Waarom teams vastlopen met traditionele integraties
De meeste producten beginnen met eenvoudige point-to-point-integraties: Systeem A roept Systeem B aan, of een klein script kopieert data van de ene plek naar de andere. Dat werkt totdat het product groeit, teams zich opsplitsen en het aantal verbindingen vermenigvuldigt. Al snel vereist elke wijziging coördinatie tussen meerdere services, omdat één klein veld of statusupdate door een keten van afhankelijkheden kan gaan.
Snelheid breekt meestal als eerste. Een nieuwe feature toevoegen betekent meerdere integraties bijwerken, meerdere services redeployen en hopen dat niets anders afhankelijk was van het oude gedrag.
Dan wordt debuggen pijnlijk. Als iets in de UI niet klopt, is het lastig om basisvragen te beantwoorden: wat gebeurde er, in welke volgorde, en welk systeem schreef de waarde die je ziet?
Wat vaak ontbreekt is een audittrail. Als data rechtstreeks van de ene database naar de andere wordt gepusht (of onderweg getransformeerd), verlies je de geschiedenis. Je ziet misschien de eindtoestand, maar niet de reeks gebeurtenissen die daar toe geleid heeft. Incidentreviews en klantondersteuning lijden omdat je het verleden niet kunt afspelen om te bevestigen wat veranderde en waarom.
Dit is ook waar het “wie bezit de waarheid” argument begint. Het ene team zegt: “De billing-service is de bron van waarheid.” Een ander zegt: “De order-service is dat.” In werkelijkheid heeft elk systeem een gedeeltelijk beeld, en point-to-point-integraties veranderen dat meningsverschil in dagelijkse wrijving.
Een simpel voorbeeld: een order wordt gemaakt, daarna betaald, daarna terugbetaald. Als drie systemen elkaar direct updaten, kan elk een ander verhaal krijgen bij retries, timeouts of handmatige fixes.
Dat leidt tot de kernvraag achter Kafka event streaming: moet je alleen werk van de ene plek naar de andere verplaatsen (een queue), of heb je een gedeeld, duurzaam logboek nodig van wat er gebeurd is dat veel systemen kunnen lezen, terugspoelen en vertrouwen (een log)? Het antwoord verandert hoe je je systeem bouwt, debugt en evolveert.
Jay Kreps, Kafka en het idee van de log
Jay Kreps hielp Kafka vormgeven en, belangrijker, de manier waarop teams nadenken over databeweging. De nuttige verschuiving is een mindset: stop met het behandelen van berichten als eenmalige leveringen en begin met het zien van systeemactiviteit als een verslag.
Het kernidee is simpel. Modelleer belangrijke wijzigingen als een stroom onveranderlijke feiten:
- Een order werd aangemaakt.
- Een betaling werd geautoriseerd.
- Een gebruiker veranderde zijn e-mail.
Elk event is een feit dat niet achteraf bewerkt zou moeten worden. Als er later iets verandert, voeg je een nieuw event toe dat de nieuwe waarheid vastlegt. Na verloop van tijd vormen die feiten een log: een append-only geschiedenis van je systeem.
Hier onderscheidt Kafka event streaming zich van veel basis messaging-setup. Veel queues zijn gebouwd rond “stuur het, verwerk het, verwijder het.” Dat is prima wanneer werk puur een overdracht is. De log-aanpak zegt: “bewaar de geschiedenis zodat veel consumers die nu en later kunnen gebruiken.”
Het praktisch superkrachtje is het opnieuw afspelen van geschiedenis.
Als een rapport niet klopt, kun je dezelfde eventgeschiedenis opnieuw door een gefixeerde analytics-job laten lopen en zien waar de cijfers veranderden. Als een bug verkeerde e-mails veroorzaakte, kun je events in een testomgeving afspelen en exact de tijdlijn reproduceren. Als een nieuwe feature historische data nodig heeft, kun je een nieuwe consumer bouwen die vanaf het begin begint en op zijn eigen tempo bijwerkt.
Een concreet voorbeeld: stel dat je fraudcontroles toevoegt nadat je al maanden betalingen hebt verwerkt. Met een log van betaling- en account-events kun je het verleden herafspelen om regels te trainen of kalibreren op echte reeksen, risico-scores voor oude transacties berekenen en “fraud_review_requested” events backfillen zonder je database te herschrijven.
Let op wat dit je dwingt te doen. Een log-gebaseerde aanpak dwingt je events duidelijk te benoemen, ze stabiel te houden en te accepteren dat meerdere teams en services ervan afhankelijk zullen zijn. Het dwingt ook nuttige vragen: Wat is de bron van waarheid? Wat betekent dit event op lange termijn? Wat doen we als we een fout maakten?
De waarde zit niet in de persoon. Het is inzicht dat een gedeelde log het geheugen van je systeem kan worden, en geheugen is wat systemen laat groeien zonder elke keer te breken als je een nieuwe consumer toevoegt.
Queue vs log: het eenvoudigste mentale model
Een message queue is als een takenrij voor je software. Producers zetten werk in de rij, consumers pakken het volgende item, doen het werk en het item is verdwenen. Het systeem draait vooral om elk taakje één keer zo snel mogelijk af te handelen.
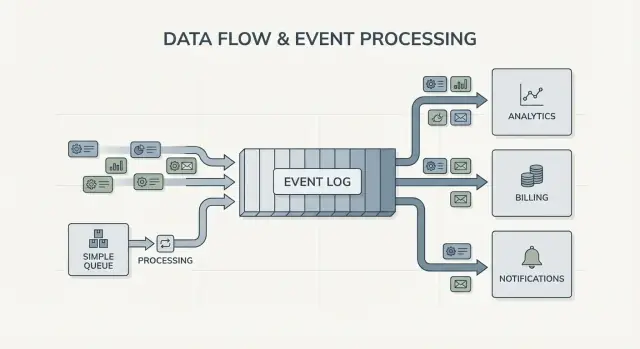
Een log is anders. Het is een geordend verslag van feiten die gebeurd zijn, bewaard in een duurzame volgorde. Consumers “nemen” events niet weg. Ze lezen de log op hun eigen tempo en kunnen deze later opnieuw lezen. In Kafka event streaming is die log het kernidee.
Een praktische manier om het verschil te onthouden:
- Queue = werk dat gedaan moet worden. Zodra een worker bevestigt, verdwijnt het.
- Log = geschiedenis van wat er gebeurd is. Events blijven bestaan voor een retentieperiode.
Retentie verandert het ontwerp. Met een queue, als je later een nieuwe feature nodig hebt die afhankelijk is van oude berichten (analytics, fraudcontroles, replays na een bug), moet je vaak een aparte database toevoegen of ergens extra kopieën gaan bijhouden. Met een log is replay normaal: je kunt een afgeleide view reconstrueren door vanaf het begin te lezen (of vanaf een bekend checkpoint).
Fan-out is een ander groot verschil. Stel dat een checkout-service “OrderPlaced” emit. Met een queue kies je meestal één workergroep om het te verwerken, of je dupliceert werk over meerdere queues. Met een log kunnen billing, e-mail, inventory, search-indexing en analytics allemaal dezelfde eventstroom onafhankelijk lezen. Elk team kan in zijn eigen tempo bewegen en het toevoegen van een nieuwe consumer later vereist geen wijziging bij de producer.
Dus het mentale model is duidelijk: gebruik een queue wanneer je taken verplaatst; gebruik een log wanneer je events vastlegt die meerdere delen van het bedrijf nu of later willen lezen.
Wat event streaming verandert in systeemontwerp
Event streaming draait de standaardvraag om. In plaats van te vragen: “Naar wie stuur ik dit bericht?”, begin je met het opnemen van: “Wat is er zojuist gebeurd?” Dat klinkt klein, maar het verandert hoe je je systeem modelleert.
Je publiceert feiten zoals OrderPlaced of PaymentFailed, en andere delen van het systeem beslissen of, wanneer en hoe ze erop reageren.
Met Kafka event streaming hoeven producers geen lijst met directe integraties meer te hebben. Een checkout-service kan één event publiceren en het hoeft niet te weten of analytics, e-mail, fraudcontroles of een toekomstige recommendation-service het zullen gebruiken. Nieuwe consumers kunnen later verschijnen, oudere kunnen gepauzeerd worden, en de producer gedraagt zich hetzelfde.
Dit verandert ook hoe je herstelt van fouten. In een alleen-berichten wereld, als een consumer iets mist of een bug heeft, is de data vaak “weg” tenzij je aangepaste backups bouwde. Met een log kun je de code repareren en de geschiedenis opnieuw afspelen om de correcte staat opnieuw op te bouwen. Dat verslaat vaak handmatige database-edits of eenmalige scripts die niemand vertrouwt.
In de praktijk zie je de verschuiving op een paar betrouwbare manieren: je behandelt events als duurzaam verslag, je voegt features toe door te subscriben in plaats van producers te wijzigen, je kunt read-models (search-indexen, dashboards) van nul heropbouwen en je krijgt duidelijkere tijdlijnen van wat er gebeurd is over services heen.
Observability verbetert omdat de eventlog een gedeelde referentie wordt. Als iets misgaat, kun je een bedrijfsvolgorde volgen: order aangemaakt, voorraad gereserveerd, betaling opnieuw geprobeerd, verzending ingepland. Die tijdlijn is vaak makkelijker te begrijpen dan verspreide applicatielogs omdat hij gefocust is op zakelijke feiten.
Een concreet voorbeeld: als een kortingsbug bestellingen twee uur verkeerd prijst, kun je een fix uitrollen en de getroffen events opnieuw afspelen om totalen opnieuw te berekenen, facturen bij te werken en analytics te verversen. Je corrigeert uitkomsten door resultaten opnieuw af te leiden, niet door te raden welke tabellen je met de hand moet patchen.
Wanneer een simpele queue voldoende is
Een simpele queue is het juiste gereedschap wanneer je werk verplaatst en geen langdurig verslag bouwt. Het doel is een taak aan een worker over te dragen, uit te voeren en daarna te vergeten. Als niemand het verleden hoeft te herhalen, oude events te inspecteren of later nieuwe consumers toe te voegen, houdt een queue het simpeler.
Queues blinken uit bij achtergrondtaken: inschrijf-e-mails versturen, afbeeldingen schalen na upload, een nachtelijk rapport genereren of een externe API aanroepen die traag kan zijn. In die gevallen is het bericht gewoon een werkticket. Zodra een worker klaar is, heeft het ticket zijn doel bereikt.
Een queue past ook bij het gebruikelijke eigenaarsmodel: één consumergroep is verantwoordelijk voor het werk en andere services verwachten niet hetzelfde bericht onafhankelijk te lezen.
Een queue is meestal genoeg als de meeste van deze waar zijn:
- De data heeft korte levensduurwaarde.
- Eén team of service bezit de taak end-to-end.
- Replays en lange retentie zijn geen vereisten.
- Debugging hangt niet af van het opnieuw afspelen van geschiedenis.
Voorbeeld: een product uploadt gebruikersfoto's. De app schrijft een "resize image" taak naar een queue. Worker A pakt het op, maakt thumbnails, slaat ze op en markeert de taak als klaar. Als de taak twee keer draait, is de output hetzelfde (idempotent), dus at-least-once delivery is prima. Geen andere service hoeft dat ticket later te lezen.
Als je behoeften richting gedeelde feiten (meerdere consumers), replay, audit of “wat geloofde het systeem vorige week?” schuiven, dan betaalt Kafka event streaming en een log-gebaseerde aanpak zich uit.
Wanneer een log-gebaseerde aanpak zich uitbetaalt
Een log-gebaseerd systeem betaalt zich uit wanneer events stoppen met eenmalige berichten te zijn en beginnen met gedeelde geschiedenis te worden. In plaats van “stuur het en vergeet het,” bewaar je een geordend verslag dat veel teams nu of later op hun eigen tempo kunnen lezen.
Het duidelijkste signaal is meerdere consumers. Eén event zoals OrderPlaced kan billing, e-mail, fraudchecks, search-indexing en analytics voeden. Met een log leest elke consumer dezelfde stroom onafhankelijk. Je hoeft geen custom fan-out pipeline te bouwen of te coördineren wie het bericht eerst krijgt.
Een andere winst is kunnen antwoorden op: “Wat wisten we toen?” Als een klant een transactie betwist of een aanbeveling verkeerd leek, maakt een append-only geschiedenis het mogelijk feiten af te spelen zoals ze binnenkwamen. Dat auditspoor is moeilijk later aan een simpele queue toe te voegen.
Je krijgt ook een praktische manier om nieuwe features toe te voegen zonder oude te herschrijven. Als je maanden later een nieuwe “verzendstatus”-pagina toevoegt, kan een nieuwe service zich abonneren en backfillen vanuit bestaande geschiedenis om zijn staat op te bouwen, in plaats van andere systemen om exports te vragen.
Een log-gebaseerde aanpak is vaak de moeite waard wanneer je één of meer van deze behoeften herkent:
- Dezelfde events moeten meerdere systemen voeden (analytics, search, billing, supporttools).
- Je hebt replay, auditing of onderzoek nodig op basis van vroegere feiten.
- Nieuwe services moeten vanuit geschiedenis backfillen zonder eenmalige jobs.
- Ordering per entiteit (per order, per gebruiker) doet ertoe.
- Eventformaten zullen evolueren en je hebt een gecontroleerde manier nodig om versiebeheer te doen.
Een veelvoorkomend patroon is een product dat begint met orders en e-mails. Later wil finance omzetrapporten, product wil funnels en ops wil een live dashboard. Als elke nieuwe behoefte je dwingt data via een nieuw kanaal te kopiëren, lopen de kosten snel op. Een gedeelde eventlog laat teams bouwen op dezelfde bron van waarheid, ook als het systeem groeit en events van vorm veranderen.
Hoe te beslissen, stap voor stap
Kiezen tussen een simpele queue en een log-gebaseerde aanpak is makkelijker als je het als een productkeuze behandelt. Begin bij wat waar moet zijn over een jaar, niet alleen wat deze week werkt.
Een praktische 5-stappen beslissing
-
Breng publishers en readers in kaart. Schrijf op wie events creëert en wie ze nu leest, en voeg waarschijnlijke toekomstige consumers toe (analytics, search-indexing, fraudchecks, klantmeldingen). Als je verwacht dat veel teams dezelfde events onafhankelijk lezen, begint een log logisch te worden.
-
Vraag of je geschiedenis opnieuw moet lezen. Wees specifiek waarom: replay na een bug, backfills of consumers die in verschillend tempo lezen. Queues zijn goed om werk één keer af te handelen. Logs zijn beter wanneer je een verslag wilt dat je kunt herafspelen.
-
Definieer wat “klaar” betekent. Voor sommige workflows betekent klaar: “de taak draaide” (stuur een e-mail, schaal een afbeelding). Voor andere betekent klaar: “het event is een duurzaam feit” (een order is geplaatst, een betaling is geautoriseerd). Duurzame feiten duwen je richting een log.
-
Kies leveringsverwachtingen en beslis hoe je met duplicaten omgaat. At-least-once delivery is gangbaar, wat duplicaten kan veroorzaken. Als een duplicaat schadelijk kan zijn (dubbel afschrijven), plan dan idempotentie: sla verwerkte event-ID's op, gebruik unieke constraints of maak updates veilig om te herhalen.
-
Begin met één dunne slice. Kies één eventstroom die makkelijk te begrijpen is en bouw van daaruit. Als je voor Kafka event streaming kiest, houd het eerste topic gefocust, benoem events duidelijk en vermijd het mengen van niet-gerelateerde eventtypes.
Een concreet voorbeeld: als OrderPlaced later shipping, facturatie, support en analytics voedt, laat een log elk team in zijn eigen tempo lezen en na fouten bijwerken. Als je alleen een achtergrondworker nodig hebt om een ontvangstbewijs te sturen, is een simpele queue meestal voldoende.
Voorbeeld: order-events in een groeiend product
Stel je een kleine online winkel voor. In het begin hoeft hij alleen orders aan te nemen, een kaart te belasten en een verzendverzoek te maken. De makkelijkste versie is één achtergrondjob die na checkout draait: “process order.” Die job praat met de payments API, werkt de order-rij in de database bij en belt dan de shipping.
Die queue-stijl werkt goed wanneer er één duidelijke workflow is, je slechts één consumer nodig hebt (de worker) en retries en dead letters de meeste fouten afdekken.
Het begint te knellen als de winkel groeit. Support wil automatische “waar is mijn order?” updates. Finance wil dagelijkse omzetcijfers. Product wil klantmails. Fraud moet plaatsvinden voordat verzending gebeurt. Met één “process order” job blijf je diezelfde worker steeds aanpassen, takken toevoegen en loop je het risico op nieuwe bugs in de kernflow.
Met een log-gebaseerde aanpak produceert checkout kleine feiten als events en kan elk team daarop verder bouwen. Typische events kunnen eruitzien als:
- OrderPlaced
- PaymentConfirmed
- ItemShipped
- RefundIssued
De sleutelverandering is eigenaarschap. De checkout-service bezit OrderPlaced. De payments-service bezit PaymentConfirmed. Shipping bezit ItemShipped. Later kunnen nieuwe consumers verschijnen zonder de producer te veranderen: een fraud-service leest OrderPlaced en PaymentConfirmed om risico te scoren, een e-mailservice stuurt ontvangstbewijzen, analytics bouwt funnels en supporttools houden een tijdlijn bij van wat er gebeurd is.
Hier betaalt Kafka event streaming zich uit: de log bewaart geschiedenis, zodat nieuwe consumers kunnen terugspoelen en vanaf het begin bijlezen (of vanaf een bekend punt) in plaats van elk upstream-team te vragen een extra webhook toe te voegen.
De log vervangt je database niet. Je hebt nog steeds een database nodig voor de huidige staat: de laatste orderstatus, het klantrecord, voorraadniveaus en transactionele regels (zoals “niet verzenden tenzij betaling bevestigd”). Zie de log als het verslag van wijzigingen en de database als de plek om te vragen “wat is er nu waar?”.
Veelvoorkomende fouten en valkuilen
Event streaming kan systemen overzichtelijker doen aanvoelen, maar een paar veelvoorkomende fouten kunnen de voordelen snel tenietdoen. De meeste komen voort uit het behandelen van een eventlog als een afstandsbediening in plaats van als een verslag.
Een veelgemaakte val is events schrijven als commands, zoals “SendWelcomeEmail” of “ChargeCardNow.” Dat maakt consumers sterk gekoppeld aan je intentie. Events werken beter als feiten: “UserSignedUp” of “PaymentAuthorized.” Feiten verouderen goed. Nieuwe teams kunnen ze later hergebruiken zonder te raden wat je bedoelde.
Duplicaten en retries zijn de volgende grote pijnbron. In echte systemen retryen producers en herverwerken consumers. Als je daar niet op plant, krijg je dubbele afschrijvingen, dubbele e-mails en boze supporttickets. De oplossing is niet exotisch, maar wel bewust: idempotente handlers, stabiele event-ID's en businessregels die “al toegepast” detecteren.
Veelvoorkomende valkuilen:
- Events gebruiken in command-stijl die services vertellen wat te doen in plaats van vastleggen wat er gebeurde.
- Consumers bouwen die breken als ze hetzelfde event twee keer zien.
- Streams te vroeg opsplitsen, waardoor één bedrijfsflow over te veel topics verspreid raakt.
- Schemaregels negeren totdat een kleine wijziging oudere consumers breekt.
- Streaming behandelen als vervanging voor goed databaseontwerp.
Schema en versiebeheer verdienen speciale aandacht. Zelfs als je met JSON begint, heb je nog steeds een duidelijk contract nodig: verplichte velden, optionele velden en hoe wijzigingen worden uitgerold. Een kleine wijziging zoals het hernoemen van een veld kan stilletjes analytics, billing of mobiele apps breken die langzamer updaten.
Een andere valkuil is oversplitsen. Teams maken soms voor elke feature een nieuwe stream. Een maand later kan niemand nog antwoord geven op: “Wat is de huidige staat van een order?” omdat het verhaal over te veel plekken verspreid is.
Event streaming haalt niet de noodzaak weg voor solide datamodellen. Je hebt nog steeds een database nodig die de actuele waarheid representeert. De log is geschiedenis, niet je volledige applicatie.
Snelle checklist en vervolgstappen
Als je twijfelt tussen een queue en Kafka event streaming, begin dan met een paar snelle checks. Ze vertellen je of je een simpele overdracht tussen workers nodig hebt, of een log die je jaren kunt hergebruiken.
Snelle checks
- Heb je replay nodig (voor backfills, bugfixes of nieuwe features), en hoe ver terug?
- Zal meer dan één consumer dezelfde events nodig hebben nu of binnenkort (analytics, search, e-mails, fraud, billing)?
- Heb je retentie nodig zodat teams geschiedenis opnieuw kunnen lezen zonder de producer te vragen opnieuw te sturen?
- Hoe belangrijk is ordering, en op welk niveau: per entiteit (per order, per gebruiker) of echt globaal?
- Kunnen consumers idempotent zijn (veilig om hetzelfde event opnieuw te proberen zonder dubbel te belasten, dubbele e-mails of dubbele updates)?
Als je “nee” antwoordde op replay, “één consumer alleen” en “korte levensduur berichten”, is een basisqueue meestal genoeg. Als je “ja” antwoordde op replay, meerdere consumers of langere retentie, betaalt een log-gebaseerde aanpak zich vaak terug omdat het één stroom feiten verandert in een gedeelde bron waarop andere systemen kunnen bouwen.
Vervolgstappen
Zet de antwoorden om in een klein, testbaar plan.
- Noteer 5–10 kern-events in gewone taal (voorbeeld: OrderPlaced, PaymentAuthorized, OrderShipped) en noteer wie publiceert en wie consumeert.
- Bepaal de ordering key (vaak per entiteit, zoals
orderId) en documenteer wat “correcte volgorde” betekent.
- Definieer een idempotentieregel per consumer (bijvoorbeeld: sla de laatst verwerkte event-ID per order op).
- Kies een retentiedoel dat past bij je behoeften (dagen voor queue-achtige workflows, weken/maanden wanneer replay ertoe doet).
- Draai één end-to-end slice in een sandbox voordat je het hele systeem vastlegt.
Als je snel prototypeert, kun je de eventflow schetsen in Koder.ai planningmodus en itereren op het ontwerp voordat je eventnamen en retryregels vastzet. Omdat Koder.ai sourcecode-export, snapshots en rollback ondersteunt, is het ook een praktische manier om een enkele producer-consumer slice te testen en eventvormen aan te passen zonder vroege experimenten in productieschuld te veranderen.