Waarom Joe Beda’s vroege Kubernetes-keuzes nog steeds belangrijk zijn
Joe Beda was een van de sleutelpersonen achter het vroege ontwerp van Kubernetes—samen met andere oprichters die lessen uit Google’s interne systemen meenamen naar een open platform. Zijn invloed ging niet over het najagen van hippe features; het ging over het kiezen van eenvoudige primitieve bouwstenen die echte productiechaos konden overleven en toch begrijpelijk bleven voor dagelijkse teams.
Die vroege keuzes zijn de reden dat Kubernetes meer werd dan “een containertool”. Het veranderde in een herbruikbare kernel voor moderne applicatieplatforms.
Containerorkestratie, in gewone woorden
“Containerorkestratie” is de set regels en automatisering die je app draaiend houdt wanneer machines uitvallen, verkeer piekt of je een nieuwe versie uitrolt. In plaats van dat een mens servers in de gaten houdt, plant het systeem containers op computers, herstart ze bij crashes, spreidt ze voor veerkracht en zorgt voor netwerkverbindingen zodat gebruikers ze kunnen bereiken.
De rommel vóór Kubernetes
Voordat Kubernetes algemeen werd, plakten teams vaak scripts en aangepaste tools aan elkaar om basisvragen te beantwoorden:
- Waar moet deze container nu draaien?
- Wat gebeurt er als een node om 2 uur 's nachts uitvalt?
- Hoe deployen we veilig zonder downtime?
- Hoe vinden services elkaar als IP-adressen continu veranderen?
Die doe-het-zelf-systemen werkten—tot ze het niet meer deden. Elke nieuwe app of team voegde eigen logica toe, en operationele consistentie was moeilijk te bereiken.
Wat dit artikel behandelt
Dit stuk loopt de vroege ontwerpkeuzes van Kubernetes door (de “vorm” van Kubernetes) en waarom ze nog steeds moderne platforms beïnvloeden: het declaratieve model, controllers, Pods, labels, Services, een sterke API, consistente clusterstaat, plug-in scheduling en uitbreidbaarheid. Zelfs als je Kubernetes niet direct draait, gebruik je waarschijnlijk een platform dat op deze ideeën is gebouwd—of je worstelt met dezelfde problemen.
Het probleem dat Kubernetes probeerde op te lossen
Vóór Kubernetes betekende “containers draaien” meestal het draaien van een paar containers. Teams plakte bash-scripts, cronjobs, golden images en een handvol ad-hoc tools aan elkaar om dingen te deployen. Als iets kapot ging, leefde de oplossing vaak in iemands hoofd—of in een README die niemand vertrouwde. Operaties waren een aaneenschakeling van eenmalige ingrepen: processen herstarten, load balancers omzetten, schijf schoonmaken en gokken welke machine veilig te raken was.
Containers op schaal creëerden nieuwe faalwijzen
Containers maakten packaging makkelijker, maar namen de rommel van productie niet weg. Op schaal faalt het systeem op meer manieren en vaker: nodes verdwijnen, netwerken partitioneren, images rollen niet consistent uit en workloads driften af van wat je denkt dat draait. Een “simpele” deploy kan in een cascade veranderen—sommige instanties bijgewerkt, andere niet, sommige vastgelopen, sommige gezond maar onbereikbaar.
Het echte probleem was niet het starten van containers. Het was het draaiend houden van de juiste containers, in de juiste vorm, ondanks constante wisselingen.
Een consistent model over infrastructuren heen
Teams gingen ook om met verschillende omgevingen: on‑prem hardware, VM's, vroege cloudproviders en allerlei netwerken en opslagoplossingen. Elk platform had zijn eigen vocabulaire en faalpatronen. Zonder een gedeeld model betekende elke migratie het herschrijven van operationele tooling en het bijscholen van mensen.
Kubernetes wilde een enkele, consistente manier bieden om applicaties en hun operationele behoeften te beschrijven, ongeacht waar de machines staan.
Ontwikkelaars wilden self-service: deployen zonder tickets, schalen zonder om capaciteit te moeten vragen en terugrollen zonder drama. Ops-teams wilden voorspelbaarheid: gestandaardiseerde health checks, herhaalbare deploys en een duidelijke bron van waarheid voor wat er zou moeten draaien.
Kubernetes probeerde geen fancy scheduler te zijn. Het wilde de basis vormen voor een betrouwbaar applicatieplatform—één dat rommelige realiteit omzet in een systeem waar je over kunt redeneren.
Beslissing 1: Een declaratief, desired-state-model
Een van de invloedrijkste vroege keuzes was Kubernetes declaratief maken: je beschrijft wat je wilt en het systeem werkt eraan om de werkelijkheid daarmee te laten overeenkomen.
Desired state, uitgelegd met een thermostaat
Een thermostaat is een nuttig dagelijks voorbeeld. Je zet de verwarming niet handmatig elke paar minuten aan en uit. Je stelt een gewenste temperatuur in—bijv. 21°C—en de thermostaat controleert de kamer en past de verwarming aan om dicht bij dat doel te blijven.
Kubernetes werkt op dezelfde manier. In plaats van de cluster stap voor stap te instrueren “start deze container op die machine, herstart hem als hij faalt”, declareer je het resultaat: “Ik wil 3 kopieën van deze app draaiend.” Kubernetes controleert continu wat er daadwerkelijk draait en corrigeert afwijkingen.
Minder handmatige stappen, minder verrassingen
Declaratieve configuratie verkleint de verborgen “ops-checklist” die vaak in iemands hoofd of in een half-aangepast runbook leeft. Je past de config toe en Kubernetes regelt de mechanica—plaatsing, herstarts en het verzoenen van wijzigingen.
Het maakt veranderingen ook makkelijker bespreekbaar. Een wijziging is zichtbaar als een diff in configuratie, niet als een reeks ad-hoccommando's.
Herhaalbaarheid tussen omgevingen
Omdat de gewenste staat is opgeschreven, kun je dezelfde aanpak hergebruiken in dev, staging en productie. De omgeving kan verschillen, maar de intentie blijft consistent, waardoor deploys voorspelbaarder en makkelijker te auditen zijn.
De afwegingen
Declaratieve systemen hebben een leercurve: je moet denken in “wat moet waar zijn” in plaats van “wat doe ik nu”. Ze vertrouwen ook sterk op goede defaults en duidelijke conventies—zonder die kunnen teams configs produceren die technisch werken maar moeilijk te begrijpen en te onderhouden zijn.
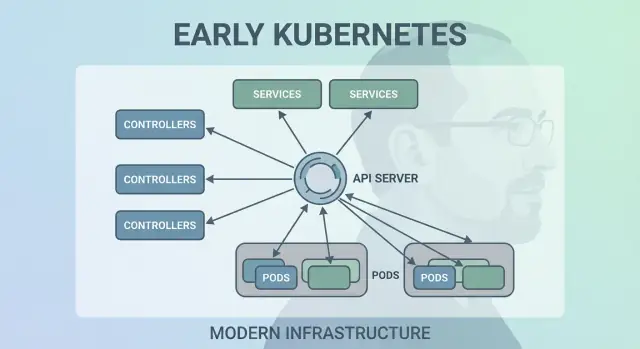
Beslissing 2: Control loops (controllers) als motor
Kubernetes slaagde niet omdat het containers één keer kon draaien—het slaagde omdat het ze in de loop van de tijd correct kon houden. De grote ontwerpzet was om “control loops” (controllers) de kernmotor van het systeem te maken.
Wat een controller is
Een controller is een simpele lus:
- Kijk naar de huidige staat (wat draait er echt)
- Vergelijk die met de gewenste staat (wat je hebt gevraagd)
- Onderneem acties totdat de twee overeenkomen
Het is minder een eenmalige taak en meer autopilot. Je hoeft workloads niet te “bewaken”; je declareert wat je wilt en controllers sturen de cluster steeds terug naar dat resultaat.
Omgaan met crashes, nodeverlies en drift
Dit patroon is waarom Kubernetes veerkrachtig is als de echte wereld dingen kapotmaakt:
- Containercrashes: de controller merkt minder draaiende instanties dan gewenst en start vervangers.
- Nodeverlies: als een node verdwijnt, plannen controllers pods elders opnieuw in om het gewenste aantal te herstellen.
- Configuratiedrift: als iemand resources wijzigt of verwijdert, verzoenen controllers het verschil en herstellen ze het.
In plaats van fouten als uitzonderingen te behandelen, zien controllers ze als routine “staat-komt-niet-overeen”-gevallen en repareren ze ze op dezelfde manier elke keer.
Waarom het beter schaalt dan scripts
Traditionele automatiseringsscripts veronderstellen vaak een stabiele omgeving: voer stap A uit, daarna B, dan C. In gedistribueerde systemen breken die aannames voortdurend. Controllers schalen beter omdat ze idempotent zijn (veilig herhaaldelijk uit te voeren) en eventueel consistent (ze blijven proberen tot het doel is bereikt).
Alledaagse voorbeelden: Deployments en ReplicaSets
Als je een Deployment hebt gebruikt, heb je op control loops vertrouwd. Onder de motorkap gebruikt Kubernetes een ReplicaSet-controller om te zorgen dat het gevraagde aantal pods bestaat—en een Deployment-controller om rolling updates en rollbacks voorspelbaar te beheren.
Beslissing 3: Pods als de atomische scheduler-eenheid
Kubernetes had ook “alleen containers” kunnen schedulen, maar het team van Joe Beda introduceerde Pods om het kleinste inzetbare object te representeren dat de cluster op een machine plaatst. Het sleutelidee: veel echte applicaties zijn geen enkel proces. Het zijn een kleine groep nauw verbonden processen die samen moeten leven.
Waarom Pods in plaats van individuele containers?
Een Pod is een omhulsel rond één of meer containers die hetzelfde lot delen: ze starten samen, draaien op dezelfde node en schalen samen. Dit maakt patronen zoals sidecars natuurlijk—denk aan een log shipper, proxy, config reloader of security-agent die altijd bij de hoofdapp hoort.
In plaats van elke app die hulpjes te laten integreren, kun je ze als aparte containers verpakken die toch als één eenheid gedrag vertonen.
Wat Pods mogelijk maakten voor netwerk en opslag
Pods maakten twee belangrijke aannames praktisch:
- Netwerk: containers in een Pod delen een netwerkidentiteit (één IP en poortruimte). De hoofdapp kan met de sidecar praten via
localhost, wat simpel en snel is.
- Opslag: containers in een Pod kunnen volumes delen. Een helper kan bestanden schrijven die de hoofdapp leest (of andersom), zonder omslachtige externe sprongen.
Deze keuzes verminderden de noodzaak voor maatwerk-koppelcode, terwijl containers op procesniveau geïsoleerd bleven.
Waar Pods nieuwkomers verwarren
Nieuwe gebruikers verwachten vaak “één container = één app” en struikelen dan over Pod-niveauconcepten: herstarts, IP's en schaling. Veel platforms verhullen dit door opiniërende templates te bieden (bijv. “web service”, “worker” of “job”) die Pods achter de schermen genereren—zodat teams profiteren van sidecars en gedeelde resources zonder dagelijks over Pod-mechanica na te hoeven denken.
Beslissing 4: Labels en selectors voor losse koppeling
Bouw met desired-state-denken
Genereer een kleine service met stabiele API's en verfijn die vervolgens zoals een controller-loop.
Een stilzwijgend krachtige vroege keuze in Kubernetes was labels als eersteklas metadata te behandelen en selectors als de primaire manier om “dingen te vinden”. In plaats van relaties hard te coderen (zoals “deze exacte drie machines draaien mijn app”), moedigt Kubernetes je aan groepen te beschrijven met gedeelde attributen.
Een label is een eenvoudige key/value-paar dat je toevoegt aan resources—Pods, Deployments, Nodes, Namespaces en meer. Ze fungeren als consistente, doorzoekbare “tags”:
app=checkoutenv=prodtier=frontend
Omdat labels lichtgewicht en door gebruikers gedefinieerd zijn, kun je je organisatie realiteit modelleren: teams, kostencenters, compliance-zones, releasekanalen of wat maar belangrijk is voor je operatie.
Selectors: relaties zonder strakke afhankelijkheden
Selectors zijn queries over labels (bijv. “alle Pods waar app=checkout en env=prod”). Dit verslaat vaste hostlijsten omdat het systeem zich kan aanpassen als Pods worden verplaatst, opgeschaald of vervangen tijdens rollouts. Je configuratie blijft stabiel, zelfs als de onderliggende instanties continu veranderen.
Dynamische groepering op schaal
Dit ontwerp schaalt operationeel: je beheert geen duizenden instance-identiteiten—je beheert een paar betekenisvolle label-sets. Dat is de kern van losse koppeling: componenten verbinden met groepen die veilig van samenstelling kunnen veranderen.
Labels doen meer dan groeperen
Zodra labels bestaan, worden ze een gedeelde woordenschat in het platform. Ze worden gebruikt voor traffic routing (Services), beleidsscheiding (NetworkPolicy), observability-filters (metrics/logs) en zelfs kostenregistratie en chargeback. Eén simpel idee—dingen consistent taggen—opent een heel ecosysteem van automatisering.
Beslissing 5: Services voor stabiel netwerken
Kubernetes moest een manier vinden om netwerken voorspelbaar te laten voelen, ook al zijn containers dat niet. Pods worden vervangen, verplaatst en opgeschaald—dus hun IP's en zelfs de specifieke machines waarop ze draaien veranderen. Het kernidee van een Service is simpel: geef een stabiele “voordeur” naar een verschuivende set Pods.
Stabiele toegang tot veranderende Pods
Een Service geeft je een consistente virtuele IP en DNS-naam (zoals payments). Achter die naam houdt Kubernetes continu bij welke Pods overeenkomen met de Service’s selector en routeert verkeer dienovereenkomstig. Als een Pod sterft en er een nieuwe verschijnt, wijst de Service nog steeds naar de juiste plek zonder dat je applicatie-instellingen hoeft aan te passen.
Service discovery die configuratie vereenvoudigde
Deze aanpak verwijderde veel handmatig bedraden. In plaats van IP's in configbestanden te bakstenen, kunnen apps vertrouwen op namen. Je deployt de app, deployt de Service en andere componenten vinden hem via DNS—geen aangepaste registry nodig, geen harde endpoints.
Ingebouwde load balancing voor betrouwbaarheid
Services brachten ook standaard load-balancing over gezonde endpoints. Dat betekende dat teams niet voor elke interne microservice hun eigen load balancer hoefden te bouwen. Verdeling van verkeer verkleint de impact van één Pod-fout en maakt rolling updates minder risicovol.
Grenzen—en hoe Ingress/Gateway dit uitbreiden
Een Service is geweldig voor L4 (TCP/UDP) verkeer, maar modelleert geen HTTP-routeringsregels, TLS-terminatie of edgebeleid. Daar komen Ingress en, steeds meer, de Gateway API om de hoek kijken: ze bouwen voort op Services om hostnames, paden en externe toegangspunten netter af te handelen.
Beslissing 6: Een API als productoppervlak
Een van de stilletjes radicaalste vroege keuzes was Kubernetes te behandelen als een API waarop je bouwt—niet als een monolithisch gereedschap dat je “gebruikt”. Die API-eersthouding maakte Kubernetes minder een product om door te klikken en meer een platform dat je kunt uitbreiden, scripten en besturen.
Als de API het oppervlak is, kunnen platformteams standaardiseren hoe applicaties beschreven en beheerd worden, ongeacht welke UI, pipeline of intern portaal erbovenop zit. “Een app deployen” wordt “API-objecten indienen en bijwerken” (zoals Deployments, Services en ConfigMaps), wat een veel schoner contract is tussen appteams en het platform.
Omdat alles via dezelfde API gaat, hebben nieuwe tools geen bevoegde achterdeurtjes nodig. Dashboards, GitOps-controllers, policy-engines en CI/CD-systemen kunnen allemaal opereren als normale API-clients met beperkte permissies.
Die symmetrie is belangrijk: dezelfde regels, auth, auditing en admission controls gelden of het verzoek nu van een persoon, een script of een intern platform-UI komt.
Versionering en compatibiliteit voor langlopende clusters
API-versionering maakte het mogelijk Kubernetes te laten evolueren zonder elke cluster of tool ineens te breken. Deprecations kunnen gefaseerd worden; compatibiliteit kan getest worden; upgrades kunnen gepland worden. Voor organisaties die clusters jarenlang draaien, is dat het verschil tussen “we kunnen upgraden” en “we zitten vast”.
Wat kubectl werkelijk is
kubectl is niet Kubernetes—het is een client. Dat denkkader duwt teams om in API-workflows te denken: je kunt kubectl vervangen door automatisering, een web-UI of een aangepast portaal, en het systeem blijft consistent omdat het contract de API zelf is.
Beslissing 7: Gecentraliseerde clusterstaat (etcd) en consistentie
Behoud volledige controle over code
Krijg de broncode-export wanneer je diepere aanpassingen of je eigen pipeline wilt.
Kubernetes had één "bron van waarheid" nodig voor hoe de cluster er nu uit zou moeten zien: welke Pods bestaan, welke nodes gezond zijn, waar Services naar verwijzen en welke objecten worden bijgewerkt. Dat is wat etcd biedt.
Wat etcd doet (in simpele termen)
etcd is de database voor de control plane. Wanneer je een Deployment maakt, een ReplicaSet schaalt of een Service update, wordt de gewenste configuratie in etcd geschreven. Controllers en andere control-planecomponenten kijken naar die opgeslagen staat en werken om de realiteit ermee te laten overeenkomen.
Waarom consistentie telt als alles tegelijk reageert
Een Kubernetes-cluster zit vol bewegende delen: schedulers, controllers, kubelets, autoscalers en admission checks kunnen allemaal tegelijk reageren. Als ze verschillende versies van “de waarheid” lezen, ontstaan races—zoals twee componenten die conflicterende beslissingen nemen over dezelfde Pod.
etcd’s sterke consistentie zorgt dat wanneer de control plane zegt “dit is de huidige staat”, iedereen daarop afgestemd is. Die afstemming maakt control loops voorspelbaar in plaats van chaotisch.
Hoe het backups, upgrades en disaster recovery raakt
Omdat etcd de configuratie en geschiedenis van veranderingen bevat, is het ook wat je beschermt tijdens:
- Backups: zonder een etcd-snapshot kun je clusterobjecten niet betrouwbaar herstellen.
- Upgrades: zorgvuldige etcd-health en snapshotting verkleinen upgraderisico.
- Disaster recovery: het herstellen van etcd is vaak de snelste weg om de control plane terug te krijgen met dezelfde intentie.
Praktische richtlijnen
Behandel control-plane-state als kritieke data. Maak regelmatige etcd-snapshots, test restores en bewaar backups buiten de cluster. Als je managed Kubernetes draait, leer wat je provider backupt—en wat jij nog moet backuppen (bijv. persistente volumes en app-data).
Beslissing 8: Plug-in scheduling en resourcebewustzijn
Kubernetes zag “waar een workload draait” niet als bijzaak. Vroeg was de scheduler een apart onderdeel met een duidelijke taak: Pods matchen aan nodes die ze daadwerkelijk kunnen draaien, op basis van de huidige clusterstaat en de vereisten van de Pod.
Hoe de scheduler workloads matcht aan nodes
Op hoog niveau is scheduling een tweestapsbeslissing:
- Filteren: verwijder nodes die niet aan harde constraints voldoen (niet genoeg CPU/geheugen, ontbrekende labels, onverenigbare taints, poorten al in gebruik, enz.).
- Scoren: rangschik de overgebleven nodes op voorkeuren (spreiden over zones, packen voor efficiëntie, lawaaige buren vermijden, affinity-regels respecteren).
Deze structuur maakte het mogelijk Kubernetes-scheduling te evolueren zonder alles te herschrijven.
Scheiding van verantwoordelijkheden: scheduler vs runtime vs netwerk
Een sleutelontwerpkeuze was taken schoon te scheiden:
- De scheduler beslist plaatsing.
- De container runtime (en kubelet) voert uit op de gekozen node.
- De networking layer levert connectiviteit zodra dingen draaien.
Omdat deze zorgen gescheiden zijn, dwingen verbeteringen in het ene gebied (bijv. een nieuwe CNI-plugin) geen nieuw schedulingmodel af.
Constraints en prioriteiten groeiden natuurlijk
Resourcebewustzijn begon met requests en limits, wat de scheduler zinvolle signalen gaf in plaats van giswerk. Van daaruit voegde Kubernetes rijkere controles toe—node affinity/anti-affinity, pod affinity, priorities and preemption, taints en tolerations en topology-aware spreading—gebouwd op dezelfde basis.
Moderne impact: multi-tenant en kostenefficiënte plaatsing
Deze aanpak maakt gedeelde clusters van vandaag mogelijk: teams kunnen kritieke services isoleren met priorities en taints, terwijl iedereen profiteert van hogere benutting. Met betere bin-packing en topology-controls kunnen platforms workloads kostenefficiënter plaatsen zonder betrouwbaarheid op te offeren.
Beslissing 9: Uitbreidbaarheid boven “één ingebouwde manier”
Prototypeer een mobiele companion-app
Genereer een Flutter-mobiele app naast je backend om de volledige workflow te testen.
Kubernetes had met een volledig opiniërende platformervaring kunnen verschijnen—buildpacks, app-routingregels, achtergrondjobs, configconventies en meer. In plaats daarvan hield Joe Beda en het vroege team de kern gefocust op een kleinere belofte: workloads betrouwbaar draaien en herstellen, ze blootleggen en een consistente API bieden om tegen te automatiseren.
Waarom Kubernetes geen complete PaaS probeerde te zijn
Een “complete PaaS” zou één workflow en één set afwegingen aan iedereen hebben opgelegd. Kubernetes richtte zich op een bredere fundering die veel platformstijlen kon ondersteunen—Heroku-achtige eenvoud, enterprise governance, batch + ML-pijplijnen of basale infrastructuurcontrole—zonder een productfilosofie vast te leggen.
Kubernetes’ uitbreidbaarheidsmechanismen creëerden een gecontroleerde manier om mogelijkheden toe te voegen:
- CRD's laten je nieuwe API-typen toevoegen (bijv.
Certificate of Database) die natuurlijk aanvoelen.
- Controllers/operators reconciliëren die nieuwe resources met hetzelfde desired-state-patroon als ingebouwde onderdelen.
- Admission controllers/webhooks dwingen beleid af (security, naamgeving, quota) en muteren defaults bij de API-grens.
Dit betekent dat interne platformteams en leveranciers features als add-ons kunnen uitrollen, terwijl ze nog steeds Kubernetes-primitieven zoals RBAC, namespaces en audit logs gebruiken.
Voordelen—en het grootste risico
Voor leveranciers maakt het onderscheidende producten mogelijk zonder Kubernetes te fork-en. Voor interne teams maakt het een “platform op Kubernetes” mogelijk dat is afgestemd op organisatiebehoeften.
De afweging is ecosysteem-sprawl: te veel CRD's, overlappende tools en inconsistente conventies. Governance—standaarden, eigenaarschap, versiebeheer en deprecatieregels—wordt onderdeel van het platformwerk.
De vroege keuzes van Kubernetes creëerden niet alleen een container-scheduler—ze creëerden een herbruikbare platformkernel. Daarom zijn veel moderne internal developer platforms (IDP's) in de kern “Kubernetes plus opiniërende workflows.” Het declaratieve model, controllers en een consistente API maakten het mogelijk om hogere producten te bouwen—zonder steeds deployment, reconciliatie en service discovery opnieuw uit te vinden.
Kubernetes als gedeelde control plane
Omdat de API het productoppervlak is, kunnen leveranciers en platformteams standaardiseren op één control plane en verschillende ervaringen erbovenop bouwen: GitOps, multi-cluster management, beleid, service-catalogi en deployment-automatisering. Dit is een grote reden dat Kubernetes de gemeenschappelijke noemer voor cloud native platforms werd: integraties richten zich op de API, niet op een specifieke UI.
Wat moeilijk bleef (Day-2 realiteit)
Zelfs met schone abstracties blijft het zwaarste werk operationeel:
- Security: identity, network policy, secrets en supply chain trust
- Upgrades: Kubernetes-versies, CRD's en add-ons die met verschillende snelheden bewegen
- Betrouwbaarheid: controllers debuggen, misconfiguraties en lawaaierige buren
Stel vragen die operationele volwassenheid blootleggen:
- Hoe worden upgrades afgehandeld en wat is het rollback-verhaal?
- Welke onderdelen zijn standaard Kubernetes vs propriëtaire extensies?
- Welke guardrails bestaan er (beleid, defaults, templates) om voetangels te voorkomen?
- Hoe observeerbaar is het systeem (events, logs, audit trails) en wie is eigenaar van incidenten?
Een goed platform vermindert cognitieve last zonder de onderliggende control plane te verbergen of escape-hatches pijnlijk te maken.
Een praktische lens: helpt het platform teams van “idee → draaiende service” te gaan zonder iedereen op dag één Kubernetes-experts te maken? Tools in de “vibe-coding” categorie—zoals Koder.ai—zetten hier op in door teams te laten genereren vanuit chat (web in React, backends in Go met PostgreSQL, mobiel in Flutter) en vervolgens snel te itereren met functies als planning mode, snapshots en rollback. Of je zoiets adopteert of je eigen portaal bouwt, het doel is hetzelfde: behoud Kubernetes’ sterke primitieve bouwstenen terwijl je de workflow-achtergrond eromheen vermindert.
Belangrijke conclusies en praktische lessen
Kubernetes kan ingewikkeld aanvoelen, maar veel van die “vreemdheid” is doelbewust: het is een set kleine primitieve onderdelen die samen in veel soorten platforms kunnen componeren.
Ruim twee veelvoorkomende misvattingen op
Ten eerste: “Kubernetes is alleen Docker-orchestratie.” Kubernetes gaat niet primair over het starten van containers. Het gaat over continu het gewenste staat (wat je wilt dat draait) verzoenen met de actuele staat (wat er echt gebeurt), over fouten, rollouts en veranderende vraag heen.
Ten tweede: “Als we Kubernetes gebruiken, worden we allemaal microservices.” Kubernetes ondersteunt microservices, maar ook monolieten, batchjobs en interne platforms. De eenheden (Pods, Services, labels, controllers en de API) zijn neutraal; je architectuurkeuzes worden niet door het gereedschap voorgeschreven.
Waar de complexiteit echt vandaan komt
De moeilijke onderdelen zijn meestal niet YAML of Pods—het zijn netwerk, security en multi-team gebruik: identiteit en toegang, secret management, policies, ingress, observability, supply-chain controls en het creëren van guardrails zodat teams veilig kunnen uitrollen zonder elkaar in de weg te zitten.
Beslissingsgerichte lessen die je kunt gebruiken
Bij plannen, denk in termen van de originele ontwerpkeuzes:
- Geef de voorkeur aan declaratieve workflows en automatisering die drift kan verzoenen.
- Gebruik labels/selectors om koppeling tussen teams en componenten laag te houden.
- Behandel de API als een product: versionering, conventies en duidelijk eigenaarschap zijn belangrijk.
Een praktische volgende stap
Breng je echte eisen in kaart en koppel ze aan Kubernetes-primitieven en platformlagen:
-
Workloads → Pods/Deployments/Jobs
-
Connectiviteit → Services/Ingress
-
Operaties → controllers, beleid en observability
Als je evalueert of standaardiseert, noteer deze mapping en bespreek die met stakeholders—bouw je platform incrementeel rond de gaten, niet rond trends.
Als je ook de “build”-kant wilt versnellen (niet alleen de “run”-kant), denk na over hoe je delivery-workflow intent omzet in deployable services. Voor sommige teams is dat een gecureerde set templates; voor anderen is het een AI-ondersteunde workflow zoals Koder.ai die een initiële werkende service snel kan produceren en daarna de broncode exporteert voor diepere aanpassing—terwijl je platform nog steeds profiteert van Kubernetes’ kernontwerpbeslissingen eronder.