Stel doelen en scope voor reliability‑tracking
Voordat je metrics kiest of dashboards bouwt, bepaal waarvoor je reliability‑app verantwoordelijk is — en wat niet. Een duidelijke scope voorkomt dat de tool verandert in een allesomvattend “ops‑portaal” waar niemand op vertrouwt.
Definieer wat je gaat volgen
Begin met het opsommen van de interne tools die de app dekt (bijv. ticketing, payroll, CRM‑integraties, datapijplijnen) en de teams die ze bezitten of ervan afhankelijk zijn. Wees expliciet over grenzen: “klantgerichte website” kan buiten scope zijn, terwijl “intern admin‑console” binnen is.
Spreek af wat “betrouwbaarheid” hier betekent
Organisaties gebruiken het woord verschillend. Schrijf je werkdefinitie in gewone taal—meestal een mix van:
- Beschikbaarheid: kunnen mensen er bij wanneer dat nodig is?
- Latentie: is het snel genoeg om bruikbaar te zijn?
- Fouten: faalt het op manieren die gebruikers merken (timeouts, job‑fouten, slechte responses)?
Als teams het daar niet over eens zijn, ga je appels met peren vergelijken.
Bepaal de gewenste uitkomsten
Kies 1–3 primaire uitkomsten, zoals:
- Sneller detecteren van problemen (kortere “time to notice”)
- Duidelijkere rapportage voor managers en stakeholders
- Minder terugkerende incidenten door betere opvolging
Deze uitkomsten sturen later wat je meet en hoe je het presenteert.
Identificeer gebruikers en rollen
Maak een lijst van wie de app gebruikt en welke beslissingen ze nemen: engineers die incidenten onderzoeken, support die escaleren, managers die trends bekijken en stakeholders die statusupdates nodig hebben. Dit bepaalt terminologie, permissies en detailniveau per view.
Kies de betrouwbaarheid‑metrics die ertoe doen (SLIs/SLOs)
Reliability‑tracking werkt alleen als iedereen het eens is over wat “goed” is. Begin met het scheiden van drie termen die op elkaar lijken.
SLIs vs SLOs vs SLAs (in gewoon Nederlands)
Een SLI (Service Level Indicator) is een meting: “Welk percentage verzoeken slaagde?” of “Hoe lang duurde het laden van pagina's?”
Een SLO (Service Level Objective) is het doel voor die meting: “99.9% succes over 30 dagen.”
Een SLA (Service Level Agreement) is een belofte met consequenties, meestal extern gericht (credits, boetes). Voor interne tools stel je vaak SLOs in zonder formele SLAs—genoeg om verwachtingen af te stemmen zonder van betrouwbaarheid contracten te maken.
Houd het vergelijkbaar tussen tools en makkelijk uit te leggen. Een praktisch startpunt is:
- Uptime/beschikbaarheid: was de tool bereikbaar?
- Responstijd: hoe snel reageerden belangrijke pagina's of endpoints?
- Foutpercentage: welk aandeel checks of verzoeken faalde (5xx, timeouts, bekende fouttoestanden)?
Voeg niet meer toe totdat je kunt beantwoorden: “Welke beslissing zal deze metric sturen?”
Kies tijdsvensters die passen bij hoe mensen denken
Gebruik rolling windows zodat scorecards continu updaten:
- 7 dagen: pakt regressies snel op
- 30 dagen: maandrapportage en trends
- 90 dagen: stabiliteit over kwartalen
Definieer incidenten met duidelijke severity‑niveaus
Je app moet metrics omzetten in actie. Definieer severity‑levels (bijv. Sev1–Sev3) en expliciete triggers zoals:
- Sev1: tool down of kritisch workflow geblokkeerd voor X minuten
- Sev2: grote degradatie (bv. foutpercentage boven Y% voor Z minuten)
- Sev3: kleine issues of intermitterende fouten
Deze definities maken alerting, incident‑timelines en error‑budget tracking consistent tussen teams.
Plan je databronnen en ingestie‑aanpak
Een reliability‑tracker is alleen zo geloofwaardig als de data erachter. Voordat je ingestie‑pipelines bouwt, map elk signaal dat je als “waarheid” ziet en noteer welke vraag het beantwoordt (beschikbaarheid, latentie, fouten, deploy‑impact, incidentrespons).
Map bestaande dat bronnen
De meeste teams dekken de basis met een mix van:
- Status checks / synthetic probes (uptime en basis responstijd)
- Metrics (latency‑percentielen, foutpercentages, saturatie)
- Logs (fouttellingen, meest falende endpoints)
- Traces (waar tijd in latency wordt besteed over afhankelijkheden)
- Ticketing/incidenttools (incident start/eind, severity, owner, postmortem links)
Wees expliciet over welke systemen gezaghebbend zijn. Bijvoorbeeld: je “uptime SLI” kan alleen afkomstig zijn van synthetic probes, niet van serverlogs.
Beslis push vs pull (en hoe vaak)
- Pull werkt goed voor API's (Prometheus, cloud monitoring, ticketing): je app polled volgens schema.
- Push is beter voor high‑volume events (deploys, incidents, alerts): systemen sturen webhooks/events naar je app.
Stel updatefrequentie in naar gebruiksgeval: dashboards kunnen elke 1–5 minuten verversen, terwijl scorecards elk uur/dag kunnen worden berekend.
Normaliseer identifiers en eigenaarschap
Maak consistente IDs voor tools/services, omgevingen (prod/stage) en owners. Stem naamgevingsregels vroeg af zodat “Payments-API”, “payments_api” en “payments” niet drie verschillende entiteiten worden.
Retentie en privacy
Plan wat je bewaart en hoe lang (bijv. raw events 30–90 dagen, dagelijkse aggregaten 12–24 maanden). Vermijd het opnemen van gevoelige payloads; bewaar alleen metadata die nodig is voor betrouwbaarheidanalyse (timestamps, statuscodes, latency‑buckets, incidenttags).
Ontwerp het datamodel en de databaseschema
Je schema moet twee dingen makkelijk maken: dagelijkse vragen beantwoorden (“is deze tool gezond?”) en reconstrueren wat er gebeurde tijdens een incident (“wanneer begonnen de symptomen, wie wijzigde wat, welke alerts werden getriggerd?”). Begin met een klein set kernentiteiten en maak relaties expliciet.
Kernentiteiten (begin minimaal)
- Tool/Service: de interne tool die wordt gevolgd (naam, omschrijving, omgeving, criticaliteit).
- Check: een specifieke uptime of synthetic check gekoppeld aan een tool (type, target URL, schema, ingeschakeld).
- Metric: time‑series datapoints (latency, success rate, error count) gerelateerd aan een tool of check.
- SLO: het target en evaluatievenster (bijv. 99.9% over 30 dagen) plus error‑budget instellingen.
- Incident: een betrouwbaarheid‑impactend event (severity, status, start/eind, samenvatting).
- Event: een tijdlijnrecord voor incidenten (statuswijzigingen, notities, ontvangen alerts, toegepaste mitigatie).
- Owner: team of persoon verantwoordelijk voor de tool.
Relaties die queries simpel houden
Een praktisch uitgangspunt:
- Tool heeft veel Checks (en kan veel SLOs hebben).
- Check heeft veel Metrics (of metric‑streams).
- Incident behoort tot Tool, en Incident heeft veel Events voor de timeline.
- Tool behoort tot Owner (of many‑to‑many als gedeeld eigenaarschap vaak is).
Deze structuur ondersteunt dashboards (“tool → actuele status → recente incidenten”) en drill‑down (“incident → events → gerelateerde checks en metrics”).
Audit‑velden en tagging
Voeg audit‑velden toe overal waar je verantwoordelijkheid en geschiedenis nodig hebt:
created_by, created_at, updated_atstatus plus status change tracking (of in de Event‑tabel of een dedicated history‑tabel)
Voeg tenslotte flexibele tags toe voor filteren en rapportage (bv. team, criticaliteit, systeem, compliance). Een tool_tags join‑tabel (tool_id, key, value) houdt tagging consistent en maakt scorecards en rollups later veel eenvoudiger.
Kies een tech‑stack en deploymentmodel
Je reliability‑tracker moet in het beste geval saai zijn: makkelijk te runnen, makkelijk te veranderen en makkelijk te ondersteunen. De “juiste” stack is meestal die welke je team zonder heldendaden kan onderhouden.
Begin met wat je team al levert
Kies een mainstream webframework dat je team goed kent—Node/Express, Django of Rails zijn allemaal solide opties. Geef prioriteit aan:
- Duidelijke conventies (zodat nieuwe bijdragers niet verdwalen)
- Goede libraries voor auth, background jobs en charts
- Voorspelbare upgradepaden
Als je integreert met interne systemen (SSO, ticketing, chat), kies het ecosysteem waar die integraties het makkelijkst zijn.
Als je de eerste iteratie wilt versnellen, kan een vibe‑coding platform zoals Koder.ai een praktisch startpunt zijn: je beschrijft je entiteiten (tools, checks, SLOs, incidenten), workflows (alert → incident → postmortem) en dashboards in chat, en genereert dan snel een werkende webapp‑scaffold. Omdat Koder.ai vaak React frontend en Go + PostgreSQL backend target, sluit het goed aan bij de “saai, onderhoudbaar” default stack die veel teams prefereren—en je kunt de broncode exporteren als je later volledig handmatig wilt verdergaan.
Eerst database, daarna ondersteunende onderdelen
Voor de meeste interne reliability‑apps is PostgreSQL de juiste default: het kan relationele rapportage, tijdsgebaseerde queries en auditing goed aan.
Voeg extra componenten alleen toe wanneer ze een echt probleem oplossen:
- Cache (bv. Redis) als dashboards traag zijn of je rate‑limits van upstream APIs raakt
- Queue/background jobs (Redis + worker, Sidekiq, Celery, BullMQ) voor polling van uptime, verzenden van notificaties en genereren van rapporten
Hosting en deploymentmodel
Kies tussen:
- Interne cloud / Kubernetes wanneer je striktere netwerktoegang tot interne services nodig hebt
- PaaS wanneer je eenvoudigere ops en snelle iteratie wilt
Standaardiseer dev/stage/prod en automatiseer deployments (CI/CD), zodat wijzigingen niet stilletjes betrouwbaarheidscijfers veranderen. Als je een platformbenadering gebruikt (inclusief Koder.ai), zoek naar features zoals omgeving‑scheiding, deployment/hosting en snelle rollback (snapshots) zodat je veilig kunt itereren zonder de tracker zelf te breken.
Configuratiemanagement waarop je kunt vertrouwen
Documenteer configuratie op één plek: environment‑variabelen, secrets en feature flags. Houd een duidelijk “hoe lokaal draaien”‑gids en een minimaal runbook (wat te doen als ingestie stopt, de queue achterloopt of de database limieten bereikt). Een korte pagina in /docs is vaak genoeg.
Ontwerp de UX: dashboards, drill‑downs en workflows
Start een gefocuste pilot
Zet een lichte tracker op voor 2–3 tools om SLIs, alerting en eigenaarschap te valideren.
Een reliability‑tracker slaagt als mensen twee vragen binnen enkele seconden kunnen beantwoorden: “Gaat het goed?” en “Wat doe ik nu?” Ontwerp schermen rond die beslissingen, met duidelijke navigatie van overzicht → specifieke tool → specifiek incident.
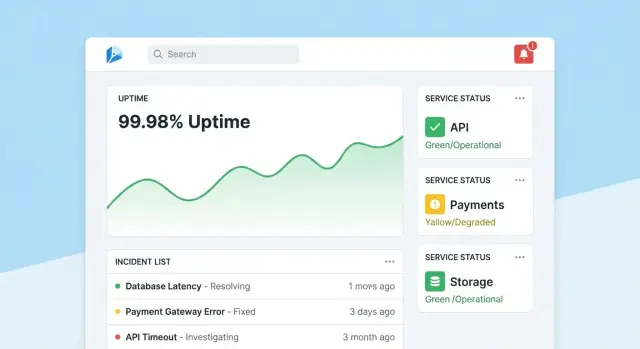
Homepage: een snelle health‑read
Maak de homepage een compact command center. Begin met een algemene health‑samenvatting (bijv. aantal tools die SLOs halen, actieve incidenten, grootste huidige risico's), en toon dan recente incidenten en alerts met statusbadges.
Hou de standaardview rustig: highlight alleen wat aandacht nodig heeft. Geef elke tegel een directe drill‑down naar de getroffen tool of het incident.
Elke tool‑pagina moet beantwoorden “Is deze tool betrouwbaar genoeg?” en “Waarom/waarom niet?” Voeg toe:
- Huidige SLO‑status met een eenvoudige pass/fail en resterend error‑budget
- Grafieken voor uptime, latentie of foutpercentage over selecteerbare tijdsintervallen
- Recente wijzigingen (deploys, config‑edits, check‑updates) zodat patronen duidelijk zijn
- Runbooks en owners: een prominente “Wat te doen”‑sectie met links en contacten
Ontwerp grafieken voor niet‑experts: label eenheden, markeer SLO‑drempels en voeg korte uitleg (tooltips) toe in plaats van dichte technische controls.
Incident‑pagina: gedeelde context en timeline
Een incident‑pagina is een levend record. Voeg een tijdlijn toe (automatisch vastgelegde events zoals alert fired, acknowledged, mitigated), menselijke updates, getroffen gebruikers en genomen acties.
Maak updates makkelijk om te publiceren: één tekstvak, vooraf gedefinieerde status (Investigating/Identified/Monitoring/Resolved) en optionele interne notities. Wanneer het incident gesloten wordt, moet een “Start postmortem”‑actie feiten uit de tijdlijn voorinvullen.
Admin‑pagina's: eigenaarschap en consistentie
Admins hebben eenvoudige schermen nodig om tools, checks, SLO‑targets en owners te beheren. Optimaliseer voor correctheid: zinvolle defaults, validatie en waarschuwingen wanneer wijzigingen rapportage beïnvloeden. Voeg een zichtbare “last edited”‑tracé toe zodat mensen de cijfers vertrouwen.
Implementeer authenticatie, permissies en audit trails
Reliability‑data blijft alleen nuttig als mensen erop vertrouwen. Dat betekent elke wijziging koppelen aan een identiteit, beperken wie grote wijzigingen kan doen en een duidelijke geschiedenis bewaren die je bij reviews kunt raadplegen.
Authenticatie: gebruik wat je bedrijf al gebruikt
Voor een interne tool is standaard SSO (SAML) of OAuth/OIDC via je identity provider (Okta, Azure AD, Google Workspace) aan te raden. Dit vermindert wachtwoordbeheer en maakt onboarding/offboarding automatisch.
Praktische details:
- Handhaaf MFA via de IdP (implementatie in de app vermijden).
- Map IdP‑groepen naar app‑rollen bij login.
- Stel korte sessietijden in en ondersteun handmatig uitloggen.
Permissies: role‑based toegang met “protected actions”
Begin met simpele rollen en voeg fijnmazige regels pas toe wanneer nodig:
- Viewer: read‑only dashboards en scorecards voor stakeholders.
- Editor: maak/update checks, incidenten en notities.
- Admin: beheer SLO‑definities, thresholds, integraties en gebruikers/rolmappings.
Bescherm acties die betrouwbaarheid of rapportage kunnen veranderen:
- Alleen Admins mogen SLO‑targets, alert‑thresholds of data‑source mappings wijzigen.
- Beperk wie incidenten mag sluiten of als “resolved” mag markeren, en vereis een resolutie‑samenvatting.
Audit trails: onveranderlijke geschiedenis van wijzigingen
Log elke wijziging aan SLOs, checks en incidentvelden met:
- wie het deed (gebruiker + rol)
- wanneer het gebeurde (timestamp)
- wat er veranderde (voor/na‑waarden)
- waar het vandaan kwam (UI, API, automatisering)
Maak auditlogs doorzoekbaar en zichtbaar vanuit relevante detailpagina's (bv. een incident‑pagina toont zijn volledige wijzigingsgeschiedenis). Dit houdt reviews feitelijk en vermindert discussie tijdens postmortems.
Bouw monitoring checks en uptime‑collectie
Monitoring is de “sensorlaag” van je reliability‑app: het zet echt gedrag om in data die je kunt vertrouwen. Voor interne tools zijn synthetic checks vaak de snelste weg omdat je kunt bepalen wat “healthy” betekent.
Begin met een klein set checktypes die de meeste interne apps dekken:
- HTTP ping: controleer of de service reageert (statuscode, TLS, basisheaders).
- Endpoint‑validatie: raak een bekende URL aan en valideer iets betekenisvols (verwachte JSON‑structuur, een sleutelstring in HTML of gezondheidspayload).
- Login‑vrije “smoke”‑pad: test indien mogelijk één read‑only flow die de gebruikerservaring weerspiegelt (bijv. laad de dashboardpagina en verifieer dat deze rendert).
Houd checks deterministisch. Als een validatie kan falen door veranderende content, creëer je ruis en ondermijn je vertrouwen.
Verzamel uptime en latentie (en sla het verstandig op)
Leg per check‑run vast:
- Timestamp (start en eind)
- Resultaat: up/down/unknown
- Latentie: totale duur (en optioneel DNS/connect/TTFB als je dat meet)
- Reden: foutcode, timeout, validatiefout of exception‑message
Sla data op als time‑series events (één rij per check‑run) of als geaggregeerde intervallen (bijv. per‑minuut rollups met counts en p95‑latency). Events zijn goed voor debugging; rollups zijn snel voor dashboards. Veel teams doen beide: raw events 7–30 dagen bewaren en rollups voor langeretermijnrapportage.
Behandel outages vs ontbrekende data expliciet
Een ontbrekend checkresultaat betekent niet automatisch “down”. Voeg een expliciete unknown‑status toe voor gevallen zoals:
- de checker‑worker is gestopt
- netwerkpartition tussen checker en target
- configuratie mid‑run verwijderd
Dit voorkomt opgeblazen downtime en maakt “monitoring gaps” zichtbaar als hun eigen operationele issue.
Draai checks on‑schedule met background jobs
Gebruik background workers (cron‑achtige scheduling, queues) om checks op vaste intervallen te draaien (bijv. elke 30–60 seconden voor kritieke tools). Bouw timeouts, retries met backoff en concurrency‑limits in zodat je checker interne services niet overloadt. Persist elke run‑resultaat—ook fouten—zodat je uptime‑dashboard zowel actuele status als betrouwbare historie kan tonen.
Creëer alerting‑ en notificatieflows
Voeg mobiele statusviews toe
Maak nu een webapp en breid later uit naar Flutter‑mobiele schermen wanneer teams status onderweg nodig hebben.
Alerts zijn waar reliability‑tracking in actie verandert. Het doel is simpel: waarschuw de juiste mensen, met de juiste context, op het juiste moment—zonder iedereen te overspoelen.
Koppel alerts aan SLOs (niet alleen aan thresholds)
Begin met alertregels die direct koppelen aan je SLIs/SLOs. Twee praktische patronen:
- Burn‑rate alerts: page wanneer het error‑budget snel verbrandt en je het SLO anders niet haalt.
- Threshold breaches: waarschuw wanneer een metric een duidelijke grens overschrijdt (bv. beschikbaarheid < 99.5% over 15 minuten).
Bewaar bij elke regel het “waarom” naast het “wat”: welke SLO wordt geraakt, het evaluatievenster en de bedoelde severity.
Maak notificaties actiegericht
Stuur notificaties via kanalen waar teams al in leven (email, Slack, Microsoft Teams). Elk bericht moet bevatten:
- Een één‑regel samenvatting (service + symptoom + severity)
- Een directe link naar de relevante dashboard‑view (bv. /services/payments?window=1h)
- Een link naar een incidentpagina als er één is aangemaakt (bv. /incidents/123)
Vermijd het dumpen van ruwe metrics. Geef een korte “next step” zoals “Bekijk recente deploys” of “Open logs.”
Verminder ruis met dedupe, groepering en stille uren
Implementeer:
- Deduplicatie (zelfde alert fingerprint → update bestaand draadje)
- Groepering (één incident kan meerdere gerelateerde alerts verzamelen)
- Stille uren en routeringsregels zodat low‑severity alerts de on‑call niet wakker maken
Ondersteun escalatie en on‑call routing
Zelfs voor een interne tool willen mensen controle. Voeg handmatige escalatie toe (knop op alert/incident‑pagina) en integreer met on‑call tooling indien beschikbaar (PagerDuty/Opsgenie equivalenten), of minstens een configureerbare rotatielijst opgeslagen in je app.
Voeg incidentmanagement en postmortem‑features toe
Incidentmanagement verandert “we zagen een alert” in een gedeelde, traceerbare respons. Bouw dit in zodat mensen van signaal naar coördinatie kunnen zonder tussen tools te springen.
One‑click incidentcreatie
Maak het mogelijk een incident direct te maken vanuit een alert, servicepagina of uptime‑grafiek. Voorinvul sleutelvelden (service, omgeving, alertbron, first seen time) en wijs een uniek incident‑ID toe.
Een goede set defaultvelden houdt het lichtgewicht: severity, impact op interne teams, huidige owner en links naar de triggerende alert.
Status‑levenscyclus en samenwerking
Gebruik een simpele levenscyclus die past bij hoe teams echt werken:
- Open → Investigating → Mitigated → Resolved
Elke statuswijziging legt vast wie het deed en wanneer. Voeg timeline‑updates toe (korte, getimestampte notities), en ondersteuning voor attachments en links naar runbooks en tickets (bijv. /runbooks/payments-retries of /tickets/INC-1234). Dit wordt de enkele thread voor “wat gebeurde en wat deden we.”
Postmortems met actiepunten
Postmortems moeten snel te starten en consistent te beoordelen zijn. Bied templates met:
- Samenvatting, impact, detectie en root cause
- Bijdragende factoren (inclusief proceslacunes)
- Wat werkte / wat niet
- Follow‑ups met owners en deadlines
Koppel actiepunten terug aan het incident, volg voltooiing en toon achterstallige items op teamdashboards. Als je leerrondes ondersteunt, bied een “blameless” modus die focust op systeem‑ en proceswijzigingen in plaats van individuele fouten.
Rapportage en reliability‑scorecards
Begin met Go en Postgres
Genereer een onderhoudbare backend met PostgreSQL‑schema's afgestemd op tools, checks, SLOs en incidenten.
Rapportage is waar reliability‑tracking besluitvorming mogelijk maakt. Dashboards helpen operators; scorecards helpen leiders begrijpen of interne tools verbeteren, welke gebieden investering nodig hebben en wat “goed” betekent.
Wat in een scorecard te zetten
Bouw een consistente, herhaalbare view per tool (en optioneel per team) die snel een paar vragen beantwoordt:
- SLO‑naleving over tijd: toon de huidige periode (week/maand/kwartaal) en een trendlijn tegen het SLO‑target.
- Top onbetrouwbare tools: rangschik op gemiste SLO, hoogste downtime‑minuten of grootste error‑budget burn.
- MTTR: mediaan en p90 time‑to‑restore, zodat één lang incident geen patroon verbergt.
- Incidentaantallen: totaal aantal incidenten + severity‑verdeling (Sev1–Sev3), met vergelijking naar de vorige periode.
Voeg waar mogelijk lichte context toe: “SLO gemist door 2 deploys” of “Meeste downtime door dependency X”, zonder het rapport in een volledige incidentreview te veranderen.
Filters die leiderschap bruikbaar maken
Leiders willen zelden “alles”. Voeg filters toe voor team, tool‑criticaliteit (bv. Tier 0–3) en tijdsvak. Zorg dat hetzelfde tool in meerdere rollups kan verschijnen (platformteam is eigenaar, finance is afhankelijk).
Samenvattingen en export
Bied wekelijkse en maandelijkse samenvattingen die buiten de app gedeeld kunnen worden:
- Eén‑klik CSV export voor spreadsheets
- Schone PDF export voor statusreviews
Houd de verhaalvoering consistent (“Wat veranderde sinds de vorige periode?” “Waar zitten we over budget?”). Als stakeholders een primer nodig hebben, verwijs naar een korte gids zoals /blog/sli-slo-basics.
Beveiliging, datakwaliteit en operationele hardening
Een reliability‑tracker wordt snel een bron van waarheid. Behandel het als een productiesysteem: secure by default, resistent tegen slechte data en makkelijk te herstellen als er iets misgaat.
Bescherm het app‑oppervlak
Sluit elk endpoint af—ook “internal‑only” ones.
- Valideer inputs aan de grens (types, ranges, allowed enums, max payload sizes) en verwerp onbekende velden.
- Voeg rate limiting per gebruiker/service token toe om te voorkomen dat lawaaierige clients ingestie of dashboards overbelasten.
- Gebruik geparametriseerde queries en veilige ORM‑patronen om injection‑issues te vermijden.
Secrets en toegangscontrole
Houd credentials uit de code en uit logs.
Sla secrets op in een secret manager en roteer ze. Geef de webapp least‑privilege database‑toegang: aparte read/write rollen, beperk toegang tot alleen de benodigde tabellen en gebruik kort‑levende credentials waar mogelijk. Versleutel data in transit (TLS) tussen browser↔app en app↔database.
Datakwaliteit guardrails
Reliability‑metrics zijn alleen bruikbaar als de onderliggende events betrouwbaar zijn.
Voeg server‑side checks toe voor timestamps (timezone/clock skew), verplichte velden en idempotency‑sleutels om retries te dedupliceren. Track ingestie‑fouten in een dead‑letter queue of “quarantine”‑tabel zodat slechte events geen dashboards vergiftigen.
Operationele basics (sla niet over)
Automatiseer database‑migraties en test rollbacks. Plan backups, herstel ze regelmatig en documenteer een minimaal disaster‑recoveryplan (wie, wat, hoe lang).
Maak tenslotte de reliability‑app zelf betrouwbaar: voeg healthchecks toe, basismonitoring voor queue‑lag en DB‑latency, en alert wanneer ingestie stilletjes naar nul zakt.
Rollout‑plan en iteratie‑roadmap
Een reliability‑tracker slaagt als mensen het vertrouwen en echt gebruiken. Behandel de eerste release als een leerloop, niet als een “big bang”‑lancering.
Begin met een gefocuste pilot
Kies 2–3 interne tools die veel gebruikt worden en duidelijke owners hebben. Implementeer een klein set checks (bijv. homepage availability, login success en een belangrijk API‑endpoint) en publiceer één dashboard dat antwoordt: “Is het online? Zo niet, wat veranderde en wie is eigenaar?”
Houd de pilot zichtbaar maar beperkt: één team of een kleine groep power users is genoeg om de flow te valideren.
Verzamel feedback waar het pijn doet
In de eerste 1–2 weken verzamel actief feedback over:
- Wat verwarrend aanvoelt (metric‑namen, grafieken, filters, definities)
- Wat lawaaierig is (alerts die niet overeenkomen met gebruikersimpact)
- Wat ontbreekt (eigenaarschap, runbooks, links naar incidenten)
Zet feedback om in concrete backlog‑items. Een eenvoudige “Rapporteer een probleem met deze metric”‑knop op elke grafiek brengt vaak de snelste inzichten boven tafel.
Itereer met integraties en automatisering
Voeg waarde toe in lagen: verbind eerst met je chattool voor notificaties, daarna met je incidenttool voor automatische ticketcreatie, en dan CI/CD voor deploy‑markers. Elke integratie moet handwerk verminderen of time‑to‑diagnose verkorten—anders is het alleen maar complexiteit.
Als je snel prototypet, overweeg Koder.ai’s planning‑modus om de initiële scope (entiteiten, rollen en workflows) te mappen voordat je de eerste build genereert. Het is een eenvoudige manier om het MVP strak te houden—en omdat je snapshots en rollback kunt gebruiken, kun je veilig itereren op dashboards en ingestie terwijl teams definities verfijnen.
Definieer succesmetrics en breid uit
Voordat je naar meer teams uitrolt, definieer succesmetrics zoals wekelijkse actieve dashboardgebruikers, verminderde time‑to‑detect, minder dubbele alerts of consistente SLO‑reviews. Publiceer een lichte roadmap in /blog/reliability-tracking-roadmap en breid tool‑voor‑tool uit met duidelijke owners en trainingssessies.