geven terwijl hij alleen reads nodig heeft, en dan aannemen "we zullen voorzichtig zijn"
- Het overslaan van een audittrail, zodat je later niet kunt zeggen wie een commando draaide, welke inputs ze gebruikten en wat er veranderde
- Vrije SQL, regex of ad-hoc filters toestaan die per ongeluk enorme tabellen of logs scannen en systemen neerhalen
- Omgevingen mengen zodat staging-acties productie kunnen bereiken doordat configs, tokens of basis-URLs gedeeld zijn
- Geheimen naar een terminal, browserconsole of logs printen en vergeten dat die outputs in tickets en chat gekopieerd worden
Een realistisch falen ziet er zo uit: een on-call engineer gebruikt een log-search CLI tijdens een incident. De tool accepteert elke regex en stuurt het naar de log-backend. Eén dure pattern draait uren aan hoge logvolume, drijft kosten op en vertraagt searches voor iedereen. In dezelfde sessie print de CLI een API-token in debug output, en het eindigt in een openbaar incidentdocument.
Veiliger defaults die de meeste incidenten voorkomen
Behandel read-only als een echte veiligheidsgrens, niet als een gewoonte. Gebruik aparte credentials per omgeving en aparte service-accounts per tool.
Een paar guardrails doen het meeste werk:
- Gebruik allow-listed queries (of templates) in plaats van raw SQL, en cap tijdsbereiken en rijen
- Log elke actie met een request-ID, gebruikersidentiteit, target-omgeving en exacte parameters
- Vereis expliciete omgevingsselectie, met een luide bevestiging voor productie
- Redacteer geheimen standaard en schakel debug-output uit tenzij een bevoorrechte flag gebruikt wordt
Als de tool iets gevaarlijks niet kan doen bij ontwerp, hoeft je team niet te vertrouwen op perfecte aandacht tijdens een 3 uur 's nachts incident.
Snelle checklist voordat je de tool uitrolt
Plan it before you build
Map inputs, outputs, and permissions before code is generated.
Voordat je interne tool echte gebruikers bereikt (vooral on-call), behandel het als een productiesysteem. Bevestig dat toegang, permissies en veiligheidslimieten echt zijn, niet impliciet.
Begin met toegang en permissies. Veel ongelukken gebeuren omdat "tijdelijke" toegang permanent wordt of omdat een tool in de loop van de tijd stilletjes write-macht krijgt.
- Auth en offboarding: bevestig wie kan inloggen, hoe toegang wordt toegekend en hoe het dezelfde dag wordt ingetrokken als iemand van team verandert
- Rollen klein houden: houd 2-3 rollen max (viewer, operator, admin) en schrijf op wat elke rol kan doen
- Standaard read-only: maak bekijken het standaardpad en vereis een expliciete rol voor alles wat data verandert
- Omgaan met geheimen: sla tokens en keys buiten de repo op en verifieer dat de tool ze nooit print in logs of foutmeldingen
- Break-glass-flow: als je noodtoegang nodig hebt, maak het tijdsgebonden en gelogd
Valideer vervolgens guardrails die veelgemaakte fouten voorkomen:
- Bevestigingen voor risicovolle acties: vereis getypte bevestigingen voor deletes, backfills of configwijzigingen
- Limieten en timeouts: cap resultaatgrootte, handhaaf tijdsvensters en laat queries time-outs hebben zodat een slechte request niet oneindig draait
- Inputvalidatie: valideer IDs, datums en omgevingsnamen; verwerp alles dat op "run everywhere" lijkt
- Auditlogs: registreer wie wat deed, wanneer en van waar; maak logs makkelijk te doorzoeken tijdens incidenten
- Basis-metrics en fouten: track succespercentages, latency en top fouttypes zodat je fouten vroeg opmerkt
Voer change control uit zoals voor elke service: peer review, een paar gerichte tests voor gevaarlijke paden en een rollback-plan (inclusief een manier om de tool snel uit te schakelen als hij verkeerd gedraagt).
Volgende stappen: veilig uitrollen en blijven verbeteren
Behandel de eerste release als een gecontroleerd experiment. Begin met één team, één workflow en een klein aantal echte taken. Een logsearch-tool voor on-call is een solide pilot omdat je tijdwinst kunt meten en risicovolle queries snel kunt spotten.
Houd de uitrol voorspelbaar: pilot met 3 tot 10 gebruikers, begin in staging, gate toegang met least-privilege-rollen (geen gedeelde tokens), stel duidelijke gebruikslimieten in en registreer auditlogs voor elk commando of knopklik. Zorg dat je configuratie- en permissiewijzigingen snel kunt terugdraaien.
Schrijf het contract van de tool in platte taal. Noem elk commando (of dashboardactie), de toegestane parameters, wat succes is en wat fouten betekenen. Mensen verliezen vertrouwen in interne tools wanneer outputs vaag aanvoelen, ook al is de code correct.
Voeg een feedbackloop toe die je echt bekijkt. Volg welke queries traag zijn, welke filters veel voorkomen en welke opties mensen in de war brengen. Als je herhaalde omwegen ziet, is dat meestal een teken dat de interface een veilige default mist.
Onderhoud heeft een eigenaar en een schema nodig. Beslis wie dependencies update, wie credentials roteert en wie gepaged wordt als de tool faalt tijdens een incident. Review AI-gegenereerde wijzigingen zoals je een productiedienst zou reviewen: permissiediffs, queryveiligheid en logging.
Als je team voorkeur geeft aan chat-gedreven iteratie, kan Koder.ai (koder.ai) een praktische manier zijn om een kleine CLI of dashboard uit een gesprek te genereren, snapshots van bekende goede staten bij te houden en snel terug te rollen wanneer een wijziging risico introduceert.